《剖析 Linux 文件系统:架构、原理与实战操作指南》


前引:文件系统是 Linux 系统的 “骨架”—— 它不仅决定了文件如何存储、读取,更直接影响系统的稳定性与性能。无论是 EXT4、XFS 等常见文件系统,还是 “挂载”“分区” 等核心操作,背后都有一套严谨的工作机制。本文将拆解 Linux 文件系统的底层架构,详解 inode、超级块、目录项的作用,同时搭配格式化、挂载配置、磁盘检查等实战案例,帮你打通 “理论” 与 “实操” 的壁垒!
新建一个文件,系统要做什么?
分配 inode ,形成该文件的所有属性然后保存在磁盘,同时和文件名关联
删除一个文件,系统要做什么?
查看引用计数,符合要求就将数据块和对应的 inode 取消关联,改变文件状态,允许覆盖
查找/修改一个文件,系统要做什么?
根据 inode 找到对应的数据块,取/修改里面的对应数据
目录
【一】硬件认识-磁盘
【二】线性结构转化
【三】文件系统
(1)“块”的概念
(2)文件系统
【四】软硬链接
(1)软链接
(2)硬链接
(3)软硬对比
(4)当前路径与上级路径
【五】物理内存的管理
(1)页框、页帧的理解
(2)页号的理解
(3)数据的存储过程
【一】硬件认识-磁盘
下面来认识一下我们计算机中的存储外设——磁盘:可以看到随便一个盘容量就达到了上百G!


磁盘大致零件分布对我们的认识不大,我们主要看下面的物理和存储结构:
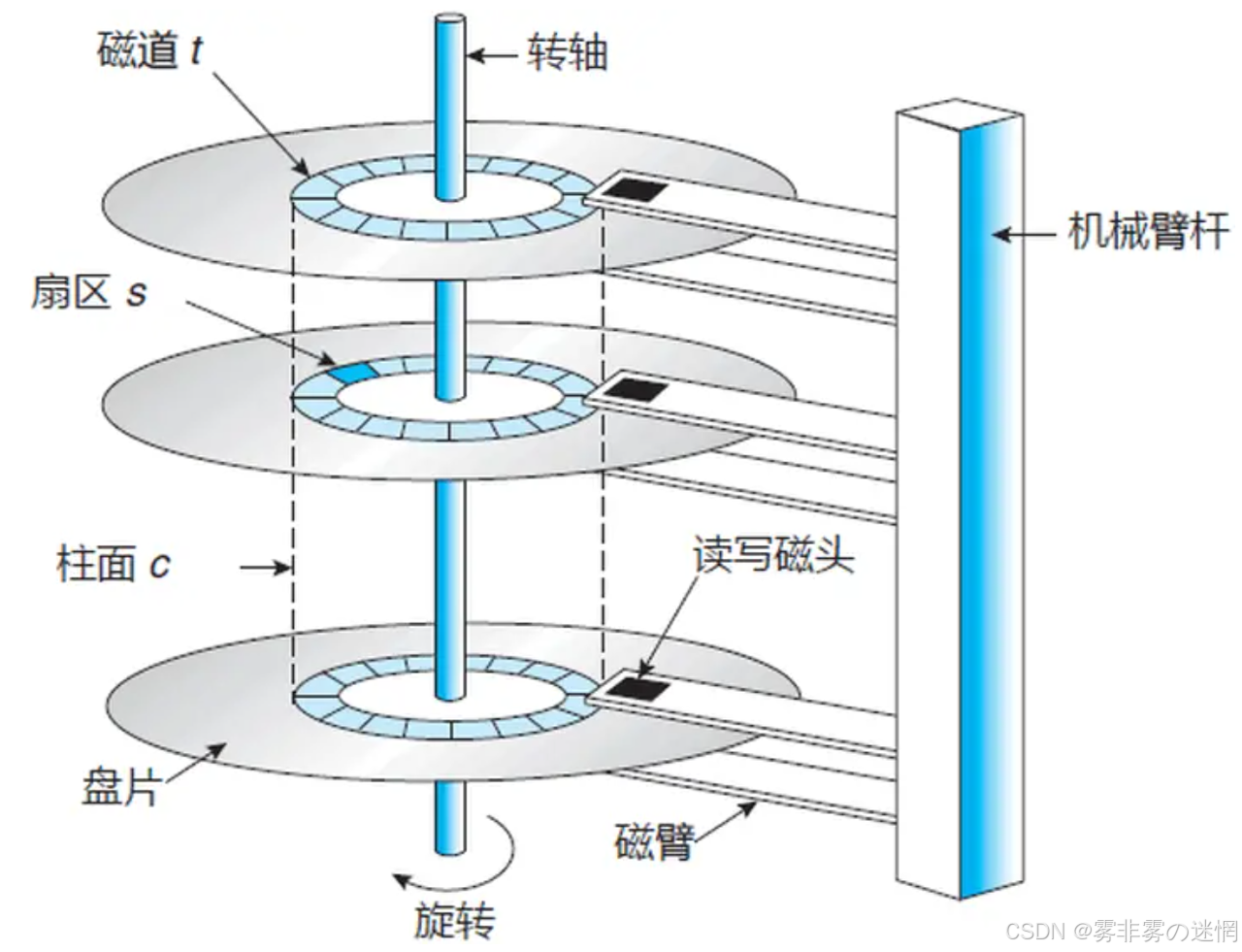
工作原理讲解:
整个磁盘是有若干个小磁盘(圆滑面)的,每个正反面是单独的存储面,每个存储面都有一个磁头
当整个磁盘工作时会高速旋转,同时磁头左右摆动来锁定目标位置,达到管理效果(存储、访问.....)
