释放内存与加速推理:PyTorch的torch.no_grad()与torch.inference_mode()
文章目录
- 0. 前言
- 1. 为什么需要它们?理解计算图与梯度
- 2. `torch.no_grad()`:经典解决方案
- 3. `torch.inference_mode()`:更高效的继任者
- 4. 关键区别与最佳实践
- 5. 总结
0. 前言
📣按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解及成果,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。
在PyTorch模型中,从训练切换到评估/推理时,我们经常会看到model.eval()的身影。然而,还有一个(或者说两个)更为重要的"开关"能够显著提升推理性能并减少内存占用——它们就是torch.no_grad()和它的进化版torch.inference_mode(),本文将介绍它们的用法。
1. 为什么需要它们?理解计算图与梯度
我在前文 基于TorchViz详解计算图(附代码) 详细介绍过计算图。
简单来说,PyTorch的关键特性是自动求导。在训练过程中,每当对张量进行计算时,PyTorch会默默地构建一个计算图,跟踪所有操作以便通过反向传播计算梯度。
在训练时,这种跟踪是必要的。但在推理时,我们只需要前向传播的输出,不需要计算梯度。继续维护计算图只会:
- 消耗额外内存存储中间结果的梯度信息
- 增加计算开销为不必要的反向传播做准备
2. torch.no_grad():经典解决方案
下面我们直接通过实例来演示torch.no_grad()的作用,首先先定义一个极简的模型:
import torch
import torch.nn as nnclass SimpleModel(nn.Module):def __init__(self):super().__init__()self.linear = nn.Sequential(nn.Linear(5000,50000),nn.ReLU(),nn.Linear(50000,5000))def forward(self,x):return self.linear(x)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = SimpleModel().to(device)x = torch.ones(1000,5000).to(device)
x.requires_grad =True
然后对比不使用torch.no_grad()和使用torch.no_grad():
print("====有梯度的计算====")
torch.cuda.empty_cache()
start_mem = torch.cuda.memory_allocated()
output_with_grad = model(x)
mem_with_grad = (torch.cuda.memory_allocated() - start_mem) / 1024 ** 2
print(f"是否有梯度:{output_with_grad.requires_grad}")
print(f"输出梯度函数{output_with_grad.grad_fn}")
print(f"有梯度的内存占用{mem_with_grad:.2f}MB")print("====使用torch.no_grad()====")
torch.cuda.empty_cache()
start_mem = torch.cuda.memory_allocated()
with torch.no_grad():output_with_no_grad = model(x)mem_with_no_grad = (torch.cuda.memory_allocated() - start_mem) / 1024 ** 2print(f"是否有梯度:{output_with_no_grad.requires_grad}")print(f"输出梯度函数{output_with_no_grad.grad_fn}")print(f"无梯度的内存占用{mem_with_no_grad:.2f}MB")print(f"使用no_grad()能节省{(1-mem_with_no_grad/mem_with_grad)*100:.2f}%的内存")
输出结果:
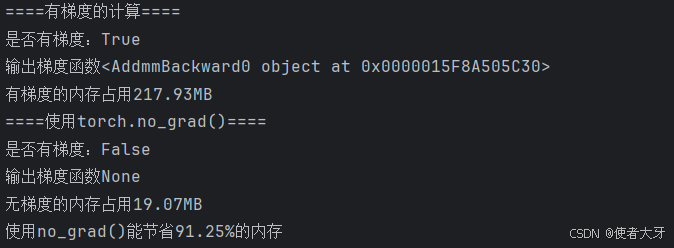
可以看到,在torch.no_grad()可以节省大量的内存!
3. torch.inference_mode():更高效的继任者
PyTorch 1.10引入了torch.inference_mode(),它比torch.no_grad()更加激进和高效,我们再看下torch.inference_mode()的内存占用情况
print("====使用torch.inference_mode====")
model.eval()
torch.cuda.empty_cache()
start_mem = torch.cuda.memory_allocated()
with torch.inference_mode():output_inference_mode = model(x)mem_inference_mode = (torch.cuda.memory_allocated() - start_mem) / 1024 ** 2print(f"是否有梯度:{output_inference_mode.requires_grad}")print(f"输出梯度函数{output_inference_mode.grad_fn}")print(f"inference_mode的内存占用{mem_inference_mode:.2f}MB")
输出结果:

在本次实验中,torch.inference_mode()与torch.no_grad()显示出相同的内存占用(均为19.07MB),这主要是因为两者在核心优化机制上是一致的:它们都通过完全禁用梯度计算和计算图构建来实现主要的内存节省。在简单的单次前向传播场景下,内存消耗的主要来源是计算图中间结果的存储,而这一点两者都已完美解决。
然而,内存节省只是性能优化的一个维度,torch.inference_mode()作为torch.no_grad()的进化版本,其真正优势在于更激进的内部优化策略——包括禁用版本计数器、减少运行时检查等,这些优化虽然对单次内存占用影响不大,但对计算效率的提升却至关重要。为了全面评估两者的性能差异,下面我们通过时间效率测试来揭示torch.inference_mode()在推理速度上的显著优势:
print("====让我们再对比下时间====")
import time
model.eval()# 测试 torch.no_grad() 性能
start_time = time.time()
with torch.no_grad():for _ in range(100):_ = model(x)
no_grad_time = time.time() - start_time# 测试 torch.inference_mode() 性能
start_time = time.time()
with torch.inference_mode():for _ in range(100):_ = model(x)
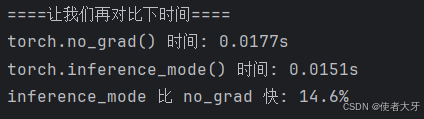
inference_time = time.time() - start_timeprint(f"torch.no_grad() 时间: {no_grad_time:.4f}s")
print(f"torch.inference_mode() 时间: {inference_time:.4f}s")
print(f"inference_mode 比 no_grad 快: {(1 - inference_time/no_grad_time)*100:.1f}%")
输出结果:
4. 关键区别与最佳实践
| 特性 | torch.no_grad() | @torch.inference_mode() |
|---|---|---|
| 梯度计算 | 禁用 | 禁用 |
| 计算图构建 | 仍然构建,但不记录操作 | 完全不构建 |
| 版本计数器 | 仍然递增 | 不递增 |
| 性能 | 较好 | 更优 |
| 内存使用 | 较少 | 更少 |
| 灵活性 | 可在其中启用梯度 | 不能在其中启用梯度 |
最佳实践建议:
- 训练代码中:使用
model.eval()+torch.no_grad() - 部署/生产环境中:优先使用
@torch.inference_mode() - 需要调试或特殊情况:使用
torch.no_grad()(更灵活)
5. 总结
torch.no_grad()和torch.inference_mode()都是PyTorch推理优化的重要工具。理解它们的区别并正确使用,可以:
- ✅ 显著减少内存占用
- ✅ 提升推理速度
- ✅ 让模型部署更加高效
记住这个简单的规则:在不需要梯度计算的任何地方,特别是模型推理时,都应该使用torch.inference_mode()。