快速学完 LeetCode top 1~50 [特殊字符]
文章目录
- [LeetCode top 1~50](https://leetcode.cn/studyplan/top-100-liked/)
- 「哈希」
- [1. 两数之和](https://leetcode.cn/problems/two-sum/)
- 题目描述
- 核心思路
- 题解代码
- 时空分析
- [49. 字母异位词分组](https://leetcode.cn/problems/group-anagrams/)
- 题目描述
- 核心思路
- 题解代码
- 时空分析
- [128. 最长连续序列](https://leetcode.cn/problems/longest-consecutive-sequence/)
- 题目描述
- 核心思路
- 题解代码
- 时空分析
- 「双指针」
- [283. 移动零](https://leetcode.cn/problems/move-zeroes/)
- 题目描述
- 核心思路
- 题解代码
- 时空分析
- [11. 盛最多水的容器](https://leetcode.cn/problems/container-with-most-water/)
- 题目描述
- 核心思路
- 题解代码
- 时空分析
- [15. 三数之和](https://leetcode.cn/problems/3sum/)
- 题目描述
- 核心思路
- 题解代码
- 时空分析
- [42. 接雨水](https://leetcode.cn/problems/trapping-rain-water/)
- 题目描述
- 核心思路
- 题解代码
- 时空分析
- 「滑动窗口」
- [3. 无重复字符的最长子串](https://leetcode.cn/problems/longest-substring-without-repeating-characters/)
- 题目描述
- 核心思路
- 题解代码
- 时空分析
- [438. 找到字符串中所有字母异位词](https://leetcode.cn/problems/find-all-anagrams-in-a-string/)
- 题目描述
- 核心思路
- 题解代码
- 「子串」
- [560. 和为 K 的子数组](https://leetcode.cn/problems/subarray-sum-equals-k/)
- 题目描述
- 核心思路
- 题解代码
- [239. 滑动窗口最大值](https://leetcode.cn/problems/sliding-window-maximum/)
- 题目描述
- 核心思路
- 题解代码
- [76. 最小覆盖子串](https://leetcode.cn/problems/minimum-window-substring/)
- 题目描述
- 核心思路
- 题解代码
- 「普通数组」
- [53. 最大子数组和](https://leetcode.cn/problems/maximum-subarray/)
- 题目描述
- 核心思路
- 题解代码
- [56. 合并区间](https://leetcode.cn/problems/merge-intervals/)
- 题目描述
- 核心思路
- 题解代码
- [189. 轮转数组](https://leetcode.cn/problems/rotate-array/)
- 题目描述
- 核心思路
- 题解代码
- [238. 除自身以外数组的乘积](https://leetcode.cn/problems/product-of-array-except-self/)
- 题目描述
- 核心思路
- 题解代码
- [41. 缺失的第一个正数](https://leetcode.cn/problems/first-missing-positive/)
- 题目描述
- 核心思路
- 题解代码
- 「矩阵」
- [73. 矩阵置零](https://leetcode.cn/problems/set-matrix-zeroes/)
- 题目描述
- 核心思路
- 题解代码
- [54. 螺旋矩阵](https://leetcode.cn/problems/spiral-matrix/)
- 题目描述
- 核心思路
- 题解代码
- [48. 旋转图像](https://leetcode.cn/problems/rotate-image/)
- 题目描述
- 核心思路
- 题解代码
- [240. 搜索二维矩阵 II](https://leetcode.cn/problems/search-a-2d-matrix-ii/)
- 题目描述
- 核心思路
- 题解代码
- 「链表」
- [160. 相交链表](https://leetcode.cn/problems/intersection-of-two-linked-lists/)
- 题目描述
- 核心思路
- 题解代码
- [206. 反转链表](https://leetcode.cn/problems/reverse-linked-list/)
- 题目描述
- 核心思路
- 题解代码
- [234. 回文链表](https://leetcode.cn/problems/palindrome-linked-list/)
- 题目描述
- 核心思路
- 题解代码
- [141. 环形链表](https://leetcode.cn/problems/linked-list-cycle/)
- 题目描述
- 核心思路
- 题解代码
- [142. 环形链表 II](https://leetcode.cn/problems/linked-list-cycle-ii/)
- 题目描述
- 核心思路
- 题解代码
- [21. 合并两个有序链表](https://leetcode.cn/problems/merge-two-sorted-lists/)
- 题目描述
- 核心思路
- 题解代码
- [2. 两数相加](https://leetcode.cn/problems/add-two-numbers/)
- 题目描述
- 核心思路
- 题解代码
- [19. 删除链表的倒数第 N 个结点](https://leetcode.cn/problems/remove-nth-node-from-end-of-list/)
- 题目描述
- 核心思路
- 题解代码
- [24. 两两交换链表中的节点](https://leetcode.cn/problems/swap-nodes-in-pairs/)
- 题目描述
- 核心思路
- 题解代码
- [25. K 个一组翻转链表](https://leetcode.cn/problems/reverse-nodes-in-k-group/)
- 题目描述
- 核心思路
- 题解代码
- [138. 随机链表的复制](https://leetcode.cn/problems/copy-list-with-random-pointer/)
- 题目描述
- 核心思路
- 题解代码
- [148. 排序链表](https://leetcode.cn/problems/sort-list/)
- 题目描述
- 核心思路
- 题解代码
- [23. 合并 K 个升序链表](https://leetcode.cn/problems/merge-k-sorted-lists/)
- 题目描述
- 核心思路
- 题解代码
- [146. LRU 缓存](https://leetcode.cn/problems/lru-cache/)
- 题目描述
- 核心思路
- 题解代码
- 「二叉树」
- [94. 二叉树的中序遍历](https://leetcode.cn/problems/binary-tree-inorder-traversal/)
- 题目描述
- 核心思路
- 题解代码
- 时空分析
- [104. 二叉树的最大深度](https://leetcode.cn/problems/maximum-depth-of-binary-tree/)
- 题目描述
- 核心思路
- 题解代码
- 时空分析
- [226. 翻转二叉树](https://leetcode.cn/problems/invert-binary-tree/)
- 题目描述
- 核心思路
- 题解代码
- [101. 对称二叉树](https://leetcode.cn/problems/symmetric-tree/)
- 题目描述
- 核心思路
- 题解代码
- [543. 二叉树的直径](https://leetcode.cn/problems/diameter-of-binary-tree/)
- 题目描述
- 核心思路
- 题解代码
- [102. 二叉树的层序遍历](https://leetcode.cn/problems/binary-tree-level-order-traversal/)
- 题目描述
- 核心思路
- 题解代码
- [108. 将有序数组转换为二叉搜索树](https://leetcode.cn/problems/convert-sorted-array-to-binary-search-tree/)
- 题目描述
- 核心思路
- 题解代码
- [98. 验证二叉搜索树](https://leetcode.cn/problems/validate-binary-search-tree/)
- 题目描述
- 核心思路
- 题解代码
- [230. 二叉搜索树中第 K 小的元素](https://leetcode.cn/problems/kth-smallest-element-in-a-bst/)
- 题目描述
- 核心思路
- 题解代码
- [199. 二叉树的右视图](https://leetcode.cn/problems/binary-tree-right-side-view/)
- 题目描述
- 核心思路
- 题解代码
- [114. 二叉树展开为链表](https://leetcode.cn/problems/flatten-binary-tree-to-linked-list/)
- 题目描述
- 核心思路
- 题解代码
- [105. 从前序与中序遍历序列构造二叉树](https://leetcode.cn/problems/construct-binary-tree-from-preorder-and-inorder-traversal/)
- 题目描述
- 核心思路
- 题解代码
- [437. 路径总和 III](https://leetcode.cn/problems/path-sum-iii/)
- 题目描述
- 核心思路
- 题解代码
- [236. 二叉树的最近公共祖先](https://leetcode.cn/problems/lowest-common-ancestor-of-a-binary-tree/)
- 题目描述
- 核心思路
- 题解代码
- [124. 二叉树中的最大路径和](https://leetcode.cn/problems/binary-tree-maximum-path-sum/)
- 题目描述
- 核心思路
- 题解代码
LeetCode top 1~50

「哈希」
1. 两数之和
题目描述
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。
你可以按任意顺序返回答案。
核心思路
使用 HashMap 存储 val 到 Index 的映射。
题解代码
class Solution {public int[] twoSum(int[] nums, int target) {// 1.由于返回的是索引,所以需要用一个 Map 存储 val 到 Index 的映射HashMap<Integer, Integer> valToIndex = new HashMap<>();// 2.遍历迭代for(int i = 0; i < nums.length; i++){int need = target - nums[i];if(valToIndex.containsKey(need)){return new int[]{valToIndex.get(need), i};}valToIndex.put(nums[i], i);}return null;}
}
时空分析
- 时间复杂度:(O(n))
- 空间复杂度:(O(n))
- 原因分析:
- 时间复杂度:代码包含一个
for循环,该循环遍历数组nums一次。在每次循环中,执行的操作如计算差值、在HashMap中查找和插入元素,平均情况下,这些操作的时间复杂度均为 (O(1))。所以总的时间复杂度为 (O(n)\times O(1)= O(n)) 。- 空间复杂度:代码中使用了一个
HashMap来存储数组中的元素及其索引。在最坏情况下,数组中的所有元素都需要存储到HashMap中,因此空间复杂度与数组的长度 n 成正比,即 (O(n)) 。
49. 字母异位词分组
题目描述
给你一个字符串数组,请你将字母异位词组合在一起。可以按任意顺序返回结果列表。
核心思路
数据编码和 HashMap -> 找到一种编码方法,使得字母异位词的编码都相同。找到这种编码方式之后,就可以用一个哈希表存储编码相同的所有异位词,得到最终的答案。
编码方法:利用每个字符出现的次数进行编码。 “10001…000”
题解代码
