大模型通识
目录
一、基础概念
稠密模型/稀疏模型
二、大语言模型训练
pre-training“预训练”
Post training后训练
三、为什么需要强化学习?大模型的短板是什么?
RLHF 的核心流程
一、基础概念
大语言模型:LLM,如deepseek,豆包
prompt:提示词,聊天时,输入的话语
token:大模型理解内容的最小单元,prompt被“分词器”(tokenizer)切分成一个个的token;每个token都对应着一个数字叫token id
大模型的任务:计算这串token序列后应当续写哪些token。
为了完成这个任务,大模型普遍采用了Transformer架构,他采用了“自注意力机制”,能很好的捕捉上下文之间的关联。
过程:在计算的时候,大模型会采用一个token一个token的计算,每次计算他都会把新生成的token加入到原有的token序列,再投入到模型中,算出下一个token,再加入token串,再投入大模型再算出下一个token,如此循环往复,大模型就会输出一个长长的回答,所以大模型计算的本质就是在不断的“续写”token串。
联网搜索/外挂私人知识库:使用RAG功能(检索增强生成--Retrieval-Augmented Generation)。先把互联网或者知识库中抓取到的内容加入到token串里,再开始计算续写,这样可以提高输出的准确率,这一串过程就是大模型在工作时的基础流程。
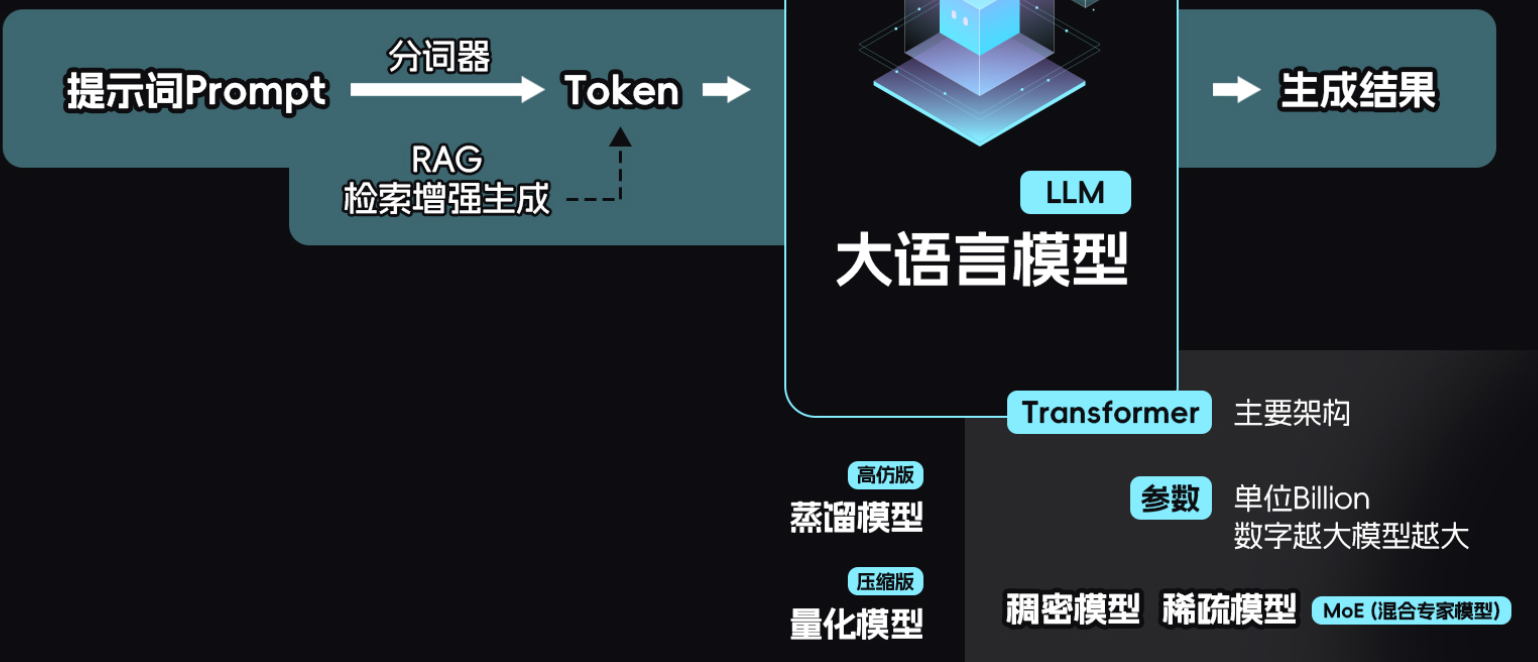
大模型是在计算结果,因为他的内部有很多数学表达式,这里面就有很多可以调整的“参数”,很多人都认为模型参数越多,规模越大,算力越高表现就好==>Scaling Law
很多大模型后面都会标注参数的大小,B===Billion十亿
稠密模型/稀疏模型
稀疏模型:当问一个问题时,并不会调动所有的参数,只会激活其中跟问题相关的一部分参数,比较冷静,能降低计算量,提升速度。
稀疏模型中最流行的一种加MOE==> “混合专家模型”(deepseek),他们通过“门控网络”,给每个问题分配合适的“专家”,赋予他们不同的权重,再生成结果。
二、大语言模型训练
不管怎么说每个大模型中的参数量都远远超出了手动设定的范围,怎么才能将他们调整的恰到好处,做出一颗能说会道的大脑呢?
