论文学习_One Bug, Hundreds Behind: LLMs for Large-Scale Bug Discovery
标题: One Bug, Hundreds Behind: LLMs for Large-Scale Bug Discovery (Qiushi Wu,2025)
作者: Qiushi Wu, Yue Xiao, Dhilung Kirat, Kevin Eykholt, Jiyong Jang, Douglas Lee Schales
期刊: Arxiv
摘要
管理大型程序和修复漏洞是一项具有挑战性的任务,需要投入大量的时间和人工精力。实际中,当发现一个漏洞时,通常会将其报告给项目维护者,维护者与报告者合作修复问题。一旦漏洞被修复,该问题就会被标记为已关闭。然而,在整个程序中,往往存在许多相似的代码片段,这些片段可能也包含相同的漏洞,但在最初的发现过程中被遗漏。逐个查找和修复这些重复出现的漏洞实例非常耗时。更令人担忧的是,漏洞报告有时会无意中扩大攻击面,因为它们为攻击者提供了一种可利用的模式,而这种模式可能在程序的其他部分仍未修复。
本文探讨了这些重复模式漏洞(Recurring Pattern Bugs, RPBs)——它们源自同一根本原因,反复出现在程序的不同代码段甚至不同程序中,即使已有修复方案,也可能仍未被解决。我们的研究发现,RPBs 不仅普遍存在,还可能严重威胁软件程序的安全性。虽然已有多种静态分析工具可以用于查找特定的漏洞模式,但这些工具通常需要大量的工程投入,且难以推广到预定义模板之外的情况。
同源漏洞(侧重于代码本身)-重复模式漏洞(侧重于代码功能)
为了解决 RPB 问题并提升项目维护效率,本文提出了BUGSTONE,一个结合 LLVM 与大型语言模型(LLM)的程序分析系统。核心思想是:许多 RPB 通常只有一个实例被修补,因此可以利用该修补实例来提炼出一致的错误模式(例如特定的 API 误用)。通过在整个程序中搜索这一模式,就能发现其他可能受相同类型漏洞影响的代码片段。以 135 个独特的种子 RPB 为起点,BUGSTONE 在 Linux 内核中识别出了超过 2.2 万个潜在问题。对其中 400 个结果进行人工分析后,确认有 246 个是真实漏洞。这些问题包括无效指针解引用、资源泄露、类型错误、性能问题等,均对程序的安全性和稳定性构成威胁。
结合LLVM与LLM,从已知漏洞中提炼出一致的错误模式,例如特定的API误用。
LLVM 是一个强大的编译器基础设施框架,它将源代码转换为通用的中间表示(IR),经过优化后生成高效的机器代码,同时也为代码分析和安全研究提供了理想的平台。
此外,我们还基于 23 篇近年顶级会议论文中报告的 1900 余个 Linux 内核安全漏洞构建了一个数据集。我们对该数据集进行了人工标注,识别出 80 种重复漏洞模式及其 850 个对应修复实例,并在该数据集上对 BUGSTONE 进行了评估,覆盖 6 种不同的 LLM 和 6 种提示配置。即便采用成本较低的模型,BUGSTONE 依然实现了 92.2% 的精确率 和 79.1% 的成对匹配准确率,展示了其在真实程序中精准识别 RPB 的能力。
基于Linux内核漏洞构建数据集并对工作进行验证,未提及是否挖掘出新的漏洞。
引言
