Mysql杂志(三十四)——MVCC、日志分类
我们之前在第三十二篇的时候说过https://blog.csdn.net/qq_45041250/article/details/153202270?spm=1001.2014.3001.5501,数据库的隔离性是由MVCC+锁的机制来实现的。锁的相关内容主包上一篇已经说的很明白了,今天来说一下MVCC多版本控制。
什么是MVCC
MVCC(Multi-Version Concurrency Control)是InnoDB实现非锁定读的核心机制,通过维护数据的多个历史版本,实现:读不阻塞写、写不阻塞读、避免脏读/不可重复读。实现这个功能的主要功臣就是ReadView,我们之前也讲过四个隔离级别,分别是读未提交、读已提交、可重复读、串行读,其中读未提交本身就是脏读所以不需要MVCC,而串行读是全部加锁一个一个排队来,所以不存在脏读、幻读所以也不需要MVCC,所以MVCC服务的对象就是读已提交、可重复读这2个隔离级别,现在其他的都不需要管,只需要记住读已提交不管在不在一个事务,都会生成新的ReadView,而可重复读,在同一个事物中查同一行数据只会生成一个ReadView,主包认为这个就是可重复读的名字由来。
ReadView
| 字段 | 大小 | 作用 | 示例 |
|---|---|---|---|
| DB_TRX_ID | 6B | 最后修改事务ID | 10023 |
| DB_ROLL_PTR | 7B | 回滚指针 | 0x7FAB89 |
| DB_ROW_ID | 6B | 隐式自增ID | 1024 |
这个是我们之前讲索引的时候讲的行格式中的三个隐藏字段,其中DB_ROLL_PTR这个指向的就是undolog。
这个是ReadView的主要字段,其实每个ReadView还有个trx_id,也就是创建他的事务id,如果是查询且没有加事务,那么这个trx_id就是0,也就是MVCC不管加没加事务都会生成一个Readview,来保证数据的一致性也就是可重复读。
