Prometheus(二)—— 在K8s集群中部署Prometheus+Grafana+AlertManager实现全方位监控
文章目录
- 前言
- 一、环境准备
- 1.1 环境说明
- 1.2 前置依赖检查
- 二、部署node-exporter(采集节点监控数据)
- 2.1 创建监控专用命名空间
- 2.2 编写node-exporter部署清单
- 2.3 部署并验证node-exporter
- 三、部署Prometheus Server(核心监控系统)
- 3.1 创建SA账号并配置RBAC授权
- 3.2 编写Prometheus Server配置文件(ConfigMap)
- 3.3 部署Prometheus Server实例(Deployment)
- 3.4 创建Service暴露Prometheus Server访问入口
- 3.5 Prometheus配置热加载(避免重启丢失数据)
- 四、部署Grafana(监控数据可视化)
- 4.1 编写Grafana部署清单
- 4.2 部署并验证Grafana
- 4.3 配置Grafana数据源(关联Prometheus)
- 4.4 导入监控模板(快速生成仪表盘)
- 4.4.1 导入节点监控模板
- 4.4.2 导入容器监控模板
- 五、部署kube-state-metrics(采集K8s资源指标)
- 5.1 创建RBAC授权(kube-state-metrics专用)
- 5.2 部署kube-state-metrics实例与Service
- 5.3 导入K8s集群监控模板
- 六、配置AlertManager实现邮件告警
- 6.1 Prometheus告警处理流程
- 6.2 配置AlertManager(邮件发送参数)
- 6.3 更新Prometheus配置(关联AlertManager)
- 6.4 部署包含AlertManager的Prometheus实例
- 6.5 创建AlertManager Service(暴露访问入口)
- 6.6 处理kube-proxy监控告警(可选)
- 6.7 邮件告警功能测试
- 总结
- 核心成果回顾
- 关键配置要点
前言
随着Kubernetes(简称K8s)集群在生产环境中的广泛应用,其动态性、复杂性也随之增加——节点状态、容器资源、Pod运行情况等都需要实时监控,才能及时发现并解决问题。Prometheus作为开源监控利器,擅长时序数据采集与存储;Grafana则能将监控数据可视化,生成直观的仪表盘;AlertManager可基于监控指标触发告警,通过邮件等方式通知运维人员。
本文将详细介绍如何在K8s集群中部署node-exporter(采集节点数据)、Prometheus(核心监控)、Grafana(可视化)、kube-state-metrics(采集K8s资源指标)及AlertManager(邮件告警)。
一、环境准备
1.1 环境说明
本次部署基于已搭建完成的K8s集群,节点信息如下表所示:
| 节点角色 | 节点名称 | 节点IP | 核心作用 |
|---|---|---|---|
| 控制节点(Master) | master01 | 192.168.10.14 | 集群控制、调度任务 |
| 工作节点(Node) | node01 | 192.168.10.15 | 部署Prometheus、AlertManager |
| 工作节点(Node) | node02 | 192.168.10.16 | 承载业务Pod |
1.2 前置依赖检查
在开始部署前,需确保以下条件满足:
1、K8s集群状态正常:执行kubectl get nodes,所有节点需处于Ready状态;
2、kubectl命令可用:执行kubectl version,能正常输出客户端与服务端版本;
3、端口开放或防火墙关闭:
- 关闭防火墙(CentOS示例):
systemctl stop firewalld && systemctl disable firewalld; - 若需保留防火墙,开放关键端口:
9100(node-exporter)、9090(Prometheus)、3000(Grafana)、9093(AlertManager)。
4、关闭增强功能:
setenforce 0 # 临时关闭SELinux
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config # 永久关闭
二、部署node-exporter(采集节点监控数据)
node-exporter是Prometheus的节点级监控插件,用于采集节点的CPU、内存、磁盘、网络等硬件与系统指标,通过DaemonSet控制器部署可确保集群中每个节点都运行一份实例。
2.1 创建监控专用命名空间
为避免监控组件与业务组件混淆,创建独立命名空间monitor-sa:
kubectl create ns monitor-sa
2.2 编写node-exporter部署清单
1、创建工作目录并编写YAML文件:
mkdir -p /opt/prometheus && cd /opt/prometheus
vim node-export.yaml
2、粘贴以下配置(关键配置已加注释):
apiVersion: apps/v1
kind: DaemonSet # DaemonSet确保每个节点运行1个Pod实例
metadata:name: node-exporternamespace: monitor-sa # 部署到监控命名空间labels:name: node-exporter
spec:selector:matchLabels:name: node-exporter # 匹配Pod标签template:metadata:labels:name: node-exporterspec:hostPID: true # 共享宿主机PID命名空间,可查看宿主机进程hostIPC: true # 共享宿主机IPC命名空间,支持进程间通信hostNetwork: true # 使用宿主机网络,直接暴露9100端口(无需额外创建Service)containers:- name: node-exporterimage: prom/node-exporter:v0.16.0 # 固定版本,避免兼容性问题ports:- containerPort: 9100 # node-exporter默认监听端口resources:requests:cpu: 0.15 # 最低CPU需求,确保资源分配securityContext:privileged: true # 开启特权模式,允许访问宿主机硬件信息args: # 配置数据采集路径与忽略目录- --path.procfs- /host/proc # 挂载宿主机/proc目录(系统进程信息)- --path.sysfs- /host/sys # 挂载宿主机/sys目录(硬件与内核信息)- --collector.filesystem.ignored-mount-points- '"^/(sys|proc|dev|host|etc)($|/)"' # 