存储结构讲解:
我们重点来看每个磁盘面:每个盘面会以中间的主轴为中心,向外分为一个个同心磁道,而每个磁道又会被划分为各个扇区,文件的存储,无非就是占据扇区的问题
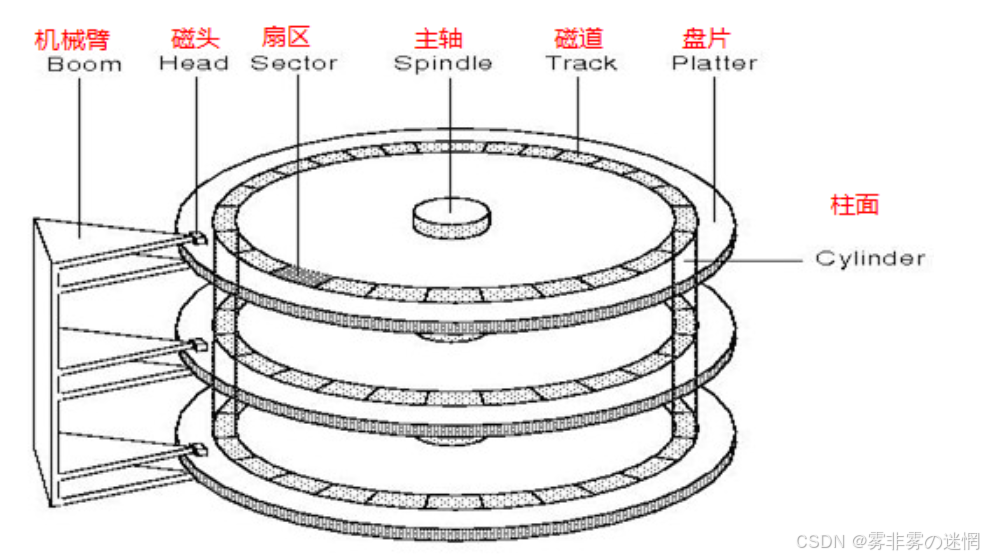
【二】线性结构转化
在上面我们知道每个磁面是被分为了很多个磁道的,那每个磁道抽象理解为一种线性结构,例如:

这样是不是很像数组!每个扇区都有一个线性地址也就是下标,这个地址我们称为 LBA
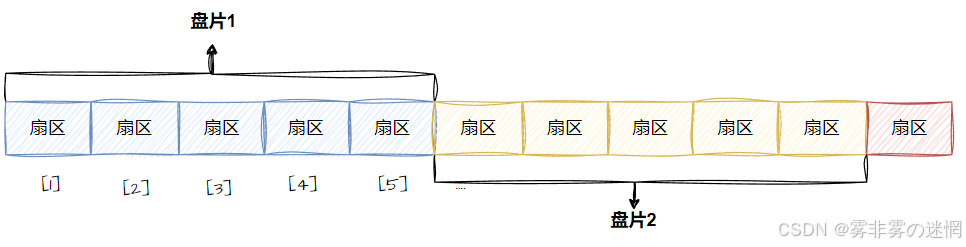
文件其实就是存储在这些一个个扇区上,通过确定磁面->磁道->扇区(CHS)来锁定扇区,如何完成 CHS——LBA的相互转化?
