MFF-YOLOv8:基于多尺度特征融合的无人机遥感图像小目标检测
摘要
https://ietresearch.onlinelibrary.wiley.com/doi/epdf/10.1049/ipr2.70066
在无人机拍摄场景中,目标检测是一项热门任务,其图像包含大量小目标,但现有网络常出现漏检和误检问题。为解决此问题,我们提出了一种基于多尺度特征融合的YOLO算法——MFF-YOLOv8,用于无人机航拍图像中的小目标检测。首先,我们设计了一个高分辨率特征融合金字塔(HFFP),该模块利用包含丰富小目标信息的高分辨率特征图来引导特征融合模块,对特征图进行加权融合,从而增强网络对小目标的表征能力。同时,采用了一个重建特征选择(RFS)模块,以去除高分辨率特征图产生的大量噪声。其次,在骨干网络中设计了一种混合高效多尺度注意力(HEMA)机制,以最大限度地保留和提取与小目标相关的特征信息,同时抑制背景噪声干扰。最后,设计了一种内智交并比(Inner-WIoU)损失函数,用于联合辅助边界框和动态焦距边界框回归,从而提高网络回归结果的准确性,进而提升模型对小目标的检测精度。MFF-YOLOv8在VisDrone2019数据集上进行了实验,取得了47.9%的mAP50,相比基线网络YOLOv8s提升了9.3%。此外,为了验证整体网络的泛化能力,还在DOTA和UAVDT数据集上进行了评估,mAP50分别提升了3.7%和1.8%。结果表明,MFF-YOLOv8显著提升了无人机航拍场景中小目标的检测精度。
1 引言
无人机因其能够搭载多种传感器进行常规巡检而备受青睐,具有数据采集强度高、运营成本低、运输便捷等优势,因此在作物监测、交通管制、城市规划、市政管理、电力线巡检、搜救行动、国防等领域得到日益广泛的应用[1, 2]。然而,传统的物体检测方法面临时间复杂度高、窗口冗余度高、缺乏特异性以及特征设计困难等挑战,难以满足无人机图像目标检测的需求。
近年来,基于深度学习的目标检测算法异军突起,成为研究热点。与传统方法相比,深度学习具有自动特征学习、高精度、强模型泛化能力和高可扩展性等优势。因此,越来越多的研究人员采用深度学习技术来解决无人机影像中的目标检测难题[3]。这一趋势在农业、交通、城市规划、市政管理、电力线巡检和搜救行动等多个领域均有体现。基于深度学习的主要目标检测方法包括两阶段检测算法、单阶段检测算法和视觉Transformer。两阶段算法(如R-CNN系列,包括Faster R-CNN[4]、Mask R-CNN[5]、Cascade R-CNN[6]和R-FCN[7])首先生成候选边界框,然后精炼目标区域,检测精度高但速度慢。单阶段算法(如YOLO[8]、YOLOv3[9]、YOLOv4[10]、YOLOv7[11]、SSD[12]和RetinaNet[13])直接预测物体位置和类别,省略了冗余过程,检测速度更快。视觉Transformer将图像分割成序列化的块,并利用自注意力机制捕获全局信息,在物体和场景识别上更为准确,例如Swin Transformer[14]、Detection Transformer (DETR)[15]、MViT[16]及其后续变体。
在无人机影像的小目标检测中,平衡速度、精度和模型大小至关重要。单阶段检测算法(如YOLO)因其出色的实时性能和高精度而受到青睐。然而,YOLO系列主要针对全尺寸物体,这限制了其在处理大量小目标时的有效性。由于其广泛应用的成功,研究人员已开发出多种策略来增强其对小目标的检测精度。Zhu等人[17]将Transformer预测头集成到YOLOv5架构中,提出了TPH-YOLOv5模型。该模型引入了额外的检测头和卷积块注意力模块(CBAM)[18],以增强对多尺度和密集物体的检测能力,但这些改进带来了更高的计算和参数复杂度。Zhao等人[19]通过在深度、宽度和分辨率上扩展特征提取网络,提出了Fire-YOLO,该方法增强了在光照条件下受干扰的森林火灾图像中对更小规模火灾的检测。Wang等人[20]通过引入BiFormer注意力机制提出了UAV-YOLOv8,并采用焦距FasterNet块(FFNB)进行特征处理,增加了两个检测尺度,有效聚合了浅层和深层特征信息,降低了小目标的漏检率。Xu等人[21]通过引入一种新的残差神经网络变体——跨阶段部分重参数化视觉几何群(CSP-RepVGG),提出了PP-YOLOE模型。该模型采用无锚点解耦头和任务对齐学习(TAL)标签分配策略,提高了训练速度和效率。
同时,超分辨率技术也广泛应用于小目标检测任务。Courtrai等人[22]将基于残差块的生成对抗网络集成到循环模型中,并添加辅助网络进行检测,丰富了航拍图像中小目标的空间信息细节,提高了小目标特征信息的检测能力。Zhang等人[23]设计了一个高分辨率特征提取器,以提取真实的高分辨率特征作为特征级监控信号。这些真实高分辨率特征可以引导生成器网络直接从低分辨率图像中提取高分辨率特征,从而实现了船舶数据集中小船检测精度的提升。
然而,上述方法仍存在一定的局限性,导致小目标的漏检和误检。这些问题包括:检测过程中对小目标的特征提取不完整;网络中多次下采样操作导致小目标信息大量丢失;以及损失函数对不同尺度目标的敏感性不同。
为解决上述问题,我们提出了一种改进的YOLOv8算法——MFF-YOLOv8,用于无人机航拍图像中的小目标检测,该算法基于多尺度特征融合。本算法的主要贡献如下:
- 为聚合更多有利于小目标检测的特征信息,我们设计了一个高分辨率特征融合金字塔(HFFP)模块,以改进颈部网络,并充分利用不同尺度的特征信息。引入P2层的高分辨率特征图以获取更多小目标的特征信息。同时,利用重建特征选择(RFS)模块去除高分辨率特征图产生的大量噪声,从而获得更多的小目标信息。
- 为使网络能有效提取无人机航拍图像中小目标的特征信息,我们设计了一种混合高效多尺度注意力(HEMA)机制,并将其与特征提取模块中的C2f模块结合,得到一个新的HEMA_C2f模块。该新模块收集多尺度特征信息,并充分利用特征图的空间和通道信息,从而全面提取小目标的特征信息。
- 为缓解完整交并比(CIoU)损失在小尺度目标回归中的显著误差,我们提出了内智交并比(Inner-WIoU)损失,旨在改善复杂背景下的小目标检测。
2 相关工作
2.1 目标检测中的多尺度特征
构建有效的特征金字塔对于检测多尺度物体至关重要。深度神经网络具有强大的语义表征能力和广阔的感受野,能够有效编码复杂的语义信息。然而,深度网络中特征图的低分辨率导致特征映射能力不足,使其空间信息表征较弱。相比之下,浅层网络尽管感受野有限且缺乏语义表征,但其高分辨率的特征图包含更多的空间信息,能够捕获更多的几何特征。因此,结合浅层和深层网络的优势,可以整合特征图的语义和空间信息,提高网络的检测精度。
Lin等人[24]提出了特征金字塔网络(FPN)。首先,以自底向上的方式生成多尺度特征图,将低分辨率的语义丰富特征与高分辨率的空间细节特征相结合,旨在增强特征图的信息。然后,使用自顶向下的路径和横向连接来充分利用不同尺度下各特征图的语义信息。Liu等人[25]在FPN的基础上提出了用于实例分割的路径聚合网络(PANet)。在FPN中,浅层特征在自底向上传输过程中经过多层后会遭受显著的信息丢失。为解决此问题,PANet增加了一个自底向上的路径增强结构,更好地保留了浅层特征信息。Guo等人[26]提出了增强型特征金字塔网络(AugFPN)以增强FPN并解决其不足。AugFPN引入了一致性监督,通过将相同的监督信号应用于多个监督信号,在特征融合前减少不同尺度特征之间的语义差异。此外,它使用残差特征增强来提取稳定的比率上下文语义信息,减少了最高金字塔层级特征图中的信息丢失。BiFPN[27]是一种双向特征金字塔网络,允许特征在自顶向下和自底向上两个方向上进行融合,有效整合了不同尺度的特征。同时,它为每个输入特征添加权重以优化融合过程,适应不同的输入分辨率和目标尺寸。然而,在逐层特征提取和空间变换过程中,这些基本模块可能会丢失大量信息,尤其是在检测小目标时。
2.2 目标检测中的特征提取
Mao等人[28]在YOLOv5模型的基础上提出了MSA-YOLO网络,通过引入多尺度特征提取模块(MFEM)。MFEM将挤压-激励模块与空间注意力模块结合作为骨干结构,增强了无人机航拍图像中小目标的检测精度。Hua等人[29]引入了一个自注意力模块来提取注意力特征图。通过结合卷积长短时记忆网络,他们优化了这些注意力特征图。该方法引导获取场景中目标的潜在子区域,并增强了网络的特征提取能力,提高了复杂背景下的物体识别能力。Li等人[30]设计了一个多层注意力网络,提出了旋转检测器(RADet)模型,通过建模全局像素之间的空间位置相关性并突出物体特征来提高检测精度。该模型使网络能够从复杂背景中准确检测出感兴趣的目标。Ran等人[31]提出了多尺度上下文和增强通道注意力(MCCA)模型,通过增强通道级注意力来提高卷积神经网络在复杂背景下表征物体特征的能力。Li等人[32]通过添加自适应协同注意力模块(ACAM)提出了ACAM-YOLO网络,有效减少了YOLOv5网络的参数数量,从而提高了其性能。为解决无人机航拍图像中目标数量众多且小目标比例高的检测难题,Wu等人[33]设计了坐标位置注意力模块(CPAM),提出了CPAM-YOLO网络。此外,Zhang等人[34]提出了可变形局部和全局注意力(DLGADet),将分层注意力机制(HAMs)的能力与可变形多尺度特征融合的通用性无缝结合,有效提高了识别和检测性能。
3 所提出的方法
我们提出了MFF-YOLOv8网络,这是YOLOv8s网络的一个改进版本,旨在充分利用网络内的多尺度信息,以增强无人机航拍图像中小目标的检测能力。MFF-YOLOv8网络结构如图1所示。首先,设计了一个HEMA模块,并将其与C2f模块结合,创建了HEMA_C2f模块,该模块收集多尺度特征信息,并充分利用特征图的空间和通道信息,更全面地提取小目标特征。其次,设计了HFFP模块以改进原始的颈部网络特征融合模块,确保有效利用不同尺度的目标特征。最后,引入了Inner-WIoU损失函数,以提高小目标检测的精度。
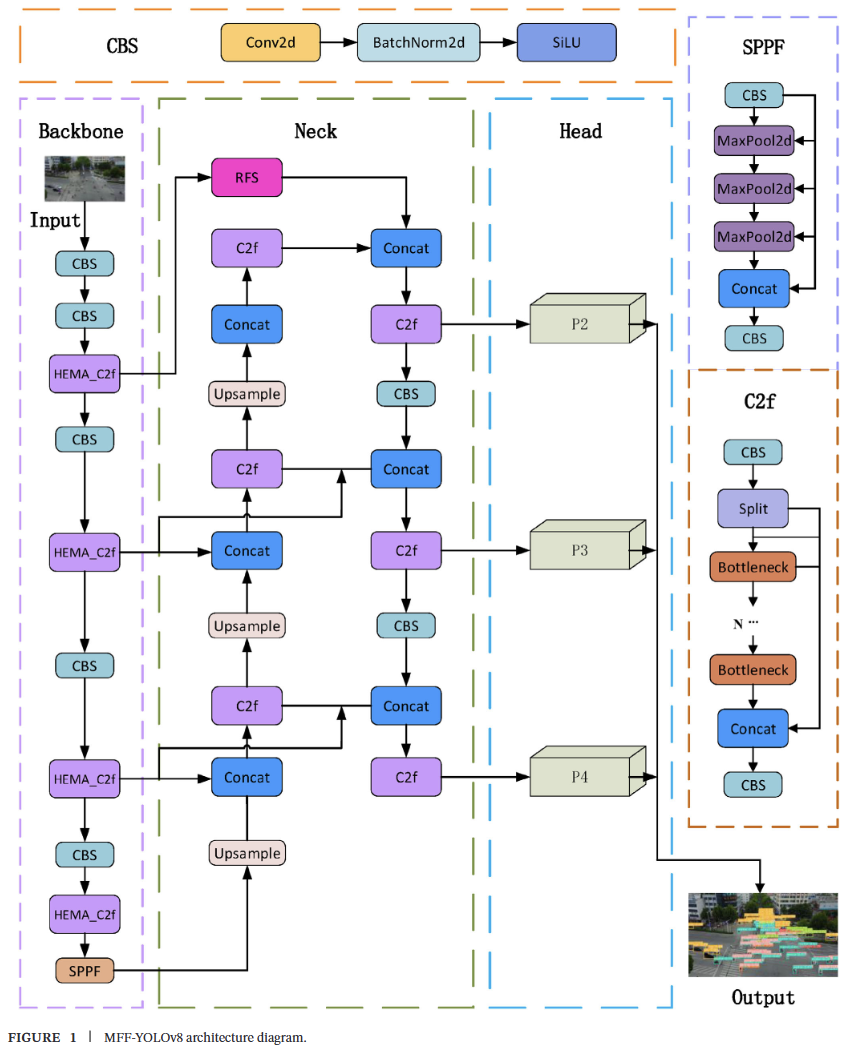
3.1 高分辨率特征融合金字塔(HFFP)
随着深度学习网络的发展,它们倾向于丢弃一些浅层特征,而这些特征通常包含小尺寸物体的关键信息。因此,小目标特征常常遭受显著的信息丢失。采用多尺度特征融合方法对于缓解这一问题至关重要。
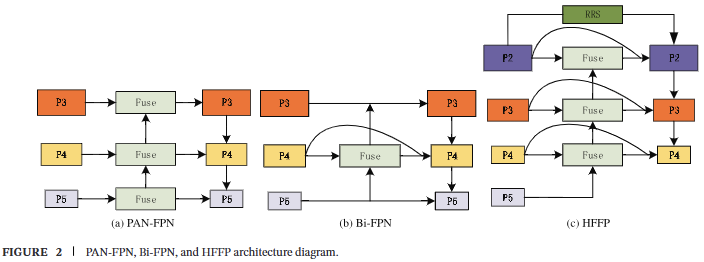
YOLOv8的颈部网络采用PAN-FPN架构,如图2所示。P3、P4和P5检测层分别产生80×80、40×40和20×20像素大小的特征图,分别针对小、中、大物体。然而,专为检测小物体设计的P3层将原始图像下采样8倍,限制了其对小于8×8像素物体的检测能力。在基于无人机的目标检测场景中,许多目标小于8×8像素,导致检测不精确、漏检和误检。
