transformer多头注意力机制代码详解
今天咱们来用通俗+原理结合的方式,把 Transformer 的“多头注意力机制(Multi-Head Attention)”讲明白。
多头注意力机制就是:
“让模型在同一句话里同时从多个角度看问题。”
它像一个团队的“八个小脑袋”,每个脑袋专注不同的语义关系,然后再把结果合在一起,得到更全面的理解。
一. 背景:为什么要注意力(Attention)
假设你有一句话:
“我请李雷帮我订了去北京的机票。”
如果模型要理解“机票”跟谁有关?
可能要关注到“订”、“李雷”、“我”这些词。
传统的 RNN/LSTM 是一串一串读,容易“忘记”前面的信息。
Transformer 用 Attention 机制,让模型可以直接看整句话,
根据相关性动态决定“我该重点看哪里”。
基础版:单头注意力(Self-Attention)
我们对每个词都做三次投影,得到三个向量:
-
Query(查询):当前词在问——“我该注意谁?”
-
Key(键):每个词在说——“我有什么信息?”
-
Value(值):每个词真正的“内容”。
比如对词 机票:
-
它的 Query 去“问”所有词的 Key。
-
用“相似度”算一个权重(点积 + softmax)。
-
再用这些权重加权平均各个 Value,得到“机票的新表示”。

这让模型自动学会:
-
“机票”该多关注“订”;
-
“北京”该多关注“去”;
-
“李雷”该多关注“我请”。
二.多头的意义:多个视角一起看
单头 Attention 像一个人一次只能注意一种关系,比如“动作→宾语”。
但句子里的关系多种多样:
-
主谓关系(我→请)
-
动作与对象(订→机票)
-
地点关系(去→北京)
于是我们用 多个头(head):
每个头各自有独立的 Q, K, V 投影矩阵,
所以每个头会关注不同类型的关系。
就是说每个不同的头关注的侧重点不一样,最后得到的关注度权重也不一样,最后把这多个关注维度的头获得的权重结果相加,把这些头的结果拼起来,再线性融合成一个向量:就实现了多个视角一起看。
| Head | 关注关系示例 |
|---|---|
| 头1 | 动作 ↔ 宾语 |
| 头2 | 主语 ↔ 谓语 |
| 头3 | 地点 ↔ 动作 |
| 头4 | 时间 ↔ 动作 |
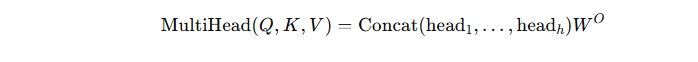
输入句子 → 线性层 → Q,K,V
↓
多个头并行计算注意力
↓
拼接(Concat)
↓
线性层融合 → 输出
三.多头注意力推演
句子:我请李雷帮我订了去北京的机票
第 1 步:分词(Tokenization)
Transformer 看到的不是字,而是 token。
咱们假设用中文 BPE 或 SentencePiece 分词,简单起见我们手动分成词:总共 10 个 token。
[我] [请] [李雷] [帮] [我] [订了] [去] [北京] [的] [机票]
第 2 步:嵌入(Embedding):每个 token 被映射成一个向量,比如维度是 4(实际常为 512或768)。这里推演 先忽略位置编码。
| Token | 向量(简化示例) |
|---|---|
| 我 | [0.2, 0.1, 0.4, 0.5] |
| 请 | [0.6, 0.3, 0.2, 0.1] |
| 李雷 | [0.9, 0.7, 0.4, 0.2] |
| 帮 | [0.3, 0.8, 0.6, 0.3] |
| 我 | [0.2, 0.1, 0.4, 0.5] |
| 订了 | [0.8, 0.4, 0.3, 0.2] |
| 去 | [0.5, 0.6, 0.4, 0.1] |
| 北京 | [0.9, 0.8, 0.5, 0.3] |
| 的 | [0.1, 0.2, 0.1, 0.2] |
| 机票 | [0.8, 0.9, 0.6, 0.4] |
第 3 步:计算 Q, K, V(三个投影)
对于每个 token 的向量,我们各自乘三个不同的矩阵:
Q=XWQ,K=XWK,V=XWVQ = XW_Q, \quad K = XW_K, \quad V = XW_VQ=XWQ,K=XWK,V=XWV
这些矩阵是模型参数(训练学得),作用就是:
-
Q:表示“我在问什么”
-
K:表示“我能提供什么”
-
V:表示“我的内容是什么”
举例(简化理解):
| Token | Q(问) | K(答) | V(内容) |
|---|---|---|---|
| 我 | 想知道谁是动作执行者 | 我是主语 | “我” |
| 请 | 想知道谁被请、请什么事 | 动词-动作 | “请” |
| 李雷 | 想知道谁干了什么 | 是人名 | “李雷” |
| 帮 | 想知道谁帮谁 | 动作辅助关系 | “帮” |
| 订了 | 想知道订的是什么 | 动作-宾语关系 | “订了” |
