perf 子系统宏观认知
一、什么是 perf?
perf 是内置于 Linux 内核的性能分析工具,它起源于 Linux 的 perf_events 子系统。它的核心功能是进行性能监控和追踪,帮助开发者找到软件的性能瓶颈。
主要能力包括:
- CPU 性能分析:分析函数、指令级别的 CPU 使用率。
- 硬件事件计数:统计缓存命中/失效、分支预测失败、周期数等 CPU 硬件事件。
- 软件事件计数:统计页错误、上下文切换、CPU 迁移等内核事件。
- 动态追踪:在不修改代码的情况下,对函数调用(probe)、内核事件等进行跟踪。
- 静态追踪:使用内核的tracepoint进行跟踪。
- 用户态与内核态:可以同时分析应用程序和操作系统内核的行为。
二、perf 的宏观架构
perf 的整体架构可以分为三个层次:用户空间工具、内核子系统和硬件支撑。
+-----------------------------------+ +-----------------------+
| User Space Tools | | Perf Data Files |
|-----------------------------------| |-----------------------|
| `perf record`, `perf stat`, |<--->| perf.data, build-id, |
| `perf top`, `perf report`, ... | | call-graphs, etc. |
+-----------------------------------+ +-----------------------+^| (系统调用, mmap, ioctl)v
+-----------------------------------+
| Kernel Subsystem |
|-----------------------------------|
| perf_events |
| - perf_event_open() 系统调用 |
| - 事件管理、调度、缓冲区管理 |
| - 输出数据到用户空间 |
+-----------------------------------+^| (HW Counters, NMI, PMU)v
+-----------------------------------+
| Hardware |
|-----------------------------------|
| Performance Monitoring Unit (PMU) |
| - CPU Cycles |
| - Instructions Retired |
| - Cache Misses/Hits |
| - ... |
+-----------------------------------+
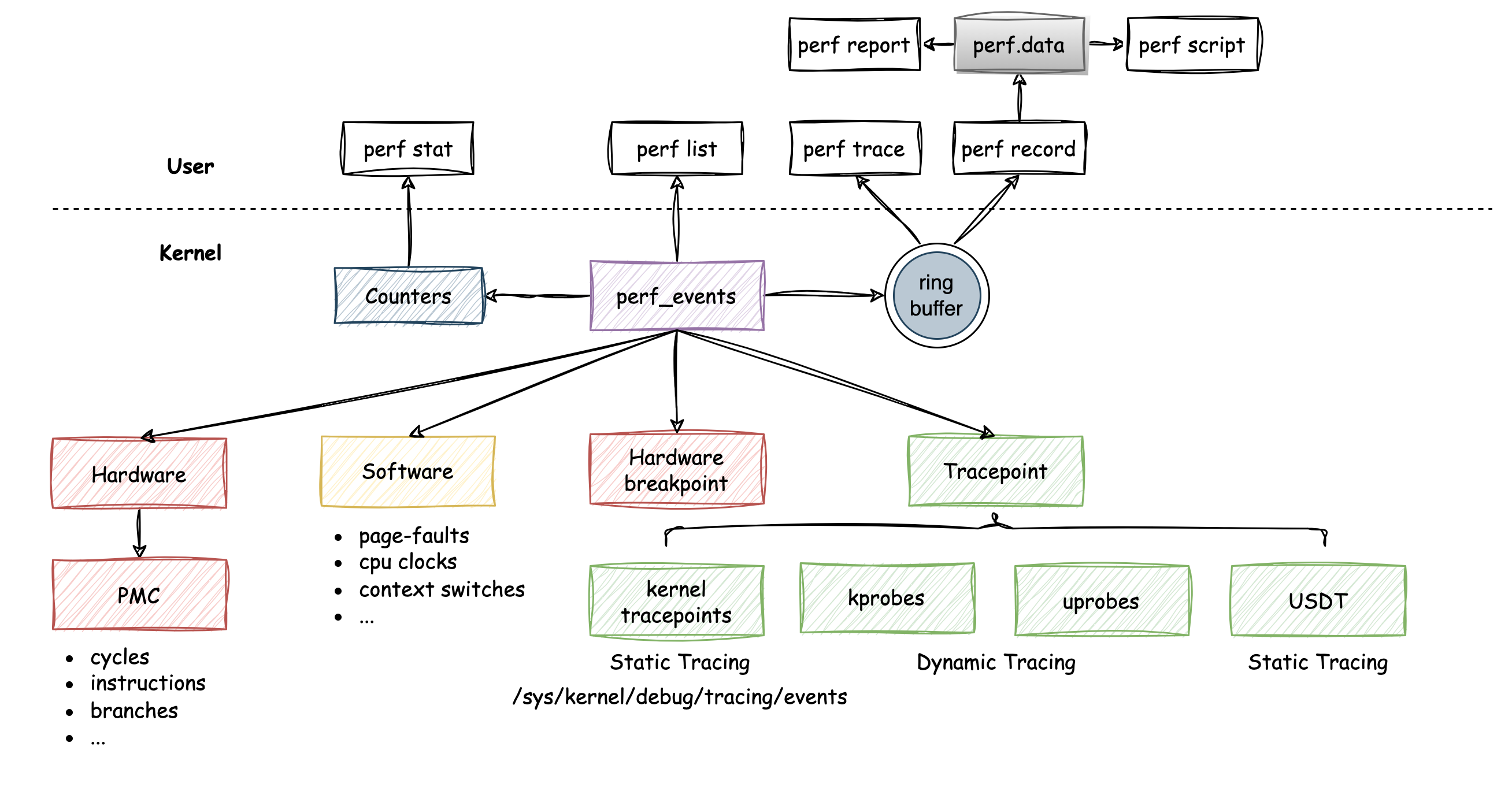
三、核心组件详解
1. 硬件层:Performance Monitoring Unit (PMU)
现代 CPU(如 Intel 的 PMU,ARM 的 PMU)内部都集成了专门的硬件单元,用于计数和采样。
- 性能监控计数器:一组特殊的硬件寄存器,可以配置为对特定事件(如“周期数”、“指令数”、“L3缓存未命中”)进行计数。
- 工作原理:
- 内核通过写 MSR 等特定寄存器来配置 PMC,告诉它“监视哪个事件”。
