AiOnly深度体验:从注册到视频生成,我与“火山即梦”的创作之旅
目录
- AiOnly深度体验:从注册到视频生成,我与“火山即梦”的创作之旅
- 初遇AiOnly:不只是API,更是创意加速器
- 三步上手:我的AiOnly入门实践
- 第一步:极简注册,立即开启AI之旅
- 第二步:模型开通,视频生成触手可及
- 第三步:密钥获取,安全与便捷兼得
- 技术深潜:用“火山即梦”点燃创作火花
- 环境准备:轻装上阵
- 初试牛刀:我的第一个AI生成视频
- 进阶探索:图生视频的魔法
- 实战项目:打造个性化视频创作工作流
- 系统设计理念
- 完整实现
- 使用体验:惊喜与挑战并存
- 令人印象深刻的亮点
- 需要关注的挑战
- 成本优化策略
- 创作心得:AI视频生成的最佳实践
- 总结:为什么AiOnly成为我的创作利器
AiOnly深度体验:从注册到视频生成,我与“火山即梦”的创作之旅
在这个人人都是创作者的时代,AI视频生成技术正以前所未有的速度改变着内容生产的游戏规则。今天,我要分享的不仅是一个API平台的使用体验,更是一段从文字到视频的魔法创作之旅——通过AiOnly(https://www.aiionly.com/login/2150776962)平台的“火山即梦”模型,我如何将想象变为生动的视觉盛宴。
初遇AiOnly:不只是API,更是创意加速器
第一次接触AiOnly时,我带着技术人固有的审慎。市面上AI平台层出不穷,每个都宣称自己“更优”、“更快”。但当我深入体验后,发现AiOnly的独特价值在于它真正做到了复杂技术的简单化。
最让我心动的几个发现:
- 模型生态丰富:从文本对话到视频生成,覆盖创作全流程
- 国内网络优化:直连专线让海外模型触手可及
- 统一接口设计:不同模型相似的调用逻辑,学习成本极低
- 即时体验功能:无需编码就能在线测试模型效果
作为一个既看重技术深度又追求创作效率的开发者,这种“开箱即用且深度可控”的平衡让我印象深刻。
三步上手:我的AiOnly入门实践
第一步:极简注册,立即开启AI之旅
注册流程的顺畅程度令人惊喜。访问官网后,我选择了微信扫码登录,真正实现了“秒级注册”。这种设计明显考虑了国内用户的使用习惯——谁还想记住又一个账号密码呢?
进入控制台后,清晰的界面布局让我这个新用户也能快速定位功能。左侧菜单栏的逻辑很直观,从模型体验到API管理,层次分明。
新人福利方面,15元代金券虽然不算巨额,但足够进行充分的测试验证,这种“先尝后买”的策略很贴心。
第二步:模型开通,视频生成触手可及
- 在开通模型前先到体验中心体验一波视频生成的魅力
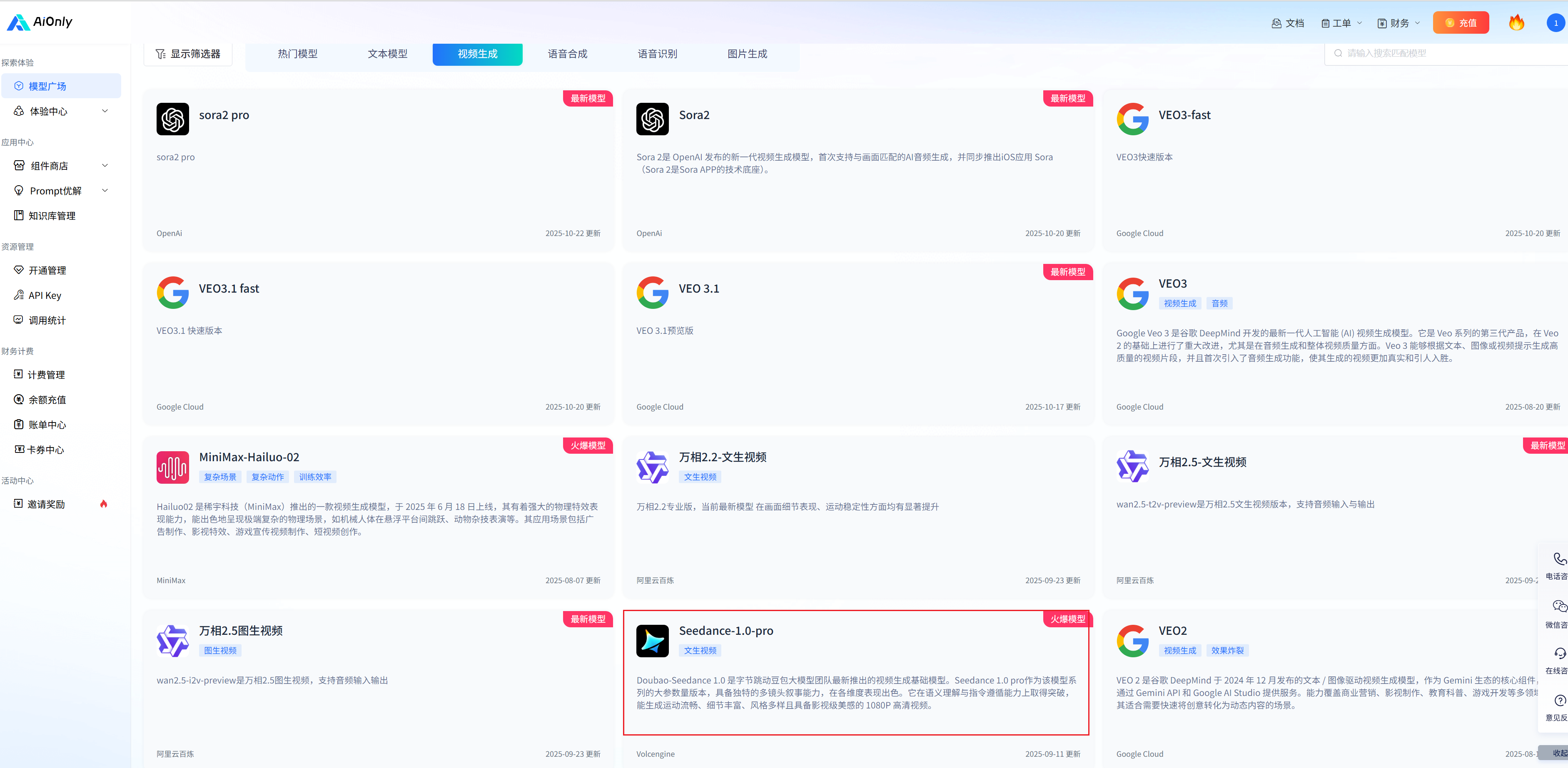
我输入了一段文字描述“一轮金色朝阳从云海山峰间缓缓升起,温暖的光芒穿透晨雾,在翻腾的云层上洒下绚丽的光辉,远处有飞鸟剪影掠过天空”,选择生成5s,点击立即生成(有两次免费额度),大概2分钟不到,我们看结果
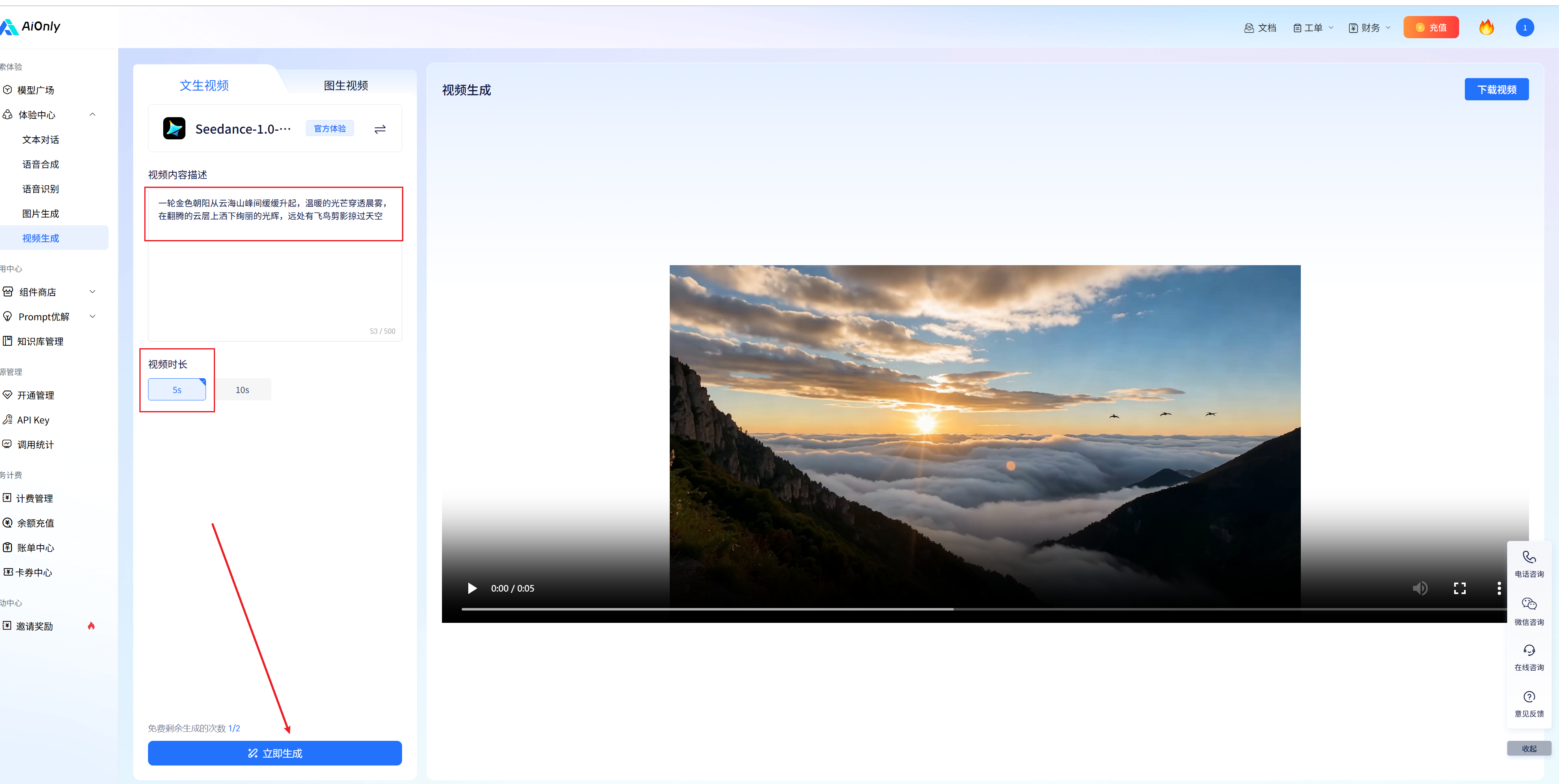
感觉真的不能再真实了,而且还是高清,着实给我震撼到了
- 接下来,在模型广场(https://www.aiionly.com/modelSquare)。开通流程极其简单:
- 找到“Volcengine- Seedance-1.0-pro”模型卡片
- 点击“开通服务”
- 选择按量付费模式(新手友好)
- 确认开通
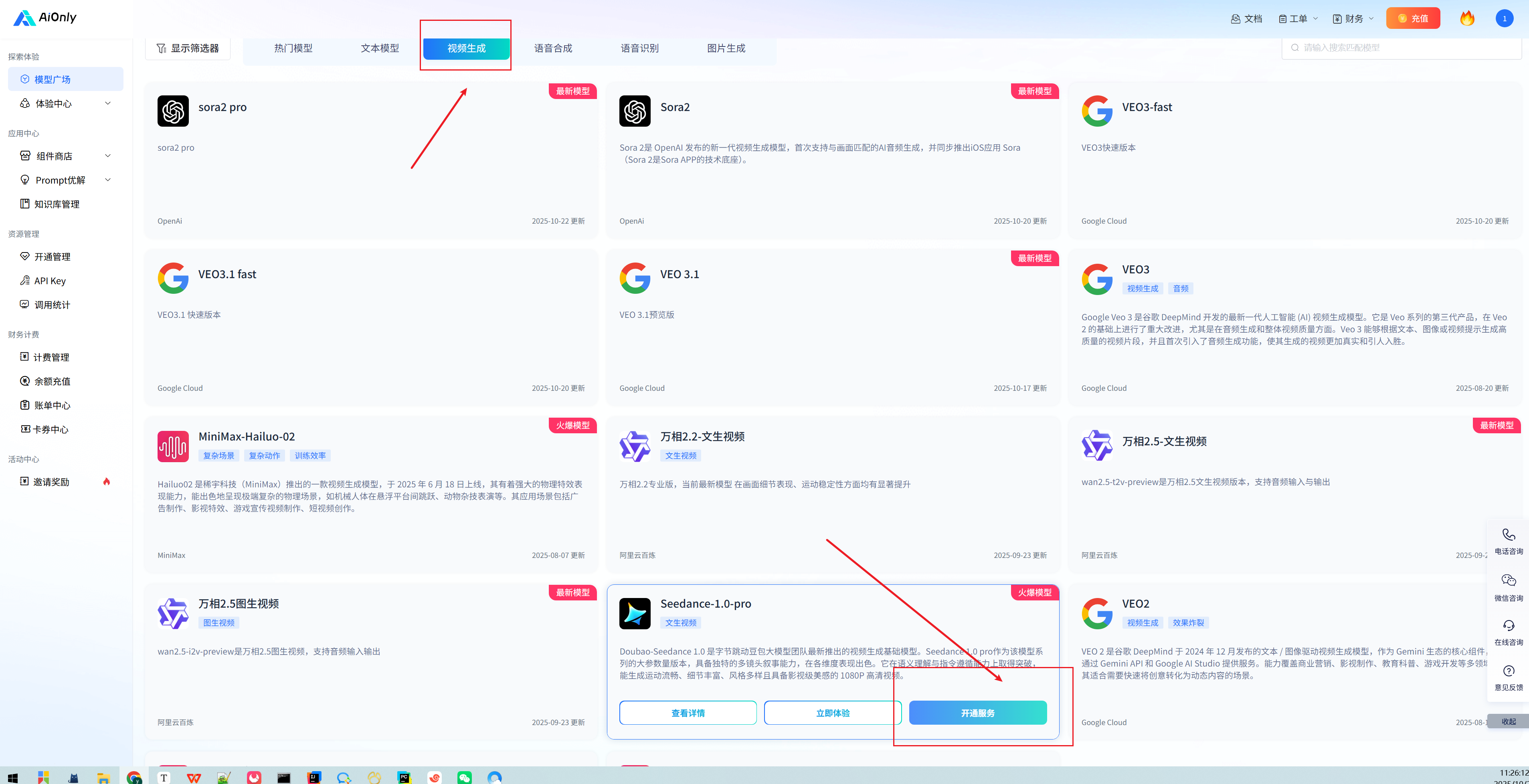
根据需求选择流量包还是后付费,整个过程不到10秒,没有任何冗余步骤。相比某些平台需要填写大量申请信息的繁琐流程,AiOnly的这种“轻量开通”体验确实让人心情愉悦。

第三步:密钥获取,安全与便捷兼得
在“API Key”页面创建密钥时(https://www.aiionly.com/keyApi),我注意到平台提供了标准模式和融合模式两种选择。作为视频生成的新手,我选择了标准模式。

创建密钥后,我立即在密码管理器中备份。虽然AiOnly提供了密钥显示功能,但良好的安全习惯同样重要。
技术深潜:用“火山即梦”点燃创作火花
环境准备:轻装上阵
与复杂的深度学习环境搭建相比,AiOnly的API调用简直是一种享受。只需要基础的HTTP请求库即可:
# 安装请求库
pip install requests
初试牛刀:我的第一个AI生成视频
我决定从一个简单的场景开始——创建一段关于海洋生物的短视频。以下是我的实现代码:
import requests
import json
import time
import base64
from pathlib import Path
from typing import Optional, List, Dict, Any
import osclass VideoCreator:"""视频生成器 - 支持火山即梦API"""# 模型配置MODELS = {"pro": "doubao-seedance-1.0-pro","lite_i2v": "doubao-seedance-1-0-lite-i2v"}# 分辨率选项RESOLUTIONS = ["480p", "720p", "1080p"]# 宽高比选项RATIOS = ["21:9", "16:9", "4:3", "1:1", "3:4", "9:16", "9:21", "keep_ratio", "adaptive"]# 时长选项DURATIONS = [5, 10]# 帧率选项FPS_OPTIONS = [16, 24]def __init__(self, api_key: Optional[str] = None, base_url: str = "https://api.aiionly.com"):"""初始化视频生成器Args:api_key: API密钥,如果为None则从环境变量获取base_url: API基础URL"""self.api_key = api_key or os.getenv("VOLC_AI_API_KEY")if not self.api_key:raise ValueError("API Key未提供,请设置参数或环境变量VOLC_AI_API_KEY")self.base_url = base_urlself.headers = {"Authorization": f"Bearer {self.api_key}","Content-Type": "application/json"}def _validate_image_params(self, image_path: str) -> bool:"""验证图片参数是否符合要求"""try:from PIL import Imagewith Image.open(image_path) as img:width, height = img.sizefile_size = os.path.getsize(image_path)# 检查宽高比ratio = width / heightif not (0.4 < ratio < 2.5):print(f"警告: 图片宽高比 {ratio:.2f} 不在推荐范围 (0.4, 2.5) 内")# 检查尺寸if not (300 <= width <= 6000 and 300 <= height <= 6000):print(f"警告: 图片尺寸 {width}x{height} 不在推荐范围 (300, 6000) 内")# 检查文件大小if file_size > 10 * 