Evaluating Long Context (Reasoning) Ability
超越“草堆找针”:构建更真实的长上下文评测体系
原文:https://nrehiew.github.io/blog/long_context/
背景
推理模型和长链式智能体轨迹正在占据上下文窗口中宝贵的空间。为了应对这一情况,模型厂商不断推出具有更大上下文窗口的模型;最新的 Grok 4 Fast 甚至拥有 200 万个 token 的窗口。
然而,任何使用过这些模型的人都知道:模型能够接收的 token 数量,与它能够真正进行推理的 token 数量并不相同。模型性能往往在远未达到标称窗口长度时就已经显著下降。这与众多模型提供商宣称的“完美上下文窗口”相矛盾。
有效上下文长度(Effective Context Length)
| 模型 | 有效上下文长度 |
|---|---|
| Gemini 2.5 Pro (High)、GPT-5 (High) | 128 k (最大) |
| Claude Sonnet 4、Qwen 3 Max (blue) | 64 k–128 k |
| Grok-4 Fast、DeepSeek Chat v3.1 | 32 k–64 k |
| Grok-4 | 16 k–32 k |
| Kimi K2、GLM 4.5 (High) | < 32 k |
“有效上下文长度”指的是在 LongCodeEdit 基准测试(其最大上下文长度为 128 k)上,模型性能仍然保持高且稳定的最大输入 token 长度。
在本文中,我将通过分析现有的长上下文基准测试,展示这种差异存在的原因。随后,我将讨论什么样的测试才是一个好的长上下文基准,并介绍一个新的基准测试——LongCodeEdit。
现有的长上下文评估(Existing Long Context Evaluation)
目前的长上下文基准测试主要尝试回答三个核心问题:
1. 模型是否能够访问其上下文窗口?
这是最直接的问题,本质上是看模型的最后一个 token 是否能“看到”第一个 token。
例如,一个可以输入 100 万个 token、但训练时只见过 4K 序列的模型,由于训练时的掩码限制,很可能无法真正访问到整个上下文。
最早被广泛使用的长上下文基准是 Needle In A Haystack(NIAH,草堆中的针)。
该测试中,模型会收到一个查询、一段冗长的“草堆”文本,以及隐藏在其中的一根“针”(即答案),任务是找到那根针。后来,RULER 对其进行了扩展,引入了多根针甚至干扰针的设定。
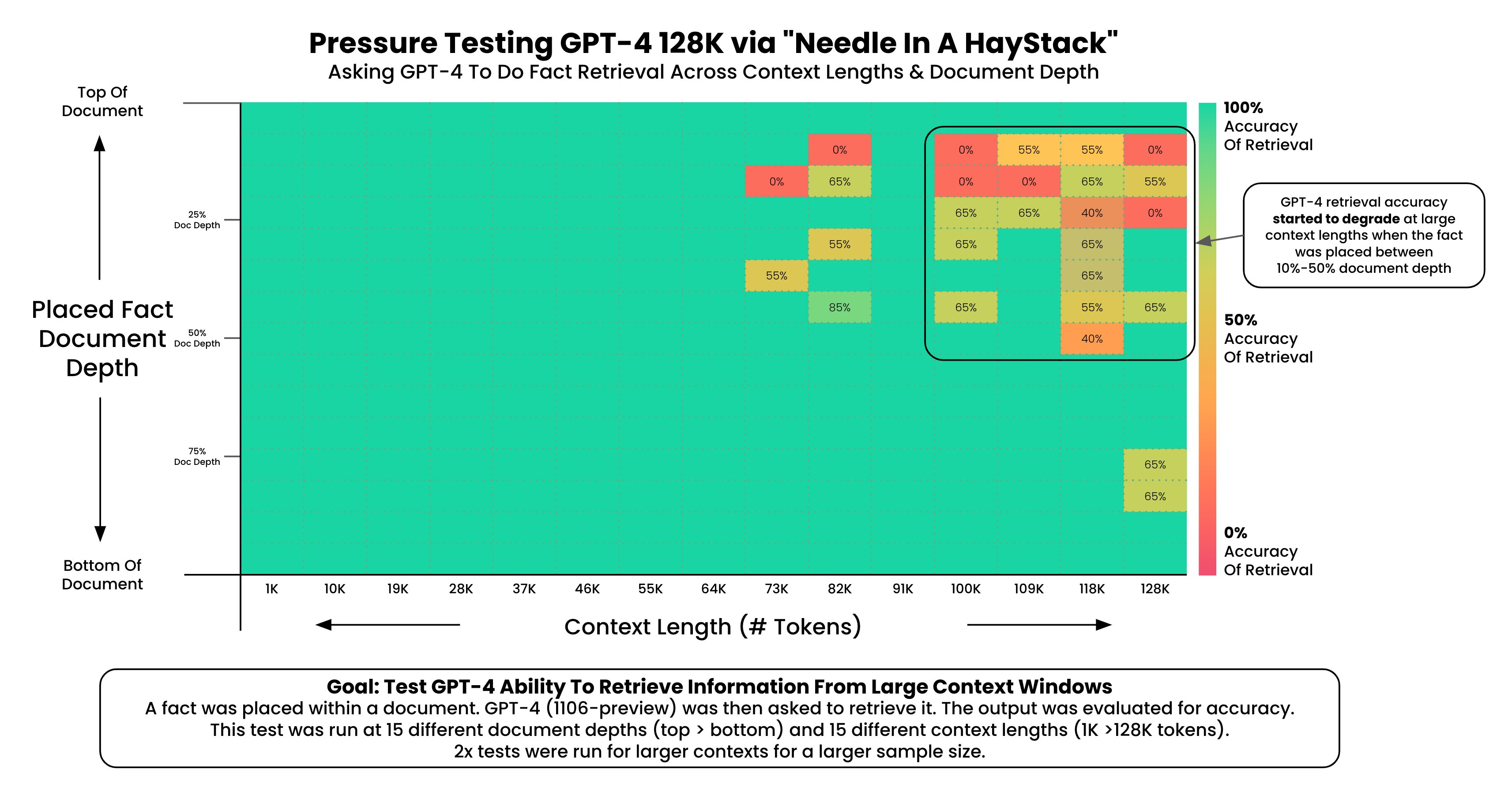
📊 Needle In A Haystack 示例:
模型在一篇很长的文章中查找一个特定短句或数字,若能成功定位即为通过。
这种测试曾因模型全绿的结果图而走红网络,被大量引用。但这种基准很快“饱和”了,不再能有效衡量模型的长上下文能力。
原因很简单——我们来看一个 RULER 的示例:
…Which means that what matters is who you are, not when you do it.
