用 AI 编码代理重塑前后端交互测试的未来
引言:E2E 测试的隐性成本与新时代的拂晓
在现代软件工程的宏伟蓝图中,端到端(End-to-End, E2E)测试无疑是确保交付质量的最后、也是最关键的一道防线。它模拟真实用户的完整操作路径,贯穿前端用户界面、中层业务逻辑乃至后端数据存储,以无可辩驳的姿态验证着整个系统的协同工作能力。然而,每一位在工程实践前线奋战的开发者、测试工程师和 DevOps 专家都心知肚明,这份“质量保证”的背后,附带着一张沉重且常常被低估的“隐性成本”清单。

我们称之为 “E2E 测试税” (The E2E Testing Tax)。
这笔税费体现在多个方面:
- 高昂的编写与维护成本:传统的 E2E 测试脚本,无论是基于 Selenium、Cypress 还是 Playwright,本质上都是一种“指令式编程”。开发者需要像一个微观管理者一样,精确地告诉自动化工具每一步该“如何”操作:点击哪个 ID 的按钮、等待哪个 CSS 选择器出现、在哪个输入框里填入什么文本。当 UI 发生哪怕最微小的重构——一个类名的变更、一个组件的拆分——都可能导致成百上千行测试脚本的脆弱断裂,引发连锁性的维护噩梦。
- 固有的不稳定性(Flakiness):网络延迟、动画效果、资源加载顺序等异步问题,是 E2E 测试不稳定的主要根源。为了解决这些问题,我们堆砌了大量的
waitForSelector,setTimeout,retry逻辑,这些“防御性”代码让测试脚本变得臃肿不堪,却依然无法根除偶发性的“红灯”。每一次 CI/CD 流水线的随机失败,都在无形中消耗着团队的注意力和信任。 - 陡峭的学习曲线与专业化壁垒:精通一套 E2E 测试框架,并能写出健壮、可维护的测试代码,本身就是一项专业技能。这在团队内部形成了知识壁垒,使得前端开发者可能不愿涉足,后端开发者望而却步,最终测试自动化的重担往往落在少数专家身上,成为流程中的瓶颈。
长久以来,我们默认接受了这笔“税费”,将其视为保障质量的必要代价。我们不断优化框架、改进设计模式,试图在这座不断变化的沙丘上建造一座尽可能坚固的城堡。
然而,一场由大型语言模型(LLM)驱动的范式革命正在悄然发生,它预示着一个根本性的转变。它将我们从繁琐、脆弱的 “指令式脚本” (Imperative Scripting) 中解放出来,带入一个全新的、以自然语言为核心的 “意图驱动自动化” (Declarative Intent Automation) 时代。
在这个新时代,我们不再需要手把手地教机器“如何做”,我们只需清晰地描述我们“想要什么”。
本文将作为您深入探索这个前沿领域的向导。我们将通过一个 100% 真实、可复现、可落地 的实战案例,手把手地向您展示如何利用 Google 的 Gemini CLI、Chrome DevTools MCP 和 Microsoft 的 Playwright MCP,构建一个能够理解人类语言的“AI 编码代理”。这个代理将全自动地完成一个典型的全栈应用交互测试场景——从启动服务、操作浏览器,到深度网络抓包验证,再到生成测试报告——全过程无需手写一行测试代码。
准备好迎接这场变革了吗?让我们一同揭开 AI 编码代理的神秘面纱,见证它如何彻底颠覆我们对软件测试自动化的传统认知。
第一部分:理论基石 —— 解构 AI 编码代理的内在机理
在深入实践之前,我们必须首先建立一个坚实的理论框架。理解“AI 编码代理”不仅仅是学会一个新工具的用法,更是理解一种全新的工作模式。这一部分,我们将像解剖学家一样,逐层剖析构成这个代理的核心组件,理解它们各自的角色以及它们如何协同作战,最终实现“意图”到“执行”的惊人飞跃。
第一章:软件工程中的“代理”工作流 (Agentic Workflows)
“代理”(Agent)一词在计算机科学中并不新鲜,但与 LLM 结合后,它被赋予了全新的、更为强大的内涵。一个“AI 代理”,尤其是在软件工程领域,可以被定义为:
一个以大型语言模型为核心“大脑”,能够自主理解高级目标、将其分解为一系列可执行任务、并利用外部工具集(The Toolbox)来完成这些任务的自治系统。
这个定义包含三个核心要素:
- 大脑 (The Brain):即 LLM,如 Google 的 Gemini 模型。它负责处理自然语言,进行逻辑推理、规划和决策。它是代理的认知中枢。
- 任务分解 (Task Decomposition):代理的核心能力之一是“化整为零”。它能将一个模糊的、高级的目标(例如,“测试一下用户登录功能”)分解成一系列具体的、原子化的步骤(启动数据库 -> 启动后端服务 -> 启动前端服务 -> 打开浏览器 -> 导航到登录页 -> …)。
- 工具使用 (Tool Usage):这是代理能够与真实世界(或数字世界)互动的关键。仅有大脑是无法执行操作的。代理必须能够调用外部工具来完成任务,例如调用终端执行命令、调用文件系统 API 读写文件、调用浏览器自动化框架来操作网页。
传统的 CI/CD 流水线,本质上是一种“硬编码”的自动化。我们预先定义好每一个步骤,机器严格按照脚本执行。而代理工作流则是一种“动态”的、“智能化”的自动化。我们提供的是目标和可用的工具集,代理则在运行时动态地生成并执行计划。这种模式的优势是巨大的灵活性和适应性。

