从0到1理解智能体模式
在 AI 技术从 “工具调用” 向 “自主决策” 演进的过程中,“智能体(Agent)” 已成为构建复杂系统的核心范式。然而,面对 “Agentic architectures”、“Agentic workflows” 等概念,很多开发者常陷入 “知道要做,但不知如何落地” 的困境。实际上,智能体的落地依赖于可复用的设计模式—— 这些模式如同 “蓝图”,将抽象的 “自主性” 转化为具体的代码逻辑。
本文将从 “工作流与智能体的本质区别” 切入,系统拆解 7 种核心模式(含 3 种工作流模式 + 4 种智能体模式),每个模式均配套Python示例代码与图例,帮助你从0到1理解并落地智能体系统。示例使用ollama启动本地大模型,具体安装方式参考官方文档(https://docs.ollama.com/)
一、工作流 vs 智能体
在深入模式前,必须明确一个核心区别:工作流(Workflow)是 “按剧本演戏”,智能体(Agent)是 “按目标决策”。
维度 | 工作流(Workflow) | 智能体(Agent) |
执行逻辑 | 预定义固定路径,步骤不可动态调整 | 基于目标自主决策,可灵活选择工具/步骤 |
核心优势 | 可预测性高、性能稳定、成本低 | 灵活性强、适配动态/模糊任务 |
适用场景 | 任务步骤明确(如 “数据提取→汇总”) | 任务复杂/多变(如 “规划旅行 + 订机票”) |
典型案例 | 固定流程的报表生成 | 多工具协作的智能客服 |
简单来说:如果能明确写出 “第一步做A,第二步做B”,优先用工作流;如果需要 “根据情况决定下一步做什么”,再用智能体。
二、3 种核心工作流模式:从 “固定流程” 入手
工作流是智能体的基础 —— 许多复杂智能体系统,本质是 “工作流 + 动态决策” 的组合。以下 3 种工作流模式是落地智能体的 “入门阶梯”。
1. Prompt Chaining(链式工作流)
定义
将任务分解为线性依赖的步骤,前一步的输出作为后一步的输入,形成 “链式传递”。适用于 “步骤顺序固定、后步依赖前步” 的场景。
流程图

图例说明:流程呈线性串联,每个 LLM 的输出直接作为下一个 LLM 的输入,无分支或循环。
适用场景
结构化文档生成(大纲→内容填充→校对)
多步数据处理(数据提取→格式转换→汇总)
跨语言内容生产(原文总结→翻译→本地化润色)
实战代码:“总结→翻译” 链式流程
基于 Ollama 实现 “先总结英文文本,再将总结翻译成中文” 的流程。
import ollama# 1. 初始化Ollama配置(确保本地Ollama服务已启动:ollama serve)MODEL = "llama3:8b"def prompt_chaining(original_text: str) -> tuple[str, str]: """链式工作流:先总结文本,再翻译总结""" # 步骤1:总结英文文本 summary_prompt = f"""请用1句话总结以下文本:{original_text}要求:简洁准确,保留核心信息。""" summary_response = ollama.generate( model=MODEL, prompt=summary_prompt, options={"temperature": 0.3}, # 低随机性,确保总结稳定 ) summary = summary_response["response"].strip() print(f"步骤1 - 总结结果:\n{summary}\n") # 步骤2:将总结翻译成中文 translate_prompt = f"""请将以下英文总结翻译成中文:{summary}要求:译文流畅,符合中文表达习惯,不添加额外内容。""" translate_response = ollama.generate( model=MODEL, prompt=translate_prompt, options={"temperature": 0.1} ) translation = translate_response["response"].strip() print(f"步骤2 - 翻译结果:\n{translation}\n") return summary, translation# 测试:总结并翻译关于LLM的文本if __name__ == "__main__": original_text = """A large language model (LLM) is a language model trained with self-supervised machine learning on a vast amount of text, designed for natural language processing tasks, especially language generation.[1][2] The largest and most capable LLMs are generative pre-trained transformers (GPTs) and provide the core capabilities of chatbots such as ChatGPT, Gemini and Claude. LLMs can be fine-tuned for specific tasks or guided by prompt engineering.[3] These models acquire predictive power regarding syntax, semantics, and ontologies[4] inherent in human language corpora, but they also inherit inaccuracies and biases present in the data they are trained on.""" prompt_chaining(original_text)2. Routing(路由工作流)