class Solution {public List<List<String>> groupAnagrams(String[] strs) {// 编码到分组的映射HashMap<String, List<String>> codeToGroup = new HashMap<>();for (String s : strs) {// 对字符串进行编码String code = encode(s);// 把编码相同的字符串放在一起codeToGroup.putIfAbsent(code, new LinkedList<>());codeToGroup.get(code).add(s);}// 获取结果List<List<String>> res = new LinkedList<>();for (List<String> group : codeToGroup.values()) {res.add(group);}return res;}// 利用每个字符的出现次数进行编码String encode(String s) {char[] count = new char[26];for (char c : s.toCharArray()) {int delta = c - 'a';count[delta]++;}return new String(count);}
}
时空分析
- 时间复杂度:(O(n \cdot k))
- 空间复杂度:(O(n \cdot k))
- 原因分析:
- 时间复杂度:
- 外层有一个
for循环遍历strs数组,循环次数为 n,n 是strs数组的长度。- 对于
strs中的每一个字符串,都会调用encode方法。在encode方法中,又有一个for循环遍历字符串 s,假设字符串平均长度为 k,这个循环时间复杂度为 (O(k))。- 此外,在
groupAnagrams方法的for循环中,每次循环还有平均时间复杂度为 (O(1)) 的putIfAbsent和add操作。所以整体时间复杂度为 (O(n)\times O(k + 1)= O(n \cdot k)) 。- 空间复杂度:
- 代码中使用了一个
HashMap来存储编码后的字符串及其对应的字符串列表。在最坏情况下,所有不同的编码字符串都不同,且每个编码字符串对应一个长度为 k 的字符串列表。每个编码字符串长度为 26(常数),假设平均每个编码字符串对应一个长度为 k 的字符串列表,所以HashMap占用空间为 (O(n \cdot k))。- 此外,
res列表存储所有分组后的结果,在最坏情况下,它也占用 (O(n \cdot k)) 的空间。因此,总的空间复杂度为 (O(n \cdot k)) 。
128. 最长连续序列
题目描述
给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
请你设计并实现时间复杂度为 O(n) 的算法解决此问题。
核心思路
HashSet -> 想找连续序列,首先要找到这个连续序列的开头元素,然后递增,看看之后有多少个元素还在 nums 中,即可得到最长连续序列的长度了。
题解代码
class Solution {public int longestConsecutive(int[] nums) {// 转化成哈希集合,方便快速查找是否存在某个元素HashSet<Integer> set = new HashSet<Integer>();for (int num : nums) {set.add(num);}int res = 0;for (int num : set) {if (set.contains(num - 1)) {// num 不是连续子序列的第一个,跳过continue;}// num 是连续子序列的第一个,开始向上计算连续子序列的长度int curNum = num;int curLen = 1;while (set.contains(curNum + 1)) {curNum += 1;curLen += 1;}// 更新最长连续序列的长度res = Math.max(res, curLen);}return res;}
}
时空分析
- 时间复杂度:(O(n))
- 空间复杂度:(O(n))
- 原因分析:
- 时间复杂度:
- 首先,有一个
for循环遍历数组nums并将元素添加到HashSet中,这个过程的时间复杂度为 (O(n)),因为向HashSet中添加元素平均时间复杂度是 (O(1)),总共添加 n 个元素。- 然后,又有一个
for循环遍历HashSet中的元素。在这个循环中,对于每个元素,首先检查其前驱元素是否存在,如果不存在,则从该元素开始查找连续序列的长度。虽然这里有一个while循环,但对于每个连续序列,只会从序列的起始元素进入while循环一次。例如,对于序列[1, 2, 3],只有1会进入while循环来计算这个序列的长度。因此,这个while循环的总时间复杂度也是 (O(n))。所以整体时间复杂度为 (O(n + n)= O(n)) 。- 空间复杂度:
- 代码中使用了一个
HashSet来存储数组中的元素。在最坏情况下,数组中的所有元素都不相同,HashSet需要存储 n 个元素,所以空间复杂度为 (O(n))。
「双指针」
283. 移动零
题目描述
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
请注意 ,必须在不复制数组的情况下原地对数组进行操作。
核心思路
快慢指针 -> 先移除所有 0,然后把最后的元素都置为 0,就相当于移动 0 的效果。
题解代码
class Solution {public void moveZeroes(int[] nums) {// 去除 nums 中的所有 0// 返回去除 0 之后的数组长度int p = removeElement(nums, 0);// 将 p 之后的所有元素赋值为 0for (; p < nums.length; p++) {nums[p] = 0;}}// 双指针技巧,复用 [27. 移除元素] 的解法。int removeElement(int[] nums, int val) {int fast = 0, slow = 0;while (fast < nums.length) {if (nums[fast] != val) {nums[slow] = nums[fast];slow++;}fast++;}return slow;}
}
时空分析
时间复杂度:(O(n))
空间复杂度:(O(1))
原因分析:
时间复杂度:代码的核心操作集中在两个方法的循环中:
removeElement方法中,fast指针从 0 遍历到数组末尾(共 n 次,n 为数组长度),循环内操作均为常数时间 (O(1)),因此该方法时间复杂度为 (O(n));
moveZeroes方法中,除调用removeElement外,还包含一个从 (i = r) 到 (i = n-1) 的循环,该循环执行次数为 (n - r)(r 为removeElement的返回值),最多为 n 次,时间复杂度为 (O(n))。总操作次数为 (O(n) + O(n) = O(n)),忽略常数系数后,整体时间复杂度为 (O(n))。
空间复杂度:两个方法均仅使用固定数量的临时变量(如
fast、slow、r、i),未申请额外数组或动态内存,空间占用不随输入规模 n 变化,因此空间复杂度为常数级 (O(1))。
11. 盛最多水的容器
题目描述
给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。
找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
返回容器可以储存的最大水量。
说明: 你不能倾斜容器。
核心思路
左右指针 -> 用 left 和 right 两个指针从两端向中心收缩,一边收缩一边计算 [left, right] 之间的矩形面积,取最大的面积值即是答案。
题解代码
class Solution {public int maxArea(int[] height) {int left = 0, right = height.length - 1;int res = 0;while (left < right) {// [left, right] 之间的矩形面积int cur_area = Math.min(height[left], height[right]) * (right - left);res = Math.max(res, cur_area);// 双指针技巧,移动较低的一边if (height[left] < height[right]) {left++;} else {right--;}}return res;}
}
时空分析
时间复杂度:(O(n))
空间复杂度:(O(1))
原因分析:
时间复杂度:代码使用双指针法,核心是一个
while循环:
初始时左指针
left = 0,右指针right = n - 1(n 为数组长度);每次循环中,指针只会向中间移动一次(
left++或right--);循环终止条件为
left >= right,最多执行(n-1)次(指针从两端移动到相邻位置);循环内部操作(计算面积、更新结果、移动指针)均为常数时间 (O(1))。
总操作次数为 (O(n)),因此时间复杂度为 (O(n))。
空间复杂度:仅使用固定数量的临时变量(
left、right、res、area),未申请额外的数组或动态内存空间,空间占用不随输入规模 n 变化,因此空间复杂度为常数级 (O(1))。
15. 三数之和
题目描述
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i != j、i != k 且 j != k ,同时还满足 nums[i] + nums[j] + nums[k] == 0 。请你返回所有和为 0 且不重复的三元组。
注意: 答案中不可以包含重复的三元组。
核心思路
nSumTarget 模版。
排序 + 双指针 -> 先给数组从小到大排序,然后双指针 lo 和 hi 分别在数组开头和结尾,这样就可以控制 nums[lo] 和 nums[hi] 这两数之和的大小。如果你想让它俩的和大一些,就让 lo++,如果你想让它俩的和小一些,就让 hi--。
题解代码
class Solution {public List<List<Integer>> threeSum(int[] nums) {Arrays.sort(nums);// n 为 3,从 nums[0] 开始计算和为 0 的三元组return nSumTarget(nums, 3, 0, 0);}// 注意:调用这个函数之前一定要先给 nums 排序// n 填写想求的是几数之和,start 从哪个索引开始计算(一般填 0),target 填想凑出的目标和List<List<Integer>> nSumTarget(int[] nums, int n, int start, long target) {int sz = nums.length;List<List<Integer>> res = new ArrayList<>();// 至少是 2Sum,且数组大小不应该小于 nif (n < 2 || sz < n) return res;// 2Sum 是 base caseif (n == 2) {// 双指针那一套操作int lo = start, hi = sz - 1;while (lo < hi) {int sum = nums[lo] + nums[hi];int left = nums[lo], right = nums[hi];if (sum < target) {while (lo < hi && nums[lo] == left) lo++;} else if (sum > target) {while (lo < hi && nums[hi] == right) hi--;} else {res.add(new ArrayList<>(Arrays.asList(left, right)));while (lo < hi && nums[lo] == left) lo++;while (lo < hi && nums[hi] == right) hi--;}}} else {// n > 2 时,递归计算 (n-1)Sum 的结果for (int i = start; i < sz; i++) {List<List<Integer>> sub = nSumTarget(nums, n - 1, i + 1, target - nums[i]);for (List<Integer> arr : sub) {// (n-1)Sum 加上 nums[i] 就是 nSumarr.add(nums[i]);res.add(arr);}while (i < sz - 1 && nums[i] == nums[i + 1]) i++;}}return res;}
}
时空分析
时间复杂度:(O(n^2))
空间复杂度:(O(\log n))
原因分析:
时间复杂度:
- 首先对数组进行排序,排序操作的时间复杂度为 (O(n \log n))(其中 n 为数组长度)。
- 核心逻辑通过递归实现 nSum 计算,对于本题的
threeSum(即 (n = 3)):
- 外层有一个遍历数组的循环,时间复杂度为 (O(n));
- 每次循环内部调用 2Sum 逻辑,2Sum 通过双指针实现,时间复杂度为 (O(n));
- 因此 3Sum 的整体计算复杂度为 (O(n \times n) = O(n^2))。
- 由于 (O(n^2)) 的增长速度快于排序的 (O(n \log n)),最终时间复杂度由 (O(n^2)) 主导。
空间复杂度:
主要来源于两部分:
- 排序过程中(Java 的
Arrays.sort对基本类型使用双轴快排)的递归栈空间,复杂度为 (O(\log n));- 递归调用
nSumTarget的栈深度,对于threeSum仅从 3Sum 递归到 2Sum,深度为常数级((O(1)))。因此整体空间复杂度由排序的递归栈空间主导,为 (O(\log n))。