维护大型程序需要大量的人工劳动,包括调试、提升性能、升级功能等。比如,一项最近的研究显示,近年来,Linux 内核每年接收超过 80,000 次提交,其中约 10,000 次是用于修复漏洞,这凸显了巨大的维护工作量。随着时间的推移,程序的规模和复杂性的增加使得这一情况更加严重,导致漏洞报告的数量上升,并且对维护的需求也随之增加。例如,通过使用 Cloc 工具来衡量代码库的大小,Linux 内核从版本 2.6.12 的 500 万行代码增长到版本 6.8 的 2800 万行,这反映了程序规模的显著增长。
鉴于代码库的庞大规模,大型项目通常采用以下两种维护策略。首先是模块化维护,即将一个或多个维护者指派负责管理程序的特定子模块,从而实现更集中的管理和更高效的维护。其次是开放报告,即鼓励所有用户在遇到问题时报告漏洞或提交修复补丁,从而促进协作和包容的维护过程。
模块化和协作维护策略中固有的安全挑战。尽管这种维护方式对于独立模块非常有效,但这些策略也存在以下不足,并带来潜在的安全隐患。首先,API 函数的更新可能不会及时或充分地集成到所有下游或依赖模块中。这是供应链中的一个众所周知的问题,维护者负责多个模块,可能无法及时完全了解或理解 API 变更的影响。其次,由于多个贡献者的反复疏忽以及模块化维护策略的影响,相似的漏洞可能在不同模块中出现。用户通常专注于解决自己遇到的特定问题,这使得其他模块或代码区域中的类似问题得不到解决。因此,重复的工作浪费在反复识别、报告、审查、测试和修复类似的重复漏洞上。例如,最近的研究表明,一个单一的 API 函数可能会引发数百个类似的漏洞,每个漏洞都由单独的补丁进行处理。最后,最关键的问题是,针对单个重复问题的修复可能无意中帮助攻击者发现并利用整个代码库中相似的潜在漏洞。因此,这类问题不仅会加剧维护挑战,还会导致安全问题。
为了高效解决大型软件项目中的维护和安全问题,现代策略集中于三种核心方法。首先,漏洞报告分类和优先级排序使维护者能够迅速处理关键问题,从而缩短软件中漏洞的生命周期。其次,识别重复的漏洞报告通过防止冗余工作,提高了维护效率。第三,漏洞检测结合了静态和动态分析技术,包括基于规则的方法、统计方法和模糊测试,从多个角度主动识别和解决漏洞,从而增强软件的可靠性和安全性。
然而,采用独立漏洞检测方法时,根本原因——未解决的重复漏洞——仍无法得到妥善处理。考虑到当前代码库的规模和现有补丁的数量,我们需要一种自动化方法来识别重复漏洞,因为维护者忙于解决新报告的漏洞。解决方案需要能够直接从现有补丁中提取和总结重复的漏洞模式。此外,这些模式应该是通用的。它们应当匹配代码模式,而不是特定的 API 调用,例如函数名称,应匹配诸如在错误发生时未能释放由特定函数分配的资源等模式。传统的程序分析方法通常依赖于手动识别漏洞模式或通过交叉检查大量函数调用来提取漏洞模式。它们还需要为每种特定的漏洞模式定制专门的代码分析器。最近的研究表明,纯基于大型语言模型(LLM)的方法在准确检测和分析漏洞方面仍然存在不足。
论文将这些相似的漏洞称为重复模式漏洞(Recurring Pattern Bugs, RPBs)。这个术语表明,这些漏洞不仅源于反复的疏忽,还具有共享的语义特征,从而在多个相似的代码实现中形成一致的模式。该项目的目标是提供一种系统化的方法来识别重复模式漏洞。为此,我们提出了BUGSTONE,一个以补丁为中心的系统,通过利用单个补丁作为线索,揭示程序中所有相关的漏洞。