为了增强对更小物体的检测能力,引入了一个下采样因子为4的P2检测层。这一添加产生了更高分辨率的特征图,捕获了更多关于小物体的细节信息,减轻了特征融合过程中的严重信息丢失。然而,这一改进是以显著增加网络参数量和计算需求为代价的。
本文提出的改进型HFFP模块增加了尺寸为160×160像素的P2检测层,同时移除了P5检测层。P5层有512个通道,而P2层只有128个通道。通过用P2层替换P5层,网络参数量显著减少,同时更加专注于小目标检测,进一步提高了检测精度。
为解决PAN-FPN中不同特征层的贡献无法动态调整的问题,我们采用了受Bi-FPN启发的跨尺度连接和加权特征融合。改进后的网络引入了一种使用快速归一化的可学习加权机制,如公式(1)所示。这种方法允许更有效地整合来自不同层的特征,增强了网络的整体性能和适应性。
Out=∑iωiε+∑iωiIi\mathrm{Out}=\sum_{i}\frac{\omega_{i}}{\varepsilon+\sum_{i}\omega_{i}}I_{i}Out=i∑ε+∑iωiωiIi
其中,ωi\omega_{i}ωi 表示由网络训练并由激活函数确定的权重,该权重始终大于零。ε\varepsilonε 是一个用于确保结果整体稳定性的常数。IiI_{i}Ii 表示输入图像的特征,Out\mathrm{Out}Out 表示融合结果。这种加权特征融合方法能自动学习每个特征层的重要性,使模型能够为不同尺度的特征图分配不同的权重。它能动态调整每一层的贡献,增强相关小目标特征的贡献。
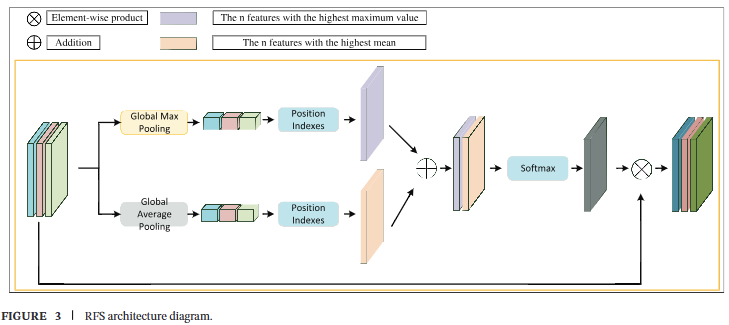
尽管跨尺度连接为网络提供了更多关于小目标的特征信息,但也带来了来自不同特征层(尤其是P2层)的大量噪声。为了减轻P2层高分辨率图像带来的噪声对小目标检测的影响,我们设计了一个重建特征选择(RFS)模块,以有效提取特征图中的有用信息并抑制噪声。RFS模块的结构如图3所示。
首先,RFS模块对输入特征图 XXX 进行全局最大池化和全局平均池化,得到 GMP(X)GMP(X)GMP(X) 和 GAP(X)GAP(X)GAP(X),从中选择前 nnn 个元素来索引 XXX 中的位置。得到的 MAX(X,n)MAX(X,n)MAX(X,n) 和 AVG(X,n)AVG(X,n)AVG(X,n) 分别代表具有最大值和平均值的最大重建特征。全局最大池化捕获全局空间信息,而全局平均池化获取局部空间信息。这两种方法有助于识别特征图中的小尺度目标和大跨度目标。结合 MAX(X,n)MAX(X,n)MAX(X,n) 和 AVG(X,n)AVG(X,n)AVG(X,n) 增强了网络捕获多尺度特征信息的能力。
接下来,将 MAX(X,n)MAX(X,n)MAX(X,n) 和 AVG(X,n)AVG(X,n)AVG(X,n) 连接起来并通过一个判别器,该判别器将重建特征映射到图像级分辨率,以获得图像的特征权重 WIGHT(X)WIGHT(X)WIGHT(X)。最后,使用这些特征权重对输入特征图 XXX 进行加权,生成加权特征图 RFS(X)RFS(X)RFS(X)。该过程增强了网络从特征图中捕获特征信息的能力,同时抑制了噪声。
通过RFS模块获得加权特征图 RFS(X)RFS(X)RFS(X) 的整体过程可以用公式(2)表示。在本文中,softmax表示使用softmax激活函数。
RFS(X)=softmax[MAX(GMP(X))+AVG(GAP(X))]X(2)RFS(X)=softmax[MAX(GMP(X))+AVG(GAP(X))]X\quad(2)RFS(X)=softmax[MAX(GMP(X))+AVG(GAP(X))]X(2)
3.2 新型混合高效多尺度注意力(HEMA)
在无人机航拍条件下,目标检测面临诸多挑战,如目标数量众多、部分目标过小、目标密集遮挡以及环境条件多样。YOLOv8网络结构中的学习残差特征模块无法解决这些问题,难以有效提取小目标特征信息。
因此,为进一步增强网络的特征提取能力并改善其特征表征,我们基于高效多尺度注意力(EMA)[35]设计了一种HEMA机制。该机制改进了YOLOv8网络的C2f结构,形成了一个新的模块HEMA_C2f,用于跨通道和空间的多尺度特征提取。HEMA_C2f在通道和空间维度上使用动态权重分布,增强了网络区分背景和目标的能力。改进后的C2f结构HEMA_C2f如图4所示。
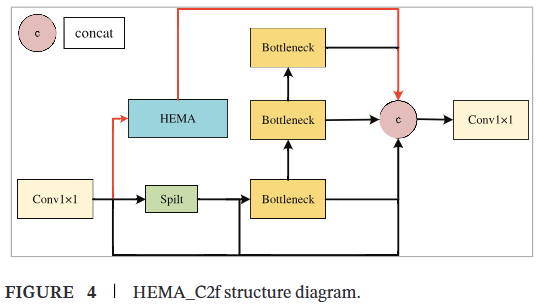
对于任意输入特征图 X∈RC×H×WX\in\mathbb{R}^{C\times H\times W}X∈RC×H×W,HEMA机制沿通道维度将输入 XXX 划分为 GGG 个子特征,以学习不同的语义。分组可表示为 xX=[X0,X1,…,XG−1]\mathfrak{x}X=[X_{0},X_{1},\dots,X_{G-1}]xX=[X0,X1,…,XG−1],其中 Xi∈RC×H×WX_{i}\in\mathbb{R}^{C\times H\times W}Xi∈RC×H×W。不失一般性,令 G≪CG\ll CG≪C,并假设所学习的注意力权重描述符将用于增强每个子特征中感兴趣区域的特征表征。
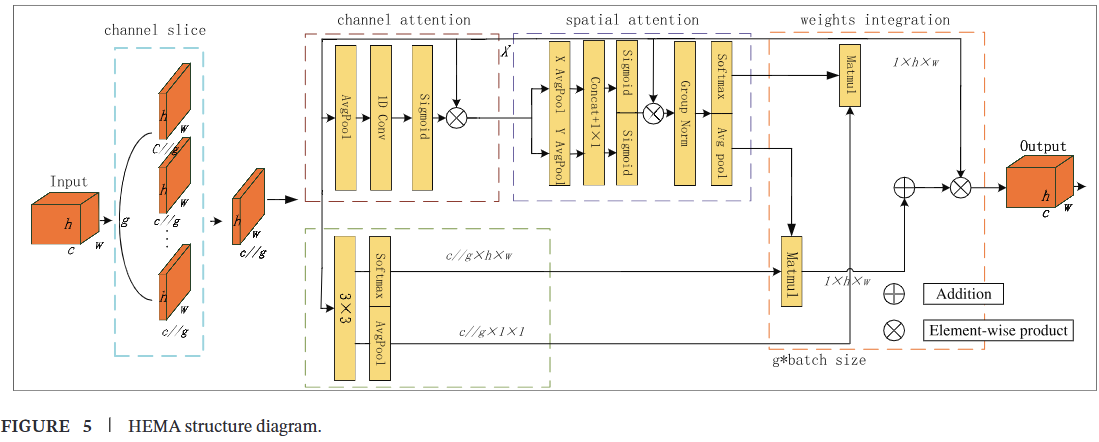
