大模型在企业云计算领域的核心应用能力要求
一、能力模型总览:AIOps的智能化升级
大模型在企业云计算运营运维(CloudOps / AIOps)领域的应用,旨在将传统的自动化运维提升到智能化运维的新高度。其能力框架可以概括为五个相互支撑的维度,共同构成一个完整的、可信赖的智能运维体系。
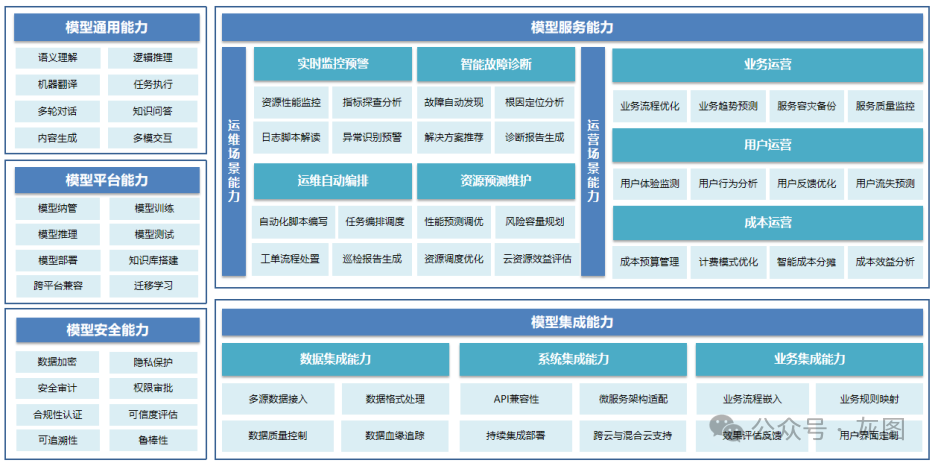
- 模型通用能力
: 模型智能化的基础,决定其能否“听懂”和“看懂”运维世界。
- 模型平台能力
: MLOps的体现,确保模型能够被高效地管理、训练和部署。
- 模型服务能力
: 核心价值所在,直接解决运营和运维场景中的具体痛点。
- 模型集成能力
: 实现技术与业务融合的桥梁,让模型无缝接入现有IT生态。
- 模型安全能力
: 可信的基石,保障智能化过程中的数据、系统和决策安全。
二、五大核心能力详解
1. 模型通用能力 (Foundation)
这是大模型能够理解和处理CloudOps领域复杂信息的基础。
- 核心能力
:
语义理解: 精准解析技术文档、非结构化日志(Logs)、告警信息(Alerts)、配置项(Configuration Items)的真实意图。
逻辑推理: 基于已知的系统状态、监控指标(Metrics)和拓扑关系,进行因果分析和故障路径预测。
任务执行: 将自然语言指令(如“重启XX应用的pod”)转化为可执行的API调用或自动化脚本。
内容生成: 自动编写运维报告、根因分析(RCA)文档、自动化巡检脚本等。
知识问答: 充当“超级运维专家”,快速回答关于系统架构、故障处理预案等问题。
多轮对话&
多模交互: 支持通过对话式交互进行故障排查,并能理解图表、截图等多种信息格式。
- 【扩展】
在CloudOps领域,
语义理解和逻辑推理是关键。模型必须能区分“CPU使用率高”在不同上下文中的含义:在批处理任务中可能正常,但在实时交易系统中则可能是严重告警。这种上下文感知能力是超越传统阈值告警的核心优势。
2. 模型平台能力 (MLOps)
这是支撑大模型在企业内部高效迭代和规模化应用的一站式工程化平台。
- 核心能力
:
模型纳管: 对多种基础模型或微调后的领域模型进行统一的版本控制、注册和元数据管理。
模型训练&
迁移学习: 使用企业内部的运维数据(如历史工单、CMDB信息)对基础模型进行微调,使其适应特定环境,并通过迁移学习快速适应新场景。模型推理&
模型部署: 提供高可用、低延迟的推理服务,并支持云原生(Kubernetes)一键部署及CI/CD集成。知识库搭建: 支持连接和管理企业私有知识库(如Confluence、内部文档、SOP手册),是RAG技术应用的基础。
- 【扩展】
模型平台是实现模型
自主可控的关键。企业不能仅仅依赖外部的公有大模型API,而应建立能够对模型进行持续训练和优化的内部平台,以保护数据隐私并确保模型与业务的持续对齐。
3. 模型服务能力 (Core Value)
这是大模型在CloudOps场景中创造价值的直接体现,分为运维和运营两大方向。
- 运维场景 (Operations)
: 关注系统的稳定性和效率。
实时监控预警: 从海量指标和日志中智能发现异常,预测潜在风险,实现从被动响应到主动预防的转变。
智能故障诊断: 自动关联告警,分析根因,并从知识库中推荐解决方案,核心目标是缩短MTTR(平均故障解决时间)。
运维自动编排: 自动化执行变更、扩容、故障恢复等复杂操作流程。
资源预测维护: 结合业务趋势进行容量规划和性能调优,避免资源浪费或不足。
- 运营场景 (Business Operations)
: 关注成本和用户体验。
业务运营: 预测业务流量趋势,为资源规划提供依据;自动化服务容灾备份,保障业务连续性。
用户运营: 监测用户体验指标,分析用户行为,并预测用户流失风险。
成本运营 (FinOps): 智能分析云资源账单,识别闲置或配置不当的资源,提供成本优化建议,核心目标是降低TCO(总拥有成本)。
- 【扩展】
大模型驱动的
智能故障诊断不仅仅是简单的模式匹配,它能够理解告警之间的逻辑关系。例如,它能推断出“数据库连接池满”的告警可能源于上游“应用实例CPU飙升”,从而引导运维人员直击根本原因。
4. 模型集成能力 (Integration)
确保大模型的智能能够“即插即用”地融入企业现有的IT工作流。
- 核心能力
数据集成: 必须能接入多源异构数据,如:监控系统(Prometheus)、日志系统(ELK)、配置管理数据库(CMDB)、工单系统(Jira)等,并进行ETL和质量控制。
系统集成: 通过标准化的API与现有ITSM、Observability、CI/CD等平台无缝对接,适配微服务和云原生架构。