| 要素 | 生成规则 | 作用 |
|---|---|---|
| m_ids | 快照时刻活跃事务ID列表 | 过滤未提交事务 |
| m_up_limit_id | 最小活跃事务ID | 快速判断老事务 |
| m_low_limit_id | 分配的下个事务ID | 识别新事务 |
然后我们创建一个ReadView的时候,就会检测当前未提交的事务这些事务被称为活跃事务,然后把这些活跃事务写入到m_ids列表中,然后m_up_limit_id记录的是当前最小的活动事务ID,m_low_limit_id这个是当前最大事务ID+1,表示的就是下次事务分配的id就是这个数。
ReadView读取流程
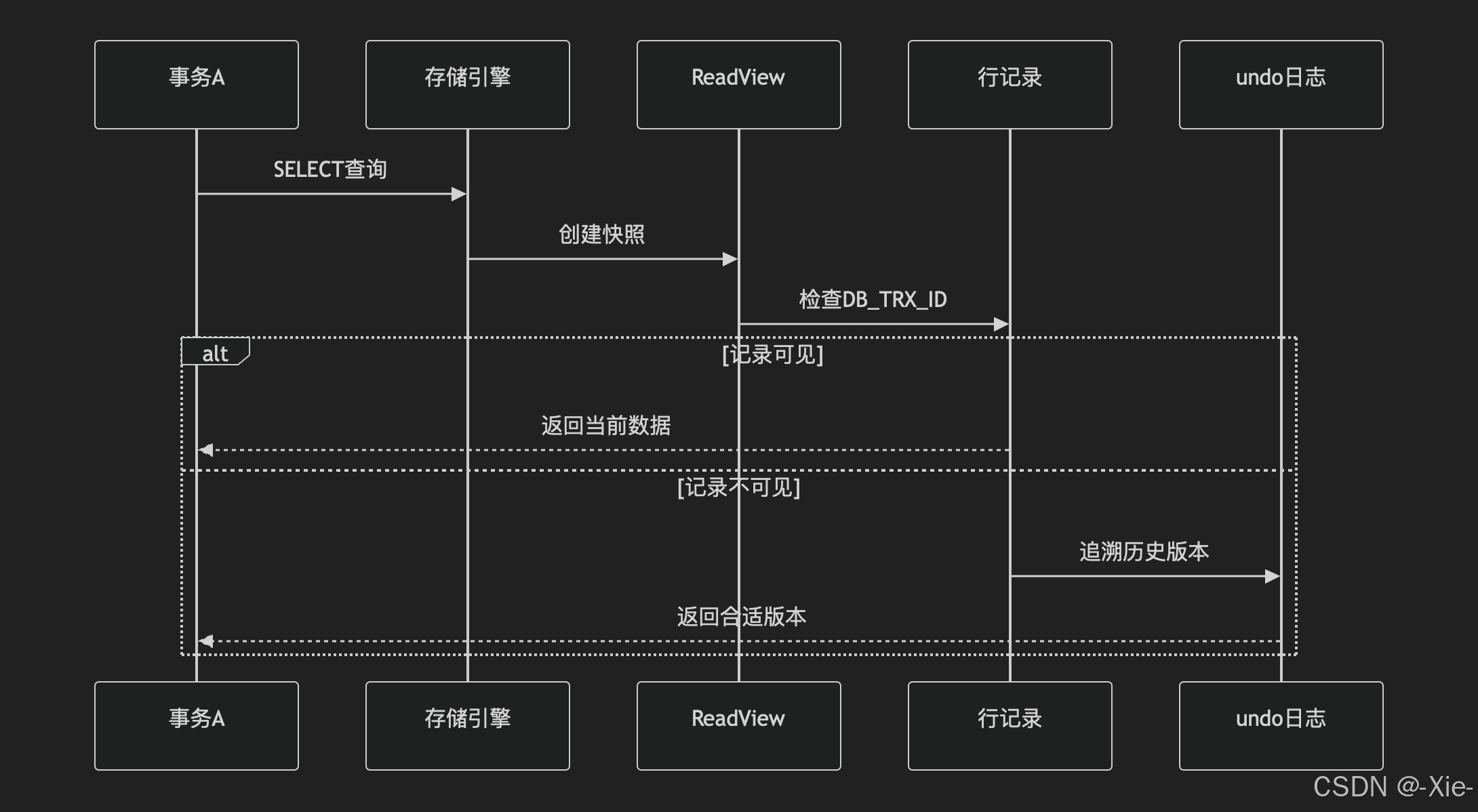
第一,我们读取一行数据的时候,不管这个数据加没加锁都会生成一个ReadView,然后记录当前活跃的事务数组。
第二,找到要读取的这行数据的事务ID,然后按照以下的方式进行读取。
def is_visible(trx_id, read_view):# 第一阶:低水位线检查if trx_id < read_view.m_up_limit_id:return True # 已提交的老事务# 第二阶:高水位线检查if trx_id >= read_view.m_low_limit_id:return False # 未来事务或当前事务自身修改# 第三阶:活跃事务检查if trx_id in read_view.m_ids:return False # 未提交的活跃事务return True # 已提交的中间事务先检查最小事务id也就是低水位线,如果小于那么表示这个数据早就提交了,是干净的数据,返回当前行的数据。
如果不满足就检查是否大于等于最高事务ID也就是高水位线,如果是则进行下一个循环也就是找到undolog的下一个版本,为什么不能大于等于最高水位线?是因为这个是未来的事务id,你不知道他是否已经提交,所以不能读取万一是脏读呢?