定义
通过 “路由智能体” 对输入进行分类,将不同类型的请求导向专用处理逻辑(如不同模型、工具或流程)。核心是 “按需分配资源”,避免 “大材小用”。
流程图
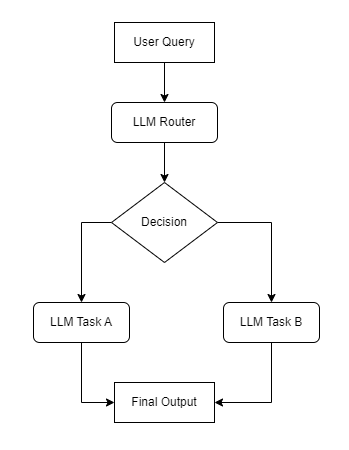
图例说明:LLM Router是核心节点,根据输入类型将流程分支到不同的专用处理节点,最终汇总为统一输出。
适用场景
客服系统(账单问题→账单专员,技术问题→技术支持)
多模型调度(简单查询→轻量模型,复杂推理→大模型)
任务分类处理(天气查询→天气 API,数学计算→计算器工具)
实战代码:“查询分类→定向处理” 路由流程
实现一个能区分 “天气查询”“科学问题”“未知问题” 的路由系统,不同类型请求对应不同处理逻辑。
import ollamaimport jsonfrom typing import OptionalMODEL = "llama3:8b"def get_routing_decision(user_query: str) -> dict: """路由决策:判断用户查询类型,返回分类结果(JSON格式)""" routing_prompt = f"""请分析用户查询,将其分类到以下类别之一:- weather:关于天气的问题(如“北京今天气温多少”)- science:关于科学知识的问题(如“量子物理是什么”)- unknown:无法归入上述类别的问题要求:1. 输出格式为JSON,包含两个字段: - category:分类结果(weather/science/unknown) - reasoning:分类理由(1-2句话)2. 不要输出任何额外内容,仅JSON。用户查询:{user_query}""" response = ollama.generate( model=MODEL, prompt=routing_prompt, options={"temperature": 0.1} ) # 解析JSON结果(处理模型可能的格式偏差) try: return json.loads(response["response"].strip()) except json.JSONDecodeError: return {"category": "unknown", "reasoning": "无法解析查询类型"}def handle_weather_query(user_query: str) -> str: """处理天气查询(模拟调用天气工具)""" weather_prompt = f"""请根据用户查询提及的地点, 提供该地点的简要天气预报(假设实时数据已获取):要求:包含温度、天气状况(晴/雨等)、建议(如“带伞”),1-2句话。用户查询:{user_query}""" response = ollama.generate(model=MODEL, prompt=weather_prompt) return response["response"].strip()def handle_science_query(question: str) -> str: """处理科学问题""" science_prompt = f"""请用通俗的语言解答以下科学问题,避免过于专业的术语:{question}要求:回答简洁,3-5句话。""" response = ollama.generate(model=MODEL, prompt=science_prompt) return response["response"].strip()def routing_workflow(user_query: str) -> str: """路由工作流:分类→处理→返回结果""" # 步骤1:获取路由决策 decision = get_routing_decision(user_query) print(f"路由决策:\n类别={decision['category']}\n理由={decision['reasoning']}\n") # 步骤2:根据分类处理 if decision["category"] == "weather": return handle_weather_query(user_query) elif decision["category"] == "science": return handle_science_query(user_query) else: return "抱歉,我暂时无法处理这个问题,请尝试询问天气或科学相关话题~"# 测试:不同类型的查询if __name__ == "__main__": test_queries = [ "北京今天的天气怎么样?", "为什么月亮会绕着地球转?", "推荐一部好看的电影", ] for query in test_queries: print(f"用户查询:{query}") result = routing_workflow(query) print(f"最终回复:{result}\n" + "-" * 50 + "\n")3. Parallelization(并行化工作流)