第二章:指挥官的大脑 —— Gemini CLI 作为意图编排器
如果说 Gemini 模型是代理的“大脑”,那么 Gemini CLI (Command-Line Interface) 就是连接我们与这个大脑的“神经接口”和“指挥系统”。它扮演着意图编排器 (Intent Orchestrator) 的关键角色。
gemini 命令本身不仅仅是一个简单的模型 API 包装器。它被设计成一个强大的、支持工具化扩展的本地开发环境。当我们执行类似 gemini -F GEMINI.md -p "..." 这样的命令时,背后发生了一系列复杂的编排工作:
- 上下文加载 (Context Loading):Gemini CLI 会读取
-F参数指定的文件(GEMINI.md),以及-p参数提供的提示(Prompt),将这些信息组合成一个完整的、富含上下文的请求。这为模型提供了执行任务所需的所有背景知识。 - 工具发现与注入 (Tool Discovery & Injection):这是最核心的环节。Gemini CLI 会检查当前环境中注册了哪些可用的“工具”。在我们的案例中,它会发现
chrome-devtools和playwright这两个工具(即 MCP)。然后,它会将这些工具的功能描述(以一种模型能理解的特定格式)一并注入到发送给 Gemini 模型的请求中。这相当于告诉模型:“嘿,你现在不仅能思考,你还拥有了这两件强大的武器,这是它们的使用说明书。” - 模型推理与规划 (Model Reasoning & Planning):Gemini 模型接收到包含目标、上下文和可用工具集的完整请求后,开始进行它的核心工作。它会阅读
GEMINI.md中的任务列表,理解最终目标,然后生成一个详细的、分步骤的执行计划。这个计划不再是抽象的文字,而是具体的、针对所提供工具的函数调用序列。 - 执行与反馈循环 (Execution & Feedback Loop):Gemini CLI 接收到模型返回的“计划”(即一系列工具调用指令)。它会解析这些指令,并在本地环境中实际执行它们。例如,当模型决定“使用 Playwright 启动浏览器”时,CLI 就会调用 Playwright MCP 对应的功能。如果工具执行成功,CLI 会将结果返回给模型,以便它继续执行下一步计划。如果执行失败,错误信息也会被反馈给模型,模型可能会尝试修正计划或报告失败。
因此,Gemini CLI 远不止是一个命令行工具,它是整个代理工作流的本地执行引擎和总调度师,确保了从人类的自然语言意图到机器的精确代码执行之间的无缝转换。
第三章:代理的双手 —— 深入理解 MCP (Model-Centric Peripheral) 架构
这是整个技术栈中最具创新性和决定性的部分。如果我们说 LLM 是大脑,CLI 是神经系统,那么 MCP (Model-Centric Peripheral) 就是代理得以与复杂软件世界交互的“高精度机械臂”或“通用传感器”。
[核心概念] MCP (Model-Centric Peripheral)
MCP,即“以模型为中心的外设”,是一种标准化的软件封装协议。它的核心思想是将任何复杂的软件工具(如 Chrome DevTools、Playwright、Kubernetes CLI)封装成一个独立的、可通过标准输入输出(stdin/stdout)进行通信的命令行程序。这个程序能够向 AI 模型清晰地“自我描述”其所能提供的功能(Capabilities),并能精确地执行模型发出的指令。
要理解 MCP 的革命性,我们必须先看看没有它时 AI 面临的困境:
-
传统方式的局限:在 MCP 出现之前,让 LLM 使用工具通常依赖于“函数调用”(Function Calling)或“ReAct”等框架。开发者需要手写大量的“胶水代码”,为每个工具的每个功能都定义好精确的 API 模式(Schema),并处理复杂的调用逻辑。这种方式紧耦合、难以扩展,每增加一个新工具都意味着大量的开发工作。
-
MCP 的优雅解决方案:MCP 架构将这种复杂性彻底解耦。
- 自描述能力 (Self-Description):任何一个 MCP 程序,当你用一个特定的标志(例如
--mcp-schema)去调用它时,它必须返回一个 JSON 格式的“功能清单”。这个清单详细描述了它叫什么名字、能做什么、每个功能需要什么参数、参数是什么类型等等。Gemini CLI 正是利用这个机制来自动发现和理解工具能力的。 - 标准化通信协议 (Standardized Communication):当模型决定使用某个 MCP 的功能时,Gemini CLI 会以一种标准的 JSON 格式通过 stdin 将指令(函数名和参数)传递给 MCP 进程。MCP 执行完任务后,再将结果(成功或失败,以及返回值)以同样的标准 JSON 格式通过 stdout 返回。
- 独立与可组合 (Standalone & Composable):每个 MCP 都是一个独立的 npm 包(或可执行文件)。你可以像乐高积木一样,即插即用地为你的 AI 代理添加新的能力。今天你可以组合 DevTools 和 Playwright 来做测试,明天就可以组合
gcloud和kubectl的 MCP 来做云资源管理。