| 去 | 想知道目的地 | 动作-方向关系 | “去” |
| 北京 | 想知道“去”去哪 | 地点 | “北京” |
| 机票 | 想知道和什么动作关联 | 名词对象 | “机票” |
第 4 步:计算注意力权重(以“机票”为例)
我们现在取 机票 的 Query,去跟所有 token 的 Key 计算相似度(点积)。
假设结果如下(归一化前):
| 对象 | Q·K 相似度 | softmax 后权重 |
|---|---|---|
| 我 | 1.1 | 0.05 |
| 请 | 1.4 | 0.08 |
| 李雷 | 1.6 | 0.10 |
| 帮 | 1.9 | 0.15 |
| 我 | 1.1 | 0.05 |
| 订了 | 2.8 | 0.25 |
| 去 | 1.5 | 0.10 |
| 北京 | 2.2 | 0.18 |
| 的 | 0.5 | 0.02 |
| 机票 | 2.0 | 0.12 |
然后 softmax 一归一化,得到权重分布:
👉 机票 主要关注:
-
“订了” (0.25)
-
“北京” (0.18)
-
“帮” (0.15)
也就是模型学到了语义关系:
“机票”是“订”的,“订”的是“去北京”的。
再根据这些权重对对应的 Value 向量加权平均:
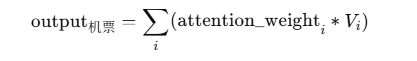
得到“机票”的新表示:融合了“订”、“北京”、“帮”的信息。
第 5 步:并行计算所有 token
上面我们只是举了一个 token(机票)。
在实际中,模型会同时对所有 token 做这种 QK^T 点积运算,形成一个 10×10 的注意力矩阵。
这个矩阵的每个元素代表:
token i 对 token j 的注意力程度。
比如(简化示意):
| Token | 我 | 请 | 李雷 | 帮 | 我 | 订了 | 去 | 北京 | 的 | 机票 |
|---|---|---|---|---|---|---|---|---|---|---|
| 我 | - | 0.1 | 0.2 | 0.1 | - | 0.3 | 0.05 | 0.05 | 0 | 0.1 |
| 请 | 0.2 | - | 0.4 | 0.1 | 0.1 | 0.1 | 0 | 0 | 0 | 0.1 |
| 李雷 | 0.05 | 0.2 | - | 0.4 | 0.1 | 0.1 | 0 | 0 | 0 | 0.05 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
这就是自注意力(Self-Attention)矩阵。
第 6 步:多头(Multi-Head)注意力
假设我们有 4 个头(实际一般是 8 或 12):
| 头编号 | 专注内容 | 举例 |
|---|---|---|
| Head 1 | 主谓关系 | “我” ↔ “请” |
| Head 2 | 动作与宾语 | “订了” ↔ “机票” |
| Head 3 | 动作与地点 | “去” ↔ “北京” |
| Head 4 | 代词指代 | “我(第1个)” ↔ “我(第5个)” |
每个头各自计算一套 Q,K,V(不同参数),
得到不同的注意力矩阵。
于是:
-
Head 2 会在 “订了→机票” 的位置上有最高注意力;
-
Head 3 会在 “去→北京” 上最强;
-
Head 4 会让模型知道 “我” 出现两次其实是同一个人。
最后所有 head 的输出拼接起来,再过一个线性层:
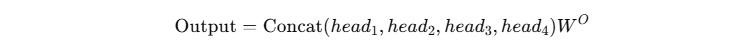
这样一融合,模型就理解了整句话的结构和语义关系。
第 7 步:多层堆叠(Transformer Block)
通常一个 Transformer 有多个这样的层(比如 12 层)。
上层的注意力就能看得更“抽象”:
-
底层:词法关系(谁修饰谁)
-
中层:语法关系(主谓宾)
-
高层:语义关系(意图、主题)
最后,整个句子的语义向量就出来了。
小结:我们刚才做了什么
| 阶段 | 内容 | 比喻 |
|---|---|---|
| Tokenize | 把句子拆成词 | “每个角色登场” |
| Embedding | 变成数字向量 | “角色的属性卡” |
| Q/K/V | 三个视角 | “问、答、内容” |
| Attention | 看别人时的权重 | “我重点听谁的” |
| Multi-Head | 多角度分析 | “多个小脑袋同时想” |
| Output | 汇总融合 | “开会总结发言” |
最终理解(以句子为例)
多头注意力机制让模型学会:
我(主语) ──请──> 李雷(宾语) 李雷(执行者) ──帮──> 我 帮──订了──> 机票(宾语) 订了──去──> 北京(地点)
这些关系全靠不同头的注意力学习出来,不用人工规则。
下一章用python手搓多头注意力机制的具体的代码实现