中国网站设计师广州最专业的网站建设
文章结尾部分有CSDN官方提供的学长 联系方式名片
博主开发经验15年,全栈工程师,专业搞定大模型、知识图谱、算法和可视化项目和比赛
编号:F002
✅ usercf + itemcf 两种协同过滤推荐算法
✅ 豆瓣250数据可视化,多种echarts:包括交互式时间轴、词云、多种折线图、面积图、大数据图、滚动柱状图、饼图、水滴图等,提供全面的数据展示。
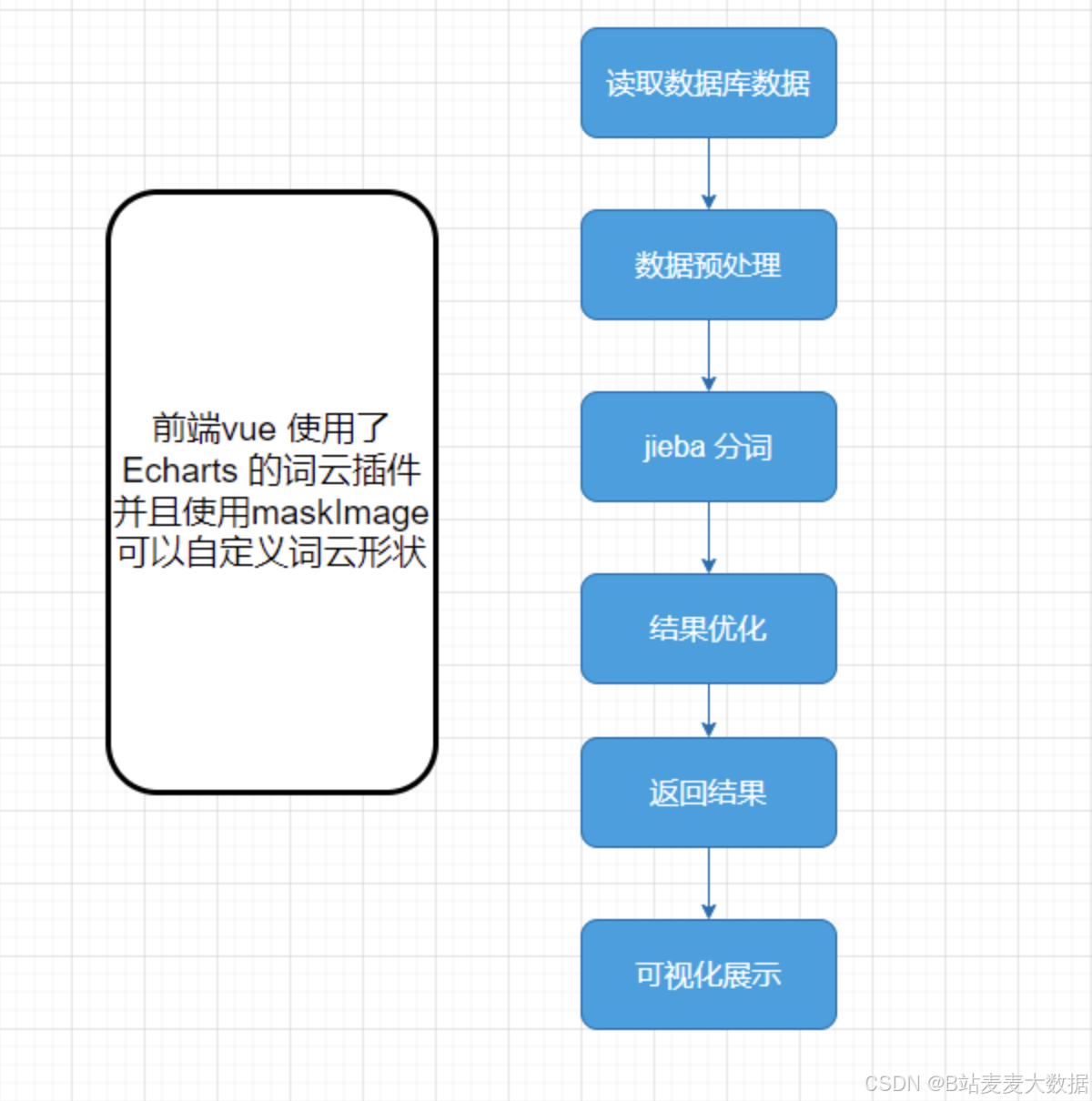