42. 接雨水
题目描述
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
核心思路
对于任意一个位置 i,能够装的水为:
water[i] = min(# 左边最高的柱子max(height[0..i]),# 右边最高的柱子max(height[i..end])) - height[i]
然后将这些位置求和即可。
题解代码
class Solution {public int trap(int[] height) {if (height.length == 0) {return 0;}int n = height.length;int res = 0;// 数组充当备忘录int[] l_max = new int[n];int[] r_max = new int[n];// 初始化 base casel_max[0] = height[0];r_max[n - 1] = height[n - 1];// 从左向右计算 l_maxfor (int i = 1; i < n; i++)l_max[i] = Math.max(height[i], l_max[i - 1]);// 从右向左计算 r_maxfor (int i = n - 2; i >= 0; i--)r_max[i] = Math.max(height[i], r_max[i + 1]);// 计算答案for (int i = 1; i < n - 1; i++)res += Math.min(l_max[i], r_max[i]) - height[i];return res;}
}
时空分析
时间复杂度:(O(n))
空间复杂度:(O(n))
原因分析:
时间复杂度:代码包含三个独立的线性循环,均基于数组长度 n 执行:
第一个循环(计算左侧最大值数组 (l_max))从 (i = 1) 到 (i = n-1),共执行 (n-1) 次;
第二个循环(计算右侧最大值数组 (r_max))从 (j = n-2) 到 (j = 0),共执行 (n-1) 次;
第三个循环(累加总接水量)从 (i = 0) 到 (i = n-1),共执行 n 次。
总操作次数为 ((n-1) + (n-1) + n = 3n - 2),根据大 O 表示法的定义,忽略常数项和系数后,时间复杂度为(O(n))。
空间复杂度:额外使用了两个长度为 n 的数组 (l_max) 和 (r_max),用于存储每个位置的左侧最大值和右侧最大值,总额外空间为 2n;其他变量(如 n、i、j、res)仅占用常数空间。忽略系数后,空间复杂度为 (O(n))。
「滑动窗口」
3. 无重复字符的最长子串
题目描述
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
核心思路
用一个 HashMap(CharToCount) 统计窗口中出现的字符的数量。当 window[c] 值大于 1 时,说明窗口中存在重复字符,不符合条件,就该移动 left 缩小窗口了。
题解代码
class Solution {public int lengthOfLongestSubstring(String s) {Map<Character, Integer> window = new HashMap<>();int left = 0, right = 0;// 记录结果int res = 0;while (right < s.length()) {char c = s.charAt(right);right++;// 进行窗口内数据的一系列更新window.put(c, window.getOrDefault(c, 0) + 1);// 判断左侧窗口是否要收缩while (window.get(c) > 1) {char d = s.charAt(left);left++;// 进行窗口内数据的一系列更新window.put(d, window.get(d) - 1);}// 在这里更新答案res = Math.max(res, right - left);}return res;}
}
时空分析
- 时间复杂度:(O(n))
- 空间复杂度:(O(min(n, m))),其中 n 是字符串
s的长度,m 是字符集的大小- 原因分析:
- 时间复杂度:
- 代码使用滑动窗口算法,通过
while循环遍历字符串s。right指针从字符串开头开始,逐步向右移动,最多移动 n 次,其中 n 是字符串s的长度。- 对于每个
right指针移动,虽然存在一个内层while循环用于收缩左侧窗口,但从整体来看,left指针也最多向右移动 n 次。也就是说,两个指针移动的总次数最多为 2n 次。因此,整体时间复杂度为 (O(n))。- 空间复杂度:
- 代码中使用了一个
HashMap来存储窗口内的字符及其出现的次数。在最坏情况下,窗口内可能包含所有不同的字符。如果字符集大小为 m,那么HashMap最多会存储 m 个不同的字符。当 (m < n) 时,空间复杂度为 (O(m));当 (m \geq n) 时,窗口内最多只能容纳 n 个不同字符,此时空间复杂度为 (O(n))。所以空间复杂度为 (O(min(n, m)))。
438. 找到字符串中所有字母异位词
题目描述
给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
核心思路
先用一个 HashMap 统计 p 中各个字符出现的次数,need。然后在用一个 HashMap 统计 window 中各字符出现的次数。如果 window 满足了 need(用一个 valid 实现),就将索引添加到结果列表中。
什么时候扩大窗口? right 一直往右遍历。
什么时候缩小窗口? right - left >= p.length() 时缩小窗口。
什么时候更新答案? 当缩小窗口时,如果满足 valid 则更新答案。
note:Integer 包装器类型,判断值是否相等要使用 .equals()。
题解代码
class Solution {public List<Integer> findAnagrams(String s, String t) {Map<Character, Integer> need = new HashMap<>();Map<Character, Integer> window = new HashMap<>();for (char c : t.toCharArray()) {need.put(c, need.getOrDefault(c, 0) + 1);}int left = 0, right = 0;int valid = 0;// 记录结果List<Integer> res = new ArrayList<>();while (right < s.length()) {char c = s.charAt(right);right++;// 进行窗口内数据的一系列更新if (need.containsKey(c)) {window.put(c, window.getOrDefault(c, 0) + 1);if (window.get(c).equals(need.get(c))) {valid++;}}// 判断左侧窗口是否要收缩while (right - left >= t.length()) {// 当窗口符合条件时,把起始索引加入 resif (valid == need.size()) {res.add(left);}char d = s.charAt(left);left++;// 进行窗口内数据的一系列更新if (need.containsKey(d)) {if (window.get(d).equals(need.get(d))) {valid--;}window.put(d, window.get(d) - 1);}}}return res;}
}
「子串」
560. 和为 K 的子数组
题目描述
给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的子数组的个数 。
子数组是数组中元素的连续非空序列。
核心思路
前缀和 和 HashMap -> 需要在维护 preSum 前缀和数组的同时动态维护 count 映射,而不能等到 preSum 计算完成后再处理 count,因为 count[need] 应该维护 preSum[0..i] 中值为 need 的元素个数。
题解代码
class Solution {public int subarraySum(int[] nums, int k) {int n = nums.length;// 前缀和数组int[] preSum = new int[n + 1];preSum[0] = 0;// 前缀和到该前缀和出现次数的映射,方便快速查找所需的前缀和HashMap<Integer, Integer> count = new HashMap<>();count.put(0, 1);// 记录和为 k 的子数组个数int res = 0;// 计算 nums 的前缀和for (int i = 1; i <= n; i++) {preSum[i] = preSum[i - 1] + nums[i - 1];// 如果之前存在值为 need 的前缀和// 说明存在以 nums[i-1] 结尾的子数组的和为 kint need = preSum[i] - k;if (count.containsKey(need)) {res += count.get(need);}// 将当前前缀和存入哈希表if (!count.containsKey(preSum[i])) {count.put(preSum[i], 1);} else {count.put(preSum[i], count.get(preSum[i]) + 1);}}return res;}
}
239. 滑动窗口最大值
题目描述
给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
返回 滑动窗口中的最大值 。
核心思路
单调队列作为滑动窗口。
使用一个队列充当不断滑动的窗口,每次滑动记录其中的最大值:

如何在 O(1) 时间计算最大值,只需要一个特殊的数据结构「单调队列」,push 方法依然在队尾添加元素,但是要把前面比自己小的元素都删掉,直到遇到更大的元素才停止删除。

题解代码
class Solution {// 单调队列的实现class MonotonicQueue {LinkedList<Integer> q = new LinkedList<>();public void push(int n) {// 将小于 n 的元素全部删除while (!q.isEmpty() && q.getLast() < n) {q.pollLast();}// 然后将 n 加入尾部q.addLast(n);}public int max() {return q.getFirst();}public void pop(int n) {if (n == q.getFirst()) {q.pollFirst();}}}// 解题函数的实现public int[] maxSlidingWindow(int[] nums, int k) {MonotonicQueue window = new MonotonicQueue();List<Integer> res = new ArrayList<>();for (int i = 0; i < nums.length; i++) {if (i < k - 1) {// 先填满窗口的前 k - 1window.push(nums[i]);} else {// 窗口向前滑动,加入新数字window.push(nums[i]);// 记录当前窗口的最大值res.add(window.max());// 移出旧数字window.pop(nums[i - k + 1]);}}// 需要转成 int[] 数组再返回int[] arr = new int[res.size()];for (int i = 0; i < res.size(); i++) {arr[i] = res.get(i);}return arr;}
}
76. 最小覆盖子串
题目描述
给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 "" 。
注意:
- 对于
t中重复字符,我们寻找的子字符串中该字符数量必须不少于t中该字符数量。 - 如果
s中存在这样的子串,我们保证它是唯一的答案。
核心思路
滑动窗口 -> 标准滑动窗口框架,用两个 HashMap 分别充当 window 和 need,统计每个字符的数量。
什么时候扩大窗口?right < n 时扩大窗口。
什么时候缩小窗口?当 valid >= need.size() 时缩小窗口,也就是窗口中覆盖了 t 的所有字符。
什么时候更新答案?当缩小窗口的时候更新答案。
题解代码
