CoRL-2025 | VLM赋能高阶推理导航!ReasonNav:在人类世界中实现与人类一致的导航

- 作者:Bhargav Chandaka, Gloria X. Wang, Haozhe Chen, Henry Che, Albert J. Zhai, Shenlong Wang
- 单位:伊利诺伊大学厄巴纳-香槟分校
- 论文标题:Human-like Navigation in a World Built for Humans
- 论文链接:https://arxiv.org/pdf/2509.21189v1
- 项目主页:https://reasonnav.github.io/
- 代码链接:https://github.com/ReasonNav/ReasonNav
主要贡献

- 提出模块化的导航系统ReasonNav,通过利用视觉语言模型的推理能力,将人类在人造环境中导航时的行为(如阅读标识、询问他人方向等)整合到机器人导航中,使机器人能够更高效地在大型复杂建筑中导航。
- 设计了基于导航地标的紧凑输入和输出抽象,让VLM能够专注于语言理解和推理,从而更好地利用周围环境中的知识资源来提高导航效率。
- 在真实和模拟的导航任务中对ReasonNav进行了评估,结果表明该系统能够成功运用高阶推理来高效导航,并且与不包含这些高阶导航技能的系统相比,性能有显著提升,为实现类似人类的导航效率提供了一种有前景的方法。
研究背景