✅ 实现影片库搜索,jieba主题词分析,满足用户的多样化数据分析需求。
✅ 帅气界面,一辈子的事。
视频介绍
【推荐算法+可视化】最帅 vue+flask 电影大数据推荐算法与分析可视化平台python源码带爬虫+前后端分离+自适应移动端 +mysql
系统介绍 ✨
随着电影行业的发展,如何高效获取和分析电影数据成为了电影爱好者和研究者的重要需求。传统的手工数据收集和分析方法不仅耗时费力,而且难以应对庞大的数据量和复杂的分析需求。因此,开发一套高效的数据采集、存储和可视化系统显得尤为必要。
本系统旨在通过自动化爬虫技术获取豆瓣电影Top250数据,并结合前沿的数据可视化工具,为用户提供一个功能强大、易于使用的电影数据分析平台。通过前端Vue与后端Flask的结合,实现电影数据的全面分析和展示,帮助用户快速洞察电影行业趋势,满足多样化的数据分析需求。
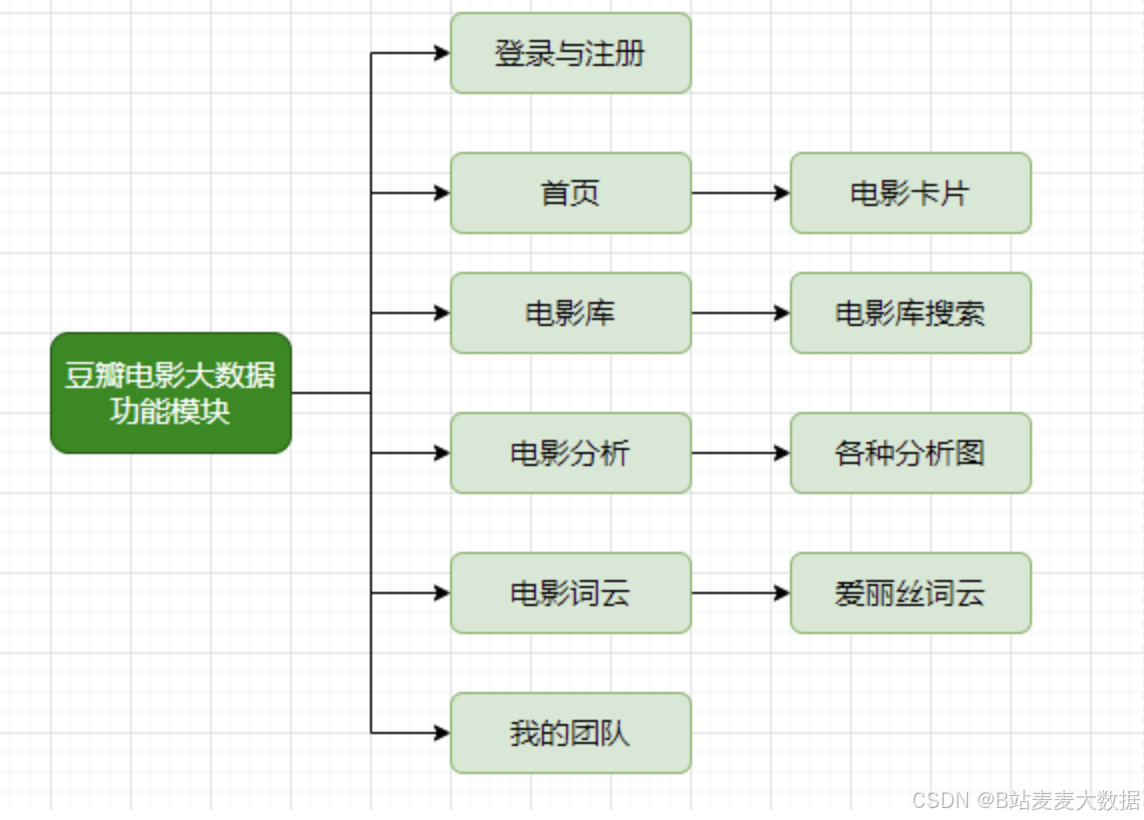
