Linux_基础IO(2)
接上篇,我们现在继续来讲讲文件IO知识。
我们回顾一下流程:1-3已经讲了,4的缓冲区也讲了,现在我们来讲一下关于重定向(补充)。

重定向
什么是重定向?
上一篇我们已经讲了关于文件描述符的分配规则了。
也已经认识到了
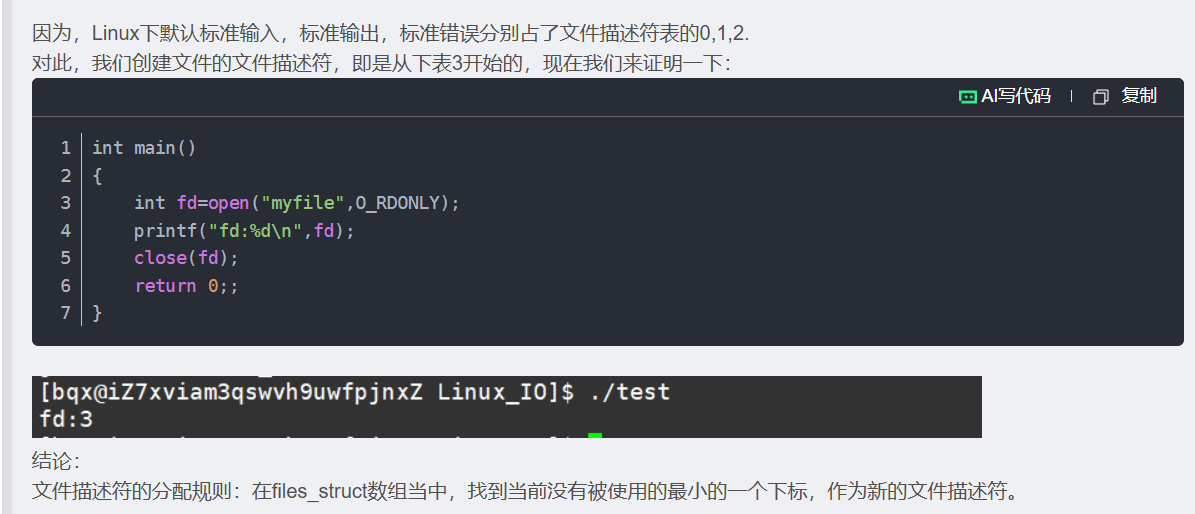
那么,现在我们再用代码来看现象:
关闭0(文件描述符)
int main()
{close(0);int fd=open("myfile",O_RDONLY);if(fd<0){perror("open");return 1;}printf("fd:%d\n",fd);close(fd);return 0;
}![]()
我们发现:当我们关了文件描述符0后,在files_struct数组当中,找到当前没有被使用的最小的一个下标,作为新的文件描述符。这结果也符合我们的分配规则。
那么,我们继续把1关闭了呢?
int main()
{close(1);int fd=open("myfile",O_WRONLY|O_CREAT,0666);if(fd<0){perror("open");return 1;}printf("fd:%d\n",fd);fflush(stdout);close(fd);return 0;
}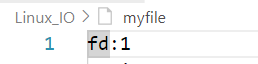
注意⚠️:这里需要用fflush刷新后才能看到结果,因为文件是全缓冲,缓冲区满了才刷新,所以我们手动刷新一下。
上面这种现象就叫做重定向。其中常见的重定向有:>, >>, <。
谈谈重定向的本质:
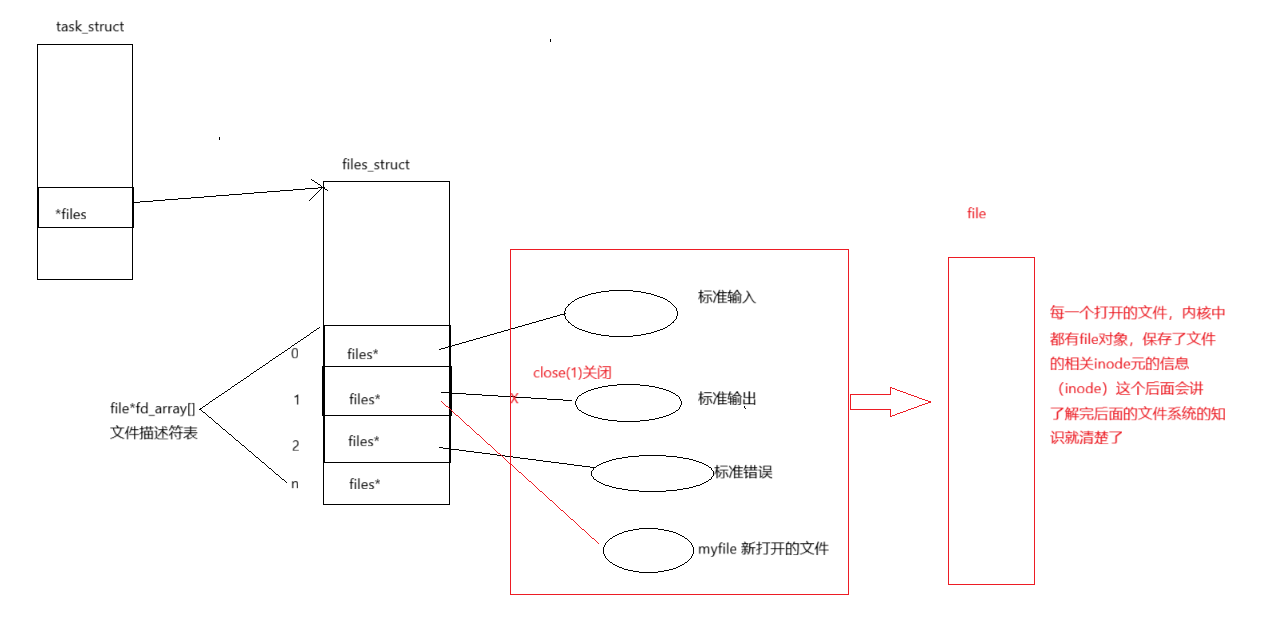
重定向的系统调用接口dup2
我们这里主要介绍dup2
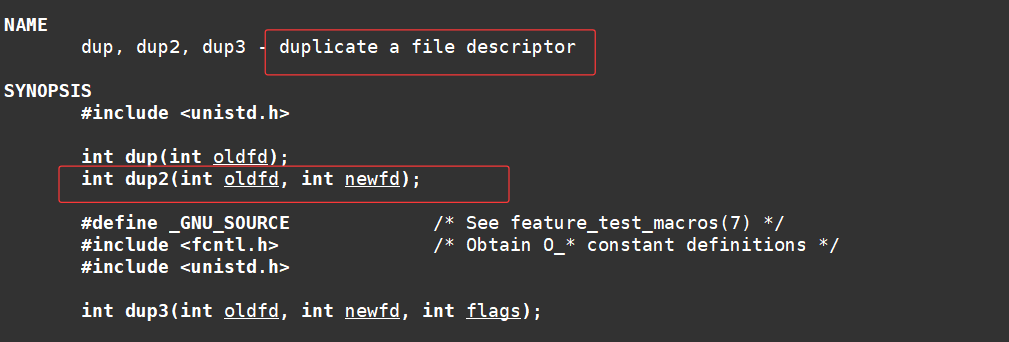
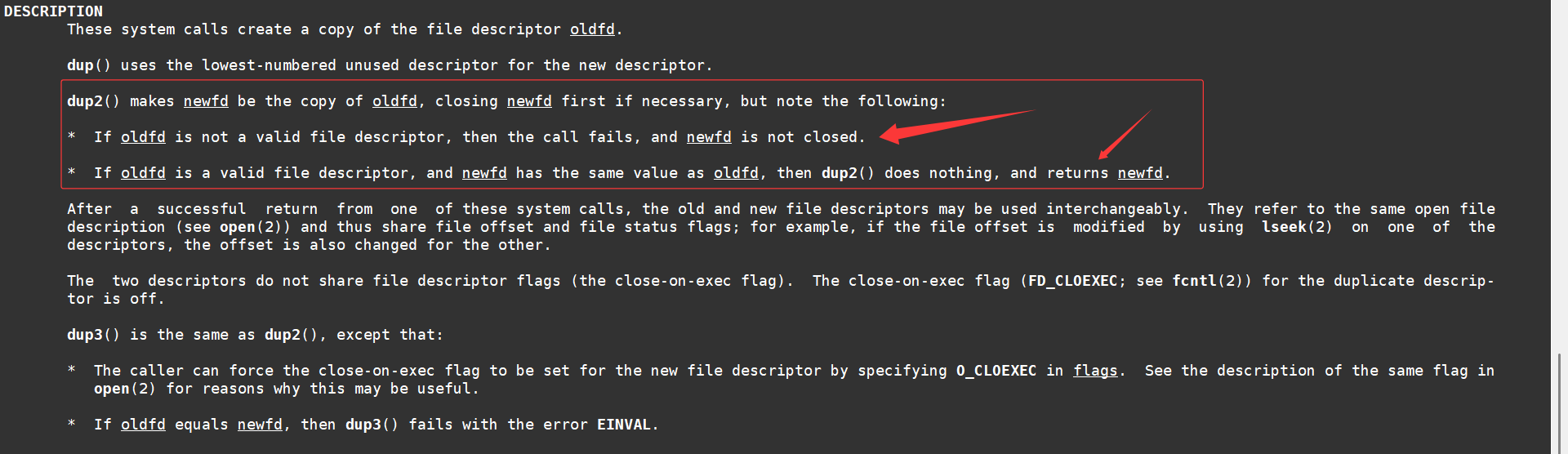