定义
将任务分解为多个独立子任务,并行执行(同时调用多个模型 / 工具),最后聚合结果。核心是 “用并发换时间”,提升处理效率。
流程图
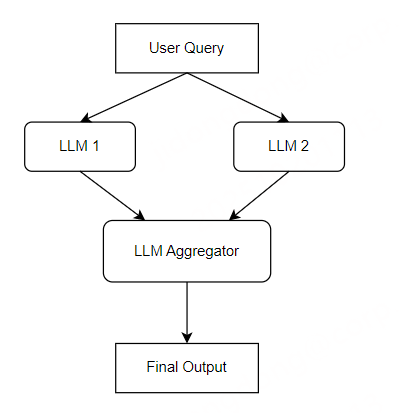
图例说明:任务先被拆分为多个无依赖的子任务,由多个 LLM 并行处理,最后通过 “聚合器” 合并结果,核心是 “并行执行 + 统一汇总”。
适用场景
多视角内容生成(同一主题生成 “幽默”“严肃”“专业” 三种风格文案)
RAG 查询分解(复杂问题拆分为多个子查询,并行检索后汇总)
批量数据处理(多份文档同时总结,再合并为统一报告)
实战代码:“并行生成→结果聚合” 流程
以 “生成旅行攻略子话题” 为例:并行生成 “景点推荐”“美食推荐”“交通贴士”,再聚合为完整攻略。
import ollamaimport asyncioimport timeMODEL = "llama3:8b"async def async_generate(prompt: str, task_name: str) -> tuple[str, str]: """异步生成函数:调用Ollama生成结果,返回任务名和结果""" print(f"开始执行任务:{task_name}") start_time = time.time() client = ollama.AsyncClient() response = await client.generate( model=MODEL, prompt=prompt, options={"temperature": 0.6} # 适度随机性,增加内容多样性 ) end_time = time.time() print(f"任务{task_name}完成,耗时:{end_time - start_time:.2f}秒") return task_name, response["response"].strip()async def parallel_workflow(destination: str) -> str: """并行化工作流:并行生成子话题→聚合结果""" # 步骤1:定义3个独立子任务的Prompt tasks = [ { "name": "景点推荐", "prompt": f"推荐{destination}的3个必去景点,每个景点用1句话说明特色,不要冗长。" }, { "name": "美食推荐", "prompt": f"推荐{destination}的2种特色美食,说明口感和推荐店铺类型(如街边摊/老字号)。" }, { "name": "交通贴士", "prompt": f"给出{destination}的3条旅行交通贴士(如市内交通方式、机场到市区路线等)。" } ] # 步骤2:异步并行执行所有任务 print(f"开始并行处理{destination}旅行攻略任务...") start_total = time.time() # 创建异步任务列表 async_tasks = [ async_generate(task["prompt"], task["name"]) for task in tasks ] # 并行执行并获取结果 results = await asyncio.gather(*async_tasks) # results = asyncio.run(asyncio.gather(*async_tasks)) end_total = time.time() print(f"所有并行任务完成,总耗时:{end_total - start_total:.2f}秒\n") # 步骤3:聚合结果(生成完整攻略) result_dict = dict(results) aggregate_prompt = f"""将以下{destination}旅行攻略的子结果整合成一篇连贯的短文:1. 景点推荐:{result_dict['景点推荐']}2. 美食推荐:{result_dict['美食推荐']}3. 交通贴士:{result_dict['交通贴士']}要求:- 用自然的中文连接,段落清晰;- 保留所有关键信息,不遗漏子结果内容。""" final_response = ollama.generate(model=MODEL, prompt=aggregate_prompt) return final_response["response"].strip()# 测试:生成杭州旅行攻略if __name__ == "__main__": destination = "杭州" final_guide = asyncio.run(parallel_workflow(destination)) print(f"\n{destination}旅行攻略(最终聚合结果):\n") print(final_guide)三、4 种核心智能体模式:从 “自主决策” 进阶
当任务具备 “动态性”“模糊性” 或 “多工具协作” 需求时,单纯的工作流已无法满足,需引入智能体模式 —— 核心是 “让系统自主决定‘做什么’和‘怎么做’”。