HEMA机制是一种混合多尺度注意力机制,其结构如图5所示。每个子特征随后通过一个并行子网络进行处理。在并行子网络的 1×11\times11×1 并行分支中,首先进行平均池化,然后进行一维卷积以捕获所有通道间的依赖关系,形成通道注意力。然后,在通道特征的联合激活函数之前通过乘法连接最小分支,实现跨通道信息聚合。结果记为 F1(Xi)F_{1}(X_{i})F1(Xi),其实现由公式(3)表示,其中 iii 的范围从1到 G−1G-1G−1。在此上下文中,σ\sigmaσ 表示Sigma激活函数。
F1(Xi)=σ(Conv1D(AVG(Xi)))XiF_{1}(X_{i})=\sigma(Conv_{1D}(AVG(X_{i})))X_{i}F1(Xi)=σ(Conv1D(AVG(Xi)))Xi
之后,进行两次一维全局平均池化操作,以沿两个空间方向对通道进行编码,提取空间信息,然后在 1×11\times11×1 卷积后进行全局平均池化以编码全局空间信息。在通道特征的联合激活函数之前通过乘法连接最小分支,实现跨空间信息聚合。结果记为 F2(Xi)F_{2}(X_{i})F2(Xi),其实现可表示为公式(4)。在 3×33\times33×3 并行分支中,仅执行 3×33\times33×3 卷积以捕获多尺度信息并扩展特征空间。结果记为 F3(Xi)F_{3}(X_{i})F3(Xi),其实现可表示为公式(5),其中 iii 的范围从1到 G−1G-1G−1。
F2(Xi)=[σ(Conv1×1(AVGx(F1(Xi))))]×[σ(Conv1×1(AVGy(F1(Xi))))]Xi\begin{array}{r l}{F_{2}(X_{i})=[}&{{}\sigma(Conv_{1\times1}(AVG_{x}(F_{1}(X_{i}))))]}\\ {\quad}&{{}\times\big[\sigma\big(Conv_{1\times1}\big(AVG_{y}(F_{1}(X_{i}))\big)\big)\big]X_{i}}\end{array}F2(Xi)=[σ(Conv1×1(AVGx(F1(Xi))))]×[σ(Conv1×1(AVGy(F1(Xi))))]Xi
F3(Xi)=Conv3×3(Xi)F_{3}(X_{i})=Conv_{3\times3}(X_{i})F3(Xi)=Conv3×3(Xi)
在此基础上,使用全局平均池化对 3×33\times33×3 分支输出的全局信息进行编码。然后,通过sigmoid函数和归一化操作对两个分支的输出特征进行调制。最后,通过一个跨维度交互模块将输出进行融合,以捕获像素级成对关系和所有像素的全局上下文信息。结果记为 F4(Xi)F_{4}(X_{i})F4(Xi),其实现可表示为公式(6),其中 iii 的范围从1到 G−1G-1G−1。
F4(Xi)=[softmax(F3(Xi))⋅F2(Xi)+softmax(F2(Xi))⋅F3(Xi)]Xi\begin{array}{r l}{F_{4}(X_{i})=[softmax(F_{3}(X_{i}))\cdot F_{2}(X_{i})}&{}\\ &{}\\ &{\quad+softmax(F_{2}(X_{i}))\cdot F_{3}(X_{i})]X_{i}}\end{array}F4(Xi)=[softmax(F3(Xi))⋅F2(Xi)+softmax(F2(Xi))⋅F3(Xi)]Xi
3.3 改进的回归损失函数 Inner-WIoU
在YOLOv8模型中,通常使用CIoU损失函数[36]来计算边界框损失。CIoU损失函数主要考虑重叠区域,并结合了中心点距离和宽高比惩罚等几何惩罚项,这些项对整体损失函数有显著影响。
因此,我们引入了WIoU损失函数[37],旨在当锚框和目标框高度重叠时,通过削弱几何惩罚项来增强模型的泛化能力。在此基础上,提出了一种基于距离指数的距离注意力机制,从而形成了一种具有两层注意力机制的损失函数。设预测框为 B⃗=[x,y,w,h]\vec{B}=[x,y,w,h]B=[x,y,w,h],真实框为 Bgt→=[xgt,ygt,wgt,hgt]\overrightarrow{B_{gt}}=[x_{gt},y_{gt},w_{gt},h_{gt}]Bgt=[xgt,ygt,wgt,hgt],其中 (xgt,ygt)(x_{gt},y_{gt})(xgt,ygt) 和 (x,y)(x,y)(x,y) 分别为真实框和预测框的中心坐标,wgt,hgtw_{gt},h_{gt}wgt,hgt 和 w,hw,hw,h 分别为真实框和预测框的宽高。WIoU损失函数的实现如公式(7)和(8)所示。
LWIoU=RWIoU⋅LIoU{\cal L}_{WIoU}=R_{WIoU}\cdot{\cal L}_{IoU}LWIoU=RWIoU⋅LIoU
RWIoU=exp((x−xgt)2+(y−ygt)2(Wg2+Hg2))R_{WIoU}=\exp\left(\frac{(x-x_{gt})^{2}+(y-y_{gt})^{2}}{(W_{g}^{2}+H_{g}^{2})}\right)RWIoU=exp((Wg2+Hg2)(x−xgt)2+(y−ygt)2)
其中,LWIoU{\cal L}_{WIoU}LWIoU 表示WIoU损失函数,LIoU{\cal L}_{IoU}LIoU 表示IoU损失,RWIoUR_{WIoU}RWIoU 是用于放大普通质量锚框 LIoU{\cal L}_{IoU}LIoU 的参数。其他参数定义见图6。

