Flink Data Source 理论与实践架构、时序一致性、容错恢复、吞吐建模与实现模式
1. 总览与三张图
图 A:枚举器在 JobManager 上分配 Splits,多个 TaskManager 上的 SourceReader 并行消费
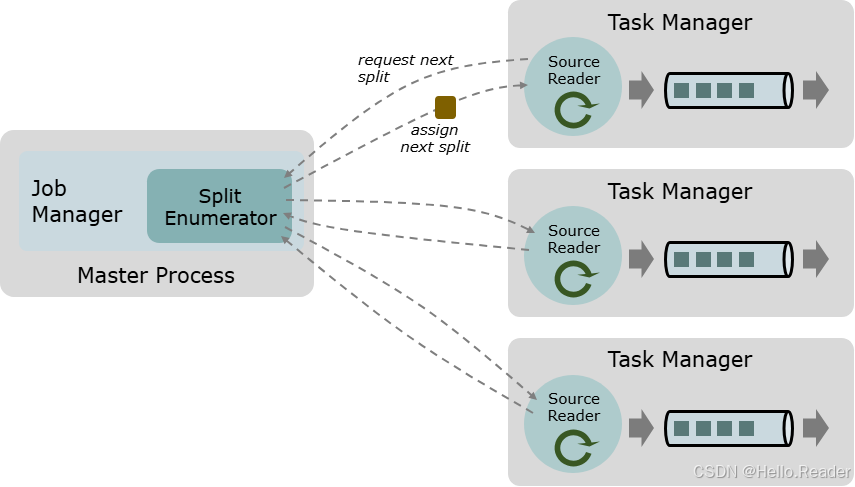
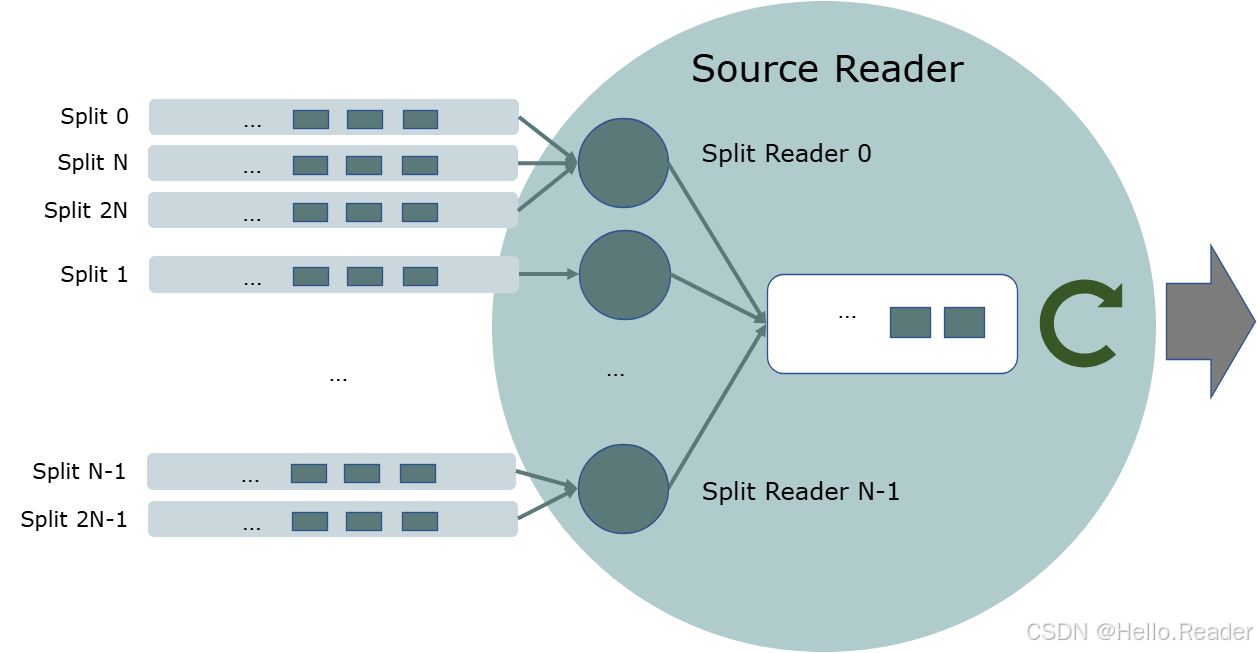
图 B:SourceReader 内部的 SplitFetcher / SplitReader 线程模型(解耦阻塞 I/O 与异步 pollNext)
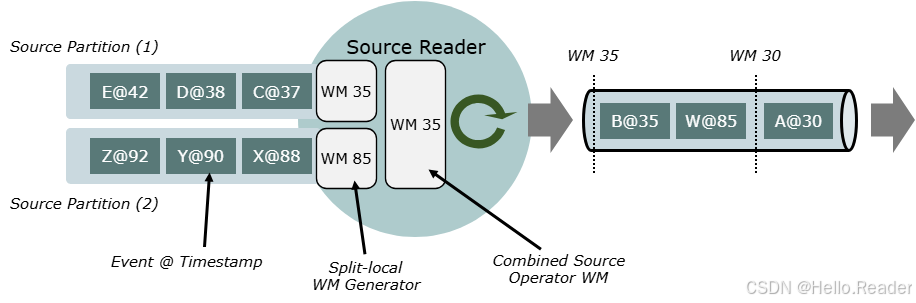
图 C:按 Split 独立推进事件时间与水位线(Split-aware Watermark)
2. 概念模型与协议
三要素
- Split:最小并行/容错单元(文件/片段、Topic 分区、游标范围…)。
- SplitEnumerator(SE):JM 单例,负责发现/分配/回收 Split,处理注册、失败与 SourceEvent 协调。
- SourceReader(SR):TM 并行实例,拉取式
pollNext(ReaderOutput)发射数据,状态驻留在每个 Split。
关键时序(简化)
- SR→SE:
RequestSplit(subtaskId)(或 SE 主动分配); - SE→SR:
AddSplits([splits])/NoMoreSplits; - SR:消费 Split →
snapshotState()返回 Split 状态; - SR 失败:SE 调用
addSplitsBack()收回未确认分配并再分配; - 双向 SourceEvent 做高级协同(限流、亲和、schema 变更等)。
约束:尽量把状态放进 Split,SR 本体“轻状态”,以利迁移与恢复。
3. 批/流统一语义
- Bounded(批):SE 产生固定集合的 Splits,Split 有限;Reader 完成后返回
END_OF_INPUT。 - Unbounded(流):Split 无限或 SE 持续发现新 Split;一般无自然结束,需要外部停止或自定义边界。
概念化示例
- 有界文件:Split=文件/片段;分完返回
NoMoreSplits;SR 读完即退。 - 无界文件:同上,但 SE 周期扫描路径发现新文件。
- 无界 Kafka:Split=TopicPartition;无终点,不会自然结束。
- 有界 Kafka:Split=TopicPartition + end offset;到达即完成。
4. 时间、顺序与一致性
4.1 两步打时间戳
- 源记录时间戳(可选):
SourceOutput.collect(event, sourceTs); - TimestampAssigner(应用配置):决定最终事件时间(可用源 ts 或事件字段)。
若源无 ts 而选择“用源 ts”,最终为
Long.MIN_VALUE。
4.2 水位线与有序性
- Unordered:在相邻 WM之间允许无序,但 WM 不会被记录越过;延迟最低。
- Ordered:保持输入顺序,需要缓冲,延迟与状态更高。
- 批执行:Watermark 生成器停用(no-op)。
4.3 按 Split 的 WM 与对齐
- Split Reader API 天然支持 Split-aware WM;
- 低层 SR API 则需用
createOutputForSplit(splitId)/releaseOutputForSplit(splitId)让不同 Split 走不同输出; - Split 级对齐:实现
SourceReader#pauseOrResumeSplits与SplitReader#pauseOrResumeSplits,在某 Split 超过对齐阈值时暂停/恢复。
5. 容错模型与恢复流程
- Enumerator Checkpoint:待分配队列、扫描游标等;
- Split State:每 Split 的位点、块边界、局部 WM、schema 版本等;
- SR 失败:SE
addSplitsBack()回收未确认分配 → 再分配; - SE 失败:从枚举器快照恢复;
- Exactly-Once 边界:以块/offset 作为 checkpoint 边界,恢复时从上次确认位置重读至边界,与下游(两阶段/幂等写)共同保证 EO。
6. 伸缩再均衡与拓扑变化
- 扩容:基于
currentParallelism()重算所有权,将 backlog/活跃 Splits 迁移到新 SR; - 缩容:回收被释放 SR 的活跃 Splits 并均衡分配;
- 目录/Topic 变化:周期发现 + 幂等分配(稳定 SplitId、确认机制);
- 主机亲和:可用
hostname优先本地性(HDFS、本地盘),否则退化为均衡。
7. 性能建模与容量规划
-
Little’s Law(单 SR):
WIP ≈ λ × RTT- 提升吞吐:①更多并发/分片;②更大批量降低 RTT;③提升并行度;