dup2() 会将 newfd 作为 oldfd 的副本,必要时会先关闭 newfd ,但请注意以下几点:
- 如果 oldfd 不是有效的文件描述符,调用会失败,且 newfd 不会被关闭。
- 如果 oldfd 是有效的文件描述符,且 newfd 的值与 oldfd 相同, dup2() 不会执行任何操作。
在这些系统调用成功返回后,新旧文件描述符可以使用相同的文件描述(参见 open(2) ),因此会共享文件偏移量和文件状态标志;例如,如果通过其中一个描述符修改了文件偏移量,另一个的偏移量也会随之改变。
这两个描述符不共享文件描述符标志(执行时关闭标志)。执行时关闭标志(……)默认是关闭的。
使用代码:
int main()
{int fd=open("myfile",O_RDWR|O_CREAT);if(fd<0){perror("open");return 1;}close(1);dup2(fd,1);while(1){char buf[128]={0};ssize_t s=read(0,buf,sizeof(buf));if(s<0){perror("read");return;}printf("%s",buf);fflush(stdout);}return 0;
}
属于这个接口,需要注意的区分哪个是newfd,哪个是oldfd(仔细读一下文档中的解释上面给出的图片)
文件系统
前言:
我们知道,文件分为被打开的文件和没被打开的文件
如果一个文件没有被打开,它是在磁盘中存储的。这就需要我们考虑以下问题了:
1.路径问题
2.存储问题
3.获取的问题(属性+文件内容)
4.效率问题
文件=文件内容+文件属性
即转换成,
磁盘上存储文件=存文件的内容+存文件的属性
文件内容---数据块
文件属性--inode
因此,Linux的文件在磁盘中存储,是将属性和内容分开存储的
现在,我们来过一遍我们讲文件系统的大致流程:
流程
1.从硬件层面出发
2.从软件层面出发
3.再回到文件系统
首先,我们上面说到磁盘,如果是第一次听说的话,会感到陌生,抽象!
