【图像超分】论文复现:轻量化超分 | FMEN的Pytorch源码复现,跑通源码,整合到EDSR-PyTorch中进行训练、重参数化、测试
【图像超分】论文复现:轻量化超分 | FMEN的Pytorch源码复现,跑通源码,整合到EDSR-PyTorch中进行训练、重参数化、测试
前言
论文题目:Fast and Memory-Eficient Network Towards Eficient mage Super-Resoluion9 --高效图像超分辨率的快速内存高效网络
论文地址:Fast and Memory-Efficient Network Towards Efficient lmage Super-Resolution
论文源码:https://github.com/NJU-JeU/FMEN
CVPRW 2022!NTIRE 2022 最低内存和第二少的运行时间。

实现代码
准备工作
首先配置一下EDSR的环境
下载DIV2K的数据集,数据集地址:https://data.vision.ee.ethz.ch/cvl/DIV2K/

下载FMEN的项目,网址:https://github.com/NJU-Jet/FMEN
下载EDSR的项目,网址:https://github.com/sanghyun-son/EDSR-PyTorch
训练
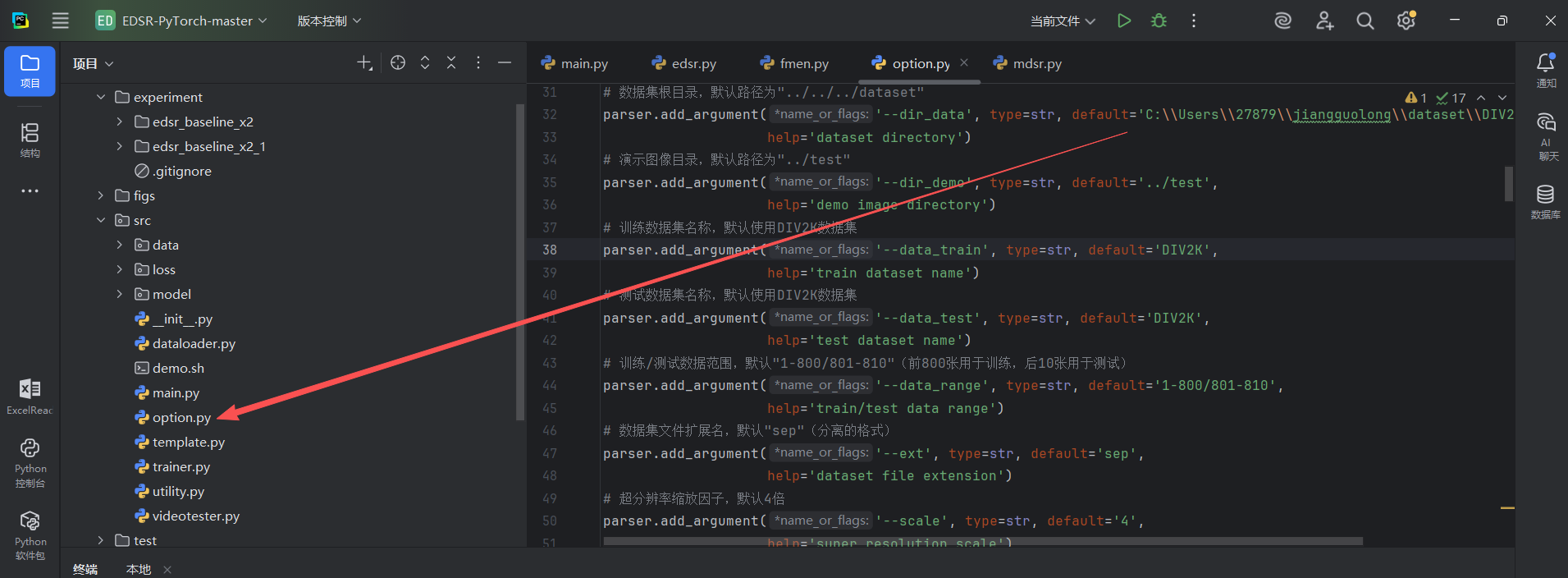
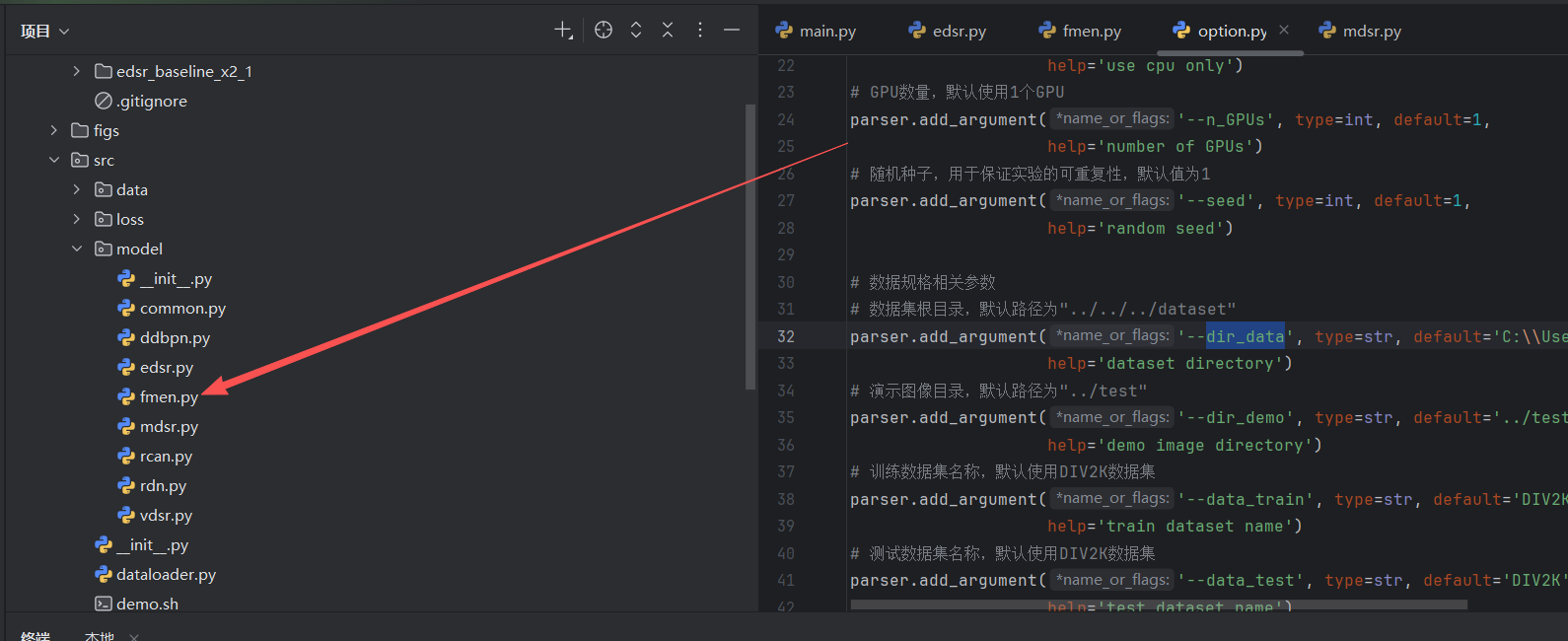
在这个文件中有一个dir_data
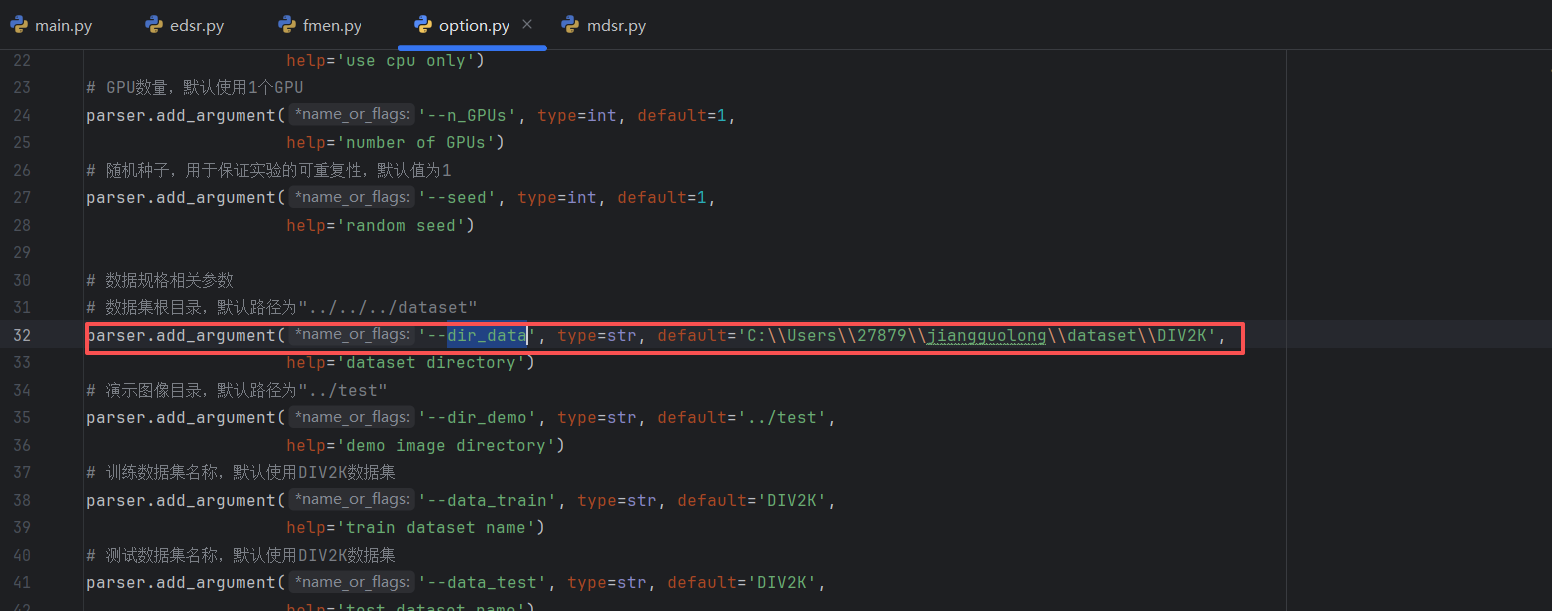
改为自己下载的数据集的位置
在此文件中添加
#--------------------------------------FMEN---------------------------------------------------------------------
# 在参数解析的地方添加以下代码
parser.add_argument('--down_blocks', type=int, default=4, help='Number of [ERB-HFAB] pairs')
parser.add_argument('--up_blocks', type=int, nargs='+', default=[2,1,1,1,1], help='Number of ERBs in each HFAB')
parser.add_argument('--mid_feats', type=int, default=16, help='Number of feature maps in branch ERB')
parser.add_argument('--backbone_expand_ratio', type=int, default=2, help='Expand ratio of RRRB in trunk ERB')
parser.add_argument('--attention_expand_ratio', type=int, default=2, help='Expand ratio of RRRB in branch ERB')
#--------------------------------------FMEN---------------------------------------------------------------------然后在FMEN中复制train_fmen.py到EDSR中的src中的model,名字改为fmen.py
在src中打开终端
python main.py --model FMEN --scale 2 --patch_size 48 --epochs 3 --save edsr_baseline_x2_1 --reset --down_blocks 4 --up_blocks 2 1 1 1 1 --mid_feats 16 --n_feats 50
重参数化
对于训练后的权重,我们只需要用FMEN中的reparameterize.py
import torch
import torch.nn.functional as F
import test_fmen
from tqdm import tqdm