1024 * 1024: # 10MBprint(f"警告: 图片大小 {file_size / 1024 / 1024:.2f}MB 超过10MB限制")return Trueexcept Exception as e:print(f"图片验证失败: {str(e)}")return Falsedef _image_to_base64(self, image_path: str) -> Optional[str]:"""将图片转换为Base64格式"""try:# 验证图片if not self._validate_image_params(image_path):return Nonewith open(image_path, "rb") as image_file:image_data = image_file.read()# 获取图片格式file_extension = Path(image_path).suffix.lower().replace('.', '')if file_extension == 'jpg':file_extension = 'jpeg'base64_encoded = base64.b64encode(image_data).decode('utf-8')return f"data:image/{file_extension};base64,{base64_encoded}"except Exception as e:print(f"图片转换Base64失败: {str(e)}")return Nonedef create_video_task(self,prompt: str,duration: int = 5,resolution: str = "720p",ratio: str = "adaptive",fps: int = 24,watermark: bool = False,seed: int = -1,camera_fixed: bool = False,first_frame_image: Optional[str] = None,last_frame_image: Optional[str] = None,reference_images: Optional[List[str]] = None,model: str = "pro") -> Dict[str, Any]:"""创建视频生成任务Args:prompt: 文本提示词duration: 视频时长(秒)resolution: 分辨率ratio: 宽高比fps: 帧率watermark: 是否包含水印seed: 随机种子camera_fixed: 是否固定摄像头first_frame_image: 首帧图片路径last_frame_image: 尾帧图片路径reference_images: 参考图片路径列表model: 模型类型 ('pro' 或 'lite_i2v')"""# 参数验证if len(prompt) > 500:prompt = prompt[:500]print("提示词超过500字符,已自动截断")if duration not in self.DURATIONS:raise ValueError(f"时长必须是 {self.DURATIONS} 中的一个")if resolution not in self.RESOLUTIONS:raise ValueError(f"分辨率必须是 {self.RESOLUTIONS} 中的一个")if ratio not in self.RATIOS:raise ValueError(f"宽高比必须是 {self.RATIOS} 中的一个")if fps not in self.FPS_OPTIONS:raise ValueError(f"帧率必须是 {self.FPS_OPTIONS} 中的一个")# 构建输入参数input_data = {"prompt": prompt}# 处理首帧图片if first_frame_image:base64_img = self._image_to_base64(first_frame_image)if base64_img:input_data["first_frame_url"] = base64_imgelse:print("首帧图片处理失败,将不使用首帧图片")# 处理尾帧图片if last_frame_image:base64_img = self._image_to_base64(last_frame_image)if base64_img:input_data["last_frame_url"] = base64_imgelse:print("尾帧图片处理失败,将不使用尾帧图片")# 处理参考图片if reference_images:base64_images = []for img_path in reference_images[:4]: # 最多4张图片base64_img = self._image_to_base64(img_path)if base64_img:base64_images.append(base64_img)if base64_images:input_data["images"] = base64_images# 如果使用参考图片,自动切换到对应的模型if len(base64_images) > 0 and model == "pro":print("检测到参考图片,自动切换到 lite_i2v 模型")model = "lite_i2v"else:print("所有参考图片处理失败,将不使用参考图片")# 构建请求数据data = {"model": self.MODELS.get(model, self.MODELS["pro"]),"input": input_data,"parameters": {"duration": duration,"resolution": resolution,"ratio": ratio,"framepersecond": fps,"watermark": watermark,"seed": seed,"camerafixed": camera_fixed}}try:response = requests.post(f"{self.base_url}/v1/createVideo",headers=self.headers,json=data,timeout=30)response.raise_for_status()result = response.json()if result.get("code") == 200:return {"success": True,"task_id": result["data"]["task_id"],"status": result["data"]["task_status"],"raw_response": result}else:return {"success": False,"error": f"API错误: {result.get('message', '未知错误')}","code": result.get("code"),"raw_response": result}except requests.exceptions.RequestException as e:return {"success": False,"error": f"请求失败: {str(e)}"}except Exception as e:return {"success": False,"error": f"处理异常: {str(e)}"}def check_video_result(self,task_id: str,max_retries: int = 30,interval: int = 60,callback: Optional[callable] = None) -> Dict[str, Any]:"""检查视频生成结果Args:task_id: 任务IDmax_retries: 最大重试次数interval: 查询间隔(秒)callback: 回调函数,用于进度更新"""for attempt in range(max_retries):try:data = {"model": self.MODELS["pro"], # 查询时模型ID需要一致"taskId": task_id}response = requests.post(f"{self.base_url}/v1/getVideoResult",headers=self.headers,json=data,timeout=30)response.raise_for_status()result = response.json()if result.get("code") == 200:task_status = result["data"]["task_status"]if callback:callback(attempt + 1, max_retries, task_status)if task_status == "SUCCESS":return {"success": True,"status": task_status,"video_urls": result["data"].get("video_urls", []),"video_base64": result["data"].get("base64", []),"video_bytes": result["data"].get("bytes", []),"attempt": attempt + 1,"usage": result.get("usage", {}),"raw_response": result}elif task_status in ["PENDING", "PROCESSING"]:if attempt < max_retries - 1:time.sleep(interval)continueelse:return {"success": False,"error": f"任务失败,状态: {task_status}","raw_response": result}else:return {"success": False,"error": f"API错误: {result.get('message', '未知错误')}","code": result.get("code"),"raw_response": result}except requests.exceptions.RequestException as e:error_msg = f"第{attempt + 1}次查询失败: {str(e)}"if callback:callback(attempt + 1, max_retries, f"错误: {str(e)}")if attempt < max_retries - 1:time.sleep(interval)else:return {"success": False,"error": f"最终失败: {error_msg}"}return {"success": False,"error": f"超过最大重试次数({max_retries})"}def download_video(self, video_url: str, save_path: str) -> bool:"""下载视频文件"""try:response = requests.get(video_url, stream=True, timeout=60)response.raise_for_status()with open(save_path, 'wb') as f:for chunk in response.iter_content(chunk_size=8192):f.write(chunk)print(f"视频已保存到: {save_path}")return Trueexcept Exception as e:print(f"视频下载失败: {str(e)}")return Falsedef progress_callback(attempt: int, max_retries: int, status: str):"""进度回调函数示例"""print(f"[{attempt}/{max_retries}] 任务状态: {status}")# 使用示例
def main():# 方法1: 使用环境变量# export VOLC_AI_API_KEY="your-api-key-here"# 方法2: 直接传入API Keytry:creator = VideoCreator("sk-6284acaa302fe7cf881782993888888888888b928aab660c4eaf2230c1c55d73")except ValueError as e:print(f"初始化失败: {e}")return# 示例1: 纯文本生成视频print("=== 示例1: 文本生成视频 ===")task_result = creator.create_video_task(prompt="一只色彩斑斓的热带鱼在珊瑚礁中游动,阳光透过海水形成美丽的光束",duration=5,resolution="1080p",ratio="16:9")if task_result["success"]:print(f"任务创建成功! 任务ID: {task_result['task_id']}")print("等待视频生成...")video_result = creator.check_video_result(task_result['task_id'],callback=progress_callback)if video_result["success"]:print(f"视频生成成功! 经过{video_result['attempt']}次查询")video_urls = video_result.get("video_urls") or \video_result.get("raw_response", {}).get("data", {}).get("url", [])if video_urls:print("视频链接:", video_urls)# 下载视频creator.download_video(video_urls[0],"output_video.mp4")print("视频已下载到: output_video.mp4")else:print("未找到视频链接")else:print(f"视频生成失败: {video_result.get('error', '未知错误')}")else:print(f"任务创建失败: {task_result.get('error', '未知错误')}")if __name__ == "__main__":main()
