Linux是怎么工作的--第二章
这是一个系列文章
文章目录
目录
文章目录
前言
一、系统调用
1.1 CPU的模式切换
1.2 发起系统调用时的情形
1.3 实验
1.3.1 执行系统调用所需的时间
二、系统调用的包装函数
三、C标准库
四、OS提供的程序
前言
在今天我们主要了解用户模式实现的,包括系统调用,系统调用的包装函数,C标准库,OS提供的程序
OS并非仅有内核构成,还包含许多在用户模式下运行的程序。这些程序有的以库的形式存在,还有的单独的进程运行,这里我们先看以下计算机系统中的各种进程与OS的关系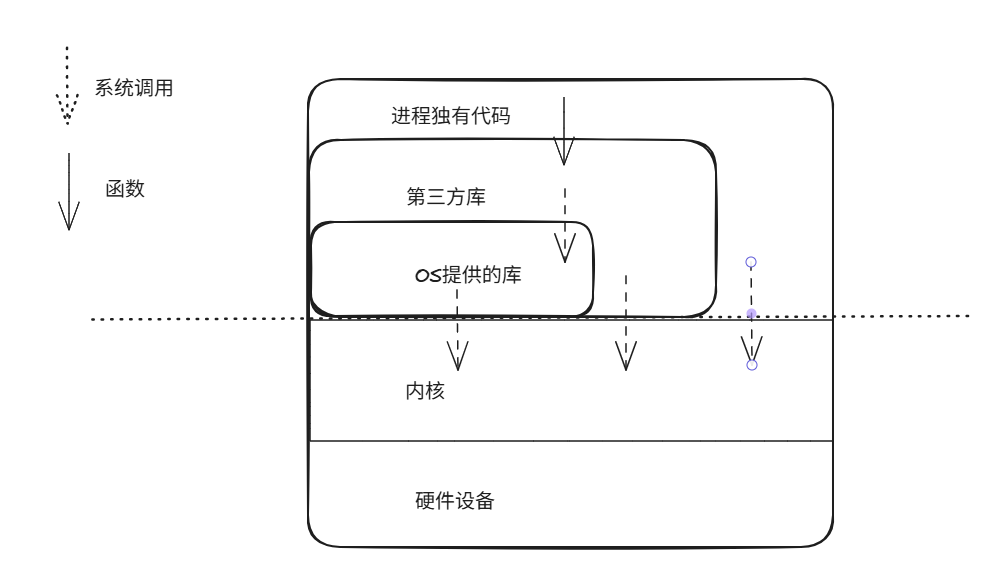
一般来说,由用户模式下运行的进程通过系统调用向内和发送相应的请求,其中存在进程独有代码向内核发送请求的情况,也存在进程所依赖的库向内核发送请求的情况,库分为OS提供的库与第三方库两种类型
一、系统调用
进程在执行创建进程、操控硬件等依赖于内核的处理时,必须通过系统调用向内核发起请求,系统调用的种类如下
- 进程控制(创建和删除)
- 内存管理(分配和释放)
- 进程间通信
- 网络管理
- 文件系统操作
- 文件操作(访问设备)
1.1 CPU的模式切换
系统调用需要CPU执行特殊的CPU命令来发起,通常进程运行在用户模式下,通过系统调用向内核发送请求时,CPU会发生中断,CPU先用户切换为内核,对请求内容进行处理,等内核处理完所有系统调用后,重新回到用户模式,继续运行进程
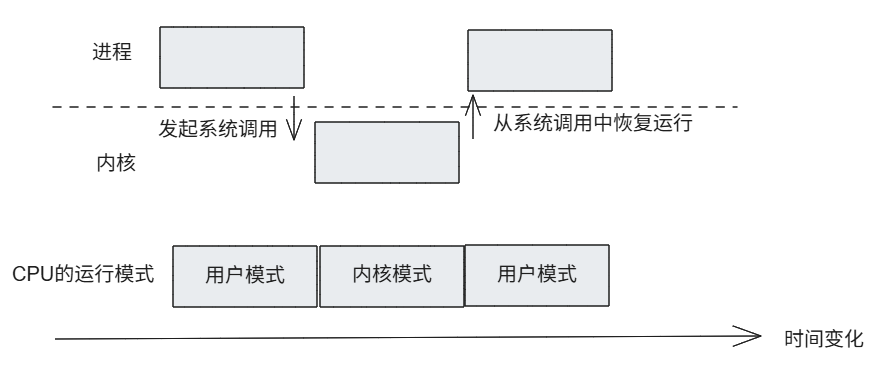