from argparse import ArgumentParserclass Args:def __init__(self):self.n_feats = 50self.mid_feats = 16self.down_blocks = 4self.up_blocks = [2, 1, 1, 1, 1]self.backbone_expand_ratio = 2self.attention_expand_ratio = 2self.n_colors = 3self.scale = [4]def merge_bn(w, b, gamma, beta, mean, var, eps, before_conv=True):"""Merge BN layer into convolution layer.Args:w (torch.tensor): Convolution kernel weight. (C_out, C_in, K, K)b (torch.tensor): Convolution kernel bias. (C_out)"""out_feats = w.shape[0]std = (var + eps).sqrt()scale = gamma / stdbn_bias = beta - mean * gamma / std# Reparameterizing kernelif before_conv:rep_w = w * scale.reshape(1, -1, 1, 1)else:rep_w = torch.mm(torch.diag(scale), w.view(out_feats, -1)).view(w.shape)# Reparameterizing biasif before_conv:rep_b = torch.mm(torch.sum(w, dim=(2,3)), bn_bias.unsqueeze(1)).squeeze() + belse:rep_b = b.mul(scale) + bn_biasreturn rep_w, rep_bdef bn_parameter(pretrain_state_dict, k, dst='bn1'):src = k.split('.')[-2]gamma = pretrain_state_dict[k.replace(src, dst)]beta = pretrain_state_dict[k.replace(f'{src}.weight', f'{dst}.bias')]mean = pretrain_state_dict[k.replace(f'{src}.weight', f'{dst}.running_mean')]var = pretrain_state_dict[k.replace(f'{src}.weight', f'{dst}.running_var')]eps = 1e-05return gamma, beta, mean, var, epsif __name__ == '__main__':parser = ArgumentParser()parser.add_argument('--pretrained_path', type=str, required=True)args = parser.parse_args()model_args = Args()model = test_fmen.make_model(model_args).cuda()rep_state_dict = model.state_dict()pretrain_state_dict = torch.load(args.pretrained_path, map_location='cuda')for k, v in tqdm(rep_state_dict.items()):# merge conv1x1-conv3x3-conv1x1 if 'rep_conv.weight' in k:k0 = pretrain_state_dict[k.replace('rep', 'expand')]k1 = pretrain_state_dict[k.replace('rep', 'fea')]k2 = pretrain_state_dict[k.replace('rep', 'reduce')]bias_str = k.replace('weight', 'bias')b0 = pretrain_state_dict[bias_str.replace('rep', 'expand')]b1 = pretrain_state_dict[bias_str.replace('rep', 'fea')]b2 = pretrain_state_dict[bias_str.replace('rep', 