忽略非业务挂载点,减少无效数据volumeMounts: # 挂载宿主机目录到容器内- name: devmountPath: /host/dev- name: procmountPath: /host/proc- name: sysmountPath: /host/sys- name: rootfsmountPath: /rootfstolerations: # 容忍master节点污点,允许在master上运行(默认master有污点,禁止普通Pod调度)- key: "node-role.kubernetes.io/master"operator: "Exists"effect: "NoSchedule"volumes: # 定义宿主机目录挂载源- name: prochostPath:path: /proc- name: devhostPath:path: /dev- name: syshostPath:path: /sys- name: rootfshostPath:path: /
2.3 部署并验证node-exporter
1、执行部署命令:
kubectl apply -f node-export.yaml
2、查看Pod运行状态(确保所有节点均有实例):
kubectl get pods -n monitor-sa -o wide
# 预期输出:master01、node01、node02各1个node-exporter Pod,状态为Running

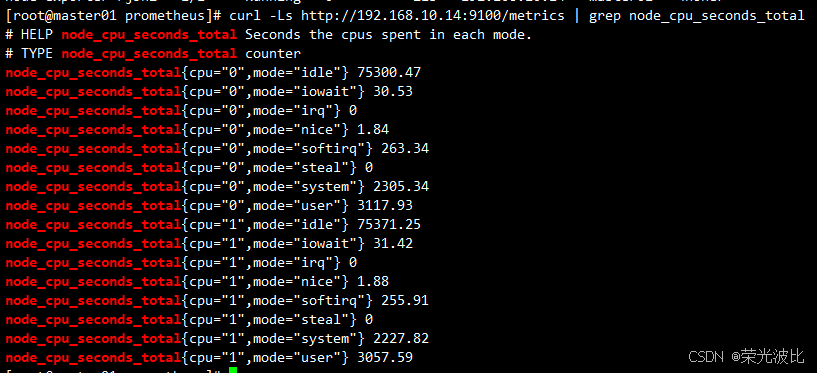
3、验证数据采集(以master01为例,替换IP可测试其他节点):
# 采集CPU指标(查看节点CPU各模式耗时)
curl -Ls http://192.168.10.14:9100/metrics | grep node_cpu_seconds_total
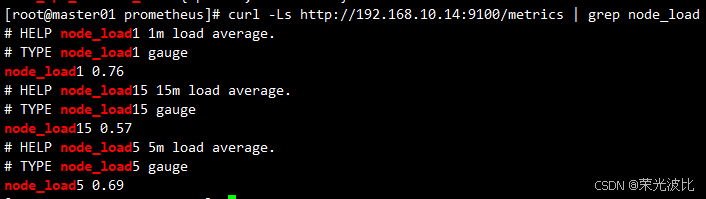
# 采集节点负载(查看1分钟、5分钟、15分钟负载均值)
curl -Ls http://192.168.10.14:9100/metrics | grep node_load
若能正常输出指标数据,说明node-exporter部署成功。
三、部署Prometheus Server(核心监控系统)
Prometheus Server是监控体系的核心,负责从node-exporter等数据源采集数据、存储时序数据,并基于配置的规则评估告警。部署分为4步:创建SA账号授权、配置ConfigMap存储监控规则、部署Prometheus Server实例、创建Service暴露访问入口。
3.1 创建SA账号并配置RBAC授权
K8s通过RBAC(基于角色的访问控制)管理权限,需创建专用SA账号monitor并绑定cluster-admin角色(确保Prometheus Server能访问集群所有资源):
# 1、创建SA账号(命名空间:monitor-sa)
kubectl create serviceaccount monitor -n monitor-sa# 2、绑定cluster-admin角色(clusterrolebinding作用于整个集群)
kubectl create clusterrolebinding monitor-clusterrolebinding \-n monitor-sa \--clusterrole=cluster-admin \--serviceaccount=monitor-sa:monitor
3.2 编写Prometheus Server配置文件(ConfigMap)
通过ConfigMap存储Prometheus Server的核心配置(如全局采集间隔、数据源、告警规则),后续修改配置无需重启Pod(支持热加载)。
1、创建ConfigMap清单:
vim /opt/prometheus/prometheus-cfg.yaml
2、粘贴以下配置:
kind: ConfigMap
apiVersion: v1
metadata:labels:app: prometheusname: prometheus-confignamespace: monitor-sa
data:prometheus.yml: |global: # 全局配置,所有数据源默认继承scrape_interval: 15s # 数据采集间隔(默认1分钟,缩短至15秒提升实时性)scrape_timeout: 10s # 采集超时时间(超过则丢弃该次采集)evaluation_interval: 1m # 告警规则评估间隔(默认1分钟)scrape_configs: # 数据源配置(Job列表,每个Job对应一类数据源)# Job1:采集K8s节点指标(从node-exporter获取)- job_name: 'kubernetes-node'kubernetes_sd_configs: # 启用K8s服务发现(自动发现集群节点)- role: node # 服务发现角色:node(基于K8s节点信息发现目标)relabel_configs: # 标签重写:将默认的kubelet端口10250替换为node-exporter的9100端口- source_labels: [__address__] # 原始标签:目标地址(格式:IP:10250)regex: '(.*):10250' # 匹配10250端口(kubelet默认端口)replacement: '${1}:9100' # 替换为IP:9100(node-exporter端口)target_label: __address__ # 新标签:替换后的目标地址action: replace- action: labelmap # 保留K8s节点标签(如node-role.kubernetes.io/master)regex: __meta_kubernetes_node_label_(.+) # 匹配K8s节点自带标签# Job2:采集容器指标(从kubelet的cadvisor接口获取)- job_name: 'kubernetes-node-cadvisor'kubernetes_sd_configs:- role: nodescheme: https # 访问kubelet接口需HTTPStls_config: # 配置TLS证书(使用集群默认SA证书)ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token # 认证Tokenrelabel_configs:- action: labelmapregex: __meta_kubernetes_node_label_(.+)- target_label: __address__ # 替换目标地址为K8s API Server(默认443端口)replacement: kubernetes.default.svc:443- source_labels: [__meta_kubernetes_node_name] # 基于节点名拼接cadvisor接口路径regex: (.