- 人类在人造环境中导航时,会借助标识、询问他人等行为来高效地到达目的地,而现有的机器人导航系统缺乏这些能力,导致在大型环境中导航效率低下,需要花费大量时间进行探索。
- 随着大型视觉语言模型(VLM)的发展,其在语言理解和推理方面表现出色,为将人类的高阶导航技能整合到机器人导航系统中提供了可能。这些技能包括阅读标识、询问方向等,对于在大型环境中导航尤为重要。
方法
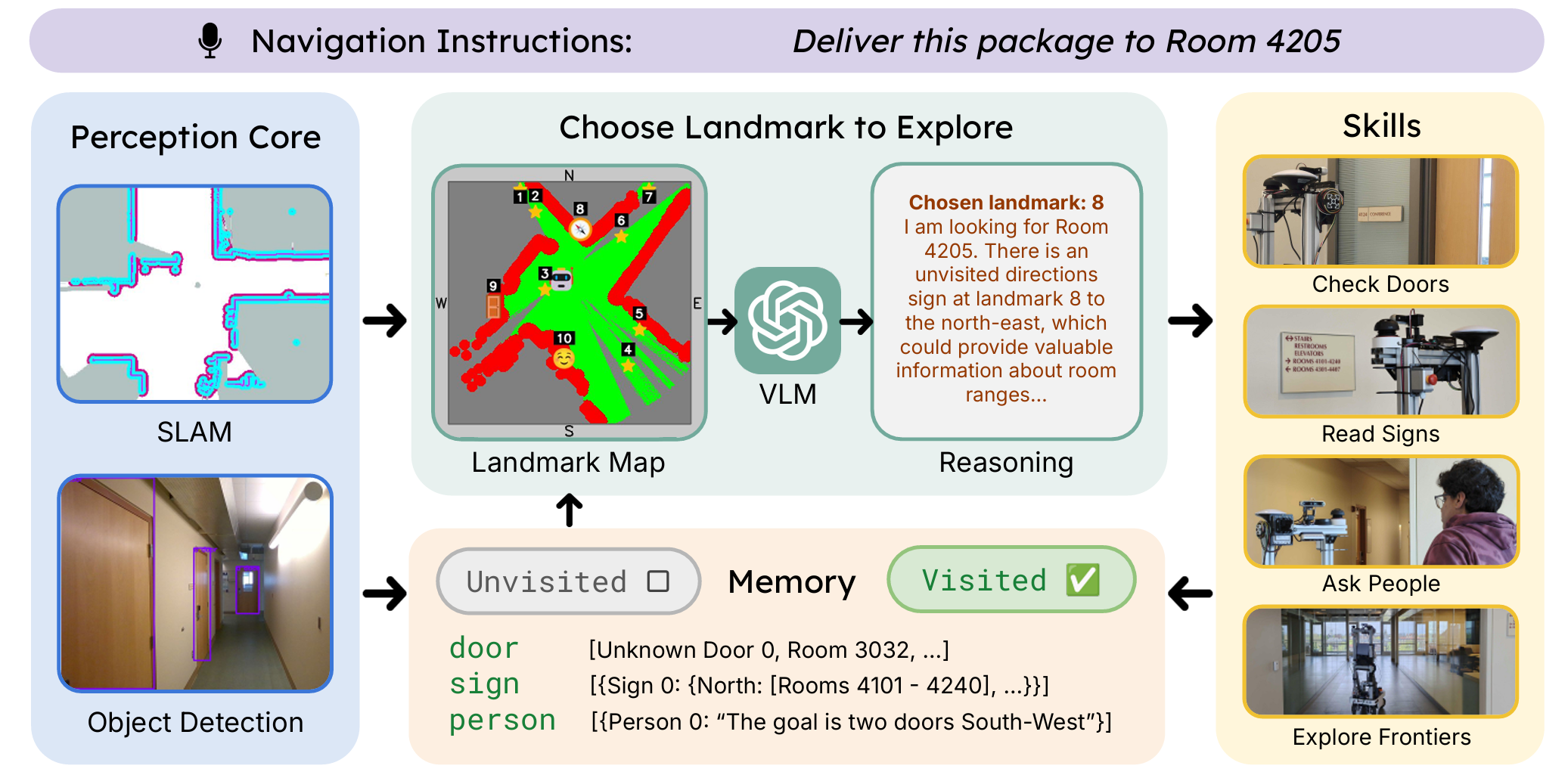
VLM观测和动作抽象
核心思想
- ReasonNav通过利用VLM在智能体框架中整合类似人类的导航行为,从而显著提高导航效率。
- VLM在语言理解和常识推理方面表现出色,但在理解和处理复杂的时空数据以及直接产生精确数值输出方面存在困难。
- 因此,需要精心设计VLM的输入(观测)和输出(动作)的抽象,以便有效地利用其推理能力。
地标的定义与作用
- 本方法的抽象设计以地标为中心,地标是指在导航任务中特别重要的显著物体。具体来说,地标包括三个类别的物体:门、人和方向标识,以及俯视图地图的边界。
- 系统从检测器的输出中填充地标的记忆库,并在执行各种技能时附加额外的导航相关信息。
- 例如,对于门,会附加与之关联的房间标签文本;对于人,会附加VLM生成的从他们那里收到的信息的摘要;对于方向标识,会附加每个方向上的标识文本以及相应的方向列表。
- 所有物体都会被标记为“已访问”或“未访问”。
VLM的输入和输出
- VLM的输入包括文本指令和两种形式的抽象场景信息。