假设每个盘面有2W个扇区,每个盘面有50个磁道,每个磁道有400个扇区,假设LBA是28888:
LBA->CHS:
确定磁面:C = LBA / 单个磁面的总扇区数
确定磁道:H = C / 单个磁道扇区数
确定扇区:S = (LBA % 每磁道扇区数) + 1
CHS->LBA:
LBA = 柱⾯号C*(单个磁面扇区总数) + 磁头号H*每磁道扇区数 + 扇区号S - 1
(扇区号通常从1开始,在LBA中,地址是从0开始的,柱⾯和磁道都是从0开始编号的)
所以我们只需要得到一个 LBA,就可以经过计算得到准确扇区的位置!
【三】文件系统
(1)“块”的概念
操作系统从磁盘读取数据的时,通常不会一个一个扇区读取,而是一次性读取多个扇区,即“块”
硬盘的每个分区是被划分为⼀个个的”块”
⼀个”块”的⼤⼩是由格式化的时候确定的,并且不可以更改
最常⻅的是4KB,即连续⼋个扇区组成⼀个”块”。”块”是⽂件存取的最⼩单位
(2)文件系统
上面我们了解到一个“块”通常由八个扇区组成,例如:下面的 Block group 就是文件系统
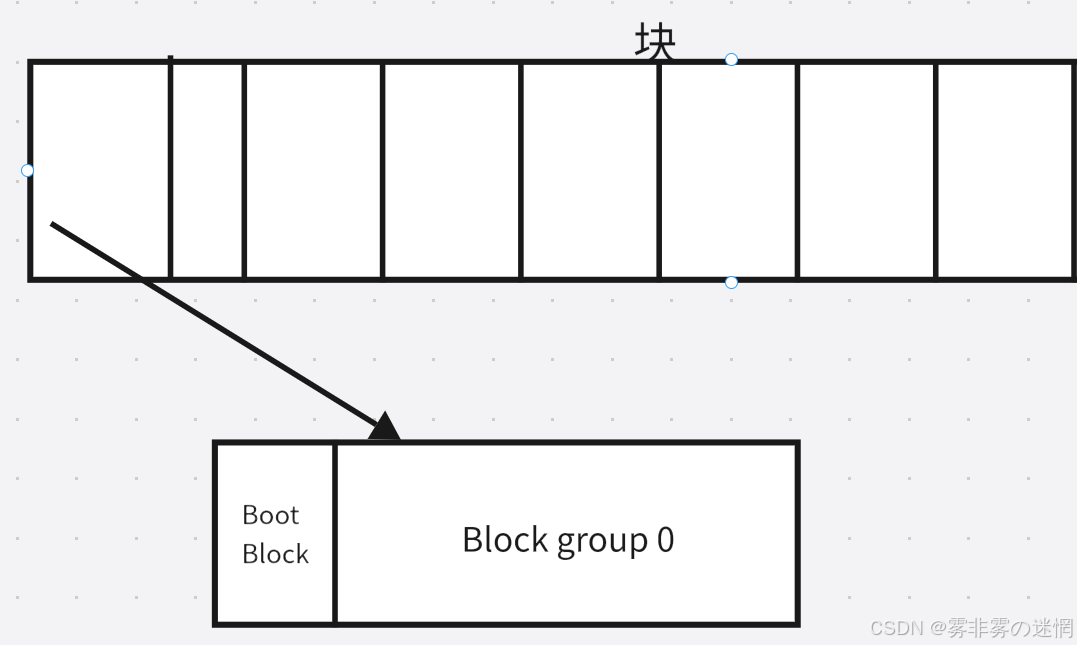
而每个文件系统又可以再细分为下面的组成,下面来讲解这些组成,如图:(大致了解即可)

Date Blocks:存储文件的内容,以块的形式呈现,通常是4KB,一个文件系统的大小
Inode Table:单个文件的所有属性,比如 inode 编号,例如我们可以通过 ls - li 查看 innode编号
Inode Bitmap、Block Bitmap:用二进制表示已经存储的该文件的使用情况,比如1表示已经占 用,0表示空缺
Group Descriptor Table:快速定位到目标文件的核心细节
Super Block:超级块,用来存储该区整个文件系统的信息,为了防止数据丢失解决恢复问题,一 般在改块的其它扇区也存在记录
【四】软硬链接
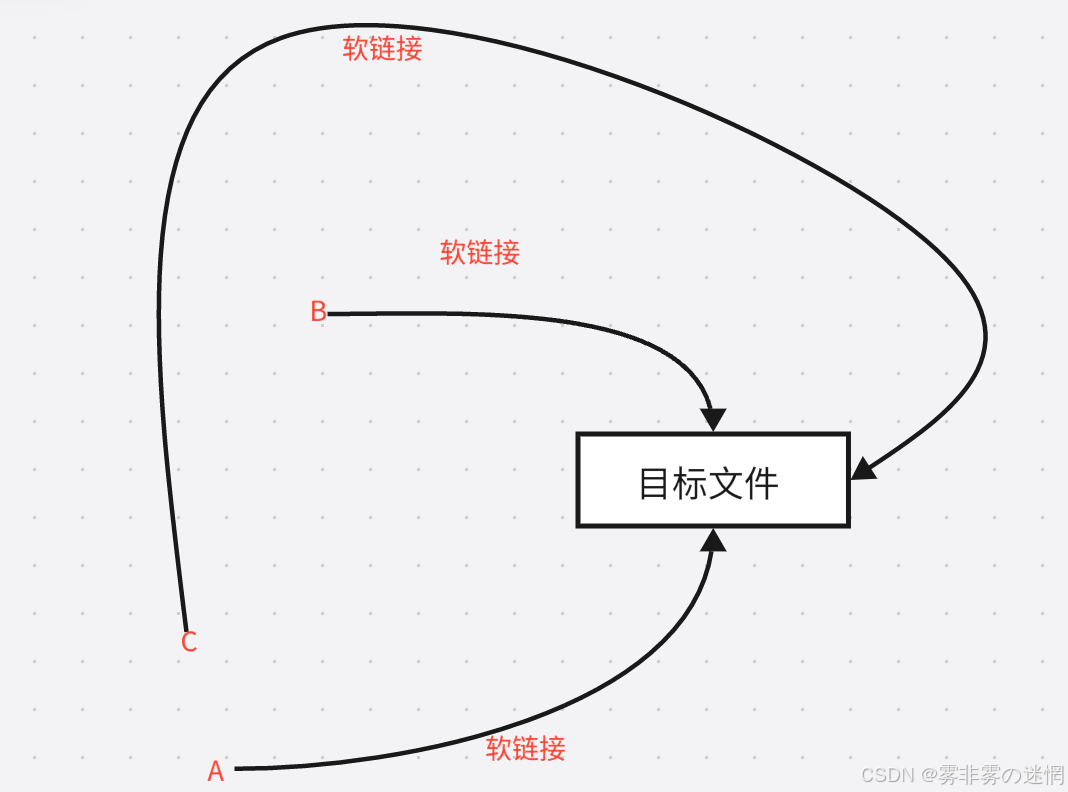
(1)软链接
