vllm系统架构图解释
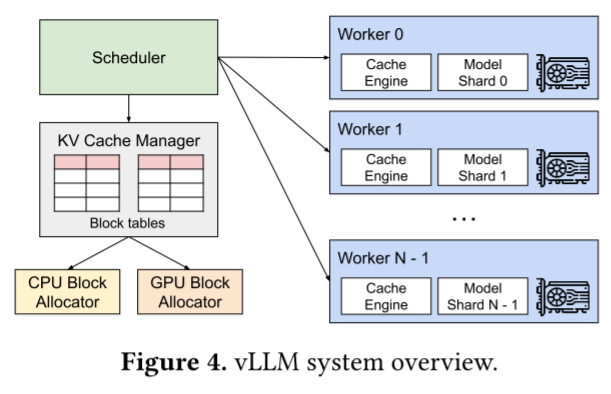
要理解Figure 4(vLLM系统架构图),我们可以从模块功能、组件协作、技术设计意图三个维度逐一拆解:
一、核心模块的功能与角色
1. Scheduler(调度器)
- 功能:作为系统的“大脑”,负责接收用户请求,并将请求分配给不同的Worker(即不同的计算节点)。
- 设计意图:实现请求的负载均衡,确保多个Worker(如Worker 0、Worker 1…Worker N-1)能高效协同处理大量并发请求。
2. KV Cache Manager(KV缓存管理器)
- 子组件:
Block tables(块表)、CPU Block Allocator(CPU块分配器)、GPU Block Allocator(GPU块分配器)。 - 功能:
Block tables:记录KV缓存块在GPU/CPU显存中的物理地址映射(类似操作系统的页表,管理“逻辑块”到“物理块”的映射)。CPU/GPU Block Allocator:负责在**GPU显存(优先)或CPU内存(兜底)**中分配、回收固定大小的KV缓存块(即PagedAttention中的“块”)。
- 设计意图:通过“分块管理+跨设备分配”,解决传统系统的显存碎片问题,同时实现KV缓存的高效共享与动态调度。
3. Worker(工作节点)
- 子组件:
Cache Engine(缓存引擎)、Model Shard(模型分片,如Model Shard 0、Model Shard 1…Model Shard N-1)。 - 功能:
Cache Engine:基于KV缓存管理器提供的块信息,执行PagedAttention算法(即拼接分散的KV块,完成注意力计算)。Model Shard:LLM模型被分片存储在不同Worker上(比如一个70B模型拆分成多个Shard,每个Worker存一个Shard),负责执行模型的前向计算(token生成)。
- 设计意图:通过模型分片+分布式Worker,支持超大模型(如千亿参数模型)的推理,并利用多GPU并行提升吞吐量。
二、组件间的协作流程
以“用户发送一个生成请求”为例,系统的协作逻辑如下:
- 请求接入:Scheduler接收用户的生成请求。
- 调度分配:Scheduler根据负载将请求分配给某个Worker(如Worker 0)。
- 缓存分配:KV Cache Manager通过
GPU Block Allocator为该请求分配GPU显存块(若GPU显存不足,再由CPU Block Allocator分配CPU内存块),并在Block tables中记录块的映射关系。 - 推理计算:Worker的
Cache Engine读取Block tables中的块信息,拼接KV缓存块;同时Model Shard加载模型参数,结合KV缓存执行前向计算,生成新token。 - 结果返回:Worker将生成结果返回给用户,同时KV Cache Manager更新块的使用状态(如新增生成token的KV块)。
三、技术设计的核心意图(结合论文背景)
vLLM的架构是为了解决传统LLM服务中KV缓存碎片多、显存利用率低、吞吐量不足的问题:
- 分块管理(PagedAttention):通过KV Cache Manager将KV缓存拆分为固定块,避免连续存储导致的内部/外部碎片,提升显存利用率。
- 分布式Worker+模型分片:支持超大模型的推理(单GPU无法容纳全量模型时,分片到多Worker),同时通过多Worker并行处理请求,提升整体吞吐量。
- CPU/GPU混合缓存:GPU显存优先用于性能敏感的KV缓存,CPU内存作为兜底,在显存不足时临时存储,保证请求不被拒绝。
通过这一架构,vLLM实现了“高显存利用率+高吞吐量”的LLM服务能力,这也是论文核心创新点的工程落地体现。
1. 你上面生成的答案中【功能:作为系统的 “大脑”,负责接收用户请求,并将请求分配给不同的 Worker(即不同的计算节点)。】Worker(即不同的计算节点)指的是gpu吗?2. 每个worker里面还有2个白色的框,分别是cache engine 和 model shard请问这2个是什么,有什么作用??
问题1解答
Worker 不完全等同于 GPU,它是承载计算任务的逻辑单元,其计算资源核心是 GPU,但也包含配套的 CPU、内存等。
- 从硬件角度看:每个 Worker 通常会绑定一张或多张 GPU(比如论文中测试用的 NVIDIA A100 GPU),GPU 是执行 LLM 模型计算(如注意力机制、张量运算)的核心硬件。
- 从逻辑架构看:Worker 是系统层面的“工作节点”抽象,除了 GPU,还需要 CPU 来处理调度、内存管理等辅助任务,以及内存来存储模型参数、中间结果等。所以说 Worker 是包含 GPU 在内的“计算节点”,而非单纯的 GPU。
问题2解答
Cache Engine(缓存引擎)
- 作用:负责 KV 缓存的高效管理与运算加速。
- 基于 PagedAttention 算法,它能将分散存储的 KV 缓存块(这些块可能在 GPU 显存或 CPU 内存中)“虚拟拼接”起来,供注意力计算使用,解决了传统连续存储导致的显存碎片和浪费问题。
- 在推理过程中,快速读取、更新 KV 缓存,支撑大批次请求的并行处理,是提升 LLM 服务吞吐量的关键组件。
Model Shard(模型分片)
- 作用:实现大模型的分布式存储与计算。
- 对于超大规模 LLM(如千亿参数模型),单张 GPU 显存无法容纳完整模型参数。Model Shard 将模型按层或按张量分片,分散存储在不同 Worker 的 GPU 显存中。
- 推理时,不同 Worker 的 Model Shard 协同工作,完成模型的前向传播计算,使得大模型在多 GPU 集群上的高效推理成为可能。