Chainlit+LlamaIndex 多模态 RAG 开发实战8:Text2SQL 技术解析与工作流驱动的数据库 RAG 全流程实现
经常会有这种情况的发生...
- 产品经理甩来一句 “查下近 3 个月各部门销售额”,你盯着数据库半天,忘了 JOIN 表的语法;
- 写了个复杂 RAG 流程,结果步骤混乱得像一团毛线,改一个地方全流程报错;
- 非技术同事想查学生成绩,你得帮他写 SQL,一天下来光 “翻译” 需求就累到想摸鱼……
别慌!今天咱们用 LlamaIndex —— 把 Text2SQL(自然语言转 SQL)和工作流结合,搭一个 “会懂人话、能管流程” 的数据库 RAG 系统。从技术解析到落地实战,全程带吐槽、避坑指南,保证你看完能上手,再也不用跟 SQL 和复杂流程死磕!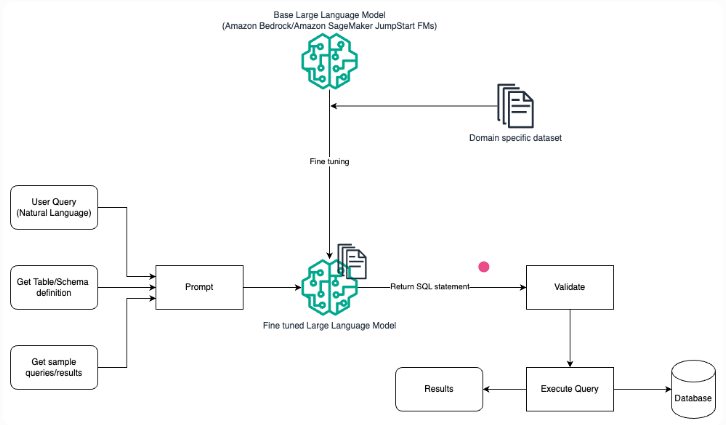
一、先唠明白:Text2SQL 到底是啥 “神仙技术”?
简单说,Text2SQL 就是 “把人话翻译成 SQL” 的工具。比如用户说 “获取所有学生的基本信息”,它能自动生成SELECT id, stu_name, major FROM student;—— 不用你记 SQL 语法,不用查字段名,简直是 “SQL 小白救星”。
1.1 Text2SQL 的 “四大超能力”(核心功能)
别觉得它玄乎,其实就是四步走,跟 “点外卖” 一样简单:
核心功能
- 自然语言理解(NLU):用NLP解析你的话——分词、实体识别。目标:抓意图,如“获取”=SELECT,“筛选”=WHERE。
- 语义解析:匹配表/列名,处理JOIN、GROUP BY。复杂时像解谜。
- SQL 生成:从简单SELECT到嵌套查询,全支持。
- 查询执行与结果返回:跑SQL,格式化输出。用户零SQL知识,就能get结果。
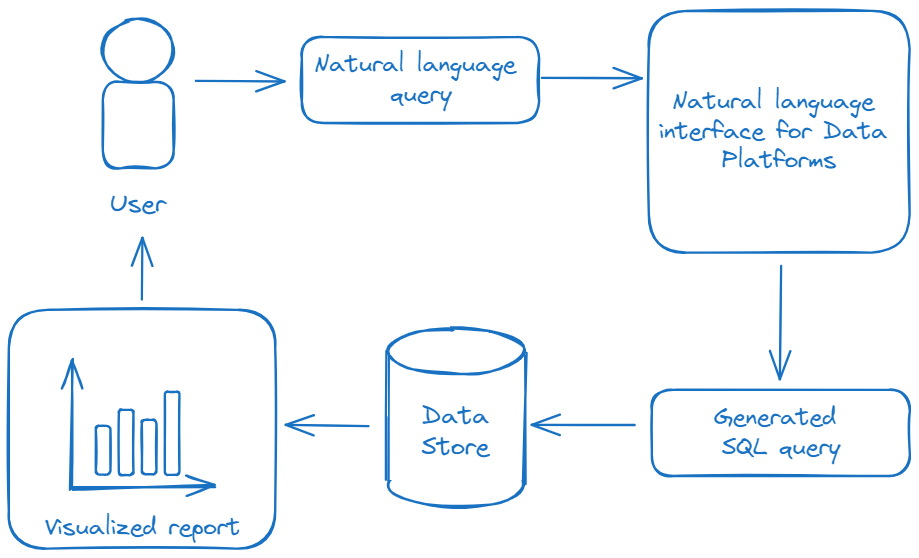
- 自然语言理解(NLU):相当于 “猜你想吃啥”比如用户说 “高成绩学生”,系统得先搞懂 “高成绩” 是 “≥90 分” 还是 “前 10%”,这一步靠 NLP 技术(分词、词性标注这些),避免理解偏差。
- 语义解析:相当于 “找对应餐厅和菜品”系统要从数据库里找 “学生表”“成绩表”,对应 “姓名”“成绩” 字段,还要搞懂 “JOIN”(比如学生表和成绩表通过学号关联),不然就会查错数据。
- SQL 生成:相当于 “写订单备注”把理解到的需求写成正确的 SQL,简单的比如
SELECT单表,复杂的比如多表 JOIN、嵌套查询。举个例子,“查 2020 年入学的计算机专业学生”,会生成:SELECT stu_name, age FROM student WHERE major='计算机科学' AND enrollment_year='2020-09-01'; - 结果返回:相当于 “外卖送到家,还帮你拆盒”执行 SQL 后,把结果转成自然语言,比如 “2020 年入学的计算机专业学生有张三、刘十一,共 2 人”,不用用户自己看数据表。
1.2 这些场景用它,效率直接翻倍(应用场景)
Text2SQL 不是 “花架子”,实实在在能解决问题:
- 商业智能(BI):非技术同事不用再找你写 SQL,自己输 “Q3 各部门销售额” 就能出报表,你再也不用当 “SQL 工具人”;
- 客户支持:客服输 “用户张三最近 3 笔订单”,秒查结果,不用翻后台找半天;
- 数据探索:你自己查数据也快,比如 “2022 年入学学生的专业分布”,输完就出结果,不用回忆字段名;
- 教育领域:老师查 “计算机专业学生平均成绩”,不用懂 SQL,直接得结果。
1.3 别高兴太早,这些坑得避开(技术挑战)
Text2SQL 也不是万能的,有三个 “老大难” 问题:
- 自然语言歧义:比如 “高成绩学生”,用户没说清是多少分,系统可能猜错;
- 数据库模式理解:如果数据库里 “学号” 叫
student_id,系统得知道 “学号” 对应这个字段,不然会查错; - 复杂查询处理:多表嵌套、聚合计算(比如
COUNT+GROUP BY),容易生成语法错误的 SQL,得靠好的提示模板和 LLM 来解决。
二、实战:用学生数据库玩转 Text2SQL
光说不练假把式,咱们用 “学生信息数据库” 举例子,从建表到查数据,一步一步来,复制粘贴就能用!
2.1 先搭个学生数据库(表结构 + 测试数据)
首先建个student表,存学生的基本信息,SQL 直接给你:
CREATE TABLE student (id INT AUTO_INCREMENT PRIMARY KEY, -- 自增主键,不用手动填stu_name VARCHAR(30) NOT NULL, -- 学生姓名,不能为空major VARCHAR(10) NOT NULL, -- 专业,比如“计算机科学”enrollment_year DATE NOT NULL, -- 入学年份,格式YYYY-MM-DDage INT NOT NULL -- 年龄
);
然后插 10 条测试数据,覆盖不同专业、入学年份,不用自己编:
INSERT INTO student (stu_name, major, enrollment_year, age) VALUES
('张三', '计算机科学', '2020-09-01', 20),
('孙七', '人工智能', '2022-09-01', 18),
('王五', '数据科学', '2021-09-01', 19),
('赵六', '网络安全', '2020-09-01', 20),
('李四', '软件工程', '2019-09-01', 21),
('周八', '信息系统', '2018-09-01', 22),
('吴九', '计算机工程', '2021-09-01', 19),
('郑十', '信息技术', '2019-09-01', 21),
('刘十一', '软件工程', '2020-09-01', 20),
('陈十二', '数据科学', '2022-09-01', 18);
避坑点:MySQL 日期格式别写错(必须是YYYY-MM-DD),不然数据插不进去,还得回头查半天。
2.2 写代码:让 LlamaIndex 帮你 “说人话查数据”
接下来写DatabaseRAG_Example.py,核心是用 LlamaIndex 的NLSQLTableQueryEngine,把自然语言转成 SQL。代码步骤清晰,我帮你拆成 “5 步走”:
步骤 1:导入依赖(“把要用的工具备好”)
from llama_index.core import SQLDatabase, Settings
from sqlalchemy import create_engine # 数据库连接引擎
from llama_index.core.indices.struct_store import NLSQLTableQueryEngine
from llms import deepseek_llm # 自己写的LLM配置,用DeepSeek
from embeddings import embed_model_local_bge_small # 本地嵌入模型
解释:这些依赖就像 “做饭的锅碗瓢盆”,SQLDatabase 管数据库操作,create_engine 连 MySQL,NLSQLTableQueryEngine 是 “自然语言转 SQL 的核心”。
步骤 2:配置初始化(“调好比武场”)