论文首先给出重复模式漏洞(RPBs)的定义,之后提出一个以补丁为中心的自动化RPBs检测系统BUGSTONE,该系统利用单个补丁为线索,揭示程序中所有相关的漏洞。
具体而言,当报告者提交一个新补丁时,BUGSTONE 利用静态程序分析器扩展补丁周围的代码。这个步骤旨在丰富补丁的上下文信息,因为补丁通常只提供修改周围的几行代码,这对于补丁总结和漏洞识别等任务来说通常是不足够的。然后,BUGSTONE 使用大型语言模型(LLM)将补丁的细节总结为一个精确的编码规则,同时确定导致漏洞的 API 函数或代码片段。接下来,BUGSTONE 利用静态程序分析器进一步检测潜在的相似代码实现及其相关的上下文信息。在最后一步,借助 LLM 的能力,BUGSTONE 评估这些识别出的实例是否受到补丁修复的相同问题的影响。这个过程通过构建一个结构化良好的提示来实现,提示结合了预处理的补丁(可选)、推导出的安全编码规则和需要分析的目标代码实例。最终,BUGSTONE 可以自主适应具有重复模式的漏洞,而无需为每个单独的漏洞开发定制的专用工具。
为了展示BUGSTONE的有效性,我们在一个包含80个重复模式和850个相应重复模式漏洞的真实数据集上进行了评估。在该数据集上,BUGSTONE实现了92.2%的精确率和79.1%的成对准确率。随后,我们将135条独特的安全编码规则应用于Linux内核,BUGSTONE识别出了22,568个潜在违规行为,处理了超过1.17亿个输入标记,并生成了超过9,900万个输出标记。在从400个发现中抽取的样本中,246个被确认是真实漏洞,可能导致类似于已修复问题的情况,包括内存泄漏、无效指针解引用等问题。
研究背景
重复模式漏洞:由于错误使用相同的API、代码段或代码模式而引发的重复性和相似性错误;
安全编码规则:指定API或代码段正确使用的简明声明;违反该规则可能会引入安全漏洞;
补丁种子:修复单个RPB实例的代表性补丁。它可以 用于识别RPB或生成相应的安全编码规则。
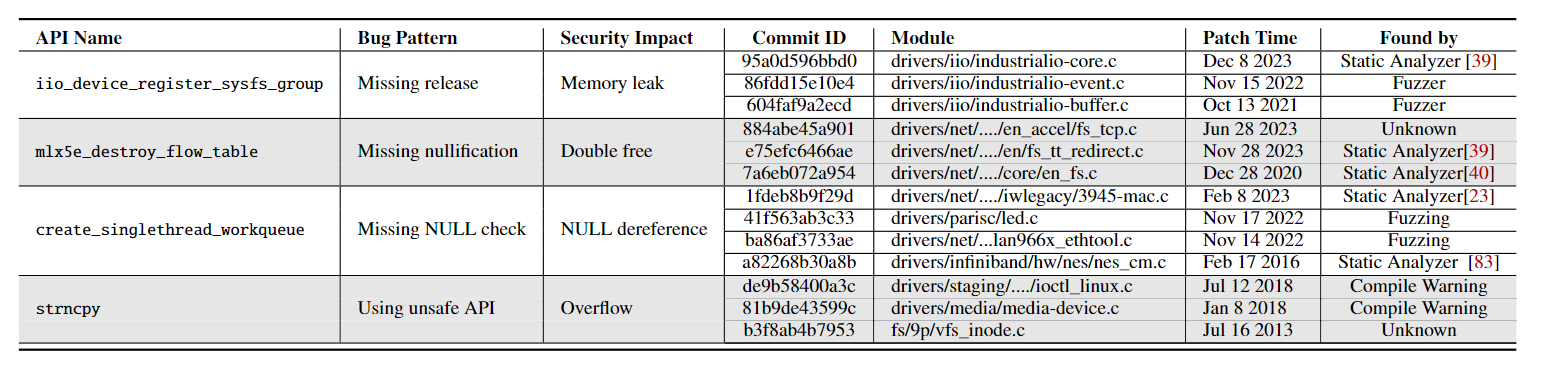
为了理解这些错误为何发生,我们分析了Linux内核,因为它是一个大型、维护良好、活跃的开源项目,具有丰富的补丁历史,便于挖掘。我们手动审查了Linux内核的补丁,并识别出多个针对相似错误的API。这些错误在安全影响上有所不同,但都是RPB的实例。表1中展示了这些错误的示例和相关信息。RPBs的成因总结如下:
- 重复的错误:开发人员由于对代码不熟悉,可能会错误地使用API函数或重用有缺陷的代码片段。例如,由于误解围绕引用计数操作的包装函数语义,使计数的增减不正确。
- 安全防护措施的遗漏:一些API函数或代码片段可能会失败,因此需要伴随错误处理代码,通常由调用者负责,以防范潜在的安全问题。许多RPB发生是因为这些防护措施,如返回值检查或指针置空,缺失。一项先前的补丁分析研究显示,安全漏洞往往是由多个错误条件的相互作用引起的。例如,释放指针后再次解引用可能会导致“使用后释放”(use-after-free)错误。原始代码可能正确实现了类似kfree(P)的API调用,但代码的更改可能会在kfree(P)之后引入对P的解引用。这可能发生在调用kfree(P)的同一函数中,也可能发生在其他地方,另一个函数甚至是另一个线程中,从而导致隐藏的“使用后释放”错误。

