Leetcode 32
1 题目
160. 相交链表 - 力扣(LeetCode)
Leetcode 14 java-CSDN博客
Leetcode 26-CSDN博客
写了好几遍了,思路很简单,速度一样,路程一样,总是会遇到的,多做几次确实发现算法没那么可怕的。
2 代码实现(c)
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/typedef struct ListNode ListNode;
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {ListNode *p1 = headA ;ListNode *p2 = headB ;while(p1 != p2 ){if (p1 != NULL){p1 = p1 -> next ;}else{p1 = headB;}if (p2 != NULL){p2 = p2 -> next ;}else{p2 = headA;}} return p1 ;
}有点小错误:
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/typedef struct ListNode ListNode;
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {ListNode *p1 = headA ;ListNode *p2 = headB ;while(p1 != p2 ){if (p1 != NULL){p1 = p1 -> next ;}else{p1 = headB;}if (p2 != NULL){p2 = p2 -> next ;}else{p2 = headA;}return NULL; } return p1 ;
}//是最后的输出不对吗,代码逻辑有问题吗你的代码逻辑思路是对的(利用 “交叉遍历” 消除长度差),但存在一个语法错误导致输出不正确 ——return NULL; 的位置放错了。
问题分析
在 while(p1 != p2) 循环内部,你在每次更新 p1 和 p2 后,直接用 return NULL; 结束了函数。这会导致:
- 循环只执行第一次迭代就返回
NULL,无法完成后续的交叉遍历,自然找不到交点。 - 即使两个链表有交点,也会被提前返回的
NULL覆盖。
正确逻辑
交叉遍历的核心是:让 p1 遍历完 A 后转去遍历 B,p2 遍历完 B 后转去遍历 A。当两者相遇时,要么是交点(有交点时),要么是 NULL(无交点时)。关键:循环需要持续执行,直到 p1 == p2 才退出循环并返回结果。
修正后的代码
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {ListNode *p1 = headA;ListNode *p2 = headB;while (p1 != p2) {// p1 遍历完 A 则转去遍历 B,否则继续往后走p1 = (p1 != NULL) ? p1->next : headB;// p2 遍历完 B 则转去遍历 A,否则继续往后走p2 = (p2 != NULL) ? p2->next : headA;}// 退出循环时,p1 == p2,要么是交点,要么是 NULL(无交点)return p1;
}
总结
错误原因是 return NULL; 放在了循环内部,导致循环无法完整执行。修正后,循环会一直运行到 p1 和 p2 相遇,此时返回的 p1(或 p2)就是正确结果(交点或 NULL)。
3 题目
19. 删除链表的倒数第 N 个结点 - 力扣(LeetCode)
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
示例 1:
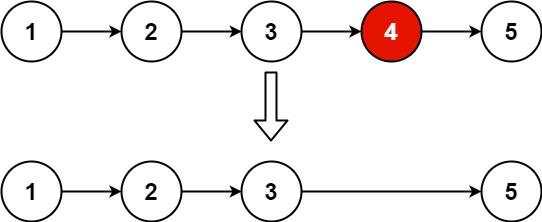
输入:head = [1,2,3,4,5], n = 2 输出:[1,2,3,5]
示例 2:
输入:head = [1], n = 1 输出:[]
示例 3:
输入:head = [1,2], n = 1 输出:[1]
提示:
- 链表中结点的数目为
sz 1 <= sz <= 300 <= Node.val <= 1001 <= n <= sz
进阶:你能尝试使用一趟扫描实现吗?