class Solution {public String minWindow(String s, String t) {Map<Character, Integer> need = new HashMap<>();Map<Character, Integer> window = new HashMap<>();for (char c : t.toCharArray()) {need.put(c, need.getOrDefault(c, 0) + 1);}int left = 0, right = 0;int valid = 0;// 记录最小覆盖子串的起始索引及长度int start = 0, len = Integer.MAX_VALUE;while (right < s.length()) {// c 是将移入窗口的字符char c = s.charAt(right);// 扩大窗口right++;// 进行窗口内数据的一系列更新if (need.containsKey(c)) {window.put(c, window.getOrDefault(c, 0) + 1);if (window.get(c).equals(need.get(c)))valid++;}// 判断左侧窗口是否要收缩while (valid == need.size()) {// 在这里更新最小覆盖子串if (right - left < len) {start = left;len = right - left;}// d 是将移出窗口的字符char d = s.charAt(left);// 缩小窗口left++;// 进行窗口内数据的一系列更新if (need.containsKey(d)) {if (window.get(d).equals(need.get(d)))valid--;window.put(d, window.get(d) - 1);} }}// 返回最小覆盖子串return len == Integer.MAX_VALUE ? "" : s.substring(start, start + len);}
}
「普通数组」
53. 最大子数组和
题目描述
给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
子数组 是数组中的一个连续部分。
核心思路
动态规划 -> dp 数组的含义:以 nums[i] 为结尾的「最大子数组和」为 dp[i]。dp[i] 有两种「选择」,要么与前面的相邻子数组连接,形成一个和更大的子数组;要么不与前面的子数组连接,自成一派,自己作为一个子数组。在这两种选择中择优,就可以计算出最大子数组。
滑动窗口 -> right < n 时扩大窗口,windowSum < 0 时缩小窗口,扩大窗口的时候同时更新答案。
题解代码
class Solution {public int maxSubArray(int[] nums) {int n = nums.length;int[] dp = new int[n];// base case// 第一个元素前面没有子数组dp[0] = nums[0];// 状态转移方程for (int i = 1; i < n; i++) {dp[i] = Math.max(nums[i], nums[i] + dp[i - 1]);}// 得到 nums 的最大子数组int res = Integer.MIN_VALUE;for (int i = 0; i < n; i++) {res = Math.max(res, dp[i]);}return res;}
}
class Solution {public int maxSubArray(int[] nums) {int n = nums.length;int windowSum = 0;int left = 0, right = 0;int res = Integer.MIN_VALUE;while(right < n){windowSum += nums[right];right++;res = Math.max(res, windowSum);while(windowSum < 0){windowSum -= nums[left];left++;}}return res;}
}
56. 合并区间
题目描述
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。
核心思路
技巧 -> 一个区间可以表示为 [start, end],先按区间的 start 排序。对于几个相交区间合并后的结果区间 x,x.start 一定是这些相交区间中 start 最小的,x.end 一定是这些相交区间中 end 最大的。
题解代码
class Solution {public int[][] merge(int[][] intervals) {LinkedList<int[]> res = new LinkedList<>();// 按区间的 start 升序排列Arrays.sort(intervals, (a, b) -> {return a[0] - b[0];});res.add(intervals[0]);for (int i = 1; i < intervals.length; i++) {int[] curr = intervals[i];// res 中最后一个元素的引用int[] last = res.getLast();if (curr[0] <= last[1]) {last[1] = Math.max(last[1], curr[1]);} else {// 处理下一个待合并区间res.add(curr);}}return res.toArray(new int[0][0]);}
}
189. 轮转数组
题目描述
给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。
核心思路
技巧 -> 先把整个数组反转,再分别反转前 k 个和后 n-k 个即可。
例如 [1,2,3,4,5], k = 3, 先反转整个数组得 [5,4,3,2,1], 再反转前 k 个得 [3,4,5,2,1], 再反转后 n-k 个得 [3,4,5,1,2] 即为答案。
note:k 需要小于 n。(取模)
题解代码
class Solution {public void rotate(int[] nums, int k) {int n = nums.length;k %= n;reverse(nums, 0, n - 1);reverse(nums, 0, k - 1);reverse(nums, k, n - 1);}public void reverse(int[] nums, int start, int end){while(start < end){int temp = nums[start];nums[start] = nums[end];nums[end] = temp;start++;end--;}}
}
238. 除自身以外数组的乘积
题目描述
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积。
题目数据 保证 数组 nums 之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。
请 不要使用除法, 且在 O(n) 时间复杂度内完成此题。
核心思路
前缀积 -> 前缀和数组中两个元素之差是子数组元素之和,那么如果构造「前缀积」数组,两个元素相除就是子数组元素之积。
构造一个 prefix 数组记录「前缀积」,再用一个 suffix 记录「后缀积」,根据前缀和后缀积就能计算除了当前元素之外其他元素的积。
题解代码
class Solution {public int[] productExceptSelf(int[] nums) {int n = nums.length;// 从左到右的前缀积,prefix[i] 是 nums[0..i] 的元素积int[] prefix = new int[n];prefix[0] = nums[0];for (int i = 1; i < nums.length; i++) {prefix[i] = prefix[i - 1] * nums[i];}// 从右到左的前缀积,suffix[i] 是 nums[i..n-1] 的元素积int[] suffix = new int[n];suffix[n - 1] = nums[n - 1];for (int i = n - 2; i >= 0; i--) {suffix[i] = suffix[i + 1] * nums[i];}// 结果数组int[] res = new int[n];res[0] = suffix[1];res[n - 1] = prefix[n - 2];for (int i = 1; i < n - 1; i++) {// 除了 nums[i] 自己的元素积就是 nums[i] 左侧和右侧所有元素之积res[i] = prefix[i - 1] * suffix[i + 1];}return res;}
}
41. 缺失的第一个正数
题目描述
给你一个未排序的整数数组 nums ,请你找出其中没有出现的最小的正整数。
请你实现时间复杂度为 O(n) 并且只使用常数级别额外空间的解决方案。
核心思路
对于一个长度为 N 的数组,其中没有出现的最小正整数只能在 [1, N+1] 中。这是因为如果 [1, N] 都出现了,那么答案是 N+1,否则答案是 [1, N] 中没有出现的最小正整数。
数组设计成哈希表 -> 我们对数组进行遍历,对于遍历到的数 x,如果它在 [1, N] 的范围内,那么就将数组中的第 x−1 个位置(注意:数组下标从 0 开始)打上「标记」。在遍历结束之后,如果所有的位置都被打上了标记,那么答案是 N+1,否则答案是最小的没有打上标记的位置加 1。
算法的流程如下:
- 我们将数组中所有小于等于 0 的数修改为 N+1;
- 我们遍历数组中的每一个数 x,它可能已经被打了标记,因此原本对应的数为 ∣x∣,其中 ∣∣ 为绝对值符号。如果 ∣x∣∈ [1, N],那么我们给数组中的第 ∣x∣−1 个位置的数添加一个负号。注意如果它已经有负号,不需要重复添加;
- 在遍历完成之后,如果数组中的每一个数都是负数,那么答案是 N+1,否则答案是第一个正数的位置加 1。
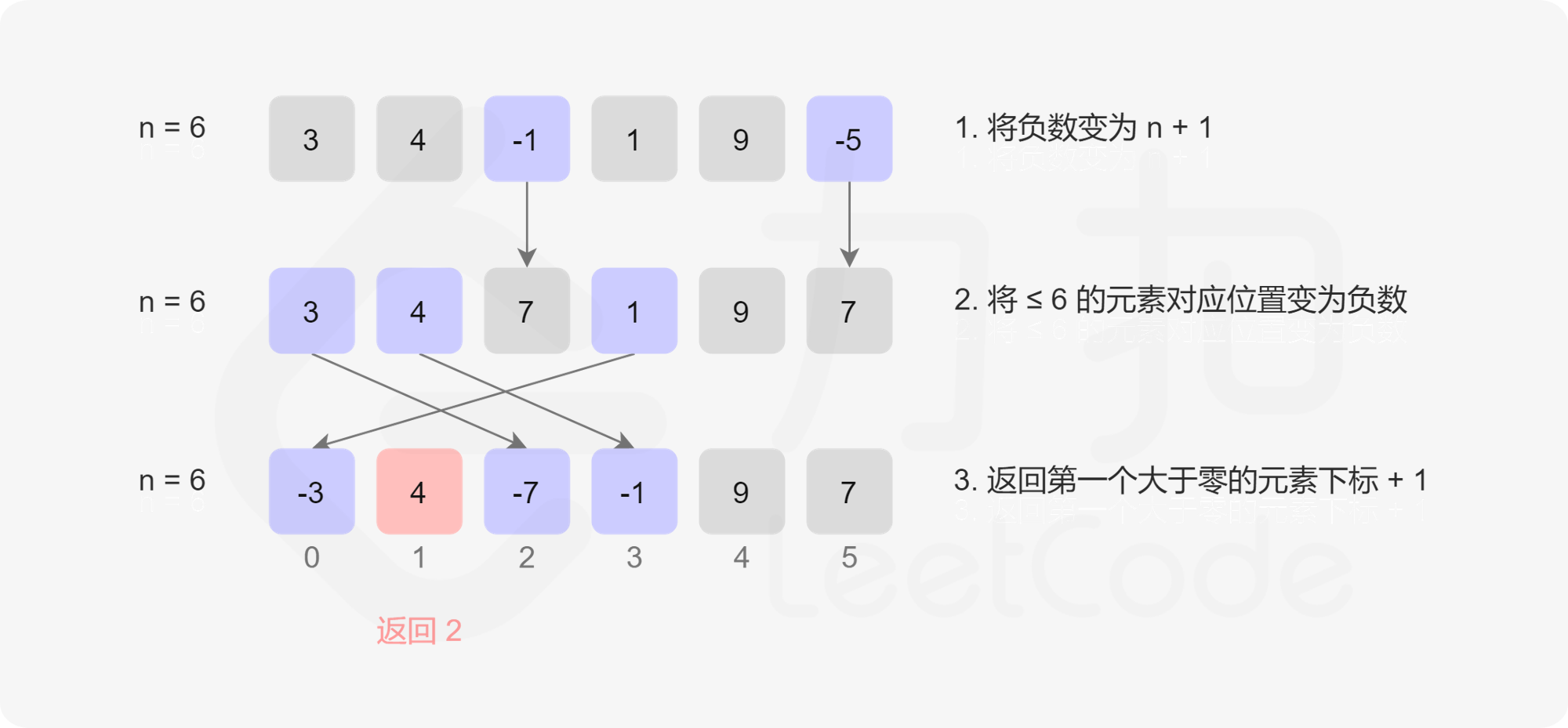
题解代码
class Solution {public int firstMissingPositive(int[] nums) {int n = nums.length;for (int i = 0; i < n; i++) {if (nums[i] <= 0) {nums[i] = n + 1;}}for (int i = 0; i < n; i++) {int num = Math.abs(nums[i]);if (1 <= num && num <= n) {nums[num - 1] = -Math.abs(nums[num - 1]);}}for (int i = 0; i < n; i++) {if (nums[i] > 0) {return i + 1;}}return n + 1;}
}
「矩阵」
73. 矩阵置零
题目描述
给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用原地算法。
核心思路
二维数组遍历 -> 用两个标记数组分别记录每一行和每一列是否有零出现 -> 首先遍历数组一次,如果某个元素为 0,那么就将该元素所在的行和列所对应标记数组的位置置为 true。最后再次遍历该数组,用标记数组更新原数组即可。
题解代码
class Solution {public void setZeroes(int[][] matrix) {int m = matrix.length, n = matrix[0].length;boolean[] row = new boolean[m];boolean[] col = new boolean[n];for (int i = 0; i < m; i++) {for (int j = 0; j < n; j++) {if (matrix[i][j] == 0) {row[i] = col[j] = true;}}}for (int i = 0; i < m; i++) {for (int j = 0; j < n; j++) {if (row[i] || col[j]) {matrix[i][j] = 0;}}}}
}
54. 螺旋矩阵
题目描述
给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。
核心思路

二维数组遍历 -> 按照 右、下、左、上 的顺序遍历数组,并使用四个变量圈定未遍历元素的边界。
题解代码
class Solution {public List<Integer> spiralOrder(int[][] matrix) {int m = matrix.length, n = matrix[0].length;int upper_bound = 0, lower_bound = m - 1;int left_bound = 0, right_bound = n - 1;List<Integer> res = new LinkedList<>();// res.size() == m * n 则遍历完整个数组while (res.size() < m * n) {if (upper_bound <= lower_bound) {// 在顶部从左向右遍历for (int j = left_bound; j <= right_bound; j++) {res.add(matrix[upper_bound][j]);}// 上边界下移upper_bound++;}if (left_bound <= right_bound) {// 在右侧从上向下遍历for (int i = upper_bound; i <= lower_bound; i++) {res.add(matrix[i][right_bound]);}// 右边界左移right_bound--;}if (upper_bound <= lower_bound) {// 在底部从右向左遍历for (int j = right_bound; j >= left_bound; j--) {res.add(matrix[lower_bound][j]);}// 下边界上移lower_bound--;}if (left_bound <= right_bound) {// 在左侧从下向上遍历for (int i = lower_bound; i >= upper_bound; i--) {res.add(matrix[i][left_bound]);}// 左边界右移left_bound++;}}return res;}
