kettle的使用
Kettle(现称Pentaho Data Integration)是一款开源的ETL(Extract, Transform, Load)工具,用于数据集成、清洗和迁移。以下是简明使用指南:
核心概念
- 转换(Transformation)
- 由多个步骤(Step)组成的数据处理流程,例如:读取数据 → 过滤 → 计算字段 → 写入数据库。
- 步骤间通过跳(Hop)连接,数据流并行执行。
- 作业(Job)
- 按顺序执行的任务集合(如转换、脚本、邮件通知),支持定时调度和条件分支。
基础操作流程
1. 安装与启动
- 需Java环境(JDK 8+)
- 下载官网社区版,解压后运行
spoon.sh(Linux/Mac)或spoon.bat(Windows)。
2. 创建转换
- 输入数据
拖拽输入步骤(如表输入、CSV文件输入)→ 配置数据源(数据库连接/文件路径)。 - 数据转换
添加转换步骤(如过滤记录、计算器、排序记录)。 - 输出数据
拖拽输出步骤(如表输出、文本文件输出)→ 配置目标位置。
3. 调试与运行
- 单击步骤按F7预览数据。
- 点击工具栏 ▶ 按钮运行转换。
- 日志视图查看执行详情。
常用步骤示例
[CSV输入] → [字段选择] → [值映射] → [表输出]
- CSV文件输入
- 指定文件路径、分隔符(如
,)、编码格式(UTF-8)。
- 指定文件路径、分隔符(如
- 字段选择
- 筛选或重命名字段(如
user_id → id)。
- 筛选或重命名字段(如
- 值映射
- 替换值(如将
gender: "M"→"男")。
- 替换值(如将
- 表输出
- 选择数据库连接,指定目标表,启用「批量插入」提升性能。
关键配置技巧
- 数据库连接
在左侧「主对象树」→「数据库」右键新建连接(JDBC驱动需放入lib目录)。 - 参数化
- 使用
${变量名}动态传递路径/条件(如:SELECT * FROM ${TABLE_NAME})。 - 通过
ktr/kjb文件启动时命令行传参:kitchen.sh -file=job.kjb -param:TABLE_NAME=users
- 使用
- 错误处理