'reduce')]mid_feats, n_feats = k0.shape[:2]# first step: remove the middle identityfor i in range(mid_feats):k1[i, i, 1, 1] += 1.0# second step: merge the first 1x1 convolution and the next 3x3 convolutionmerge_k0k1 = F.conv2d(input=k1, weight=k0.permute(1, 0, 2, 3))merge_b0b1 = b0.view(1, -1, 1, 1) * torch.ones(1, mid_feats, 3, 3).cuda()merge_b0b1 = F.conv2d(input=merge_b0b1, weight=k1, bias=b1)# third step: merge the remain 1x1 convolutionmerge_k0k1k2 = F.conv2d(input=merge_k0k1.permute(1, 0, 2, 3), weight=k2).permute(1, 0, 2, 3)merge_b0b1b2 = F.conv2d(input=merge_b0b1, weight=k2, bias=b2).view(-1)# last step: remove the global identityfor i in range(n_feats):merge_k0k1k2[i, i, 1, 1] += 1.0rep_state_dict[k] = merge_k0k1k2.float()rep_state_dict[bias_str] = merge_b0b1b2.float() elif 'rep_conv.bias' in k:pass# merge BNelif 'squeeze.weight' in k:bias_str = k.replace('weight', 'bias')w = pretrain_state_dict[k]b = pretrain_state_dict[bias_str]gamma, beta, mean, var, eps = bn_parameter(pretrain_state_dict, k, dst='bn1')rep_w, rep_b = merge_bn(w, b, gamma, beta, mean, var, eps, before_conv=True)rep_state_dict[k] = rep_wrep_state_dict[bias_str] = rep_belif 'squeeze.bias' in k:passelif 'excitate.weight' in k:bias_str = k.replace('weight', 'bias')w = pretrain_state_dict[k]b = pretrain_state_dict[bias_str]gamma1, beta1, mean1, var1, eps1 = bn_parameter(pretrain_state_dict, k, dst='bn2')gamma2, beta2, mean2, var2, eps2 = bn_parameter(pretrain_state_dict, k, dst='bn3')rep_w, rep_b = merge_bn(w, b, gamma1, beta1, mean1, var1, eps1, before_conv=True)rep_w, rep_b = merge_bn(rep_w, rep_b, gamma2, beta2, mean2, var2, eps2, before_conv=False)rep_state_dict[k] = rep_wrep_state_dict[bias_str] = rep_belif 'excitate.bias' in k:passelif k in pretrain_state_dict.keys():rep_state_dict[k] = pretrain_state_dict[k]else:raise NotImplementedError('{} is not found in pretrain_state_dict.'.format(k))torch.save(rep_state_dict, 'testx2.pt')print('Reparameterize successfully!')