那么,我们就先打破这种局面,先从硬件上认识磁盘:


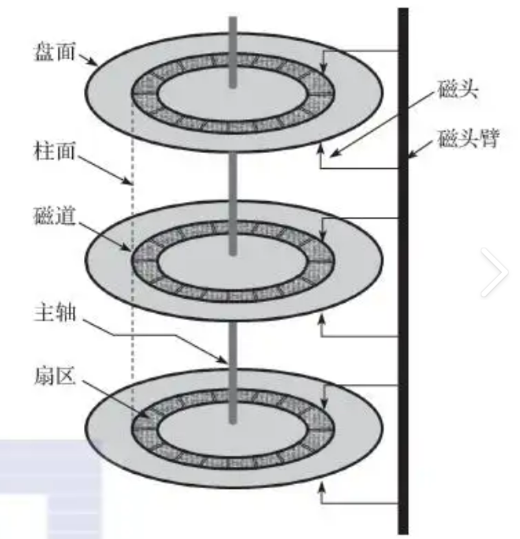
一、硬件结构
- 盘片:永久性存储介质,表面有磁记录层。
- 主轴与马达:驱动盘片旋转,是定位扇区的动力来源。
- 磁头与磁头臂:磁头一面一个,通过磁头臂移动;磁头和盘面不接触,避免物理损伤。
- 磁头停靠点:磁头非工作时的停放位置。
一、存储单元
- 扇区(Sector):磁盘访问的最基本单元,容量通常为512字节或4KB。磁盘可视为由无数扇区构成的存储介质。
二、存储结构
- 磁道(Track):盘片上的同心圆轨道。
- 柱面(Cylinder):多个盘片上同一位置的磁道组成的圆柱状区域。
- 磁头(Header):负责读写盘片数据,每个盘面对应一个磁头。
三、寻址方式(CHS)
要将数据存入磁盘,需定位一个扇区,需明确三个要素:
- 磁头(Header):定位盘面(哪一面)。
- 柱面(Cylinder):定位磁道。
- 扇区(Sector):定位具体存储单元。
这种通过Cylinder(柱面)、Header(磁头)、Sector(扇区) 定位的方式称为CHS寻址方式。
三、工作原理与效率
- 定位过程:先通过磁头臂定位磁道和柱面,再通过盘片旋转定位扇区。
- 效率逻辑:磁头运动越少,效率越高;运动越多(如频繁跨磁道、跨柱面),效率越低。
- 软件设计启示:设计时应将相关数据放在一起,减少磁头不必要的运动,提升存储访问效率。
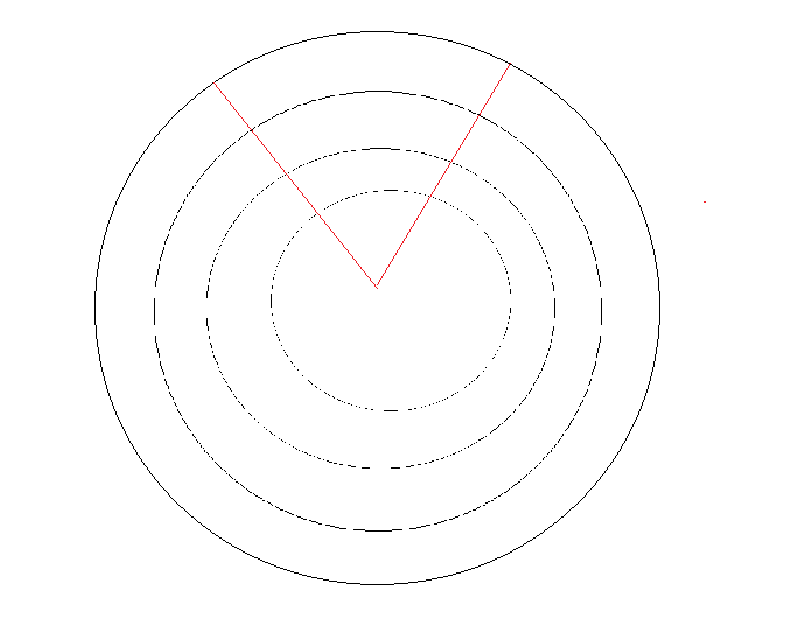
对磁盘进行逻辑结构(化抽象为具体)
把它延展开来,就是一个线性的。
我们用具体的数字来看看它是如何定位的?
比如设定:
每个盘面2w个扇区,每个盘面有50个磁道,每个磁道有400个扇区。
因为任意一个扇区都有下标。
假如现在我要找的扇区编号:28888
28888/20000=1
28888%20000=8888
8888/400=22
8888%400=88
因此,通过一系列的计算,得出来
C磁道:22
H磁头:1
S扇区:88
这就是我们所说的LBA地址!

再回到硬件,不仅仅CPU有“寄存器”,其他设备(外设也有),磁盘也有。
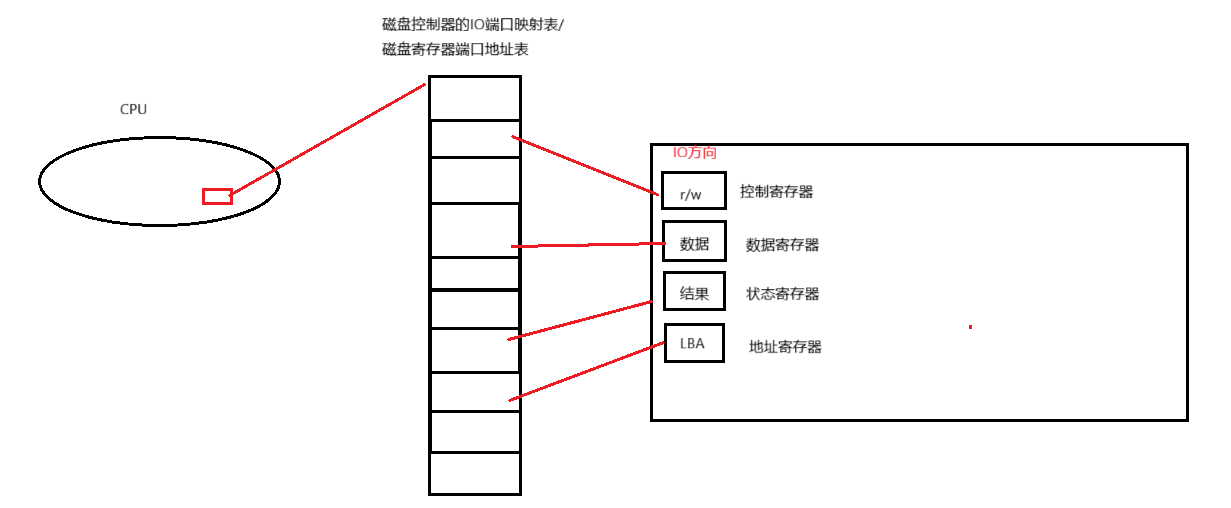
磁盘控制器的I/O端口映射表,也可称为磁盘寄存器端口地址表。
它的作用是将磁盘控制器内部的控制寄存器、数据寄存器、地址寄存器(LBA)、状态寄存器等硬件组件,映射到特定的I/O端口地址上。CPU通过读写这些端口地址,就能间接操作磁盘的各类寄存器,实现对磁盘的指令发送、数据传输和状态查询等功能(例如IDE硬盘控制器的端口0x1F0~0x1F7就对应了数据、命令、状态等不同类型的寄存器)。
- CPU:作为系统核心,发起对磁盘的IO操作指令。
- 磁盘寄存器:
- 控制寄存器(r/w):用于发送读写控制指令,决定磁盘的操作类型。
- 数据寄存器:负责暂存CPU与磁盘之间传输的实际数据。
- 地址寄存器(LBA):通过逻辑块地址(LBA)方式定位磁盘的存储单元(扇区)。
- 状态寄存器(结果):反馈磁盘操作的执行状态,如是否完成、是否出错等。
二、IO交互流程
1. 指令发起:CPU向磁盘的控制寄存器发送读写指令,明确操作类型。
2. 地址定位:通过地址寄存器(LBA)指定要访问的磁盘存储位置。
3. 数据传输:数据在CPU与磁盘的数据寄存器之间传递,完成读写操作。
4. 状态反馈:磁盘通过状态寄存器向CPU返回操作结果,CPU根据状态判断后续动作。
三、硬件设计逻辑
- 磁盘作为外设,通过专属寄存器与CPU交互,体现了“设备寄存器是硬件与CPU通信桥梁”的设计思路。
- LBA寻址方式的引入,简化了磁盘物理地址的管理,让CPU无需关注复杂的磁头、柱面、扇区硬件结构,只需通过逻辑地址即可完成存储访问。
注意:
磁盘中的这些寄存器是硬件级别的物理寄存器,并非虚拟的。
- 控制寄存器:属于命令寄存器,用于接收CPU发送的读写等控制指令,是磁盘执行操作的“指令入口”。
