大模型系列001-----NLP基础知识
文章目录
- 一、NLP概述
-
- 1. 相关企业应用
- 2. 处理流程
- 二、常用第三方库
- 三、自然语言处理基本点
-
- 1. 语料库(Corpus)
- 2. 新词发现
- 3. 中文分词(Chinese Word egmentation)
- 4. 词性标注(Part-of-speech tagging)
- 5. 句法分析(Parsing)
- 6. 词干提取(Stemming)
- 7. 词形还原(Lemmatization)
- 8. 停用词过滤(stopwords)
- 9. 命名实体消歧(Named Entity Disambiguation)
- 10. 命名实体识别(NER)
- 11. 词向量
- 四、常见语言模型
-
- 1. Word2Vec
- 2. RNN
- 3. LSTM
- 4. Bert
- 5. Transform
- 五、相关技术
-
- 1. Emmbeeding Model
- 2. 模型蒸馏(Model Distillation)
一、NLP概述
NLP(Natural Language Processing), 即自然语言处理,它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。让计算机处理或“理解”自然语言,以执行语言翻译和问题回答等任务
自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系,但又有重要的区别。自然语言处理并不是一般地研究自然语言,而在于研制能有效地实现自然语言通信的计算机系统,特别是其中的软件系统。因而它是计算机科学的一部分
自然语言处理主要应用于机器翻译、舆情监测、自动摘要、观点提取、文本分类、问题回答、文本语义对比、语音识别、中文OCR等方面,以及 关键词提取,命名实体识别(Named Entity Recognition,简称NER)(提取价格、日期、人员、公司等) ,关系抽取 ,分类:文本分类、情感分析等
1. 相关企业应用
-
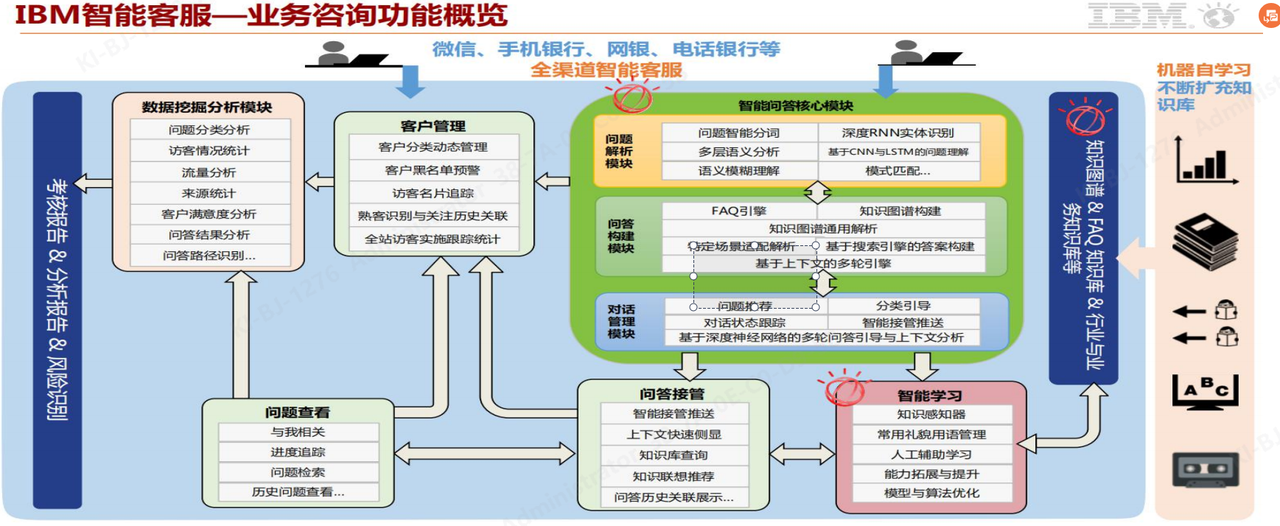
IBM 智能客服
-
京东NLP框架
![[图片]](https://i-blog.csdnimg.cn/direct/06df330ad6e94118972904d1000682e6.png)
2. 处理流程
2.1 处理流程
![[图片]](https://i-blog.csdnimg.cn/direct/a08eae676a8142959443dd1ec47afaed.png)
2.2 系统输入源
自然语言处理系统的输入源一共有 3 个 ,即语音、图像与文本 。其中文本处理是重中之重 ,其他两种数据最后也一般先要转化为文本才能进行后续的处理任务 ,对应的处理分别为语音识别(Speech Recognition)和光学字符识别(Optical Character Recognition,OCR)。
