仓颉标准库std源码深度解析:构建全场景智能应用的基石
仓颉标准库std源码深度解析:构建全场景智能应用的基石
目录
仓颉标准库(std)源码深度解析:构建全场景智能应用的基石
1. 引言:仓颉与标准库的战略意义
2. 源码获取与项目结构概览
3. 核心基石:std.core 包深度解析
3.1 内置类型系统
3.2 基础操作与异常处理
4. 文件与I/O系统:std.fs 与 std.io
4.1 std.fs:文件系统操作
4.2 std.io:通用输入输出
5. 并发编程利器:std.sync 包
5.1 核心同步原语详解
5.2 协程与通道:更高层次的并发抽象
6. 动态能力之源:std.reflect 反射包
6.1 反射API核心组件
6.2 反射的典型应用场景
7. 生态融合桥梁:std.ffi.python 互操作包
7.1 工作原理
8. 开发者工具箱:std.unittest 与 std.format
8.1 std.unittest:单元测试框架
8.2 std.format:强大的格式化能力
9.核心包能力对比与选型指南
10. 总结与展望
参考链接
摘要:本文深入剖析华为仓颉编程语言(Cangjie)的标准库(std)源码架构与核心实现。文章基于官方开源仓库 cangjie_runtime,系统拆解了 std.core、std.fs、std.sync、std.reflect 等关键包的设计哲学、API 接口与底层逻辑,并结合代码示例展示了其在文件操作、并发控制、反射及 Python 互操作等场景的应用。通过本文,开发者可全面掌握仓颉标准库的精髓,为构建高性能、高安全的全场景智能应用奠定坚实基础。
1. 引言:仓颉与标准库的战略意义
仓颉编程语言(Cangjie)作为华为面向“全场景智能”时代推出的新一代通用编程语言,其核心使命是兼顾开发效率与运行性能,为鸿蒙生态乃至更广泛的智能设备提供强大的编程支撑。在这一宏大愿景中,标准库(Standard Library, std) 扮演着至关重要的角色。它不仅是语言能力的延伸,更是连接开发者与底层系统、AI生态的桥梁。
一个强大、完备且高效的标准库,能够显著降低开发门槛,提升代码的可移植性和安全性。仓颉标准库的设计充分体现了其“原生智能化、天生全场景、高性能、强安全”的理念。本文旨在通过对仓颉标准库源码的细致拆解,揭示其内部架构与实现细节,帮助开发者从“会用”走向“精通”。
2. 源码获取与项目结构概览
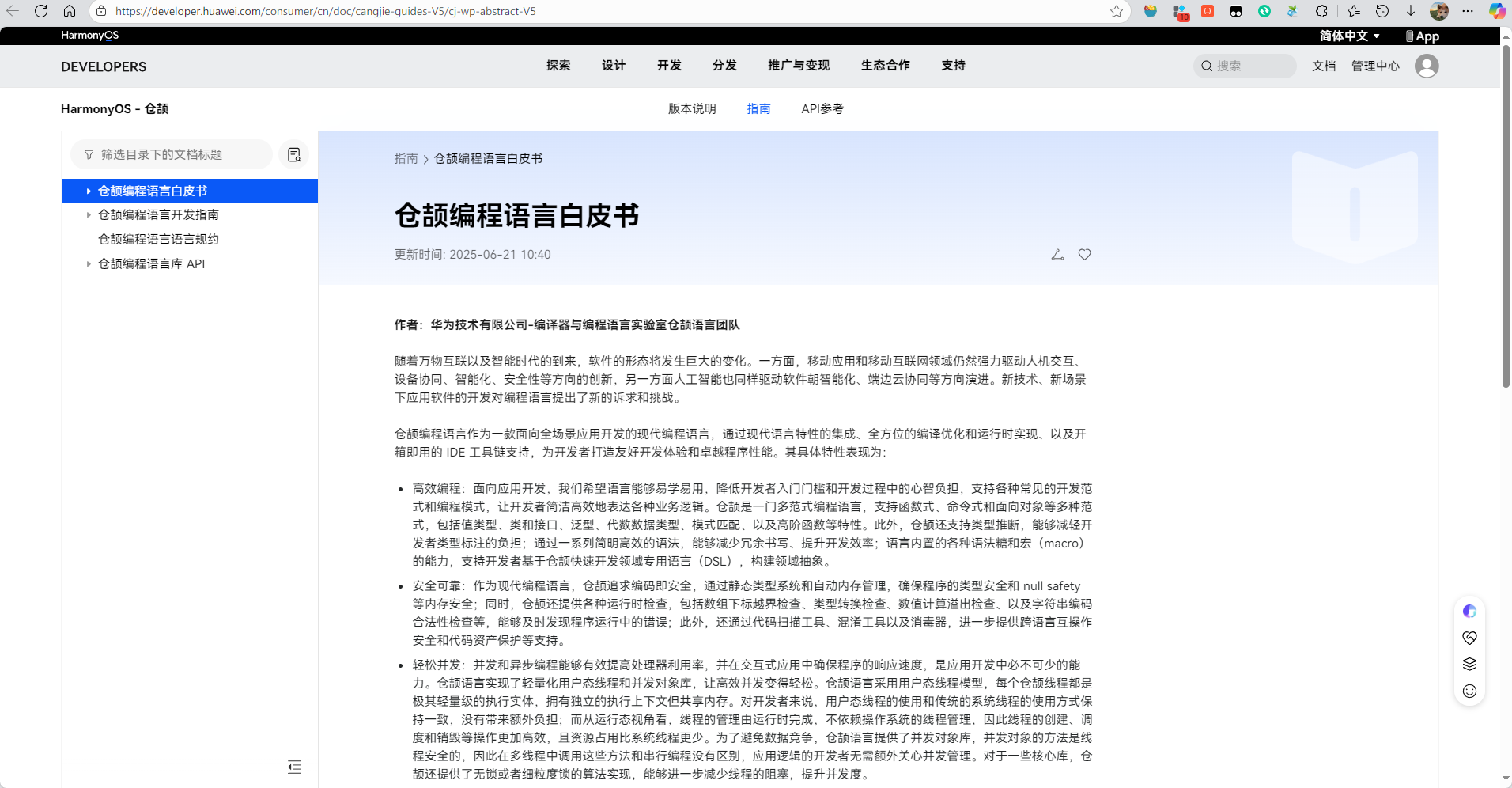
仓颉编程语言及其标准库已于2025年7月正式开源,其核心组件托管在 GitCode 平台上。标准库与运行时(Runtime)共同构成了 cangjie_runtime 项目 。
- 官方仓库地址:
https://gitcode.com/Cangjie/cangjie_runtime
仓颉运行时和仓颉编程语言标准库的源码,整体的架构图如下图所示:

三方库的使用方式
libboundscheck的使用主体是仓颉运行时和仓颉编程语言标准库,使用方式是源码依赖,会编译集成到二进制发布包中。OpenSSL的使用主体是仓颉运行时,使用方式是动态链接系统中动态库,不依赖源码。PCRE2的使用主体是标准库regex,使用方式是源码依赖,会编译集成到二进制发布包中。flatbuffers的使用主体是标准库ast,使用方式是源码依赖,会编译集成到二进制发布包中。
克隆仓库后,我们可以看到其基本目录结构:
/cangjie_runtime
├── runtime