在跳的连线上右键 → 「错误处理」→ 定义失败后的重定向或日志记录。
进阶功能
- 作业调度
用作业设置定时任务(结合cron或系统计划任务)。 - 插件扩展
支持Python脚本、R语言、Kafka等插件(需下载后放入plugins目录)。 - 性能优化
- 调整「提交记录数量」(表输出步骤)。
- 启用「分布式执行」分担负载。
调试建议
- 分阶段运行:逐步启用步骤排查问题。
- 使用
写日志步骤输出中间结果。 - 资源监控:关注
执行结果面板的耗时和内存占用。mysql
⚠️ 注意:处理大数据时避免全表扫描,优先在SQL输入阶段过滤数据。
mysql导入hive
输入是 表输入,使用 mysql ,输出是表输出,使用 hive
如果直接做,报错
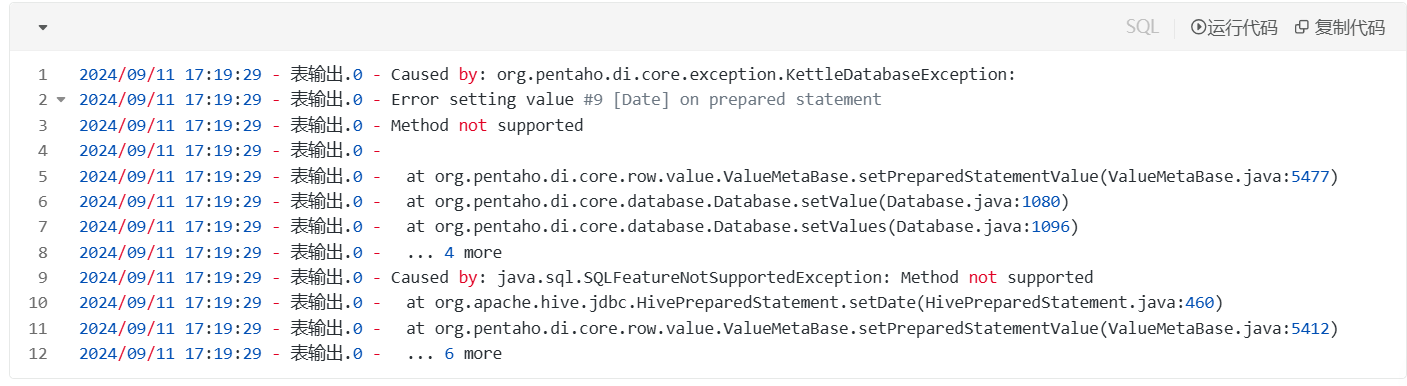
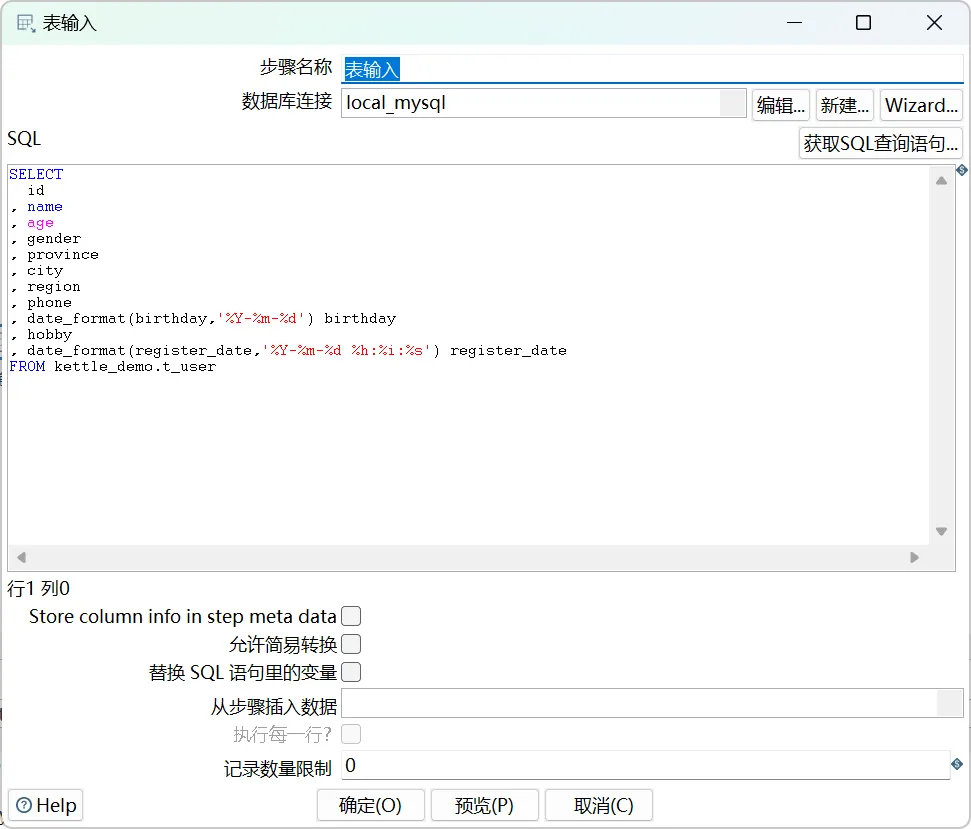
通过查看错误,发现是 Date 类型的错误,所以,修改表输入中的 SQL 语句:
SELECT
id
, name
, age
, gender
, province
, city
, region
, phone
, date_format(birthday,'%Y-%m-%d') birthday
, hobby
, date_format(register_date,'%Y-%m-%d %h:%i:%s') register_date
FROM kettle_demo.t_user
问题解决

有时候,运行成功,有时候只能导入 2 条数据,然后报错,可以在 hive 的 conf 下的 .hiverc 下,添加如下:
set hive.stats.column.autogather=false;
然后不需要重启 hiveserver2 以及 kettle,直接运行即可。
如果还不行,直接修改 hive-site.xml
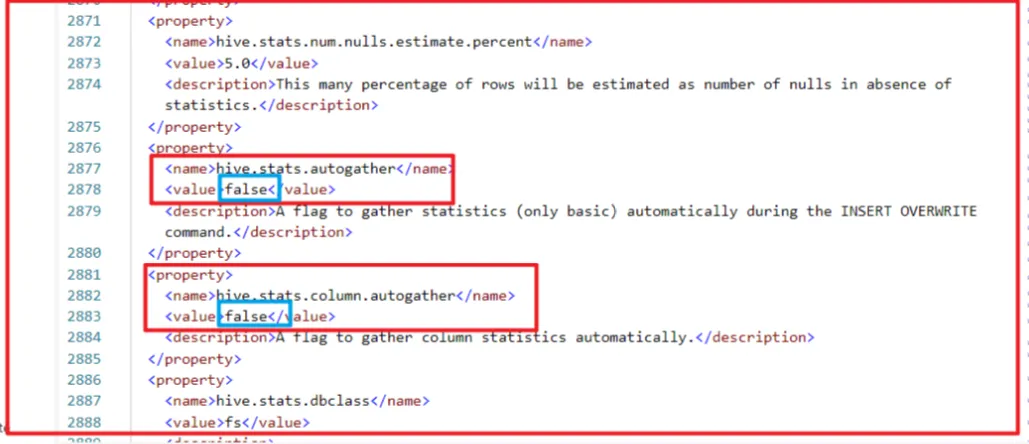
把里面的true改为false 重启hive和kettle 。
通过以上流程,可快速完成数据抽取、清洗到加载的全流程。官方文档和社区论坛(如Jira)是解决复杂问题的有效资源。