# 设置嵌入模型:用本地BGE小模型,不用联网,速度快
Settings.embed_model = embed_model_local_bge_small()
# 连接MySQL:格式是“数据库类型+驱动://用户名:密码@地址:端口/数据库名”
engine = create_engine("mysql+pymysql://root:root123@localhost:3306/student_db")
避坑点:
- 密码和端口别写错!比如你 MySQL 密码是
123456,别写成root123,不然会报 “访问被拒绝”; - 数据库名
student_db要提前建好,不然连接失败。
步骤 3:封装数据库(“把数据库装成好用的样子”)
sql_database = SQLDatabase(engine) # 封装数据库连接
# 打印可用表和表结构,确认连接成功
print("可用表:", sql_database.get_usable_table_names())
print("学生表结构:", sql_database.get_single_table_info("student"))
效果:运行后会显示可用表:['student']和学生表的字段信息,确认数据库连对了。
步骤 4:创建查询引擎(“造一个‘翻译官’”)
sql_query_engine = NLSQLTableQueryEngine(sql_database=sql_database, # 传数据库对象llm=deepseek_llm(), # 传LLM实例,负责“翻译”自然语言verbose=True # 打印详细日志,方便查错
)
解释:这个引擎就是 “核心翻译官”,接收自然语言,输出 SQL 并执行。
步骤 5:执行查询(“让翻译官干活”)
# 自然语言查询:“获取所有学生的基本信息”
response = sql_query_engine.query("获取所有学生的基本信息")
print("查询结果:", response)
2.3 运行结果:“看,说人话真的能查数据!”
运行代码后,会先打印生成的 SQL:SELECT id, stu_name, major, enrollment_year, age FROM student ORDER BY enrollment_year DESC;然后输出格式化结果:
查询结果:
1. 张三,学号:1,专业:计算机科学,入学年份:2020,年龄:20岁
2. 赵六,学号:4,专业:网络安全,入学年份:2020,年龄:20岁
...(后面还有8条,不一一列了)
成就感拉满:不用写一行 SQL,输句话就拿到结果,非技术同事也能上手!
三、工作流:给复杂流程 “装个导航”
搞定了 Text2SQL,你可能会遇到新问题:如果流程复杂,比如 “查数据前先判断查询质量→质量差就优化→质量好再查”,用普通代码写会像 “绕毛线”,改一点全乱了。这时候就需要 “工作流(Workflow)” 来救场。
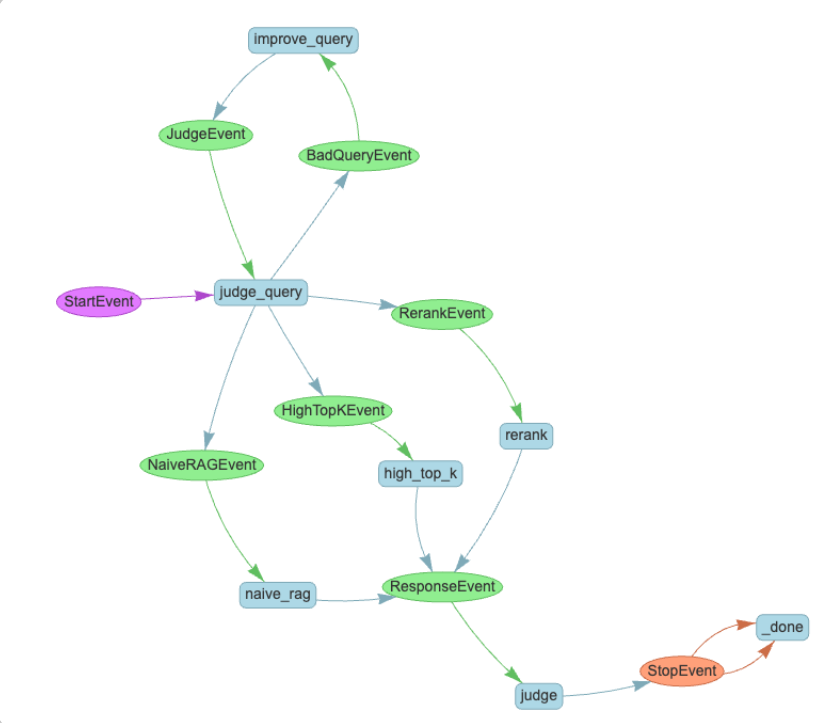
3.1 工作流是啥?用 “快递流程” 给你讲明白
工作流就是 “事件驱动、步骤化的流程管控”,简单说:
- 事件(Event):触发流程的 “信号”,比如快递的 “下单成功”“快递发货”“用户签收”;
- 步骤(Step):事件触发的 “具体操作”,比如 “下单成功” 触发 “仓库拣货”,“快递发货” 触发 “运输配送”。
举个查询优化的例子,工作流是这样的:
StartEvent(用户发起查询)→触发judge_query(判断查询质量);- 如果查询质量差→
BadQueryEvent→触发improve_query(优化查询)→JudgeEvent(再判断),循环到质量达标; - 如果质量好→同时触发