LIoU{\cal L}_{IoU}LIoU 的计算公式如公式(9)所示。
LIoU=1−Wi⋅Hiwh+wgt⋅hgt−Wi⋅Hi{\cal L}_{IoU}=1-\frac{W_{i}\cdot H_{i}}{wh+w_{gt}\cdot h_{gt}-W_{i}\cdot H_{i}}LIoU=1−wh+wgt⋅hgt−Wi⋅HiWi⋅Hi
WIoU损失函数通过采用两层注意力机制改进了IoU损失,从而避免了CIoU损失函数中由中心点距离和宽高比惩罚等几何惩罚项引起的泛化问题。然而,它忽略了IoU损失函数本身的固有局限性。在无人机航拍场景中,许多小目标被遮挡和聚集,形成难样本,因为它们的IoU值通常较低,预测框和真实框之间存在显著偏移或重叠不足。
因此,我们引入了Inner-IoU损失函数[38]以进一步改进WIoU损失函数,创建了Inner-WIoU损失函数。通过利用更大的辅助边界框来解决无人机航拍场景中大量小目标的常见问题,该方法能有效处理图像中的大量低IoU样本,增强网络在这些场景下的检测精度。Inner-IoU采用一个尺度因子 rrr 来生成不同尺度的辅助边界框进行损失计算,替换了原始的IoU损失。
通过使用尺度因子 rrr,将预测框的辅助边界框和真实框的辅助边界框分别调整为 [w⋅r,h⋅r][w\cdot r,h\cdot r][w⋅r,h⋅r] 和 [wgt⋅r,hgt⋅r][w_{gt}\cdot r,h_{gt}\cdot r][wgt⋅r,hgt⋅r],其中 rrr 为尺度因子。Inner-IoU值计算为预测框辅助边界框和真实框辅助边界框之间的交并比。设这些辅助边界框之间的交集和并集分别记为 sis_{i}si 和 sus_{u}su,则Inner-IoU损失函数的定义如公式(10)所示。
LInner=1−sisu{\cal L}_{Inner}=1-\frac{s_{i}}{s_{u}}LInner=1−susi
因此,本文使用的Inner-WIoU损失函数的计算公式如公式(11)所示。
LInner−WIoU=RWIoU⋅LInner{\cal L}_{Inner-WIoU}=R_{WIoU}\cdot{\cal L}_{Inner}LInner−WIoU=RWIoU⋅LInner
4 实验与分析
4.1 数据集与评估标准
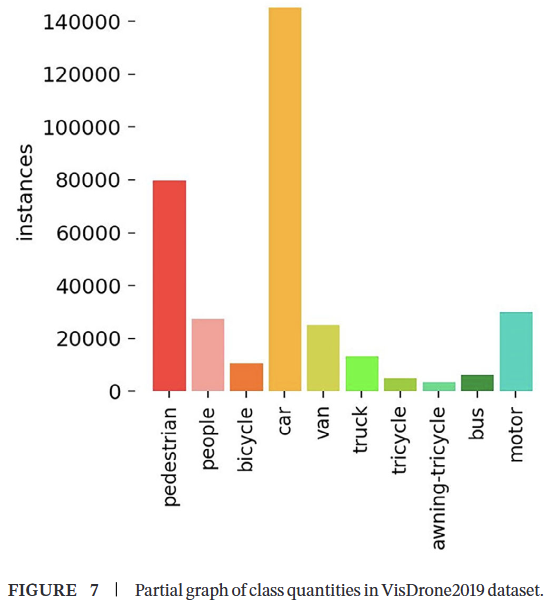
本文使用的数据集是公开的VisDrone2019数据集[39],该数据集包含8599张由无人机在高空拍摄的静态图像。其中,6471张用于训练,548张用于验证,1580张用于测试。图像类别包括行人、人、自行车、汽车、面包车、卡车、三轮车、带棚三轮车、公交车和摩托车,共有260万个标注。训练集中不同实例的分布如图7所示。值得注意的是,该数据集的检测目标从稀疏到密集,光照条件从白天到夜晚,尺度多样。特别是,数据集中60.49%的检测目标小于32×32像素,使其成为评估航拍图像中小目标检测性能的理想数据集。之后,本文将使用UAVDT和DOTA数据集作为补充实验数据集,以验证算法的泛化能力和鲁棒性。
UAVDT[40]数据集基于无人机捕获的车辆交通数据集。它由从100个视频序列中捕获的帧图像组成。这些视频序列由无人机在多个地点捕获,覆盖了城市地区的常见场景,包括广场、主干道、收费站、高速公路、交叉路口等。该数据图像集包含三个类别,即汽车、卡车和公交车,图像分辨率为1024×540。本文在该数据集上的实验将输入图像统一为640×640。
DOTA[41]数据集是用于目标检测的航空遥感数据集,包含2806张航空图像。每张图像的分辨率从800×800到4000×4000不等,数据集包含不同尺度、方向和形状的物体。有15个类别的标注示例:飞机、船舶、储油罐、棒球场、网球场、篮球场、地面跑道、港口、桥梁、大型车辆、小型车辆、直升机、环岛、足球场和游泳池。本文在该数据集上的实验将输入图像标准化为640×640。
为了更准确地评估算法性能,我们使用精度(precision)、召回率(recall)、mAP50、mAP50:95、参数量(Params)、浮点运算次数(FLOPs)和每秒帧数(FPS)作为评估指标。mAP50是在IoU阈值为0.5时所有类别的平均检测精度。Params是模型中的参数数量,FLOPs用于衡量模型的复杂度,FPS是模型每秒能处理的图像数量。mAP50:95表示在IoU阈值从0.5到0.95、步长为0.05的所有阈值下检测精度的平均值。AP由精度(P)和召回率(R)计算得出。精度和召回率使用公式(12)和(13)计算:
P=TPTP+FPP={\frac{TP}{TP+FP}}P=TP+FPTP
R=TPTP+FNR={\frac{TP}{TP+FN}}R=TP+FNTP
其中,真正例(TP)表示正确预测的正样本,假正例(FP)表示错误预测的正样本,假负例(FN)表示错误预测的负样本。平均精度(AP)衡量模型在每个类别中的性能,而平均平均精度(mAP)是所有类别AP的平均值,用于评估模型在所有类别中的整体性能。mAP使用公式(14)计算,FPS使用公式(15)计算。
mAP=1n∑i=1n∫01P(R)dR\mathrm{mAP}=\frac{1}{n}\sum_{i=1}^{n}\int_{0}^{1}P(R)\,dRmAP=n1i=1∑n∫01P(R)dR