- 一种是包括物体和地图边界在内的地标记忆库,以JSON格式呈现。每个地标都被分配一个索引,并可能附加了上述提到的额外信息。
- 另一种信息是智能体当前的俯视图地图的图像可视化。地图根据占用情况和已探索区域进行着色,并为每个地标在其类别符号和索引号的位置上进行标记。
- VLM被提示使用这两种信息来决定下一步要访问的地标。这种设计确保了VLM可以灵活地选择任何合理的高级计划,而无需预测精确的数值坐标。具体的提示和详细的推理过程可以在附录中找到。
行为原语
- 边界(探索):智能体移动到期望的边界,并使用Nav2的点目标规划器和控制器进行360度旋转以扫描其周围环境。边界导航使我们能够探索未访问的区域并识别更多的地标。
- 门(房间标签读取):智能体接近门并平移其相机,同时调用目标检测器查询房间标签。如果检测到房间标签,智能体会靠近并再次调用VLM来读取它。然后,将文本附加到记忆库中的门。如果找到了目标,任务结束。
- 人(询问方向):智能体接近人,并使用文本到语音模型询问方向。然后,它使用语音到文本记录人的回答。接下来,调用VLM生成一个关于接收到的信息的简短笔记,然后将其附加到记忆库中人的地标。重要的是,要求VLM在全局地图框架中使用基本方向,而不是相对方向(如“左”或“右”),以便在记录时不需要从记录时的智能体姿态理解笔记。
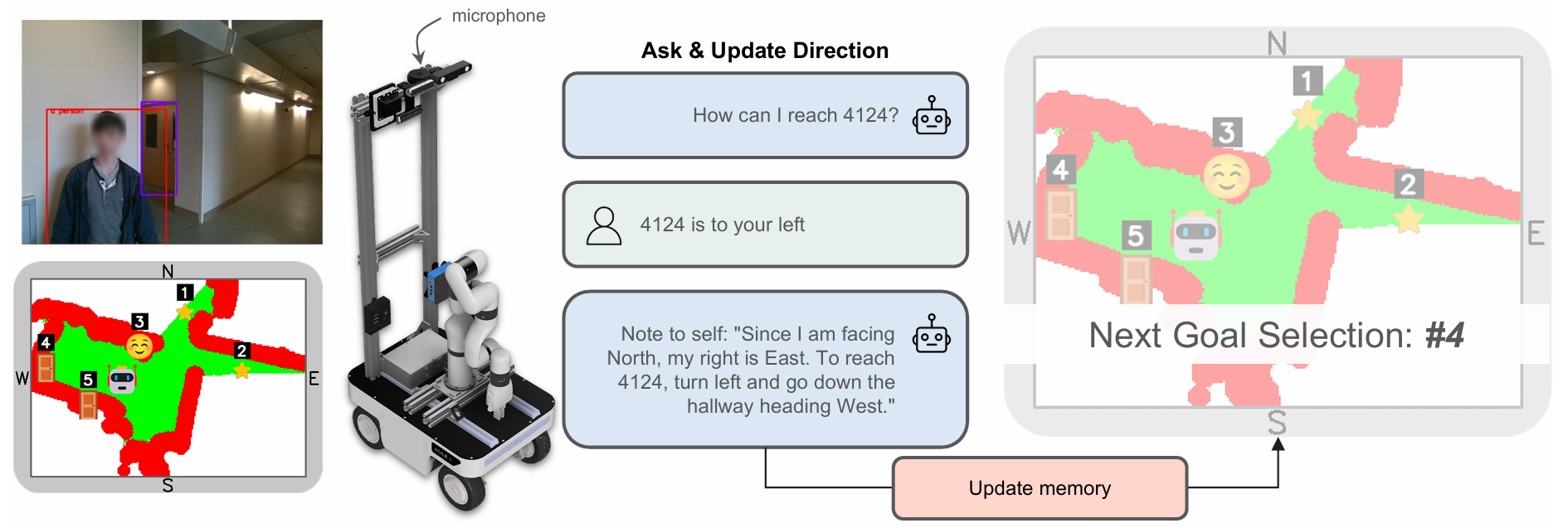
- 方向标识(标识读取):智能体接近标识并使用VLM读取它。根据箭头方向将标识文本分组(分为基本方向),并将方向转换为全局地图框架以便记录。