NaiveRAGEvent/HighTopKEvent/RerankEvent(三种 RAG 策略并行跑); - 所有策略返回结果→
judge_response(选最佳结果)→StopEvent(返回给用户)。
对比 DAG:DAG 写循环像 “绕毛线”,工作流用事件触发,循环逻辑清晰得像 “导航指路”,谁用谁知道!
3.2 为啥选工作流?DAG 的 “痛” 它都能治
之前用 DAG 做复杂流程,我踩过不少坑:
- 循环逻辑难写:DAG 的循环要编码到 “图的边缘”,看代码像 “找迷宫出口”;
- 数据传递麻烦:节点间传参数,可选值和默认值处理得写一堆代码;
- 不直观:复杂流程的 DAG 图,画出来像 “蜘蛛网”,新人看半天看不懂。
工作流刚好解决这些问题:
- 循环靠事件触发:比如 “优化查询→再判断”,用
BadQueryEvent和JudgeEvent就能实现,不用绕弯; - 数据传递简单:事件里直接带参数(比如
TableRetrieveEvent带查询和表信息),不用额外处理; - 符合 Python 思维:步骤用
@step装饰器,像写普通函数一样,不用学新语法。
3.3 小试牛刀:写个简单工作流
安装依赖:pip install llama-index-utils-workflow,然后写workflow_example.py,实现 “三步走” 流程:
StartEvent→step_one(输出 “第一步完成”);FirstEvent→step_two(输出第一步结果和年龄);SecondEvent→step_three(输出 “第二步完成”,结束流程)。
核心代码:
from llama_index.core.workflow import Workflow, step, StartEvent, Event, StopEvent
import asyncio# 自定义事件:带参数
class FirstEvent(Event):first_output: strage: intclass SecondEvent(Event):second_output: str# 工作流类
class MyWorkflow(Workflow):@step # 第一步:接收StartEvent,返回FirstEventasync def step_one(self, ev: StartEvent) -> FirstEvent:print(ev.query) # 打印用户查询return FirstEvent(first_output="第一步完成", age=30)@step # 第二步:接收FirstEvent,返回SecondEventasync def step_two(self, ev: FirstEvent) -> SecondEvent:print(ev.first_output, ev.age) # 打印第一步结果return SecondEvent(second_output="第二步完成")@step # 第三步:接收SecondEvent,返回StopEventasync def step_three(self, ev: SecondEvent) -> StopEvent:print(ev.second_output)return StopEvent(result="工作流结束!")# 运行工作流
async def main():w = MyWorkflow(timeout=10)result = await w.run(query="启动工作流")print(result)if __name__ == "__main__":asyncio.run(main())
运行效果:
启动工作流
第一步完成 30
第二步完成
工作流结束!