pre-training“预训练”
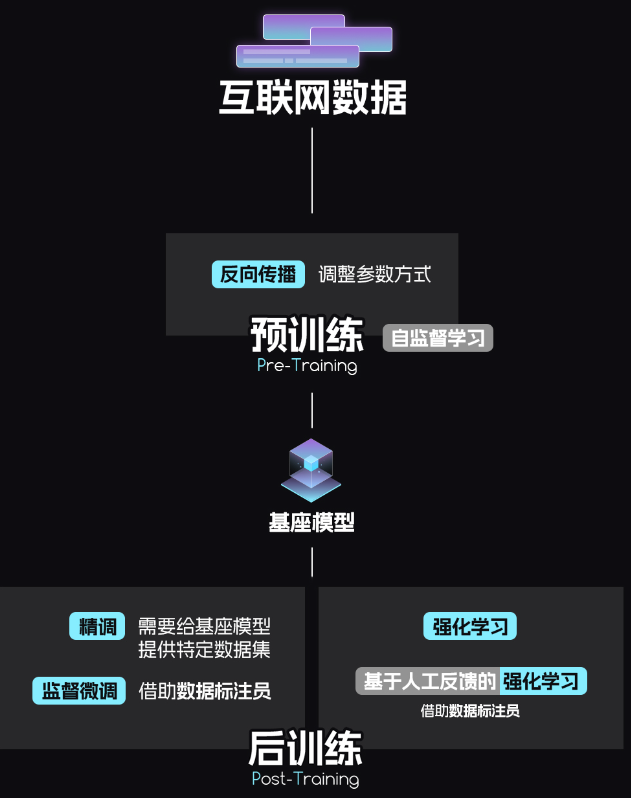
大模型制造的第一步是利用海量的互联网数据,做pre-training“预训练”,这是为了让大模型掌握人类世界各种知识和语言规律,打造出一个“基座模型”。过程:让他爬遍互联网,把大家创作的饱含人类智慧的知识精华作为数据集认真学习,并通过一种叫“反向传播”的方法,让大模型自己调整参数。
前向传播:当我们把token输入模型时,模型里会经过一顿计算,输出一个结果,这个叫“前向传播”。
反向传播:初始的预测结果往往不尽人意,我们训练的目标是让大模型输出xx,那就要把错误回答和目标进行对比,看看差了多少,这一步就是计算“损失”(loss),通过计算损失,模型可以反向找到在整个传播过程中,到底是哪些步骤出了问题,然后调整他们对应的参数,如此循环往复,逐步调整,直到输出结果逼近目标。
在预训练的时候,大模型要学习的内容太多,数据量很大,靠人力梳理根本赶不过来,所以目前预训练主要都用“自监督学习”,让大模型自己去看数据,计算损失,调整参数,自己调教自己,预训练是大模型中最耗时耗力的阶段,往往需要几个月甚至几年。预训练完成后,我们就得到一个base model“基座模型”。
base model“基座模型”:一个互联网模拟器或者一个学会了人类世界知识的“通用大脑”,无论你输入什么,他都能续出一个合适的token,不过基座模型一般不能直接用,为了把他从一个“通用大脑”编程一个有特定功能的“打工人”,我们还需要给他做Post training==”后训练”。
Post training后训练
Fine tuning(微调),他就是后训练时完成的,目前最常用的方法是“监督微调”(Supervised Fine-Tuning,SFT),所谓的“监督”就是说要给ai提供带标注的数据集,让他模仿标注数据的风格来生成内容,比如,要把他做成我们最常用的各类“对话助手”,那就要给基座模型提供对话数据集。
如果要给大模型注入灵魂,进入后训练中最重要的一步,强化学习(Reinforcement Learning),通过强化学习,大模型输出的答案会更符合人类偏好,甚至展现出超越人类的“智力”,强化学习的具体方法很多,其中一些思路即简单又巧妙。
三、为什么需要强化学习?大模型的短板是什么?
大模型通过海量文本预训练(Pretraining)学到了语言规律,但存在关键问题:
1.“正确答案”不唯一 同一个问题可能有多种合理回答(如“如何减肥?”有科学饮食、运动等多种方案)。
2.缺乏价值观对齐(Alignment Problem) 模型可能生成有害、偏见或不符合人类偏好的内容(例如暴力、虚假信息)。
3.监督微调(SFT)的局限 人工撰写示范答案成本高,且无法覆盖所有场景。
强化学习的作用:用人类偏好作为“指南针”,引导模型生成更安全、有用的回答。
RLHF 的核心流程
第 1 步:监督微调(SFT)—— 打基础
操作:用人工编写的优质问答数据微调预训练模型。
目标:让模型初步学会遵循指令生成合理回答。
第 2 步:奖励模型训练(RM)—— 学习人类偏好
关键操作:
让SFT模型对同一问题生成多个候选答案(如4个);
人工标注答案的优劣排序(如 A > B > C > D);
训练一个奖励模型(Reward Model) 学习人类偏好:
输出:奖励分数(Reward Score)
输入:(问题, 答案)
技术细节: 使用排序损失函数(如 Pairwise Ranking Loss),强制模型对优质答案打出更高分。
第 3 步:强化学习微调(RL)—— 对齐人类偏好
框架:将语言模型视为 策略(Policy),奖励模型作为 环境(Environment)
操作:
输入问题,当前模型(Policy)生成答案;
奖励模型(RM)对该答案打分(Reward);
使用 PPO 算法(近端策略优化)更新模型权重:
目标:最大化奖励分数
约束:防止模型偏离原始SFT模型太远(避免“放飞自我”)。
KL散度惩罚:确保模型生成的内容不过度偏离原始监督微调结果。