3. 常用名词中英对照报表
- OCR(Optical Character Recognition)–光学字符识别
- Speech Recognition–语音识别
- NLP(Natural Language Processing)–自然语言处理
- Tokenization–分词
- BOW(bag of word )–词袋法
- SOW(set of word)–词集法
- Part-of-Speech Tagging --词性标注
- NER(Named Entity Recognition)–命名实体识别
- Stemming–词干提取
- Lemmatization–词形还原
- Sentiment Analysis–情感分析
- Corpus–语料库
- 知识图谱 – Knowledge Graph
- 机器翻译 – Machine Translation
- 文本摘要 – Text Summarization
- 对话系统 – Dialogue System
- 自然语言生成 – Natural Language Generation
- 命名实体消歧 – Named Entity Disambiguation
- CBOW(continuous bag of words) – 连续词袋模型
二、常用第三方库
[图片]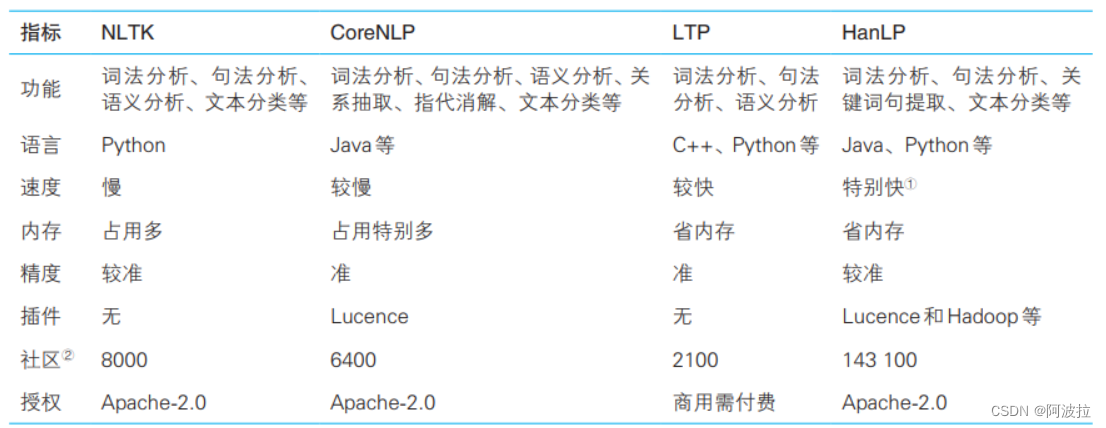
- Jieba
- 结巴分词是最受欢迎的中文分词工具
- 用法和介绍参考:python之jieba分词库使用
- HanLP
- Han Language Processing,作者何晗,用法参考:
- HanLP安装与使用
- HanLP 自然语言处理使用总结
- 常用于分词,词性标注
- NLTK
NLTK(Natural Language Toolkit) ,是一个功能强大、广泛使用的自然语言处理库,最初由宾夕法尼亚大学的计算机科学系,由Steven Bird、Ewan Klein和Edward Loper三位教授和研究员共同开发。现在NLTK已经成为了NLP领域中使用最广泛的一款自然语言处理工具包。NLTK从2001年开始开发,到现在已经发布了5个版本,包含了大量的语言学研究和计算语言学的内容,同时还提供了相关数据、文本和语言模型等方面的支持。
- Python自然语言处理:NLTK入门指南
- Python自然语言处理:NLTK库详解
- CoreNLP
斯坦福大学开发的 - gensim
Gensim是一款开源的第三方Python工具包(词向量转换工具),用于从原始的非结构化的文本中,无监督地学习到文本隐层的主题向量表达。它支持包括TF-IDF,LSA,LDA,和word2vec在内的多种主题模型算法,支持流式