+)target_label: __metrics_path__ # 指标采集路径(动态适配节点名)replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor# Job3:采集K8s API Server指标(监控集群控制平面)- job_name: 'kubernetes-apiserver'kubernetes_sd_configs:- role: endpoints # 服务发现角色:endpoints(基于服务端点发现目标)scheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:# 仅保留默认命名空间下、服务名为kubernetes、端口为https的端点- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]action: keepregex: default;kubernetes;https# Job4:采集自定义服务指标(需服务添加annotation:prometheus.io/scrape=true)- job_name: 'kubernetes-service-endpoints'kubernetes_sd_configs:- role: endpointsrelabel_configs:# 仅采集标注了"prometheus.io/scrape: true"的服务- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]action: keepregex: true# 替换采集协议(http/https,由服务annotation指定)- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]action: replacetarget_label: __scheme__regex: (https?)# 替换指标采集路径(默认/metrics,可由服务annotation指定)- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]action: replacetarget_label: __metrics_path__regex: (.+)# 替换采集端口(由服务annotation指定)- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]action: replacetarget_label: __address__regex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2# 保留服务标签并添加命名空间、服务名标签- action: labelmapregex: __meta_kubernetes_service_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_service_name]action: replacetarget_label: kubernetes_name
3、创建ConfigMap:
kubectl apply -f /opt/prometheus/prometheus-cfg.yaml

3.3 部署Prometheus Server实例(Deployment)
通过Deployment部署Prometheus Server,指定调度到node01(192.168.10.15),并挂载宿主机目录存储监控数据(避免Pod重建数据丢失)。
1、在node01创建数据存储目录(需登录node01执行):
# 登录node01(192.168.10.15)
ssh root@192.168.10.15
# 创建目录并授权(777确保Prometheus容器有读写权限)
mkdir /data && chmod 777 /data
# 退出node01
exit
2、编写Deployment清单:
vim /opt/prometheus/prometheus-deploy.yaml
3、粘贴以下配置(关键配置已适配node01):
apiVersion: apps/v1
kind: Deployment
metadata:name: prometheus-servernamespace: monitor-salabels:app: prometheus
spec:replicas: 1 # 单副本(生产环境可考虑多副本+持久化存储)selector:matchLabels:app: prometheuscomponent: servertemplate:metadata:labels:app: prometheuscomponent: serverannotations:prometheus.io/scrape: 'false' # 禁止Prometheus自采集(避免循环采集)spec:nodeName: node01 # 强制调度到node01(192.168.10.15)serviceAccountName: monitor # 使用之前创建的SA账号containers:- name: prometheusimage: prom/prometheus:v2.2.1 # 固定版本,确保稳定性imagePullPolicy: IfNotPresent # 优先使用本地镜像command: # 启动命令(指定配置文件、数据存储路径等)- prometheus- --config.file=/etc/prometheus/prometheus.yml # 配置文件路径(挂载自ConfigMap)- --storage.tsdb.path=/prometheus # 数据存储路径(挂载自宿主机/data)- --storage.tsdb.retention=720h # 数据保留时长(30天,可按需调整)- --web.enable-lifecycle # 开启配置热加载(无需重启Pod)ports:- containerPort: 9090 # Prometheus默认端口protocol: TCPvolumeMounts: # 挂载配置文件与数据目录- mountPath: /etc/prometheus/prometheus.ymlname: prometheus-configsubPath: prometheus.yml # 仅挂载ConfigMap中的prometheus.yml文件- mountPath: /prometheus/name: prometheus-storage-volumevolumes: # 定义挂载源- name: prometheus-configconfigMap:name: prometheus-config # 关联之前创建的ConfigMapitems:- key: prometheus.ymlpath: prometheus.ymlmode: 0644 # 文件权限- name: prometheus-storage-volumehostPath: # 挂载宿主机node01的/data目录path: /datatype: Directory
