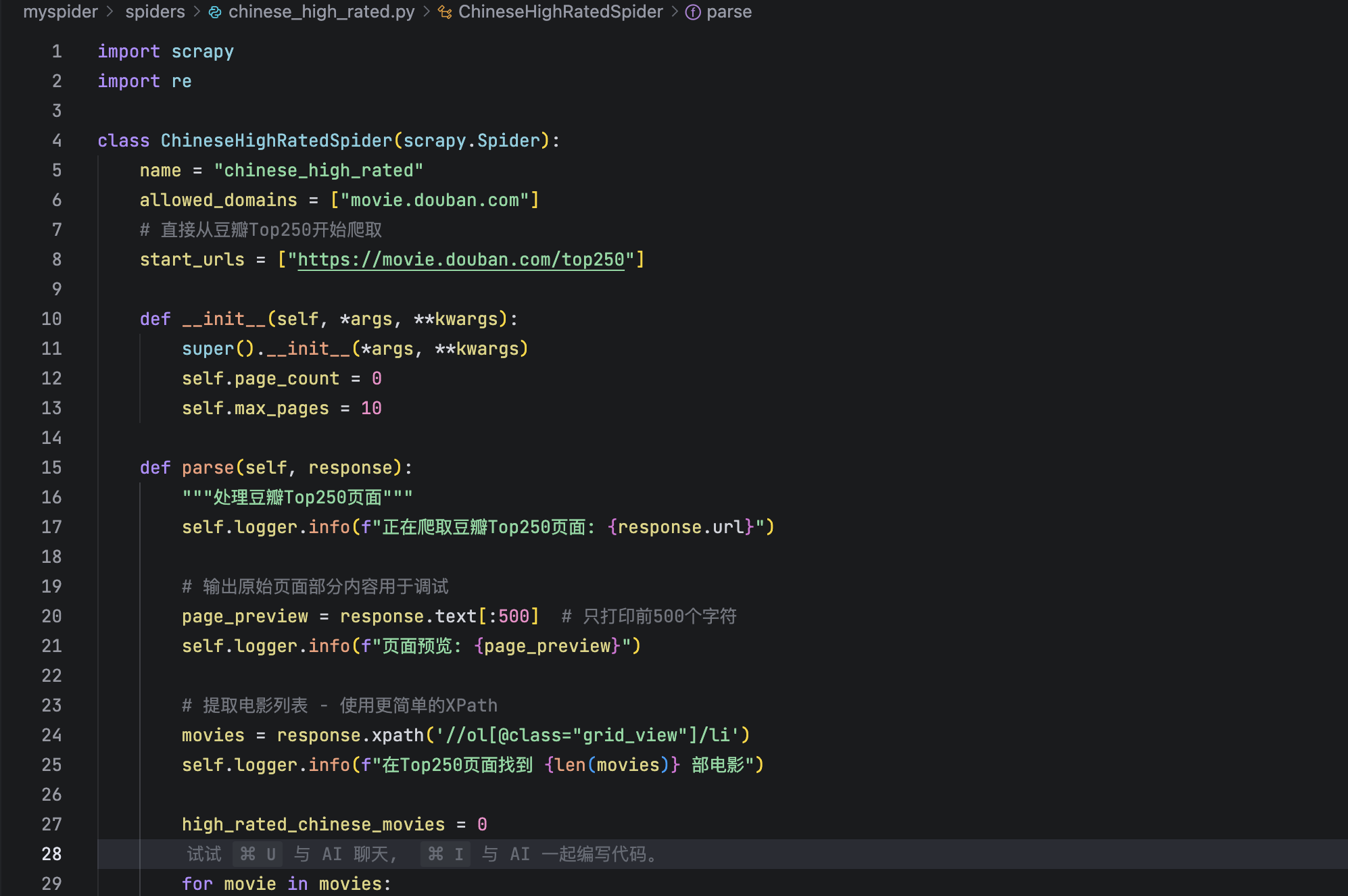
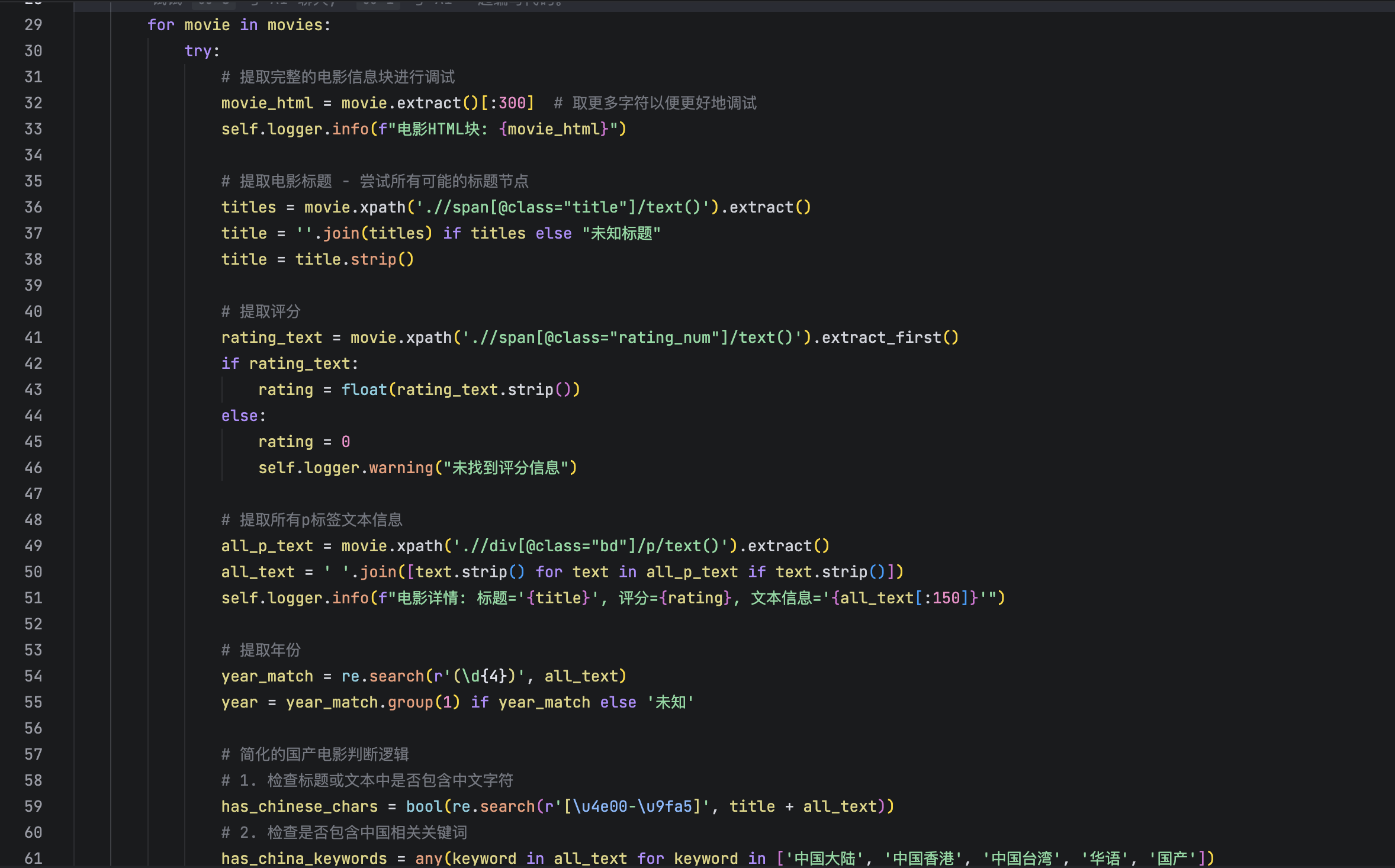
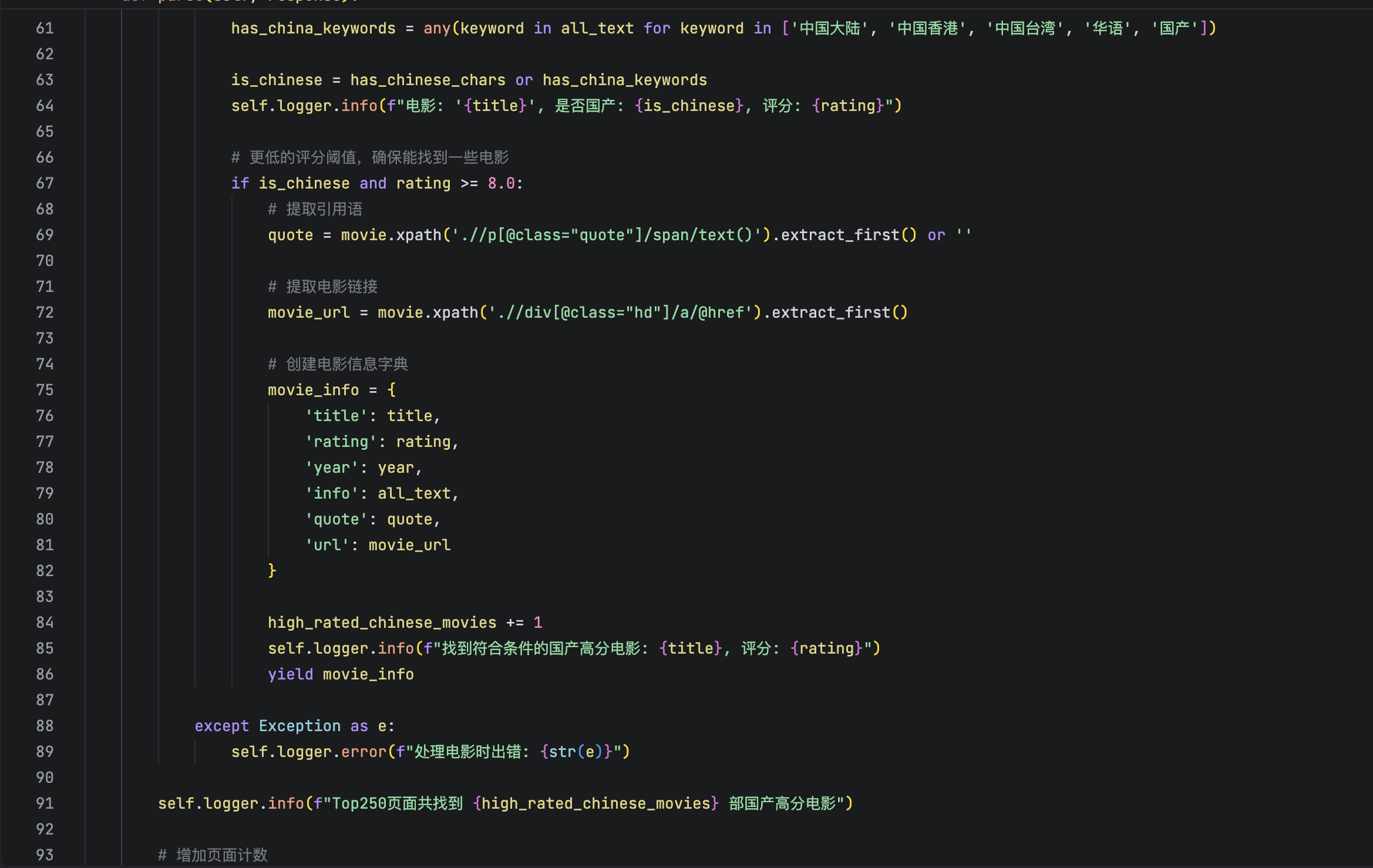
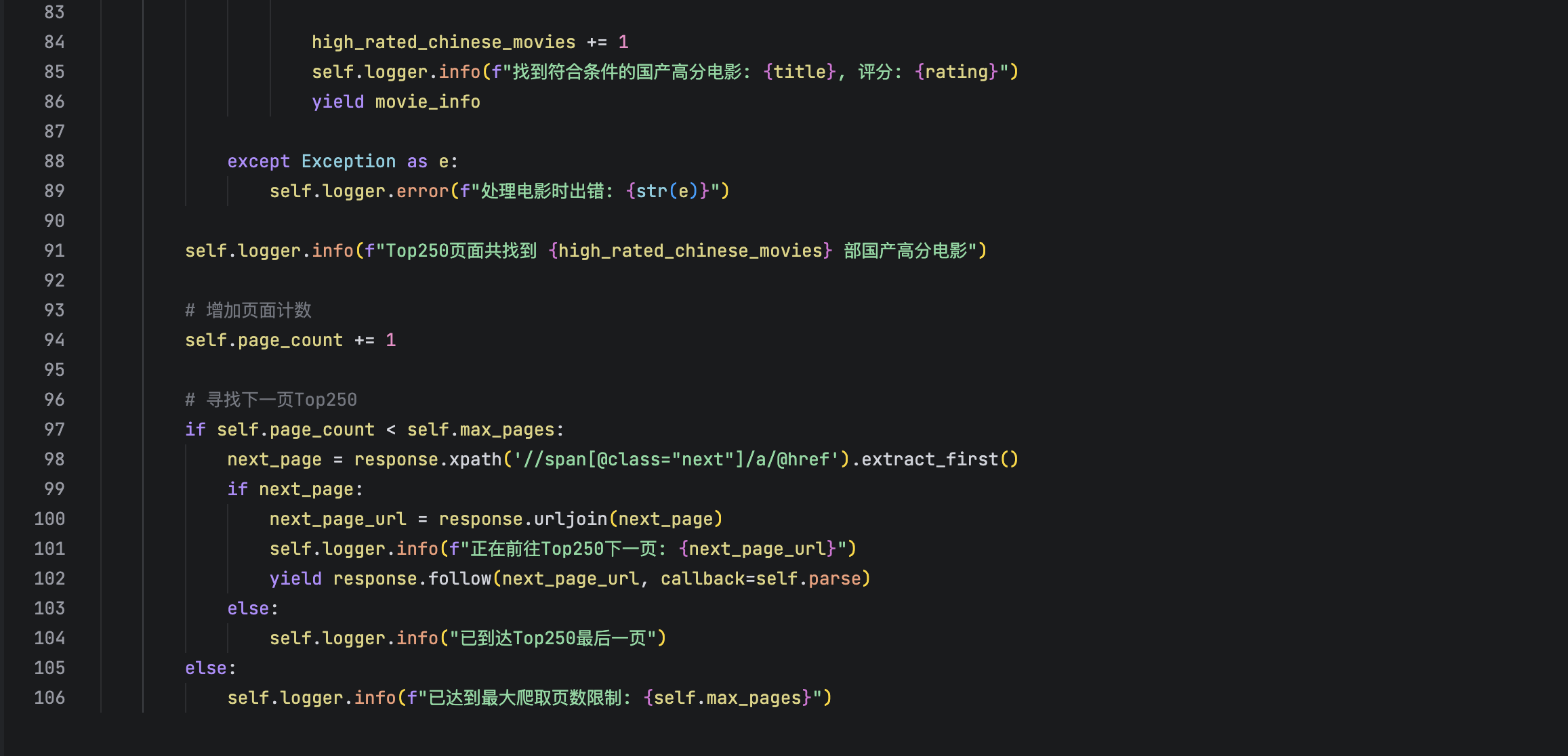
当前位置: 首页 > news >正文 scrapy爬取豆瓣电影 news 2025/10/22 8:48:53 在李玺老师《爬虫逆向进阶实战》中了解到scrapy后,本意是打算利用b站上更详细的教程爬取一下豆瓣网站国产高分电影的列表。 