-
线程模型
- 一抓取器多 Split(固定线程池):线程可控,适合大量小分片;
- 每 Split 一抓取器:简单,适合少量长分片;
- 自适应:按活跃 Split 与速率动态扩缩;
-
批量与队列:分层批量显著降开销,但过大批量会增大端到端延迟与 checkpoint 粘滞。
8. 设计与实现模式
- Split 设计:稳定 Id、可序列化且版本化的状态、友好的边界(便于快照);
- 枚举器策略:Reader 拉取优先(避免过度推送)、幂等发现、失败仅回收“未确认分配”;
- SourceEvent:SR 上报本地指标(慢分区、滞后),SE 下发限流/暂停/优先级指令。
9. 测试策略
- 单元:Split 序列化、
RecordsWithSplitIds边界; - 组件:SE 周期发现/再分配、
addSplitsBack()幂等; - 集成:随机失败恢复、扩缩容、目录/Topic 动态;
- 时序:乱序/空闲 Split 场景、WM 对齐;
- 回放:退避/超时/慢分区压测下的延迟与吞吐。
10. 最小骨架代码
仅展示关键段,直接复制即可改造成你的场景(文件/对象存储/Kafka 等)。
10.1 Split 与序列化
// 最小 Split:文件的一个范围(块对齐)
public class FileRangeSplit implements SourceSplit, Serializable {private final String splitId; // 稳定 ID(幂等发现/再分配依据)private final String path; // 文件路径private final long start; // 起始偏移(包含/半开按实现约定)private final long end; // 结束偏移// 可选:局部 WM/Schema 版本等public FileRangeSplit(String splitId, String path, long start, long end) {this.splitId = splitId; this.path = path; this.start = start; this.end = end;}@Override public String splitId() { return splitId; }public String path() { return path; }public long start() { return start; }public long end() { return end; }
}// 版本化序列化器:保证 savepoint/升级兼容
public class FileRangeSplitSerializer implements SimpleVersionedSerializer<FileRangeSplit> {private static final int V1 = 1;@Override public int getVersion() { return V1; }@Override public byte[] serialize(FileRangeSplit s) throws IOException {try (var bos = new ByteArrayOutputStream(); var out = new DataOutputStream(bos)) {out.writeUTF(s.splitId()); out.writeUTF(s.path()); out.writeLong(s.start()); out.writeLong(s.end());out.flush(); return bos.toByteArray();}}@Override public FileRangeSplit deserialize(int v, byte[] b) throws IOException {try (var in = new DataInputStream(new ByteArrayInputStream(b))) {return new FileRangeSplit(in.readUTF(), in.readUTF(), in.readLong(), in.readLong());}}
}
10.2 SplitEnumerator:周期发现 + 幂等分配
// 枚举器快照:待分配队列 + 已见集合(用于幂等发现)