- 数据寄存器:属于数据缓冲寄存器,是CPU与磁盘之间传输数据的“临时中转站”,物理上由硬件电路实现数据暂存。
- 地址寄存器(LBA):属于地址缓冲寄存器,用于暂存逻辑块地址(LBA),将CPU的逻辑地址请求转化为磁盘可识别的存储定位信息,是硬件层面的地址映射组件。
- 状态寄存器:属于状态指示寄存器,物理上通过硬件电路的电平、标志位等反馈磁盘的操作状态,是CPU感知磁盘工作情况的“硬件信号窗口”。
这些寄存器是磁盘控制器硬件的一部分,直接参与硬件层面的IO交互,和CPU内部的物理寄存器类似,都是真实的硬件组件,而非虚拟抽象的概念。
磁盘怎么和软件进行交互的?
⚠️:并不是通过32条总线来进行交互的!!
以常见的IDE(并行ATA)和SATA(串行ATA)接口为例:
- IDE(并行ATA):采用并行总线,数据总线位宽为16位,并非32位。它通过多个I/O端口(如0x1F0~0x1F7)与CPU交互,这些端口对应磁盘的控制、数据、地址等寄存器,软件通过读写这些端口来操作磁盘。
- SATA(串行ATA):采用串行总线,仅用4根差分信号线(2对收发线)实现数据传输,通过“影子寄存器”和FIS(帧信息结构)模拟传统IDE寄存器的交互方式,软件通过这些虚拟的寄存器接口与磁盘通信,本质上是串行总线的逻辑抽象,并非32条物理总线。
上面所说的寄存器是属于谁的??
这些寄存器属于磁盘控制器,是磁盘硬件的一部分。
磁盘控制器是集成在磁盘内部的硬件模块,负责管理磁盘的读写操作、地址映射、状态反馈等功能。控制寄存器、数据寄存器、地址寄存器(LBA)和状态寄存器都是磁盘控制器的组成组件,用于在硬件层面与CPU(通过总线和I/O端口)进行指令、数据和状态的交互,是磁盘实现硬件功能和软件可操作性的核心桥梁。
注意⚠️:这里磁盘控制器≠磁盘
| 对比项 | 磁盘控制器 | 磁盘本身 |
| 定义 | 是磁盘内部的硬件模块,负责管理磁盘的各类操作 | 是存储数据的物理介质(盘片、磁头等) |
| 功能 | 处理CPU指令、管理数据传输、地址映射、状态反馈等 | 提供永久性存储介质,通过磁记录技术保存数据 |
| 组成 | 由控制寄存器、数据寄存器、地址寄存器、状态寄存器等硬件电路构成 | 由盘片、磁头、主轴马达、磁头臂等机械和存储组件构成 |
| 与CPU交互 | 直接通过总线和I/O端口与CPU通信,解析并执行指令 | 需通过磁盘控制器间接与CPU交互,自身不直接处理软件指令 |
| 核心作用 | 是磁盘的“大脑”,负责逻辑控制和硬件调度 | 是磁盘的“存储载体”,负责数据的物理存储 |
ok,大概了解完磁盘后,我们来认识一下关于文件系统里面的知识点。
在此之前,先介绍一下mke2fs指令
mke2fs指令
mke2fs 是 Linux 系统中用于创建 ext2、ext3、ext4 文件系统的工具,属于 e2fsprogs 软件包的一部分。它负责在磁盘分区上初始化文件系统的元数据(如超级块、inode 表、数据块等),使分区能被 Linux 识别并用于存储文件(存储和组织)。
语法:mke2fs [选项] 设备名
通过 mke2fs ,你可以灵活地为磁盘分区初始化 ext 系列文件系统,满足不同场景的存储需求。
价值:
创建好的 ext 文件系统是 Linux 生态的“通用语言”——系统的文件管理工具(如 ls 、 cp 、 rm )、应用程序(如数据库、Web 服务)都依赖它来读写数据,是 Linux 存储层的核心基础工具之一。
即,没有 mke2fs 创建的文件系统,Linux 就无法在磁盘分区上“理解”和管理文件
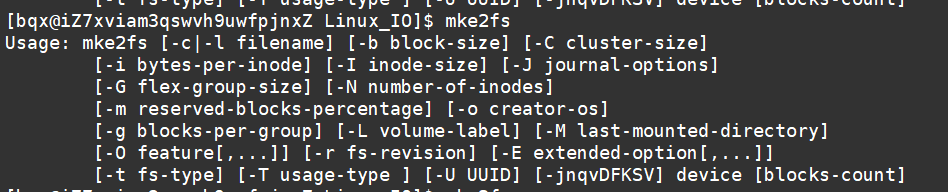
看一下Linux显示文件的信息:
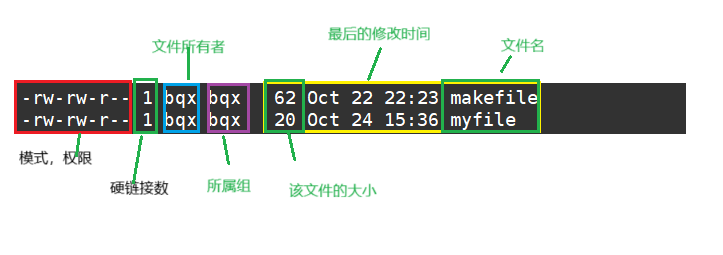
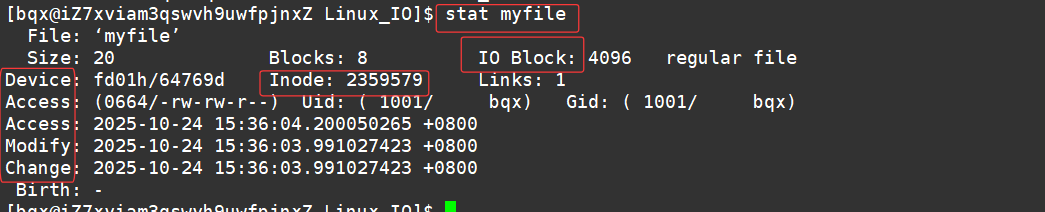
从上面我们看到有个inode,它代表什么意思呢?