- 自描述能力 (Self-Description):任何一个 MCP 程序,当你用一个特定的标志(例如
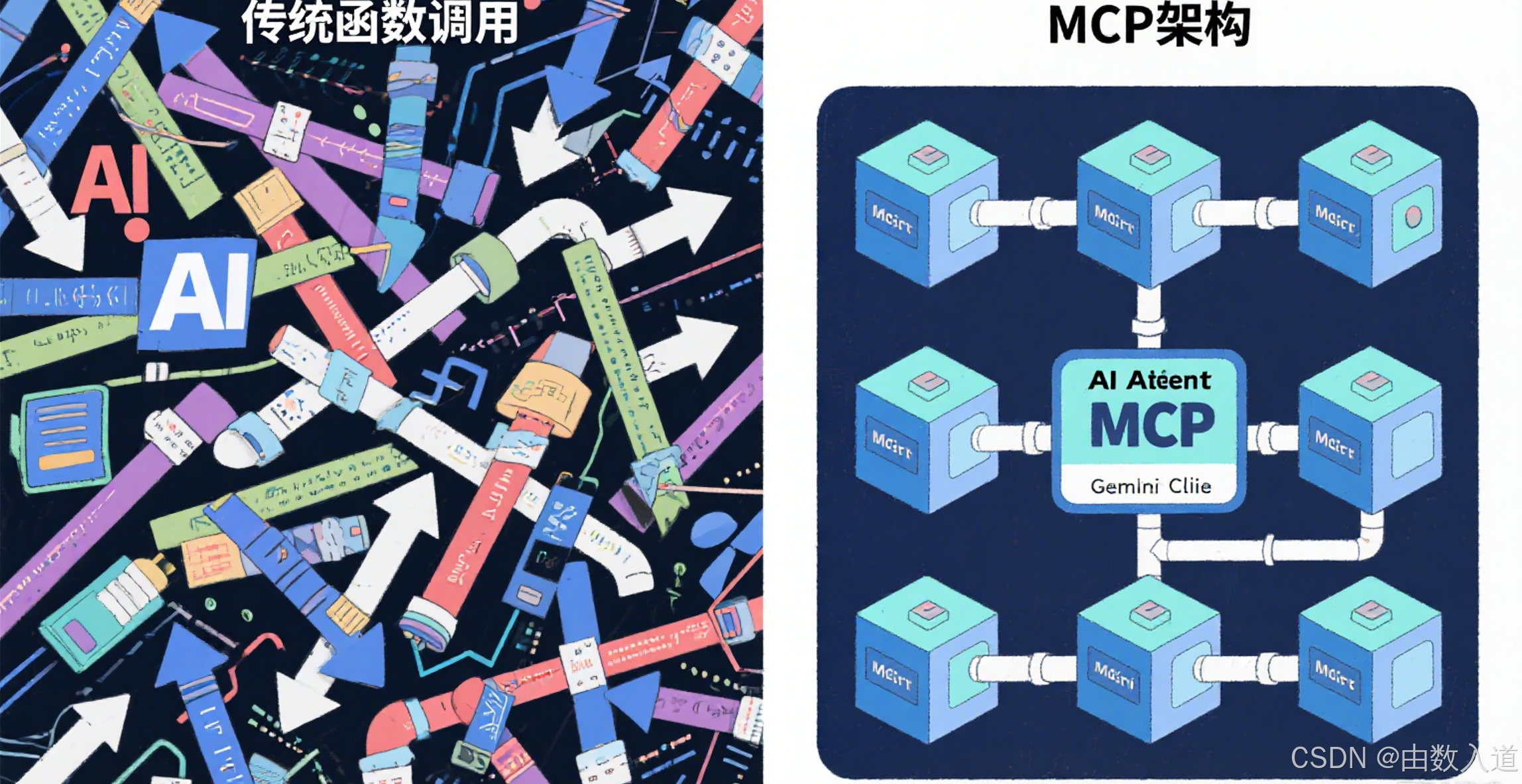
MCP 的本质,是为 AI 定义了一个 “与软件交互的通用总线”。它将世界上的任意软件,从复杂的 GUI 应用(如浏览器)到命令行工具,都转化成了模型可以理解和操作的、标准化的“外设”。这正是“AI 编码代理”能够可靠、稳定地执行复杂任务的底层技术保障。没有 MCP,代理就如同一个有大脑但没有四肢的思想家,空有智慧却无法行动。
第四章:我们的工具箱 —— Playwright 与 DevTools MCP 详解
现在,让我们具体看看本次实战中使用的两个核心 MCP:
-
@playwright/mcp:- 角色: 浏览器自动化执行器。
- 封装能力: 它将 Playwright 这个强大的浏览器自动化库的核心功能,如启动浏览器、打开页面、点击元素、填写表单、等待网络请求、截图等,封装成了 MCP 协议下的标准工具。
- AI 如何使用: 模型不再需要知道 Playwright 的具体 API(如
page.goto()或page.screenshot())。它只需要发出一个更高层次的指令,比如playwright.newPage({url: 'http://...'})或playwright.screenshot({path: 'ping.png'})。Playwright MCP 内部会负责将这个指令翻译成真实的 Playwright 代码并执行。这极大地降低了模型使用浏览器的认知负担。
-
chrome-devtools-mcp:- 角色: 深度浏览器状态检查器。
- 封装能力: 这是一个更为精妙的工具。它利用 Chrome DevTools Protocol (CDP),可以直接连接到由 Playwright(或其他工具)启动的浏览器实例的调试端口。它暴露出的能力,是直接对浏览器内核进行“审问”,例如:捕获所有网络请求的详细信息(URL、状态码、请求头、响应体)、检查性能指标、分析可访问性树等。
- AI 如何使用: 在我们的场景中,AI 需要验证
/api/ping这个网络请求的细节。如果只用 Playwright,这将非常繁琐,需要注入复杂的客户端脚本来监听fetch事件。但有了 DevTools MCP,模型可以直接发出指令,如chrome-devtools.captureNetworkRequests(),然后对返回的请求列表进行分析。这是一种远比模拟用户操作更为精准、可靠的底层数据验证方式。
总结一下:在这个代理系统中,Playwright MCP 扮演了“操作者”的角色,负责执行用户的行为;而 Chrome DevTools MCP 则扮演了“观察者”或“审查员”的角色,负责深入浏览器内部,验证行为导致的结果是否符合预期。两者的结合,构成了一个功能完备、能力互补的 Web 自动化测试工具箱。
至此,我们已经完整地构建了 AI 编码代理的理论大厦。我们理解了代理工作流的宏观概念,认识了 Gemini CLI 作为指挥官的角色,洞悉了 MCP 架构作为连接桥梁的关键作用,并熟悉了我们将要使用的两个核心工具。现在,理论已经武装到牙齿,是时候进入激动人心的实战环节了。
第二部分:实战蓝图 —— 构建“零配置”的全栈测试流水线
理论的价值最终要在实践中得以体现。在这一部分,我们将卷起袖子,一步一步地搭建并运行我们的 AI 编码代理。我们将使用一个极简但功能完备的全栈项目,亲眼见证前文所述的所有理论概念如何协同工作,最终仅凭一份自然语言的“指令单”,完成一次复杂的端到端交互测试。
第一章:场景设定 —— 待测的全栈应用
为了让演练清晰明了,我们准备了一个典型的现代 Web 应用开发场景:
- 前端 (Client): 一个基于 React + Vite 的单页面应用。它运行在本地的
http://localhost:5173。这个应用非常简单,在加载后会立即向后端发送一个 API 请求。 - 后端 (Server): 一个基于 Node.js + Express 的轻量级 API 服务器。它运行在本地的
http://localhost:3001。它只提供一个接口/api/ping,当收到 GET 请求时,会返回一个 JSON 对象{ "msg": "pong" }。
测试目标: 我们的核心任务是自动化地验证前后端之间的交互是否正确。具体来说,AI 代理需要完成以下所有操作:
- 同时启动前端和后端两个服务。
- 等待服务完全启动。
- 使用无头浏览器访问前端页面。
- 在浏览器开发者工具中捕获网络流量。
- 确认前端确实发起了对
/api/ping的请求。 - 验证该请求的 HTTP 响应状态码是
200 OK。 - 验证该请求的响应体内容完全符合预期的
{ "msg": "pong" }。 - 将测试结果(包括截图和结构化报告)保存到本地文件。
- 最后,优雅地关闭所有启动的进程,清理现场。
这是一个看似简单但五脏俱全的 E2E 测试场景,传统方法下,它需要编写包含进程管理、延时等待、Playwright 脚本、网络监听、断言库、文件操作等在内的复杂代码。而现在,我们将展示如何用几行自然语言来完成这一切。