1. 系统功能 👍
- 数据采集:系统能够读取豆瓣电影Top250数据,解析后存储到MySQL数据库中,确保数据的完整性和可靠性。
- 数据可视化:利用Flask开发接口,对接Vue前端,实现对电影数据的可视化分析,包括多种Echarts图形和词云展示,提供直观的视觉效果。
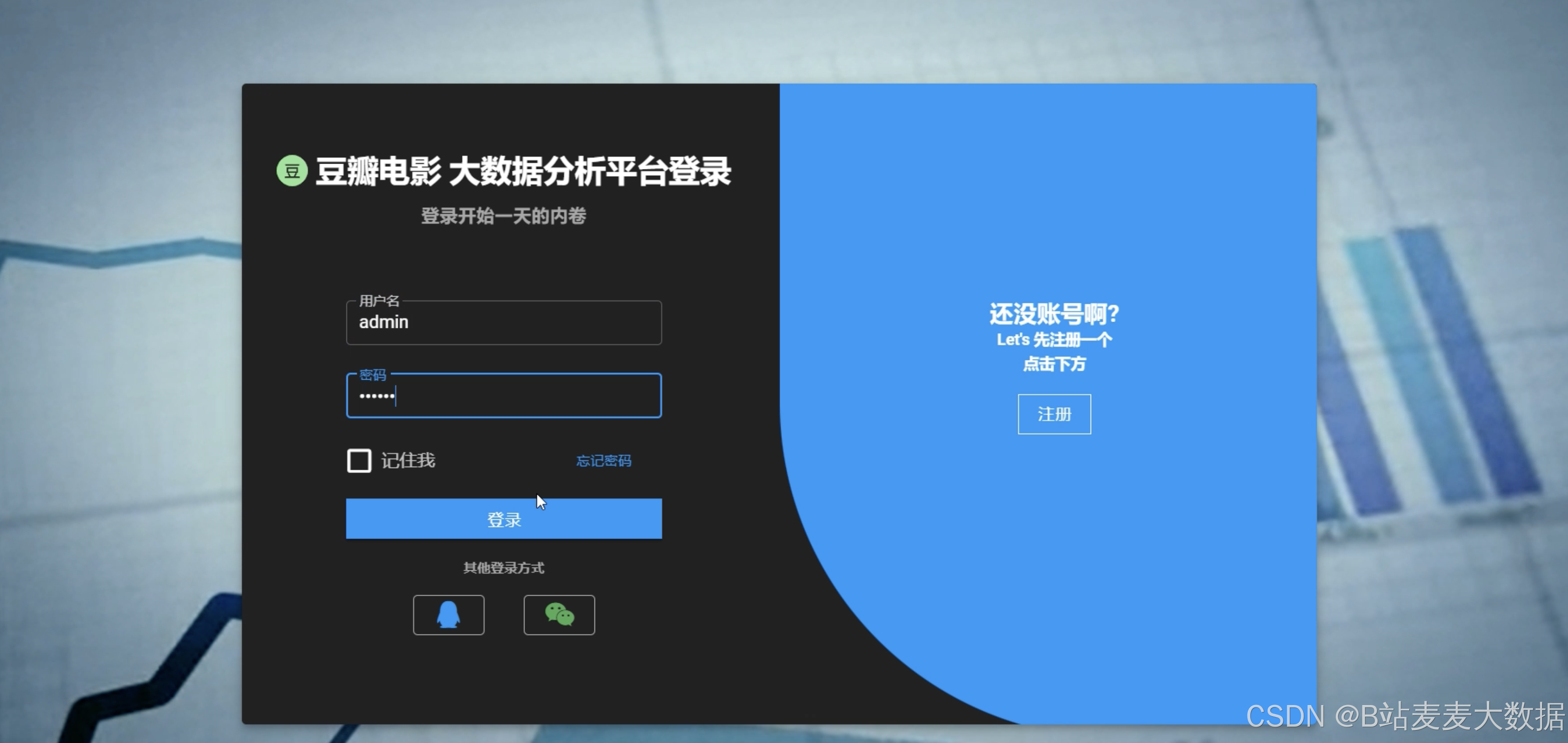
- 用户认证:系统支持用户登录和注册功能,保障数据的安全性和用户的个性化需求。