我们先了解一下Linux下的文件系统的构成:
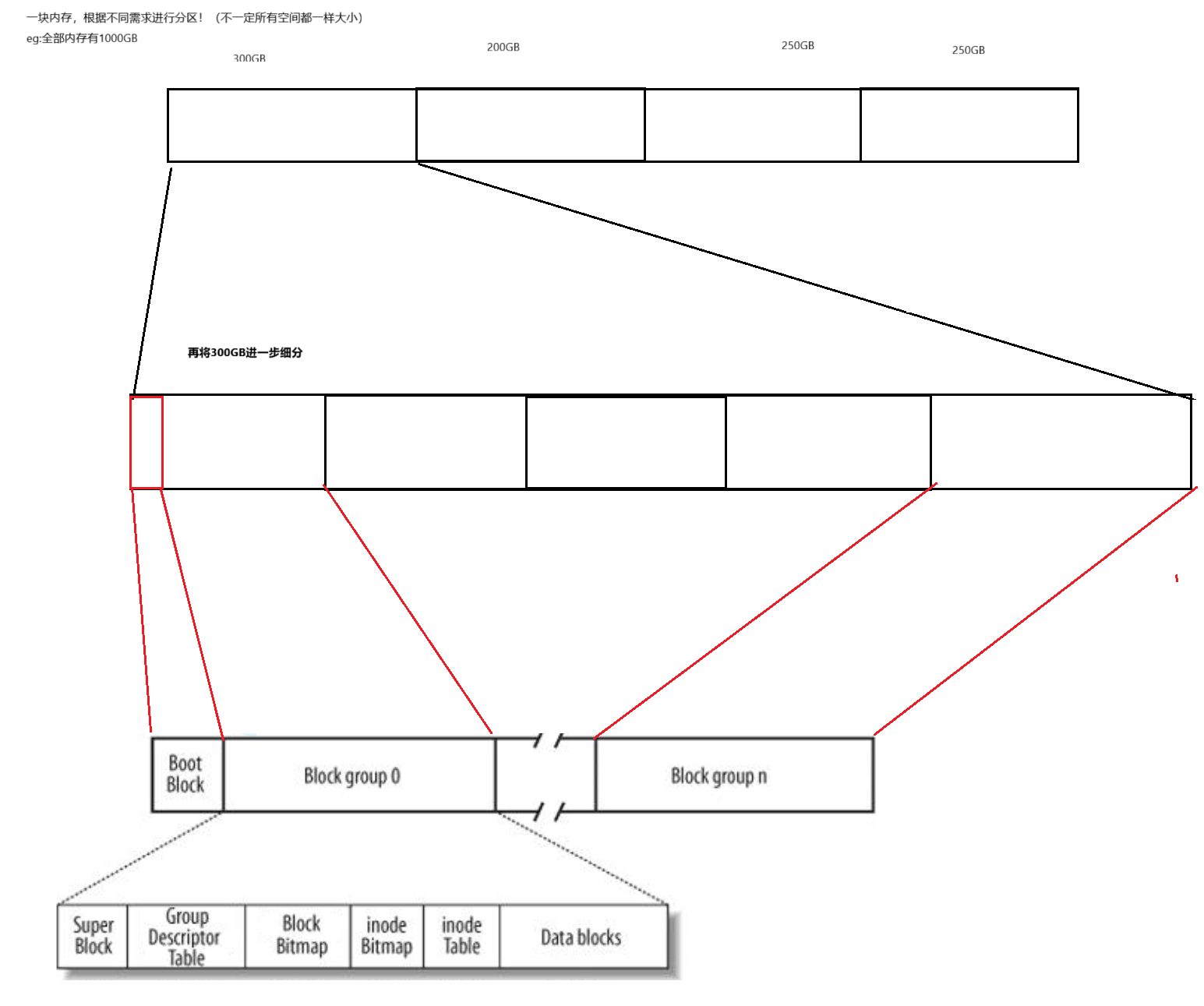
现在我们来对上面的名词进行解释!