}
48. 旋转图像
题目描述
给定一个 n × n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。
你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。
核心思路
二维数组遍历 -> 先把二维矩阵沿对角线反转,然后反转矩阵的每一行,结果就是顺时针反转整个矩阵。
题解代码
class Solution {public void rotate(int[][] matrix) {int n = matrix.length;// 先沿对角线反转二维矩阵for (int i = 0; i < n; i++) {for (int j = i; j < n; j++) {// swap(matrix[i][j], matrix[j][i]);int temp = matrix[i][j];matrix[i][j] = matrix[j][i];matrix[j][i] = temp;}}// 然后反转二维矩阵的每一行for (int[] row : matrix) {reverse(row);}}// 反转一维数组void reverse(int[] arr) {int i = 0, j = arr.length - 1;while (j > i) {// swap(arr[i], arr[j]);int temp = arr[i];arr[i] = arr[j];arr[j] = temp;i++;j--;}}
}
240. 搜索二维矩阵 II
题目描述
编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性:
- 每行的元素从左到右升序排列。
- 每列的元素从上到下升序排列。
核心思路
二维数组遍历 -> 从右上角开始遍历,规定只能向左或向下移动。如果向左移动,元素在减小,如果向下移动,元素在增大,这样的话就可以根据当前位置的元素和 target 的相对大小来判断应该往哪移动,不断接近从而找到 target 的位置。
题解代码
class Solution {public boolean searchMatrix(int[][] matrix, int target) {int m = matrix.length, n = matrix[0].length;// 初始化在右上角int i = 0, j = n - 1;while (i < m && j >= 0) {if (matrix[i][j] == target) {return true;}if (matrix[i][j] < target) {// 需要大一点,往下移动i++;} else {// 需要小一点,往左移动j--;}}// while 循环中没有找到,则 target 不存在return false;}
}
「链表」
160. 相交链表
题目描述
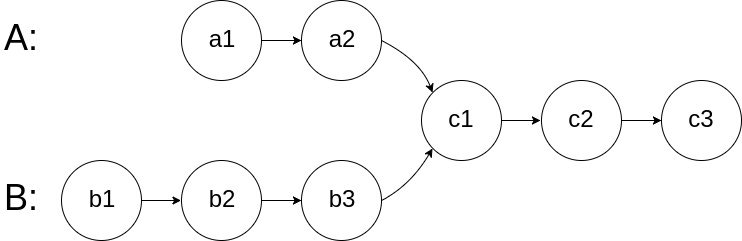
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
图示两个链表在节点 c1 开始相交:
题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构。
核心思路
两个指针 p1 和 p2 分别在两条链表上前进,我们可以让 p1 遍历完链表 A 之后开始遍历链表 B,让 p2 遍历完链表 B 之后开始遍历链表 A,这样相当于「逻辑上」两条链表接在了一起。
如果这样进行拼接,就可以让 p1 和 p2 同时进入公共部分,也就是同时到达相交节点 c1。
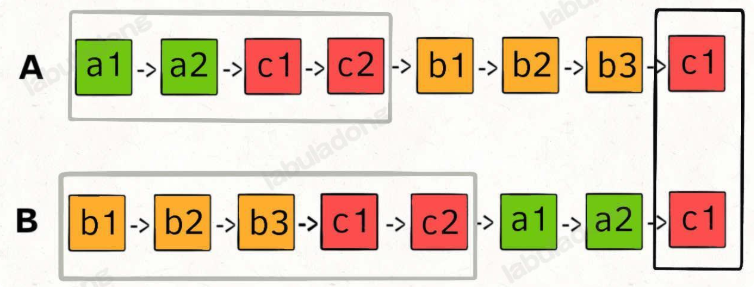
题解代码
public class Solution {public ListNode getIntersectionNode(ListNode headA, ListNode headB) {// p1 指向 A 链表头结点,p2 指向 B 链表头结点ListNode p1 = headA, p2 = headB;while (p1 != p2) {// p1 走一步,如果走到 A 链表末尾,转到 B 链表if (p1 == null) p1 = headB;else p1 = p1.next;// p2 走一步,如果走到 B 链表末尾,转到 A 链表if (p2 == null) p2 = headA;else p2 = p2.next;}return p1;}
}
206. 反转链表
题目描述
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
核心思路
迭代 -> 三个结点 cur,pre 与 next。
题解代码
class Solution {public ListNode reverseList(ListNode head) {ListNode cur = head, pre = null;while(cur != null){ListNode next = cur.next;cur.next = pre;pre = cur;cur = next;}return pre;}
}
234. 回文链表
题目描述
给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。
核心思路
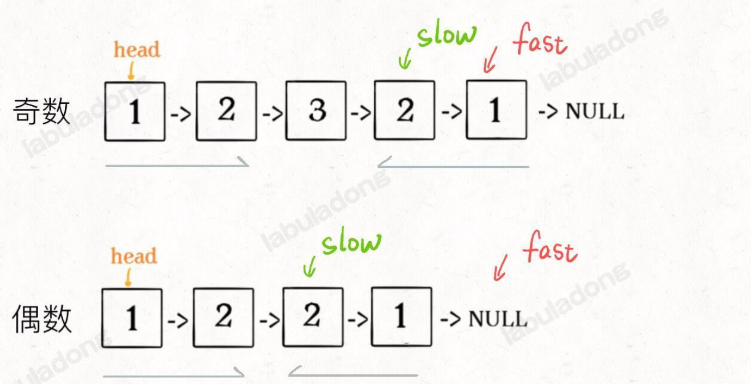
- 先通过快慢指针找到链表的中点。(注意奇偶长度)
- 从 slow 开始反转后面的链表,现在就可以开始比较回文串了。
题解代码
class Solution {public boolean isPalindrome(ListNode head) {ListNode slow, fast;slow = fast = head;while (fast != null && fast.next != null) {slow = slow.next;fast = fast.next.next;}if (fast != null)slow = slow.next;ListNode left = head;ListNode right = reverse(slow);while (right != null) {if (left.val != right.val)return false;left = left.next;right = right.next;}return true;}ListNode reverse(ListNode head) {ListNode pre = null, cur = head;while (cur != null) {ListNode next = cur.next;cur.next = pre;pre = cur;cur = next;}return pre;}
}
141. 环形链表
题目描述
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
核心思路
快慢指针 -> 每当慢指针 slow 前进一步,快指针 fast 就前进两步。如果 fast 最终遇到空指针,说明链表中没有环;如果 fast 最终和 slow 相遇,那肯定是 fast 超过了 slow 一圈,说明链表中含有环。
题解代码
public class Solution {public boolean hasCycle(ListNode head) {// 快慢指针初始化指向 headListNode slow = head, fast = head;// 快指针走到末尾时停止while (fast != null && fast.next != null) {// 慢指针走一步,快指针走两步slow = slow.next;fast = fast.next.next;// 快慢指针相遇,说明含有环if (slow == fast) {return true;}}// 不包含环return false;}
}
142. 环形链表 II
题目描述
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改 链表。
核心思路
基于环形链表的解法,直观地来说就是当快慢指针相遇时,让其中任一个指针指向头节点,然后让它俩以相同速度前进,再次相遇时所在的节点位置就是环开始的位置。
题解代码
class Solution {public ListNode detectCycle(ListNode head) {ListNode fast, slow;fast = slow = head;while (fast != null && fast.next != null) {fast = fast.next.next;slow = slow.next;if (fast == slow) break;}// 上面的代码类似 hasCycle 函数if (fast == null || fast.next == null) {// fast 遇到空指针说明没有环return null;}// 重新指向头结点slow = head;// 快慢指针同步前进,相交点就是环起点while (slow != fast) {fast = fast.next;slow = slow.next;}return slow;}
}
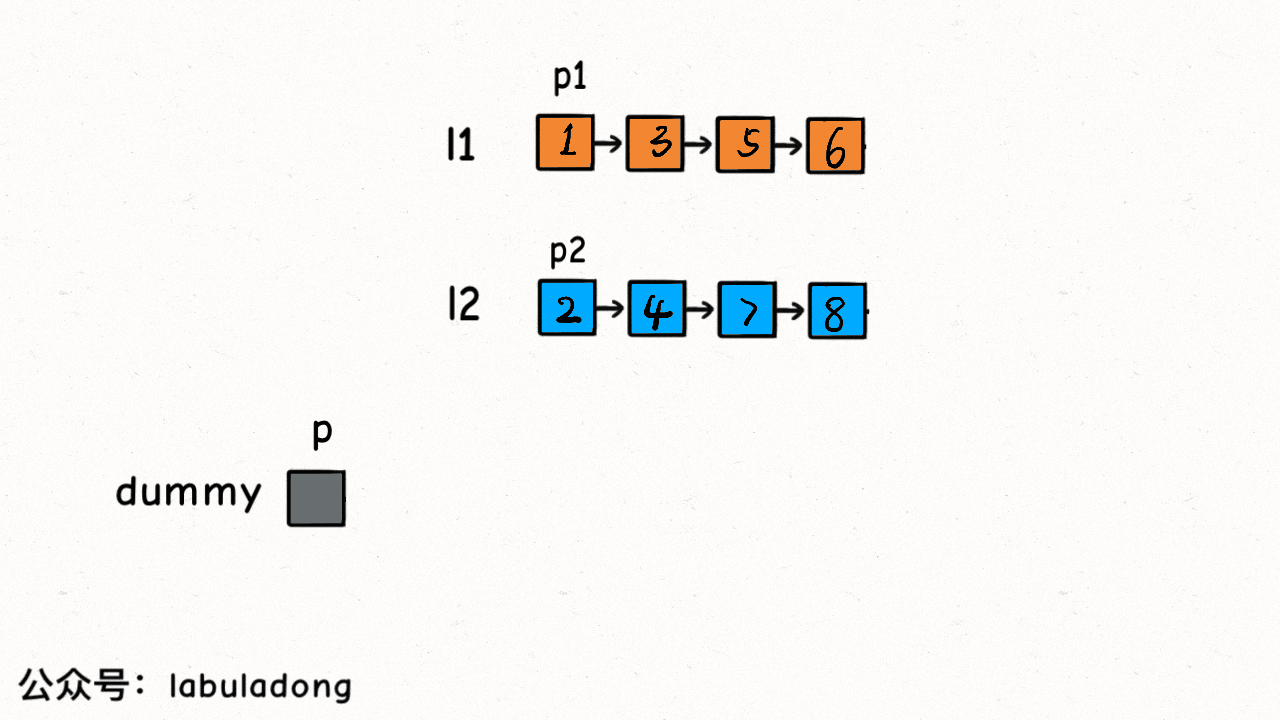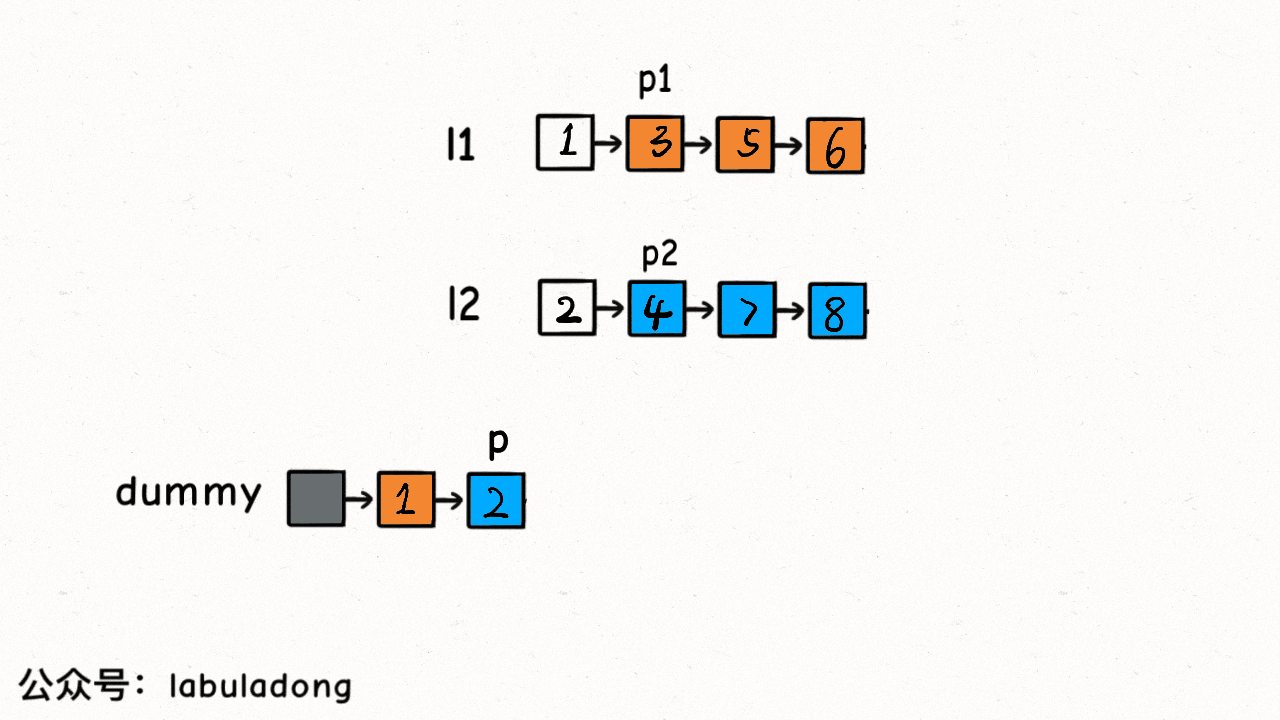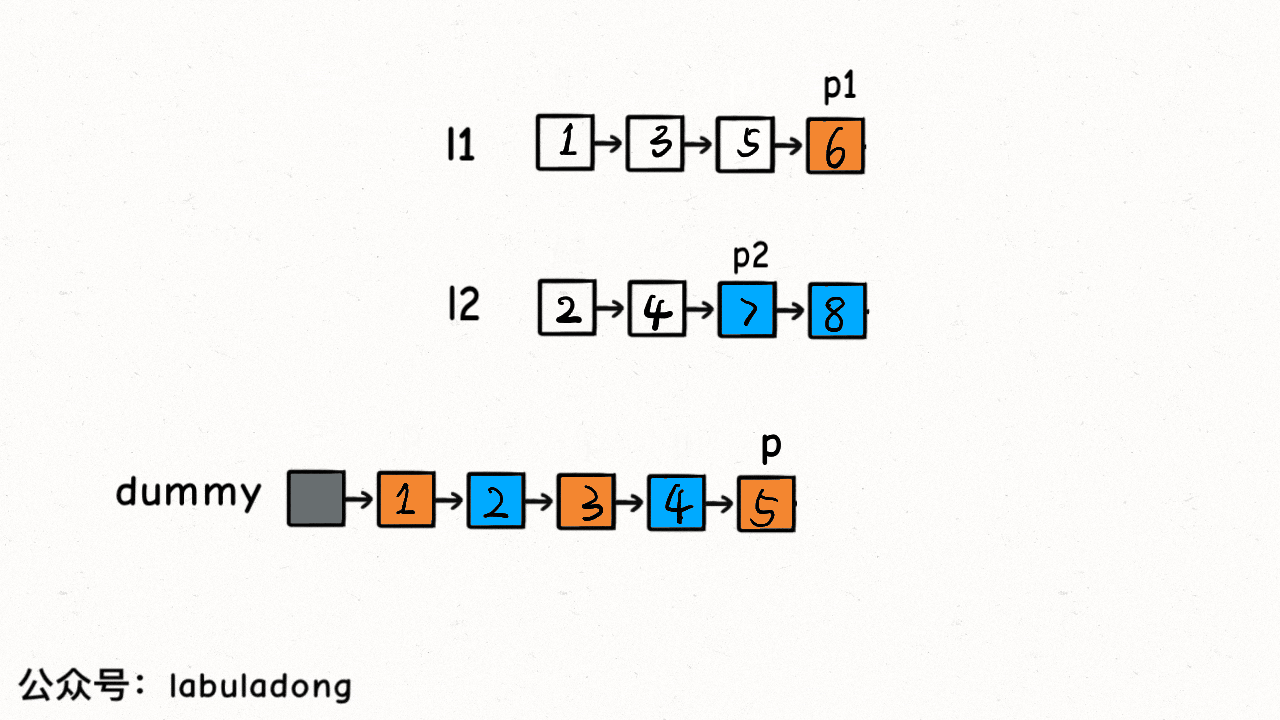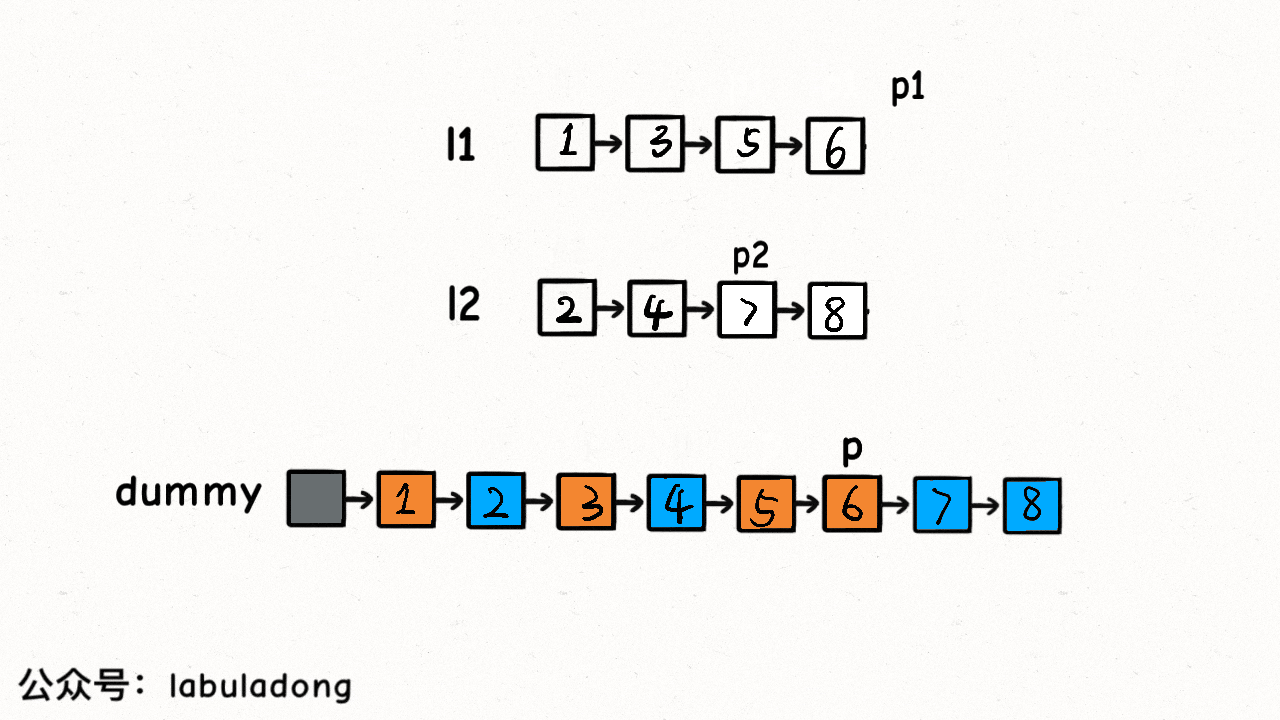
21. 合并两个有序链表
题目描述
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
核心思路
双指针和虚拟头结点
题解代码
class Solution {public ListNode mergeTwoLists(ListNode l1, ListNode l2) {// 虚拟头结点ListNode dummy = new ListNode(-1), p = dummy;ListNode p1 = l1, p2 = l2;while (p1 != null && p2 != null) {// 比较 p1 和 p2 两个指针// 将值较小的的节点接到 p 指针if (p1.val > p2.val) {p.next = p2;p2 = p2.next;} else {p.next = p1;p1 = p1.next;}// p 指针不断前进p = p.next;}if (p1 != null) {p.next = p1;}if (p2 != null) {p.next = p2;}return dummy.next;}
}
2. 两数相加
题目描述
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
核心思路
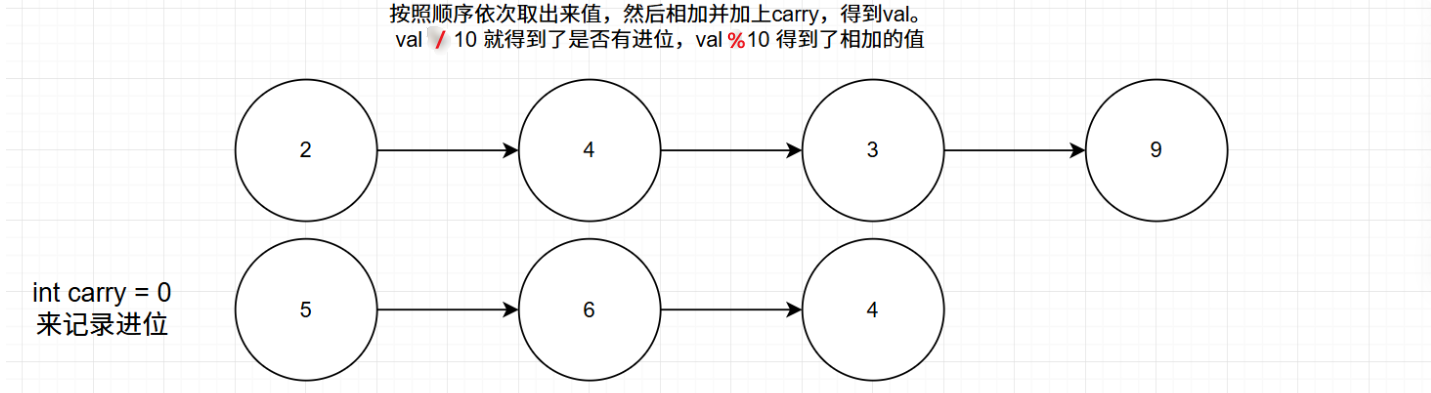
用一个 carry 变量记录进位,然后通过 (valA + valB + carry) % 10 计算当前位的值,通过 (valA + valB + carry) / 10 计算进位。
题解代码
class Solution {public ListNode addTwoNumbers(ListNode l1, ListNode l2) {// 在两条链表上的指针ListNode p1 = l1, p2 = l2;// 虚拟头结点(构建新链表时的常用技巧)ListNode dummy = new ListNode(-1);// 指针 p 负责构建新链表ListNode p = dummy;// 记录进位int carry = 0;// 开始执行加法,两条链表走完且没有进位时才能结束循环while (p1 != null || p2 != null || carry > 0) {// 先加上上次的进位int val = carry;if (p1 != null) {val += p1.val;p1 = p1.next;}if (p2 != null) {val += p2.val;p2 = p2.next;}// 处理进位情况carry = val / 10;val = val % 10;// 构建新节点p.next = new ListNode(val);p = p.next;}// 返回结果链表的头结点(去除虚拟头结点)return dummy.next;}
}
19. 删除链表的倒数第 N 个结点
题目描述
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
核心思路
要删除倒数第 n 个节点,就得获得倒数第 n + 1 个节点的引用。
第一步,我们先让一个指针 p1 指向链表的头节点 head,然后走 k 步。
第二步,用一个指针 p2 指向链表头节点 head。
第三步,让 p1 和 p2 同时向前走,p1 走到链表末尾的空指针时走了 n - k 步,p2 也走了 n - k 步,也就是链表的倒数第 k 个节点。
这样,只遍历了一次链表,就获得了倒数第 k 个节点 p2。