2. 系统亮点 ⭐
- 专业设计:由专业美工整体设计的细腻酷黑主题,前后端分离一体化系统(爬虫→MySQL→Flask→Vue),提供统一且美观的用户界面。
- 多样分析:实现影片库搜索,支持多种Echarts图形分析和jieba分词分析,满足用户的多样化数据分析需求。
- 自适应设计:系统完全responsive自适应,自动适配H5移动端,保证在不同设备上的良好显示效果。
- 动感界面:卡片式登录页面和大数据Style动画,提升用户的交互体验和视觉享受。
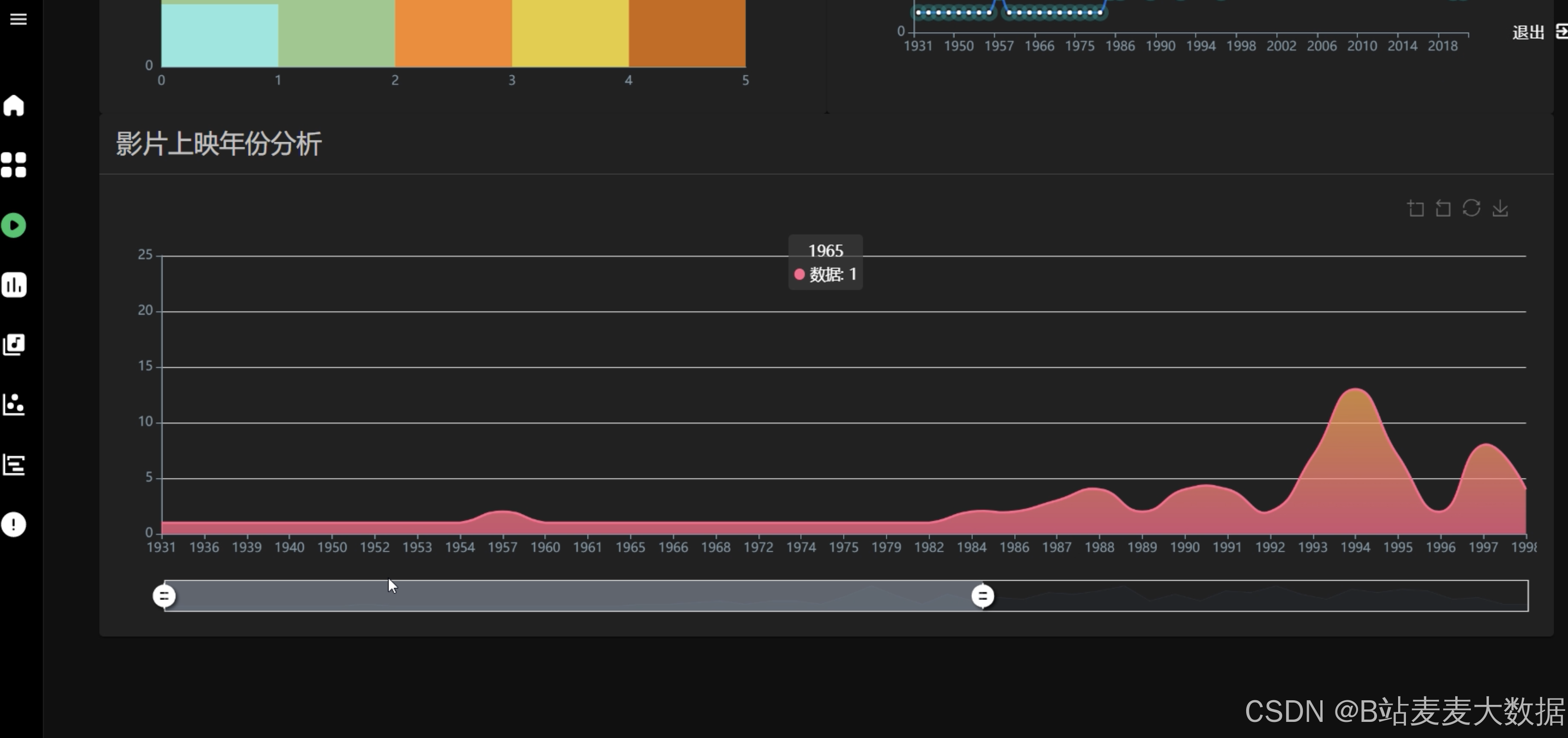
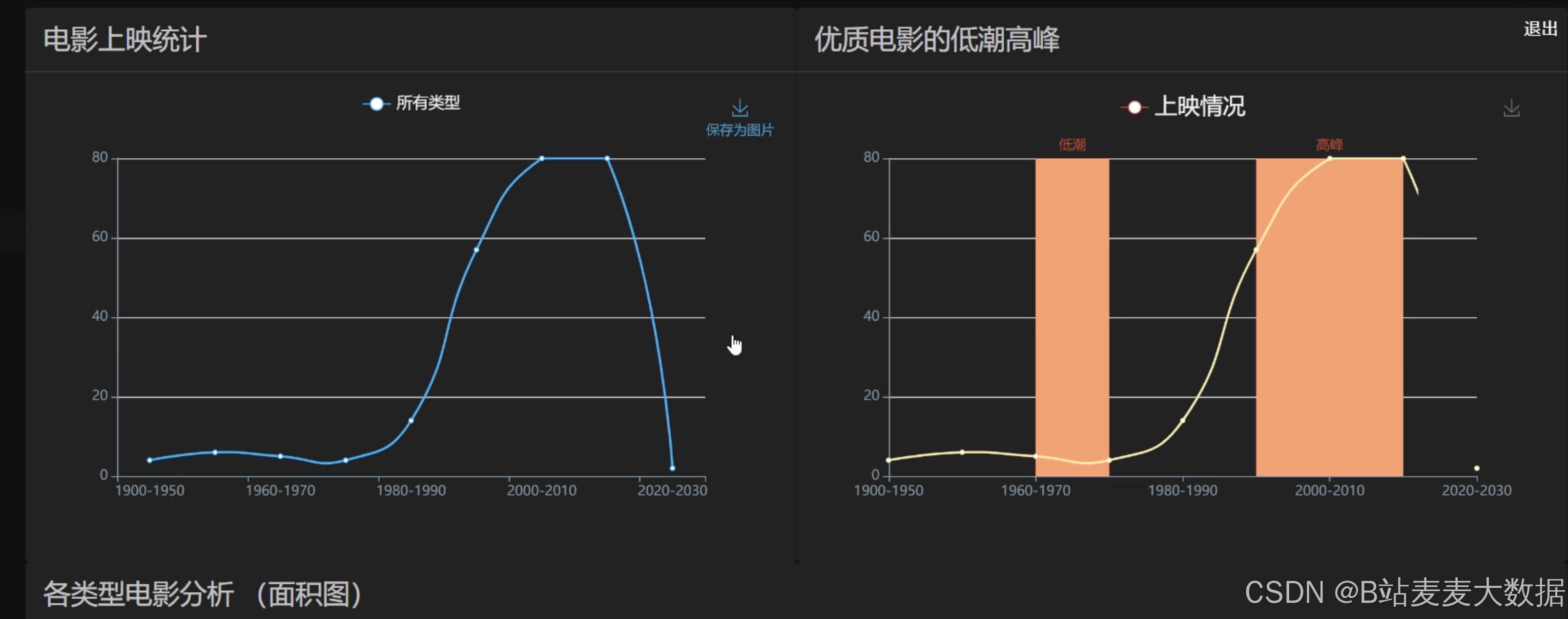
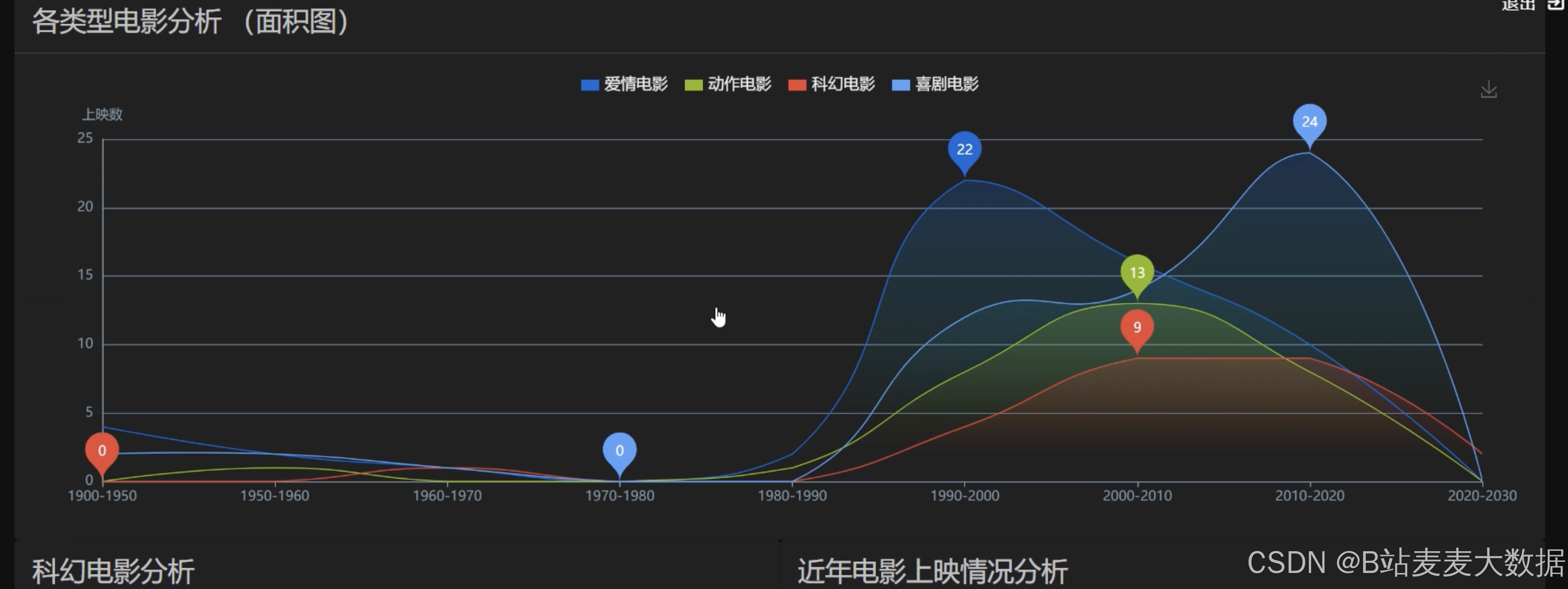
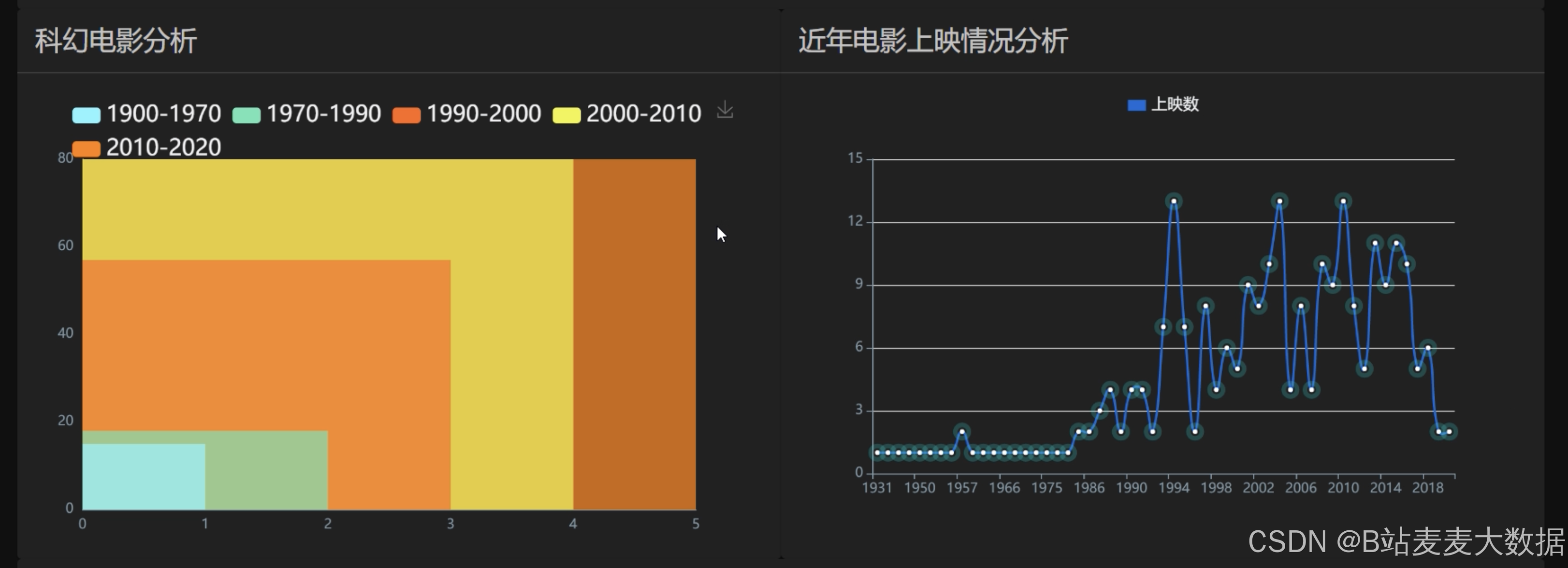
- 丰富图表:实现多种分析图表,包括交互式时间轴、词云、多种折线图、面积图、大数据图、滚动柱状图、饼图、水滴图等,提供全面的数据展示。