public record EnumCp(List<FileRangeSplit> backlog, Set<String> seen) implements Serializable {}public class FileEnumerator implements SplitEnumerator<FileRangeSplit, EnumCp> {private final SplitEnumeratorContext<FileRangeSplit> ctx;private final Queue<FileRangeSplit> backlog = new ArrayDeque<>();private final Set<String> seen = new HashSet<>();public FileEnumerator(SplitEnumeratorContext<FileRangeSplit> ctx) { this.ctx = ctx; }@Override public void start() {// 周期扫描目录,无需自建线程ctx.callAsync(this::scanOnce, (splits, err) -> {if (err == null && splits != null) {for (var s : splits) if (seen.add(s.splitId())) backlog.add(s); // 幂等assignPending();}}, 0L, 30_000L);}@Override public void handleSplitRequest(int subtaskId, @Nullable String host) {var s = backlog.poll();if (s != null) {ctx.assignSplits(new SplitsAssignment<>(Map.of(subtaskId, List.of(s))));} else {ctx.signalNoMoreSplits(subtaskId); // 有界时务必告知 Reader}}@Override public void addSplitsBack(List<FileRangeSplit> splits, int subtaskId) { backlog.addAll(splits); }@Override public EnumCp snapshotState(long cpId) { return new EnumCp(new ArrayList<>(backlog), new HashSet<>(seen)); }@Override public void close() {}// 扫描目录,返回新 Split 列表(略)private List<FileRangeSplit> scanOnce() { return List.of(); }private void assignPending() { ctx.registeredReaders().keySet().forEach(this::handleSplitRequest); }
}
10.3 SplitReader + SourceReaderBase:阻塞 I/O 解耦
// 只做阻塞式读取;由 SplitFetcher 线程调用
public class FileSplitReader implements SplitReader<String, FileRangeSplit> {private final Map<String, FileRangeSplit> active = new HashMap<>();@Overridepublic RecordsWithSplitIds<String> fetch() throws IOException {// 这里进行阻塞 I/O(FileSystem/HDFS/S3 读);一次返回一批记录及其 splitId// 真实实现需维护偏移与边界,这里省略,用伪数据说明return new RecordsWithSplitIds<>() {int idx = 0; final String sid = active.keySet().stream().findFirst().orElse(null);@Override public String nextSplit() { return idx == 0 ? sid : null; }@Override public String nextRecordFromSplit() { return idx++ == 0 ? "record" : null; }@Override public Collection<String> finishedSplits() { return List.of(); }@Override public void recycle() {}};}@Override public void handleSplitsChanges(SplitsChange<FileRangeSplit> change) {change.splits().forEach(s -> active.put(s.splitId(), s));}@Override public void wakeUp() { /* 中断阻塞 I/O */ }@Override public void pauseOrResumeSplits(Collection<String> pause, Collection<String> resume) { /* Split 级对齐 */ }@Override public void close() {}
}// SourceReader 复用 SourceReaderBase,获得抓取线程池/状态/WMs 等能力