1. Reflection(反思模式)
定义
通过 “生成→评估→优化” 的迭代循环,让智能体自主检查输出是否符合要求,并基于反馈修正结果。又称 “评估器 - 优化器模式”,核心是 “自我纠错”。
流程图
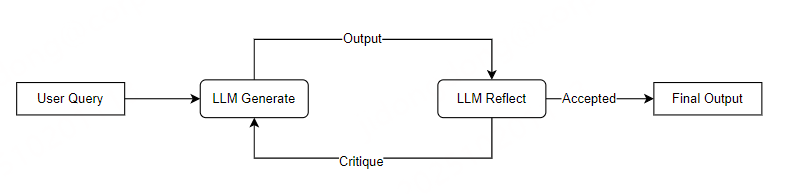
图例说明:核心是 “生成器 - 评估器” 的循环闭环,评估器判断结果是否符合标准,不达标则生成反馈驱动生成器优化,直至满足要求。
适用场景
文案优化(生成初稿→评估语气 / 逻辑→润色)
代码生成(写代码→检查语法 / 逻辑错误→修复)
报告撰写(生成报告→验证数据准确性→补充细节)
实战代码:“生成报告→评估→优化” 反思流程
以 “生成产品功能报告” 为例,让智能体自主评估报告是否 “包含 3 个核心功能”,未达标则优化。
import ollamafrom typing import TupleMODEL = "llama3:8b"MAX_ITERATIONS = 3 # 最大迭代次数,避免无限循环def generate_product_report(product_name: str, feedback: str = "") -> str: """生成产品功能报告(支持基于反馈优化)""" base_prompt = f"""请生成{product_name}的功能报告,包含以下内容:1. 产品定位(1句话);2. 核心功能(至少3个,每个功能用1句话说明);3. 目标用户(1句话)。要求:结构清晰,语言简洁。""" # 若有反馈,加入优化指令 if feedback: base_prompt += f"\n\n请根据以下反馈优化报告:{feedback}" response = ollama.generate(model=MODEL, prompt=base_prompt) return response["response"].strip()def evaluate_report(report: str) -> Tuple[bool, str]: """评估报告:判断是否符合要求,返回“是否通过”和“反馈”""" eval_prompt = f"""请评估以下产品功能报告是否符合要求:评估标准:1. 包含“产品定位”“核心功能”“目标用户”三个模块;2. 核心功能至少有3个;3. 每个模块内容简洁(1句话/功能)。报告内容:{report}要求:1. 先判断“通过(PASS)”或“不通过(FAIL)”;2. 若不通过,给出具体反馈(说明未达标的点);3. 反馈需具体,可直接用于优化报告。""" response = ollama.generate(model=MODEL, prompt=eval_prompt) eval_result = response["response"].strip() # 解析评估结果(简化处理,实际可加正则提取) if "PASS" in eval_result: return True, "报告符合要求,无需优化。" else: # 提取反馈内容(取“反馈:”后的文字) feedback = eval_result.split("反馈:")[-1].strip() if "反馈:" in eval_result else "核心功能数量不足或模块缺失。" return False, feedbackdef reflection_workflow(product_name: str) -> str: """反思工作流:生成→评估→优化(直到通过或达到最大迭代次数)""" current_report = "" current_iteration = 0 while current_iteration < MAX_ITERATIONS: current_iteration += 1 print(f"=== 反思迭代 {current_iteration}/{MAX_ITERATIONS} ===") # 步骤1:生成/优化报告 feedback = "" if current_iteration == 1 else last_feedback current_report = generate_product_report(product_name, feedback) print(f"生成的报告:\n{current_report}\n") # 步骤2:评估报告 pass_eval, last_feedback = evaluate_report(current_report) print(f"评估结果:{'通过' if pass_eval else '不通过'}") print(f"评估反馈:{last_feedback}\n") # 若通过,返回最终报告 if pass_eval: print("反思流程完成,报告符合要求!") return current_report # 达到最大迭代次数,返回最后一版 print(f"达到最大迭代次数({MAX_ITERATIONS}次),返回最后一版报告。") return current_report# 测试:生成“智能笔记APP”的功能报告if __name__ == "__main__": product = "智能笔记APP" final_report = reflection_workflow(product) print(f"\n=== 最终产品功能报告 ===") print(final_report)2. Tool Use(工具使用模式)