内核在开始进行处理时,会验证来自进程的请求是否合理(例如,请求的内存量是否大于系统所拥有的内存量等),如果请求不合理,系统调用将执行失败,而且并不存在用户进程绕过系统调用而直接切换CPU运行模式的方法(假如有,内核就失去了存在的意义)
1.2 发起系统调用时的情形
我们可以通过strace命令对进程进行追踪,接下来我们举个例子,我们通过运行hello.c程序如下
#include<stdio.h>
int main()
{printf("hello world");return 0;
}首先不用strace命令,尝试编译并运行一遍
cc -o hello hello.c
./hello
![]()
接下来我们介绍一下strace这个命令
strace 是一个在 Linux 系统上用于诊断、调试和监控程序的强大命令行工具。它的核心功能是跟踪一个程序在运行过程中与操作系统内核之间的交互,具体来说,就是跟踪程序发出的系统调用和接收的信号。
我们接下来去用strace命令去观察hello.c这个文件在后台干了些什么
strace -o hello.log ./hello
PS:.log 文件是用于记录系统、程序或服务运行过程中关键信息的文本文件,主要作用是帮助排查故障、追踪操作记录和分析运行状态,常见于 Linux、Windows 等各类系统和软件中。
程序和上次运行一样,接下来,打开hello.log文件,看看strace命令的运行结果
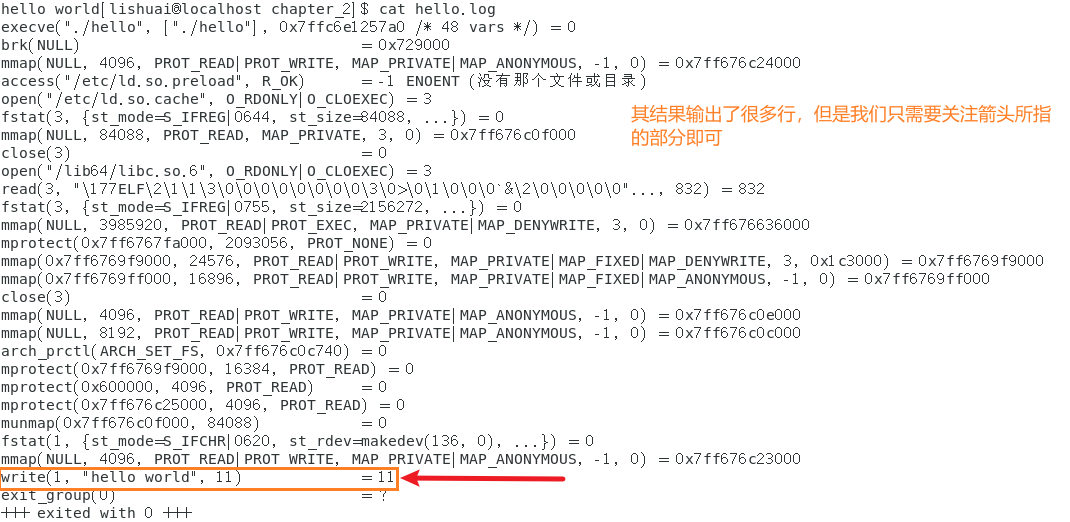