4 代码实现(c)
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/
typedef struct ListNode ListNode;
struct ListNode* removeNthFromEnd(struct ListNode* head, int n) {ListNode *p = (ListNode*)malloc(sizeof(ListNode));p -> next = head;ListNode *fast = p;ListNode *slow = p;for(int i = 0 ; i < n ; i++){fast = fast -> next;if (fast == NULL){return head ;}}while(fast -> next != NULL){fast = fast -> next ;slow = slow -> next ;}ListNode *q = slow -> next;slow -> next = slow -> next -> next ;free(q);ListNode *result = p -> next;return result;
}
过程遇到了困难,没有处理好删除节点是头节点的情况。
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/
typedef struct ListNode ListNode;
struct ListNode* removeNthFromEnd(struct ListNode* head, int n) {ListNode *result = head;ListNode *fast = head;ListNode *slow = head;for(int i = 0 ; i < n ; i++){fast = fast -> next;if (fast == NULL){return result;}}while(fast -> next != NULL){fast = fast -> next ;slow = slow -> next ;}ListNode *p = slow -> next;slow -> next = slow -> next -> next ;free(p);return result;
}1. 为什么删除头节点会失败?
当要删除的节点是头节点时(例如:链表只有 1 个节点,且 n=1;或链表长度为 n,删除倒数第 n 个即头节点),你的代码逻辑会失效:
- 原代码中,
fast先向前移动 n 步。如果链表长度正好为 n,fast会移动到NULL(因为第 n 步移动后,fast指向头节点的第 n 个 next,即超出链表尾部)。 - 此时你的代码直接
return result(原头节点),但实际需要删除头节点,应返回head->next。
2. 其他问题
- 未处理链表长度不足 n 的情况:题目约束中 n 是有效的(1≤n≤链表长度),但代码中若 n 大于链表长度,
fast移动时会访问NULL->next,导致空指针异常。 - 释放节点后未处理唯一节点的情况:当链表只有 1 个节点且 n=1 时,删除后应返回
NULL,但原代码会尝试访问slow->next(此时slow是头节点,next为NULL),导致slow->next->next空指针异常。
改进方案:引入哑节点(Dummy Node)
解决头节点删除问题的经典方法是添加一个「哑节点」,它指向头节点,统一所有节点的删除逻辑(包括头节点)。
改进代码如下:
struct ListNode* removeNthFromEnd(struct ListNode* head, int n) {// 创建哑节点,指向头节点,避免删除头节点时的特殊处理ListNode* dummy = (ListNode*)malloc(sizeof(ListNode));dummy->next = head;ListNode* fast = dummy;ListNode* slow = dummy;// 快指针先移动n步(从哑节点开始,确保移动n步后,快慢指针间距为n+1)for (int i = 0; i < n; i++) {fast = fast->next;// 若n超过链表长度(题目约束n有效,可省略此判断,但加上更健壮)if (fast == NULL) {free(dummy);return head;}}// 快慢指针同时移动,直到快指针到达尾节点while (fast->next != NULL) {fast = fast->next;slow = slow->next;}// 此时slow指向待删除节点的前一个节点(可能是哑节点)ListNode* toDelete = slow->next;slow->next = slow->next->next; // 跳过待删除节点free(toDelete); // 释放内存ListNode* result = dummy->next; // 结果为哑节点的next(可能已更换头节点)free(dummy); // 释放哑节点return result;
}
改进点说明:
-
哑节点的作用:哑节点
dummy指向头节点,使得「删除头节点」和「删除其他节点」的逻辑一致 —— 都是通过「待删除节点的前一个节点」来修改指针。例如:- 若删除头节点,
slow会指向dummy,slow->next = slow->next->next等价于dummy->next = head->next,即新头节点为原头节点的 next。
- 若删除头节点,
-
快慢指针的起始位置:均从
dummy开始,快指针先移动 n 步,确保当快指针到达尾节点时,慢指针恰好指向「待删除节点的前一个节点」,无需额外判断边界。 -
内存管理:手动释放了待删除节点和哑节点的内存,避免内存泄漏(实际刷题中可省略,但工程中需注意)。
测试用例验证:
- 链表
[1,2,3,4,5],n=2 → 删除 4,结果[1,2,3,5](正确)。 - 链表
[1],n=1 → 删除 1,结果[](正确)。 - 链表
[1,2],n=2 → 删除 1,结果[2](正确)。