理解:软链接就是建立一个指向该文件的路径(比如Windows的快捷键方式),例如:
特点:
(1)本质是一个 “特殊文件”,这个文件里只存了原文件的路径,而非原文件的数据
(2)它像一个 “指路牌”,访问软链接时,系统会先根据路径找到原文件,再读取原文件的数据
(3)软链接有自己独立的 inode,与原文件的 inode 完全不同
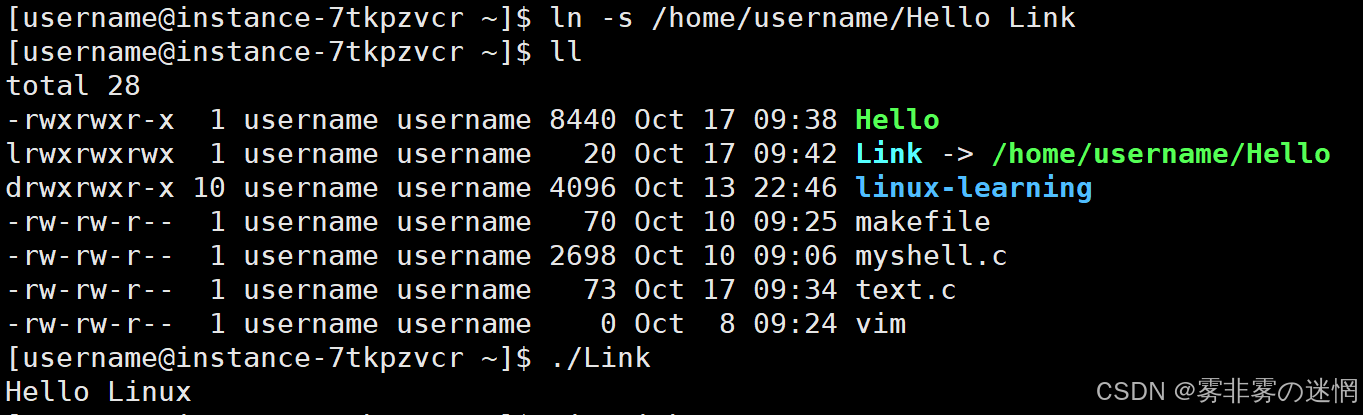
创建软链接:
ln -s 源文件名(可带路径) 目标文件名例如:现在有一个编译了的文件,给它创建软链接,注意它们是两个不同的文件
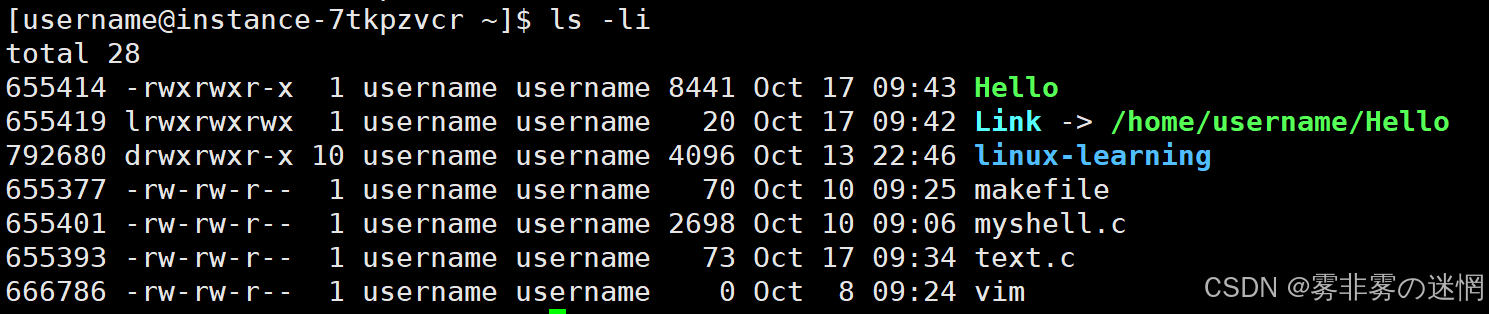
(2)硬链接
理解:硬链接就是建立一个指向该文件的别名(比如:黑旋风和李逵是同一个人)
特点:
(1)本质是给原文件的inode 新增一个 “别名”,没有独立的 inode,和原文件共用同一个inode
(2)可以理解为:一个文件的底层数据被多个文件名 “指向”,这些文件名都是硬链接