测试
测试代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import logging
from datetime import datetime
from PIL import Image
import torchvision.transforms as transforms
import torchvision.utils as utils
import os
import time
from os.path import join# 配置日志
def setup_logger(log_file):"""设置日志记录器,同时输出到控制台和文件"""# 创建日志目录(如果不存在)log_dir = os.path.dirname(log_file)if log_dir and not os.path.exists(log_dir):os.makedirs(log_dir)# 日志格式log_format = '%(asctime)s - %(levelname)s - %(message)s'date_format = '%Y-%m-%d %H:%M:%S'# 创建日志记录器logger = logging.getLogger('SR_Logger')logger.setLevel(logging.INFO)# 避免重复添加处理器if logger.handlers:return logger# 文件处理器file_handler = logging.FileHandler(log_file)file_handler.setLevel(logging.INFO)file_formatter = logging.Formatter(log_format, datefmt=date_format)file_handler.setFormatter(file_formatter)# 控制台处理器console_handler = logging.StreamHandler()console_handler.setLevel(logging.INFO)console_formatter = logging.Formatter(log_format, datefmt=date_format)console_handler.setFormatter(console_formatter)# 添加处理器logger.addHandler(file_handler)logger.addHandler(console_handler)return loggerlrelu_value = 0.1
act = nn.LeakyReLU(lrelu_value)def make_model(args, parent=False):return TEST_FMEN(args)class RRRB(nn.Module):def __init__(self, n_feats):super(RRRB, self).__init__()self.rep_conv = nn.Conv2d(n_feats, n_feats, 3, 1, 1)def forward(self, x):out = self.rep_conv(x)return outclass ERB(nn.Module):def __init__(self, n_feats):super(ERB, self).__init__()self.conv1 = RRRB(n_feats)self.conv2 = RRRB(n_feats)def forward(self, x):res = self.conv1(x)res = act(res)res = self.conv2(res)return resclass HFAB(nn.Module):def __init__(self, n_feats, up_blocks, mid_feats):super(HFAB, self).__init__()self.squeeze = nn.Conv2d(n_feats, mid_feats, 3, 1, 1)convs = [ERB(mid_feats) for _ in range(up_blocks)]self.convs = nn.Sequential(*convs)self.excitate = nn.Conv2d(mid_feats, n_feats, 3, 1, 1)self.sigmoid = nn.Sigmoid()def forward(self, x):out = act(self.squeeze(x))out = act(self.convs(out))out = self.excitate(out)out = self.sigmoid(out)out *= xreturn outclass TEST_FMEN(nn.Module):def __init__(self, args):super(TEST_FMEN, self).__init__()self.down_blocks = args.down_blocksup_blocks = args.up_blocksmid_feats = args.mid_featsn_feats = args.n_featsn_colors = args.n_colorsscale = args.scale[0]# 头部模块self.head = nn.Conv2d(n_colors, n_feats, 3, 1, 1)# 预热模块self.warmup = nn.Sequential(nn.Conv2d(n_feats, n_feats, 3, 1, 1),HFAB(n_feats, up_blocks[0], mid_feats - 4))# 主体模块ERBs = [ERB(n_feats) for _ in range(self.down_blocks)]HFABs = [HFAB(n_feats, up_blocks[i + 1], mid_feats) for i in range(self.down_blocks)]self.ERBs = nn.ModuleList(ERBs)self.HFABs = nn.ModuleList(HFABs)self.lr_conv = nn.Conv2d(n_feats, n_feats, 3, 1, 1)# 尾部模块(上采样)self.tail = nn.Sequential(nn.Conv2d(n_feats, n_colors * (scale ** 2), 3, 1, 1),nn.PixelShuffle(scale))def forward(self, x):x = self.head(x)h = self.warmup(x)for i in range(self.down_blocks):h = self.ERBs[i](h)h = self.HFABs[i](h)h = self.lr_conv(h)h += xx = self.tail(h)return xdef load_state_dict(self, state_dict, strict=True):own_state = self.state_dict()for name, param in state_dict.items():if name in own_state:if isinstance(param, nn.Parameter):param = param.datatry:own_state[name].copy_(param)except Exception:if name.find('tail') == -1:raise RuntimeError(f"参数 {name} 维度不匹配: 模型需要 {own_state[name].size()}, 检查点提供 {param.size()}")elif strict:if name.find('tail') == -1:raise KeyError(f"检查点中存在未预期的键: {name}")class Args:def __init__(self):self.down_blocks = 4self.up_blocks = [2, 1, 1, 1, 1]self.n_feats = 50self.mid_feats = 16self.scale = [4] # 超分倍数self.rgb_range = 255self.n_colors = 3 # RGB通道def super_resolve_single_image(model, img_tensor, device):"""单张图片张量的超分推理返回:超分后的张量 + 单张推理时间(毫秒)"""model.eval()with torch.no_grad():start_time = time.time()output_tensor = model(img_tensor)if device.type == 'cuda':torch.cuda.synchronize() # GPU同步,确保时间统计准确end_time = time.time()inference_time = (end_time - start_time) * 1000 # 转毫秒return output_tensor, inference_timedef batch_super_resolve(model, input_folder, output_folder, device, logger):"""批量处理文件夹中的所有图片,带日志记录"""# 记录开始时间start_batch_time = time.time()# 1. 