4、部署Prometheus:
kubectl apply -f /opt/prometheus/prometheus-deploy.yaml
5、验证部署状态:
kubectl get pods -o wide -n monitor-sa
# 预期输出:prometheus-server-xxx Pod状态为Running,节点为node01(192.168.10.15)

3.4 创建Service暴露Prometheus Server访问入口
通过NodePort类型的Service暴露Prometheus,允许外部通过节点IP+端口访问Web UI。
1、编写Service清单:
vim /opt/prometheus/prometheus-svc.yaml
2、粘贴以下配置:
apiVersion: v1
kind: Service
metadata:name: prometheusnamespace: monitor-salabels:app: prometheus
spec:type: NodePort # NodePort类型:在每个节点暴露一个随机端口(此处指定31000)ports:- port: 9090 # Service内部端口targetPort: 9090 # 映射到Pod的9090端口protocol: TCPnodePort: 31000 # 固定节点暴露端口(避免随机端口变动)selector: # 匹配Prometheus Pod标签app: prometheuscomponent: server
3、创建Service并验证:
# 创建Service
kubectl apply -f /opt/prometheus/prometheus-svc.yaml# 查看Service状态
kubectl get svc -n monitor-sa
# 预期输出:prometheus Service类型为NodePort,PORT(S)为9090:31000/TCP

4、访问Prometheus Web UI:
打开浏览器,输入http://192.168.10.15:31000(node01的IP+Service暴露的31000端口)。
-
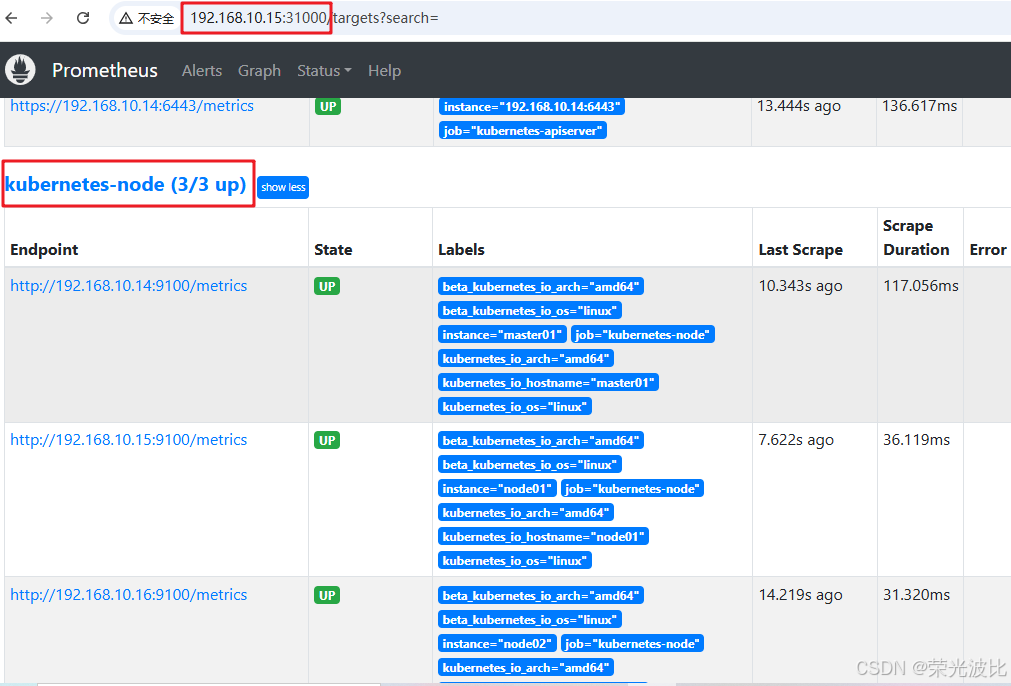
点击顶部
Status→Targets,所有Job的Target状态均为UP,说明数据源采集正常;
-
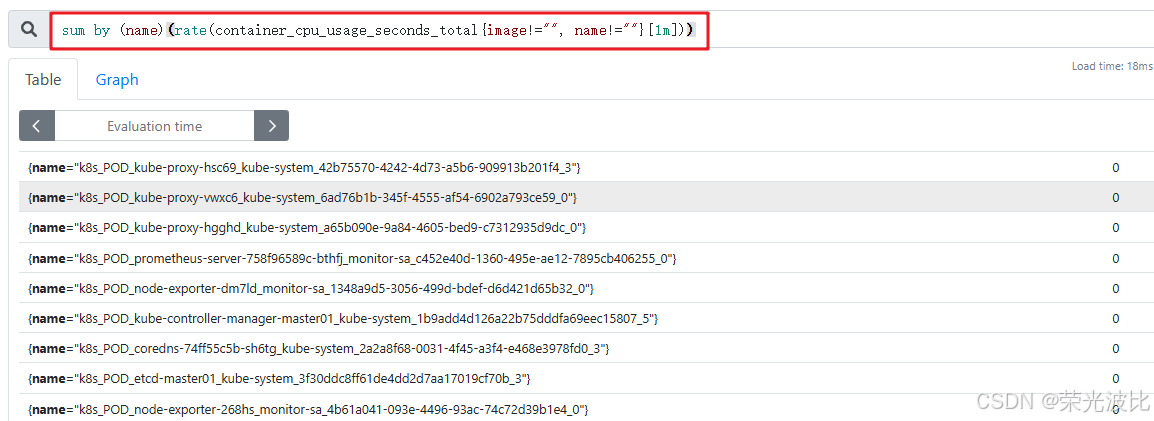
点击顶部
Graph,输入查询语句sum by (name)(rate(container_cpu_usage_seconds_total{image!="", name!=""}[1m])),可查看集群中每个Pod的1分钟CPU使用率。
3.5 Prometheus配置热加载(避免重启丢失数据)
修改ConfigMap后,无需重启Prometheus Pod,通过热加载命令即可使配置生效(线上环境推荐使用)。
1、获取Prometheus Pod的IP:
kubectl get pods -n monitor-sa -o wide -l app=prometheus
# 示例输出:IP为10.244.1.29(以实际输出为准)

2、执行热加载命令:
curl -X POST -Ls http://10.244.1.29:9090/-/reload
3、验证热加载结果(查看日志):
# 替换Pod名为实际的Prometheus Pod名
kubectl logs -n monitor-sa prometheus-server-758f96589c-bthfj | grep "Loading configuration file"
# 预期输出:没有error,说明热加载成功

注意:若热加载失败,可通过删除并重建Pod强制更新配置(线上环境谨慎使用,可能丢失内存中的临时数据):
kubectl delete -f /opt/prometheus/prometheus-cfg.yaml
kubectl delete -f /opt/prometheus/prometheus-deploy.yaml
kubectl apply -f /opt/prometheus/prometheus-cfg.yaml
kubectl apply -f /opt/prometheus/prometheus-deploy.yaml
四、部署Grafana(监控数据可视化)
Prometheus的Web UI仅支持简单查询,Grafana可通过拖拽式操作生成复杂仪表盘(如节点资源、容器状态、集群性能等),并支持导入社区现成模板,降低配置成本。
4.1 编写Grafana部署清单
Grafana部署在kube-system命名空间(与K8s系统组件同命名空间),通过Deployment+NodePort Service实现访问。
1、创建Grafana清单:
vim /opt/prometheus/grafana.yaml
2、粘贴以下配置(已开启匿名访问,方便测试):
# 1、Deployment:部署Grafana实例
---
apiVersion: apps/v1
kind: Deployment
metadata:name: monitoring-grafananamespace: kube-system
spec:replicas: 1selector:matchLabels:task: monitoringk8s-app: grafanatemplate:metadata:labels:task: monitoringk8s-app: grafanaspec:containers:- name: grafanaimage: grafana/grafana:5.0.4 # 稳定版本,兼容性好ports:- containerPort: 3000 # Grafana默认端口protocol: TCPvolumeMounts:- mountPath: /etc/ssl/certs # 挂载宿主机证书,避免HTTPS证书错误name: ca-certificatesreadOnly: true- mountPath: /var # 存储Grafana配置与仪表盘数据name: grafana-storageenv: # 环境变量配置- name: INFLUXDB_HOSTvalue: monitoring-influxdb- name: GF_SERVER_HTTP_PORTvalue: "3000"- name: GF_AUTH_BASIC_ENABLED # 关闭基础认证(测试环境用,生产环境建议开启)value: "false"- name: GF_AUTH_ANONYMOUS_ENABLED # 开启匿名访问value: "true"- name: GF_AUTH_ANONYMOUS_ORG_ROLE # 匿名用户角色为Admin(拥有所有权限)value: Admin- name: GF_SERVER_ROOT_URL # 根路径(默认/)value: /volumes:- name: ca-certificateshostPath:path: /etc/ssl/certs- name: grafana-storageemptyDir: {} # 临时存储(生产环境建议用PersistentVolume持久化)# 2、Service:暴露Grafana访问入口