实验
任务描述
- 目标:在大型未知建筑中找到指定的房间号,模拟真实的室内递送场景。
- 成功条件:智能体在15分钟内成功读取目标房间编号,任务视为成功。
评估环境

- 真实世界环境:
- 在两个复杂的大学校园多功能建筑中进行实验,每个建筑的长度超过80米。
- 建筑中大部分房间的门边都有房间标签,且分布有方向标识和人员。
- 人类的反应是开放式的,通常类似于“它就在你身后的走廊第二间门”。
- 共进行了12次试验,建筑A和建筑B各有不同的起始点和目标点。
- 模拟环境:
- 使用Isaac Sim构建模拟环境,以便进行可复现的评估。
- 使用现有的医院资产,并添加每个门的房间标签、方向标识和能提供方向的虚拟人类。
- 共进行了14次试验,每次试验的起始点和目标点都不同。
- 计划公开所有代码和用于评估的资产,以促进未来对实际室内导航的研究。

基线方法
- No Signs/Humans Feedback:在这种基线方法中,不会将标识和人员的信息处理成地标记忆库。因此,VLM无法阅读标识或向人员询问更多信息,它只能看到地图边界和门,并决定访问哪一个。
- No Landmark Map Input:在这种基线方法中,VLM不接收地图图像输入,仅通过JSON文本格式接收场景信息。
评估指标
- 成功率:机器人到达目标房间并识别到任务完成时计为成功。
- 平均时长:完成任务所需的平均时间。对于因碰撞或在15分钟后超时而失败的试验,将时长上限900秒作为惩罚。