发生的容易性:一个单一的错误是否最终成为RPB,取决于三个因素:(1)错误使用的API或代码片段被调用的次数,(2)它多容易被错误使用,以及(3)如果存在防护措施,开发人员是否能一致地应用这些措施。以宏create_singlethread_workqueue为例,图1中展示了一个补丁。这个宏在失败时可能返回NULL。因此,补丁添加了缺失的防护措施:检查返回的指针是否为NULL,并执行必要的清理。然而,这个宏在Linux内核中被调用超过197次,并且并不是每次调用都有适当的防护。我们对Linux内核补丁历史的审查发现了16个独立的修复,其中四个在表1中有所突出,修复了遗漏该防护措施的调用点,避免了NULL指针解引用。在某些情况下,某些API更容易出错,这使得这些API的RPB更常见。例如,尽管pm_runtime_get_sync函数在内核中仅被调用了几百次,但它仍然引入了超过九十个错误。该函数无条件地增加其内部引用计数,偏离了资源获取API通常的“成功时增加”的模式。这种偏离常常导致开发人员未能减少相应的引用计数。
时间和安全影响:如表1所示,RPB可以出现在同一模块中,也可以跨多个模块,并可能是单个开发者或多个开发者在一段时间内的贡献结果。模块化的维护使得由于缺乏对相关补丁的意识和复杂的依赖关系,识别和修复RPB变得困难。此外,尽管大型项目定期执行编码标准,但开发者的多样性不可避免地导致了代码库中的一些差异,从而增加了RPB发生的概率。一旦引入,可能是由于新的调用或API的变化,它可能会长时间得不到解决。例如,宏create_singlethread_workqueue分配一个工作队列,在失败时返回NULL,其返回值必须检查以避免NULL解引用。根据补丁历史,我们发现跨越七年的四个补丁(从2016年到2023年)修复了多个驱动程序中未保护使用该宏的问题。现有检测方法的局限性通常只能揭示一些孤立的RPB实例。模糊测试(Fuzzing),在我们研究的13个补丁中的四个补丁中使用,只修复了触发的问题,而不是内核中的所有问题。此外,RPB会导致广泛的安全后果。如表1所示,它们可能表现为内存泄漏、NULL指针解引用、引用计数泄漏、使用后释放错误和缓冲区溢出等。
研究内容
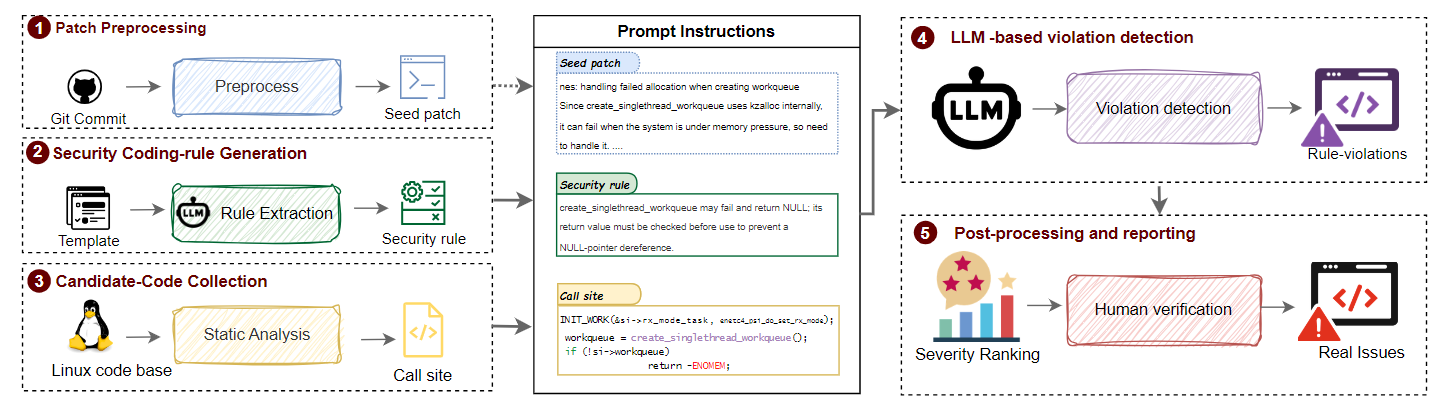
图2展示了BUGSTONE的端到端工作流程。首先,BUGSTONE接收一个对应于错误修复的Git提交。与修复无关的信息(如diff头信息、URL等)会被移除,并且识别出包含修复的完整函数。这形成了一个种子补丁,包含“清理”后的补丁信息和周围的代码上下文。其次,种子补丁通过一个提示模板(见表7)发送给大语言模型(LLM),该模板指示LLM提出一个简洁的规则,指定错误使用的API或代码片段的正确使用模式。第三,一个轻量级静态分析器扫描整个代码库,收集与重复模式相关的API或代码片段的所有调用点,并将它们标记为潜在的RPB候选项。第四,对于每个候选项,BUGSTONE将调用点的代码上下文与提取的安全规则和种子补丁结合,生成LLM提示。该提示指示语言模型判断该调用点是否违反了安全规则(完整模板见表8)。最后,BUGSTONE汇总所有候选项的模型响应,进行后处理验证,并将疑似违规项提交给人工开发者进行人工审查。所有经过人工验证仍然存在的问题将被送去修复。