Linux ext2文件系统,上图为磁盘文件系统图(内核内存映像肯定有所不同),磁盘是典型的块设备,硬盘分区被划分为一个个的block。一个block的大小是由格式化的时候确定的,并且不可以更改。例如mke2fs的-b选项可以设定block大小为1024、2048或4096字节。而上图中启动块(Boot Block)的大小是确定的,
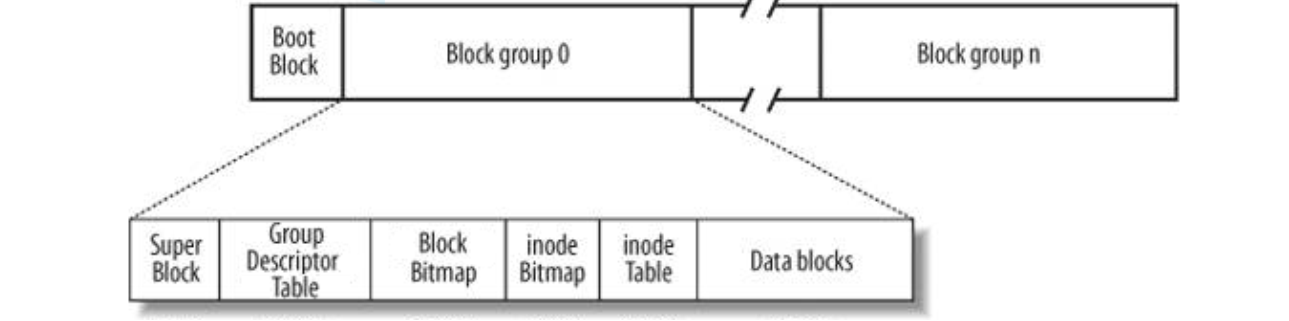
Block Group:ext2文件系统会根据分区的大小划分为数个Block Group。而每个Block Group都有着相同的结构组成。
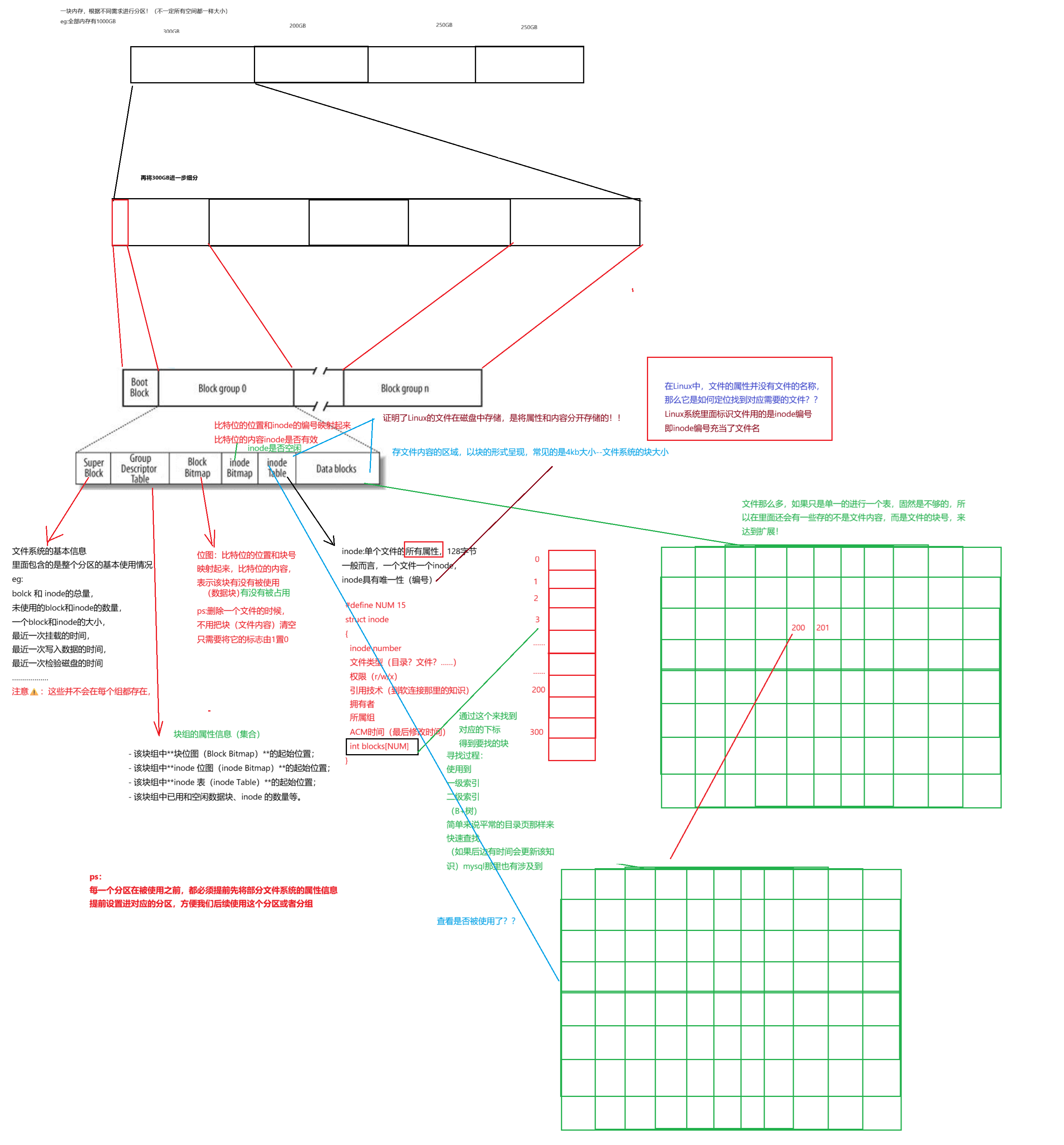
超级块(Super Block):存放文件系统本身的结构信息。记录的信息主要有:bolck 和 inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了
GDT,Group Descriptor Table:块组描述符,描述块组属性信息(每个组块都对应一个块组描述符,GDT就是这些描述符的集合)
通过 GDT,文件系统可以快速定位每个块组的管理信息,从而高效地分配、回收数据块和 inode,保障文件的存储与访问。
可将文件系统的“块组”类比为城市的“行政区”,GDT 则是记录每个行政区“政务中心位置、资源余量、管理边界”的管理台账——系统通过查阅 GDT,就能清晰掌握每个块组的状态,进而对文件存储进行精细化管理。
GDT 的完整性直接影响文件系统对块组的管理能力。若 GDT 损坏,文件系统可能无法正确识别块组的结构,导致数据块或 inode 分配异常,甚至引发文件丢失、分区无法挂载等问题。
块位图(Block Bitmap):Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没有被占用
inode位图(inode Bitmap):每个bit表示一个inode是否空闲可用。
i节点表:存放文件属性 如 文件大小,所有者,最近修改时间等
(下图的名称我上面已经解释过了!)

数据区:存放文件内容
补充:
这里说的ACM:
Access 最后访问时间
Modify 文件内容最后修改时间
Change 属性最后修改时间
一、文件与inode
- inode的核心作用:Linux中每个文件对应一个inode,inode以分区为单位管理,不可跨分区。inode存储文件的所有属性(如权限、大小、时间等),但不包含文件名。
- 文件操作的系统行为的本质:
- 新建文件:系统会分配inode、数据块,建立文件名与inode的映射。
- 删除文件:本质是允许该文件的inode和数据块被覆盖。
- 查找文件:通过文件名找到对应的inode,再通过inode访问数据块。
- 修改文件:若只是修改内容,inode可能不变;若修改属性(如权限),则直接更新inode信息。
- 查看inode编号:用户日常用文件名操作,若需查看inode,可通过 ls -i 文件名 等命令获取。
二、目录的本质
- 目录也是文件:目录有自己的inode,也具备文件的“属性+内容”结构。
- 目录的数据块内容:存储该目录下文件名与对应文件inode的映射关系。
- 目录权限的意义
- 无 w 权限:无法在该目录下创建文件。
- 无 r 权限:无法查看该目录下的文件列表。
- 无 x 权限:无法进入该目录。
- 同名文件限制:同一目录下不能有同名文件,因为目录的数据块中“文件名-inode”映射需保持唯一。
- dentry缓存:用于加速目录与文件的映射关系查询,提升文件访问效率。
将属性和数据分开存放的想法看起来很简单,但实际上是如何工作的呢?