通过这一行的内容可以了解到,今晨通过负责向画面或文件等输出数据的write()系统调用
在原书中的计算机中,该进程总共发起了31个系统调用,这些系统调用大多是由在main()函数之前或者之后执行的程序的开始处理和终止处理(OS提供的功能的一部分),无需特别注意
1.3 实验
sar命令用于获取进程分别在用户模式与内核模式下运行的时间比例,我们每秒采集一次数据,看看每个CPU核心到底在运行什么
sar(System Activity Reporter)是 sysstat 工具集中的核心命令,用于实时或周期性收集、报告系统活动数据(如 CPU、内存、I/O、网络等性能指标)。其语法灵活,支持多种参数组合,以下是详细说明:
sar [选项] [时间间隔(秒)] [次数]
-n DEV:显示所有网卡的流量(接收 / 发送字节数、数据包数等)。
-n TCP:显示 TCP 连接统计(如活跃连接、被动打开连接数等)。
-n UDP:显示 UDP 数据包统计。
-n ALL:显示所有网络相关统计。我们输入命令如下
sar -p ALL 1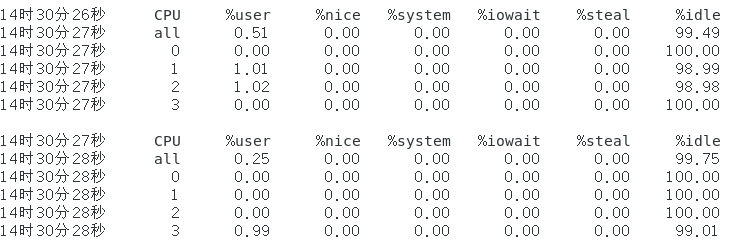
如果在运行过程中按下Ctrl+C,则sar命令会结束运行,并输出已采集的所有元素的平均值

从上图我们可以看到,每一行的字段的值的总和是100%,一行数据对应一个CPU核心,这里输出是我执行命令搭载的4个核心的数据(all的那一行数据是全部CPU核心的平均值)

