【论文精读】AIGCBench:AI 图像生成视频(I2V)的全面评估基准
标题:AIGCBench: Comprehensive Evaluation of Image-to-Video Content Generated by AI
作者:Fanda Fan, Chunjie Luo, Wanling Gao, Jianfeng Zhan
单位:a. Research Center for Advanced Computer Systems, State Key Lab of Processors, Institute of Computing Technology, Chinese Academy of Sciences, China;b. University of Chinese Academy of Sciences, China
发表:arXiv:2401.01651v3 [cs.CV] 23 Jan 2024
论文链接:https://arxiv.org/pdf/2401.01651
项目链接:https://www.benchcouncil.org/AIGCBench
代码链接:https://github.com/BenchCouncil/AIGCBench
关键词:图生视频评测基准(Image-to-Video Evaluation Benchmark)、视频生成(Video Generation)、图像到视频(Image-to-Video(I2V))、多模态人工智能(Multimodal AI)
在 AI 生成内容(AIGC)领域,视频生成技术正以惊人速度演进,其中图像生成视频(I2V)因能精准控制生成内容,在影视、电商广告、微动画等场景极具潜力。然而,现有 I2V 评估基准存在数据集单一、评估指标不统一等问题,严重阻碍了算法的公平对比与技术进步。为此,来自中国科学院计算技术研究所与中国科学院大学的团队提出了AIGCBench—— 一个全面、可扩展的视频生成评估基准,尤其聚焦 I2V 任务。
一、研究背景:为何需要 AIGCBench?
在深入 AIGCBench 设计之前,我们需先明确当前 I2V 领域的 “痛点”—— 现有评估体系的局限性,这也是 AIGCBench 诞生的核心动因。
1.1 AIGC 视频生成的发展现状
AIGC 视频生成主要包含三大主流任务:
- 文本生成视频(T2V):仅通过文本提示生成视频,但难以精准描述用户所需的具体场景;
- 图像生成视频(I2V):基于静态输入图像(通常搭配文本提示)生成动态视频,能更好地定义视频内容,是当前研究热点;
- 视频生成视频(V2V):基于已有视频生成新视频,或结合深度、姿态、轨迹等额外信息优化生成效果。
其中,T2V 的评估基准(如 FETV、EvalCrafter、VBench)已较为成熟,但 I2V 的评估却长期滞后 —— 这正是 AIGCBench 要解决的核心问题。
1.2 现有 I2V 基准的两大核心缺陷
论文通过调研指出,现有 I2V 评估基准存在两个致命问题,导致无法公平、全面地评估算法性能:
-
数据集缺乏多样性与开放性:多数基准(如 LFDM Eval、CATER-GEN)仅针对特定领域(如面部表情、3D 物体运动)设计,无法覆盖用户实际使用的 “开放域场景”(如 “蓝色巨龙在时代广场玩滑板”);即使是开放域基准(如 VideoCrafter、I2VGen-XL),也仅依赖真实世界的图像 - 文本对,缺乏人工生成的多样化样本。
-