检查并创建输出文件夹(不存在则创建)if not os.path.exists(output_folder):os.makedirs(output_folder)logger.info(f"已创建输出文件夹: {output_folder}")else:logger.info(f"输出文件夹已存在: {output_folder}")# 2. 定义支持的图片格式supported_formats = ('.jpg', '.jpeg', '.png', '.bmp', '.tiff')# 3. 获取输入文件夹中的所有图片文件image_files = [f for f in os.listdir(input_folder)if f.lower().endswith(supported_formats)]if len(image_files) == 0:logger.warning(f"输入文件夹 {input_folder} 中未找到支持格式的图片")returnlogger.info(f"发现 {len(image_files)} 张图片待处理")# 4. 图像预处理transform = transforms.Compose([transforms.ToTensor(), # 转Tensor并归一化到[0,1]])# 5. 预热模型logger.info("开始模型预热...")try:sample_img_path = join(input_folder, image_files[0])sample_img = Image.open(sample_img_path).convert('RGB')sample_tensor = transform(sample_img).unsqueeze(0).to(device)model(sample_tensor) # 预热推理logger.info("模型预热完成,开始批量超分...")except Exception as e:logger.error(f"模型预热失败: {str(e)}", exc_info=True)return# 6. 批量处理每张图片total_time = 0.0 # 统计总推理时间success_count = 0fail_count = 0fail_details = []for idx, filename in enumerate(image_files, 1):# 构建输入输出路径input_path = join(input_folder, filename)name, ext = os.path.splitext(filename)output_filename = f"{name}_sr{ext}"output_path = join(output_folder, output_filename)try:# 加载并预处理图片img = Image.open(input_path).convert('RGB')img_tensor = transform(img).unsqueeze(0).to(device) # 添加batch维度# 超分推理output_tensor, infer_time = super_resolve_single_image(model, img_tensor, device)total_time += infer_time# 后处理并保存output_tensor = torch.clamp(output_tensor, 0.0, 1.0) # 裁剪异常像素值utils.save_image(output_tensor, output_path, normalize=False)success_count += 1logger.info(f"[{idx}/{len(image_files)}] 处理成功 | 输入: {filename} | 输出: {output_filename} | 耗时: {infer_time:.2f}ms")except Exception as e:fail_count += 1fail_details.append((filename, str(e)))logger.error(f"[{idx}/{len(image_files)}] 处理失败 | 输入: {filename} | 错误: {str(e)}")continue# 7. 打印并记录批量处理统计信息total_batch_time = (time.time() - start_batch_time) * 1000 # 总耗时(毫秒)avg_time = total_time / success_count if success_count > 0 else 0 # 平均每张推理时间logger.info("\n" + "=" * 80)logger.info("批量超分处理统计:")logger.info(f"总处理图片数: {len(image_files)}")logger.info(f"成功处理: {success_count} 张")logger.info(f"处理失败: {fail_count} 张")logger.info(f"总推理时间: {total_time:.2f}ms ({total_time / 1000:.2f}s)")logger.info(f"总耗时(含IO): {total_batch_time:.2f}ms ({total_batch_time / 1000:.2f}s)")if success_count > 0:logger.info(f"平均单张推理时间: {avg_time:.2f}ms")logger.info(f"超分结果保存路径: {output_folder}")# 记录失败详情(如果有)if fail_count > 0:logger.info("\n失败详情:")for filename, error in fail_details:logger.info(f" - {filename}: {error[:200]}") # 限制错误信息长度logger.info("=" * 80)if __name__ == '__main__':# 生成带时间戳的日志文件名timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")log_file = f"sr_log_{timestamp}.txt"# 初始化日志logger = setup_logger(log_file)logger.info("====== 开始超分辨率处理程序 ======")# 配置参数args = Args()device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')logger.info(f"使用设备: {device}")logger.info(f"超分倍数: {args.scale[0]}倍")logger.info("=" * 50)# 1. 配置文件夹路径(根据实际路径修改)input_folder = "dataset/scaled_hongwai"output_folder = "test_shangbo_sr_images"weight_path = "test.pt"# 记录配置信息logger.info(f"输入文件夹: {input_folder}")logger.info(f"输出文件夹: {output_folder}")logger.info(f"模型权重路径: {weight_path}")# 2. 初始化并加载模型try:logger.info("初始化模型...")model = TEST_FMEN(args).to(device)if os.path.exists(weight_path):model.load_state_dict(torch.load(weight_path, map_location=device))logger.info(f"成功加载模型权重: {weight_path}")else:logger.error(f"未找到模型权重文件: {weight_path}")raise FileNotFoundError(f"模型权重文件不存在: {weight_path}")except Exception as e:logger.error(f"模型初始化失败: {str(e)}", exc_info=True)exit(1)# 3. 执行批量超分try:batch_super_resolve(model, input_folder, output_folder, device, logger)except Exception as e:logger.error(f"批量处理过程中发生错误: {str(e)}", exc_info=True)logger.info("====== 超分辨率处理程序结束 ======\n")测试PSNR和SSIM