将%user字段与%nice字段的值相加得到的值是进程在用户模式下运行的时间比例(%user与%nice 的区别),而CPU核心在内核模式下执行系统调用等处理所占的时间比例可以通过%system字段得到,这里的%idle指的是CPU核心完全没有运行任何处理时空闲(idle)状态
另外,也可以通过sar命令的第四个参数来指定采集信息的次数,如下所示
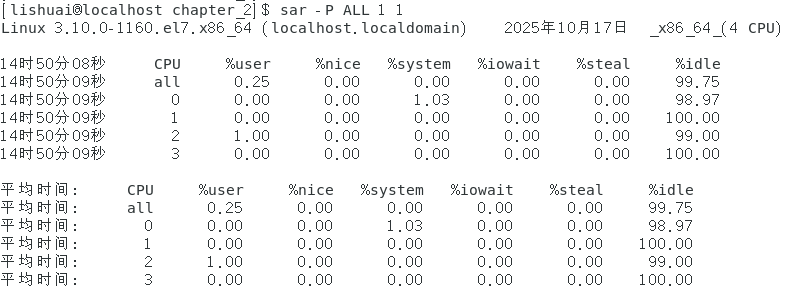
接下来我们尝试一个不发起任何系统调用,只是单纯的执行循环的程序,并通过sar命令查看它在个模式下的运行时间
#include<stdio.h>
int main()
{for(;;);
}之后我们输入以下命令
cc -o loop loop.c./loop & sar -P ALL 1 1
对于第二个程序,& 是将命令放到后台运行的符号。执行 ./loop & 时,系统会启动 loop 程序(当前目录下的可执行文件),但不会阻塞当前终端(你可以继续在终端输入其他命令,无需等待 loop 执行结束)

编译代码将出现上述的结果
参考上述箭头的那一行数据,可以看采集的这一秒内,用户程序即(loop程序)在一定时间运行在CPU核心0上
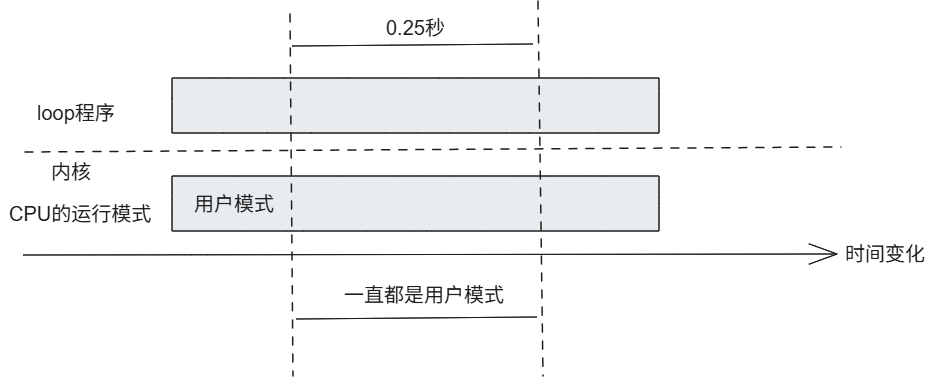
在测试完成后,记得结束在运行的loop程序
kill 66244
接下来我们对训话执行getppid()这个用于获取父进程的进程ID的系统调用的程序进行相同的操作
我们看图片上的红色箭头指向
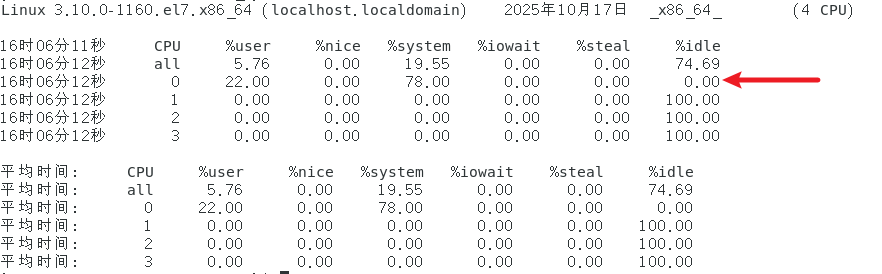