评估指标缺乏统一共识:部分基准(如 Seer、SVD)仅使用依赖参考视频的指标,部分(如 AnimateBench)仅用无参考视频的指标;且多数基准仅覆盖 “视觉对比”,未系统评估 “控制 - 视频对齐”“时间一致性” 等关键维度,无法全面反映算法优劣。
1.3 AIGCBench 的核心目标
针对上述问题,AIGCBench 提出三大核心目标:
- 提供开放域、多样化的评估数据集:融合真实世界数据与人工生成数据,覆盖不同主题、行为、背景与艺术风格;
- 建立多维度、统一的评估指标体系:涵盖控制 - 视频对齐、运动效果、时间一致性、视频质量四大维度,同时支持 “有参考视频” 与 “无参考视频” 评估;
- 实现算法的公平对比:在同等条件下评估主流 I2V 算法,明确各算法的优势与短板,为领域发展提供方向。
二、AIGCBench 的整体框架
AIGCBench 的框架由三大核心模块构成:评估数据集、待评估的视频生成模型、多维度评估指标。其整体结构如图 1 所示,各模块间相互配合,实现对 I2V 算法的全面评估。

注:图中展示了 AIGCBench 的三大模块:评估数据集(视频 - 文本对、图像 - 文本对)、待评估模型(如 Pika、SVD 等)、评估指标(四大维度共 11 项指标),同时通过人工验证确保评估标准的合理性。
三、核心模块 1:评估数据集的构建
AIGCBench 的数据集设计是其解决 “数据多样性” 问题的关键,采用 “真实世界数据 + 人工生成数据” 的混合策略,共包含3928 个样本(远超现有基准),具体分为两类:
3.1 真实世界数据集
团队从公开的大规模数据集中采样,确保数据的真实性与代表性:
-
视频 - 文本对(Video-Text Pairs)来源:WebVid-10M 数据集(包含约 1000 万条视频 - 文本对,用于视频理解任务);采样策略:从验证集中按子类型采样 1000 条视频 - 文本对,用于 “有参考视频” 的评估;作用:提供真实场景下的视频参考,用于计算 “生成视频与参考视频的相似度” 等指标。
-
图像 - 文本对(Image-Text Pairs)来源:LAION-5B 数据集的子集 LAION-Aesthetics(包含约 585 亿条图像 - 文本对,筛选出视觉质量较高的样本);采样策略:随机采样 925 条图像 - 文本对,用于 “无参考视频” 的评估;作用:模拟用户输入的静态图像场景,评估生成视频与输入图像、文本的对齐程度。
3.2 人工生成的图像 - 文本对
为解决 “真实数据无法覆盖特殊场景” 的问题,团队设计了一套T2I(文本生成图像)生成流水线,生成 2003 条高质量图像 - 文本对,具体流程如下:
步骤 1:文本组合器(Text Combiner)生成基础提示
团队基于 “主题(Subject)、行为(Behavior)、背景(Background)、图像风格(Image Style)” 四大元类型,构建文本模板:{主题} {行为} {背景}, in the {图像风格} style
并从 Civit AI(T2I 社区)收集高频词汇,生成 3000 条基础文本提示,示例如下:
- 主题:龙(a dragon)、骑士(a knight)、外星人(an alien);
- 行为:骑自行车(riding a bike)、寻宝(searching for a treasure)、跳舞(dancing);
- 背景:森林中(in a forest)、未来城市(in a futuristic city)、太空站(in a space station);
- 风格:油画(oil painting)、水彩(water color)、梵高风格(Van Gogh)。
步骤 2:GPT-4 优化文本提示