还能生成可视化 HTML 图:draw_all_possible_flows(MyWorkflow, filename="basic_workflow.html"),打开就能看到流程走向,一目了然。
四、终极落地:Text2SQL + 工作流,搭数据库 RAG
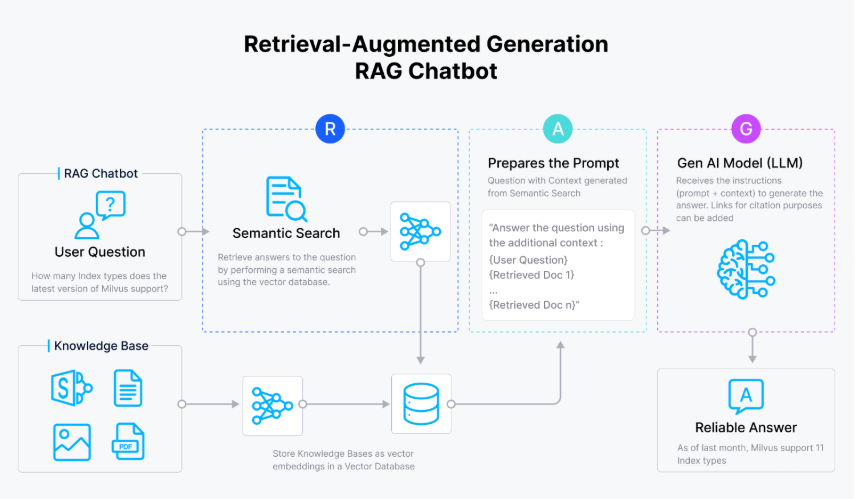
现在把 Text2SQL 和工作流结合,搭一个 “能管流程、会查数据” 的数据库 RAG 系统。核心是三个模块:text_to_sql_workflow.py(工作流核心)、database_rag.py(数据库接口)、prompts.py(LLM 提示模板)。
4.1 核心模块:各司其职,分工明确
模块 1:text_to_sql_workflow.py(“总指挥”)
这个文件是工作流的核心,负责 “接收查询→查 table 信息→生成 SQL→执行→返回结果”。关键步骤有三个:
retrieve_tables:从 Milvus 向量库查相关表结构(比如用户查 “学生成绩”,就查student和scores表);generate_sql:用TEXT_TO_SQL_PROMPT提示 LLM,生成 SQL;generate_response:执行 SQL,把结果转成自然语言返回。
核心代码片段(retrieve_tables步骤):
@step
async def retrieve_tables(self, ctx: Context, ev: StartEvent) -> TableRetrieveEvent:# 加载Milvus里的数据库索引index = await self.load_index(collection_name="database")# 检索前20个最相关的表结构retriever = index.as_retriever(similarity_top_k=20)table_schema_objs = retriever.retrieve(ev.query)# 把表结构拼成字符串,给LLM看table_content_str = "\n\n".join([node.text for node in table_schema_objs])return TableRetrieveEvent(query=ev.query, table_content_str=table_content_str)
解释:这一步是 “告诉 LLM 数据库里有啥表、啥字段”,不然 LLM 会瞎生成不存在的表名。
模块 2:database_rag.py(“数据库接口”)
负责连接数据库、加载表结构、创建索引。比如load_data方法获取所有表的结构,create_index方法把表结构存到 Milvus。
核心代码(load_data):
async def load_data(self):tables = self.sql_database.get_usable_table_names() # 拿所有表名table_schema_objs = []for table in tables:# 拿单个表结构table_info = self.sql_database.get_single_table_info(table)# 提取表描述(没有就用表名当描述)table_desc = re.search(r"with comment: \((.*?)\)", table_info).group(1) if re.search(...) else f"{table}表"# 生成表结构对象table_schema_objs.append(SQLTableSchema(table_name=table, context_str=table_desc))return table_schema_objs
模块 3:prompts.py(“给 LLM 的‘说明书’”)
提示模板是 Text2SQL 的 “灵魂”,直接影响生成 SQL 的正确性。比如TEXT_TO_SQL_PROMPT要强调 “只查需要的列”“用存在的表 / 列”:
from llama_index.core import PromptTemplate__TEXT_TO_SQL_PROMPT_STRING = """
给定问题,生成语法正确的MySQL查询,注意:
1. 只查问题需要的列,别查所有列;
2. 只用下面的表:{table_context_str};
3. 列名要用表名限定(比如student.stu_name),避免歧义;
4. 格式:
Question: {query}
SQLQuery:
"""
# 创建提示模板,指定方言为MySQL
TEXT_TO_SQL_PROMPT = PromptTemplate(__TEXT_TO_SQL_PROMPT_STRING).partial_format(dialect="mysql")
解释:LLM 很 “听话”,但你得把规则说清楚,不然它可能查SELECT *(效率低),或者用不存在的列名(报错)。
4.2 配置文件:安全又方便
.env 文件(“藏秘密的地方”)
别把数据库密码、LLM 密钥硬编码到代码里,用.env文件存:
# 数据库连接(替换成你的配置)
DB_CONNECTION_STRING="mysql+pymysql://root:root123@localhost:3306/student_db"