然后就是检查是否在我们的活跃事务id中,如果再的话也不能读取,因为活跃事务数组中的事务都是没有提交的,是脏数据,所以就会通过undolog去找上一个版本,然后再这样循环,直到找到可以访问的数据,如果没有那么就表示,这个数据是未来事务新增的,或者是活跃事务数组中的某一个事务新增的,所以就查询为空了,不会产生幻读的现象。
然后当一个事务消亡那么对应的ReadView也会消亡。好了这下知道Mysql是怎么解决幻读、脏读了吧,AICD原则也都很清楚了。
日志分类
我们之前已经知道了有undo log喝redo log,那mysql是不是还有其他的日志文件呢?那肯定是有的呀,他们可以分为三大类分别是事务日志、复制日志、操作日志。需要注意的是只有操作日志才是文本日志,其他的都是二进制日志,文本日志可以直接使用vim查看,其他的日志想查看就得借助一些工具了。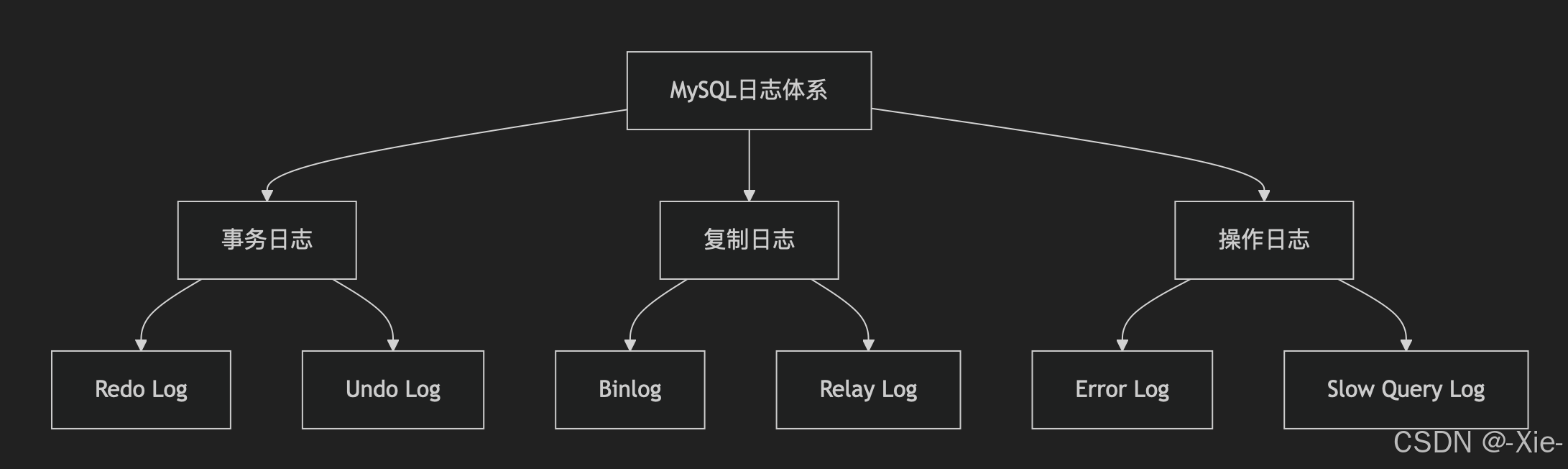
我们今天先来简单的过一下他们吧。
事务日志
1. Redo Log(重做日志)
这个我们之前讲过了这里就不说了
| 特性 | 描述 | 生产价值 |
|---|---|---|
| 作用 | 崩溃恢复、保证事务持久性 | 数据安全基石 |
| 存储 |
| 性能提升5-10倍 |
| 内容 | 物理日志(页修改) | 精确恢复 |
| 刷盘策略 |
| 之前有说过默认是1,有三种行为 |
2. Undo Log(回滚日志)
| 特性 | 描述 | 生产价值 |
|---|---|---|
| 作用 | 事务回滚、MVCC多版本控制 | 高并发基础 |
| 存储 | undo表空间(8.0+独立文件) | 隔离性保障 |
| 内容 | 逻辑日志(行前镜像) | 版本链管理 |
| 清理机制 | Purge线程异步清理 | 空间自动回收 |
复制日志
1. Binlog(二进制日志)
这一部分我们留到下篇说吧。
| 特性 | 描述 | 生产价值 |
|---|---|---|
| 作用 | 主从复制、数据恢复 | 高可用核心 |
| 存储 |
| 跨实例同步 |
| 格式 | Statement/Row/Mixed | 灵活选择 |
| 应用场景 | 数据恢复、异构同步 | 业务连续性 |
2. Relay Log(中继日志)
| 特性 | 描述 | 生产价值 |
|---|---|---|
| 作用 | 从库接收主库binlog的临时存储 | 复制缓冲 |
| 存储 |
| 解耦主从 |
| 生命周期 | SQL线程应用后删除 | 空间自动管理 |
| 监控重点 | 延迟检测、文件堆积 | 复制健康度 |
操作日志
1. Error Log(错误日志)
这个日志是mysql默认就打开的而且是无法关闭的,我们可以通过 show variables查看相关的属性,这个日志会记录整个mysql服务器的错误,默认名字是mysqld.log在linux中。
| 特性 | 描述 | 生产价值 |
|---|---|---|
| 作用 | 记录启动/运行/停止错误信息 | 故障诊断 |
| 存储 |
| 问题定位 |
| 级别 | Note/Warning/Error | 分级告警 |
| 关键信息 | 崩溃堆栈、参数错误 | 快速恢复 |
这个是相关的一些系统变量:
| 参数 | 默认值 | 推荐值 | 作用说明 |
|---|---|---|---|
|
|
| 自定义路径 | 日志文件位置 |
|
| 2 (5.7+) | 3 | 详细级别 |
|
| 8.0+ |
| 日志服务组件 |
|
| UTC | SYSTEM | 时间戳格式 |
|
| 2 | 2 | 警告级别 |
这个是错误级别:
| Verbosity | 记录内容 | 生产建议 |