import os
import cv2
import numpy as np
import time
from os.path import join
from typing import Tuple
import warnings
from skimage.metrics import structural_similarity as ssim
warnings.filterwarnings("ignore") # 忽略cv2版本兼容警告def load_image(image_path: str) -> np.ndarray:"""加载图像并转换为RGB格式(OpenCV默认BGR,需转换)返回:形状为 (H, W, 3)、数据类型为 uint8 的图像数组"""# 读取图像(cv2.imread返回BGR格式,dtype=uint8)img = cv2.imread(image_path)if img is None:raise ValueError(f"无法加载图像: {image_path}(可能路径错误或格式不支持)")# 转换为RGB格式(与超分模型输出格式一致)img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)return img_rgbdef calculate_psnr(hr_img: np.ndarray, sr_img: np.ndarray) -> float:"""计算PSNR(峰值信噪比),衡量图像失真程度,值越高越好(通常>30为可接受)公式:PSNR = 10 * log10(MAX² / MSE),其中MAX=255(uint8图像)"""# 确保两张图像尺寸和数据类型一致assert hr_img.shape == sr_img.shape, f"图像尺寸不匹配:原图{hr_img.shape},超分图{sr_img.shape}"assert hr_img.dtype == sr_img.dtype == np.uint8, "图像需为uint8类型"# 计算MSE(均方误差)mse = np.mean((hr_img - sr_img) **2)if mse == 0:return float('inf') # MSE=0表示完全一致,PSNR无穷大# 计算PSNR(MAX=255,uint8图像的最大像素值)max_pixel = 255.0psnr = 10 * np.log10((max_pixel** 2) / mse)return round(psnr, 4) # 保留4位小数def calculate_ssim(hr_img: np.ndarray, sr_img: np.ndarray) -> float:"""使用 scikit-image 计算SSIM(支持多通道RGB图像)"""# 确保两张图像尺寸和数据类型一致assert hr_img.shape == sr_img.shape, f"图像尺寸不匹配:原图{hr_img.shape},超分图{sr_img.shape}"assert hr_img.dtype == sr_img.dtype == np.uint8, "图像需为uint8类型"# 对RGB图像,分别计算每个通道的SSIM后取平均if hr_img.ndim == 3 and hr_img.shape[2] == 3:ssim_channel = []for channel in range(3):# 计算单通道SSIM(data_range=255,因为是uint8图像)ssim_val = ssim(hr_img[..., channel], sr_img[..., channel], data_range=255)ssim_channel.append(ssim_val)ssim_avg = np.mean(ssim_channel) # 三通道SSIM平均值else:# 灰度图像直接计算ssim_avg = ssim(hr_img, sr_img, data_range=255)return round(ssim_avg, 4)def get_image_prefix(filename: str) -> str:"""提取图像文件名的前6个数字作为匹配前缀示例:"000123_sr.jpg" → "000123","img_123456.png" → "123456","789012_hr.bmp" → "789012""""# 提取文件名中的所有数字,取前6个digits = ''.join([c for c in filename if c.isdigit()])if len(digits) < 6:raise ValueError(f"文件名 {filename} 中数字不足6位,无法提取匹配前缀")return digits[:6] # 返回前6个数字作为前缀def match_hr_sr_images(hr_folder: str, sr_folder: str) -> dict:"""按“前6个数字前缀”匹配原图(HR)和超分图(SR)返回:键为6位数字前缀,值为 (HR图像路径, SR图像路径) 的字典"""# 步骤1:遍历HR文件夹,建立“6位数字前缀→HR路径”的映射hr_prefix_map = {}supported_formats = ('.jpg', '.jpeg', '.png', '.bmp', '.tiff') # 支持的图像格式hr_files = [f for f in os.listdir(hr_folder) if f.lower().endswith(supported_formats)]for hr_file in hr_files:try:prefix = get_image_prefix(hr_file)if prefix in hr_prefix_map:print(f"警告:HR文件夹中存在重复6位前缀 {prefix} 的文件,仅保留最新的 {hr_file}")hr_prefix_map[prefix] = join(hr_folder, hr_file)except ValueError as e:print(f"跳过HR文件 {hr_file}:{str(e)}")# 步骤2:遍历SR文件夹,建立“6位数字前缀→SR路径”的映射,并匹配HRmatched_pairs = {}sr_files = [f for f in os.listdir(sr_folder) if f.lower().endswith(supported_formats)]for sr_file in sr_files:try:prefix = get_image_prefix(sr_file)sr_path = join(sr_folder, sr_file)# 检查该6位前缀是否有对应的HR图像if prefix in hr_prefix_map:matched_pairs[prefix] = (hr_prefix_map[prefix], sr_path)else:print(f"警告:SR文件 {sr_file}(前缀{prefix})未找到对应的HR图像,跳过")except ValueError as e:print(f"跳过SR文件 {sr_file}:{str(e)}")# 步骤3:检查未匹配的HR图像matched_prefixes = set(matched_pairs.keys())for prefix, hr_path in hr_prefix_map.items():if prefix not in matched_prefixes:hr_filename = os.path.basename(hr_path)print(f"警告:HR文件 {hr_filename}(前缀{prefix})未找到对应的SR图像,跳过")return matched_pairsdef batch_evaluate_quality(hr_folder: str, sr_folder: str, output_report: bool = True) -> Tuple[float, float]:"""批量评估所有匹配图像对的PSNR和SSIM,支持生成评估报告返回:平均PSNR、平均SSIM"""# 1. 