在核心0上,运行ppidloop程序占用28%的运行时间,根据ppidloop程序发出的请求来获取父进程的进程ID这一内核处理占用了72%的运行时间
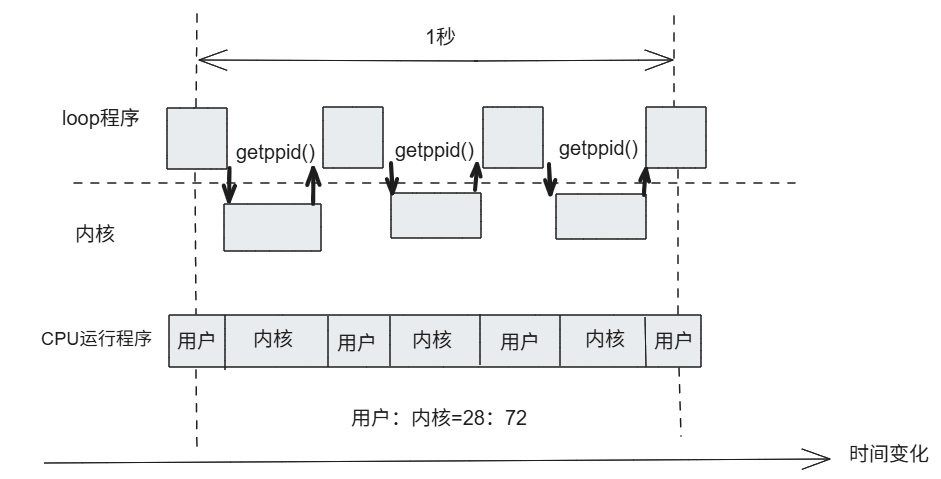
%system的值不是100%,这是因为用于循环main()函数内的getppid()的循环处理,这是属于进程自身的处理,没有调用系统内核,当然在测试完之后,不要忘记关闭进程
kill 666518
在大多数情况西,当%system的值高达几十时,大多是陷入了系统调用过多,或者系统负载过高等糟糕的状态
1.3.1 执行系统调用所需的时间
在strace的命令后加上-T选项,就能以微秒级的精度来采集各种系统调用所消耗的实际时间,在发现%system的值过高时,可以通过这个功能确定到底是那个系统调用占用了过多的系统资源,虾米按对hello world程序使用strace -T 后的输出的结果
strace -T -o hello1.log ./hello
cat hello1.log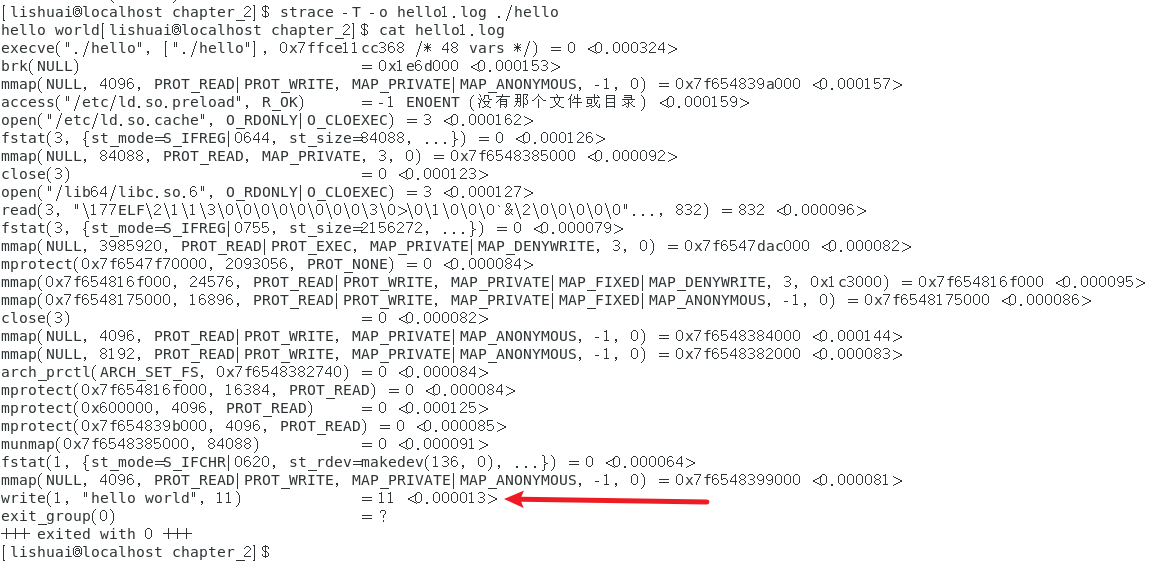
通过上述信息看,输出hello world花费了13微秒
二、系统调用的包装函数
LINUX为了编写程序方便,提供了大多数进程所依赖的库函数,需要注意的是,与常规的函数调用不同,系统调用不能被C语言直接调用,只能通过与系统架构紧密相连的汇编语言发起,例如在x86_64架构下,如下是发起getppid()这个歌系统调用的