定义
智能体根据目标自主决定 “是否调用外部工具”(如 API、数据库、计算器),并利用工具返回结果生成最终回答。核心是 “扩展 LLM 能力边界”(突破训练数据时效性 / 领域限制)。
流程图
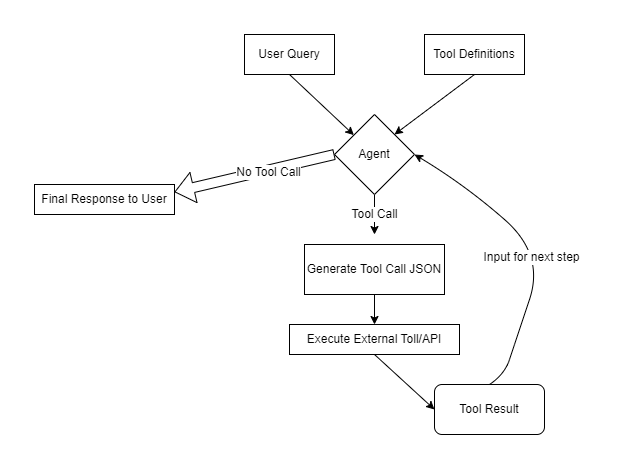
图例说明:智能体是核心决策节点,负责判断 “是否调用工具”以及“如何调用”,并基于工具返回的数据生成最终回答,实现 “LLM + 工具” 的能力扩展。
适用场景
实时信息查询(调用天气 API、股票 API)
数据计算(调用计算器工具、Excel 工具)
外部系统交互(调用日历 API 订会议、调用支付 API 退款)
实战代码:“判断是否调用工具→执行工具→生成回答” 流程
以 “查询实时股票价格” 为例:若用户查询股票价格,智能体自主调用 “股票查询工具”,再返回结果。
import ollamaimport jsonfrom typing import Optional, DictMODEL = "llama3:8b"# 模拟外部工具:股票价格查询(实际可替换为真实API)def get_stock_price(symbol: str) -> Dict[str, str]: """模拟股票价格查询工具,返回股票代码、名称、实时价格、时间""" # 模拟数据(实际应调用如Tushare、Yahoo Finance API) mock_data = { "AAPL": {"name": "苹果公司", "price": "189.56 USD", "time": "2025-10-01 14:30"}, "MSFT": {"name": "微软公司", "price": "412.89 USD", "time": "2025-10-01 14:30"}, "BABA": {"name": "阿里巴巴", "price": "78.23 USD", "time": "2025-10-01 14:30"} } return mock_data.get(symbol.upper(), {"name": "未知股票", "price": "无数据", "time": "无数据"})def decide_tool_use(user_query: str) -> tuple[bool, Optional[Dict]]: """判断是否需要调用工具,返回“是否调用”和“工具参数”""" tool_prompt = f"""请分析用户查询,判断是否需要调用“股票价格查询工具”:工具用途:查询指定股票代码的实时价格(如AAPL、MSFT)。工具参数格式:{{"tool_name": "get_stock_price", "symbol": "股票代码"}}判断逻辑:1. 若用户查询包含“股票价格”“股价”且提及具体股票代码/名称,需要调用工具;2. 否则无需调用,直接回答。要求:1. 输出格式为JSON,包含两个字段: - need_tool:true(需要调用)/false(无需调用) - tool_params:工具参数(仅need_tool为true时填写,否则为null)2. 不要输出额外内容,仅JSON。用户查询:{user_query}""" response = ollama.generate(model=MODEL, prompt=tool_prompt) try: result = json.loads(response["response"].strip()) return result["need_tool"], result.get("tool_params") except (json.JSONDecodeError, KeyError): return False, Nonedef tool_use_workflow(user_query: str) -> str: """工具使用工作流:判断→调用工具→生成回答""" # 步骤1:判断是否需要调用工具 need_tool, tool_params = decide_tool_use(user_query) print(f"是否需要调用工具:{need_tool}") if need_tool and tool_params: print(f"工具参数:{tool_params}\n") # 步骤2:调用工具(仅处理股票查询工具) if tool_params["tool_name"] == "get_stock_price": symbol = tool_params.get("symbol", "") if not symbol: return "请提供具体的股票代码(如AAPL、MSFT),以便查询实时价格。" # 执行工具 stock_data = get_stock_price(symbol) print(f"工具返回结果:{stock_data}\n") # 步骤3:基于工具结果生成回答 answer_prompt = f"""根据以下股票数据,用自然语言回答用户查询:用户查询:{user_query}股票数据:- 股票名称:{stock_data['name']}- 实时价格:{stock_data['price']}- 