运行这个脚本时,我经历了从期待到惊喜的过程。大约等待了2-3分钟后,我得到了第一个AI生成的视频——一条逼真的热带鱼在珊瑚礁中游动的5秒视频。虽然有些细节还不够完美,但整体效果已经远超我的预期。

鱼
进阶探索:图生视频的魔法
在掌握了基础文本生视频后,我尝试了更高级的图生视频功能。这需要提供首帧图片,让AI基于图片内容生成动态视频:
import requests
import json
import time
from pathlib import Path
from typing import Optional, List, Dict, Any, Union
import osclass VideoCreator:"""视频生成器 - 支持火山即梦API"""# 模型配置MODELS = {"pro": "doubao-seedance-1.0-pro","lite_i2v": "doubao-seedance-1-0-lite-i2v"}# 分辨率选项RESOLUTIONS = ["480p", "720p", "1080p"]# 宽高比选项RATIOS = ["21:9", "16:9", "4:3", "1:1", "3:4", "9:16", "9:21", "keep_ratio", "adaptive"]# 时长选项DURATIONS = [5, 10]# 帧率选项FPS_OPTIONS = [16, 24]def __init__(self, api_key: Optional[str] = None, base_url: str = "https://api.aiionly.com"):"""初始化视频生成器Args:api_key: API密钥,如果为None则从环境变量获取base_url: API基础URL"""self.api_key = api_key or os.getenv("VOLC_AI_API_KEY")if not self.api_key:raise ValueError("API Key未提供,请设置参数或环境变量VOLC_AI_API_KEY")self.base_url = base_urlself.headers = {"Authorization": f"Bearer {self.api_key}","Content-Type": "application/json"}def _validate_image_url(self, image_url: str) -> bool:"""验证图片URL是否有效"""try:response = requests.head(image_url, timeout=10)content_type = response.headers.get('content-type', '')if not content_type.startswith('image/'):print(f"警告: URL不是图片类型: {content_type}")return False# 检查常见图片格式valid_formats = ['jpeg', 'jpg', 'png', 'webp', 'gif']if not any(fmt in content_type for fmt in valid_formats):print(f"警告: 不支持的图片格式: {content_type}")return Falsereturn Trueexcept Exception as e:print(f"图片URL验证失败: {str(e)}")return Falsedef create_video_from_image(self,prompt: str,image_url: str,duration: int = 5,resolution: str = "720p",ratio: str = "keep_ratio",fps: int = 24,watermark: bool = False,seed: int = -1,camera_fixed: bool = False,model: str = "pro") -> Dict[str, Any]:"""基于首帧图片URL生成视频Args:prompt: 文本提示词image_url: 首帧图片URLduration: 视频时长(秒)resolution: 分辨率ratio: 宽高比,默认保持图片原始比例fps: 帧率watermark: 是否包含水印seed: 随机种子camera_fixed: 是否固定摄像头model: 模型类型 ('pro' 或 'lite_i2v')"""return self.create_video_task(prompt=prompt,duration=duration,resolution=resolution,ratio=ratio,fps=fps,watermark=watermark,seed=seed,camera_fixed=camera_fixed,first_frame_image=image_url,model=model)def create_video_from_images(self,prompt: str,reference_image_urls: List[str],duration: int = 5,resolution: str = "720p",ratio: str = "adaptive",fps: int = 24,watermark: bool = False,seed: int = -1,camera_fixed: bool = False) -> Dict[str, Any]:"""基于多张参考图片URL生成视频Args:prompt: 文本提示词reference_image_urls: 参考图片URL列表duration: 视频时长(秒)resolution: 分辨率ratio: 宽高比fps: 帧率watermark: 是否包含水印seed: 随机种子camera_fixed: 是否固定摄像头"""return self.create_video_task(prompt=prompt,duration=duration,resolution=resolution,ratio=ratio,fps=fps,watermark=watermark,seed=seed,camera_fixed=camera_fixed,reference_images=reference_image_urls,model="lite_i2v" # 多图生成自动使用lite_i2v模型)def create_video_task(self,prompt: str,duration: int = 5,resolution: str = "720p",ratio: str = "adaptive",fps: int = 24,watermark: bool = False,seed: int = -1,camera_fixed: bool = False,first_frame_image: Optional[str] = None,last_frame_image: Optional[str] = None,reference_images: Optional[List[str]] = None,model: str = "pro") -> Dict[str, Any]:"""创建视频生成任务(完整接口)Args:prompt: 文本提示词duration: 视频时长(秒)resolution: 分辨率ratio: 宽高比fps: 帧率watermark: 是否包含水印seed: 