例如,考虑图1中的提交a82268b30a8b。在步骤1中,BUGSTONE通过去除补丁信息中的无关元数据,并提取包含create_singlethread_workqueue宏误用的nes_cm_alloc_core函数,从而形成了一个种子补丁。步骤2中,种子补丁被提供给LLM提取器,LLM提出了以下安全规则:“create_singlethread_workqueue可能失败并返回NULL;在使用其返回值之前,必须检查它以防止NULL指针解引用。”在步骤3中,静态分析器扫描create_singlethread_workqueue的调用点,找到了197个代码段。这些代码段在步骤4中通过违规指令提示被LLM处理,BUGSTONE标记了10个新的潜在违规案例。在人工审查中,确认了四个真正的违规项,其中三个是与种子补丁修复的错误类似的漏洞。该案例与BUGSTONE工作流程的映射关系如下:
- 补丁预处理:在此步骤中,BUGSTONE接收到一个Git提交(例如提交a82268b30a8b),该提交包含了一个错误修复。首先,BUGSTONE从补丁信息中去除无关的元数据(如diff头信息、URL等),然后识别出包含错误修复的完整函数。在这个例子中,BUGSTONE提取了
nes_cm_alloc_core函数,该函数内包含了对create_singlethread_workqueue宏的错误使用。通过这种方式,BUGSTONE形成了一个“种子补丁”,它不仅包含修复的信息,还包括修复所在的代码上下文。 - 安全编码规则生成:在步骤2中,种子补丁被传递给大语言模型(LLM)提取器。LLM根据种子补丁中的错误使用模式提出一个安全编码规则。例如,LLM识别到
create_singlethread_workqueue宏可能会失败并返回NULL,因此生成的安全规则是:“create_singlethread_workqueue可能失败并返回NULL;在使用其返回值之前,必须检查它以防止NULL指针解引用。”这一安全规则为后续的代码检查提供了指导。 - 候选代码收集:在步骤3中,BUGSTONE的静态分析工具扫描整个代码库,查找所有使用
create_singlethread_workqueue宏的调用点。通过这种方式,BUGSTONE识别出197个代码段,这些代码段包含了可能出现类似错误的调用点。静态分析器的作用是收集这些调用点,并将它们标记为潜在的RPB候选项。 - LLM-based 违规检测:在步骤4中,BUGSTONE将这些候选代码段的上下文与之前提取的安全规则和种子补丁结合,生成一个LLM提示,指导大语言模型判断这些调用点是否违反了安全规则。通过这个过程,BUGSTONE能够自动判断哪些代码片段可能存在漏洞。例如,在此案例中,BUGSTONE标记了10个新的潜在违规案例,供后续审查。
- 后处理与报告:最后,在步骤5中,BUGSTONE汇总所有候选项的模型响应,并进行后处理验证。系统会将疑似违规项提交给人工开发者进行人工审查。人工审查能够确认哪些问题是真正的漏洞,并进行修复。在该示例中,人工审查识别出了4个真实的违规项,其中3个是与种子补丁修复的错误类似的漏洞。