匹配HR和SR图像对(前6位数字相同)print("=" * 60)print("开始按【前6位数字相同】匹配原图(HR)和超分图(SR)...")matched_pairs = match_hr_sr_images(hr_folder, sr_folder)total_pairs = len(matched_pairs)if total_pairs == 0:print("未找到任何匹配的图像对,评估终止")print("=" * 60)return 0.0, 0.0print(f"成功匹配 {total_pairs} 组图像对,开始计算PSNR和SSIM...")print("=" * 60)# 2. 批量计算PSNR和SSIMtotal_psnr = 0.0total_ssim = 0.0failed_count = 0report_lines = [] # 用于生成报告# 添加报告表头report_lines.append("图像质量评估报告(按前6位数字匹配)")report_lines.append("=" * 120)report_lines.append(f"{'前缀':<8} {'HR文件名':<25} {'SR文件名':<25} {'PSNR(dB)':<12} {'SSIM':<10} {'状态':<8}")report_lines.append("-" * 120)# 遍历每个匹配对计算(按前缀排序,结果更规整)for idx, prefix in enumerate(sorted(matched_pairs.keys()), 1):hr_path, sr_path = matched_pairs[prefix]hr_filename = os.path.basename(hr_path)sr_filename = os.path.basename(sr_path)try:# 加载图像hr_img = load_image(hr_path)sr_img = load_image(sr_path)# 计算指标psnr = calculate_psnr(hr_img, sr_img)ssim_val = calculate_ssim(hr_img, sr_img)# 累加统计total_psnr += psnrtotal_ssim += ssim_val# 记录结果report_lines.append(f"{prefix:<8} {hr_filename:<25} {sr_filename:<25} {psnr:<12} {ssim_val:<10} 成功")print(f"[{idx}/{total_pairs}] 前缀{prefix}:PSNR={psnr} dB,SSIM={ssim_val}")except Exception as e:failed_count += 1report_lines.append(f"{prefix:<8} {hr_filename:<25} {sr_filename:<25} {'-':<12} {'-':<10} 失败")print(f"[{idx}/{total_pairs}] 前缀{prefix}:计算失败,原因:{str(e)[:50]}") # 限制错误信息长度# 3. 计算平均值(排除失败的图像对)valid_count = total_pairs - failed_countavg_psnr = round(total_psnr / valid_count, 4) if valid_count > 0 else 0.0avg_ssim = round(total_ssim / valid_count, 4) if valid_count > 0 else 0.0# 4. 生成报告结尾report_lines.append("-" * 120)report_lines.append(f"统计信息:")report_lines.append(f" 总匹配图像对:{total_pairs}")report_lines.append(f" 成功计算:{valid_count}")report_lines.append(f" 计算失败:{failed_count}")report_lines.append(f" 平均PSNR:{avg_psnr} dB")report_lines.append(f" 平均SSIM:{avg_ssim}")report_lines.append(f" 评估时间:{time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())}")report_lines.append("=" * 120)# 5. 打印报告并保存到文件print("\n" + "\n".join(report_lines[-7:-1])) # 打印统计信息if output_report:report_path = join(os.getcwd(), "image_quality_report_hongwai.txt")with open(report_path, 'w', encoding='utf-8') as f:f.write("\n".join(report_lines))print(f"\n完整评估报告已保存至:{report_path}")return avg_psnr, avg_ssimif __name__ == "__main__":# -------------------------- 配置参数(需根据实际路径修改!)--------------------------HR_FOLDER = "hongwai_image" # 高分辨率原图文件夹SR_FOLDER = "shangbo_sr_images" # 超分结果文件夹# -----------------------------------------------------------------------------------# 检查输入文件夹是否存在if not os.path.exists(HR_FOLDER):raise FileNotFoundError(f"原图文件夹不存在:{HR_FOLDER}")if not os.path.exists(SR_FOLDER):raise FileNotFoundError(f"超分文件夹不存在:{SR_FOLDER}")# 执行批量评估print(f"评估开始时间:{time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())}")avg_psnr, avg_ssim = batch_evaluate_quality(HR_FOLDER, SR_FOLDER, output_report=True)print(f"评估结束时间:{time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())}")将数据变成excel表格
import pandas as pd
import re
import os