通过这一系统,用户可以轻松获取和分析电影数据,快速掌握电影行业动态,为电影研究和商业决策提供有力支持。 🎬📊
3 相关图片 ⚒️
- 架构图
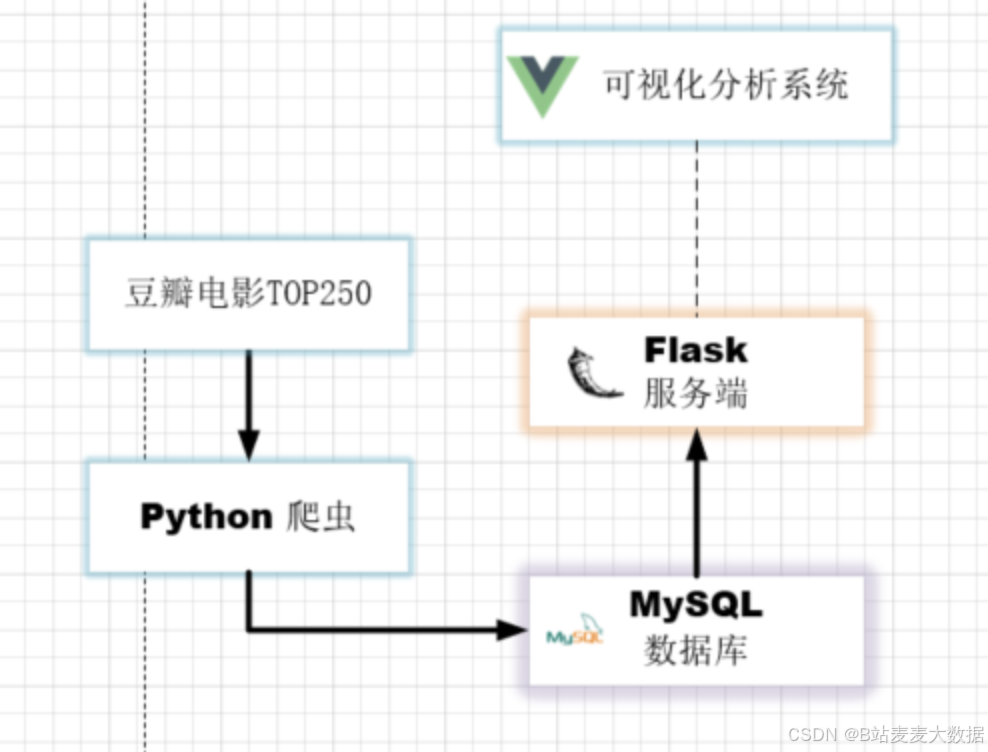
- 功能模块图
- 词云的逻辑
登录&注册
电影推荐,usercf+itemcf两种协同过滤推荐电影
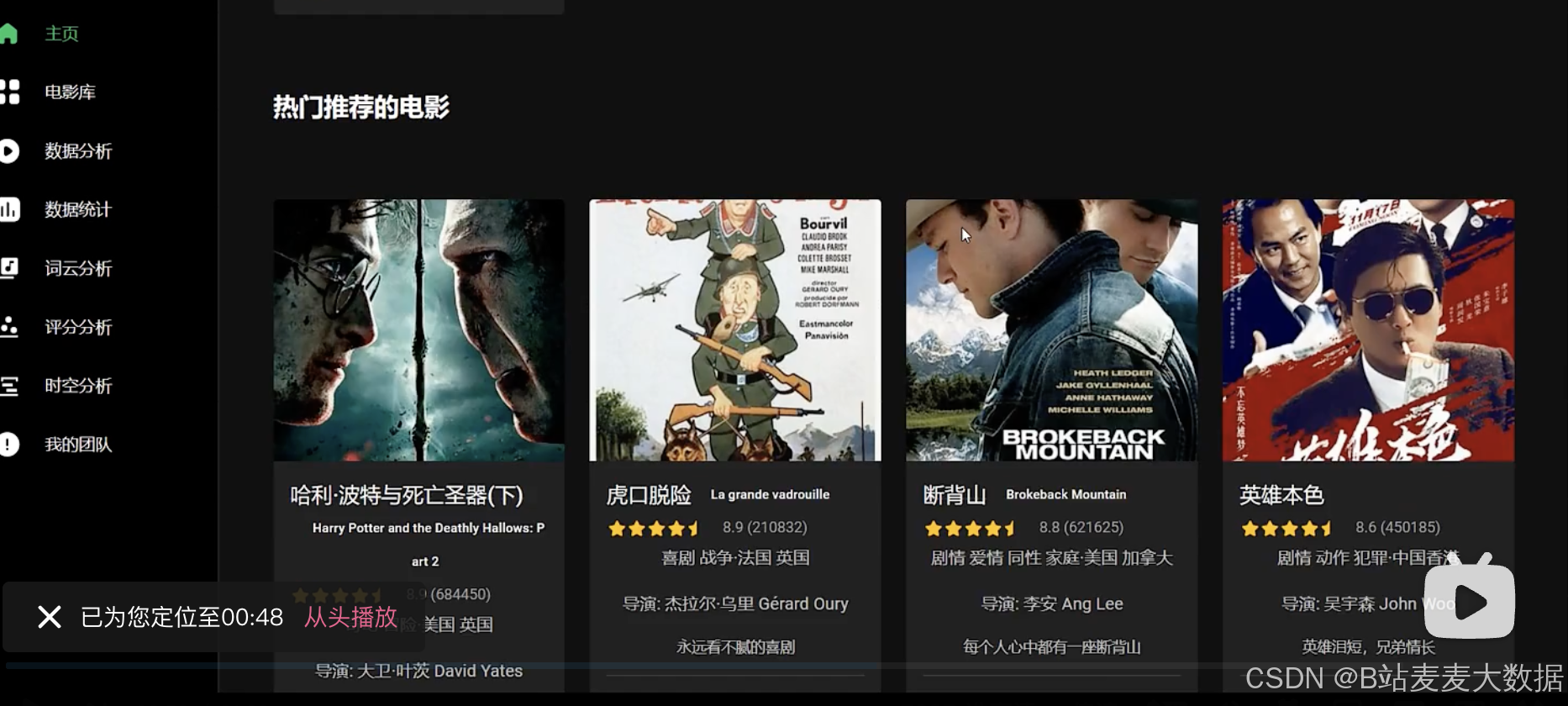