│ ├── build # 构建脚本
│ └── src
│ ├── Base # 日志等基础能力模块
│ ├── CJThread # 仓颉线程管理模块
│ ├── Common # 通用模块
│ ├── Concurrency # 并发管理模块
│ ├── CpuProfiler # CPU 采集工具
│ ├── Demangler # 符号去混淆工具
│ ├── Exception # 异常处理模块
│ ├── Heap # 内存管理模块
│ ├── Inspector # DFX 工具
│ ├── Loader # 加载器
│ ├── Mutator # GC 与业务线程状态同步模块
│ ├── ObjectModel # 对象模型
│ ├── Signal # 信号管理模块
│ ├── StackMap # 回栈元数据分析模块
│ ├── Sync # 同步原语实现模块
│ ├── UnwindStack # 回栈模块
│ ├── Utils # 工具类
│ ├── arch # 硬件平台适配代码
│ └── os # 软件平台适配代码
└── stdlib此结构清晰地展示了标准库的模块化设计,每个功能包都拥有独立的目录,便于维护和扩展。
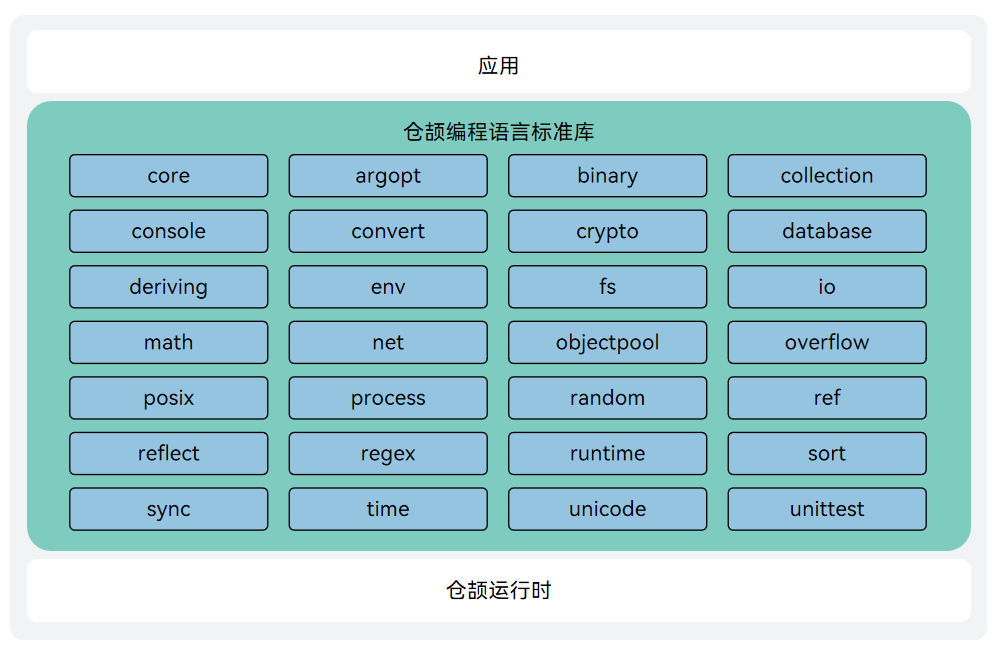
仓颉标准库的架构图如下所示:
3. 核心基石:std.core 包深度解析
std.core 是整个标准库的基石,它定义了仓颉语言最基础的数据类型、操作符和运行时行为。所有其他包都直接或间接地依赖于 core。
3.1 内置类型系统
core 包中定义了仓颉的所有内置类型,如 Int8, Int32, UInt64, Float64, Bool, String 等。这些类型不仅是语言的语法糖,更是与底层运行时紧密集成的高效数据结构。
3.2 基础操作与异常处理
该包还提供了基础的算术、逻辑、比较操作的实现,以及异常(Exception)处理机制的核心定义。例如,一个简单的整数加法操作,在底层会调用 core 包中经过高度优化的函数。
代码示例:core 包的隐式使用
// 无需显式导入 std.core
func main() {let a: Int32 = 10;let b: Int32 = 20;let sum = a + b; // 使用了 core 包定义的 Int32 加法操作console.println("Sum: ${sum}");
}4. 文件与I/O系统:std.fs 与 std.io
高效的文件和I/O操作是任何通用编程语言的必备能力。仓颉通过 std.fs 和 std.io 两个包提供了完整的解决方案。
4.1 std.fs:文件系统操作
std.fs 包封装了对文件、目录、路径和元数据的操作。其API设计简洁直观。
代码示例:文件读写
import std.fs;func main() {let filePath = "example.txt";// 写入文件fs.writeFile(filePath, "Hello, Cangjie!");// 读取文件let content = fs.readFile(filePath);console.println("File content: ${content}");// 检查文件是否存在if (fs.exists(filePath)) {console.println("File exists!");}
}4.2 std.io:通用输入输出