创建一个新文件主要有一下4个操作:
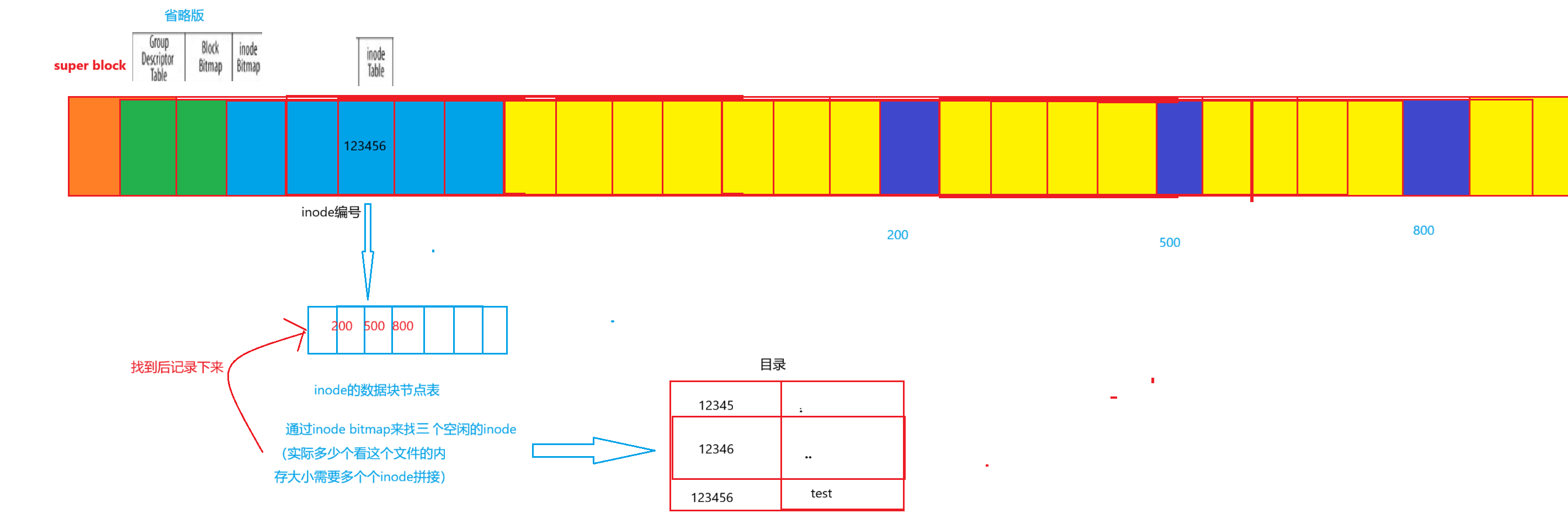
1. 存储属性
内核先找到一个空闲的i节点。内核把文件信息记录到其中。
2. 存储数据
该文件需要存储在三个磁盘块,内核找到了三个空闲块:200,500,800。将内核缓冲区的第一块数据复制到200,下一块复制到500,以此类推。
原因:
在Linux的磁盘存储架构中,文件的数据是分散存储在多个磁盘块中的。每个磁盘块有固定的容量(比如常见的4KB),当一个文件的大小超过单个磁盘块的容量时,就需要多个磁盘块来存储其全部数据。
以图中为例,该文件的数据量需要占用3个磁盘块(200、500、800),这是因为文件的实际大小超过了单个磁盘块的存储能力,所以必须通过多个磁盘块的“拼接”来完整存储文件内容。inode(i节点)会记录这些磁盘块的编号列表(如200、500、800),从而让系统能够按顺序读取这些磁盘块,还原出完整的文件数据。3. 记录分配情况
文件内容按顺序200,500,800存放。内核在inode上的磁盘分布区记录了上述块列表。
4. 添加文件名到目录
新的文件名abc。linux如何在当前的目录中记录这个文件?内核将入口(123456,abc)添加到目录文件。文件名和inode之间的对应关系将文件名和文件的内容及属性连接起来
文件的软链接与硬链接
在 Linux 系统中,文件的硬链接和软链接(符号链接)是两种不同的文件链接方式,
一、硬链接(Hard Link)
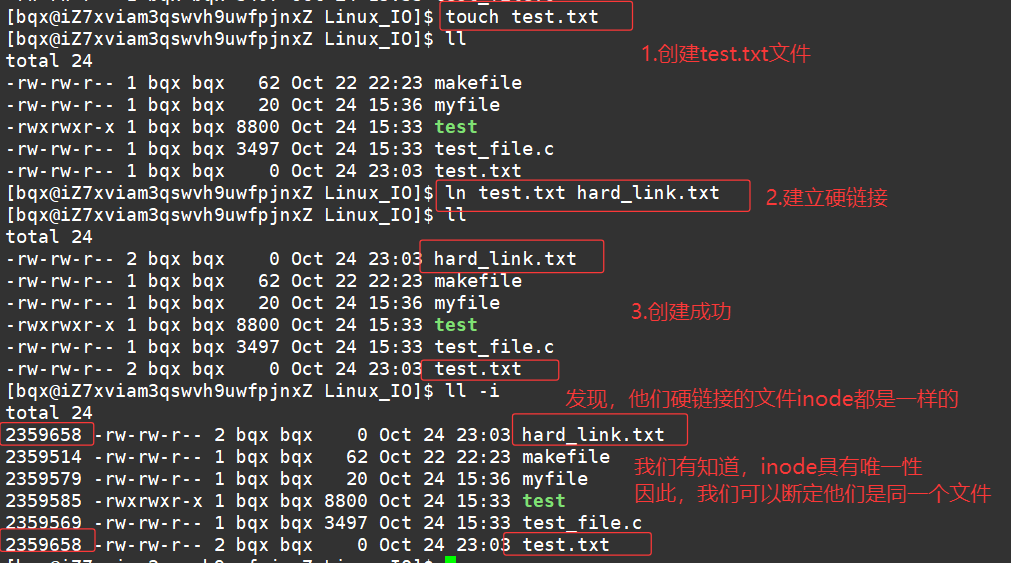
硬链接是通过inode(索引节点)来建立链接关系,多个硬链接指向同一个 inode,本质上是同一个文件。
- 创建方法:使用 ln 命令,语法为 ln 源文件 硬链接文件
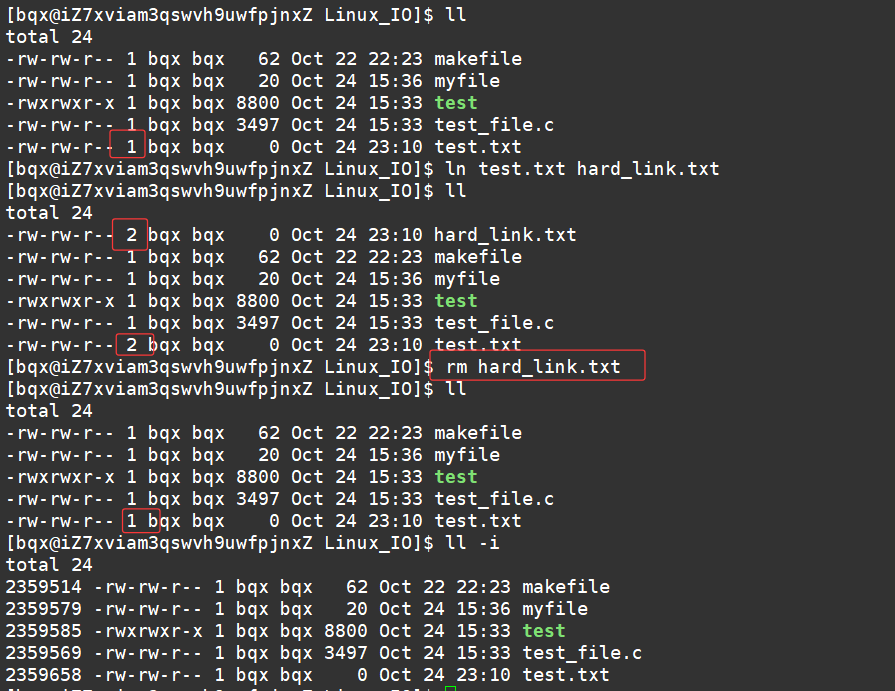
示例:若有文件 file.txt ,创建其硬链接 hard_link.txt ,可执行 ln file.txt hard_link.txt