|---|---|---|
| 1 | ERROR级错误 | 生产环境最低要求 |
| 2 | ERROR+WARNING | 默认推荐配置 |
| 3 | ERROR+WARNING+NOTE | 开发/调试环境 |
2. Slow Query Log(慢查询日志)
这个大家应该也多多少少有所耳闻了,这个默认也是关闭的,查看的相关属性的命令还是 show variabels like命令,设置同样也是set globle 。
| 特性 | 描述 | 生产价值 |
|---|---|---|
| 作用 | 记录执行超时的SQL语句 | 性能优化 |
| 存储 |
| SQL调优 |
| 阈值 |
| 可配置 |
| 分析工具 | mysqldumpslow、pt-query-digest | 自动化分析 |
这个是慢sql日志的一些系统变量和其作用:
| 参数 | 默认值 | 推荐值 | 作用说明 |
|---|---|---|---|
|
| OFF | ON | 总开关 |
|
|
| 自定义路径 | 日志文件位置 |
|
| 10秒 | 0.5-2秒 | 慢查询阈值 |
|
| OFF | ON | 记录无索引查询 |
|
| OFF | ON | 记录管理命令 |
|
| OFF | ON(主从架构) | 从库慢查询 |
|
| FILE | FILE/TABLE | 输出格式 |
这个是日志大概的样子:这个文本怎么看相信就不需要主包来解释了,学习了执行计划再来看这种日子文件还是蛮简单的。
# Time: 2023-08-15T10:23:45.123456Z
# User@Host: root[root] @ localhost [127.0.0.1]
# Query_time: 3.141592 Lock_time: 0.000123 Rows_sent: 100 Rows_examined: 1000000
SET timestamp=1692095025;
SELECT * FROM orders WHERE create_date > '2023-01-01' AND status='PENDING';3. General Query Log(通用查询日志)
这个其实也是操作日志,但是默认是关闭的,因为他记录的是所以执行的sql,可想而知是非常大的,根本没有这么多的内存可以供他一直开启,所以一般都是用在调试或者查询问题的时候短暂开启的,还是一样使用 show variables like进行查看系统变量,设置值的话还是set globle 进行设置。
| 参数 | 默认值 | 取值范围 | 作用说明 |
|---|---|---|---|
|
| OFF | ON/OFF | 总开关 |
|
|
| 合法路径 | 日志文件位置 |
|
| FILE | FILE/TABLE/NONE | 输出目标 |
|
| UTC | SYSTEM/UTC | 时间戳格式 |
日志的内容大概就是下面这个样子:
2023-08-15T10:23:45.123456Z 42 Connect root@localhost on employees
2023-08-15T10:23:46.234567Z 42 Query SELECT * FROM salaries WHERE emp_no=10001
2023-08-15T10:23:47.345678Z 42 Query UPDATE salaries SET salary=salary*1.1 WHERE emp_no=10001
2023-08-15T10:23:48.456789Z 42 Quit总结
本篇主要讲了什么是MVCC和MVCC有什么作用、实现的流程,以及介绍了日志分类。