std.io 提供了更底层的流(Stream)抽象,用于处理来自网络、文件或内存的数据流。它定义了 Reader 和 Writer 接口,是构建更复杂I/O应用的基础。
5. 并发编程利器:std.sync 包
在现代软件开发中,并发与并行处理能力已成为衡量一门语言是否“现代化”的关键指标。仓颉语言通过其 std.sync 包,为开发者提供了一套强大而安全的并发原语,使其能够轻松编写高性能、高响应性的应用程序。
5.1 核心同步原语详解
std.sync 包的核心在于其对底层操作系统线程模型的高效封装,提供了多种同步机制以应对不同场景的需求。
Mutex(互斥锁):这是最基础的同步工具,用于保护临界区(Critical Section),确保同一时间只有一个线程可以访问共享资源。仓颉的Mutex是可重入的(Reentrant),这意味着同一个线程可以多次获取同一个锁而不会导致死锁,这在递归调用等场景中非常有用。Atomic(原子操作):对于简单的计数器或标志位,使用锁会带来不必要的性能开销。std.sync提供了AtomicInt32、AtomicBool等原子类型,其底层利用 CPU 的 CAS(Compare-And-Swap)指令实现无锁(Lock-Free)的并发操作,性能极高。CondVar(条件变量):条件变量通常与互斥锁配合使用,用于线程间的等待/通知机制。一个线程可以在某个条件不满足时进入等待状态,直到另一个线程改变了条件并发出通知。
代码示例:使用 AtomicInt32 实现无锁计数器
import std.sync;
import std.thread;// 使用原子整数,无需锁
let atomicCounter = sync.AtomicInt32(0);func worker(id: Int32) {for _ in 0..1000 {atomicCounter.increment(); // 原子自增}console.println("Worker ${id} finished.");
}func main() {let workers = [];for i in 0..4 {workers.append(thread.spawn(() -> worker(i)));}for w in workers {w.join();}// 期望输出 4000console.println("Final atomic counter: ${atomicCounter.load()}");
}5.2 协程与通道:更高层次的并发抽象
除了传统的基于线程和锁的并发模型,仓颉语言还拥抱了更现代的并发范式——协程(Coroutine)与通道(Channel)。虽然协程调度可能由运行时管理,但 std.sync 包中的 Channel 是实现协程间通信的官方推荐方式。
Channel 提供了一种类型安全、无锁的通信机制,遵循“不要通过共享内存来通信,而要通过通信来共享内存”(Do not communicate by sharing memory; instead, share memory by communicating)的哲学。这极大地简化了并发程序的设计,并减少了死锁和数据竞争的风险。
代码示例:使用 Channel 进行生产者-消费者通信
import std.sync;
import std.thread;func producer(ch: sync.Channel[Int32]) {for i in 1..6 {ch.send(i); // 发送数据thread.sleep(100); // 模拟工作}ch.close(); // 关闭通道,通知消费者结束