题解代码
class Solution {// 主函数public ListNode removeNthFromEnd(ListNode head, int n) {// 虚拟头结点ListNode dummy = new ListNode(-1);dummy.next = head;// 删除倒数第 n 个,要先找倒数第 n + 1 个节点ListNode x = findFromEnd(dummy, n + 1);// 删掉倒数第 n 个节点x.next = x.next.next;return dummy.next;}// 返回链表的倒数第 k 个节点ListNode findFromEnd(ListNode head, int k) {ListNode p1 = head;// p1 先走 k 步for (int i = 0; i < k; i++) {p1 = p1.next;}ListNode p2 = head;// p1 和 p2 同时走 n - k 步while (p1 != null) {p2 = p2.next;p1 = p1.next;}// p2 现在指向第 n - k 个节点return p2;}
}
24. 两两交换链表中的节点
题目描述
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
核心思路
递归
题解代码
class Solution {// 定义:输入以 head 开头的单链表,将这个单链表中的每两个元素翻转,// 返回翻转后的链表头结点public ListNode swapPairs(ListNode head) {if (head == null || head.next == null) {return head;}ListNode first = head;ListNode second = head.next;ListNode others = head.next.next;// 先把前两个元素翻转second.next = first;// 利用递归定义,将剩下的链表节点两两翻转,接到后面first.next = swapPairs(others);// 现在整个链表都成功翻转了,返回新的头结点return second;}
}
25. K 个一组翻转链表
题目描述
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
核心思路
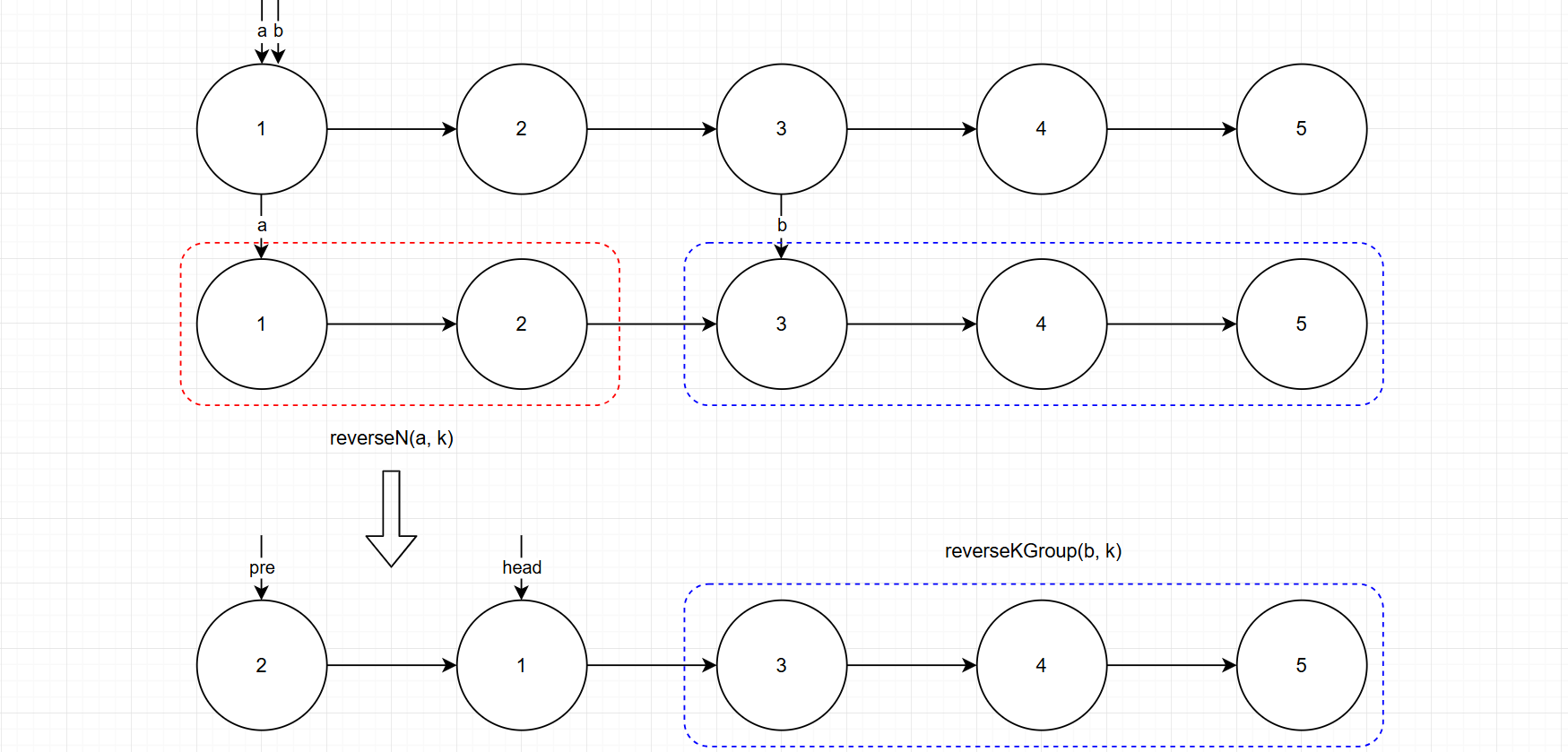
- 先反转以
head开头的k个元素。这里可以复用前面实现的reverseN函数。 - 将第
k + 1个元素作为head递归调用reverseKGroup函数。 - 将上述两个过程的结果连接起来。
题解代码
class Solution {public ListNode reverseKGroup(ListNode head, int k) {ListNode p1 = head, p2 = head;// 找到第 k + 1 个结点for(int i = 0; i < k; i++){// 如果不够 K 个,不需要反转if(p2 == null) return head;p2 = p2.next;}// 反转前 k 个元素ListNode pre = reverseK(p1, k);// 递归反转后续链表,并连接起来head.next = reverseKGroup(p2, k);return pre;}// 反转前 k 个链表public ListNode reverseK(ListNode head, int k){ListNode pre = null, cur = head;while(k != 0){ListNode next = cur.next;cur.next = pre;pre = cur;cur = next;k--;}return pre;}
}
138. 随机链表的复制
题目描述
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示Node.val的整数。random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。
你的代码 只 接受原链表的头节点 head 作为传入参数。
核心思路
一个哈希表 + 两次遍历。
第一次遍历专门克隆节点,借助哈希表把原始节点和克隆节点的映射存储起来;第二次专门组装节点,照着原数据结构的样子,把克隆节点的指针组装起来。
题解代码
class Solution {public Node copyRandomList(Node head) {HashMap<Node, Node> originToClone = new HashMap<>();// 第一次遍历,先把所有节点克隆出来for (Node p = head; p != null; p = p.next) {if (!originToClone.containsKey(p)) {originToClone.put(p, new Node(p.val));}}// 第二次遍历,把克隆节点的结构连接好for (Node p = head; p != null; p = p.next) {if (p.next != null) {originToClone.get(p).next = originToClone.get(p.next);}if (p.random != null) {originToClone.get(p).random = originToClone.get(p.random);}}// 返回克隆之后的头结点return originToClone.get(head);}
}148. 排序链表
题目描述
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
核心思路
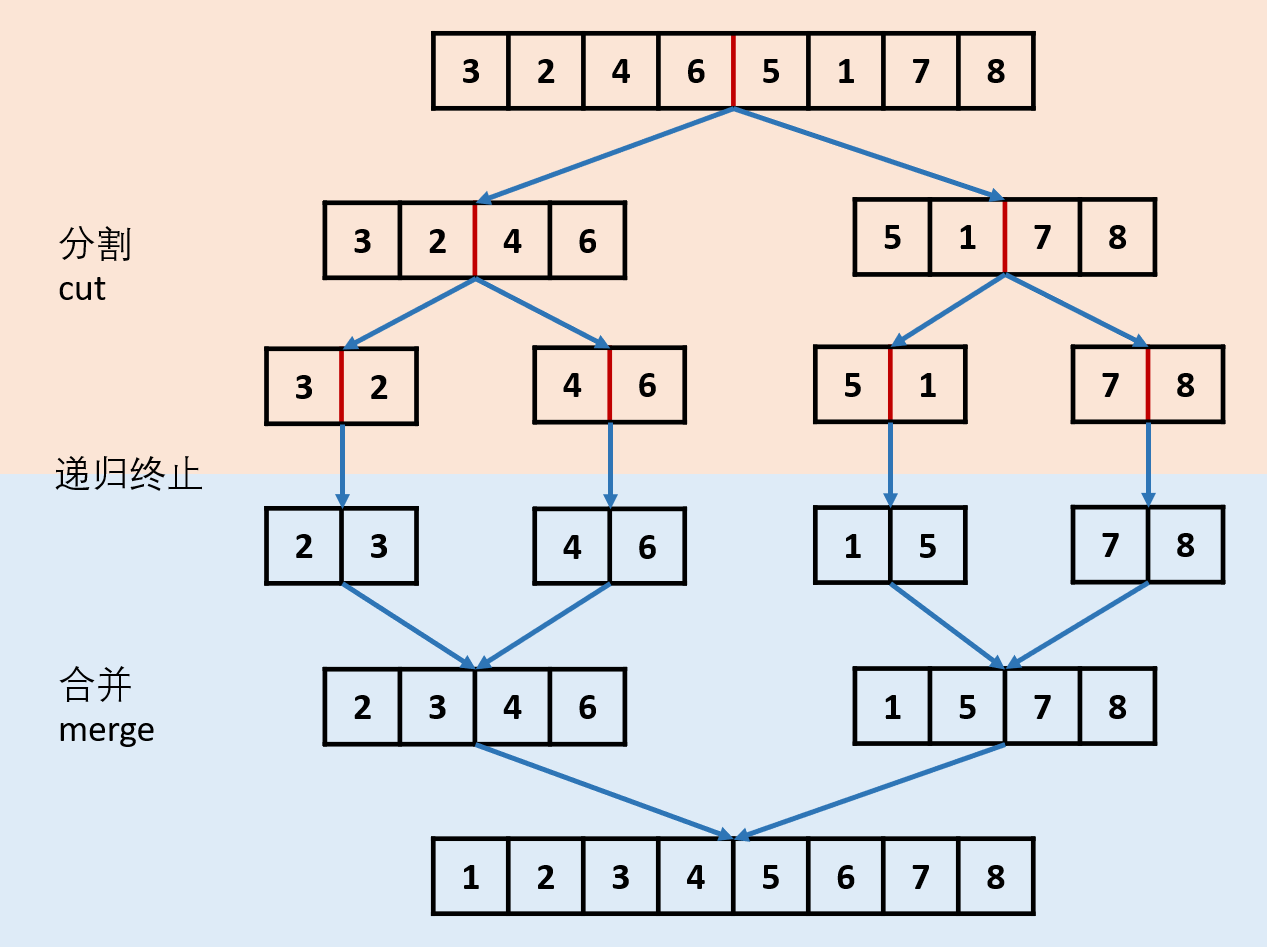
归并排序(分治) ->
- 找到 链表的中间结点 head2 的 前一个节点,并断开 head2 与其前一个节点的连接。这样我们就把原链表均分成了两段更短的链表。
- 分治,递归调用 sortList,分别排序 head(只有前一半)和 head2。
- 排序后,我们得到了两个有序链表,那么 合并两个有序链表,得到排序后的链表,返回链表头节点。
题解代码
class Solution {public ListNode sortList(ListNode head) {// 如果链表为空或者只有一个节点,无需排序if (head == null || head.next == null) {return head;}// 找到中间节点 head2,并断开 head2 与其前一个节点的连接// 比如 head=[4,2,1,3],那么 middleNode 调用结束后 head=[4,2] head2=[1,3]ListNode head2 = findMiddleNode(head);// 分治head = sortList(head);head2 = sortList(head2);// 合并return mergeTwoLists(head, head2);}// 快慢指针寻找链表中点,并将中点与前一个结点断开连接public ListNode findMiddleNode(ListNode head){ListNode fast = head, slow = head, pre = head;while(fast != null && fast.next != null){pre = slow;slow = slow.next;fast = fast.next.next;}pre.next = null;return slow;}// 合并两个有序列表public ListNode mergeTwoLists(ListNode head1, ListNode head2){ListNode dummy = new ListNode(-1), p = dummy;ListNode p1 = head1, p2 = head2;while(p1 != null && p2 != null){if(p1.val < p2.val){p.next = p1;p1 = p1.next;}else{p.next = p2;p2 = p2.next;}p = p.next;}if(p1 == null) p.next = p2;if(p2 == null) p.next = p1;return dummy.next;}
}
23. 合并 K 个升序链表
题目描述
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
核心思路
PriorityQueue -> 合并 k 个有序链表的逻辑类似合并两个有序链表,难点在于,如何快速得到 k 个节点中的最小节点,接到结果链表上?这里我们就要用到优先级队列这种数据结构,把链表节点放入一个最小堆,就可以每次获得 k 个节点中的最小节点。
题解代码
class Solution {public ListNode mergeKLists(ListNode[] lists) {ListNode dummy = new ListNode(-1), p = dummy;PriorityQueue<ListNode> q = new PriorityQueue<>((a,b) -> (a.val - b.val));// 将 K 个链表的头节点加入优先级队列for(ListNode head : lists){if(head != null){q.add(head);}}while(!q.isEmpty()){// 获取最小节点,接到结果链表中ListNode cur = q.poll();p.next = cur;p = p.next;if(cur.next != null){q.add(cur.next);}}return dummy.next;}
}
146. LRU 缓存
题目描述
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
LRUCache(int capacity)以 正整数 作为容量capacity初始化 LRU 缓存int get(int key)如果关键字key存在于缓存中,则返回关键字的值,否则返回-1。void put(int key, int value)如果关键字key已经存在,则变更其数据值value;如果不存在,则向缓存中插入该组key-value。如果插入操作导致关键字数量超过capacity,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
核心思路
要让 put 和 get 方法的时间复杂度为 O(1),可以总结出 cache 这个数据结构必要的条件:
1、显然 cache 中的元素必须有时序,以区分最近使用的和久未使用的数据,当容量满了之后要删除最久未使用的那个元素腾位置。
2、我们要在 cache 中快速找某个 key 是否已存在并得到对应的 val;
3、每次访问 cache 中的某个 key,需要将这个元素变为最近使用的,也就是说 cache 要支持在任意位置快速插入和删除元素。
哈希表查找快,但是数据无固定顺序;链表有顺序之分,插入删除快,但是查找慢,所以结合二者的长处,可以形成一种新的数据结构:哈希链表 LinkedHashMap:
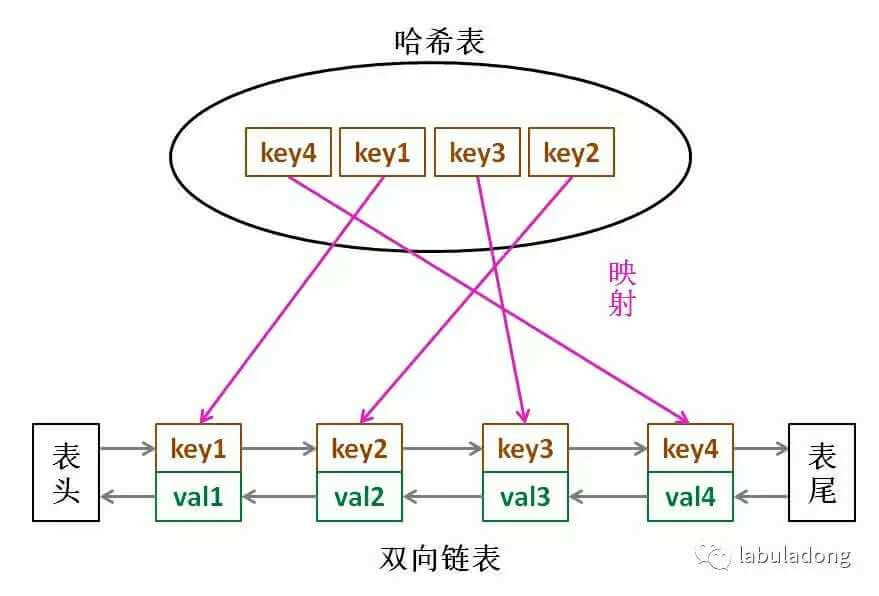
put 和 get 的具体逻辑,可以画出这样一个流程图:
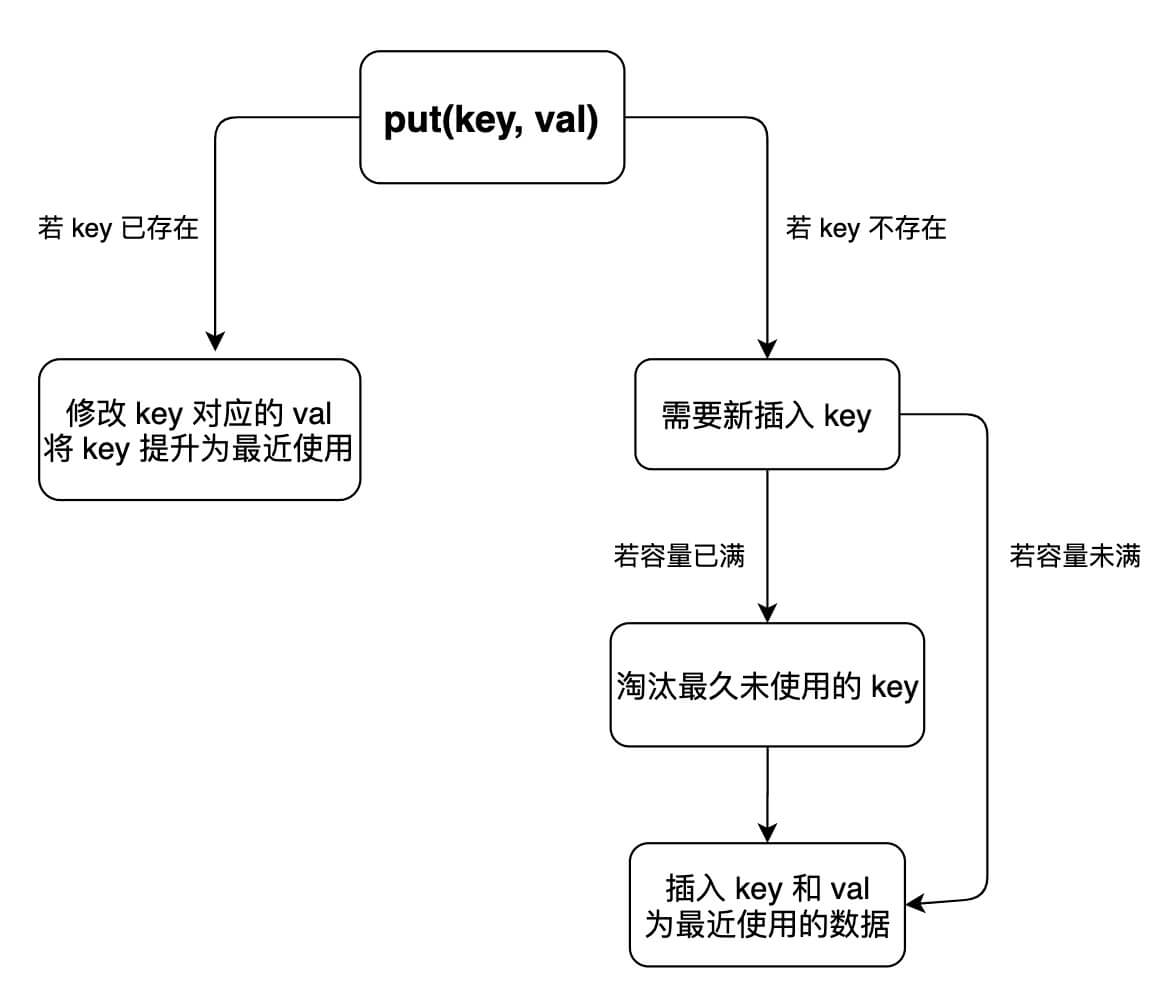
题解代码
class LRUCache {int cap;LinkedHashMap<Integer, Integer> cache = new LinkedHashMap<>();public LRUCache(int capacity) {this.cap = capacity;}public int get(int key) {if (!cache.containsKey(key)) {return -1;}// 将 key 变为最近使用makeRecently(key);return cache.get(key);}public void put(int key, int val) {if (cache.containsKey(key)) {// 修改 key 的值cache.put(key, val);// 将 key 变为最近使用makeRecently(key);return;}if (cache.size() >= this.cap) {// 链表头部就是最久未使用的 keyint oldestKey = cache.keySet().iterator().next();cache.remove(oldestKey);}// 将新的 key 添加链表尾部cache.put(key, val);}private void makeRecently(int key) {int val = cache.get(key);// 删除 key,重新插入到队尾cache.remove(key);cache.put(key, val);}
}
「二叉树」
94. 二叉树的中序遍历
题目描述
给定一个二叉树的根节点 root ,返回它的中序遍历。
核心思路
二叉树的 DFS 遍历模版。
/// 二叉树的遍历框架
void traverse(TreeNode root) {if (root == null) {return;}// 前序位置traverse(root.left);// 中序位置traverse(root.right);// 后序位置