---
apiVersion: v1
kind: Service
metadata:labels:kubernetes.io/cluster-service: 'true'kubernetes.io/name: monitoring-grafananame: monitoring-grafananamespace: kube-system
spec:type: NodePort # NodePort类型,允许外部访问ports:- port: 80 # Service内部端口(映射到Pod的3000端口)targetPort: 3000selector:k8s-app: grafana
4.2 部署并验证Grafana
1、执行部署命令:
kubectl apply -f /opt/prometheus/grafana.yaml
2、查看Grafana Pod与Service状态:
# 查看Pod(确保状态为Running)
kubectl get pods -n kube-system -l task=monitoring -o wide# 查看Service(获取NodePort端口,示例为31634,以实际输出为准)
kubectl get svc -n kube-system | grep grafana
# 预期输出:monitoring-grafana NodePort 10.96.134.33 <none> 80:31634/TCP

3、访问Grafana Web UI:
打开浏览器,输入http://192.168.10.16:31634(node02的IP+Service暴露的NodePort端口,如32087),无需登录即可进入首页。
4.3 配置Grafana数据源(关联Prometheus)
Grafana需关联Prometheus作为数据源,才能加载监控数据:
1、进入Grafana首页,点击左侧Configuration(齿轮图标)→Data Sources;
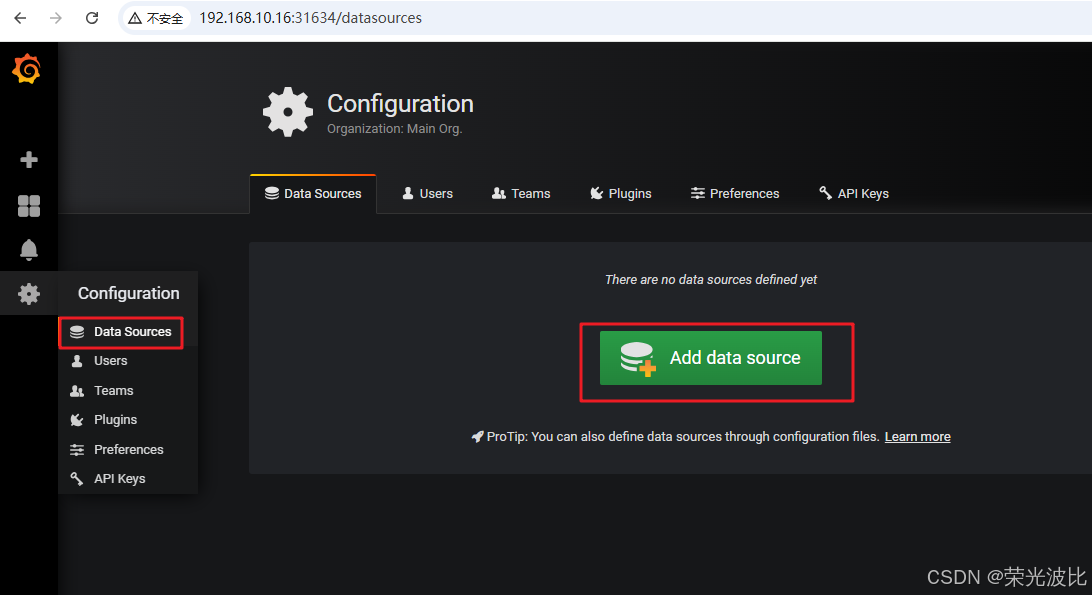
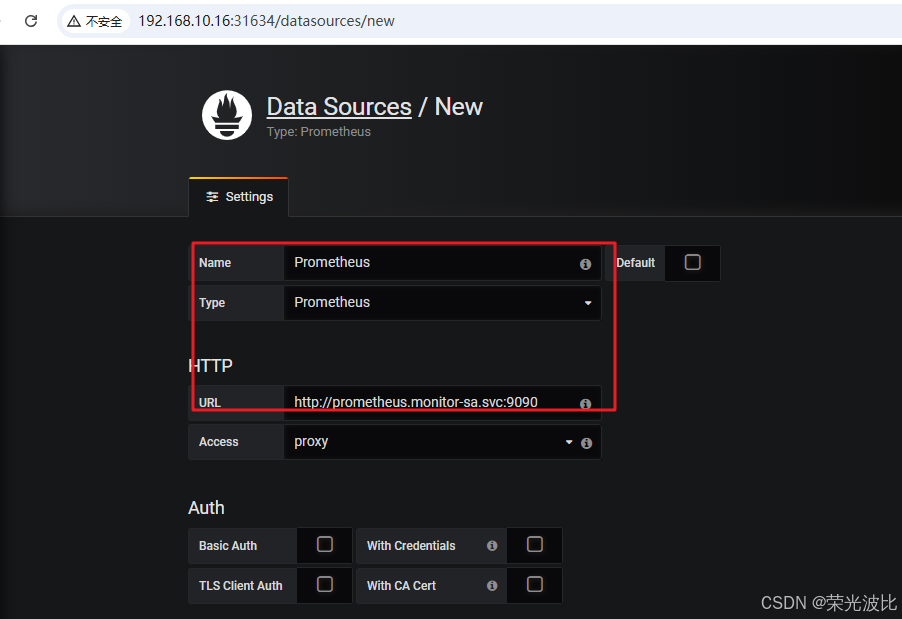
2、点击Add data source,配置如下:
Name:输入Prometheus(自定义名称,便于识别);Type:选择Prometheus(数据源类型);URL:输入http://prometheus.monitor-sa.svc:9090(Prometheus在K8s集群内部的Service地址,无需暴露公网);
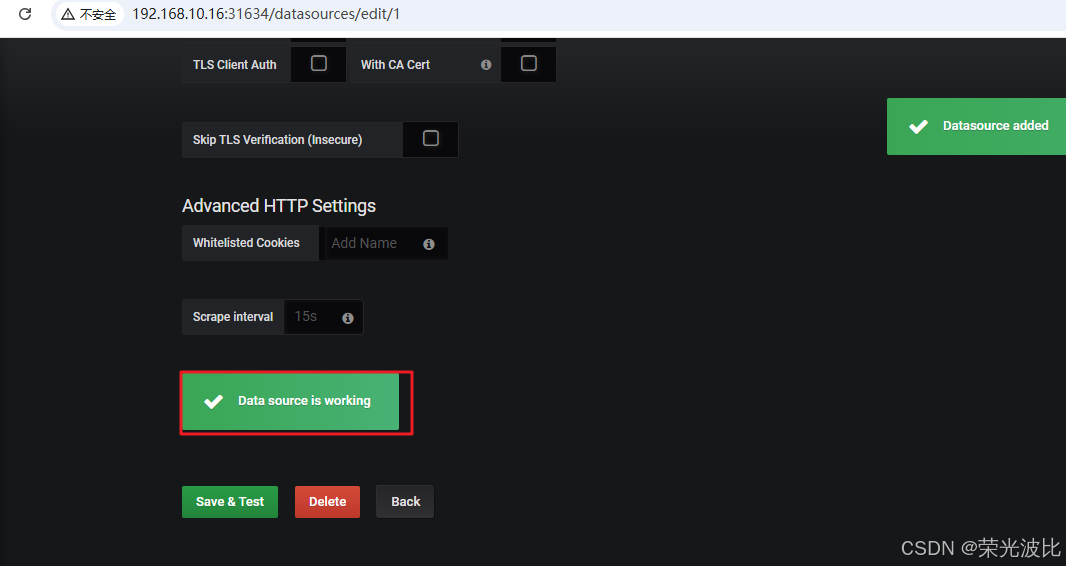
3、点击Save & Test,若提示Data source is working,说明数据源配置成功。
4.4 导入监控模板(快速生成仪表盘)
Grafana社区提供大量现成模板(https://grafana.com/dashboards),可直接导入查看节点、容器等监控数据。
4.4.1 导入节点监控模板
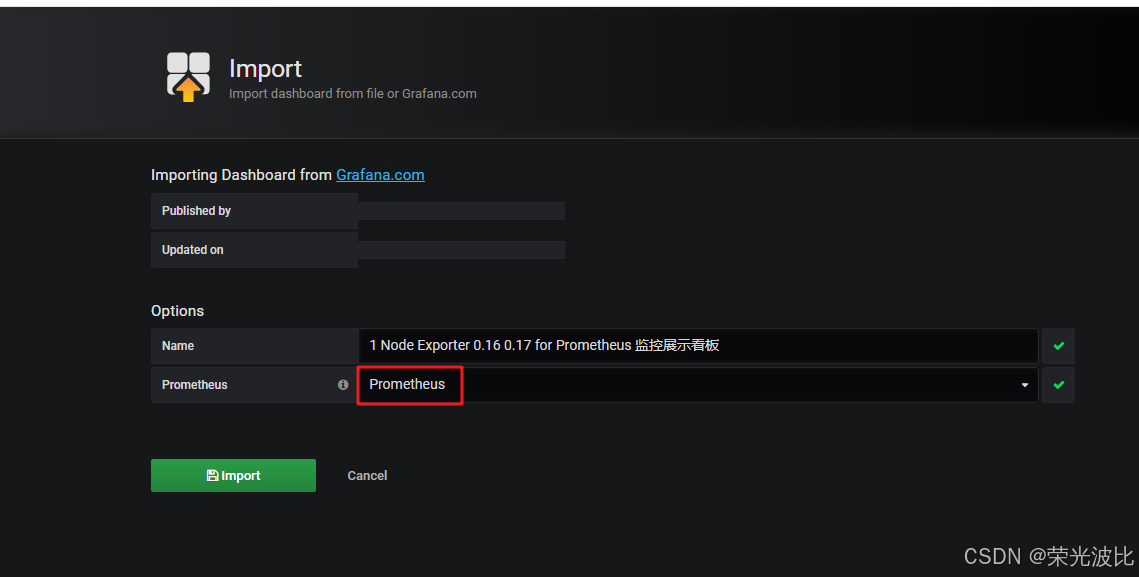
1、点击左侧+号→Import;
2、点击Upload .json File,选择本地的node_exporter.json模板(可从社区下载,搜索关键词“node exporter”);
3、在Prometheus下拉框中选择之前配置的Prometheus数据源;
4、点击Import,即可查看节点的CPU、内存、磁盘、网络等监控仪表盘。
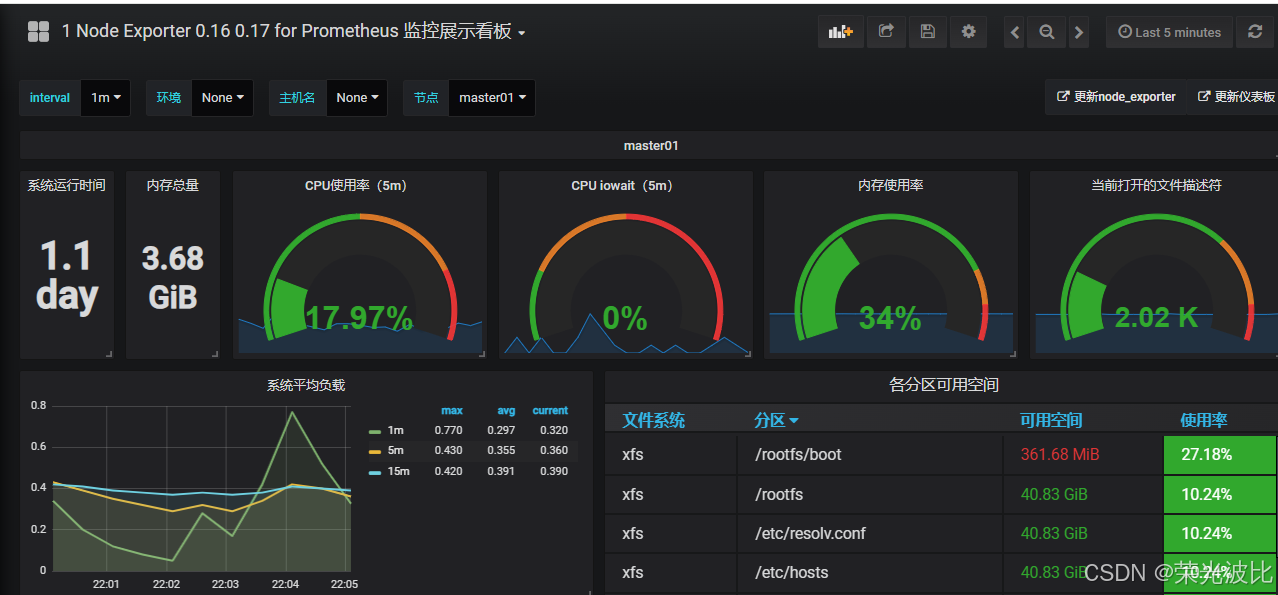
4.4.2 导入容器监控模板
1、重复步骤4.4.1的1-2,上传docker_rev1.json模板(社区搜索关键词“docker container”);
2、选择Prometheus数据源并导入,即可查看容器的CPU使用率、内存占用、网络IO等指标。
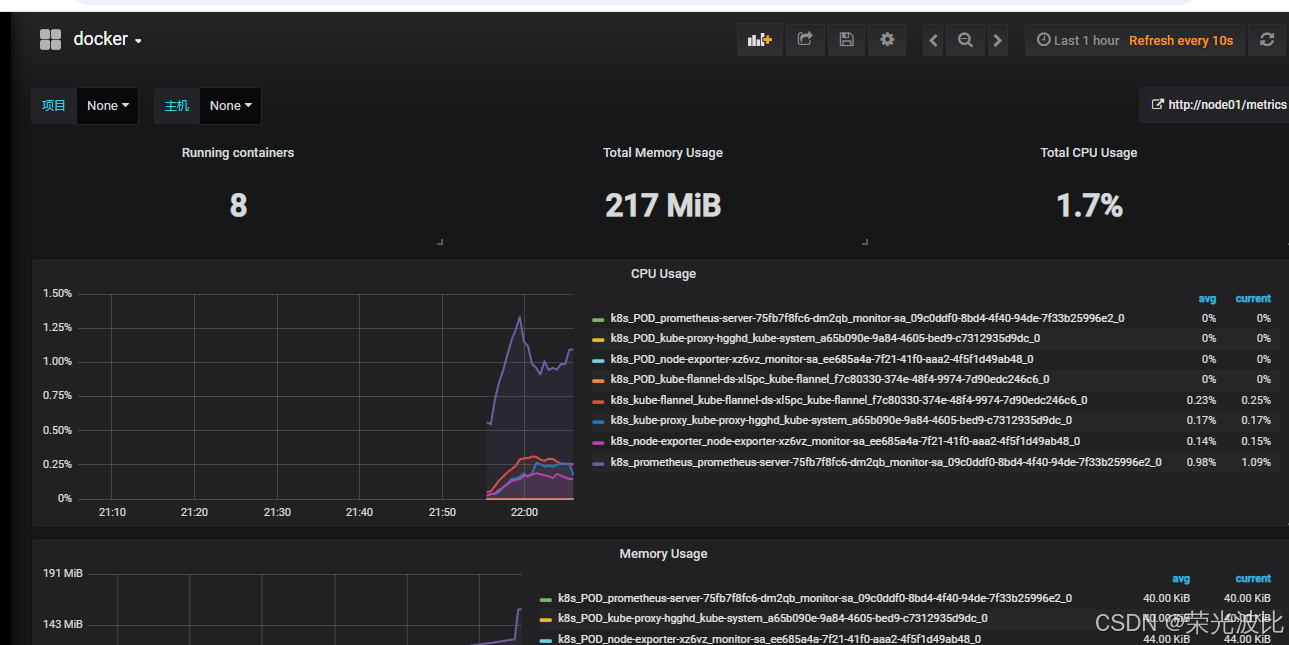
五、部署kube-state-metrics(采集K8s资源指标)
node-exporter采集节点硬件指标,kube-state-metrics则采集K8s资源对象(如Pod、Deployment、Service)的状态指标(如Pod运行状态、Deployment副本数),需配合Grafana模板查看。
5.1 创建RBAC授权(kube-state-metrics专用)
kube-state-metrics需访问K8s API获取资源信息,需创建专用SA账号并授权:
1、编写RBAC清单:
vim /opt/prometheus/kube-state-metrics-rbac.yaml
2、粘贴以下配置:
# 1、创建SA账号
---
apiVersion: v1
kind: ServiceAccount
metadata:name: kube-state-metricsnamespace: kube-system# 2、创建ClusterRole(定义访问权限)
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:name: kube-state-metrics
rules:
- apiGroups: [""]resources: ["nodes", "pods", "services", "resourcequotas", "replicationcontrollers", "limitranges", "persistentvolumeclaims", "persistentvolumes", "namespaces", "endpoints"]verbs: ["list", "watch"] # 仅允许列表和监听操作(只读权限)
- apiGroups: ["extensions"]resources: ["daemonsets", "deployments", "replicasets"]verbs: ["list", "watch"]
- apiGroups: ["apps"]resources: ["statefulsets"]verbs: ["list", "watch"]