数据时间:{stock_data['time']}要求:回答简洁,包含所有关键数据。""" response = ollama.generate(model=MODEL, prompt=answer_prompt) return response["response"].strip() # 无需调用工具,直接生成回答 direct_prompt = f"""回答用户查询:{user_query}要求:简洁明了,若涉及股票价格请提示用户提供具体股票代码。""" response = ollama.generate(model=MODEL, prompt=direct_prompt) return response["response"].strip()# 测试:查询苹果公司股票价格if __name__ == "__main__": user_query = "AAPL(苹果公司)的实时股价是多少?" result = tool_use_workflow(user_query) print(f"\n最终回答:{result}")3. Planning(编排器 - 工作者模式)
定义
通过 “编排器(Planner)” 将复杂任务分解为动态子任务列表,再由 “工作者(Worker)” 执行子任务,最后聚合结果。核心是 “化繁为简”,让每个角色专注于单一职责。
流程图
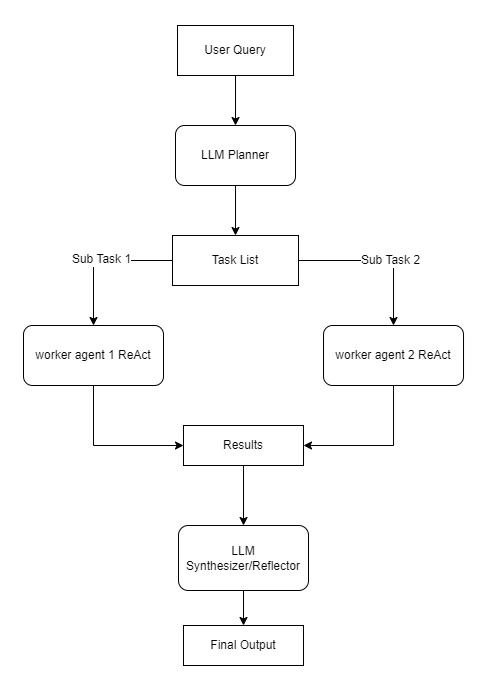
图例说明:编排器负责 “拆解任务”,工作者负责 “执行单一子任务”,聚合器负责 “合并结果”,形成 “分解→执行→聚合” 的完整链路,适合复杂任务的分治处理。
适用场景
复杂项目管理(如 “开发 APP” 分解为 “需求分析→UI 设计→编码→测试”)
多步骤内容创作(如 “写教程” 分解为 “确定主题→收集资料→撰写大纲→填充内容”)
旅行规划(如 “3 天旅行” 分解为 “订机票→订酒店→规划每日行程→准备行李清单”)
实战代码:“分解任务→执行子任务→聚合结果” 规划流程
以写一篇AI智能体入门教程为例,编排器分解任务,工作者执行每个子任务。
import ollamaimport jsonfrom typing import List, DictMODEL = "llama3:8b"class Task: """子任务数据类(简化)""" def __init__(self, task_id: int, description: str, worker: str): self.task_id = task_id self.description = description self.worker = worker # 负责执行的工作者(如Researcher、Writer)def planner(user_goal: str) -> List[Task]: """编排器:将用户目标分解为子任务列表""" plan_prompt = f"""请将“{user_goal}”分解为3-4个连续的子任务,每个任务需满足:1. 有明确的任务描述(说明“做什么”);2. 指定负责的工作者角色(可选角色:Researcher-收集资料,Writer-撰写内容,Editor-校对润色);3. 任务顺序合理(后一步可依赖前一步结果)。要求:1. 输出格式为JSON,包含“tasks”数组,每个元素有“task_id”(数字)、“description”(字符串)、“worker”(字符串);2. 不要输出额外内容,仅JSON。""" response = ollama.generate(model=MODEL, prompt=plan_prompt) try: plan_data = json.loads(response["response"].strip()) # 转换为Task对象列表 return [ Task( task_id=task["task_id"], description=task["description"], worker=task["worker"] ) for task in plan_data["tasks"] ] except (json.JSONDecodeError, KeyError): # 降级方案:默认任务列表 return [ Task(1, "收集AI智能体的核心概念和3个关键模式", "Researcher"), Task(2, "根据资料撰写教程大纲,包含核心概念和模式讲解", "Writer"), Task(3, "校对大纲,补充每个模式的简单示例说明", "Editor") ]def worker_execute(task: Task, previous_result: str = "") -> str: """工作者:执行子任务,支持基于前序任务结果""" base_prompt = f"""你现在是{task.worker},负责执行以下任务:任务描述:{task.description}要求:- Researcher:输出收集到的资料(简洁,关键点用项目符号列出);- Writer:输出撰写的内容(结构清晰,分段落);- Editor:输出校对/补充后的内容(标注修改点)。""" # 若有前序任务结果,加入上下文 if previous_result: base_prompt += f"\n\n前序任务结果(可参考):{previous_result}" response = ollama.generate(model=MODEL, prompt=base_prompt) return response["response"].strip()def planning_workflow(user_goal: str) -> str: """规划工作流:分解任务→执行任务→聚合结果""" # 步骤1:分解任务 tasks = planner(user_goal) print("编排器分解的子任务:") for task in tasks: print(f"- 任务{task.task_id}({task.worker}):{task.description}") print() # 步骤2:执行任务(按顺序,前一步结果传递给后一步) task_results = [] previous_result = "" for task in tasks: print(f"=== 执行任务{task.task_id}({task.worker}) ===") result = worker_execute(task, previous_result) task_results.append(result) previous_result = result # 传递结果给下一个任务 print(f"任务结果:\n{result}\n" + "-"*30 + "\n") # 步骤3:聚合结果(生成最终教程) aggregate_prompt = f"""将以下子任务结果整合成一篇完整的“{user_goal}”教程:{chr(10).join([f"任务{i+1}结果:{res}" for i, res in enumerate(task_results)])}要求:1. 结构连贯,按“概念→内容→补充”的顺序组织;2. 保留所有关键信息,去除重复内容;3. 语言通俗,适合入门读者。""" final_response = ollama.generate(model=MODEL, prompt=aggregate_prompt) return final_response["response"].strip()# 测试:规划“写一篇AI智能体入门教程”if __name__ == "__main__": user_goal = "写一篇AI智能体入门教程(300字左右)" final_tutorial = planning_workflow(user_goal) print("=== 最终AI智能体入门教程 ===") print(final_tutorial)4. Multi-Agent(多智能体模式)
定义
多个具备专属角色(例如产品经理、程序员、测试员、评审员)或者能力的智能体协作完成目标,通过 “协调者(Coordinator)” 或者“交接逻辑”(即一个Agent将控制权传递给另一个Agent) 实现任务传递。核心是 “分工协作”,让每个智能体专注于擅长领域。
流程图
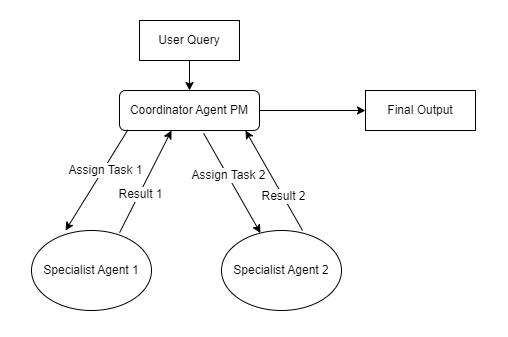
图例说明:协调者是 “中枢节点”,负责接收用户需求、分配任务给不同专业智能体,并传递上下文(如酒店位置→餐厅代理),最终汇总所有专业智能体的结果形成完整输出。
适用场景
复杂服务系统(酒店Agent + 餐厅Agent + 交通Agent → 旅行规划)
软件开发流程(产品经理Agent + 开发Agent + 测试Agent → 开发功能)
内容创作团队(选题Agent + 写作Agent + 编辑Agent → 发布文章)
实战代码:“协调者→酒店Agent→餐厅Agent” 多智能体流程
实现 “旅行规划” 场景:协调者根据用户请求,先调用酒店Agent订酒店,再调用餐厅Agent订餐厅,传递行程上下文。
import ollamafrom typing import Tuple, OptionalMODEL = "llama3:8b"# 智能体角色定义AGENT_ROLES = { "Coordinator": "旅行协调者,负责理解用户需求,分配任务给其他智能体,并传递上下文;不直接处理具体预订。", "HotelAgent": "酒店预订代理,负责根据用户行程(日期、地点、预算)推荐并预订酒店;仅处理酒店相关需求。", "RestaurantAgent": "餐厅预订代理,负责根据用户行程(地点、日期、人数、口味)推荐并预订餐厅;仅处理餐厅相关需求。"}def run_agent(agent_name: str, system_prompt: str, user_query: str, context: str = "") -> Tuple[str, Optional[str]]: """运行指定智能体,返回“智能体回复”和“下一个需调用的智能体名称(可选)”""" # 构建完整Prompt(系统提示+上下文+用户查询) full_prompt = f"""系统提示:{system_prompt}{"上下文:" + context if context else ""}用户查询:{user_query}要求:1. 若你是Coordinator:分析需求后,指定下一个需调用的智能体(HotelAgent/RestaurantAgent),并说明传递的上下文;2. 