具体实现
理想情况下,给定一个单一的错误,工具应能够在分析的代码库中揭示其他RPB。为了保持对重复模式的普遍性,我们避免仅依赖传统的静态或动态分析。动态方法,如模糊测试,通过随机执行来探索,主要揭示在特定的消毒器下出现的一小部分内存错误。它们不适合捕捉仅在特定调用顺序或状态条件下发生的错误,包括RPB。传统的静态分析方法面临不同的挑战。每种错误模式通常需要一个专门的分析器来建模其控制和数据流语义,然后进行迭代的约束调整。为每个修复的模式工程化一个新的检查器,在规模上是不可行的。
因此,我们旨在满足三个关键要求:(1)提供一种系统的方法来构建提示和上下文,在分析代码和检测各种类型的RPB时,充分利用大语言模型(LLM)的优势,同时最小化人工和工程工作量;(2)确保解决方案既具有成本效益又有效;(3)实现与最先进的错误发现工具相当的准确性。
基于LLM的语义分析器用于灵活的代码理解。上述考虑因素促使BUGSTONE的代码分析模块采用基于LLM的方法。鉴于补丁中自然语言和代码的跨领域语言多样性,LLM非常适合从给定的补丁中提取模式并进行模式匹配。LLM生态系统也是多样化且不断发展的,这为我们提供了根据用户需求更换模型的能力,并确保最先进的性能。然而,我们并不完全依赖LLM来进行漏洞检测的所有方面。BUGSTONE是一个以规则为中心、种子补丁驱动、LLM驱动的工作流,并通过轻量级静态枚举来高效发现相似的错误。与传统的程序分析研究集中于开发高度复杂的分析技术不同,本工作的主要贡献是基于LLM的分析框架和系统性研究,展示了如何利用LLM进行代码分析和漏洞发现。
补丁涉及自然语言信息和代码信息的混合。自然语言信息包含用户写的关于问题的详细描述,有时也包含修复内容,但也可能包括多余的信息,如电子邮件头、时间戳、发现方法、URLs等,这些信息可能会分散LLM的注意力并增加推理成本。BUGSTONE采用确定性预处理,仅提取用户提交的问题描述部分,以最小化推理成本并提高检测性能。代码信息也需要预处理。标准diff仅暴露编辑过的行,且上下文很少。LLM很难仅凭这么少的信息推断出编辑的原因或概括错误使用模式。尤其是当根本原因可能在几十行之外时,比如内存泄漏可能发生在分配后的后续错误路径中,这就更加困难,因为它可能超出了上下文的范围。BUGSTONE通过扩展代码上下文,涵盖整个函数,并在该函数的整体视角中展示编辑的行。这样丰富的代码上下文保留了可能对错误检测至关重要的控制流和数据依赖关系。清理补丁元数据并扩展代码上下文,创建了一个种子补丁,该补丁随后会被检测LLM处理。
主要挑战在于在现有代码库中找到RPB,尤其是对于大型项目来说。模型上下文的限制和高额的token成本使得将整个文件,更不用说整个代码库,提供给LLM并要求它一次性搜索代码块变得低效。这种方法还增加了误报和漏报的可能性,因为LLM具有非确定性和不可靠性,例如幻觉(hallucinations)。之前的安全修复研究表明,大多数补丁及其相关上下文仅跨越几十行,表明简短、集中的代码片段通常就足够了。因此,BUGSTONE使用轻量级静态分析器对代码库进行预处理,枚举所有可能与RPB相关的、匹配目标API或代码片段的调用点。与补丁类似,对于每个调用点,BUGSTONE提取整个调用者函数。我们注意到,使用函数作为代码上下文的另一个好处是提高了可扩展性。尽管过程内部分析足以检测许多RPB,但更复杂的错误可能需要过程间推理。通过建立函数级别的上下文,未来可以通过调用图扩展BUGSTONE,以支持过程间分析,这变得更加简便。