但是最后爬取出来的结果并没有成功分出国产这一栏目 在ai帮我调试了好几次也没有做好 查看全文 http://www.dtcms.com/a/511652.html 相关文章: bisheng 的 MCP服务器添加 或 系统集成 一个完整的 TCP 服务器监听示例(C#) 执行操作后元素的最高频率1 2(LeetCode 3346 3347) Java 大视界 -- Java 大数据在智慧交通停车场智能管理与车位预测中的应用实践 版本设计网站100个关键词 网站前置审批工程建设服务平台 共聚焦显微镜(LSCM)的针孔效应 STM32CubeMX 网站实现搜索功能四川建设安全协会网站 spark组件-spark core(批处理)-rdd特性-内存计算 算法练习:双指针专题 关于comfyui的triton安装(xformers的需求) 爬虫+Redis:如何实现分布式去重与任务队列? 烘焙食品网站建设需求分析wordpress生成静态地图 区块链——Solidity编程 OpenSSH安全升级全指南:从编译安装到中文显示异常完美解决 数据结构的演化:从线性存储到语义关联的未来 爱博精电AcuSys 电力监控系统赋能山东有研艾斯,铸就12英寸大硅片智能配电新标杆 基于AI与云计算的PDF操作工具开发技术探索 LeetCode 404:左叶子之和(Sum of Left Leaves) 中小企业网站建设论文高端制作网站技术 电子报 网站开发平面设计培训机构排行 无人系统搭载毫米波雷达的距离测算与策略执行详解 Adobe Acrobat软件优化配置,启用字体平滑和默认单页连续滚动 测试题-3 win10 win11搜索框空白解决方案 Linux系统:多线程编程中的数据不一致问题与线程互斥理论 遇到oom怎么处理? jenkins流水线项目部署 网口学习理解
在李玺老师《爬虫逆向进阶实战》中了解到scrapy后,本意是打算利用b站上更详细的教程爬取一下豆瓣网站国产高分电影的列表。 但是最后爬取出来的结果并没有成功分出国产这一栏目 在ai帮我调试了好几次也没有做好