基础提示可能存在 “描述单薄” 的问题,团队使用 GPT-4 对其进行优化,指令为 “make the content more vivid and rich”(让内容更生动丰富)。例如:
- 优化前:“a dragon dancing in a forest, in oil painting style”;
- 优化后:“A vibrant dragon performs a lively dance in a dense forest, capturing a bouncy rhythm in the oil painting style”。
步骤 3:Stable Diffusion 生成图像并筛选
使用当前主流的 T2I 模型 ——Stable Diffusion XL(xl-base 版本),按 16:9 比例(720×1280 分辨率,匹配 I2V 模型训练比例)生成图像;再通过 T2I-CompBench 的自动指标筛选出 2003 条高质量图像 - 文本对,确保样本质量。
生成流水线的效果如图 2 所示,可见其覆盖了 “外星人跳舞”“熊猫解谜”“机器人调制药剂” 等多样化场景,有效补充了真实数据的不足。

注:上侧为生成流水线(文本组合器→GPT-4 优化→Stable Diffusion 生成),下侧为 8 个生成示例,每个示例下方标注了文本组合器生成的原始文本。
3.3 数据集对比:AIGCBench vs 现有基准
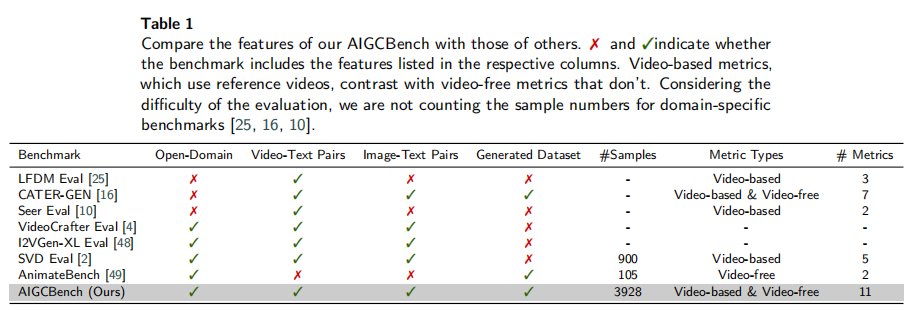
为凸显 AIGCBench 数据集的优势,论文将其与现有 I2V 基准进行对比,结果如表 1 所示。可以看出:
- AIGCBench 是唯一同时满足 “开放域”“包含视频 - 文本对 / 图像 - 文本对”“人工生成数据集”“大样本量(3928)” 的基准;
- 现有基准要么局限于特定领域(如 LFDM Eval、CATER-GEN),要么缺乏人工生成数据(如 VideoCrafter、I2VGen-XL),要么样本量过小(如 AnimateBench 仅 105 个样本)。
四、核心模块 2:多维度评估指标体系
AIGCBench 的另一大创新是建立了四大维度、11 项指标的评估体系,同时支持 “有参考视频”(基于视频 - 文本对)和 “无参考视频”(基于图像 - 文本对)评估,确保全面性与灵活性。
4.1 指标设计原则
团队在设计指标时遵循两大原则:
- 覆盖核心需求:指标需对应用户对 I2V 的核心诉求 —— 生成视频需与输入控制(图像 + 文本)对齐、运动合理、帧间连贯、质量高;
- 兼顾两种场景:同时支持 “有参考视频”(如真实世界视频 - 文本对)和 “无参考视频”(如用户上传的图像),避免依赖单一数据类型。
4.2 四大维度与 11 项指标详解
维度 1:控制 - 视频对齐(Control-Video Alignment)
评估生成视频与 “输入控制信号”(图像 + 文本)的匹配程度,共 5 项指标:
- MSE (First):生成视频第一帧与输入图像的均方误差(越低越好)—— 衡量初始帧对输入图像的保真度;
- SSIM (First):生成视频第一帧与输入图像的结构相似性(越高越好)—— 从结构层面衡量图像保真度;
- Image-GenVideo CLIP:输入图像与生成视频所有帧的 CLIP 嵌入相似度均值(越高越好)—— 衡量全视频对输入图像的语义对齐;
- GenVideo-Text CLIP:输入文本与生成视频的 CLIP 嵌入相似度(越高越好)—— 衡量视频与文本的语义对齐(无参考视频场景);