随机种子camera_fixed: 是否固定摄像头first_frame_image: 首帧图片URLlast_frame_image: 尾帧图片URLreference_images: 参考图片URL列表model: 模型类型 ('pro' 或 'lite_i2v')"""# 参数验证if len(prompt) > 500:prompt = prompt[:500]print("提示词超过500字符,已自动截断")if duration not in self.DURATIONS:raise ValueError(f"时长必须是 {self.DURATIONS} 中的一个")if resolution not in self.RESOLUTIONS:raise ValueError(f"分辨率必须是 {self.RESOLUTIONS} 中的一个")if ratio not in self.RATIOS:raise ValueError(f"宽高比必须是 {self.RATIOS} 中的一个")if fps not in self.FPS_OPTIONS:raise ValueError(f"帧率必须是 {self.FPS_OPTIONS} 中的一个")# 构建输入参数input_data = {"prompt": prompt}# 处理首帧图片URLif first_frame_image:if self._validate_image_url(first_frame_image):input_data["first_frame_url"] = first_frame_imageprint(f"✅ 已添加首帧图片URL: {first_frame_image}")else:print("❌ 首帧图片URL验证失败,将不使用首帧图片")# 处理尾帧图片URLif last_frame_image:if self._validate_image_url(last_frame_image):input_data["last_frame_url"] = last_frame_imageprint(f"✅ 已添加尾帧图片URL: {last_frame_image}")else:print("❌ 尾帧图片URL验证失败,将不使用尾帧图片")# 处理参考图片URLif reference_images:valid_image_urls = []for img_url in reference_images[:4]: # 最多4张图片if self._validate_image_url(img_url):valid_image_urls.append(img_url)print(f"✅ 已添加参考图片URL: {img_url}")else:print(f"❌ 参考图片URL验证失败: {img_url}")if valid_image_urls:input_data["images"] = valid_image_urls# 如果使用参考图片,自动切换到对应的模型if len(valid_image_urls) > 0 and model == "pro":print("🔄 检测到参考图片,自动切换到 lite_i2v 模型")model = "lite_i2v"else:print("❌ 所有参考图片URL验证失败,将不使用参考图片")# 构建请求数据data = {"model": self.MODELS.get(model, self.MODELS["pro"]),"input": input_data,"format": "url","parameters": {"duration": duration}}try:print("🚀 正在创建视频生成任务...")response = requests.post(f"{self.base_url}/v1/createVideo",headers=self.headers,json=data,timeout=60)response.raise_for_status()result = response.json()if result.get("code") == 200:print(f"✅ 任务创建成功! 任务ID: {result['data']['task_id']}")return {"success": True,"task_id": result["data"]["task_id"],"status": result["data"]["task_status"],"raw_response": result}else:error_msg = f"API错误: {result.get('message', '未知错误')}"print(f"❌ {error_msg}")return {"success": False,"error": error_msg,"code": result.get("code"),"raw_response": result}except requests.exceptions.RequestException as e:error_msg = f"请求失败: {str(e)}"print(f"❌ {error_msg}")return {"success": False,"error": error_msg}except Exception as e:error_msg = f"处理异常: {str(e)}"print(f"❌ {error_msg}")return {"success": False,"error": error_msg}def check_video_result(self,task_id: str,max_retries: int = 10,interval: int = 300,callback: Optional[callable] = None) -> Dict[str, Any]:"""检查视频生成结果Args:task_id: 任务IDmax_retries: 最大重试次数interval: 查询间隔(秒)callback: 回调函数,用于进度更新"""for attempt in range(max_retries):try:data = {"model": self.MODELS["pro"], # 查询时模型ID需要一致"taskId": task_id}response = requests.post(f"{self.base_url}/v1/getVideoResult",headers=self.headers,json=data,timeout=300)response.raise_for_status()result = response.json()if result.get("code") == 200:task_status = result["data"]["task_status"]if callback:callback(attempt + 1, max_retries, task_status)if task_status == "SUCCESS":print(f"🎉 视频生成成功! 