这里,t1t_1t1 表示图像预处理时间,t2t_2t2 表示图像推理时间,t3t_3t3 表示后处理时间。
4.2 实验环境与参数配置
本研究的实验设置基于PyTorch深度学习框架,并在Ubuntu操作系统上执行。使用NVIDIA GeForce RTX 3090 GPU进行计算加速。实验环境参数如表1所示。
训练参数设置如下:训练轮数设为200,批大小(batch size)设为8,初始学习率设为0.01,使用SGD优化器。输入图像大小为640×640,其余参数为YOLOv8的默认参数。
4.3 特征融合模块的消融实验结果与分析
为了提高无人机航拍图像中小目标的检测精度,我们提出了一系列改进措施。以YOLOv8网络为基线,我们进行了一系列消融实验。实验结果如表2所示。可以看出,所提出的HFFP模块获得了最高的检测精度。与YOLOv8中的特征融合模块相比,它在仅小幅增加浮点运算量的情况下显著提升了性能。HFFP模块将参数量减少了2.89M,同时将mAP50和mAP50:95分别提高了7.3%和4.4%。
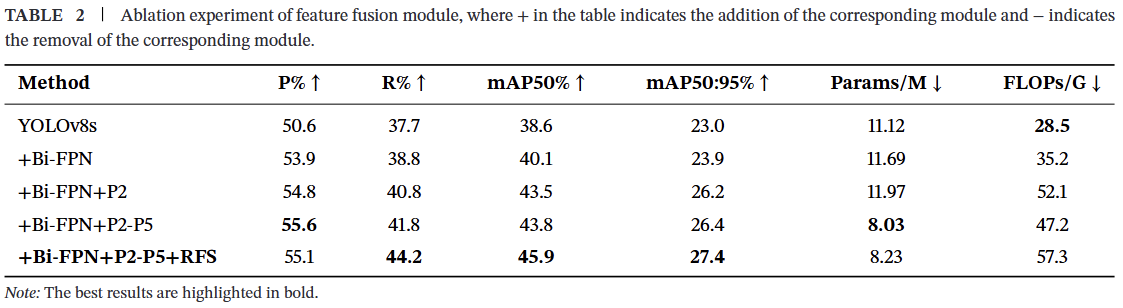
在包含P5层的场景中,HFFP通过移除P5层,进一步将参数量和浮点运算量分别减少了3.94M和4.9G,同时将mAP50和mAP50:95分别提高了0.3%和0.2%,因为P5检测层更适合在无人机航拍图像中很少出现的大目标。移除P5层不仅减轻了网络计算压力,还使网络更加专注于小目标检测,减少背景噪声,从而获得更好的检测性能。
在Bi-FPN+P2-P5的基础上,HFFP引入了去噪模块RFS,mAP50提升至45.9%,因为HFFP不仅充分利用了P2层高分辨率特征图像带来的大量小目标特征信息,还利用RFS模块消除了高分辨率特征图像带来的大量噪声,使网络能更有效地利用小目标信息。
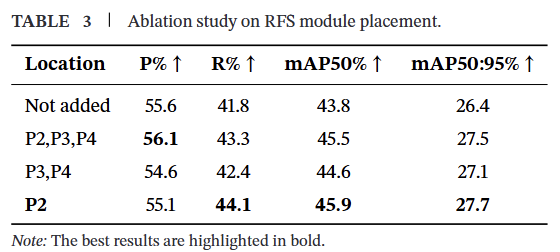
我们将RFS模块引入P2跨连接分支。为了研究在网络不同位置加入RFS模块对特征提取能力的影响,我们评估了多种场景。第一种场景是在P2跨连接分支加入RFS模块。第二种场景是在P3和P4跨连接分支加入。第三种场景是同时在P2、P3和P4分支加入。最后,我们分析了一个未包含RFS模块的对照场景。结果如表3所示。结果表明,仅在P2跨连接层加入RFS模块能获得最优结果。与初始性能相比,mAP50提升了2.1%,mAP50:95提升了1.3%,因为P2层的特征图分辨率最高,包含大量小目标信息的同时也包含显著的噪声。RFS模块生成一个掩码,创建加权特征图,能有效从图像中提取小目标信息并抑制噪声。相比之下,P3和P4层的特征和噪声信息相对有限。虽然使用RFS模块也能有效提取小目标信息并抑制噪声,但通过特征掩码创建加权特征图来抑制噪声不可避免地会导致部分特征信息的丢失。这使得当RFS模块加入P3和P4跨连接分支时,检测效果不如仅在P2跨连接分支部署时有效。因此,我们选择仅在P2跨连接分支加入RFS模块,以利于去除噪声和提取小目标信息。
表2 特征融合模块的消融实验,“+”表示添加相应模块,“-”表示移除相应模块。
| 方法 | P% ↑ | R% ↑ | mAP50% ↑ | mAP50:95% ↑ | Params/M↓ | FLOPs/G↓ |
|---|---|---|---|---|---|---|
| YOLOv8s | 50.6 | 37.7 | 38.6 | 23.0 | 11.12 | 28.5 |
| +Bi-FPN | 53.9 | 38.8 | 40.1 | 23.9 | 11.69 | 35.2 |
| +Bi-FPN+P2 | 54.8 | 40.8 | 43.5 | 26.2 | 11.97 | 52.1 |
| +Bi-FPN+P2-P5 | 55.6 | 41.8 | 43.8 | 26.4 | 8.03 | 47.2 |
| +Bi-FPN+P2-P5+RFS | 55.1 | 44.2 | 45.9 | 27.4 | 8.23 | 57.3 |
表3 RFS模块放置位置的消融研究
| 位置 | P%↑ | R% ↑ | mAP50% ↑ | mAP50:95% ↑ |
|---|---|---|---|---|
| 未添加 | 55.6 | 41.8 | 43.8 | 26.4 |
| P2,P3,P4 | 56.1 | 43.3 | 45.5 | 27.5 |
| P3,P4 | 54.6 | 42.4 | 44.6 | 27.1 |
| P2 | 55.1 | 44.1 | 45.9 | 27.7 |
4.4 注意力机制的对比实验与结果分析
为体现本研究设计的注意力机制的优越性,我们基于YOLOv8s模型,选择将HEMA机制与常用注意力机制在4个指标上进行比较:mAP50、mAP50:95、模型参数量(Params)和总FLOPs。比较结果如表4所示。结果表明,在模型参数量和FLOPs基本不变的情况下,HEMA机制在无人机航拍场景下相比常用注意力机制表现出更高的精度和准确性。
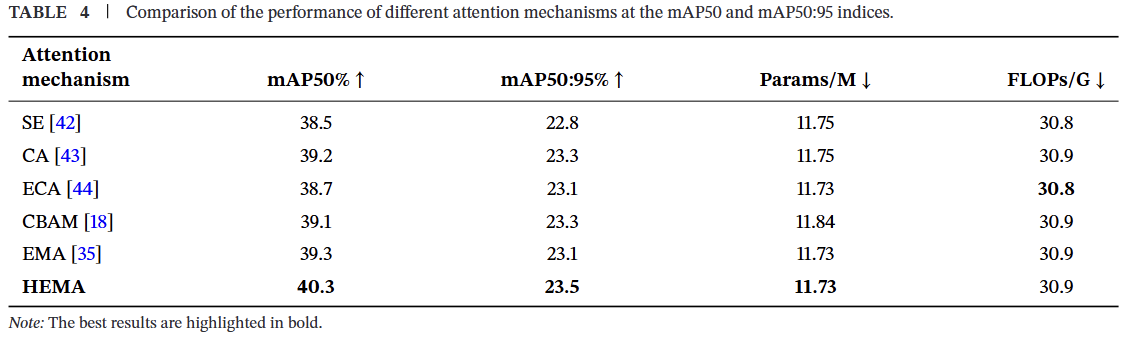
经典的模块如SE、CA和ECA仅使用空间注意力机制或通道注意力机制之一。而HEMA模块通过结合空间注意力和通道注意力的优势,使网络能够同时捕获全局语义信息和局部细节信息。因此,HEMA模块能更好地捕获小目标的局部空间信息和全局特征信息,提高航拍小目标的检测精度。与CBAM模块相比,HEMA模块通过将多尺度模块与注意力结合,使网络模型能更灵活地选择相应目标的感受野,即使目标尺寸存在轻微不平衡,也具有更高的检测精度。