若你是HotelAgent/RestaurantAgent:处理预订需求,输出预订结果(含关键信息:酒店/餐厅名称、日期、价格),并判断是否需要调用其他智能体(如需订餐厅则指定RestaurantAgent);3. 最后输出“NextAgent: 智能体名称”或“NextAgent: None”(无需继续调用),单独一行。""" response = ollama.generate(model=MODEL, prompt=full_prompt) agent_response = response["response"].strip() # 提取下一个智能体(取“NextAgent: ”后的内容) next_agent = None for line in agent_response.split("\n"): if line.startswith("NextAgent:"): next_agent = line.split(":", 1)[1].strip() agent_response = agent_response.replace(line, "").strip() # 移除NextAgent行 break return agent_response, next_agentdef multi_agent_workflow(user_goal: str) -> str: """多智能体工作流:协调者分配任务→智能体执行→任务交接""" print(f"用户目标:{user_goal}\n") current_context = "" current_agent = "Coordinator" # 初始智能体为协调者 final_result = [] # 循环直到无下一个智能体 while current_agent != "None" and current_agent in AGENT_ROLES: print(f"=== 调用智能体:{current_agent} ===") # 获取智能体的系统提示 system_prompt = AGENT_ROLES[current_agent] # 运行智能体 agent_reply, next_agent = run_agent( agent_name=current_agent, system_prompt=system_prompt, user_query=user_goal, context=current_context ) # 记录结果 final_result.append(f"【{current_agent}】:{agent_reply}") print(f"智能体回复:\n{agent_reply}\n") print(f"下一个智能体:{next_agent}\n" + "-"*40 + "\n") # 更新上下文(传递当前智能体的结果) current_context += f"\n{current_agent}处理结果:{agent_reply}" # 更新当前智能体 current_agent = next_agent # 聚合最终结果 return "\n\n".join(final_result) + "\n\n【最终旅行规划】:" + current_context.strip()# 测试:多智能体协作规划“上海3天旅行”if __name__ == "__main__": user_goal = "帮我规划上海3天旅行,9月10-12日,2人,酒店预算每晚800元以内,想订1家外滩附近的餐厅。" result = multi_agent_workflow(user_goal) print("=== 多智能体协作结果 ===") print(result)四、模式组合:从 “单一模式” 到 “复杂系统”
实际落地中,智能体系统往往是 “多模式组合” 的结果。例如:
旅行规划系统:Multi-Agent(协调者 + 酒店 / 餐厅 / 交通代理) → Planning(每个代理分解子任务,如酒店代理分解 “筛选→比价→预订”) → Tool Use(调用酒店 API / 机票 API) → Reflection(预订后检查信息是否准确)。
智能客服系统:Routing(分类用户问题) → Multi-Agent(账单代理 / 技术代理) → Tool Use(调用用户订单数据库) → Reflection(生成回答后检查是否符合话术规范)。
组合的核心原则:从简单模式入手,按需叠加复杂模式。例如:先实现 “Routing+Tool Use” 解决基础查询,再叠加 “Multi-Agent” 扩展服务类型,最后用 “Reflection” 提升回答质量。
结语
智能体模式不是 “银弹”,而是 “解决问题的工具箱”。无论是简单的链式工作流,还是复杂的多智能体协作,核心都是 “匹配任务特性选择合适的模式”。希望本文的7种模式,能帮助你从 0 到 1 搭建智能体系统,让 AI 的 “自主性” 真正落地到实际场景中。
更多技术干货,
请关注“360智汇云开发者”👇
360智汇云是以"汇聚数据价值,助力智能未来"为目标的企业应用开放服务平台,融合360丰富的产品、技术力量,为客户提供平台服务。
目前,智汇云提供数据库、中间件、存储、大数据、人工智能、计算、网络、视联物联与通信等多种产品服务以及一站式解决方案。
官网:https://zyun.360.cn(复制在浏览器中打开)
更多好用又便宜的云产品,欢迎试用体验~
添加工作人员企业微信👇,get更快审核通道+试用包哦~