}func consumer(ch: sync.Channel[Int32]) {while (true) {let result = ch.receive(); // 接收数据if (result.isClosed()) {break; // 通道已关闭,退出循环}console.println("Received: ${result.value()}");}
}func main() {let ch = sync.Channel[Int32](); // 创建一个Int32类型的通道let p = thread.spawn(() -> producer(ch));let c = thread.spawn(() -> consumer(ch));p.join();c.join();
}6. 动态能力之源:std.reflect 反射包
静态类型语言通常以性能和安全性见长,但有时会牺牲一定的灵活性。仓颉语言通过 std.reflect 包巧妙地引入了反射(Reflection)机制,在保持其静态类型优势的同时,赋予了程序在运行时“自省”和“自修改”的能力。
6.1 反射API核心组件
std.reflect 包提供了一套完整的API,允许开发者在运行时探索和操作程序的结构。
Type类:这是反射的入口点。通过reflect.typeOf(instance)或reflect.typeFromName("ClassName")可以获取到任何类型的元数据对象。Type对象包含了该类型的所有信息,如名称、字段列表、方法列表、继承关系等。Field与Method类:从Type对象中可以获取到具体的Field(字段)和Method(方法)对象。这些对象不仅包含名称和类型信息,还提供了get/set(对于字段)和invoke(对于方法)等操作,允许动态地读写字段值和调用方法。Value类:这是一个通用的包装器,可以持有任何类型的值。它是连接静态世界和动态世界的桥梁,许多反射操作的输入和输出都是Value类型。
代码示例:动态创建对象并设置字段
import std.reflect;class Person {var name: String = "";var age: Int32 = 0;func introduce(): String {return "Hi, I'm ${this.name}, ${this.age} years old.";}
}func main() {// 1. 获取 Person 类型let personType = reflect.typeFromName("Person");// 2. 动态创建 Person 实例let personValue = personType.newInstance();let personObj = personValue.as[Person](); // 转换回具体类型(可选)// 3. 动态设置字段let nameField = personType.getField("name");nameField.set(personValue, reflect.Value.fromString("Alice"));let ageField = personType.getField("age");ageField.set(personValue, reflect.Value.fromInt32(30));// 4. 验证结果console.println(personObj.introduce()); // 输出: Hi, I'm Alice, 30 years old.