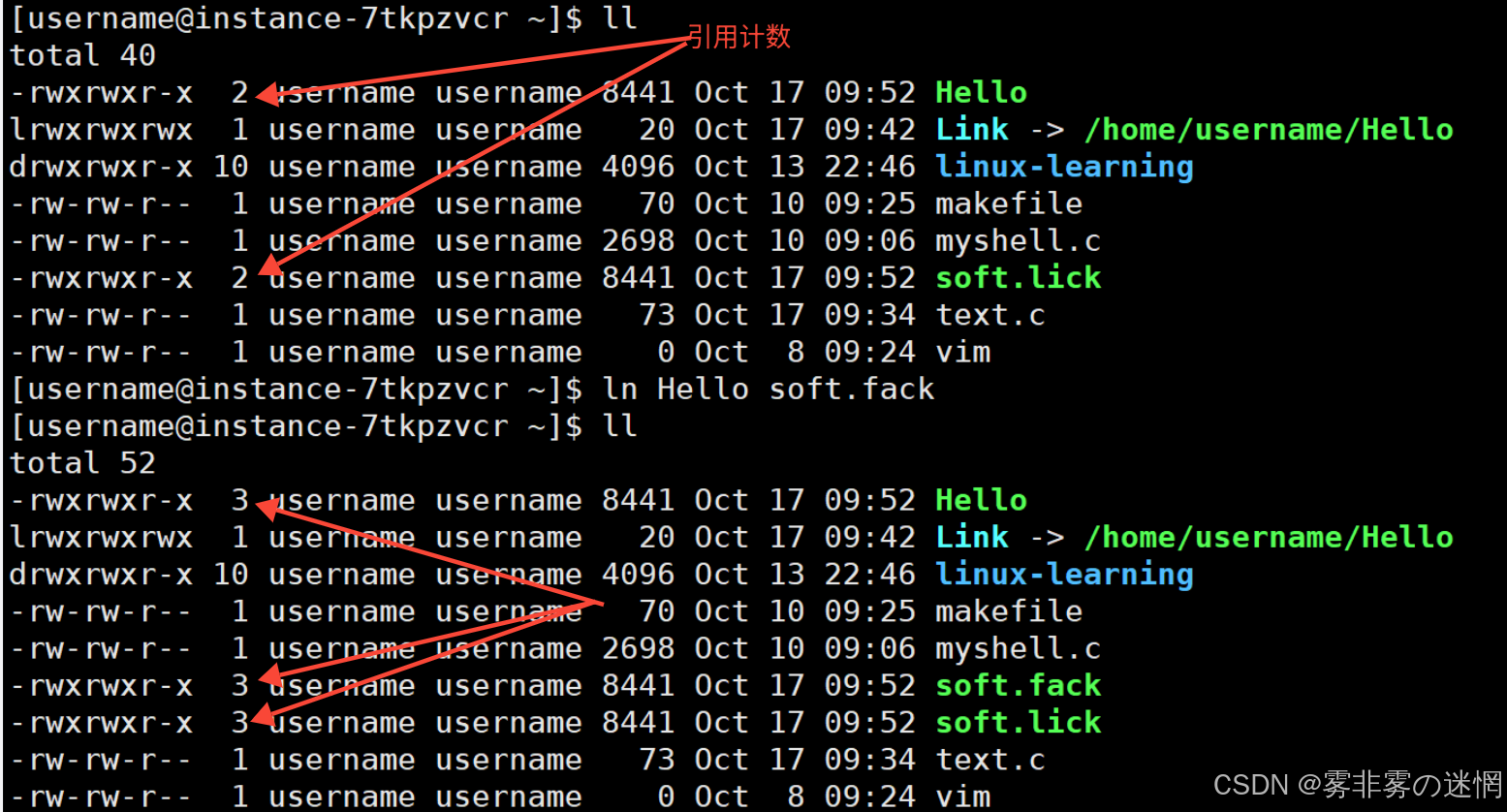
(3)系统判断文件是否真正删除,看的是 inode 的 “引用计数”—— 只要还有一个硬链接(包括原 文件名)存在,inode 和数据就不会被删除
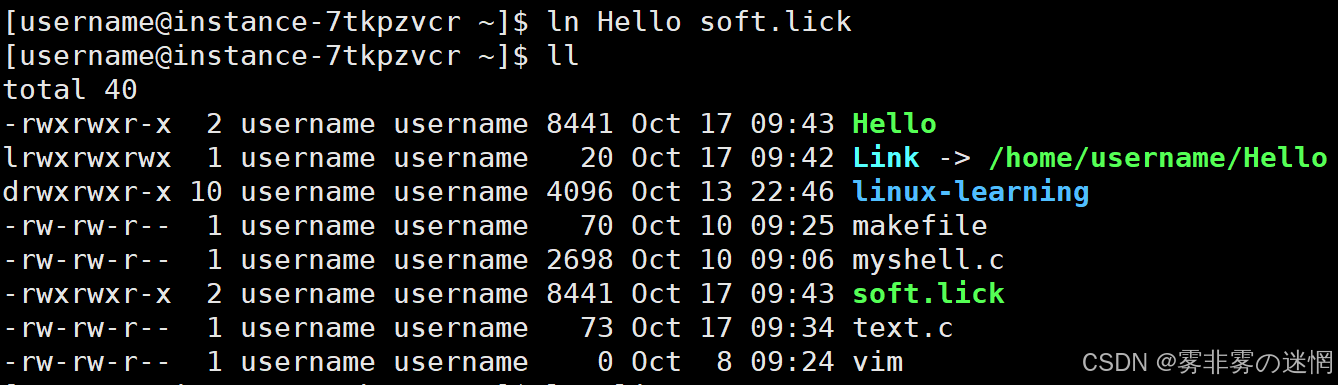
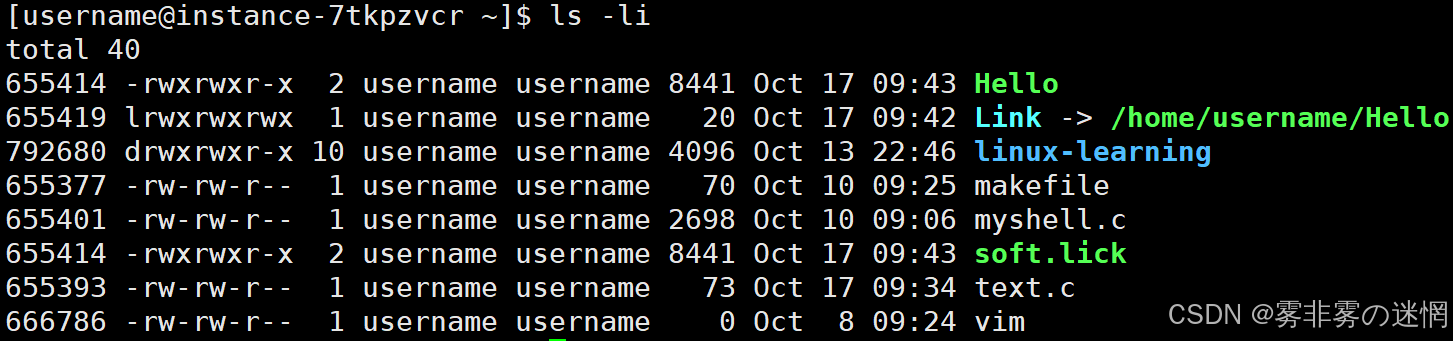
创建硬链接:
ln 源文件名(可带路径) 目标文件名例如:硬链接的文件 inode 相同而文件名不同,说明文件名不在 inode 中保存
(3)软硬对比
| 对比维度 | 软链接(ln -s) | 硬链接(ln) |
|---|---|---|
| inode 编号 | 有独立 inode,与原文件不同 | 无独立 inode,与原文件相同 |
| 指向对象 | 指向原文件的路径 | 指向原文件的别名 |
| 跨文件系统(分区) | 支持 | 不支持 |