第二章:步骤 0. 环境初始化 (一次性投入)
在召唤我们的 AI 代理之前,需要先为它准备好工作环境和工具箱。这个过程是一次性的,一旦完成,后续就可以反复使用。
[专家提示]
请确保您的开发环境中已安装 Node.js (建议 v18 或更高版本) 和 npm。
打开您的终端,执行以下命令:
# 1. 全局安装 Google Gemini CLI
# 这是我们的核心指挥系统
npm i -g @google/genai-cli# 2. 为 Gemini CLI 添加 (注册) 两个 MCP 工具
# 这相当于为 AI 代理配备它的“双手”和“眼睛”
# a. 添加 Chrome DevTools MCP,并将其命名为 'chrome-devtools'
gemini mcp add -s user chrome-devtools npx chrome-devtools-mcp@latest# b. 添加 Playwright MCP,并将其命名为 'playwright'
gemini mcp add -s user playwright npx @playwright/mcp@latest
命令深度剖析:
npm i -g @google/genai-cli: 这会在您的系统中全局安装gemini命令,让您可以从任何地方调用它。gemini mcp add ...: 这是注册 MCP 的标准命令。-s user: 指定将 MCP 信息保存在用户级别的配置中。chrome-devtools/playwright: 这是我们为工具起的“别名”。后续在指令中,AI 将通过这个名字来识别和调用工具。npx ...@latest: 这部分是 MCP 的实际“位置”或“执行方式”。npx命令可以确保每次运行时都使用最新版本的 MCP 包,避免了本地缓存带来的问题。这种设计极具弹性,MCP 不仅可以来自 npm,也可以是任何本地的可执行脚本。
完成上述步骤后,您的 AI 代理已经“武装”完毕。接下来,获取我们的示例项目代码。
# 3. 克隆包含前后端代码的示例仓库
git clone https://github.com/your-org/fullstack-quickstart.git # 请替换为实际可用的仓库地址# 4. 进入项目目录并安装依赖
cd fullstack-quickstart
npm install
至此,所有的前期准备工作都已完成。我们的舞台已经搭好,演员(前后端应用)和导演(AI 代理)都已就位。
第三章:步骤 1. 撰写 AI 的“任务简报” (GEMINI.md)
现在,我们来完成最核心的一步:用自然语言告诉 AI 它需要做什么。我们不需要写任何代码,只需在项目根目录下创建一个名为 GEMINI.md 的 Markdown 文件,然后在其中清晰地列出我们的任务步骤。
GEMINI.md 文件内容:
# AI 编码代理:全栈应用交互测试## 任务目标
自动化执行一次完整的前后端交互测试,验证核心 API `/api/ping` 的连通性与数据准确性。## 执行步骤
1. **并发启动服务**:* 在后台启动后端服务,命令为 `npm run dev:server`。它应该监听在 3001 端口。* 在后台启动前端服务,命令为 `npm run dev:client`。它应该监听在 5173 端口。2. **等待与浏览器初始化**:* 等待 5 秒,确保两个开发服务器都已完全启动并准备就绪。* 使用 Playwright 工具,启动一个 Chromium 浏览器的无头实例 (headless mode)。* 导航浏览器到前端应用的地址:`http://localhost:5173`。3. **网络请求捕获与验证**:* 使用 Chrome DevTools 工具,连接到当前浏览器实例。* 开始捕获所有网络请求。* 在捕获到的请求中,找到 URL 包含 `/api/ping` 的网络请求。* **核心断言**:验证该请求的响应满足以下所有条件:* HTTP 状态码 (status) 必须等于 `200`。* 响应体 (response body) 的 JSON 内容必须严格等于 `{ "msg": "pong" }`。4. **结果产出**:* 如果所有验证都通过,生成一份名为 `test-report.json` 的测试报告文件。报告中应包含测试结果(例如 "PASS")以及捕获到的 `/api/ping` 请求的详细信息。* 对当前浏览器页面进行截图,并保存为 `ping.png` 文件。5. **清理工作**:* 关闭 Playwright 启动的浏览器实例。* 终止在第一步中启动的前端和后端服务进程。
对这份“任务简报”的分析:
- 清晰的结构化:使用 Markdown 的标题和列表,将复杂的任务分解成逻辑清晰、循序渐进的步骤。这是向 AI 提供高质量指令的关键。
- 声明式意图:注意,我们通篇都在描述“做什么”(What),而不是“如何做”(How)。我们说“验证响应体内容”,而没有说“获取响应对象、解析 JSON、然后用
expect(body.msg).toEqual('pong')进行比较”。AI 代理会自行将我们的“意图”翻译成具体的代码实现。 - 精确的细节:虽然是自然语言,但关键信息(如端口号、URL、文件名、命令)都给得非常明确。这有助于 AI 减少猜测,生成更可靠的执行计划。