…The special magic number for XXX is 12345.
…Question: What is the special magic number for XXX?
这里的“针”(12345)与上下文内容完全无关,任务只是简单的字符串检索,几乎不需要推理。模型只需找到并复述即可。
2. 模型是否能够理解输入中的每个 token?
在这种设定下,我们假设模型能够正确检索所需信息,进一步关注它是否真正理解上下文。
最具代表性的改进是 NoLiMa,它将 NIAH 改造成一个问答任务。
此时,“针”来自与“草堆”相同分布的数据,但与问题几乎没有字面重叠,迫使模型至少进行一次推理才能建立关联。
此外:
- RULER 也加入了基于 SQuAD 数据集的 QA 任务。
- HELMET 将多个文档拼接起来,问题可能出自任意一个文档。
- LongBench v2 扩展到更多领域,包括代码仓库、结构化数据与长对话。
- Fiction.Live 是更具挑战性的 QA 基准,答案无法直接从单句中提取,而需在整个文档中进行推理。
3. 模型是否能够执行真实世界的长上下文任务?
长上下文评估的一大问题是——高质量的长上下文数据极为稀缺。
因此,大多数基准测试往往通过在已有任务(如语言建模或 QA)上人为填充无关内容来延长上下文。
这些任务本身往往过于简单,例如 RULER 使用的 SQuAD v2(2018 年发布) 已被所有主流 LLM 完全攻克。
相比之下,若我们将这些长上下文任务与通用智能评测(如 GPQA Diamond)对比,其难度差距极大。
📘 NoLiMa 示例:
文本:“…Actually, Yuki lives next to the Semper Opera House…”
问题:哪个角色去过德累斯顿?
答案:Yuki(因为 Semper 歌剧院在德累斯顿)
📗 GPQA Diamond 示例:
关于新分子 Xantheraquin 的多手性和互变异构分析问题,选项涉及量子化学、ADME 模拟和体外验证。
答案:D — 在进行大规模对接研究之前,通过体外结合实验验证最有希望的构型。
可以看到,GPQA 类型的问题明显更贴近真实科研和复杂推理,而大部分长上下文测试仍停留在“低级 QA”层面。
新定义与局限
OpenAI 最近推出的 MRCR 给出了他们对“具有挑战性的长上下文任务”的定义:
MRCR 的挑战在于:
- 针与干扰项来自相同分布(都由 GPT-4o 生成),针不会显得突兀;
- 模型必须识别针的顺序;
- 针越多、任务越难;
- 上下文越长、任务越难。
然而,这一设定依然不能完全代表真实世界的长上下文任务难度。
例如,“重复第二首关于貘(Tapir)的诗”这种任务,与“找出这份财务报告中的错误”或“让一个研究型智能体在海量搜索结果中筛选信息并生成报告”相比,显然要简单得多。
后两者才真正体现出对复杂推理与理解能力的需求。
什么样的测试才算“好的”长上下文基准?