}6.2 反射的典型应用场景
反射虽然强大,但因其在运行时解析类型信息,通常会带来一定的性能开销,因此应谨慎使用。其主要应用场景包括:
- 序列化/反序列化(Serialization/Deserialization):JSON、XML、Protobuf 等数据格式的解析器和生成器,需要在不知道具体类型的情况下,遍历对象的字段并进行读写。反射是实现这类通用库的核心技术。
- 依赖注入(Dependency Injection, DI)框架:DI框架需要在程序启动时,根据配置动态地创建对象并注入其依赖。这通常需要通过反射来实例化类并设置其属性。
- 对象关系映射(ORM):ORM框架将数据库表记录映射为程序中的对象。在执行查询时,框架需要动态地将数据库行的数据填充到新创建的对象实例中,这同样离不开反射。
- 通用工具函数:例如,一个通用的
deepCopy(深拷贝)函数或equals(深度比较)函数,需要能够处理任意类型的对象,反射是实现这种通用性的关键。
通过 std.reflect,仓颉语言成功地在静态与动态之间找到了一个优雅的平衡点,极大地增强了其在构建复杂框架和通用库方面的能力。
7. 生态融合桥梁:std.ffi.python 互操作包
仓颉语言的一大亮点是其对AI和数据科学生态的拥抱。std.ffi.python 包通过外部函数接口(FFI),实现了与 Python 的无缝互操作,让开发者可以直接在仓颉代码中调用 NumPy、Pandas、PyTorch 等强大的Python库。
7.1 工作原理
该包在底层通过 CPython API 与 Python 解释器进行通信,将仓颉的数据类型自动转换为 Python 对象,反之亦然。
代码示例:调用 Python 的 math 模块
import std.ffi.python;func main() {// 初始化 Python 环境python.init();// 获取 Python 的 math 模块let mathModule = python.importModule("math");// 调用 math.sqrt 函数let sqrtFunc = mathModule.getAttr("sqrt");let result = sqrtFunc.call([16.0]);console.println("Square root of 16 is: ${result}");// 清理 Python 环境python.finalize();
}这一能力极大地扩展了仓颉的应用边界,使其能够轻松融入现有的AI工作流。
8. 开发者工具箱:std.unittest 与 std.format
一个优秀的标准库不仅提供运行时能力,还应包含提升开发效率的工具。
8.1 std.unittest:单元测试框架
std.unittest 是一个功能完备的单元测试框架,支持测试用例的组织、断言、Mock以及测试结果的报告。
代码示例:编写单元测试
import std.unittest;func add(a: Int32, b: Int32): Int32 {return a + b;
}class TestMath extends unittest.TestCase {func testAdd() {this.assertEqual(add(2, 3), 5);this.assertEqual(add(-1, 1), 0);}
