2025年第六届MathorCup大数据竞赛赛题浅析-助攻快速选题
MathorCup妈杯大数据竞赛,题目简单【国赛难度的0.5】,比赛时长一周,获奖率高(50%),可以看做2025年下半年最容易获奖的中文数模竞赛,本文将为大家带来赛题浅析,以帮助大家尽快选题。同时会尽可能标记每个题目在后续求解中可能存在的难点以便大家提前规避。
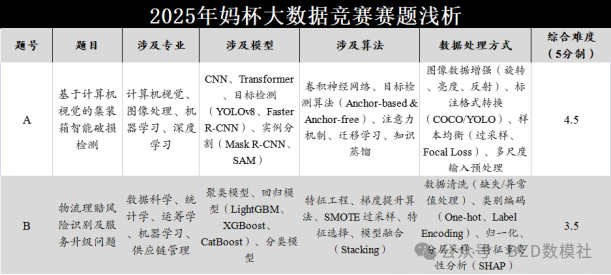
赛题难度A:B=9:7
选题人数A:B=2:8
选题须知:数学建模每个赛题获奖率都是一样的,因此更简单的、选题多的更容易获奖,这种题目小白会多也就意味着相对来讲竞争会小一些;选题少、难度大的题目通常是有一定知识背景、专业合适,即竞争更加激烈。
解题须知:对于一道数学建模题目,3000只队伍进行基于同样的背景、同样的问题进行解题。模型重复、论文相似在所难免。相对于数模社提供的人为模型思路,AI思路更会具有同质化。数模社提供作品最多也就是几百支队伍可以看到,现在95%的队伍都使用AI,也就意味着有3000支队伍都在参考AI给出的模型。两者参考数量相对而言,本数模社老师亲自建立模型+AI辅助实现的思路相对来讲更为小众、更容易获奖。
注释:AI目前给出的思路是可行的,但是当下AI的最大问题在于同质化。
Ø2024年国赛,对于双目标优化模型求解算法,在无AI时代智能算法、NSGA-II(非显性排序遗传算法II)、MOPSO(多目标粒子群优化)等看起来高大上的模型。但是在实际评阅中60%以上的队伍都无脑使用了AI推荐的算法,就导致原本小众、较好的算法在竞赛中其实并不出众。国奖中大部分使用算法也并非AI推荐。(2024年九月还没到中文AI迸发的时代)。
Ø2025年国赛,各种中文AI层出不穷,赛中也给出了各种五花八门的求解方案。基本第一点就与评审要点不同(AI普遍建议使用聚类模型进行分组分类,评阅要点求其强调不推荐聚类模型直接分组)。
因此,当下AI时代下人为建立模型进行求解才更显得更小众、更容易获奖。
赛道 A:集装箱智能破损检测
任务分为三层:
1.二分类任务:判断图像是否存在破损;
2.检测+分割任务:如果存在破损,定位位置、识别破损类别;
3.模型评估:设计合理的多维度指标(准确率、mAP、Dice、推理速度等)。
难点包括:
·背景复杂、光照不均、反光、污渍等干扰;
·残损形态多尺度;
·类别分布极不均衡。
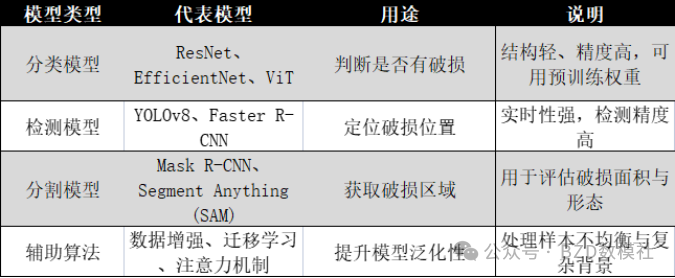
采用“分层建模+多任务学习”策略:
(1)任务 1:破损存在性分类
·目标:输出是否破损(0/1)。
·模型候选:
oCNN 基础模型:ResNet50 / EfficientNet / ConvNeXt。
oTransformer 模型:Swin-Transformer、ViT。
o轻量化模型(适合部署):MobileNetV3 / EfficientNet-B0。
·增强与正则:
o数据增强:随机旋转、亮度调整、CutMix、MixUp。
o类别不平衡:Focal Loss / 加权交叉熵。
·指标:准确率、AUC、召回率。
(2)任务 2:破损检测与分割
·目标检测模型:
oYOLOv8/YOLOv11(推荐):支持实例分割,易部署;
oMask R-CNN(mmdetection 框架);
oSegment Anything (SAM) + 分类头(用于微裂纹)。
·训练策略:
o多尺度输入;
o混合损失:CIoU + 分类 + mask loss;
o小目标增强:Mosaic + Copy-Paste。
·类别样本不均衡处理:
o类别重采样;
o基于 focal loss 的类别平衡;
o迁移学习:使用预训练模型(COCO/工业检测数据)。
(3)任务 3:模型评估
·检测指标:mAP@0.5、mAP@0.5:0.95;
·分割指标:Dice、IoU;
·分类指标:Accuracy、Precision、Recall、F1;
·性能指标:推理时间、FPS;
·鲁棒性分析:光照变化、噪声干扰、旋转鲁棒性。
赛道 B:物流理赔风险识别与服务升级
目标:通过历史理赔数据,进行:
1.风险标注(标签生成);
2.赔付金额预测;
3.风险分类预测(多分类问题)。
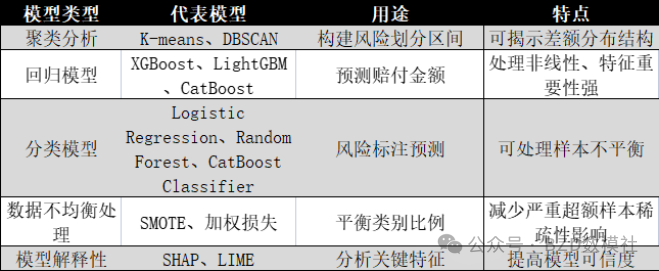
二、问题 1:风险标注模型构建
·指标:索赔差额 = 实际赔付金额 - 索赔金额;
·样本不平衡(严重超额 <3%,合理诉求 >85%)。
思路:
·EDA:
o分析索赔差额分布;
o按赔付金额分组绘制箱线图;
o观察“密集 vs 稀疏”分布;
·标注规则设计:
o设阈值函数
,例如:
其中
为分位数或基于聚类(K-means on 差额)。
·输出:风险标注类别。
三、问题 2:实际赔付金额预测
·预测目标:连续变量。
·候选模型:
o基线:线性回归、随机森林、XGBoost;
o高级:LightGBM、CatBoost(支持类别变量);
o深度模型:TabTransformer。
·特征处理:
oOne-hot 编码:异常原因、进线渠道、商品类型;
o数值标准化;
o网点特征归一化;
o缺失值填充:均值/众数。
·评估指标:
oRMSE、MAE;
oR²;
o相对误差 <10% 占比。
四、问题 3:风险分类预测
·输入:附件 1 特征;
·标签:风险标注类别;
·建模路线:
o机器学习模型:LightGBM / XGBoost;
o不平衡处理:
§SMOTE / Borderline-SMOTE;
§类别加权;
§分层采样。
·指标:
o宏平均 F1;
o准确率;
o混淆矩阵;
oROC-AUC(多类)。