}
题解代码
class Solution {List<Integer> res = new LinkedList<>();public List<Integer> inorderTraversal(TreeNode root) {traverse(root);return res;}public void traverse(TreeNode root){if(root == null){return;}traverse(root.left);res.add(root.val);traverse(root.right);}
}
时空分析
- 时间复杂度:(O(n))
- 空间复杂度:(O(h))
- 原因分析:
- 时间复杂度:
- 该代码实现了二叉树的中序遍历。在遍历过程中,每个节点都会被访问一次且仅一次。假设二叉树节点数为 n,每次访问节点时执行的操作(如添加节点值到结果列表)时间复杂度为常数 (O(1))。所以总的时间复杂度为 (O(n\times1)= O(n))。
- 空间复杂度:
- 空间复杂度主要来源于递归调用栈。在最坏情况下,二叉树是一条链,递归深度达到树的高度 (h = n),此时空间复杂度为 (O(n))。而在平衡二叉树中,树的高度 (h =\log n),空间复杂度为 (O(\log n))。一般情况下,空间复杂度取决于树的高度 h,因此空间复杂度为 (O(h))。这里不考虑存储结果
res所占用的空间,如果考虑res,其空间复杂度为 (O(n)),因为最终res会存储 n 个节点的值。但按照常规分析递归算法空间复杂度的方式,不把存储结果的空间计算在内,所以空间复杂度为 (O(h))。
104. 二叉树的最大深度
题目描述
给定一个二叉树 root ,返回其最大深度。
二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。
核心思路
递归(分解问题) -> 输入一个节点,返回以该节点为根的二叉树的最大深度。
题解代码
class Solution {// 定义:输入一个节点,返回以该节点为根的二叉树的最大深度public int maxDepth(TreeNode root) {if (root == null) {return 0;}int leftMax = maxDepth(root.left);int rightMax = maxDepth(root.right);// 根据左右子树的最大深度推出原二叉树的最大深度return 1 + Math.max(leftMax, rightMax);}
}
时空分析
- 时间复杂度:(O(n))
- 空间复杂度:(O(h))
- 原因分析:
- 时间复杂度:
- 此代码通过递归方式计算二叉树的最大深度。每个节点在递归过程中都会被访问一次,且仅一次。设二叉树的节点数为 n,每次访问节点执行的操作(如递归调用、比较等)时间复杂度为常数 (O(1))。所以整体时间复杂度为 (O(n\times1)= O(n))。
- 空间复杂度:
- 空间复杂度主要由递归调用栈的深度决定。在最坏情况下,二叉树为一条链,此时树的高度 (h = n),递归调用栈深度也为 n,空间复杂度为 (O(n))。对于平衡二叉树,树的高度 (h = \log n),递归调用栈深度为 (\log n),空间复杂度为 (O(\log n))。一般地,空间复杂度取决于树的高度 h,因此空间复杂度为 (O(h))。
226. 翻转二叉树
题目描述
给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。
核心思路
递归(分解问题)-> 把二叉树上的每个节点的左右子节点都交换一下。
题解代码
class Solution {// 定义:将以 root 为根的这棵二叉树翻转,返回翻转后的二叉树的根节点TreeNode invertTree(TreeNode root) {if (root == null) {return null;}// 利用函数定义,先翻转左右子树TreeNode left = invertTree(root.left);TreeNode right = invertTree(root.right);// 然后交换左右子节点root.left = right;root.right = left;// 和定义逻辑自恰:以 root 为根的这棵二叉树已经被翻转,返回 rootreturn root;}
}
101. 对称二叉树
题目描述
给你一个二叉树的根节点 root , 检查它是否轴对称。
核心思路
递归(分解问题) -> 判断两棵树是否镜像对称,只要判断两棵子树都是镜像对称的就行了。
题解代码
class Solution {public boolean isSymmetric(TreeNode root) {if (root == null) return true;// 检查两棵子树是否对称return check(root.left, root.right);}// 定义:判断输入的两棵树是否是镜像对称的boolean check(TreeNode left, TreeNode right) {if (left == null || right == null) {return left == right;}// 两个根节点需要相同if (left.val != right.val) return false;// 左右子树也需要镜像对称return check(left.right, right.left) && check(left.left, right.right);}
}
543. 二叉树的直径
题目描述
给你一棵二叉树的根节点,返回该树的 直径 。
二叉树的 直径 是指树中任意两个节点之间最长路径的 长度 。这条路径可能经过也可能不经过根节点 root 。
两节点之间路径的 长度 由它们之间边数表示。
核心思路
二叉树的直径,就是左右子树的最大深度之和 -> 在求最大深度时,运用二叉树的后序遍历,在 maxDepth 的后序遍历位置顺便计算最大直径。
题解代码
class Solution {int maxDiameter = 0;public int diameterOfBinaryTree(TreeNode root) {maxDepth(root);return maxDiameter;}int maxDepth(TreeNode root) {if (root == null) {return 0;}int leftMax = maxDepth(root.left);int rightMax = maxDepth(root.right);// 后序遍历位置顺便计算最大直径maxDiameter = Math.max(maxDiameter, leftMax + rightMax);return 1 + Math.max(leftMax, rightMax);}
}
102. 二叉树的层序遍历
题目描述
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
核心思路
二叉树 BFS 遍历模版。
void levelOrderTraverse(TreeNode root) {if (root == null) {return;}Queue<TreeNode> q = new LinkedList<>();q.offer(root);// 记录当前遍历到的层数(根节点视为第 1 层)int depth = 1;while (!q.isEmpty()) {int sz = q.size();for (int i = 0; i < sz; i++) {TreeNode cur = q.poll();// 访问 cur 节点,同时知道它所在的层数System.out.println("depth = " + depth + ", val = " + cur.val);// 把 cur 的左右子节点加入队列if (cur.left != null) {q.offer(cur.left);}if (cur.right != null) {q.offer(cur.right);}}depth++;}
}
题解代码
class Solution {public List<List<Integer>> levelOrder(TreeNode root) {List<List<Integer>> res = new LinkedList<>();if (root == null) {return res;}Queue<TreeNode> q = new LinkedList<>();q.offer(root);// while 循环控制从上向下一层层遍历while (!q.isEmpty()) {int sz = q.size();// 记录这一层的节点值List<Integer> level = new LinkedList<>();// for 循环控制每一层从左向右遍历for (int i = 0; i < sz; i++) {TreeNode cur = q.poll();level.add(cur.val);if (cur.left != null)q.offer(cur.left);if (cur.right != null)q.offer(cur.right);}res.add(level);}return res;}
}
108. 将有序数组转换为二叉搜索树
题目描述
给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 平衡 二叉搜索树。(平衡二叉树 是指该树所有节点的左右子树的高度相差不超过 1。)
核心思路
递归(分解问题)-> 二叉树的构建问题遵循固定的套路,构造整棵树可以分解成:先构造根节点,然后构建左右子树。一个有序数组对于 BST 来说就是中序遍历结果,根节点在数组中心,数组左侧是左子树元素,右侧是右子树元素。
题解代码
class Solution {public TreeNode sortedArrayToBST(int[] nums) {return build(nums, 0, nums.length - 1);}// 将闭区间 [left, right] 中的元素转化成 BST,返回根节点TreeNode build(int[] nums, int left, int right) {if (left > right) {// 区间为空return null;}// 构造根节点// BST 节点左小右大,中间的元素就是根节点int mid = (left + right) / 2;TreeNode root = new TreeNode(nums[mid]);// 递归构建左子树root.left = build(nums, left, mid - 1);// 递归构造右子树root.right = build(nums, mid + 1, right);return root;}
}
98. 验证二叉搜索树
题目描述
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
有效 二叉搜索树定义如下:
- 节点的左子树只包含 严格小于 当前节点的数。
- 节点的右子树只包含 严格大于 当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
核心思路
递归(分解问题)-> BST 左小右大的特性是指 root.val 要比左子树的所有节点都更大,要比右子树的所有节点都小。通过使用辅助函数,增加函数参数列表,在参数中携带额外信息,将这种约束传递给子树的所有节点。
题解代码
class Solution {public boolean isValidBST(TreeNode root) {return isValidBST(root, null, null);}// 限定以 root 为根的子树节点必须满足 max.val > root.val > min.valboolean isValidBST(TreeNode root, TreeNode min, TreeNode max) {// base caseif (root == null) return true;// 若 root.val 不符合 max 和 min 的限制,说明不是合法 BSTif (min != null && root.val <= min.val) return false;if (max != null && root.val >= max.val) return false;// 限定左子树的最大值是 root.val,右子树的最小值是 root.valreturn isValidBST(root.left, min, root)&& isValidBST(root.right, root, max);}
}
230. 二叉搜索树中第 K 小的元素
题目描述
给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 小的元素(从 1 开始计数)。
核心思路
递归(遍历)-> BST 的中序遍历结果是有序的(升序),所以用一个外部变量记录中序遍历结果第 k 个元素即是第 k 小的元素。
题解代码
class Solution {public int kthSmallest(TreeNode root, int k) {// 利用 BST 的中序遍历特性traverse(root, k);return res;}// 记录结果int res = 0;// 记录当前元素的排名int rank = 0;void traverse(TreeNode root, int k) {if (root == null) {return;}traverse(root.left, k);// 中序代码位置rank++;if (k == rank) {// 找到第 k 小的元素res = root.val;return;}traverse(root.right, k);}