- 工具的暗示:我们在描述中自然地提到了“使用 Playwright 工具”、“使用 Chrome DevTools 工具”,这为 AI 在规划时选择哪个 MCP 提供了强有力的线索。
这份 GEMINI.md 文件,就是我们与 AI 编码代理沟通的桥梁。它的质量直接决定了代理执行任务的成功率和准确性。
第四章:步骤 2. 一键启动,见证奇迹
所有铺垫都已完成,现在是见证奇迹的时刻。在您的终端中,确保当前路径位于项目根目录(fullstack-quickstart),然后执行这唯一的一条命令:
gemini --stream -F GEMINI.md \-p "请严格按照 GEMINI.md 文件中定义的步骤,执行一次完整的前后端交互测试。整个过程应该是全自动的,无需任何人工干预。"
命令参数详解:
gemini: 调用我们安装的 Gemini CLI。--stream: 以流式模式输出结果。这意味着你将能实时看到 AI 的思考过程、它生成的代码以及代码的执行输出,这对于调试和理解其工作方式非常有帮助。-F GEMINI.md: 指定包含任务上下文和详细步骤的 Markdown 文件。-p "...": 提供一个高层次的、总结性的指令(Prompt)。这个指令通常是对-F文件内容的一个概括和强调,可以帮助 AI 更好地把握核心任务。
按下回车后,请坐下来,泡杯咖啡,欣赏表演。您将会在终端中看到类似以下的输出流:
- AI 首先会确认它理解了任务。
- 接着,它会开始生成一个执行计划,通常会以代码的形式展现。
- 然后,Gemini CLI 会开始执行这段由 AI 生成的代码。
- 您会看到
npm run dev:server和npm run dev:client的启动日志。 - 接着是 Playwright 的执行信息。
- 最后,是任务完成的提示。
整个过程大约会持续 10-30 秒,具体取决于您的机器性能和网络状况。当命令执行完毕,没有任何错误报告时,就意味着我们的 AI 代理已经成功地完成了它的使命。
第五章:魔法揭秘 —— 剖析 AI 自动生成的代码
AI 到底在幕后做了什么?这是最令人好奇的部分。虽然我们无需手写代码,但 Gemini CLI 提供了一种方式来审查 AI 的“工作成果”。在实际执行中,AI 代理(由 Gemini 模型驱动,通过 CLI 执行)会动态生成并执行一段类似于下面这样的 TypeScript/JavaScript 脚本。
[深度剖析]
以下代码是根据GEMINI.md的意图自动生成的,它完美地融合了 Node.js 的子进程管理、Playwright 的浏览器操作和文件系统操作。开发者在整个流程中无需编写或维护这段代码。
// <auto-generated by AI agent based on GEMINI.md>
// 这段代码是 AI 工作的逻辑核心,由 Gemini CLI 在内存中生成并执行。import { test, expect } from '@playwright/test';
import { spawn, ChildProcess } from 'child_process';
import * as fs from 'fs';
import * as util from 'util';// promisify a few things for easier async/await usage
const sleep = util.promisify(setTimeout);// --- 步骤 1 & 2: 启动服务并等待 ---
console.log('步骤 1: 并发启动前后端服务...');
const backend: ChildProcess = spawn('npm', ['run', 'dev:server'], { stdio: 'pipe', detached: true });
const frontend: ChildProcess = spawn('npm', ['run', 'dev:client'], { stdio: 'pipe', detached: true });console.log('等待 5 秒以确保服务启动...');
await sleep(5000);// --- 步骤 2 & 3: Playwright 测试与网络验证 ---
// AI 智能地选择使用 Playwright 的 test runner 来组织测试逻辑