public class FileSourceReader extends SourceReaderBase<String, String, FileRangeSplit, FileRangeSplit> {public FileSourceReader(SourceReaderContext ctx, Configuration conf) {super(new FixedSizeSplitFetcherManager<>(conf.get(SourceConfig.NUM_FETCHERS), // 抓取线程数FileSplitReader::new, // 创建 SplitReaderconf),(element, out, splitState) -> out.collect(element), // RecordEmitter:发射并更新状态conf,ctx);}@Override protected void onSplitFinished(Map<String, FileRangeSplit> finished) { /* 上报/度量 */ }@Override protected FileRangeSplit initializedState(FileRangeSplit s) { return s; }@Override protected FileRangeSplit toSplitType(String splitId, FileRangeSplit st) { return st; }
}
10.4 在作业中使用 Source + 水位线策略
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();Source<String, FileRangeSplit, EnumCp> mySource = new Source<>() {@Override public Boundedness getBoundedness() { return Boundedness.BOUNDED; }@Override public SourceReader<String, FileRangeSplit> createReader(SourceReaderContext c) { return new FileSourceReader(c, new Configuration()); }@Override public SplitEnumerator<FileRangeSplit, EnumCp> createEnumerator(SplitEnumeratorContext<FileRangeSplit> c) { return new FileEnumerator(c); }@Override public SplitEnumerator<FileRangeSplit, EnumCp> restoreEnumerator(SplitEnumeratorContext<FileRangeSplit> c, EnumCp cp) { return new FileEnumerator(c); }@Override public SimpleVersionedSerializer<FileRangeSplit> getSplitSerializer() { return new FileRangeSplitSerializer(); }@Override public SimpleVersionedSerializer<EnumCp> getEnumeratorCheckpointSerializer() { return null; /* 省略 */ }
};DataStream<String> stream = env.fromSource(mySource,WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ofSeconds(2)).withTimestampAssigner((e, ts) -> System.currentTimeMillis()),"MyFileSource");stream.print();
env.execute("My Data Source Job");
11. 反模式清单
- 在
pollNext()做阻塞 I/O(会卡住 TM 事件循环)。 - SR 保存大量本地不可迁移状态,而不是放进 Split。
- 无界文件源未做幂等发现(重复分配/重复消费)。
- 忽视 Split 级水位线 与 对齐(空闲分区钉住全局时间)。
- Split/枚举器快照未版本化,导致 savepoint 不可升级。
12. 结语
FLIP-27 将“发现/分配/读取”分层:Enumerator 管全局与协议,Reader 管本地与时序,Split 管状态与容错。理解这套分层,你就能系统地权衡 吞吐、延迟、恢复时间、工程复杂度。复制本文骨架,替换 Split 定义、发现逻辑与 I/O 实现,就能在你的系统(文件/对象存储/消息队列/自研存储)中快速落地一个生产可用的 Source。