- PMC 在该 CPU 核上运行,事件发生时计数器加一。
- 当计数器溢出时,会产生一个性能监控中断,这是一个 NMI。
- 局限性:PMC 的数量是有限的(比如只有4个或8个),但需要监控的事件可能很多,所以
perf需要采用多路复用技术来时分复用这些硬件计数器。
2. 内核子系统:perf_events
这是 perf 架构的核心,位于 kernel/events/ 目录下。它通过 perf_event_open() 系统调用向用户空间提供服务。
关键功能:
-
事件抽象:
- 硬件事件:直接映射到 PMU 的事件,如
cpu-cycles。 - 软件事件:由内核模拟的事件,如
page-faults,context-switches。 - 跟踪点事件:内核中静态定义的钩子点,如
syscalls,sched子系统中的关键点。开销很小。 - 探针事件:动态追踪,包括:
kprobe:可以跟踪几乎任何内核函数。uprobe:可以跟踪用户空间程序的函数。
- 硬件事件:直接映射到 PMU 的事件,如
-
事件管理与多路复用:
当用户想要监控的事件数量超过硬件PMC数量时,perf_events会采用时间分片的方式轮流监控不同的事件。这会带来一定的误差,但对于宏观分析通常是可接受的。 -
缓冲区管理:
perf record工作时,内核需要高效地将采样数据(如调用栈、指令指针、时间戳)传递给用户空间。- 这是通过一个环形缓冲区 实现的。内核是生产者,用户空间的
perf工具是消费者。 - 为了减少系统调用开销,
perf使用mmap将这个环形缓冲区映射到用户空间,这样用户态工具可以直接读取数据,而无需每次都进入内核。
-
采样与溢出:
这是perf record工作的核心流程:- 用户通过
-c或-F指定一个采样周期(例如,每发生10,000次cpu-cycles事件采样一次)。 - PMC 被初始化为这个采样周期的负值(例如 -10000)。
- PMC 开始计数,当从 -10000 计数到 0 时,发生溢出,触发 PMI。
- 在 PMI 的中断处理程序中,内核会:
- 捕获当前的指令指针、进程ID、调用栈等信息。
- 将这些信息作为一个记录写入环形缓冲区。
- 重置PMC,继续计数。
- 用户空间的
perf工具从环形缓冲区中读取这些记录,并最终写入perf.data文件。
- 用户通过
3. 用户空间工具
这是用户直接交互的部分。perf 是一个庞大的工具集,遵循 perf <command> [<options>] 的语法。
核心命令分类:
-
采样分析:
perf record:录制性能数据到perf.data。perf report:解析并交互式地浏览perf.data。perf annotate:注解汇编代码和源码,查看热点指令。perf top:实时显示系统的性能热点,类似于top。
-
计数统计:
perf stat:运行一个命令,并汇总报告其运行过程中的各种事件计数。非常适合做宏观的瓶颈定位和基准测试。
-
追踪分析:
perf probe:动态创建 kprobe 或 uprobe。perf trace:类似于strace,但基于perf_events框架,性能更好。perf script:将perf.data中的记录以脚本可读的格式打印出来,便于后续自动化处理。
四、一个例子:perf record -g -F 99 的内部流程
- 命令行解析:
perf用户工具解析参数,知道要使用 99Hz 的频率进行 CPU 采样,并捕获调用栈。 - 系统调用:调用