test.describe('AI Agent: Full-stack Interaction Test', () => {test('should correctly fetch /api/ping', async ({ page }) => {console.log('步骤 2: Playwright 启动并导航至页面...');// 创建一个数组来存储网络请求的详细信息// 这是 AI 为了完成 DevTools 抓包任务而设计的精妙实现const networkRequests: any[] = [];// 监听 'response' 事件,捕获所有响应的元数据page.on('response', async (response) => {try {const request = response.request();const body = await response.json();networkRequests.push({url: response.url(),status: response.status(),method: request.method(),body: body,});} catch (e) {// 忽略无法解析为 JSON 的响应}});await page.goto('http://localhost:5173');// AI 知道需要等待特定的网络请求完成,而不是使用硬编码的延时await page.waitForResponse(response => response.url().includes('/api/ping') && response.status() === 200);console.log('步骤 3: 验证网络请求...');const pingRequest = networkRequests.find(r => r.url.includes('/api/ping'));// 断言 1: 确保请求被找到了expect(pingRequest).toBeDefined();// 断言 2: 验证状态码expect(pingRequest.status).toBe(200);// 断言 3: 验证响应体expect(pingRequest.body).toEqual({ msg: 'pong' });console.log('所有断言通过!');// --- 步骤 4: 生成报告和截图 ---console.log('步骤 4: 生成测试产物...');await page.screenshot({ path: 'ping.png' });const report = {test: 'Full-stack Interaction Test',result: 'PASS',timestamp: new Date().toISOString(),validatedRequest: pingRequest,};fs.writeFileSync('test-report.json', JSON.stringify(report, null, 2));console.log('测试报告 test-report.json 和截图 ping.png 已生成。');});
});// --- 步骤 5: 清理工作 ---
// AI 生成了一个优雅的清理函数,确保无论测试成功与否都会执行
function cleanup() {console.log('步骤 5: 清理并关闭所有进程...');// 使用 process.kill 并传入负的 pid 来杀死整个进程组,确保子进程也被关闭if (backend.pid) process.kill(-backend.pid);if (frontend.pid) process.kill(-frontend.pid);console.log('清理完成。');
}// 运行 Playwright 测试,并在结束后调用清理函数
// 这是一个健壮的设计,确保资源得到释放
try {// 动态执行 Playwright 测试// ... (此处的具体 Playwright runner 调用逻辑由 CLI 环境注入)
} finally {cleanup();
}
对生成代码的亮点分析:
- 智能的工具选择与融合:AI 不仅是简单地调用 MCP,它还理解到这是一个“测试”场景,因此创造性地使用了 Playwright 的
testrunner 结构来组织代码,并利用了其内置的expect断言库。这是一个超越简单脚本生成的、更高级的规划能力体现。 - 健壮的进程管理:AI 选择了
spawn来创建子进程,并且在cleanup函数中使用了process.kill(-pid)的高级技巧来确保杀掉整个进程树,这是一个经验丰富的 Node.js 开发者才会使用的健壮实践。 - 高效的事件驱动编程:在处理网络请求时,AI 没有采用轮询或不稳定的延时,而是正确地使用了 Playwright 的事件监听机制(
page.on('response', ...)),这是最高效、最可靠的方式。 - 自解释的代码:生成的代码包含了清晰的日志输出,每一步都在控制台打印出它正在做什么,这极大地增强了可观测性。
这段代码的质量,已经达到了一个中高级工程师为该特定任务精心编写的水平。而我们的全部投入,仅仅是一份 Markdown 文档。这就是“意图驱动”的真正威力。
第六章:验收成果 —— 检查测试产物
当命令成功执行后,检查您的项目目录。ls -l 一下,您会发现多了两个新文件:
-
ping.png:- 这是一个浏览器页面的截图。打开它,您会看到我们的 React 应用的渲染界面。这在进行 UI 相关的测试时,提供了非常有价值的视觉证据,便于人工复核和归档。
(图片: 展示生成的 ping.png 截图内容)
- 这是一个浏览器页面的截图。打开它,您会看到我们的 React 应用的渲染界面。这在进行 UI 相关的测试时,提供了非常有价值的视觉证据,便于人工复核和归档。