- 特点:
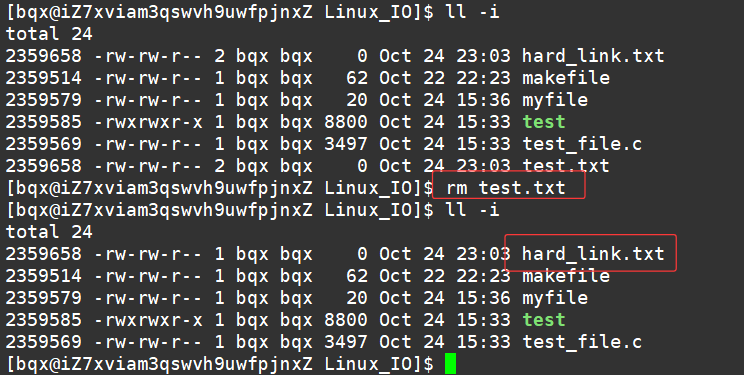
- 删除源文件,硬链接文件仍可正常访问,因为 inode 未被删除,只要还有一个硬链接存在,文件数据就不会被删除。
- 硬链接不能跨文件系统(分区)创建。。- 限制:Linux 系统不允许对目录建立硬链接,原因是会导致目录结构出现循环引用,破坏文件系统的树形结构(而目录内的 . 和 .. 是系统特殊处理的硬链接,不属于用户可创建的范围)。
另外,看上图,我们会发现这个就是我们之前说的inode的结构体中存储的引用计数。
这也是为什么删除源文件,硬链接的文件还能访问的原因!
二、软链接(Symbolic Link,符号链接)
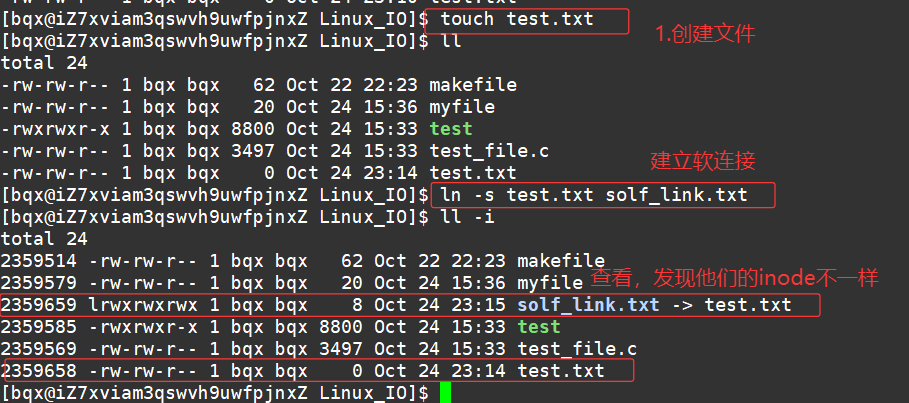
软链接是通过路径来建立链接关系,类似于 Windows 中的快捷方式,链接文件中存储的是源文件的路径。
- 应用场景:用于跨文件系统(分区)链接、目录链接,或需要明确路径指向的场景。
- 创建方法:使用 ln -s 命令,语法为 ln -s 源文件 软链接文件
示例:为 file.txt 创建软链接 soft_link.txt ,执行 ln -s file.txt soft_link.txt
- 特点:
- 软链接可以跨文件系统(分区)创建。
- 可以对目录创建软链接。
- 删除源文件后,软链接会失效,因为其指向的路径不再有效。
- 软链接文件的权限通常显示为 lrwxrwxrwx ,第一个 l 表示是链接文件。
查看链接的方法
- 可以使用 ls -l 命令查看文件的链接情况,硬链接会显示链接数( nlink ),软链接会显示指向的源路径。
示例: ls -l file.txt hard_link.txt soft_link.txt

ok,本次分享就到此结束了,希望大家一起进步!
最后到了本次鸡汤环节:
日日行,不怕千万里;常常做,不怕千万事。