- GenVideo-RefVideo CLIP (Keyframes):生成视频与参考视频的 4 个均匀采样关键帧的 CLIP 相似度均值(越高越好)—— 衡量视频与参考视频的语义对齐(有参考视频场景)。
维度 2:运动效果(Motion Effects)
评估生成视频中运动的 “强度” 与 “合理性”,共 2 项指标:
- Flow-Square-Mean:使用 RAFT 光流算法计算相邻帧的光流平方均值(越高表示运动越强,但需小于 10 以过滤异常值)—— 衡量运动强度;
- GenVideo-RefVideo CLIP (Corresponding frames):生成视频与参考视频对应帧的 CLIP 相似度均值(越高越好)—— 衡量运动的合理性(有参考视频场景)。
维度 3:时间一致性(Temporal Consistency)
评估生成视频帧间的连贯性,共 2 项指标(复用 1 项运动维度的指标,避免冗余):
- GenVideo CLIP (Adjacent frames):生成视频相邻帧的 CLIP 相似度均值(越高越好)—— 衡量帧间语义连贯性(无参考视频场景);
- GenVideo-RefVideo CLIP (Corresponding frames):复用运动维度的指标 —— 衡量生成视频与参考视频的帧间对应性(有参考视频场景)。
维度 4:视频质量(Video Quality)
评估生成视频的 “长度” 与 “整体质量”,共 2 项指标:
- Frame Count:生成视频的帧数(越高越好)—— 衡量算法生成长视频的能力;
- DOVER:无参考视频质量评估指标(越高越好)—— 从美学和技术层面综合评分(无参考视频场景);
- GenVideo-RefVideo SSIM:生成视频与参考视频对应帧的 SSIM 均值(越高越好)—— 衡量视频的空间结构质量(有参考视频场景)。
4.3 指标有效性验证
为确保指标与人类主观判断一致,团队通过 “用户研究” 验证:随机选取 5 个算法的各 30 个生成结果,由 42 名用户对 “图像保真度”“运动效果”“时间一致性”“视频质量” 四大维度投票,结果显示指标评分与用户投票高度吻合(后续实验会详细展示),证明指标体系的合理性。
五、实验设计与结果分析
论文选取了当前 I2V 领域的 5 个主流算法进行评估,涵盖 “开源项目” 与 “闭源项目”,确保结果具有代表性。
5.1 待评估模型与参数设置
开源模型(3 个)
- VideoCrafter [4]:开源视频生成工具包,支持 I2V;参数:引导尺度(guidance scale)=12,DDIM 步数 = 25,分辨率按比例调整为统一尺寸;
- I2VGen-XL [48]:阿里通义实验室开源的 I2V 模型;参数:引导尺度 = 9,FP16 精度推理;
- Stable Video Diffusion (SVD) [2]:基于 Stable Diffusion 扩展的 I2V 模型;参数:25 帧版本,暂不支持文本输入(故不计算文本相关指标)。
闭源模型(2 个)
- Pika [28]:工业界代表性模型,支持多风格视频生成;参数:默认运动强度 = 1,引导尺度 = 12,手动测试 60 个案例(30 个来自 WebVid,30 个来自人工生成数据集);
- Gen2 [7]:多模态视频生成系统;参数:默认运动强度 = 5,不启用相机运动参数。
5.2 定量结果分析
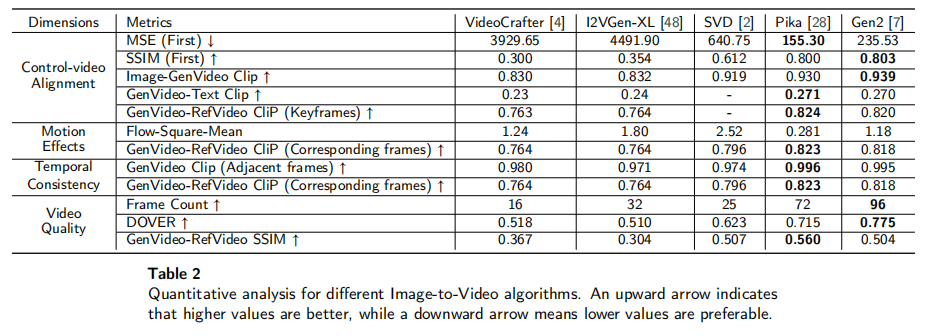
论文对 5 个模型在 11 项指标上的表现进行量化评估,结果如表 2 所示(↑表示指标越高越好,↓表示越低越好)。通过分析可得出以下关键结论:
结论 1:闭源模型在 “控制 - 视频对齐” 上全面领先
- 图像保真度(MSE/SSIM/Image-GenVideo CLIP):Pika(MSE=155.30,SSIM=0.800)和 Gen2(MSE=235.53,SSIM=0.803)表现最佳,远优于开源模型(如 VideoCrafter 的 MSE=3929.65,SSIM=0.300);
- 文本对齐(GenVideo-Text CLIP):Pika(0.271)和 Gen2(0.270)略优于开源模型,但整体得分偏低,说明现有算法在 “文本细粒度控制” 上仍有不足。
结论 2:运动效果的 “强度” 与 “合理性” 需平衡
- 运动强度(Flow-Square-Mean):SVD(2.52)最高(倾向于相机运动),Pika(0.281)最低(倾向于局部物体运动);
- 运动合理性(GenVideo-RefVideo CLIP):Pika(0.823)和 Gen2(0.818)最佳,说明其运动更符合真实场景;而 SVD 虽运动强度高,但合理性略低(0.796),因相机运动可能偏离参考视频。
结论 3:闭源模型在 “时间一致性” 和 “视频质量” 上优势显著
- 时间一致性(GenVideo CLIP):Pika(0.996)和 Gen2(0.995)几乎无帧间断裂,远优于开源模型(如 I2VGen-XL=0.971);
- 视频长度(Frame Count):Gen2(96 帧,约 4 秒)最长,Pika(72 帧,约 3 秒)次之,开源模型最短(VideoCrafter 仅 16 帧);
- 整体质量(DOVER):Gen2(0.775)最高,Pika(0.715)次之,开源模型中 SVD(0.623)最佳。
5.3 定性结果分析
为更直观展示算法差异,论文选取 3 个典型场景(骑士在雪山马拉松、机器人在中世纪小镇解谜、美人鱼在古战场跳舞),对比了 5 个算法的生成效果,结果如图 3 所示。

注:从左到右依次为 VideoCrafter、I2VGen-XL、SVD、Pika、Gen2 的生成结果,每个场景对应一行。
定性结果进一步验证了定量结论:
- 开源模型:VideoCrafter 和 I2VGen-XL 难以保留输入图像的空间结构(如 “骑士雪山” 场景中,输入图像的 “雪山背景” 被严重篡改);SVD 虽能保留结构,但运动以相机平移为主,缺乏物体自身运动;
- 闭源模型:Pika 和 Gen2 不仅能精准保留输入图像的细节(如 “美人鱼古战场” 场景中,美人鱼的姿态、古战场的背景均与输入一致),且运动更自然(如骑士的跑步、机器人的解谜动作)。
5.4 用户研究结果
为验证指标与人类判断的一致性,论文统计 42 名用户对 5 个算法在四大维度的 “最佳投票比例”,结果如图 4 所示(雷达图)。
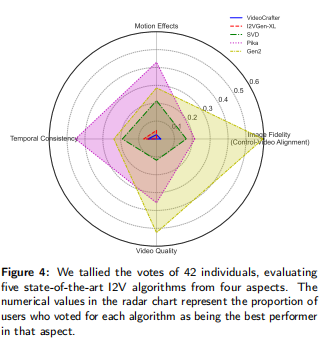
注:数值表示用户投票该算法为 “某维度最佳” 的比例,维度包括图像保真度、运动效果、时间一致性、视频质量。
用户研究结果与定量指标高度吻合:
- Gen2 在 “图像保真度” 和 “视频质量” 上得票最高;
- Pika 在 “运动效果” 和 “时间一致性” 上得票最高;
- SVD 在开源模型中表现均衡,得票仅次于闭源模型;
- VideoCrafter 和 I2VGen-XL 在所有维度得票最低。
这进一步证明 AIGCBench 的指标体系能够准确反映人类主观感受,具备有效性。
六、核心发现与领域挑战
通过 AIGCBench 的全面评估,团队总结出当前 I2V 领域的三大核心挑战,为后续研究指明方向:
6.1 缺乏细粒度控制能力
现有算法虽能匹配文本的 “粗语义”(如 “骑士跑步”),但无法捕捉 “细粒度描述”(如 “骑士穿着红色盔甲、在雪山上以每秒 5 米的速度跑步”)。原因在于:
- 现有文本对齐依赖 CLIP 嵌入,仅能捕捉全局语义,无法区分细粒度差异;
- 缺乏针对 “视频场景” 的细粒度文本 - 视频对齐模型。
建议:未来需设计专门用于视频的细粒度语义匹配模型,将文本拆解为 “物体属性、运动参数、环境细节” 等子模块,逐一对齐生成视频。
6.2 长视频生成能力不足
当前主流算法的最大生成长度仅为 96 帧(Gen2,按 24fps 计算约 4 秒),远无法满足影视、广告等场景对 “分钟级视频” 的需求。现有解决方案存在缺陷:
- 多步推理(粗→细):先生成关键帧,再补全中间帧,但难以保证帧间一致性;
- 多 GPU 单模型推理:虽能提升长度,但生成质量下降明显。
建议:需探索 “时间维度的稀疏建模”(如仅建模关键帧的时间依赖)或 “分层生成策略”(如先生成视频结构,再填充细节),在长度与质量间找到平衡。
6.3 推理速度过慢
现有算法生成 3 秒视频(约 72 帧)需在 V100 显卡上运行 1 分钟,无法满足实时应用需求。当前加速思路有两种:
- ** latent 空间降维 **:如 SVD 将视频映射到低维 latent 空间(尺寸缩小 8 倍),但会损失部分细节;
- 扩散模型加速:如采用 “蒸馏”“剪枝” 等技术,但可能导致生成质量下降。
建议:未来需结合 “latent 空间优化” 与 “扩散模型加速”,在速度与质量间 trade-off,例如设计更高效的 latent 表示,或采用 “非扩散模型”(如 Transformer)实现快速生成。
七、AIGCBench 的局限性与未来规划
7.1 现有局限性
- 样本量不足:因 I2V 模型推理慢、部分模型闭源,当前仅评估 3950 个案例,未来需扩大样本量;
- 细粒度评估缺失:无法自动判断 “物体运动方向与文本是否一致”(如 “水流从左到右” 是否与生成视频匹配),需依赖人工;
- 任务覆盖不全面:当前仅聚焦 I2V,未包含 T2V、V2V 等其他视频生成任务。
7.2 未来规划
- 扩展任务范围:将 T2V、V2V、深度 / 姿态引导的视频生成等任务纳入 AIGCBench,建立统一的视频生成评估框架;
- 提升细粒度评估能力:训练 “文本 - 视频细粒度对齐模型”,实现对 “运动方向、物体属性” 等细节的自动评估;
- 开源更多资源:扩大数据集规模,开放更多评估工具(如细粒度评估代码),推动领域标准化。
八、总结
AIGCBench 作为当前 I2V 领域最全面的评估基准,通过 “多样化数据集”“多维度指标体系”“公平的算法对比”,填补了现有评估体系的空白。其核心贡献可概括为三点:
- 数据集创新:融合真实世界与人工生成数据,覆盖开放域场景,样本量达 3928 个,远超现有基准;
- 指标体系创新:四大维度 11 项指标,同时支持有 / 无参考视频评估,且与人类判断高度一致;
- 领域洞察:通过评估明确现有算法的短板,指出 “细粒度控制、长视频生成、推理速度” 三大核心挑战,为后续研究提供方向。
AIGCBench 的开源(数据集与代码已发布于https://www.benchcouncil.org/AIGCBench)将推动 I2V 领域的标准化发展,助力更多高效、高质量的 I2V 算法诞生。对于研究者而言,AIGCBench 不仅是评估工具,更是洞察领域趋势的 “指南针”;对于工业界而言,AIGCBench 可作为算法选型的 “客观标准”,加速 I2V 技术的落地应用。