-
test-report.json:- 这是一个结构化的数据文件,包含了测试的核心结果。它的内容大致如下:
{"test": "Full-stack Interaction Test","result": "PASS","timestamp": "2023-10-27T10:30:00.123Z","validatedRequest": {"url": "http://localhost:3001/api/ping","status": 200,"method": "GET","body": {"msg": "pong"}} }- 为什么这个 JSON 报告如此重要? 因为它是机器可读的。在自动化的世界里,这意味着它可以被其他工具轻松消费。CI/CD 系统可以读取这个文件,根据
result字段的值来判断流水线是该通过还是失败。您可以编写脚本将这些报告聚合起来,生成测试覆盖率仪表盘。这种结构化的输出,是实现更高级自动化(自动化之上的自动化)的基石。
至此,我们已经走完了一个完整的、端到端的 AI 代理自动化流程。从一个简单的想法,到一份自然语言的描述,再到一个全自动、可验证、有产出的测试任务,我们没有编写一行传统的测试脚本。这不仅仅是一次技术演示,它预示着一种全新的、更高效、更直观的软件开发与测试协作方式的到来。
第三部分:规模化与未来展望 —— 从本地到企业级 CI 的跃迁
我们已经证明,AI 编码代理在本地开发环境中表现出色。但一项技术若要真正产生革命性的影响,就必须能够无缝融入团队协作和企业级的自动化流程中。在这一部分,我们将探讨如何将这个强大的代理工作流从开发者的个人电脑,提升到云端,集成到像 GitHub Actions 这样的主流 CI/CD 平台中,并展望这项技术未来的广阔前景。
第一章:自动化“自动化” —— 与 GitHub Actions 的深度集成
目标是实现“无人值守”的自动化测试:每当有新的代码被推送到代码仓库时(例如 push 到主分支,或创建一个 pull_request),我们的 AI 代理都应该被自动唤醒,在云端的虚拟环境中完整地执行我们在 GEMINI.md 中定义的所有测试,并将结果报告出来。
这可以通过在项目中添加一个 GitHub Actions 的工作流(workflow)文件来实现。在您的项目根目录下,创建 .github/workflows/ai-interop-test.yml 目录和文件。
.github/workflows/ai-interop-test.yml 文件内容:
# 工作流名称
name: AI-Powered Full-Stack E2E Test# 触发条件:在 push 或 pull_request 事件时触发
on: [push, pull_request]# 定义工作任务
jobs:# 任务 IDai-driven-test:# 任务名称name: Execute AI Agent Test# 运行环境:使用最新的 Ubuntu 虚拟机runs-on: ubuntu-latest# 任务步骤steps:# 步骤 1: 检出代码# 拉取当前仓库的最新代码到虚拟机中- name: Checkout repositoryuses: actions/checkout@v4# 步骤 2: 设置 Node.js 环境# 安装 CI 环境所需的 Node.js 版本- name: Setup Node.jsuses: actions/setup-node@v4with:node-version: 20# 步骤 3: 安装和配置 AI 代理环境# 这部分复刻了我们在本地的 "步骤 0"- name: Install & Configure Gemini CLI and MCPsrun: |npm i -g @google/genai-cligemini mcp add -s user chrome-devtools npx chrome-devtools-mcp@latestgemini mcp add -s user playwright npx @playwright/mcp@latestecho "AI Agent environment configured."# 步骤 4: 安装项目依赖# 使用 npm ci 以获得更快、更可靠的安装- name: Install project dependenciesrun: npm ci# 步骤 5: 执行 AI 代理测试# 这是核心执行步骤,与本地命令稍有不同- name: Run AI Agent Test and Capture Reportrun: |gemini -F GEMINI.md \-p "按 GEMINI.md 执行前后端交互测试" \--output-format json > ai-test-summary.json# 步骤 6: 上传测试产物# 将 AI 生成的报告和截图作为构建产物保存,以便后续查看和分析- name: Upload test artifactsuses: actions/upload-artifact@v4with:name: ai-test-reportpath: |ai-test-summary.jsontest-report.jsonping.png