特别是,与EMA机制相比,在相同背景下,HEMA机制将mAP50和mAP50:95分别提高了1%和0.4%,因为它在EMA基础上引入了一维卷积进行跨通道交互。一维卷积参数更少、核尺寸更小,并且在单一维度上操作,因此增加了很少的额外参数。此外,这种通道注意力操作增强了模型对关键特征的关注,在通道维度上优化了输入特征图,从而提高了对小目标特征的注意力,实现了检测精度的提升。

为了更直观地展示添加HEMA机制的效果,我们可视化了使用该模块前后的热力图,如图8所示。可以看出,在未使用HEMA注意力机制的热力图中,大量热量集中在非检测物体上,而检测物体上的热量主要集中在较大物体上。相比之下,使用HEMA机制的热力图明显更加精细,热量主要集中在待检测物体上。检测物体上的热量分布更加均匀,干扰更少,有效突出了小目标。

HEMA模块被集成到C2f模块中,形成了HEMA_C2f模块。为了确定在不同网络位置用HEMA_C2f模块替换C2f模块的影响,我们在不同场景下进行了一系列比较:将HEMA_C2f模块集成到骨干网络、颈部网络、骨干和颈部网络,以及不添加HEMA_C2f模块。结果如表5所示。显然,将HEMA_C2f模块集成到骨干网络比添加到颈部网络效果更好。这是因为骨干网络负责从原始图像中提取低级和中级特征,这些特征包含丰富的空间和语义信息。将HEMA_C2f模块集成到骨干网络中,展示了其在不同尺度上捕获和整合特征的增强能力。这使得网络能在早期阶段优先强调关键特征,从而对提取的特征进行更精确和全面的表征。
虽然多尺度注意力也能增强颈部网络的特征融合,但其增强效果有限,因为该网络处理的特征已经由骨干网络提取和处理过。此外,仅将HEMA_C2f模块添加到骨干网络而非同时添加到骨干和颈部网络,就能实现相似的检测精度,同时减少了浮点运算量和参数量。这是因为骨干网络已经有效地捕获并整合了不同尺度的特征。然而,在颈部网络进行相同操作会导致冗余,检测精度的提升也不明显。因此,我们选择将HEMA_C2f模块添加到骨干网络,以增强网络提取小目标特征的能力。

4.5 损失函数模块的实验效果对比与分析
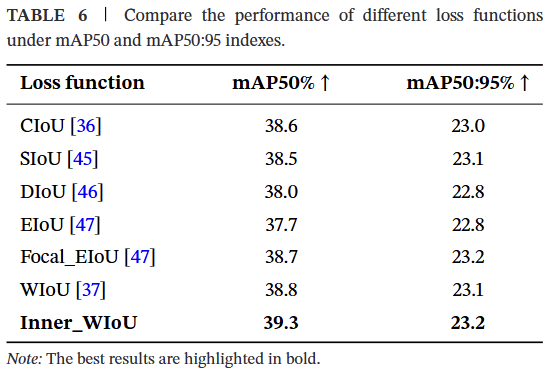
本研究基于YOLOv8s模型,将Inner-WIoU损失函数与其他常用损失函数在mAP50和mAP50:95指标上进行了比较。比较结果如表6所示。Inner-WIoU损失函数表现出更优的精度和准确性。特别是,与WIoU损失函数相比,mAP50提高了0.5%。这可以归因于无人机航拍图像中存在大量小目标,导致出现大量低IoU样本。Inner-WIoU损失函数引入了更大的辅助框来替代原始检测框,可以加速低IoU样本的回归过程,并增强其处理此类样本的能力。
4.6 消融实验结果与分析
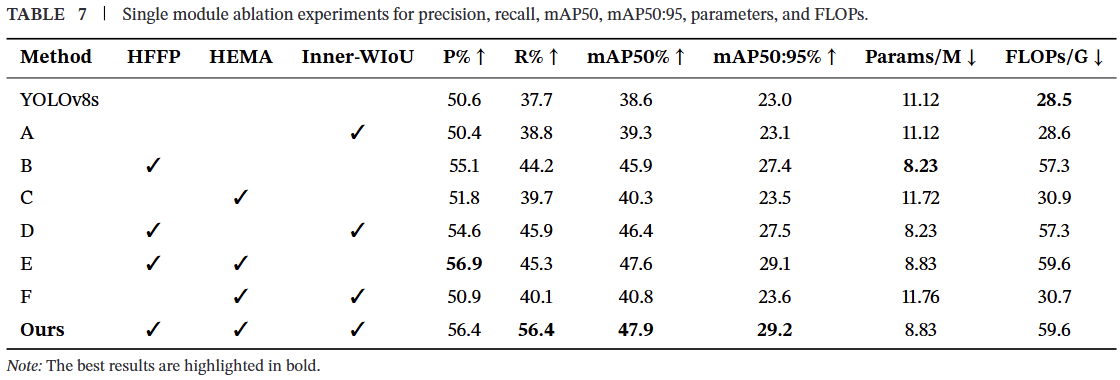
为了提高无人机航拍图像中小目标的检测精度,我们提出了一系列改进措施。本节重点对各个改进模块进行消融实验,以研究它们之间的内在关系。其中,添加HFFP可以获得最大的mAP提升。这是因为引入HFFP模块使网络能够从高分辨率小目标特征图像中获取更多的小目标特征信息。然而,引入高分辨率小目标特征图像也导致通过添加HFFP模块使网络的FLOPs大幅增加。另一方面,引入HEMA模块有助于网络更充分地利用小目标特征信息。该模块通过混合多尺度注意力机制增强了小目标特征信息的权重,从而在增加较少FLOPs和参数量的情况下实现了mAP的一定增长。最后,由于引入Inner-WIoU模块仅修改了损失函数,浮点运算量和参数量基本保持不变。由于Inner-WIoU模块提高了网络对航拍小目标的敏感性,mAP获得了较少的增长。实验结果如表7所示。可以观察到,无论是单独引入HFFP、HEMA和Inner-WIoU模块,还是两两组合,都在减少参数量和限制FLOPs计算量的同时,使精度、召回率、mAP50和mAP50:95等评估指标均有所提升。当三个模块同时使用时,mAP50和mAP50:95值达到最高,分别提升了9.3%和6.2%。这表明,高分辨率特征图和注意力机制的引入使网络更加关注小目标,提取并保留了更多小目标的特征信息,有效减少了关键特征信息的丢失,并成功增强了网络检测小目标的能力。
4.7 实验结果可视化与分析
为了更直观地展示所提出的MFF-YOLOv8算法相较于基线网络YOLOv8s的增强检测性能,我们利用它们在各种无人机航拍场景中进行检测。检测结果如图9所示,每组图像的左侧显示YOLOv8s的性能,右侧显示MFF-YOLOv8的性能。
图9a,b显示,与YOLOv8s相比,MFF-YOLOv8在小目标密集分布的航拍图像中检测到了更多的小目标。此外,在检测过程中,MFF-YOLOv8有效避免了将人误检为自行车的问题,这是YOLOv8s的常见问题,表明MFF-YOLOv8在小目标密集分布的场景中更为有效。如图9c,d所示,由于同一场景中卡车和汽车因拍摄角度不同而导致尺度差异,YOLOv8s无法检测到左下角的卡车。同样,右侧的摩托车因尺度太小也未能被检测到。相比之下,MFF-YOLOv8准确识别了两者,表明它能更好地处理无人机航拍场景中尺度变化较大的情况。图9e,f表明,在复杂光照条件下检测航拍图像时,YOLOv8s无法识别图像左右两侧低光照环境中的行人,但MFF-YOLOv8表现更好,有效识别了相同条件下的行人。这表明MFF-YOLOv8更适合在多样光照条件下检测无人机航拍场景中的小目标。