}func main() {unittest.main();
}8.2 std.format:强大的格式化能力
std.format 包提供了类似 Python f-string 或 C# string interpolation 的格式化功能,通过 Formatter 接口,任何类型都可以自定义其字符串表示。
代码示例:自定义格式化
import std.format;class Point {let x: Int32;let y: Int32;func new(x: Int32, y: Int32) {this.x = x;this.y = y;}// 实现 Formatter 接口func format(f: format.Formatter) {f.write("Point(${this.x}, ${this.y})");}
}func main() {let p = Point(3, 4);console.println("The point is: ${p}"); // 输出: Point(3, 4)
}9.核心包能力对比与选型指南
为了帮助开发者更好地理解和选择合适的工具,下表对仓颉标准库中几个核心包的关键特性进行了对比:
| 包名 (Package) | 主要用途 | 核心组件 | 适用场景 | 性能考量 |
|
| 语言基础 | 内置类型、基础操作符 | 所有程序 | 极高,无额外开销 |
|
| 文件系统操作 |
| 文件读写、日志、配置管理 | I/O密集型,受磁盘/网络速度影响 |
|
| 并发与同步 |
| 多线程、高性能服务、并行计算 |
|
|
| 运行时自省 |
| 框架开发、序列化、通用工具 | 较高开销,应避免在热路径中使用 |
|
| Python互操作 |
| AI/ML、数据分析、调用现有Python库 | 极高开销,涉及跨语言调用和数据转换 |
选型建议:对于性能敏感的代码路径,应优先考虑 std.core 和 std.sync 中的原子操作;对于需要灵活性的框架代码,std.reflect 是不二之选;而当需要快速集成AI能力时,std.ffi.python 提供了无与伦比的便利性。
10. 总结与展望
通过对仓颉标准库源码的系统性拆解,我们可以清晰地看到其设计之精妙与功能之完备。从 std.core 的坚实基础,到 std.fs/std.io 的I/O能力,再到 std.sync 的并发支持、std.reflect 的动态特性,以及革命性的 std.ffi.python 互操作能力,仓颉标准库为开发者构建现代应用提供了全方位的武器库。
仓颉标准库不仅是功能的集合,更是其“全场景智能”理念的具象化体现。它平衡了性能、安全与易用性,并积极拥抱外部生态。随着仓颉语言的持续演进和社区的壮大(如 Cangjie-TPC 三方库计划 ),我们有理由相信,其标准库将变得更加丰富和强大,成为驱动下一代智能应用创新的核心引擎。
参考链接
- 仓颉编程语言官方仓库 (
cangjie_runtime): https://gitcode.com/Cangjie/cangjie_runtime - 仓颉编程语言官方文档: https://cangjie-lang.org/std
- 《跟老卫学仓颉编程语言开发》: https://github.com/waylau/cangjie-programming
- 仓颉编程语言白皮书: https://cangjie-lang.cn/whitepaper
标签: 仓颉, Cangjie, 标准库, 源码分析, 编程语言