- apiGroups: ["batch"]resources: ["cronjobs", "jobs"]verbs: ["list", "watch"]
- apiGroups: ["autoscaling"]resources: ["horizontalpodautoscalers"]verbs: ["list", "watch"]# 3、绑定ClusterRole到SA账号
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:name: kube-state-metrics
roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: kube-state-metrics
subjects:
- kind: ServiceAccountname: kube-state-metricsnamespace: kube-system
3、创建RBAC授权:
kubectl apply -f /opt/prometheus/kube-state-metrics-rbac.yaml
5.2 部署kube-state-metrics实例与Service
1、编写部署清单:
vim /opt/prometheus/kube-state-metrics-deploy.yaml
2、粘贴以下配置:
# 1、Deployment:部署kube-state-metrics
---
apiVersion: apps/v1
kind: Deployment
metadata:name: kube-state-metricsnamespace: kube-system
spec:replicas: 1selector:matchLabels:app: kube-state-metricstemplate:metadata:labels:app: kube-state-metricsspec:serviceAccountName: kube-state-metrics # 使用专用SA账号containers:- name: kube-state-metricsimage: quay.io/coreos/kube-state-metrics:v1.9.0 # 稳定版本ports:- containerPort: 8080 # 默认端口# 2、Service:暴露指标访问端口(供Prometheus采集)
---
apiVersion: v1
kind: Service
metadata:annotations:prometheus.io/scrape: 'true' # 标注该Service需被Prometheus采集name: kube-state-metricsnamespace: kube-systemlabels:app: kube-state-metrics
spec:ports:- name: kube-state-metricsport: 8080protocol: TCPselector:app: kube-state-metrics
3、部署并验证:
# 部署
kubectl apply -f /opt/prometheus/kube-state-metrics-deploy.yaml# 验证Pod与Service状态
kubectl get pods,svc -n kube-system -l app=kube-state-metrics
# 预期输出:Pod状态为Running,Service端口为8080

5.3 导入K8s集群监控模板
1、进入Grafana,点击左侧+号→Import;
2、上传kubernetes-cluster-prometheus_rev4.json模板(监控集群资源状态)和kubernetes-cluster-monitoring-via-prometheus_rev3.json模板(监控集群性能);
3、选择Prometheus数据源并导入,即可查看K8s集群的Pod数量、Deployment状态、Namespace资源使用等指标。
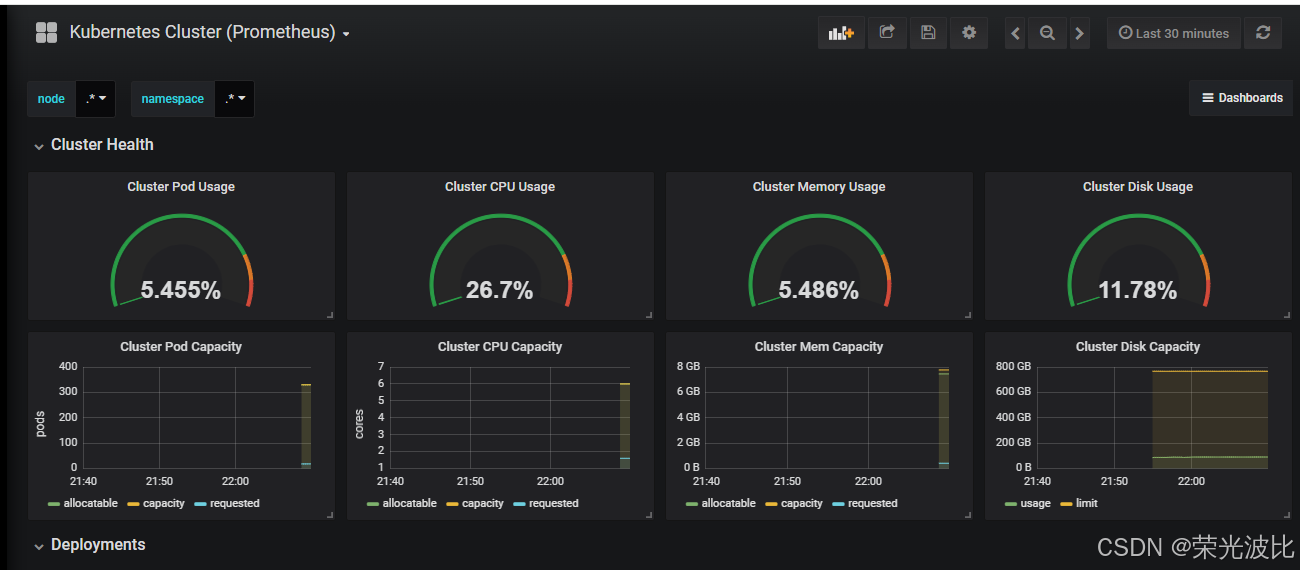
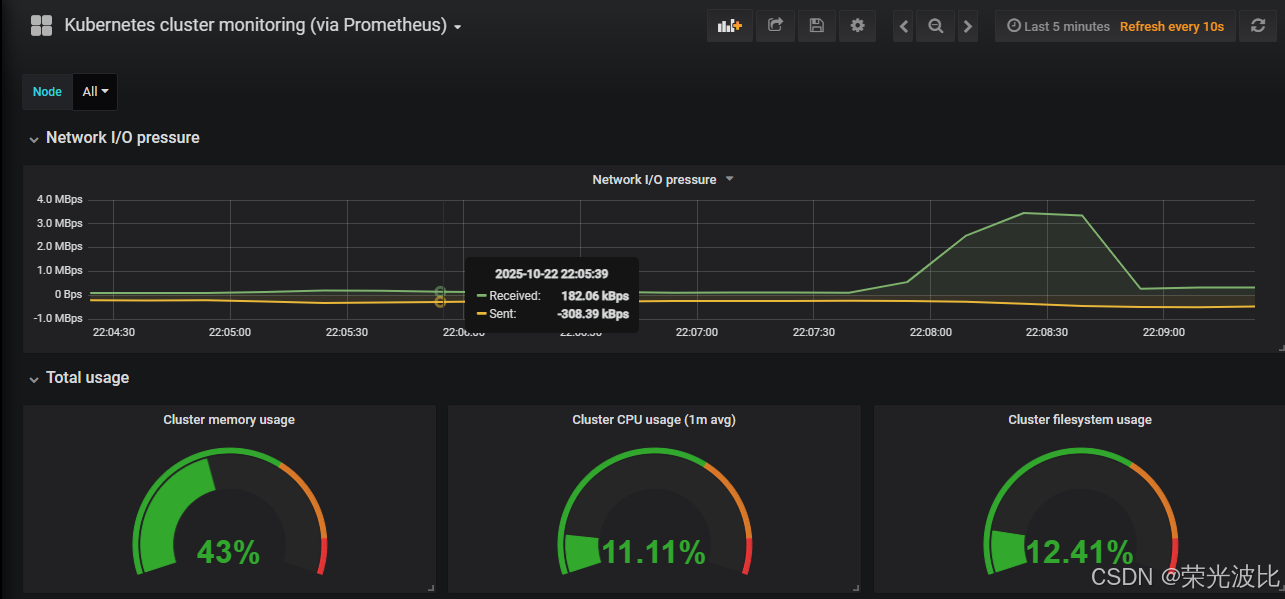
六、配置AlertManager实现邮件告警
当监控指标超出阈值(如节点CPU使用率>80%、Pod重启次数>3)时,Prometheus会触发告警,AlertManager负责接收告警、分组、抑制,并通过邮件等方式通知运维人员。
6.1 Prometheus告警处理流程
先了解告警触发的完整逻辑,便于后续配置排查:
1、Prometheus按scrape_interval定期采集目标指标;
2、若目标接口不可用,超过scrape_timeout后标记为DOWN;
3、Prometheus按evaluation_interval定期评估告警规则,若指标满足告警条件,进入PENDING状态;
4、若告警条件持续满足(超过规则中定义的for时长),状态变为FIRING,并将告警发送给AlertManager;
5、AlertManager按配置的group_by分组告警,等待group_wait后发送;
6、同组告警后续触发时,按group_interval间隔发送;
7、未恢复的告警按repeat_interval重复发送。
6.2 配置AlertManager(邮件发送参数)
通过ConfigMap存储AlertManager的核心配置(SMTP服务器、发件人、收件人等)。
1、编写AlertManager ConfigMap清单:
vim /opt/prometheus/alertmanager-cm.yaml
2、粘贴以下配置:
kind: ConfigMap
apiVersion: v1
metadata:name: alertmanagernamespace: monitor-sa
data:alertmanager.yml: |-global: # 全局SMTP配置resolve_timeout: 1m # 告警恢复后,标记为resolved的超时时间smtp_smarthost: 'smtp.qq.com:465' # QQ邮箱SMTP服务器(465端口为SSL加密)smtp_from: 'your_qq_email@qq.com' # 发件人邮箱(替换为你的QQ邮箱)smtp_auth_username: 'your_qq_email@qq.com' # 发件人邮箱账号smtp_auth_password: 'your_auth_code' # QQ邮箱授权码(非登录密码,需在QQ邮箱设置中生成)smtp_require_tls: false # 关闭TLS强制要求(避免与SSL直连冲突)route: # 告警路由策略group_by: [alertname] # 按告警名称分组(同名称告警合并为一封邮件)group_wait: 10s # 分组等待时间(收集同组告警后一起发送)group_interval: 10s # 同组告警再次触发的发送间隔repeat_interval: 10m # 未恢复告警的重复发送间隔(10分钟一次)receiver: default-receiver # 默认收件人receivers: # 收件人配置- name: 'default-receiver'email_configs:- to: 'your_target_email@139.com' # 收件人邮箱(替换为你的邮箱,支持多个用逗号分隔)send_resolved: true # 告警恢复后,发送恢复通知邮件