把长上下文任务看成两个阶段会很有帮助:首先,模型需要判断输入中哪些部分是相关的;然后,它必须完成真正的任务。从评测角度看,我们希望这两个阶段都足够困难,并且需要实质性的推理。例如,相关片段(“针”)至少应当与序列其余部分来自同一分布,而任务本身也不应只是简单的复读一句话。许多现有基准仅通过“把搜索空间垫大”来让第一阶段变难。
一个具有代表性的高难基准是 GSM-Infinite,它用随长度递增的合成小学数学问题评估模型。每增加一条信息,就在计算图中多一个节点,使得模型的推理路径更难遍历。另一个例子是 LoCoDiff:给模型一系列 diff,要求输出文件的最终状态。在这个任务里不存在“相关性筛选”,因为每个 diff 都是相关的;但随着序列变长,状态变更更多,任务难度自然上升。事实上,LoCoDiff 的排行榜对“具有挑战性的长上下文任务”的定义,比 OpenAI 的定义更贴近真实需求(后者仍过度强调检索):
- 使用天然相互关联的内容,而非人造或随意填充的上下文
- 无“废料”上下文:上下文的每一部分都是完成任务所必需的
- 测试对代码智能体至关重要的真实能力:跟踪被编辑文件的状态
把长上下文任务简化为检索的一个问题在于:它忽略了除“无法访问上下文窗口”之外的另一类失败模式——即使模型能访问所有相关信息,随着上下文长度增长,其推理能力也常常下降。这通常被称为 “上下文腐蚀(Context Rot)”。其表现包括:幻觉概率上升、不稳定性增加,或在长链式智能体交互中出现“厄运循环(doom loops)”。因此,一个有效基准不仅要评估“能否找对片段”,还应评估在长上下文下维持推理质量的能力。
接下来的部分,我将尝试设计一个新的长上下文基准。通过这个过程,我会展示基准设计的思路,并将其与上述标准逐条对照比较。
改写句复现基准(Paraphrased Sentence Repeater,PSRBench)
PSRBench 分数概览
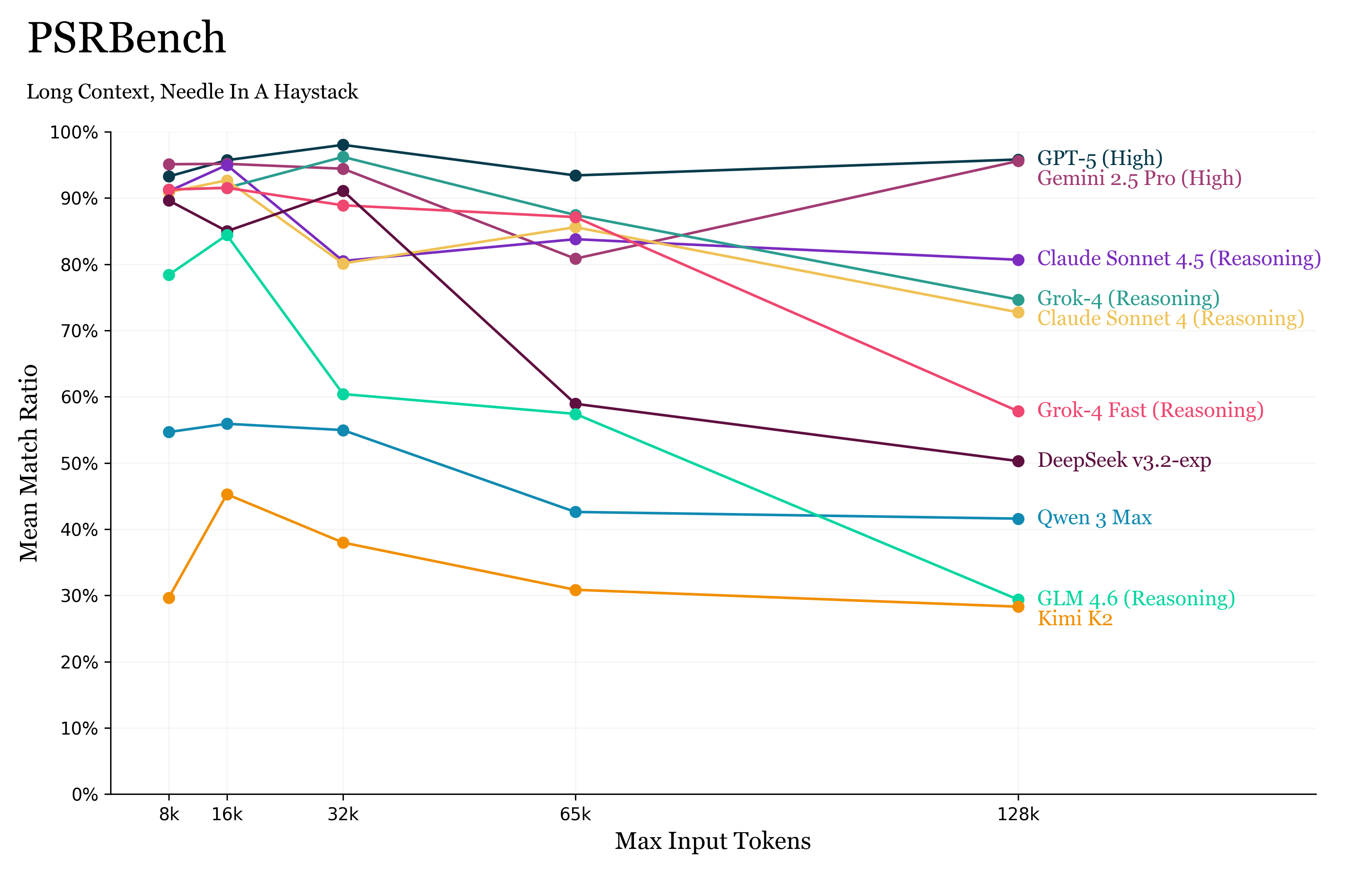
这项初步尝试借鉴了许多现有基准的思路。
PSRBench 给模型提供一篇长文档,以及一句经过改写(同义转换)的句子。模型需要回答:原句(未改写版本)的上一句或下一句是什么。
与 MRCR 一样,模型的表现通过 最长连续子序列比例(Longest Consecutive Subsequence Ratio) 来评估。
文档来自 LongWriter 数据集,并被拼接成不同上下文长度的输入提示。随后,从文档中随机抽取一句话,并用 Gemini 2.5 进行改写。
📘 示例:

绿色表示改写句(query),蓝色是原句,红色是目标答案(needle)。
Vault Boy 的顽皮笑容扩大了,他准备将自己恶臭的武器释放到毫无防备的水生生物身上……
Question:与 “He methodically situated himself in the pool’s center, making certain he was in its deepest section” 含义相同的那句话之后是什么?