- 平均行驶距离:机器人在试验中行驶的平均距离。对于失败的试验,将行驶距离上限100米作为惩罚。
定性结果
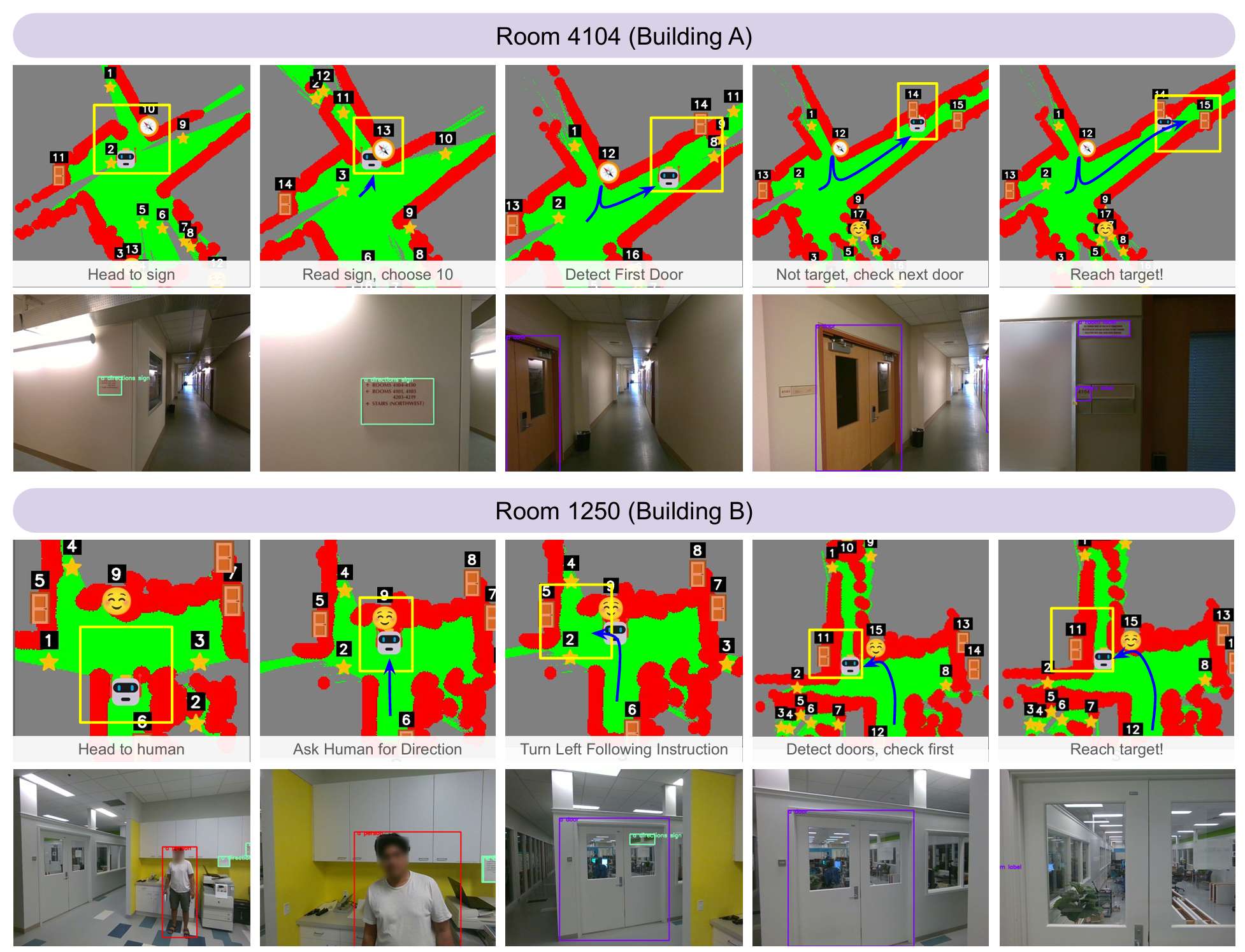
- ReasonNav行为:论文展示了ReasonNav在两个不同真实世界建筑中的完整逐级试验可视化。可以看到,ReasonNav能够成功地阅读标识,理解标识的方向,并利用这些信息选择直接前往目标的边界。类似地,ReasonNav能够向人员询问方向,记录收到的信息,并在后续的高级规划步骤中有效地使用这些信息。
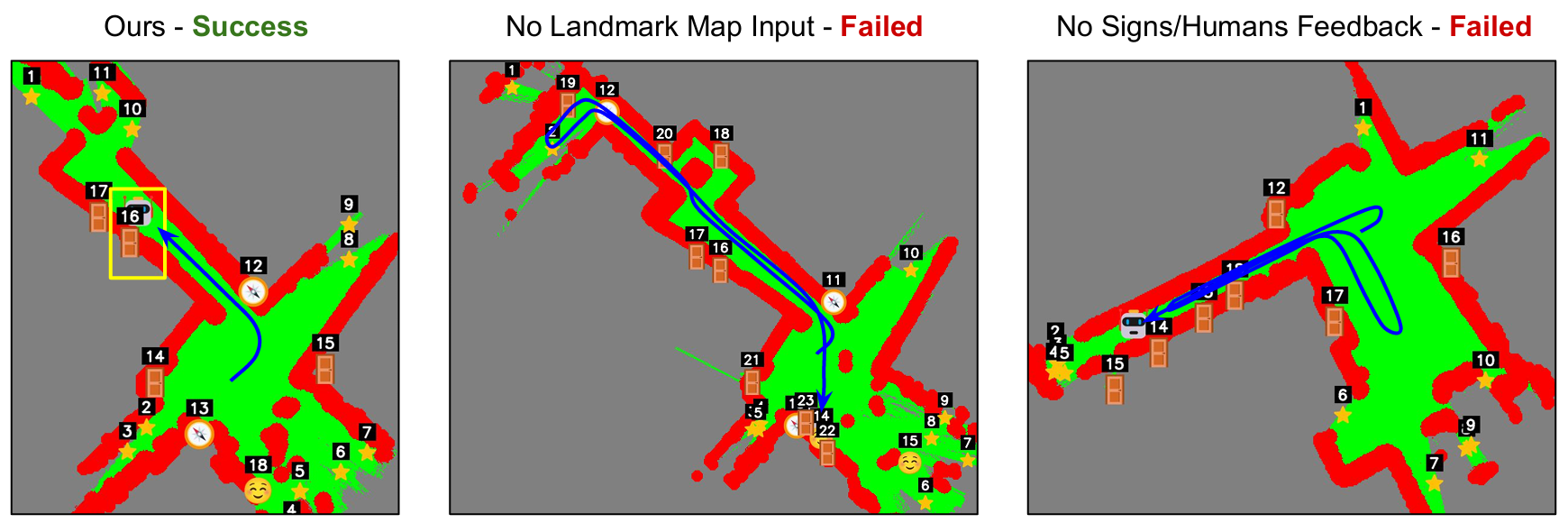
- 基线对比:论文对ReasonNav和基线方法进行了定性比较。结果表明,移除地图图像输入会显著削弱VLM的空间推理能力,使其更容易误解哪些门靠近智能体并值得访问。而移除标识阅读和与人员交流的能力会使智能体更有可能走完全错的方向,导致因超时而失败。
定量结果

- 真实世界环境:
- No Signs/Humans Feedback:成功率为8.3%,平均时长为817.00秒,平均行驶距离为900米。
- No Landmark Map Input:成功率为16.6%,平均时长为679.72秒,平均行驶距离为900米。
- ReasonNav:成功率为58.3%,平均时长为572.35秒,平均行驶距离为232.63米。

- 模拟环境:
- No Signs/Humans Feedback:成功率为42.86%,平均时长为710.76秒,平均行驶距离为75.56米。