注意:QQ邮箱授权码获取方式:登录QQ邮箱→设置→账户→开启POP3/SMTP服务→点击生成授权码。
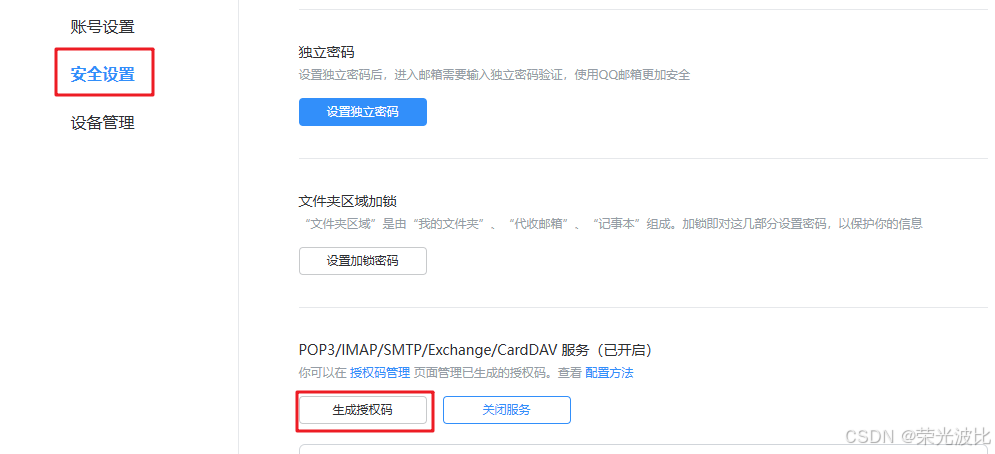
3、创建ConfigMap:
kubectl apply -f /opt/prometheus/alertmanager-cm.yaml
6.3 更新Prometheus配置(关联AlertManager)
需修改Prometheus的ConfigMap,添加AlertManager地址与告警规则(此处省略告警规则配置,可参考Prometheus官方文档添加,如节点CPU使用率过高、Pod DOWN等规则)。
1、准备好包含告警规则的Prometheus配置文件prometheus-alertmanager-cfg.yaml(在原prometheus-cfg.yaml基础上添加alerting配置),执行更新:
# 删除旧ConfigMap
kubectl delete -f /opt/prometheus/prometheus-cfg.yaml
# 创建新ConfigMap(包含AlertManager关联配置)
kubectl apply -f /opt/prometheus/prometheus-alertmanager-cfg.yaml
# 验证ConfigMap创建成功
kubectl get cm -n monitor-sa
# 预期输出:alertmanager、prometheus-config均存在

6.4 部署包含AlertManager的Prometheus实例
将AlertManager与Prometheus部署在同一个Pod中(简化架构,生产环境可独立部署),并挂载etcd证书(用于监控etcd)。
1、创建etcd证书Secret(Prometheus监控etcd需用到):
kubectl -n monitor-sa create secret generic etcd-certs \--from-file=/etc/kubernetes/pki/etcd/server.key \--from-file=/etc/kubernetes/pki/etcd/server.crt \--from-file=/etc/kubernetes/pki/etcd/ca.crt
2、编写Prometheus+AlertManager部署清单:
vim /opt/prometheus/prometheus-alertmanager-deploy.yaml
3、粘贴以下配置(调度到node01):
apiVersion: apps/v1
kind: Deployment
metadata:name: prometheus-servernamespace: monitor-salabels:app: prometheus
spec:replicas: 1selector:matchLabels:app: prometheuscomponent: servertemplate:metadata:labels:app: prometheuscomponent: serverannotations:prometheus.io/scrape: 'false'spec:nodeName: node01 # 调度到node01(192.168.10.15)serviceAccountName: monitorcontainers:# 1、Prometheus容器- name: prometheusimage: prom/prometheus:v2.2.1imagePullPolicy: IfNotPresentcommand:- "/bin/prometheus"args:- "--config.file=/etc/prometheus/prometheus.yml"- "--storage.tsdb.path=/prometheus"- "--storage.tsdb.retention=24h" # 数据保留24小时(测试环境可缩短)- "--web.enable-lifecycle"ports:- containerPort: 9090protocol: TCPvolumeMounts:- mountPath: /etc/prometheusname: prometheus-config- mountPath: /prometheus/name: prometheus-storage-volume- name: k8s-certs # 挂载etcd证书mountPath: /var/run/secrets/kubernetes.io/k8s-certs/etcd/- name: localtime # 同步宿主机时间(避免日志时间偏差)mountPath: /etc/localtime# 2、AlertManager容器- name: alertmanagerimage: prom/alertmanager:v0.14.0imagePullPolicy: IfNotPresentargs:- "--config.file=/etc/alertmanager/alertmanager.yml" # 关联AlertManager配置- "--log.level=debug" # 开启debug日志(便于排查问题)ports:- containerPort: 9093 # AlertManager默认端口protocol: TCPname: alertmanagervolumeMounts:- name: alertmanager-config # 挂载AlertManager配置mountPath: /etc/alertmanager- name: alertmanager-storage # 挂载AlertManager数据目录mountPath: /alertmanager- name: localtimemountPath: /etc/localtime# 定义挂载源volumes:- name: prometheus-configconfigMap:name: prometheus-config- name: prometheus-storage-volumehostPath:path: /datatype: Directory- name: k8s-certssecret:secretName: etcd-certs- name: alertmanager-configconfigMap:name: alertmanager- name: alertmanager-storagehostPath:path: /data/alertmanager # 宿主机node01的/data/alertmanager目录type: DirectoryOrCreate # 目录不存在则自动创建- name: localtimehostPath:path: /usr/share/zoneinfo/Asia/Shanghai # 同步上海时区