对这个 CI 工作流的深度解读:
- 标准化环境:前面的几个步骤 (
checkout,setup-node,npm ci) 都是标准 CI 操作,确保了每次测试都在一个干净、一致的环境中运行。 - CI 中的代理配置:我们在
run脚本中完全复制了本地安装和配置 Gemini CLI 及 MCPs 的命令。这证明了该工具链的良好可移植性。 - 核心命令的变体:注意
gemini命令的变化:- 我们去掉了
--stream参数。在非交互式的 CI 环境中,我们通常更关心最终的结果而非过程。 - 我们增加了
--output-format json参数。这是一个极其重要的特性。它告诉 Gemini CLI,在执行完所有任务后,不要只打印人类可读的日志,而是将整个执行过程的摘要——包括 AI 的思考、生成的代码、执行的输出和最终结果——打包成一个单一的、结构化的 JSON 对象,并打印到标准输出(stdout)。 > ai-test-summary.json: 我们通过重定向>将这个巨大的 JSON 输出保存到文件中。这个文件是 AI 执行全过程的“黑匣子”记录,对于事后调试和审计至关重要。
- 我们去掉了
- 产物归档 (Artifacts):
actions/upload-artifact步骤是 CI 流程的收尾工作。它将 AI 生成的所有重要文件(过程摘要、测试报告、截图)都打包上传。当流水线运行结束后,任何团队成员都可以从 GitHub 的运行记录页面下载这个ai-test-report.zip包,进行详细的分析。
现在,只要您将这个 .yml 文件提交到您的代码仓库,GitHub Actions 就会自动开始工作。您将在 Pull Request 页面看到一个检查项,实时显示 AI 代理的运行状态。如果测试失败,该检查项会变红,阻止有问题的代码被合并。
通过这种方式,我们真正实现了自动化的闭环。开发者的工作流程被简化为:修改代码 -> 撰写/更新 GEMINI.md -> 提交代码。剩下的所有繁琐的测试、验证、报告工作,都交由在云端待命的 AI 编码代理 7x24 小时地忠实执行。
第二章:超越测试 —— AI 代理的无限可能
我们本文聚焦于 E2E 测试,但这仅仅是 AI 编码代理能力的冰山一角。请记住,这个工作流的核心是 “自然语言意图 -> 工具使用 -> 任务完成”。只要我们能为 AI 提供合适的 MCP 工具,它就能在软件工程的几乎任何领域发挥作用:
- 自动化代码重构:想象一下,提供一个
prettier-mcp或eslint-mcp,然后用自然语言下达指令:“请对项目/src目录下所有的.ts文件执行格式化,并自动修复所有可修复的 lint 错误。” - 云资源管理 (IaC as Natural Language):通过为
terraform或pulumi编写 MCP,DevOps 工程师可以用自然语言来管理基础设施:“请在我们的 GCP 项目中,创建一个新的 GKE 集群,配置 3 个 n2-standard-4 节点,并开启自动伸缩。” - 数据库迁移与操作:提供一个
prisma-mcp或drizzle-mcp,开发者可以直接说:“请为User模型增加一个lastLogin字段,类型为DateTime,并生成相应的数据库迁移文件,然后在新环境中应用这个迁移。” - 项目脚手架与代码生成:未来的
create-react-app可能不再需要复杂的交互式问答,你只需说:“创建一个新的 React 项目,使用 TypeScript,集成 TailwindCSS 和 Zustand 进行状态管理,并帮我生成一个包含头部、侧边栏和内容区域的基本布局组件。”
这个列表可以无限延伸。关键的范式转变在于:MCP 架构将整个软件世界 API 化、工具化,使其成为大型语言模型可以操作的“外设”。任何可以通过命令行或 API 控制的工具,都有潜力被封装成 MCP,从而纳入到 AI 代理的工具箱中。
第三章:结语 —— 拥抱全新的开发者-AI 协作共生关系
我们正处在一个激动人心的技术拐点。以 Gemini CLI 和 MCP 架构为代表的 AI 编码代理技术,正在从根本上重塑开发者与计算机的交互方式。
它不是要替代开发者,而是要将开发者从繁琐、重复、低价值的“指令式”工作中解放出来,让我们能够更专注于软件工程中最核心、最具创造力的部分:业务逻辑的梳理、系统架构的设计、用户体验的创新。
我们正在从一个“编码者”(Coder)的角色,逐渐演变为一个“指挥家”(Conductor)或“架构师”(Architect)的角色。我们的主要工作,将是把复杂的业务需求,清晰、准确地翻译成 AI 代理可以理解的“任务简报”,然后监督和引导 AI 去完成具体的实现。
本文所展示的全栈测试自动化流水线,仅仅是这场宏大变革中的一个序章。它所揭示的“意图驱动”哲学,将深刻地影响未来软件开发的全生命周期。
现在,是时候开始思考:在您的日常工作中,哪些环节最符合“E2E 测试税”的描述?哪些任务最适合被定义成一份 GEMINI.md?
不要犹豫,立即动手尝试吧。安装 CLI,添加 MCP,编写您的第一份 AI 任务简报。因为未来,已经到来,它就从您在终端里敲下 gemini 命令的那一刻开始。