- No Landmark Map Input:成功率为14.29%,平均时长为860.72秒,平均行驶距离为123.95米。
- ReasonNav:成功率为57.14%,平均时长为608.99秒,平均行驶距离为72.53米。
- 关键发现:高阶导航技能(如标识阅读和向人员询问方向)对于提高导航效率至关重要。在真实世界和模拟实验中,ReasonNav均优于两种基线方法,成功率分别高出40个百分点以上。
失败分析
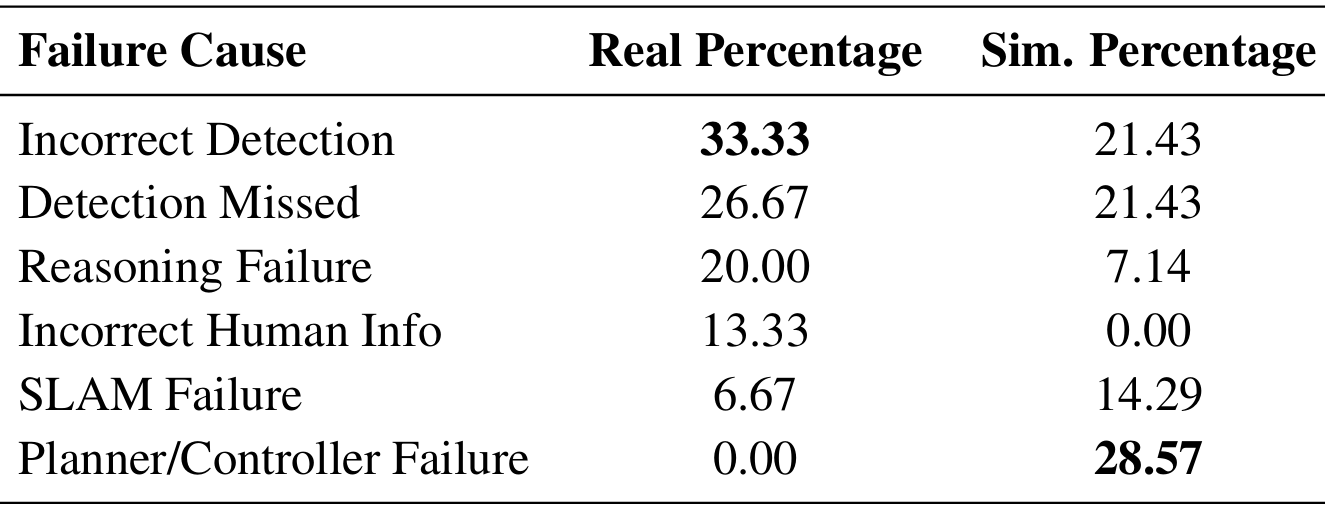
- 真实世界:在真实世界中,检测模块是导致失败的主要原因。海报常被误检测为方向标识或房间标签,导致机器人浪费时间读取它们。此外,还包括检测遗漏和推理失败等情况。
- 模拟环境:在模拟环境中,低级导航问题最为常见,尤其是在狭窄的走廊和有障碍物的区域,路径规划变得困难,会减慢机器人的速度。此外,还包括检测遗漏、推理失败、SLAM失败以及规划器/控制器失败等情况。
结论与未来工作
- 结论:
- ReasonNav通过将高阶导航技能整合到VLM框架中,成功地展示了基于高阶推理的类似人类的导航行为,证明了这些技能在大型环境中导航效率的重要性。
- 未来工作:
- 随着检测能力更好地融入VLM本身,可以用更强大的基于VLM的检测流替换专用检测器;
- 此外,目前VLM仅限于探索边界,不能选择更近的路点来探索区域,这可以通过引入更复杂的重新规划策略来缓解。
