小杰-自然语言处理(four)——transformer系列——注意力机制
注意力机制
种注意力形式及核心逻辑:
- 加性注意力:通过神经网络计算相似度,适应不同维度向量,灵活性高。
- 点积注意力:直接算查询向量与键向量的点积,点积越大相似度越高,计算高效。
- 缩放点积注意力:点积除以键向量维度平方根,避免高维下数值过大,Transformer 核心组件。
1.2.1 加性注意力
加性注意力是注意力机制的一种形式,它通过计算两个输入向量的相似度来确定权重。对于给定的查询向量 q、键向量 k,加性注意力分数的计算过程如下:
![]()


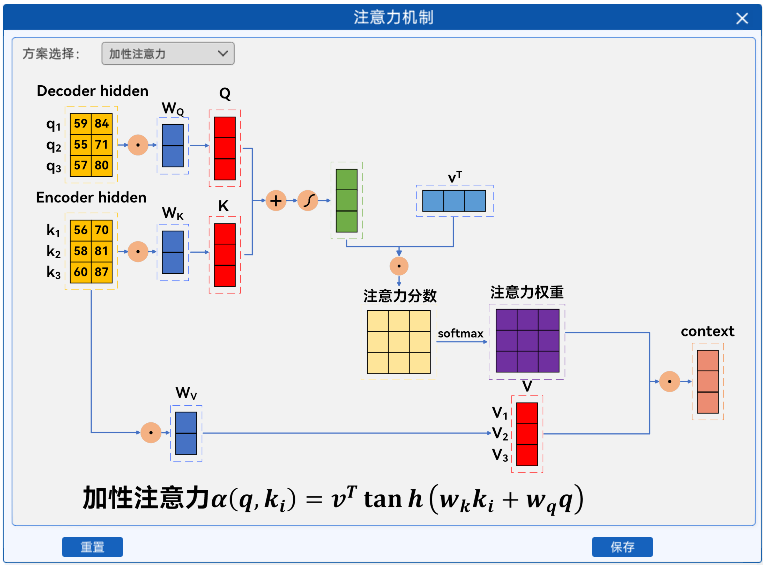
代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F#加性注意力类
class AdditiveAttention(nn.Module):def __init__(self,hidden_dim):"""hidden_dim:"""super(AdditiveAttention,self).__init__()#线性变换矩阵 q kself.w_q=nn.Linear(hidden_dim,1)self.w_k=nn.Linear(hidden_dim,1)#权重向量v^Tself.v=nn.Linear(hidden_dim,1)def forward(self,q,k,v):Q=self.w_q(q) #[batch_size,q_num,hidden_dim]K=self.w_k(k) #[batch_size,k_num,hidden_dim]V=self.v(v)#2,加性计算sum_qk=Q+Ktanh_out=torch.tanh(sum_qk)# 3.与v^T相乘,计算注意力分数random_input = torch.randn(q.size(0),q.size(1), q.size(2))v_t=self.v(random_input)score= torch.bmm(tanh_out,v_t.transpose(1,2))# 4. softmax 归一化权重atten_weight=F.softmax(score,dim=-1)#维度归一化# 5. 权重与 V 加权求和,得到 contextcontext=torch.bmm(atten_weight,V)# [batch_size, q_num, hidden_dim]return context# 模拟输入(batch_size=1,简化维度)
q=torch.tensor([[[0.59,0.84], [0.55,0.71], [0.57,0.80]]], dtype=torch.float32)
k = torch.tensor([[[0.56,0.70], [0.58,0.81], [0.60,0.87]]], dtype=torch.float32)
v = k
#计算加性注意力
atten=AdditiveAttention(hidden_dim=2)
context = atten(q, k, v)
print("上下文向量 context:\n", context.shape)
1.2.3 缩放点积注意力

作用:通过缩放因子平衡高维向量的点积结果,使 softmax 分布更平滑,提升训练稳定性。这是 Transformer 模型的核心创新之一。
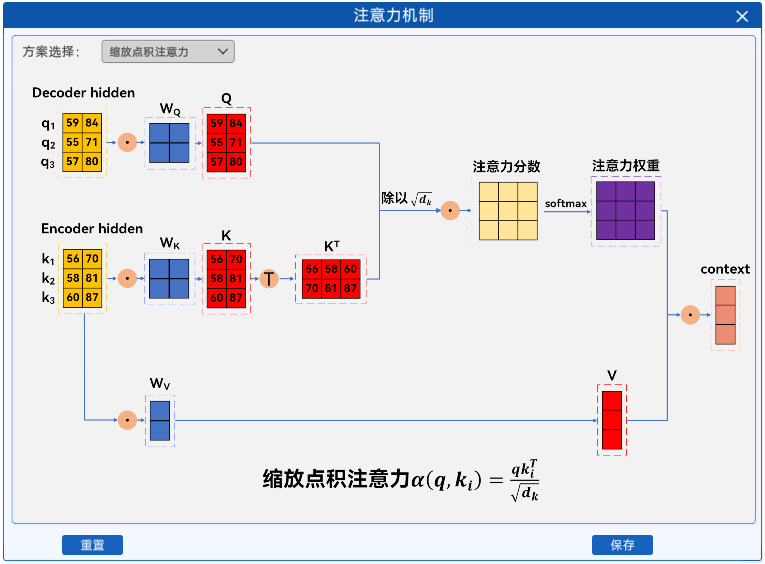
代码实现
import torch
import torch.nn.functional as Fclass ScaledDotProductAttention(torch.nn.Module):def __init__(self):super(ScaledDotProductAttention,self).__init__()self.V=torch.nn.Linear(2,1)def forward(self,Q,K,V):# 获取键向量的维度d_k = K.size(-1) # 即图示中的维度 d_k=2# 计算点积注意力分数:Q与K^T相乘scores=torch.bmm(Q,K.transpose(1,2))# 缩放点积:除以根号(d_k),防止梯度消失或爆炸scaled_scores = scores / torch.sqrt(torch.tensor(d_k, dtype=torch.float32))# 应用 softmax 计算注意力权重attention_weights = F.softmax(scaled_scores, dim=-1)# 权重与 V 相乘得到 contextV=self.V(V)context = torch.bmm(attention_weights, V)return context, attention_weightsq_before=torch.tensor([[[5.9, 8.4], [5.5, 7.1], [5.7, 8.0]]], dtype=torch.float32)
k_before = torch.tensor([[[5.6, 7.0], [5.8, 8.1], [6.0, 8.7]]], dtype=torch.float32)
# 线性变换(图示 Wq, Wk, Wv)
Wq = torch.randn((2, 2)) # 2×2 变换矩阵
Wk = torch.randn(2, 2)
Wv = torch.randn(2, 2)
Q=torch.bmm(q_before,Wq.unsqueeze(0).repeat(q_before.size(0),1,1))
K=torch.bmm(k_before,Wk.unsqueeze(0).repeat(k_before.size(0),1,1))
V = torch.bmm(k_before, Wv.unsqueeze(0).repeat(k_before.size(0), 1, 1))
#注意力模块并计算
attention = ScaledDotProductAttention()
context, attn_weights = attention(Q, K, V)print("缩放后的注意力权重矩阵:\n", attn_weights)
print("上下文向量 context:\n", context)