from typing import List, Tupledef parse_quality_data(report_lines: List[str]) -> List[dict]:"""解析报告中的图像质量数据(前缀、HR文件名、SR文件名、PSNR、SSIM)"""quality_data = []# 匹配质量数据行的正则表达式(示例行:0001 0001.png 0001x4_sr.png 31.1927 0.7125 成功)quality_pattern = re.compile(r'(\d{4})\s+(\S+\.\w+)\s+(\S+\.\w+)\s+(\d+\.\d+)\s+(\d+\.\d+)\s+成功')for line in report_lines:match = quality_pattern.search(line.strip())if match:prefix, hr_name, sr_name, psnr, ssim = match.groups()quality_data.append({"匹配前缀": prefix,"HR图像文件名": hr_name,"SR图像文件名": sr_name,"PSNR (dB)": float(psnr),"SSIM": float(ssim)})return quality_datadef parse_inference_time(report_lines: List[str]) -> List[dict]:"""解析报告中的超分推理时间数据(序号、输入文件名、输出文件名、推理时间)"""time_data = []# 匹配推理时间行的正则表达式(示例行:[1/900] 处理完成: 输入: 0001x4.png 输出: 0001x4_sr.png 单张推理时间: 68.53 毫秒)time_pattern = re.compile(r'\[(\d+)/\d+\]\s+处理完成:\s+输入:\s+(\S+\.\w+)\s+输出:\s+(\S+\.\w+)\s+单张推理时间:\s+(\d+\.\d+)\s+毫秒')for line in report_lines:match = time_pattern.search(line.strip())if match:seq, input_name, output_name, infer_time = match.groups()time_data.append({"处理序号": int(seq),"输入图像文件名": input_name,"输出图像文件名": output_name,"单张推理时间 (毫秒)": float(infer_time)})return time_datadef parse_report_summary(report_lines: List[str]) -> dict:"""解析报告末尾的统计汇总信息(总处理数、总时间、平均时间等)"""summary_data = {}# 匹配总处理图片数total_count_match = re.search(r'总处理图片数:\s+(\d+)', '\n'.join(report_lines))if total_count_match:summary_data["总处理图片数"] = int(total_count_match.group(1))# 匹配总推理时间(毫秒和秒)total_time_match = re.search(r'总推理时间:\s+(\d+\.\d+)\s+毫秒\s+\((\d+\.\d+)\s+秒\)', '\n'.join(report_lines))if total_time_match:summary_data["总推理时间 (毫秒)"] = float(total_time_match.group(1))summary_data["总推理时间 (秒)"] = float(total_time_match.group(2))# 匹配平均单张推理时间avg_time_match = re.search(r'平均单张推理时间:\s+(\d+\.\d+)\s+毫秒', '\n'.join(report_lines))if avg_time_match:summary_data["平均单张推理时间 (毫秒)"] = float(avg_time_match.group(1))# 匹配平均PSNR和SSIM(从质量统计部分提取)avg_psnr_match = re.search(r'平均PSNR:(\d+\.\d+)\s+dB', '\n'.join(report_lines))avg_ssim_match = re.search(r'平均SSIM:(\d+\.\d+)', '\n'.join(report_lines))if avg_psnr_match:summary_data["平均PSNR (dB)"] = float(avg_psnr_match.group(1))if avg_ssim_match:summary_data["平均SSIM"] = float(avg_ssim_match.group(1))# 添加报告来源和生成时间summary_data["报告文件来源"] = os.path.abspath(report_path)summary_data["Excel生成时间"] = pd.Timestamp.now().strftime("%Y-%m-%d %H:%M:%S")return summary_datadef report_to_excel(report_path: str, output_excel_path: str = "image_analysis_result_DIV2K.xlsx") -> None:"""主函数:读取报告文件,解析数据并写入Excel"""# 1. 检查报告文件是否存在if not os.path.exists(report_path):raise FileNotFoundError(f"报告文件不存在:{report_path}")# 2. 读取报告文件内容with open(report_path, 'r', encoding='utf-8') as f:report_lines = f.readlines()print(f"成功读取报告文件:{report_path}(共 {len(report_lines)} 行)")# 3. 解析各类数据print("开始解析数据...")quality_data = parse_quality_data(report_lines)time_data = parse_inference_time(report_lines)summary_data = parse_report_summary(report_lines)# 4. 验证解析结果print(f"解析完成:")print(f" - 质量指标数据:{len(quality_data)} 条(PSNR/SSIM)")print(f" - 推理时间数据:{len(time_data)} 条")print(f" - 统计汇总数据:{len(summary_data)} 项")if len(quality_data) == 0 and len(time_data) == 0:raise ValueError("未从报告中解析到有效数据,请检查报告格式是否正确")# 5. 创建Excel并写入数据with pd.ExcelWriter(output_excel_path, engine='openpyxl') as writer:# 工作表1:图像质量指标(PSNR/SSIM)if quality_data:quality_df = pd.DataFrame(quality_data)quality_df.to_excel(writer, sheet_name="图像质量指标", index=False)print(f"\n工作表「图像质量指标」已写入 {len(quality_df)} 条数据")# 工作表2:超分推理时间if time_data:time_df = pd.DataFrame(time_data)time_df.to_excel(writer, sheet_name="超分推理时间", index=False)print(f"工作表「超分推理时间」已写入 {len(time_df)} 条数据")# 工作表3:统计汇总summary_df = pd.DataFrame([summary_data]) # 转为DataFrame(一行多列)summary_df.to_excel(writer, sheet_name="统计汇总", index=False)print(f"工作表「统计汇总」已写入统计信息")# 6. 输出结果print(f"\n✅ 所有数据已成功写入Excel文件:")print(f" 路径:{os.path.abspath(output_excel_path)}")print(f" 包含工作表:图像质量指标、超分推理时间、统计汇总")if __name__ == "__main__":# -------------------------- 配置参数(需根据实际路径修改!)--------------------------report_path = "PSNRlog/image_quality_report_hongwai.txt" # 输入报告文件路径output_excel_path = "excel/image_quality_report_shangbo.xlsx" # 输出Excel路径# -----------------------------------------------------------------------------------# 执行转换try:report_to_excel(report_path, output_excel_path)except Exception as e:print(f"❌ 执行失败:{str(e)}")