没有关于错误模式的显式信息,LLM无法可靠地检测安全错误,往往表现得比随机猜测还差。为了使LLM更具针对性并专注于识别特定的错误模式,我们评估了三种处理种子补丁并将其转化为RPB识别提示的方法。在基于补丁的方法中,我们提供种子补丁和目标代码片段给LLM,并询问它补丁中修复的错误是否也出现在目标代码片段中。在基于规则的方法中,我们增加了一个额外的处理步骤,将种子补丁转化为安全编码规则。然后,指示检测LLM评估目标代码片段是否违反了提取的规则。在混合方法中,我们同时提供种子补丁和提取的安全规则,并要求检测LLM评估目标代码片段是否违反了提取的规则。正如我们在§5.3中所展示的,基于规则的方法在经验上提供了最佳的折衷:与其他设计选择相比,它具有更高的准确性和更低的成本。
安全规则生成。用于RPB检测的安全编码规则必须准确捕捉到重复模式错误和错误的根本原因。我们探索了两种不同的获取RPB安全编码规则的方法:人工生成和种子补丁生成。在审查补丁时,维护者可以手动定义规则并提供给BUGSTONE,以便查找其他RPB实例。这种方法对于新颖的RPB非常有用,但人工生成的规则在表达性和细节上可能有所不同。例如,一位专家可能写“使用framebuffer_release释放通过framebuffer_alloc分配的缓冲区”,而另一位专家可能写“在错误路径中使用edac_mc_free释放通过edac_mc_alloc分配的缓冲区”。这两者都是针对如何修复特定内存泄漏问题的规则,但可能无意中增加或删除了对检测模式的约束。我们的种子补丁基础规则利用LLM自动从种子补丁生成规则。由于规则生成是自动化的,我们需要平衡规则的粒度。过于抽象的规则可能无法约束错误模式并导致过多的报告;过于详细的规则可能会对数据流或实现细节进行过拟合,从而无法很好地泛化。基于我们对1900多个安全错误补丁的研究,我们将高质量规则定义为:该规则指定了根本原因(错误的API或代码片段,其误用导致错误)、防止错误发生所需的处理操作、如果错误被触发时的预期影响,以及适用范围的限制条件,如仅限于错误处理路径或特定类别的函数。我们部署了一套标准化、简洁的规则模板和提示程序,生成的输出既足够详细以指导检测,又足够简洁以便泛化并帮助维护者。
BUGSTONE创造性的提出了基于漏洞模式的RPBs漏洞检测,需要注意RBPs漏洞与同源漏洞之间存在包含关系,即同源漏洞必定术语RBP漏洞,因此借助其核心思想可以协助同源漏洞的确认工作。
参考BUGSTONE的核心思想,一种潜在的BCSD优化方法是,在 LibAM+LibvDiff 检测结果的基础上确定候选二进制文件(Candidate Binary)及其对应的版本,并获取候选二进制文件对应的补丁信息,以实现 BCSD 方法与 BUGSTONE 模块一与模块二的对接;对目标二进制文件(Target Binary)进行反编译(可以考虑用大模型进行优化),以实现 BCSD 方法与 BUGSTONE 第三个模块的对接。