PSRBench 相比许多 NIAH 基准有所改进,因为与 NoLiMa 类似,它的“针”并非查询句的字面匹配项,而是语义等价。此外,“针”与干扰项(distractors)来自相同分布,因此没有查询就难以区分。
然而,相关性判定阶段仍然相对简单——模型只需逐句进行语义相似度匹配,而这是当前 LLM 的强项。任务本身(输出改写句前/后的句子)也几乎没有难度。
因此,PSRBench 的问题与其他许多基准相同:模型只需执行复杂度约为 O(tokens)O(\text{tokens})O(tokens) 的简单操作,挑战仅在于是否能在几千个 token 上重复执行该过程。
类似的例子包括:
- Bench:从长列表中找出最大数字;
- RULER:让模型跟踪一长串变量赋值(如
x1 = 123; x2 = x1; x3 = x2)或找出最常见单词; - OpenAI GraphWalks:给出图的邻接表,让模型执行广度优先搜索(BFS)。
LongCodeEdit:更真实的长上下文任务设计
我认为设计优秀基准的思路是:从真实的长上下文任务出发,再尽可能抽象出最小可复现环境。
例如在软件工程中,一个智能体需要阅读庞大的代码库并在同一会话内编辑多个文件。
因此,我提出 LongCodeEdit ——评估模型在给定大量代码的情况下识别并修复程序错误的能力。
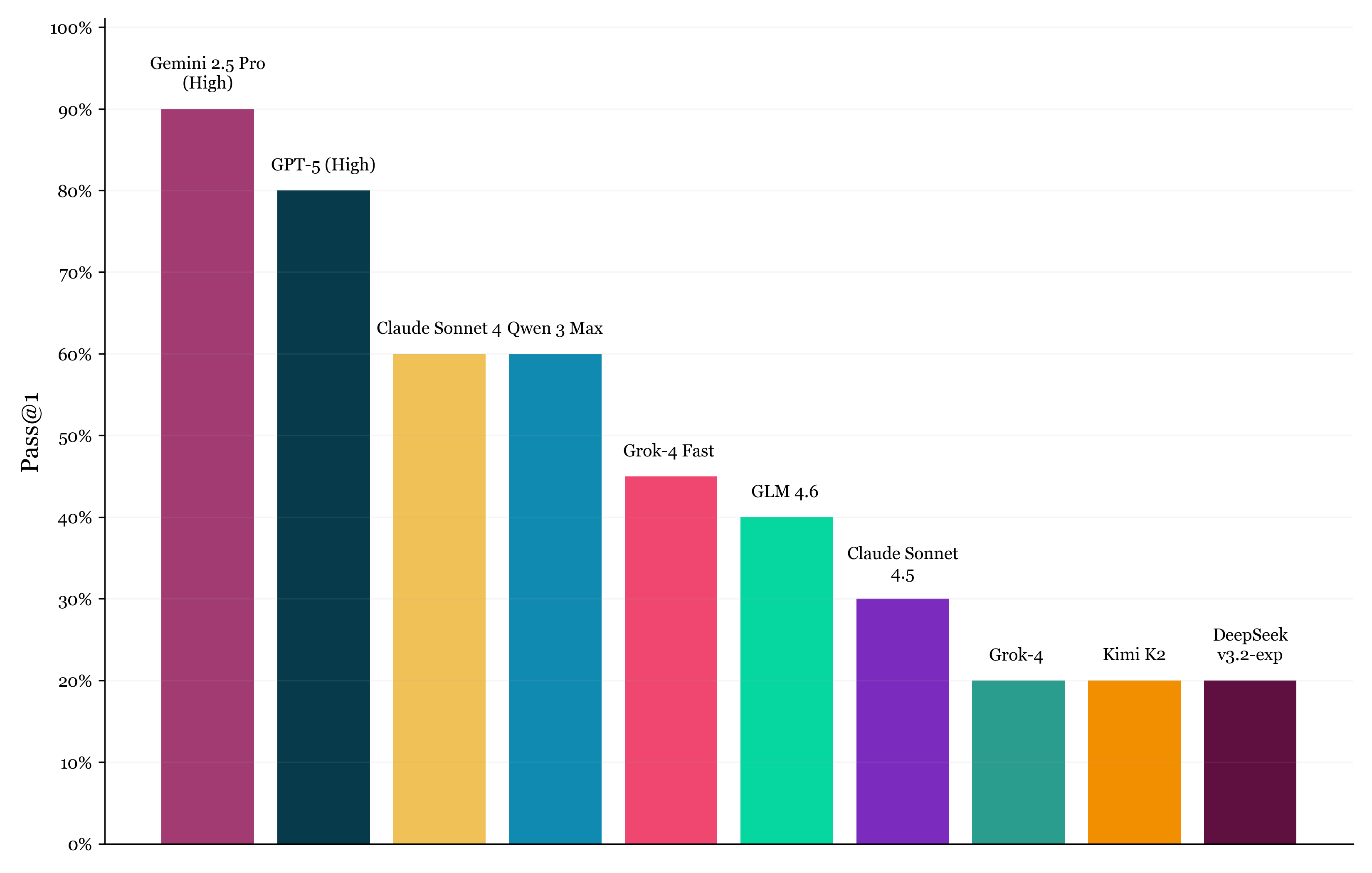
LongCodeEdit 分数概览
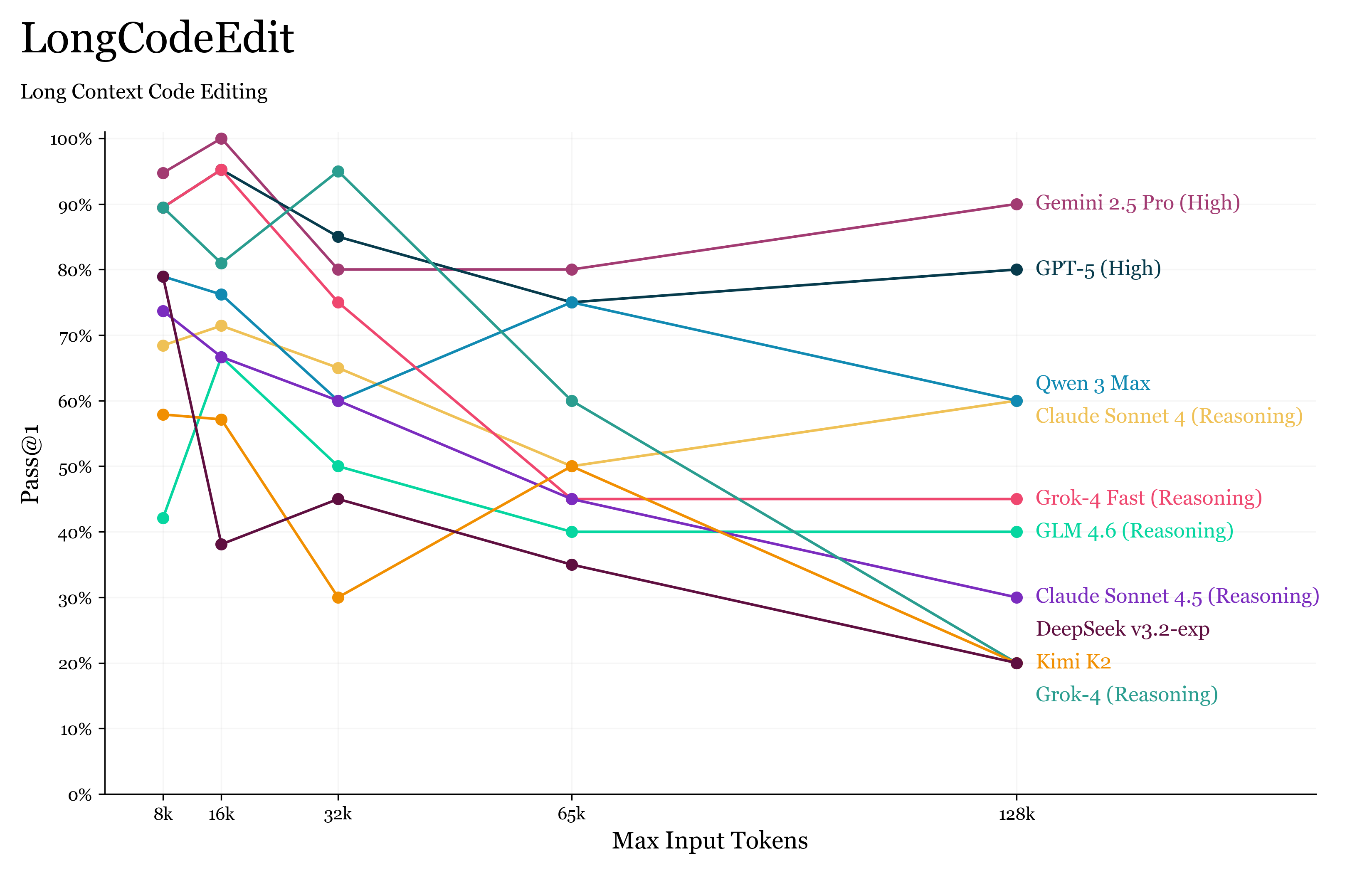
我们从 BigCodeBench 中选取样本,手动破坏部分 Python 函数,让其在测试用例下失败但语法仍然正确。
多个函数(仅一个有问题)会与对应的测试用例拼接在一起提供给模型。模型需找出并修复出错函数,性能通过 Pass@1 衡量。
📄 示例:
# def task_func1 ...
# def task_func2 ...
def task_func_3(src_folder, backup_dir):"""Backs up a given source folder to the specified backup directory, then deletes the source folder.Parameters:src_folder (str): The path of the source folder to be backed up and deleted.backup_dir (str): The path of the directory where the source folder will be backed up.Returns:bool: True if the operation is successful, False otherwise.Requirements:- os- shutilRaises:- ValueError: If the source folder does not exist.- Exception: If an error occurs while deleting the source folder.Example:>>> import tempfile>>> src_folder = tempfile.mkdtemp()>>> backup_dir = tempfile.mkdtemp()>>> with open(os.path.join(src_folder, 'sample.txt'), 'w') as f:... _ = f.write('This is a sample file.')>>> task_func_3(src_folder, backup_dir)True"""if os.path.isdir(src_folder): # <--- 这里是错误raise ValueError(f"Source folder '{src_folder}' does not exist.")backup_folder = os.path.join(backup_dir, os.path.basename(src_folder))shutil.copytree(src_folder, backup_folder)try:shutil.rmtree(src_folder)return Falseexcept Exception as e:print(f'Error while deleting source folder: {e}')return False
模型会同时得到多个函数及其测试用例,这里第 3 个函数是有问题的。
评估 LongCodeEdit 的两阶段表现
-
相关性判定阶段
模型必须通读所有函数,判断其是否满足 docstring 中的功能描述。
测试用例放在所有函数之后,因此模型需同时关联输入的多个部分,而非仅局部匹配。
错误检测本身也难度较高,因为模型必须根据测试用例推断函数逻辑。 -
任务执行阶段
修复代码本身也更具挑战。
判断任务本身固有难度的一个方法是:如果我们提取出相关部分放入一个新的短上下文中(跳过第一阶段),模型能否轻松完成?
在 OpenAI-MRCR 中,许多模型在 8K 上下文下准确率 >95%;
但在 LongCodeEdit 中,即使是最好的模型在短上下文下也只有约 90% 的准确率。
因此,下一步是让任务本身更难。
LongCodeEdit-Hard:更困难版本
LongCodeEdit-Hard 版本不再提供测试用例,而是用更多函数替代。
这更贴近许多真实的代码生成基准(如 BigCodeBench),其中模型除了 docstring 和问题描述外,没有任何测试信息。
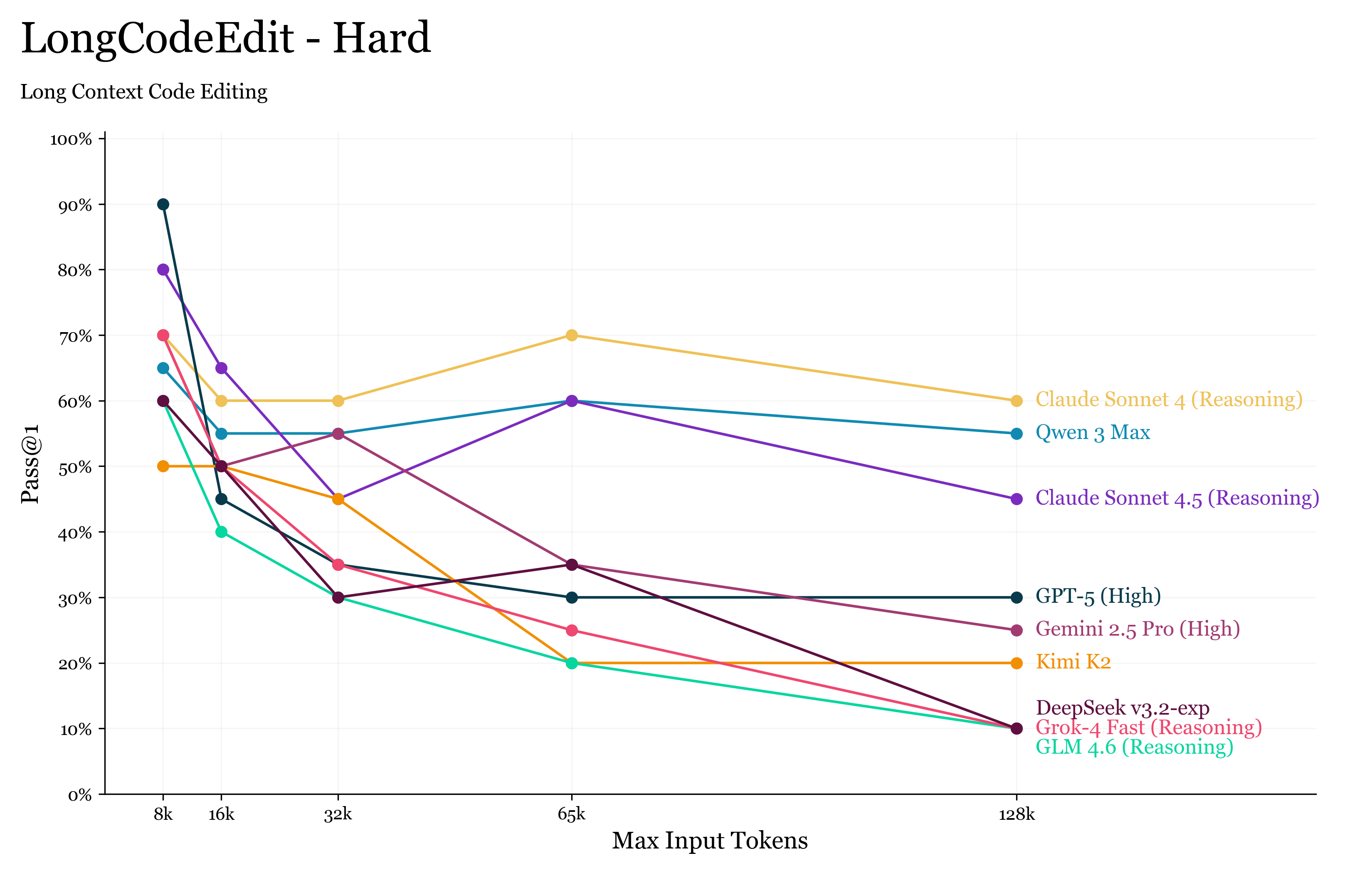
结果显示,LongCodeEdit-Hard 难度显著提升:
即便在 8K 上下文下,模型准确率也仅为 60–70%。
这符合一个理想长上下文基准的标准——相关性判定与推理阶段都困难,并且随上下文长度自然增加。
进一步观察:错误检测能力
我们还绘制了模型在 仅检测错误函数(不要求修复)时的表现:
📊 LongCodeEdit-Hard Detection Scores
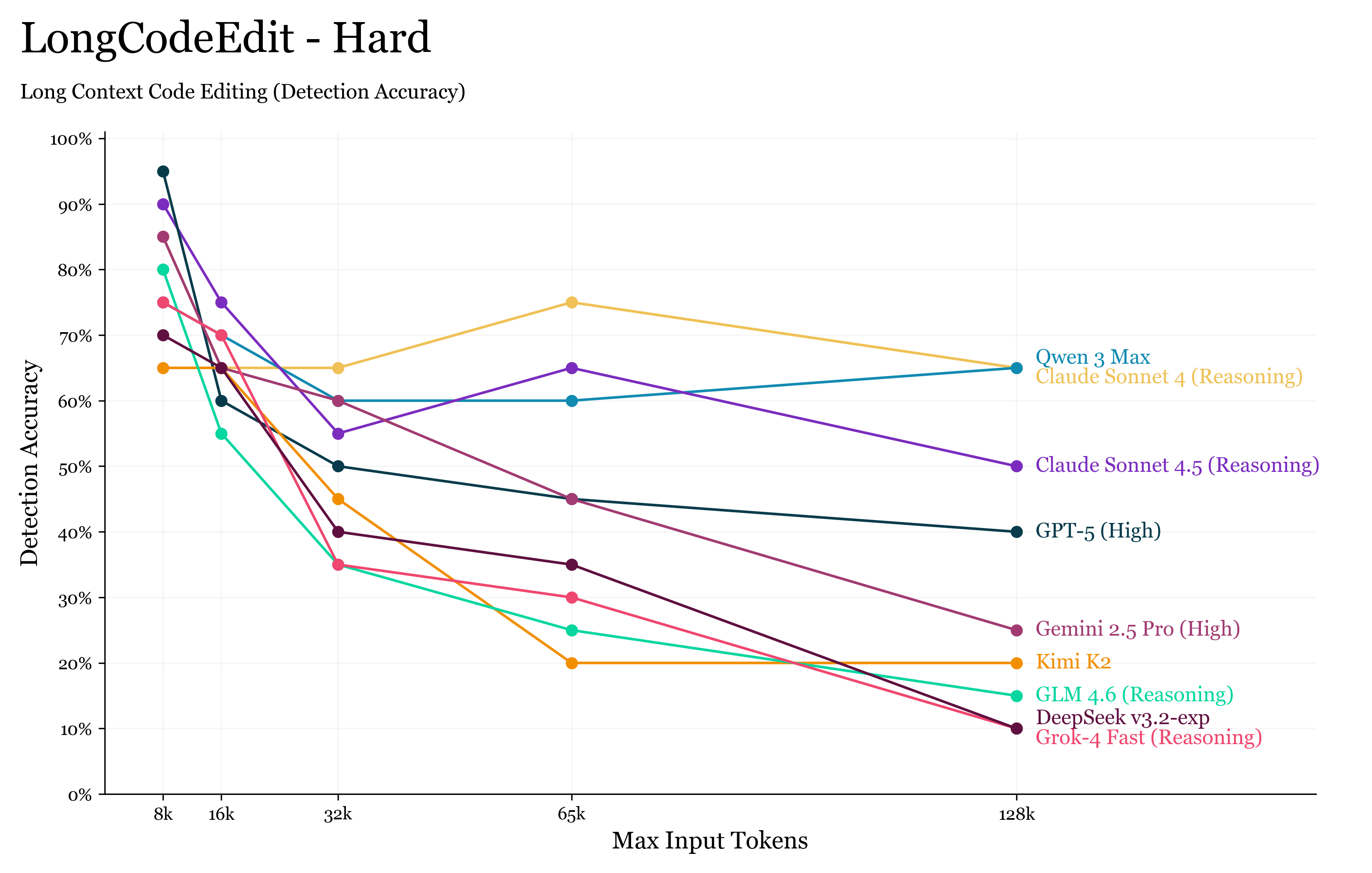