| 删除原文件后 | 软链接失效(变成 “死链接”) | 硬链接仍可用(引用计数未归零) |
| 文件大小 | 很小(只存路径,通常几字节) | 和原文件大小完全一致 |
| 目录支持 | 可以给目录创建软链接 | 不能给目录创建硬链接(避免循环) |
(4)当前路径与上级路径
注意:现在我们创建一个目录 ceshi ,可以看到当前目录和这个目录的 inode 是一样的
//分别执行
ls -ai ceshi
ls -di ceshils -ai ceshi
ls -di .
同时 ceshi 的上级目录和 .. 的 inode 也是一样的

说明 ..和. 是路径的别名(硬链接),这是老祖先自己设置的,但是我们不能!
【五】物理内存的管理
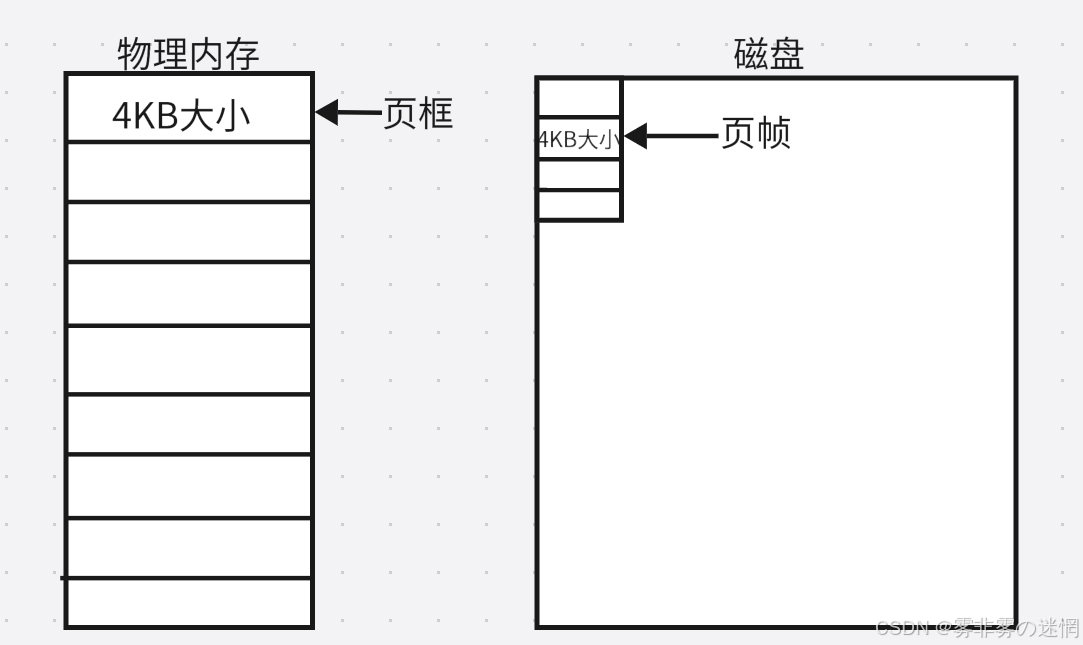
(1)页框、页帧的理解
页框、页帧都是将存储的空间分为一个个大小相同的“块”,一般为4KB,每个“块”都可以存储数据
每个“块”以4KB为单位,每次拿数据最少拿/存一个块!