mov $0x6e.%eax
上面的程序是将getppid()的系统调用编号0x6e传递给eax寄存器,这里的系统调用编号是由linux预先定义的
syscall
通过其发起系统调用,并切换到内核模式如果没有OS的帮助,程序员就要根据系统架构为每一个系统调用编写相应的汇编语言代码,然后再从高级编程语言中调用这些代码
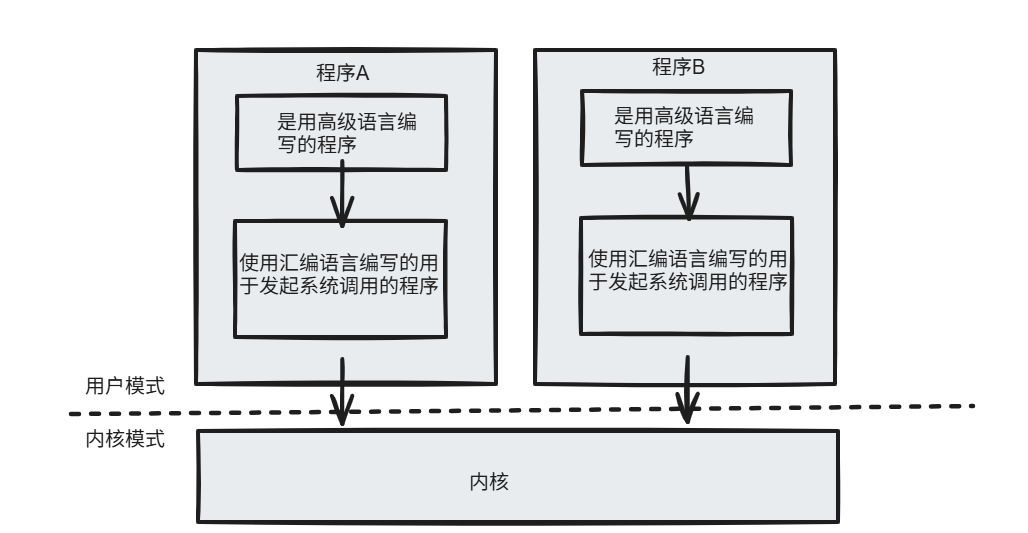
这样一来,编写程序的时间增加,程序也无法移植到别的架构
为例解决这样的问题,OS提供了一些列系统调用的包装函数的函数,高级编程语言调用这些函数就行
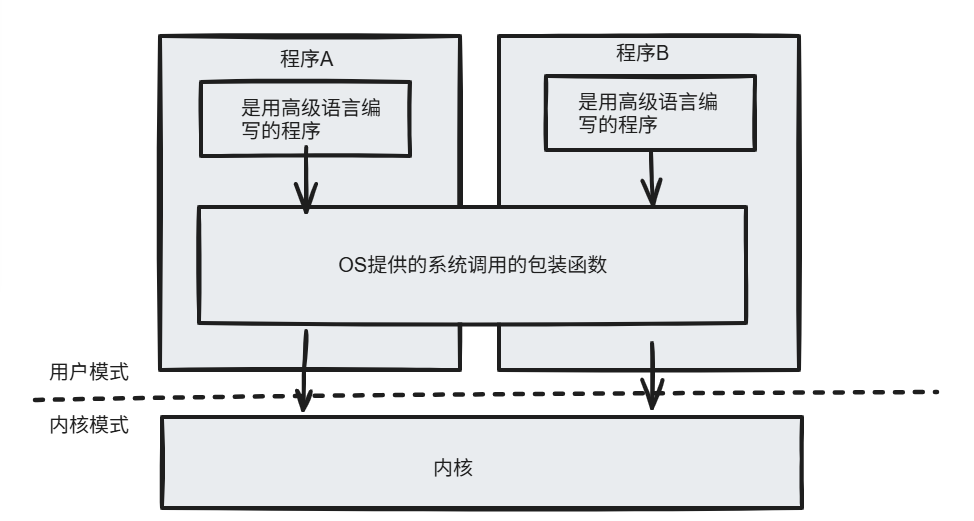
三、C标准库
C语言拥有ISO定义的标准库,Linux也提供了这些C语言标准库,不过通常会以GNU项目提供的glibc作为C标准库使用,用C语言编写的几乎所有程序都依赖于glibc库
glibc库不仅包含系统调用的包装函数,还提供了POSIX标准中定义的函数
Linux提供了ldd命令,用于查看程序所依赖的库
我们尝试对echo命令使用ldd命令

下面看一下ppidloop命令依赖于那些库
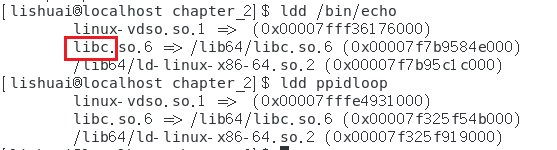
四、OS提供的程序
初始化:init
变更系统的运行方式:sysctl nice sync
文件操作 touch,mkdir
文本数据处理:grep,sort,uniq
性能测试:sar,iostat
编译:gcc