结果与 Pass@1 非常接近,这说明主要失败模式是错误检测失败,而非代码修复失败。
表现较差的模型往往容易分心——没有测试用例时,它们只能依靠 docstring 来理解函数需求,可能会过度推理或臆造错误。
考虑到我们对函数所施加的错误都非常微妙(后续将详细说明),它们成为了极强的干扰因素。
总结思考(Final Thoughts)
本文的目的并不是要否定那些只关注前两个问题(能否访问上下文窗口、能否理解输入 token)的基准。
研究架构在长上下文下的极限始终是重要的——例如,Qwen 3 Next 报告 RULER 得分就是一件好事,因为我们需要知道:线性注意力(Linear Attention)带来的效率提升,是否会以牺牲模型“看全上下文”的能力为代价。
我们许多人都曾遇到模型在长输入下表现异常的情况,例如输出乱码或陷入“doom-loop(死循环输出)”。
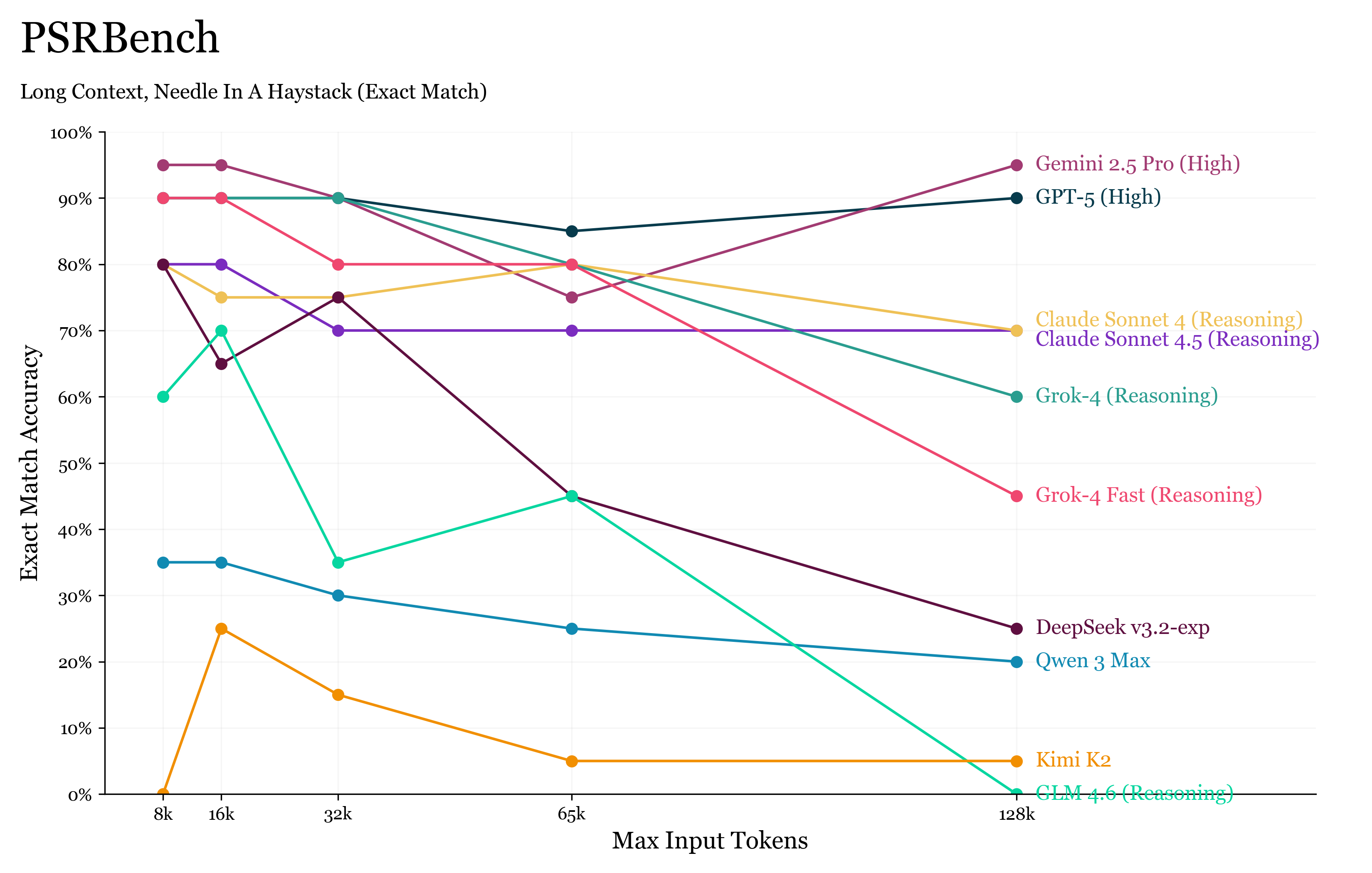
例如,你可能注意到 OpenAI MRCR 和 PSRBench 都报告的是“平均匹配率(mean match ratio)”而非“精确匹配率(exact match)”。
但当我们改看 PSRBench 的精确匹配结果 时,发现即使是最顶尖的模型也出现了约 6% 的性能下降。
对于这样一个几乎只是句子复现的任务,这种下降十分令人意外,也再次说明——前两个问题(可访问性与理解能力)仍远未被完全解决。
📊 PSRBench 精确匹配分数(Exact Match Scores)
综上,我希望本文能让你意识到:
当前的长上下文基准测试越来越单一化,我们需要更具挑战性的方式来评估模型的长上下文推理能力。
这在最近围绕 METR(长时任务评估) 的讨论中显得尤为重要。
如今的模型开始执行那些人类需要数小时才能完成的真实任务,而这些任务与现有长上下文基准的难度相比,存在巨大鸿沟。
最后要强调的是:
基准测试的真正目的,是在尽可能接近真实场景的环境中暴露模型的失败模式。
当一个新基准发布后,新模型在上面拿到近乎完美的分数时,这个基准往往就变成了“公关秀”。
一个好的基准,应该能让人“感到尴尬”。
当我们不再因为结果而皱眉时,也就该换新的基准了。