# Milvus地址(本地测试用这个)
MILVUS_URI="http://127.0.0.1:19530"
# DeepSeek API密钥
DEEPSEEK_API_KEY="sk-xxxxxxxxxxxxxxxx"
rag/config.py(“统一管理配置”)
用单例模式加载.env 文件的配置,全系统共用:
from pydantic import BaseModel, Field
import os
from dotenv import load_dotenvload_dotenv() # 加载.env文件class RagConfig(BaseModel):# 数据库连接字符串db_connection_string: str = Field(default=os.getenv("DB_CONNECTION_STRING"), description="数据库连接")# 其他配置...# 单例实例,全系统只用这一个
rag_config = RagConfig()
好处:改配置不用改代码,直接改.env 文件,比如换数据库地址,改一行就行。
4.3 界面集成:用 Chainlit 让用户 “点一点就查数据”
最后在chainlit_ui.py里加 “数据库 RAG” 选项,用户在界面上选 “数据库 RAG”,输入自然语言就能查数据:
@cl.on_message
async def main(message: cl.Message):settings = cl.user_session.get("settings")if settings.get("rag_model") == "数据库RAG":# 实例化工作流workflow = TextToSQLWorkflow()# 运行工作流,处理用户查询result = await workflow.run(query=message.content)# 显示生成的SQL(代码块形式)await cl.Message(content=f"生成的SQL:\n```sql\n{result.get('sql')}\n```", author="Assistant").send()# 流式输出结果response_gen = Settings.llm.stream_chat(result.get("message"))msg = cl.Message(content="", author="Assistant")for token in response_gen:await msg.stream_token(token.delta)await msg.send()return# 其他RAG逻辑...
效果:用户在界面上输 “查成绩前 3 名的学生”,系统会先显示 SQL,再流式输出结果,体验超棒!
五、测试 & 避坑:遇到问题不用慌
5.1 测试案例:查 “成绩前 3 名的学生”
自然语言查询:“打印成绩前 3 名的学生信息及成绩单”生成的 SQL(多表 JOIN,按成绩降序):
SELECT students.student_id, students.student_name, students.major,scores.course_id, scores.score, scores.semester
FROM scores
JOIN students ON scores.student_id = students.student_id
ORDER BY scores.score DESC
LIMIT 3;
查询结果:
- 王五(学生 ID3,专业物理学,成绩 92,课程 ID3,2020 年秋季);
- 张三(学生 ID1,专业计算机科学,成绩 90,课程 ID1,2020 年秋季);
- 李四(学生 ID2,专业计算机科学,成绩 90,课程 ID2,2022 年春季)。
完美:SQL 正确,结果准确,不用手动写 JOIN 逻辑!
5.2 常见报错解决:踩过的坑我替你填了
报错 1:RuntimeError: 'cryptography' package is required
原因:MySQL 8.0 + 默认用caching_sha2_password认证,需要cryptography包加密;解决:pip install cryptography,一行命令搞定。
报错 2:“表不存在”
原因:Milvus 里没存表结构,或者retrieve_tables步骤没查到;解决:先运行database_rag.py的create_index方法,把表结构存到 Milvus。
报错 3:SQL 语法错误
原因:提示模板没写清楚表名 / 列名,LLM 瞎猜;解决:在TEXT_TO_SQL_PROMPT里明确 “只用 {table_context_str} 里的表和列”,再重新运行。
六、总结:半天就能搭起来的 “数据库查询神器”
其实 Text2SQL + 工作流没那么复杂,核心就是:
- Text2SQL 负责 “把人话转成 SQL”,解决 “不会 SQL 的痛”;
- 工作流负责 “管控复杂流程”,解决 “步骤混乱的痛”;
- 用 LlamaIndex 搭模块,用 Milvus 存表结构,用 Chainlit 做界面,半天就能跑通全流程。