业务集成: 将模型的能力嵌入到具体的业务流程中,如自动在Jira中创建包含根因分析的工单,或在CI/CD流水线中进行部署前的风险评估。
- 【扩展】
成功的集成意味着大模型不是一个孤立的“聊天框”,而是成为现有运维工具链的一个“智能大脑”,为每个环节赋能。例如,当监控系统产生告警时,能够自动触发模型进行分析,并将分析结果附加到告警信息中,丰富告警上下文。
5. 模型安全能力 (Trust & Security)
在CloudOps场景下,模型将接触到企业最核心的运行数据和系统控制权限,因此安全至关重要。
- 核心能力
:
数据加密&
隐私保护: 对传输和存储的运维数据(可能包含PII或配置密钥)进行加密和脱敏处理。安全审计&
权限审批: 所有通过模型执行的变更操作都必须有严格的权限控制和详细的操作日志,确保行为可审计。合规性认证: 满足行业安全标准(如ISO 27001)。
可信度评估&
可追溯性: 评估模型输出结果的可靠性,并能够追溯其决策依据的数据和逻辑,这对于故障复盘和责任认定至关重要。鲁棒性: 模型必须能够抵御恶意输入(如注入有害指令的日志),在异常数据面前保持稳定,避免做出错误的运维决策导致系统崩溃。
- 【扩展】
可追溯性是建立运维团队对AI信任的关键。当模型建议执行一个高危操作(如删除数据库实例)时,它必须能清晰地解释“为什么”——展示它所依据的告警、日志、历史案例和推理链条,由人类专家最终确认。这被称为“人机协同”(Human-in-the-loop)。
配套选择题及解析
根据《面向企业云计算运营运维领域的大模型应用能力要求》,以下哪项能力是支撑模型在企业内部进行版本控制、训练、部署和管理的工程化基础?
A. 模型通用能力
B. 模型平台能力
C. 模型集成能力
D. 模型服务能力
答案: B
解析: 模型平台能力提供了一站式的MLOps服务,涵盖了模型的纳管(版本控制)、训练、推理、测试、部署等全生命周期管理,是模型在企业内规模化应用和高效迭代的工程化保障。
在运维场景中,大模型通过分析海量监控数据,自动关联分散的告警信息,追溯问题根源,并推荐解决方案。这主要体现了哪项模型服务能力,其核心目标是缩短什么指标?
A. 实时监控预警,缩短MTBF(平均无故障时间)
B. 智能故障诊断,缩短MTTR(平均故障解决时间)
C. 资源预测维护,降低TCO(总拥有成本)
D. 运维自动编排,提升部署频率
答案: B
解析: 描述的场景是典型的智能故障诊断,其核心价值在于加速从发现问题到解决问题的过程,直接对应MTTR(Mean Time To Resolution,平均故障解决时间)这一关键运维指标。
某企业希望大模型能够接入其内部的Prometheus(监控)、Jira(工单)和自建CMDB(配置管理)系统,实现数据互通和流程联动。这主要依赖于大模型的哪项能力?
A. 模型通用能力
B. 模型服务能力
C. 模型集成能力
D. 模型安全能力
答案: C
解析: 模型集成能力,特别是其中的数据集成和系统集成,专门负责确保大模型能够与企业现有的多样化IT系统(如监控、工单、CMDB等)进行有效对接,实现数据的统一利用和工作流的无缝整合。
在CloudOps场景下,模型可能会处理包含用户IP地址、交易记录等敏感信息的日志文件。为了防止信息泄露,必须采用数据脱敏、匿名化等技术。这属于模型安全能力中的哪一项要求?
A. 数据加密
B. 隐私保护
C. 安全审计
D. 鲁棒性
答案: B
解析: 隐私保护专门要求对个人身份信息(PII)和其他敏感数据进行处理(如脱敏、匿名化),以确保其在模型训练和分析过程中不被泄露。数据加密虽然相关,但更侧重于使数据不可读,而隐私保护更侧重于去除数据的身份标识性。
一位运维工程师使用自然语言向大模型提问:“分析最近一小时内交易系统API延迟增高的原因”。模型需要准确理解“API延迟增高”这一技术术语,并进行逻辑分析。这主要依赖于模型的哪项基础能力?
A. 任务执行
B. 内容生成
C. 语义理解与逻辑推理
D. 多模交互
答案: C
解析: 这是模型通用能力的体现。首先,模型需要通过语义理解来准确把握“API延迟增高”这个专业请求的意图。然后,它需要运用逻辑推理能力,结合相关的监控数据和系统知识,分析可能的原因。这是所有上层服务能力的基础。
为了建立运维团队对AI决策的信任,当模型建议执行一个高风险的自动化操作时,它必须能清晰地解释其做出该决策所依据的数据和推理过程,以便人工审核。这一特性被称为?
A. 鲁棒性
B. 可追溯性
C. 跨平台兼容
D. 迁移学习
答案: B
解析: 可追溯性要求模型的决策过程透明,能够记录和展示每一次决策的依据,包括使用了哪些数据、遵循了什么规则或逻辑链条。这对于建立人机协同的信任关系、进行故障复盘和安全审计至关重要。