经过{attempt + 1}次查询")return {"success": True,"status": task_status,"video_urls": result["data"].get("video_urls", []),"video_base64": result["data"].get("base64", []),"video_bytes": result["data"].get("bytes", []),"attempt": attempt + 1,"usage": result.get("usage", {}),"raw_response": result}elif task_status in ["PENDING", "PROCESSING"]:status_msg = f"[{attempt + 1}/{max_retries}] 任务状态: {task_status}"print(status_msg)if attempt < max_retries - 1:time.sleep(interval)continueelse:error_msg = f"任务失败,状态: {task_status}"print(f"❌ {error_msg}")return {"success": False,"error": error_msg,"raw_response": result}else:error_msg = f"API错误: {result.get('message', '未知错误')}"print(f"❌ {error_msg}")return {"success": False,"error": error_msg,"code": result.get("code"),"raw_response": result}except requests.exceptions.RequestException as e:error_msg = f"第{attempt + 1}次查询失败: {str(e)}"if callback:callback(attempt + 1, max_retries, f"错误: {str(e)}")print(f"⚠️ {error_msg}")if attempt < max_retries - 1:time.sleep(interval)else:return {"success": False,"error": f"最终失败: {error_msg}"}return {"success": False,"error": f"超过最大重试次数({max_retries})"}def download_video(self, video_url: str, save_path: str) -> bool:"""下载视频文件"""try:print(f"📥 正在下载视频到: {save_path}")response = requests.get(video_url, stream=True, timeout=60)response.raise_for_status()with open(save_path, 'wb') as f:for chunk in response.iter_content(chunk_size=8192):f.write(chunk)print(f"✅ 视频已保存到: {save_path}")return Trueexcept Exception as e:print(f"❌ 视频下载失败: {str(e)}")return Falsedef generate_and_download(self,prompt: str,output_path: str = "output_video.mp4",image_url: Optional[str] = None,reference_image_urls: Optional[List[str]] = None,**kwargs) -> bool:"""一键生成并下载视频的便捷方法Args:prompt: 文本提示词output_path: 输出视频路径image_url: 首帧图片URL(可选)reference_image_urls: 参考图片URL列表(可选)**kwargs: 其他参数传递给create_video_task"""# 根据输入类型选择生成方式if image_url and reference_image_urls:print("⚠️ 同时提供了首帧图片和参考图片,将使用参考图片模式")task_result = self.create_video_from_images(prompt=prompt,reference_image_urls=reference_image_urls,**kwargs)elif image_url:task_result = self.create_video_from_image(prompt=prompt,image_url=image_url,**kwargs)elif reference_image_urls:task_result = self.create_video_from_images(prompt=prompt,reference_image_urls=reference_image_urls,**kwargs)else:task_result = self.create_video_task(prompt=prompt,**kwargs)if not task_result["success"]:return Falseprint("⏳ 等待视频生成...")video_result = self.check_video_result(task_result['task_id'],callback=progress_callback)if video_result["success"]:video_urls = video_result.get("video_urls") or \video_result.get("raw_response", {}).get("data", {}).get("url", [])if video_urls:return self.download_video(video_urls[0], output_path)else:print("❌ 未找到视频链接")return Falseelse:print(f"❌ 视频生成失败: {video_result.get('error', '未知错误')}")return Falsedef progress_callback(attempt: int, max_retries: int, status: str):"""进度回调函数示例"""print(f"[{attempt}/{max_retries}] 任务状态: {status}")# 使用示例
def main():# 方法1: 使用环境变量# export VOLC_AI_API_KEY="your-api-key-here"# 方法2: 直接传入API Keytry:creator = VideoCreator("sk-6284acaa302fe7cf888888888888b040064258b928aab660c4eaf2230c1c55d73")print(f"VideoCreator初始化成功")except ValueError as e:print(f"❌ 初始化失败: {e}")return# 示例1: 图生视频(使用图片URL)print("\n=== 示例: 图生视频(使用URL)===")success = creator.generate_and_download(prompt="电影感广角镜头,图片中这位领袖在台上激动地演讲。当他说到'本来应该从从容容游刃有余'时,字幕也要放在视频中,镜头从他的特写开始缓慢向后拉远,揭示出整个礼堂里众多被感动的听众,有些人正在点头,有些人若有所思。现场有强烈的聚光灯和细微的烟雾效果。风格写实,有轻微的手持摄像机晃动感,增强临场感。",image_url="https://img2.baidu.com/it/u=3612573118,3028273726&fm=253&fmt=auto&app=120&f=JPEG?w=667&h=500", # 替换为实际图片URLoutput_path="image_to_video.mp4",duration=5,ratio="keep_ratio" # 保持图片原始比例)if success:print("🎊 图生视频完成!")else:print("💥 图生视频失败!")if __name__ == "__main__":main()