4、部署并验证:
# 删除旧Prometheus Deployment
kubectl delete -f /opt/prometheus/prometheus-deploy.yaml
# 部署新的Prometheus+AlertManager
kubectl apply -f /opt/prometheus/prometheus-alertmanager-deploy.yaml
# 验证Pod状态(确保2个容器均Ready)
kubectl get pods -n monitor-sa | grep prometheus
# 预期输出:prometheus-server-xxx 2/2 Running

6.5 创建AlertManager Service(暴露访问入口)
1、编写Service清单:
vim /opt/prometheus/alertmanager-svc.yaml
2、粘贴以下配置:
apiVersion: v1
kind: Service
metadata:labels:name: prometheuskubernetes.io/cluster-service: 'true'name: alertmanagernamespace: monitor-sa
spec:ports:- name: alertmanagernodePort: 30066 # 固定NodePort端口port: 9093 # Service内部端口protocol: TCPtargetPort: 9093 # 映射到AlertManager容器的9093端口selector:app: prometheus # 匹配Prometheus Pod标签sessionAffinity: Nonetype: NodePort
3、创建Service并验证:
kubectl apply -f /opt/prometheus/alertmanager-svc.yaml
# 查看Service端口
kubectl get svc -n monitor-sa
# 预期输出:alertmanager NodePort 10.96.37.197 <none> 9093:30066/TCP
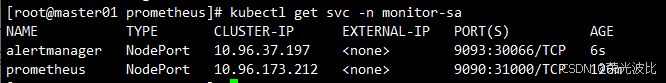
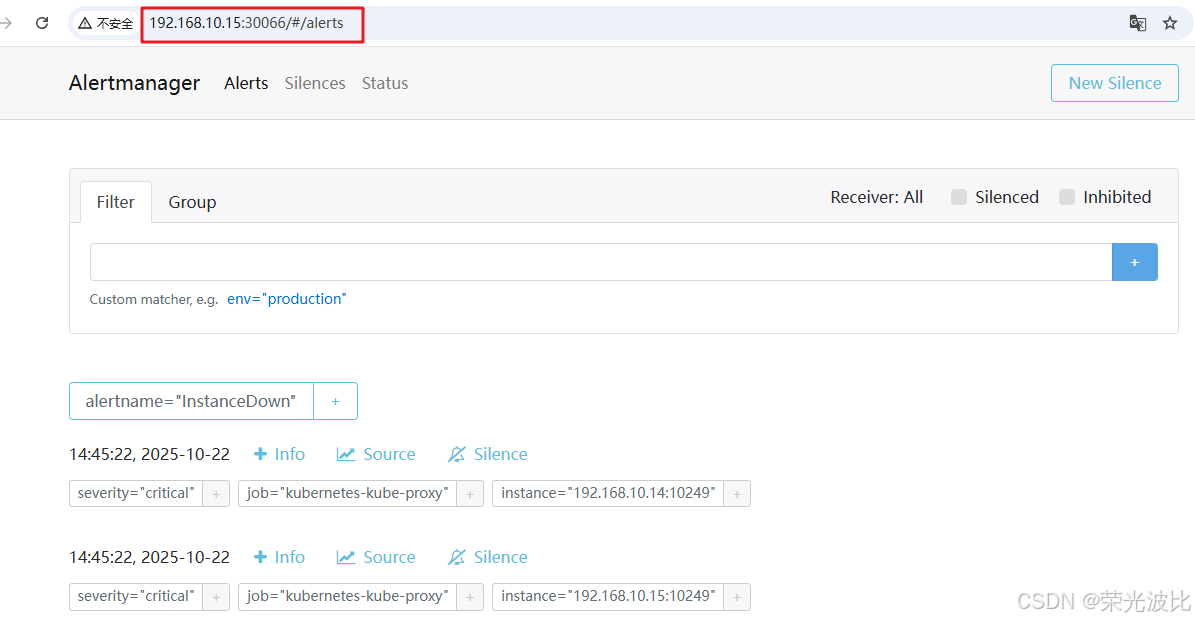
4、访问AlertManager Web UI:
打开浏览器,输入http://192.168.10.15:30066/#/alerts(node01的IP+30066端口),可查看当前告警状态。
6.6 处理kube-proxy监控告警(可选)
默认情况下,kube-proxy的metrics端口(10249)仅监听127.0.0.1,Prometheus无法采集,会触发告警,需修改配置:
1、编辑kube-proxy的ConfigMap:
kubectl edit configmap kube-proxy -n kube-system
2、找到metricsBindAddress字段,将值从127.0.0.1:10249改为0.0.0.0:10249(监听所有网卡):
metricsBindAddress: "0.0.0.0:10249"
3、保存退出后,重启所有kube-proxy Pod(使配置生效):
kubectl get pods -n kube-system | grep kube-proxy |awk '{print $1}' | xargs kubectl delete pods -n kube-system
4、验证端口监听(在任意节点执行):
ss -antulp | grep :10249
# 预期输出:tcp LISTEN 0 128 :::10249 :::* users:(("kube-proxy",pid=xxx,fd=xx))

此时,Prometheus可正常采集kube-proxy指标,相关告警会自动清除。
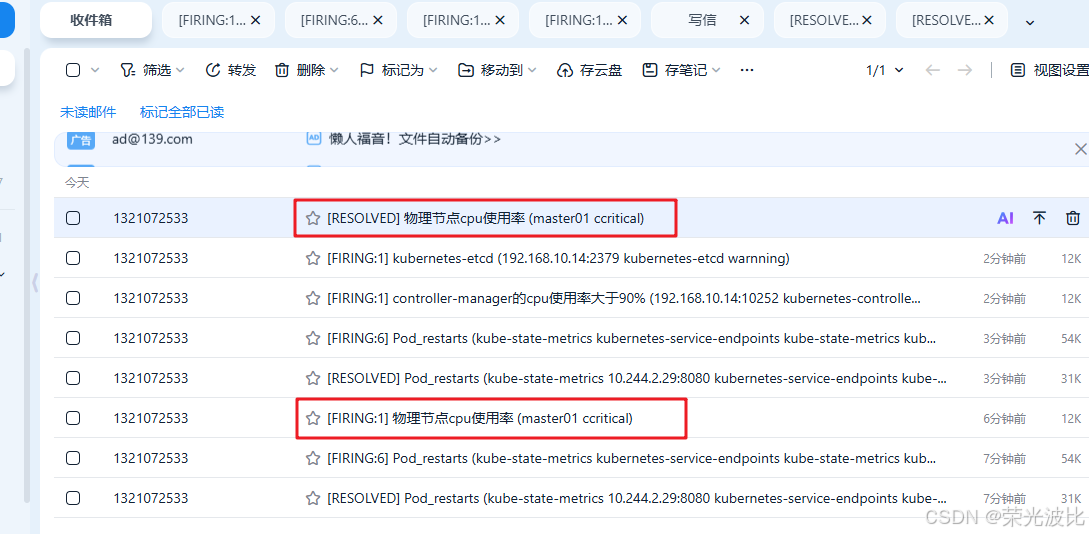
6.7 邮件告警功能测试
验证邮件告警是否生效,可以在master节点上进行压测,触发“cpu使用率”告警。
# 在master节点上执行
stress -c 4
# 查看是否收到告警邮件
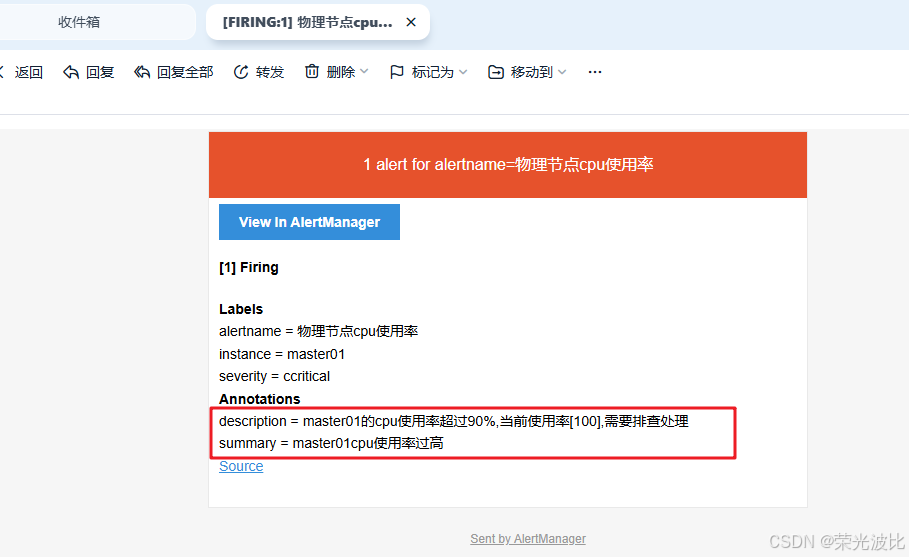
查看收件人邮箱。若配置正确,会收到类似以下内容的告警邮件:
- 标题:[FIRING:1] 物理节点cpu使用率 (master01 ccritical)
- 内容:包含实例名称、告警时间、告警描述等信息。
告警测试完成后,停止压测,恢复监控:
等待1分钟(与resolve_timeout: 1m一致)后,会收到“告警已解决”的邮件通知。
总结
本文围绕“K8s集群全维度监控”目标,完成了从组件部署到功能验证的完整落地,核心链路可概括为“数据采集→存储计算→可视化呈现→异常告警”,各环节环环相扣,形成了可复用的监控方案。
核心成果回顾
- 数据采集层:通过
node-exporter(DaemonSet部署)覆盖所有节点的CPU、内存、磁盘指标,借助kube-state-metrics补充K8s资源状态(如Pod运行状态、Deployment副本就绪率),解决了“只看节点、不看资源”的监控断层; - 存储计算层:Prometheus通过RBAC授权获取K8s资源访问权限,结合ConfigMap实现配置热加载,避免重启导致的数据丢失,同时通过Service暴露Web UI,支持指标查询与Target健康检查;
- 可视化层:Grafana通过导入社区模板,快速生成节点、容器、集群资源的仪表盘,无需手动配置复杂图表,降低了可视化门槛;
- 告警层:AlertManager通过SMTP配置实现邮件告警,解决了“故障发生后无人知晓”的问题,同时通过分组、抑制策略减少告警风暴,确保运维人员聚焦关键问题。
关键配置要点
本次部署中需重点关注3个核心细节,这也是新手常踩的坑:
- 权限配置:Prometheus与kube-state-metrics均需通过SA账号绑定
cluster-admin或专用ClusterRole,否则会因权限不足无法采集K8s资源指标; - SMTP适配:QQ邮箱需使用465端口(SSL加密)与授权码(非登录密码),若用25端口可能被运营商封锁,导致邮件发送失败;
- 端口监听:kube-proxy默认仅监听127.0.0.1:10249,需修改为0.0.0.0:10249才能被Prometheus采集,避免不必要的告警误报。