总之,从图9所示的不同场景的检测结果可以看出,增强后的MFF-YOLOv8算法在航拍图像中的目标检测更为精确,与基线网络YOLOv8s相比具有优越的检测性能。
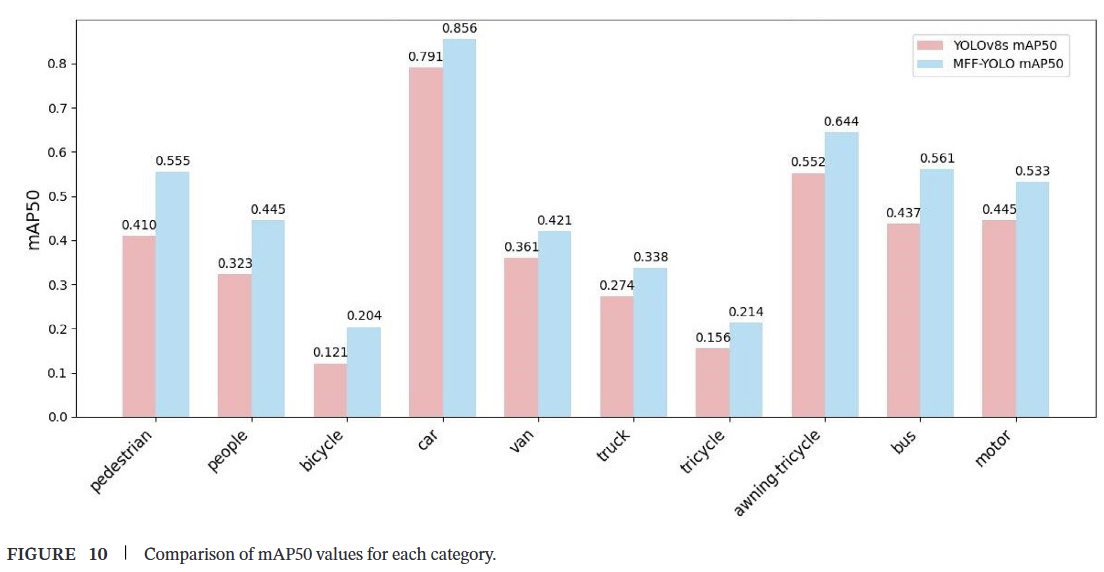
4.8 不同类别的目标检测结果分析
为研究所提出算法在VisDrone2019数据集10个不同类别上的性能差异,使用YOLOv8s和MFF-YOLOv8进行了对比实验。使用mAP50指标进行比较,结果数据如图10所示。显然,与YOLOv8s相比,MFF-YOLOv8在每个类别的识别结果上均有显著提升。在行人和人这两个经常包含小目标的类别中,提升最为显著,mAP50值分别比YOLOv8s提高了14.5%和12.2%。这表明MFF-YOLOv8在提升小目标检测性能方面更为有效。
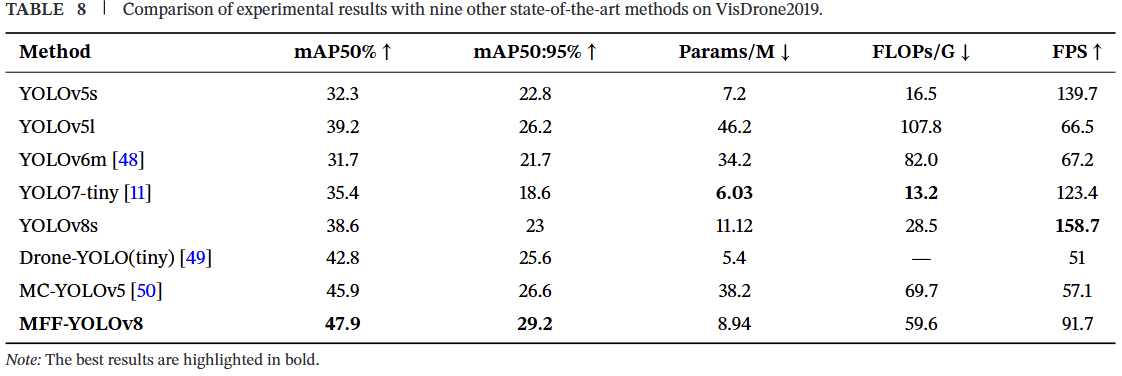
4.9 不同算法小目标检测效果的对比与分析
本节为进一步证明MFF-YOLOv8在无人机航拍图像小目标检测中的有效性,以证明其优越性。为此,将其与几种主流检测网络进行了比较。实验结果如表8所示。显然,MFF-YOLOv8相比YOLO系列中的几种算法表现出优越的性能。与YOLOv5s、YOLOv7-tiny和YOLOv8s相比,MFF-YOLOv8的mAP50分别提高了15.6%、12.5%和9.3%,而FPS仅略有下降。与YOLO系列中较大的模型YOLOv5l和YOLOv6m相比,MFF-YOLOv8在参数量和浮点运算次数显著减少的同时,mAP50分别提高了8.7%和16.2%,mAP50:95分别提高了6.4%和7.5%。与近期发布的模型Drone-YOLO (tiny)和MC-YOLOv5相比,MFF-YOLOv8的mAP50分别提高了5.1%和2.0%,且FPS高出30帧。这充分证明了MFF-YOLOv8算法在无人机航拍场景的小目标检测中表现出优越的性能。
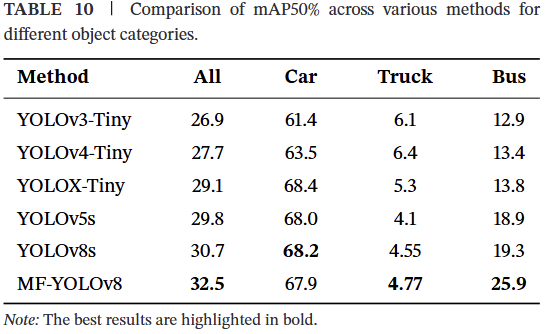
4.10 算法泛化能力的实验结果
为进一步例证本文提出的改进算法MFF-YOLOv8在航拍小目标检测中的泛化能力和鲁棒性,本节还在DOTA数据集的全部十四个类别上与基线网络YOLOv8s进行了比较。在DOTA数据集上使用mAP50指标的比较实验如表9所示。可以看出,MFF-YOLOv8在14个类别中的13个上都取得了检测精度的提升,显示出其在广泛目标类型上的优越性能。在整体检测性能方面,MFF-YOLOv8比基线网络YOLOv8s的检测精度提高了3.7个百分点。这一显著的性能提升充分证明了本文提出的改进算法在处理航拍场景中多目标、高密度分布和复杂背景挑战时表现出强大的适应性和鲁棒性。
此外,本节还在UAVDT数据集上与其他算法进行了进一步比较。从而进一步验证了本文在处理航拍场景中多目标、高密度分布和复杂背景时具有更好的鲁棒性和精度优势。UAVDT数据集上的比较实验如表10所示。可以看出,MFF-YOLOv8算法在UAVDT数据集上比其他YOLO系列算法能够实现更优秀的检测精度。与基线网络YOLOv8s相比,MFF-YOLOv8在UAVDT数据集上的检测精度提高了1.8个百分点,这进一步验证了MFF-YOLOv8算法设计的合理性和鲁棒性。
表9 DOTA数据集上不同类别的mAP50%比较
| 类别 | YOLOv8s | MFF-YOLOv8 |
|---|---|---|
| 游泳池 | 0.336 | 0.536 |
| 足球场 | 0.439 | 0.597 |
| 环岛 | 0.325 | 0.712 |
| 直升机 | 0.322 | 0.734 |
| 小型车辆 | 0.119 | 0.433 |
| 大型车辆 | 0.168 | 0.470 |
| 桥梁 | 0.232 | - |
| 港口 | 0.235 | - |
| 地面跑道 | 0.553 | - |
| 篮球场 | 0.778 | - |
| 网球场 | 0.786 | - |
| 棒球场 | 0.0539 | - |
| 储油罐 | 0.162 | - |
| 船舶 | 0.604 | - |
| 飞机 | 0.624 | - |
| 全部 | 0.343 | 0.380 |
5 结论与未来工作
针对当前网络在无人机航拍场景中对大量小目标存在的漏检和误检问题,我们提出了MFF-YOLOv8网络。
首先,设计了一个具有高分辨率特征映射的HFFP模块。该方法整合了高分辨率图中的细粒度特征信息,采用加权融合策略,并使用RFS模块去除噪声,有效增强了小目标特征提取。其次,设计并引入了HEMA模块,并将其与C2f模块集成,创建了HEMA_C2f模块。这种组合优化了与小目标相关的特征和信息的提取与保留,增强了模型有效提取小目标特征的能力。最后,设计并采用了Inner-WIoU损失函数来优化原始网络损失函数,解决了CIoU损失函数中回归结果不准确的问题,进一步提高了小目标的定位精度。在VisDrone2019数据集上的实验结果表明,所提出的MFF-YOLOv8算法在航拍场景中小目标检测方面取得了显著改进,优于近年来提出的几种优秀算法。
在未来的工作中,我们将研究在保持小目标检测精度的同时减少浮点运算次数的方法,并在保持模型精度的同时加速推理过程,以进一步适应计算资源通常有限的无人机航拍场景。