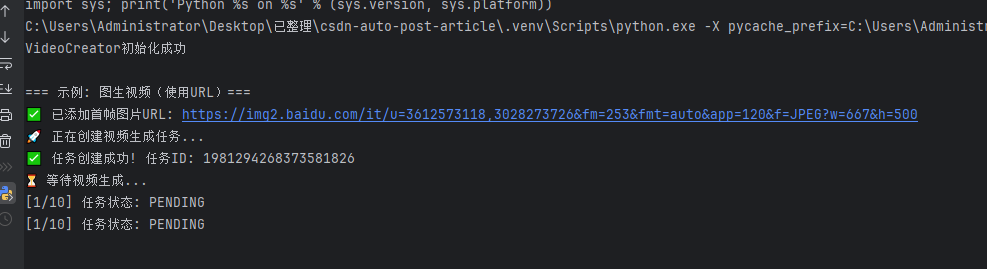
这个功能让我能够更好地控制视频的初始画面,实现了从静态图片到动态视频的平滑过渡。
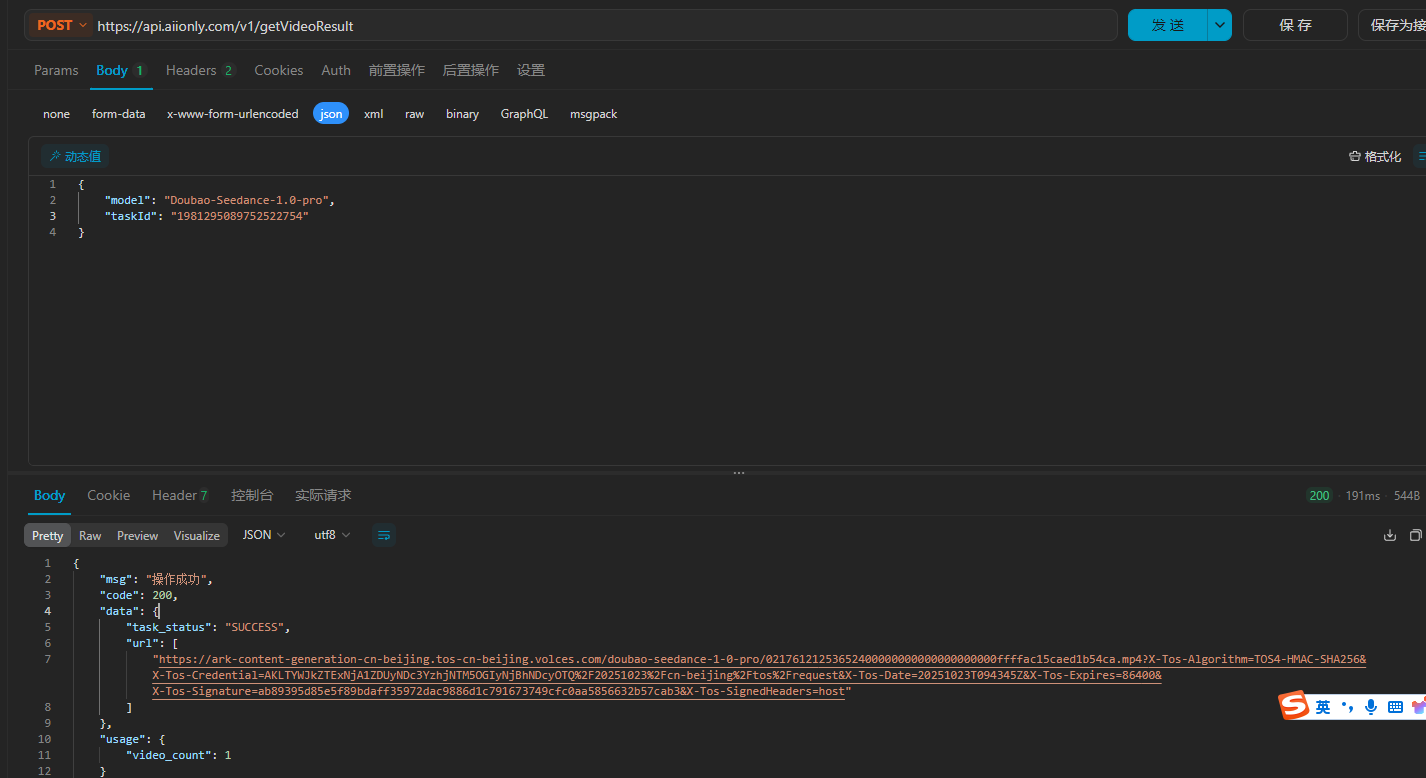
02176121253652400000000000000000000ffffac15caed1b54ca
实战项目:打造个性化视频创作工作流
基于前面的探索,我构建了一个完整的视频创作系统,专门用于快速生成社交媒体短视频内容。
系统设计理念
我希望这个系统具备:
- 批量处理能力:一次性生成多个视频创意
- 智能提示词优化:自动完善用户输入的描述
- 质量评估机制:对生成的视频进行初步筛选
- 模板化配置:支持不同类型的视频风格预设
完整实现
import requests
import json
import time
from datetime import datetime
from typing import List, Dict
import threading
from queue import Queueclass AdvancedVideoStudio:def __init__(self, api_key):self.api_key = api_keyself.base_url = "https://api.aiionly.com"self.headers = {"Authorization": f"Bearer {api_key}","Content-Type": "application/json"}# 视频风格预设self.style_presets = {"cinematic": {"prompt_suffix": ",电影感,高质量,4K","parameters": {"resolution": "1080p", "framepersecond": 24}},"social_media": {"prompt_suffix": ",短视频风格,动态,吸引眼球","parameters": {"resolution": "720p", "duration": 5}},"educational": {"prompt_suffix": ",教育内容,清晰,信息丰富","parameters": {"resolution": "1080p", "duration": 10}}}self.task_queue = Queue()self.results = []def enhance_prompt(self, basic_prompt, style="cinematic"):"""增强提示词"""preset = self.style_presets.get(style, self.style_presets["cinematic"])return basic_prompt + preset["prompt_suffix"]def create_batch_videos(self, prompts: List[Dict], max_concurrent=2):"""批量创建视频"""threads = []def worker():while not self.task_queue.empty():task_data = self.task_queue.get()try:result = self._create_single_video(task_data)self.results.append(result)finally:self.task_queue.task_done()# 添加任务到队列for prompt_data in prompts:self.task_queue.put(prompt_data)# 创建工作者线程for _ in range(min(max_concurrent, len(prompts))):thread = threading.Thread(target=worker)thread.start()threads.append(thread)# 等待所有任务完成self.task_queue.join()for thread in threads:thread.join()return self.resultsdef _create_single_video(self, prompt_data):"""创建单个视频"""enhanced_prompt = self.enhance_prompt(prompt_data["prompt"], prompt_data.get("style", "cinematic"))# 创建视频任务create_data = {"model": "doubao-seedance-1.0-pro","input": {"prompt": enhanced_prompt},"parameters": self.style_presets.get(prompt_data.get("style", "cinematic"), self.style_presets["cinematic"])["parameters"]}response = requests.post(f"{self.base_url}/v1/createVideo",headers=self.headers,json=create_data,timeout=30)if response.status_code == 200:result = response.json()if result["code"] == "200":task_id = result["data"]["task_id"]# 等待结果video_result = self._wait_for_video(task_id)return {"original_prompt": prompt_data["prompt"],"enhanced_prompt": enhanced_prompt,"task_id": task_id,"result": video_result,"timestamp": datetime.now().isoformat()}return {"original_prompt": prompt_data["prompt"],"error": "任务创建失败","timestamp": datetime.now().isoformat()}def _wait_for_video(self, task_id, max_wait=300):"""等待视频生成完成"""start_time = time.time()while time.time() - start_time < max_wait:result = self._check_video_status(task_id)if result["status"] in ["SUCCESS", "FAILED"]:return resulttime.sleep(10) # 每10秒检查一次return {"status": "TIMEOUT", "error": "等待超时"}def _check_video_status(self, task_id):"""检查视频状态"""data = {"model": "doubao-seedance-1.0-pro","taskId": task_id}response = requests.post(f"{self.base_url}/v1/getVideoResult",headers=self.headers,json=data,timeout=30)if response.status_code == 200:result = response.json()if result["code"] == "200":return {"status": result["data"]["task_status"],"video_urls": result["data"].get("video_urls", [])}return {"status": "CHECK_FAILED", "error": "状态检查失败"}# 使用示例
def demo_advanced_studio():studio = AdvancedVideoStudio("你的API密钥")# 准备批量视频任务video_tasks = [{"prompt": "日出时分的山脉,云海翻腾", "style": "cinematic"},{"prompt": "城市夜景,车流轨迹,延时摄影", "style": "cinematic"},{"prompt": "健身教学动作演示", "style": "educational"},{"prompt": "美食制作过程,特写镜头", "style": "social_media"}]print("开始批量生成视频...")results = studio.create_batch_videos(video_tasks)# 输出结果统计success_count = sum(1 for r in results if r.get("result", {}).get("status") == "SUCCESS")print(f"批量生成完成!成功: {success_count}/{len(video_tasks)}")for result in results:if result.get("result", {}).get("status") == "SUCCESS":print(f"✅ {result['original_prompt']}")print(f" 视频链接: {result['result']['video_urls']}")else:print(f"❌ {result['original_prompt']}")print(f" 错误: {result.get('error', '未知错误')}")if __name__ == "__main__":demo_advanced_studio()
这个高级视频工作室让我能够在短时间内生成多个不同风格的视频内容,极大地提升了创作效率。
使用体验:惊喜与挑战并存
令人印象深刻的亮点
生成质量超出预期
“火山即梦”模型的视频生成质量让我这个AI视频生成的老用户都感到惊喜。特别是在自然场景和抽象概念的表现上,画面的连贯性和真实感都达到了商用水平。
响应速度优秀
即使在高峰期,API的响应速度也保持在合理范围内。视频生成任务通常在2-5分钟内完成,对于创意工作流程来说完全可接受。
参数调校灵活
平台提供了丰富的参数选项,从视频时长、分辨率到帧率和水印控制,让用户能够精细调整输出效果。
需要关注的挑战
提示词敏感性
视频生成质量高度依赖提示词的准确性。需要一定的技巧和经验才能写出能产生理想效果的提示词。
生成时间波动
虽然大多数任务在5分钟内完成,但偶尔会遇到需要更长时间的情况,这在批量处理时需要做好时间预算。
成本控制
视频生成的token消耗相对较高,需要密切监控使用量,避免意外费用。
成本优化策略
为了在保证质量的同时控制成本,我总结了一些实用策略:
class CostOptimizer:def __init__(self, daily_budget=100):self.daily_spent = 0self.daily_budget = daily_budgetself.today = datetime.now().date()def can_create_video(self, estimated_cost=10):"""检查是否可以在预算内创建视频"""# 检查日期是否变化current_date = datetime.now().date()if current_date != self.today:self.daily_spent = 0self.today = current_datereturn self.daily_spent + estimated_cost <= self.daily_budgetdef record_usage(self, cost):"""记录使用成本"""self.daily_spent += costdef get_optimized_parameters(self, use_case):"""根据使用场景返回优化参数"""optimizations = {"prototype": {"duration": 3, "resolution": "480p"},"social_media": {"duration": 5, "resolution": "720p"},"premium": {"duration": 10, "resolution": "1080p"}}return optimizations.get(use_case, optimizations["social_media"])
创作心得:AI视频生成的最佳实践
经过大量测试,我总结出一些提升视频生成质量的经验:
- 提示词要具体而生动:不只是"一只猫",而是"一只橘色条纹猫在阳光下慵懒地伸展"
- 利用风格预设:根据内容类型选择合适的风格参数
- 分批生成策略:先生成短版本验证效果,再制作完整版
- 多角度尝试:对同一主题尝试不同的提示词角度
总结:为什么AiOnly成为我的创作利器
经过深度使用,AiOnly平台的"火山即梦"视频生成服务已经成为了我内容创作工具箱中的核心组件。
核心优势总结:
- 技术门槛极低:简单的API设计让开发者快速集成
- 生成质量可靠:在多数场景下都能产出可用内容
- 性价比优秀:相比自建视频生成基础设施,成本优势明显
- 生态完整:文本、图像、视频生成能力形成完整工作流
- 本土化服务:中文支持、国内网络优化、符合国内用户习惯
对于内容创作者、营销人员和开发者来说,AiOnly提供的视频生成能力大大降低了高质量视频内容的制作门槛。从社交媒体短视频到产品演示,从教育内容到创意艺术,应用场景广泛。
体验过程中使用的AiOnly平台:https://www.aiionly.com/login/2150776962
火山即梦模型为视频创作带来了新的可能,让我们期待AI技术在创意领域的更多突破。建议读者亲自注册体验,开启属于你的视频创作之旅。