(2)页号的理解
既然存储设备都是以4KB大小的“块”为单位,那么这些“块”应该是连续的,所以能看为是数组管理
因此先描述再组织,操作系统可以通过 struct page mem_array[1048576]数组来转化物理内存地址
过程:我们知道程序是通过进程运行的,每个进程每次访问的是进程地址空间,通过页表和物理内存产生联系,页号用来定位 “虚拟页” 对应哪个 “物理页框”,大胆猜测:页号很像页表的编号,页表中对应的页号映射着物理内存!
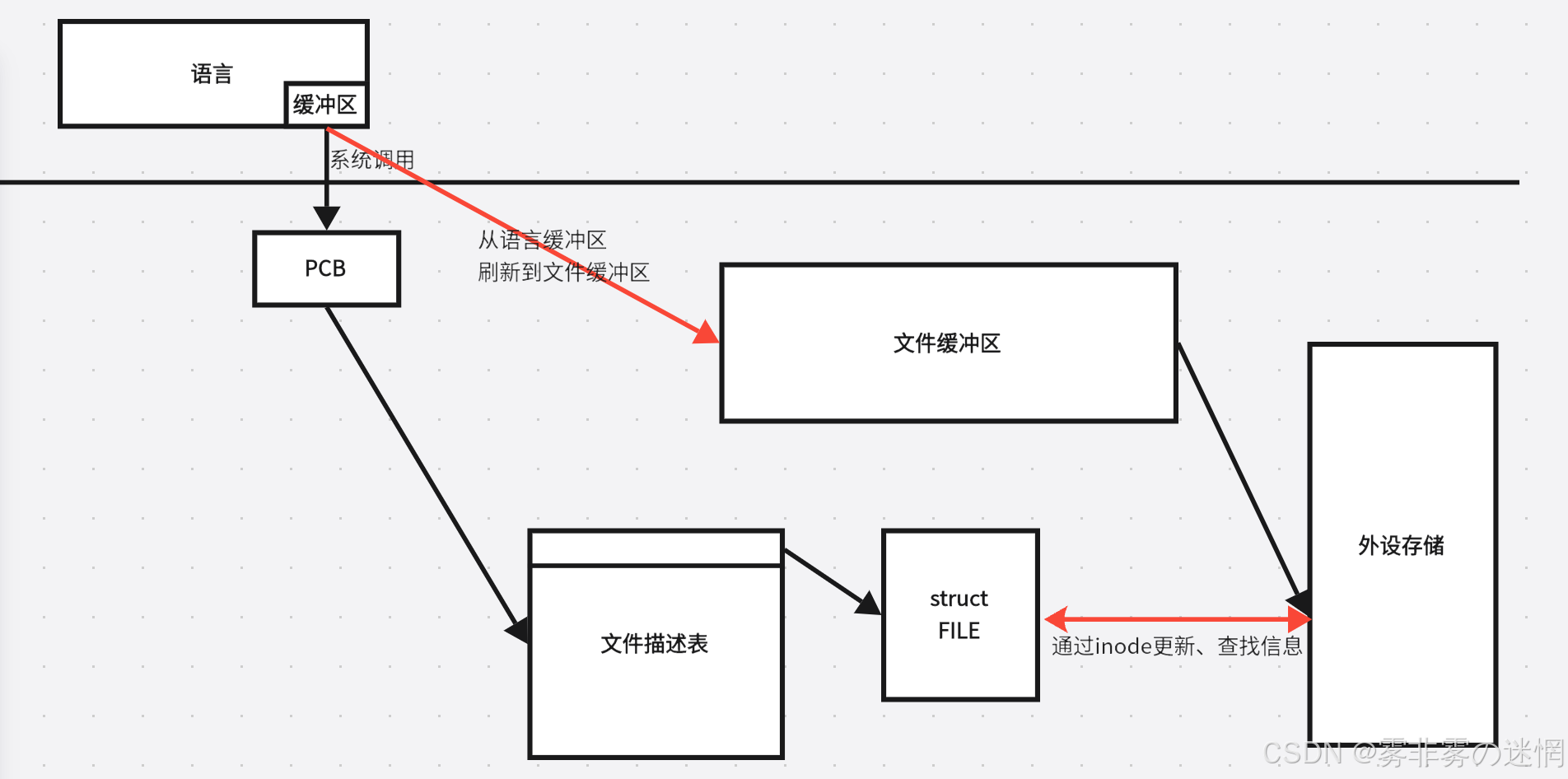
(3)数据的存储过程
从语言->语言缓冲区,语言缓冲区->文件缓冲区,文件缓冲区->外设:三次内容拷贝