}
199. 二叉树的右视图
题目描述
给定一个二叉树的 根节点 root,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。
核心思路
BFS 层序遍历 -> 每一层的最后一个节点就是二叉树的右侧视图。我们可以把 BFS 反过来,从右往左遍历每一行,进一步提升效率。
题解代码
class Solution {public List<Integer> rightSideView(TreeNode root) {List<Integer> res = new LinkedList<>();if(root == null) return res;Queue<TreeNode> q = new LinkedList<>();q.offer(root);while(!q.isEmpty()){int sz = q.size();TreeNode last = q.peek();for(int i = 0; i < sz; i++){TreeNode cur = q.poll();if(cur.right != null){q.offer(cur.right);}if(cur.left != null){q.offer(cur.left);}}res.add(last.val);}return res;}
}
114. 二叉树展开为链表
题目描述
给你二叉树的根结点 root ,请你将它展开为一个单链表:
- 展开后的单链表应该同样使用
TreeNode,其中right子指针指向链表中下一个结点,而左子指针始终为null。 - 展开后的单链表应该与二叉树 先序遍历 顺序相同。
核心思路
递归(分解问题)-> 递归函数 flatten 的定义:给 flatten 函数输入一个节点 root,那么以 root 为根的二叉树就会被拉平为一条链表。
如何利用这个定义来完成算法?想想怎么把以 root 为根的二叉树拉平为一条链表?很简单,以下流程:
1、将 root 的左子树和右子树拉平。
2、将 root 的右子树接到左子树下方,然后将整个左子树作为右子树。
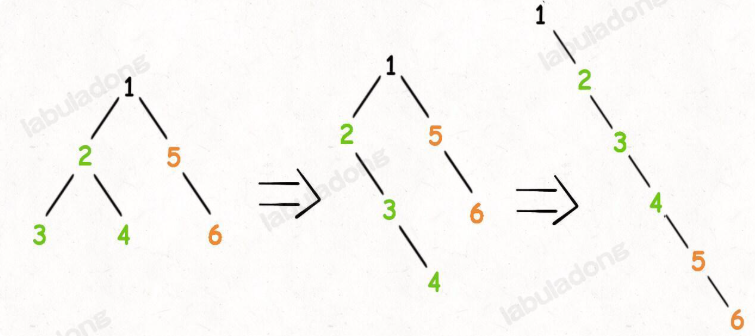
题解代码
class Solution {// 定义:将以 root 为根的树拉平为链表public void flatten(TreeNode root) {// base caseif (root == null) return;// 先递归拉平左右子树flatten(root.left);flatten(root.right);// ***后序遍历位置***// 1、左右子树已经被拉平成一条链表TreeNode left = root.left;TreeNode right = root.right;// 2、将左子树作为右子树root.left = null;root.right = left;// 3、将原先的右子树接到当前右子树的末端TreeNode p = root;while (p.right != null) {p = p.right;}p.right = right;}
}
105. 从前序与中序遍历序列构造二叉树
题目描述
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的 先序遍历, inorder 是同一棵树的 中序遍历,请构造二叉树并返回其根节点。
核心思路
构造二叉树,第一件事一定是找根节点,然后想办法构造左右子树。
二叉树的前序和中序遍历结果的特点如下:
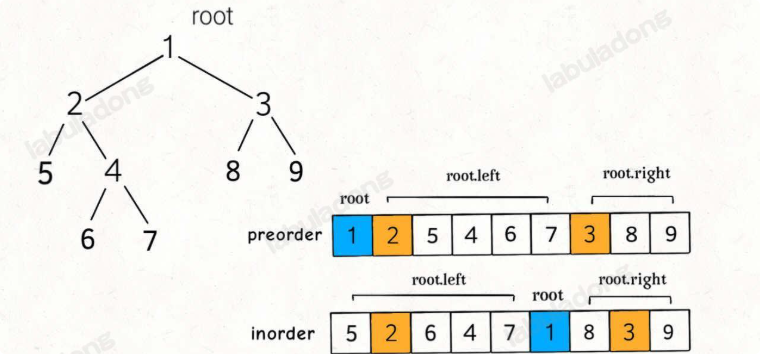
前序遍历结果第一个就是根节点的值,然后再根据中序遍历结果确定左右子树的节点。
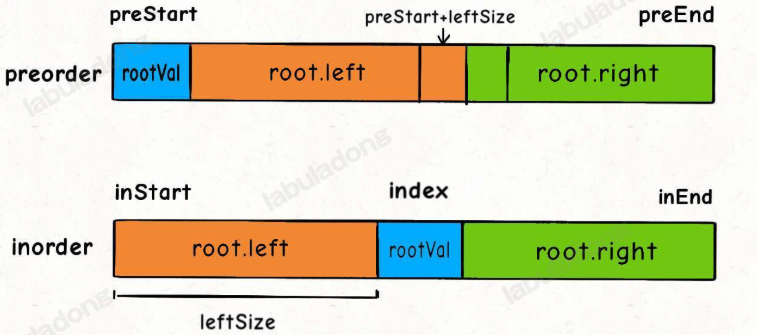
题解代码
class Solution {// 存储 inorder 中值到索引的映射HashMap<Integer, Integer> valToIndex = new HashMap<>();public TreeNode buildTree(int[] preorder, int[] inorder) {for (int i = 0; i < inorder.length; i++) {valToIndex.put(inorder[i], i);}return build(preorder, 0, preorder.length - 1,inorder, 0, inorder.length - 1);}// 定义:前序遍历数组为 preorder[preStart..preEnd]// 中序遍历数组为 inorder[inStart..inEnd]// 构造这个二叉树并返回该二叉树的根节点TreeNode build(int[] preorder, int preStart, int preEnd,int[] inorder, int inStart, int inEnd) {if (preStart > preEnd) {return null;}// root 节点对应的值就是前序遍历数组的第一个元素int rootVal = preorder[preStart];// rootVal 在中序遍历数组中的索引int index = valToIndex.get(rootVal);int leftSize = index - inStart;// 先构造出当前根节点TreeNode root = new TreeNode(rootVal);// 递归构造左右子树root.left = build(preorder, preStart + 1, preStart + leftSize,inorder, inStart, index - 1);root.right = build(preorder, preStart + leftSize + 1, preEnd,inorder, index + 1, inEnd);return root;}
}
437. 路径总和 III
题目描述
给定一个二叉树的根节点 root ,和一个整数 targetSum ,求该二叉树里节点值之和等于 targetSum 的 路径 的数目。
路径 不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点)。
核心思路
递归(遍历) + 前缀和 + HashMap -> 这道题与 560. 和为 K 的子数组 思想类似答题步骤:
- 求前缀和
- 查看 HashMap(定义为:preSumToCount) 中是否有
preSum-target的 key,有则加上对应的 count。 - 将该 preSum 放入到 HashMap 中,并更新 count 次数。
note:数据大小,preSum 应该定义为 long 类型。
题解代码
class Solution {// 记录前缀和// 定义:从二叉树的根节点开始,路径和为 pathSum 的路径有 preSumCount.get(pathSum) 个HashMap<Long, Integer> preSumCount = new HashMap<>();long pathSum, targetSum;int res = 0;public int pathSum(TreeNode root, int targetSum) {if (root == null) {return 0;}this.pathSum = 0;this.targetSum = targetSum;this.preSumCount.put(0L, 1);traverse(root);return res;}void traverse(TreeNode root) {if (root == null) {return;}// 前序遍历位置pathSum += root.val;// 从二叉树的根节点开始,路径和为 pathSum - targetSum 的路径条数// 就是路径和为 targetSum 的路径条数res += preSumCount.getOrDefault(pathSum - targetSum, 0);// 记录从二叉树的根节点开始,路径和为 pathSum 的路径条数preSumCount.put(pathSum, preSumCount.getOrDefault(pathSum, 0) + 1);traverse(root.left);traverse(root.right);// 后序遍历位置preSumCount.put(pathSum, preSumCount.get(pathSum) - 1);pathSum -= root.val;}
}
236. 二叉树的最近公共祖先
题目描述
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科 中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
核心思路
递归(分解问题) -> 最近公共祖先模板
递归函数的定义:给该函数输入三个参数 root,p,q,它会返回一个节点:
情况 1,如果 p 和 q 都在以 root 为根的树中,函数返回的即使 p 和 q 的最近公共祖先节点。
情况 2,那如果 p 和 q 都不在以 root 为根的树中怎么办呢?函数理所当然地返回 null 呗。
情况 3,那如果 p 和 q 只有一个存在于 root 为根的树中呢?函数就会返回那个节点。
// 定义:在以 root 为根的二叉树中寻找值为 val1 或 val2 的节点
TreeNode find(TreeNode root, int val1, int val2) {// base caseif (root == null) {return null;}// 前序位置,看看 root 是不是目标值if (root.val == val1 || root.val == val2) {return root;}// 去左右子树寻找TreeNode left = find(root.left, val1, val2);TreeNode right = find(root.right, val1, val2);// 后序位置,已经知道左右子树是否存在目标值return left != null ? left : right;
}
题解代码
class Solution {public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {return find(root, p.val, q.val);}public TreeNode find(TreeNode root, int val1, int val2){if(root == null) return null;if(root.val == val1 || root.val == val2) return root;TreeNode left = find(root.left, val1, val2);TreeNode right = find(root.right, val1, val2);if(left != null && right != null){return root;}return left != null ? left : right;}
}
124. 二叉树中的最大路径和
题目描述
二叉树中的 路径 被定义为一条节点序列,序列中每对相邻节点之间都存在一条边。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经过根节点。
路径和 是路径中各节点值的总和。
给你一个二叉树的根节点 root ,返回其 最大路径和 。
核心思路
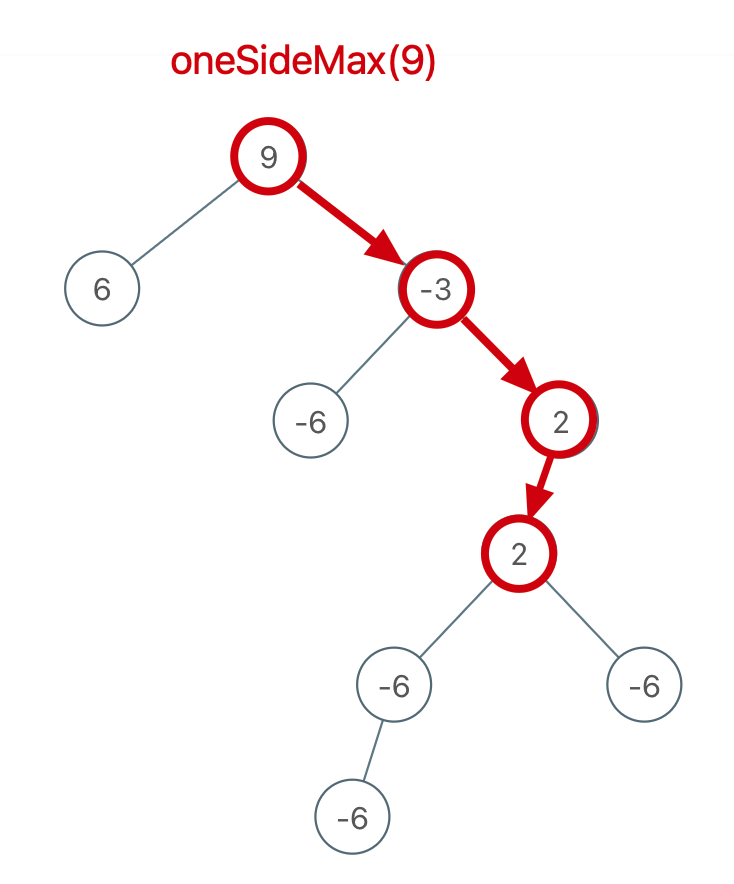
递归(分解问题) -> 分解问题的思想:定义一个 oneSideMax 函数来计算从根节点 root 为起点的最大单边路径和。oneSideMax 函数和 maxDepth 函数原理类似,只不过 maxDepth 计算最大深度,oneSideMax 计算「单边」最大路径和。然后在计算单边路径和时顺便计算最大路径和。(后序遍历位置)
题解代码
class Solution {int res = Integer.MIN_VALUE;public int maxPathSum(TreeNode root) {if (root == null) {return 0;}// 计算单边路径和时顺便计算最大路径和oneSideMax(root);return res;}// 定义:计算从根节点 root 为起点的最大单边路径和int oneSideMax(TreeNode root) {if (root == null) {return 0;}int leftMaxSum = Math.max(0, oneSideMax(root.left));int rightMaxSum = Math.max(0, oneSideMax(root.right));// 后序遍历位置,顺便更新最大路径和int pathMaxSum = root.val + leftMaxSum + rightMaxSum;res = Math.max(res, pathMaxSum);// 实现函数定义,左右子树的最大单边路径和加上根节点的值// 就是从根节点 root 为起点的最大单边路径和return Math.max(leftMaxSum, rightMaxSum) + root.val;}
}
🐮🐴