perf_event_open()系统调用,为每个CPU核(或每个任务)创建性能事件。 - 内核配置:内核配置对应CPU核的PMU,设置采样周期为
cycles事件的 1/99 秒(如果以cycles为默认事件)。 - 内存映射:
perf工具使用mmap将内核的环形缓冲区映射到自己的用户空间。 - 开始监控:通过
ioctl命令启动计数器。 - 采样发生:
- PMU 计数溢出,触发 NMI。
- 内核的中断处理程序记录IP、PID、时间戳,并尝试展开调用栈。
- 将这条记录写入环形缓冲区。
- 用户空间读取:
perf工具在后台持续从环形缓冲区读取记录,并暂存于内存。 - 结束与写入:当用户中断时,
perf将内存中的记录、以及被采样程序的符号表信息一同写入perf.data文件。 - 报告分析:用户运行
perf report,该工具读取perf.data,解析符号,将采样点统计、归类,并以交互式TUI的形式展示出热点函数和调用关系。
五、perf 架构的优势
- 统一抽象:为不同的硬件PMU、软件事件、追踪点提供了一个统一的访问接口。
- 低开销:得益于内核集成和内存映射环形缓冲区,采样开销可以做到非常低。
- 功能强大:集成了 profiling、counting、tracing 多种分析模式。
- 深度集成:可以同时分析用户态和内核态,提供完整的系统视图。
六、学习建议
- 动手实践:从
perf stat,perf record/perf report开始,这是最常用的组合。 - 理解事件:使用
perf list查看你的系统支持哪些硬件、软件和追踪点事件。 - 阅读经典:Brendan Gregg 的博客和书籍是学习系统性能分析的宝库,他大量使用
perf。 - 查看源码:如果想深入内核机制,可以阅读 Linux 内核中
kernel/events/目录下的代码。
七、参考资料
- https://cloud.tencent.com/developer/article/2363303
- https://blog.csdn.net/pwl999/article/details/81200439
- https://web.eece.maine.edu/~vweaver/projects/perf_events/overhead/fastpath2013_perfevents.pdf
- https://classes.engineering.wustl.edu/cse522/man-pages/perf_event_open.2.pdf
- https://blog.spoock.com/2023/09/16/eBPF-event/
- https://hpcas.inesc-id.pt/~unify/papers/conf_asap23.pdf
- https://events.static.linuxfound.org/slides/2011/linuxcon-japan/lcj2011_linming.pdf
- https://www.usenix.org/sites/default/files/conference/protected-files/lisa14_slides_gregg.pdf
- https://web.eece.maine.edu/~vweaver/projects/perf_events/overhead/fastpath2013_perfevent_slides.pdf