电影库,可以根据关键词进行搜索
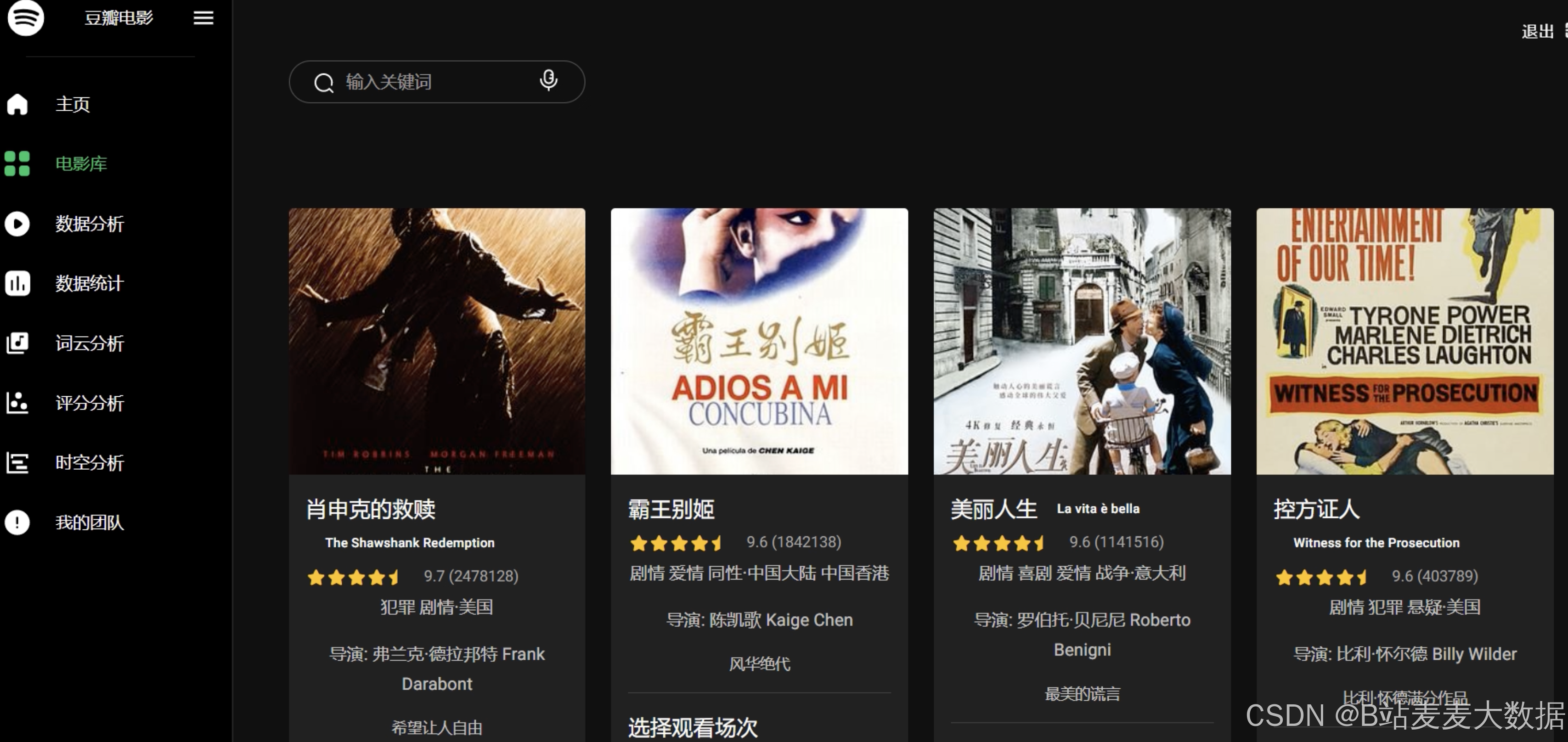
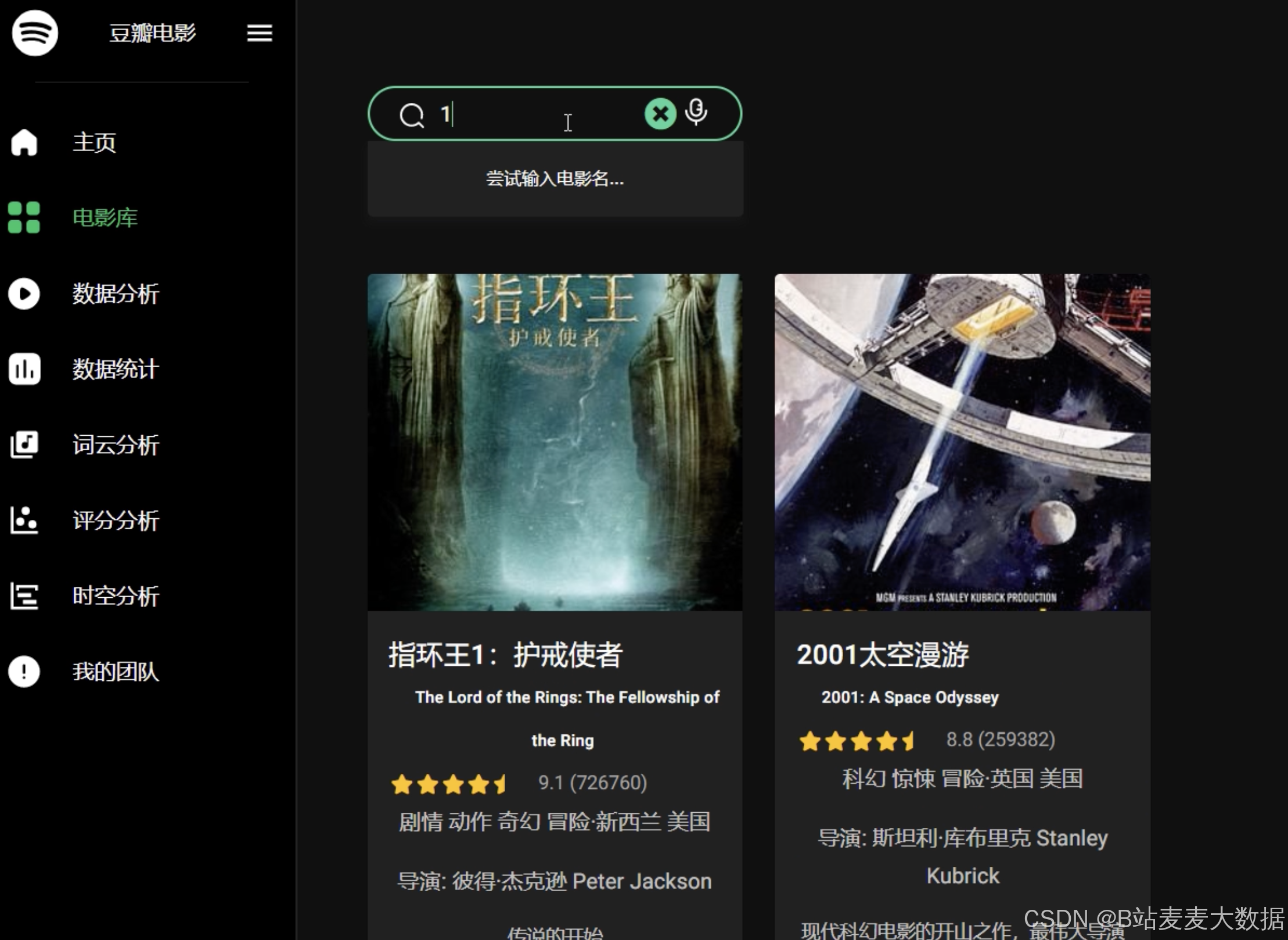
可视化功能
词云分析(jieba分词)

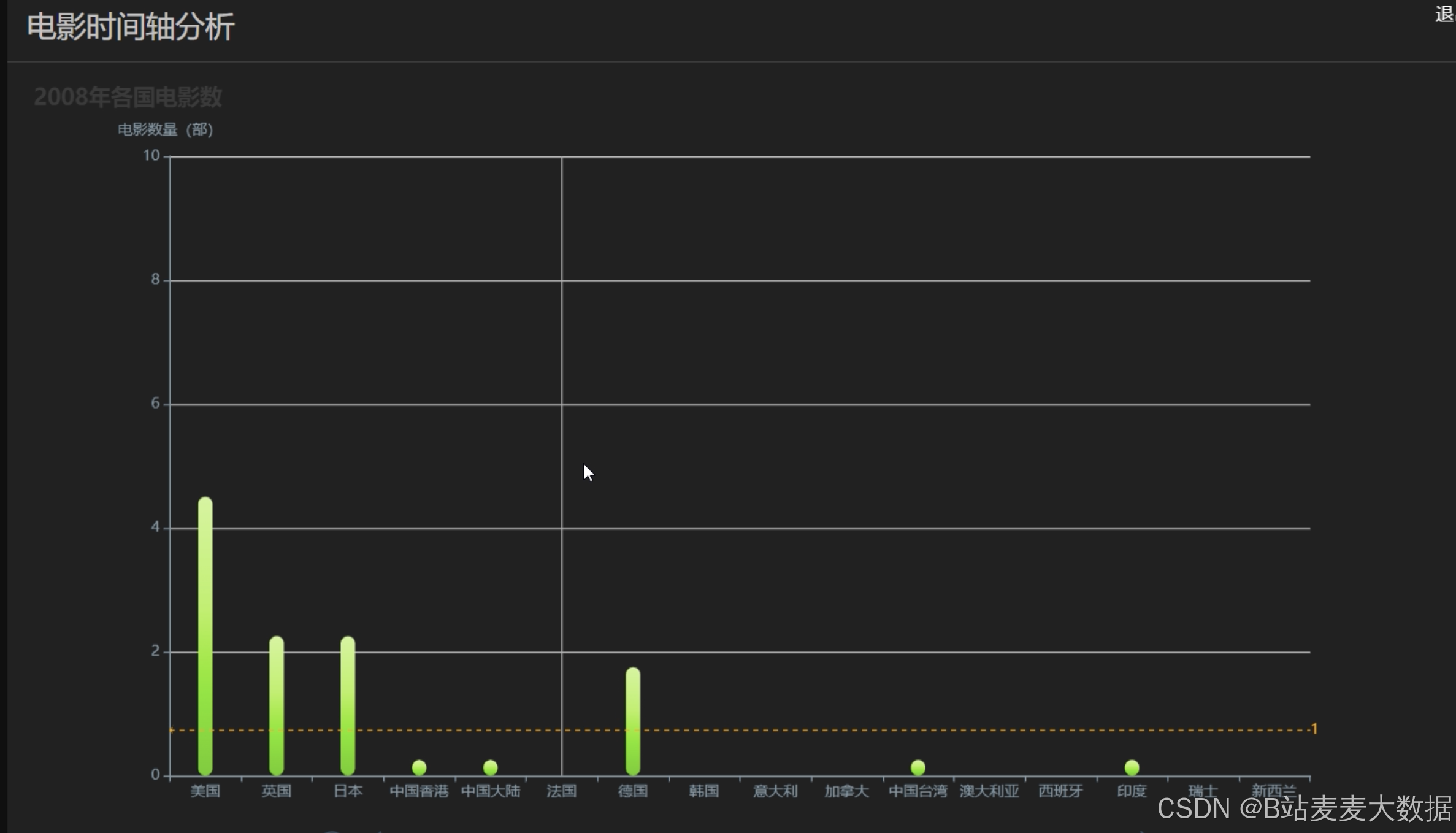
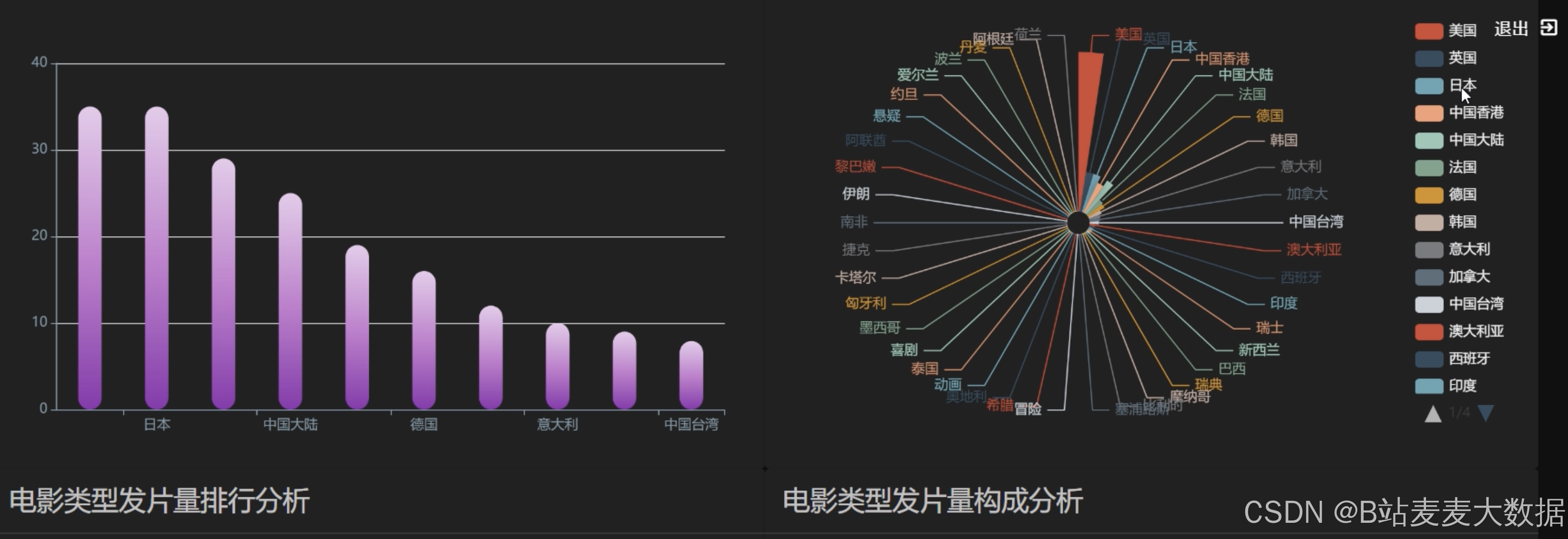
出品国家分析

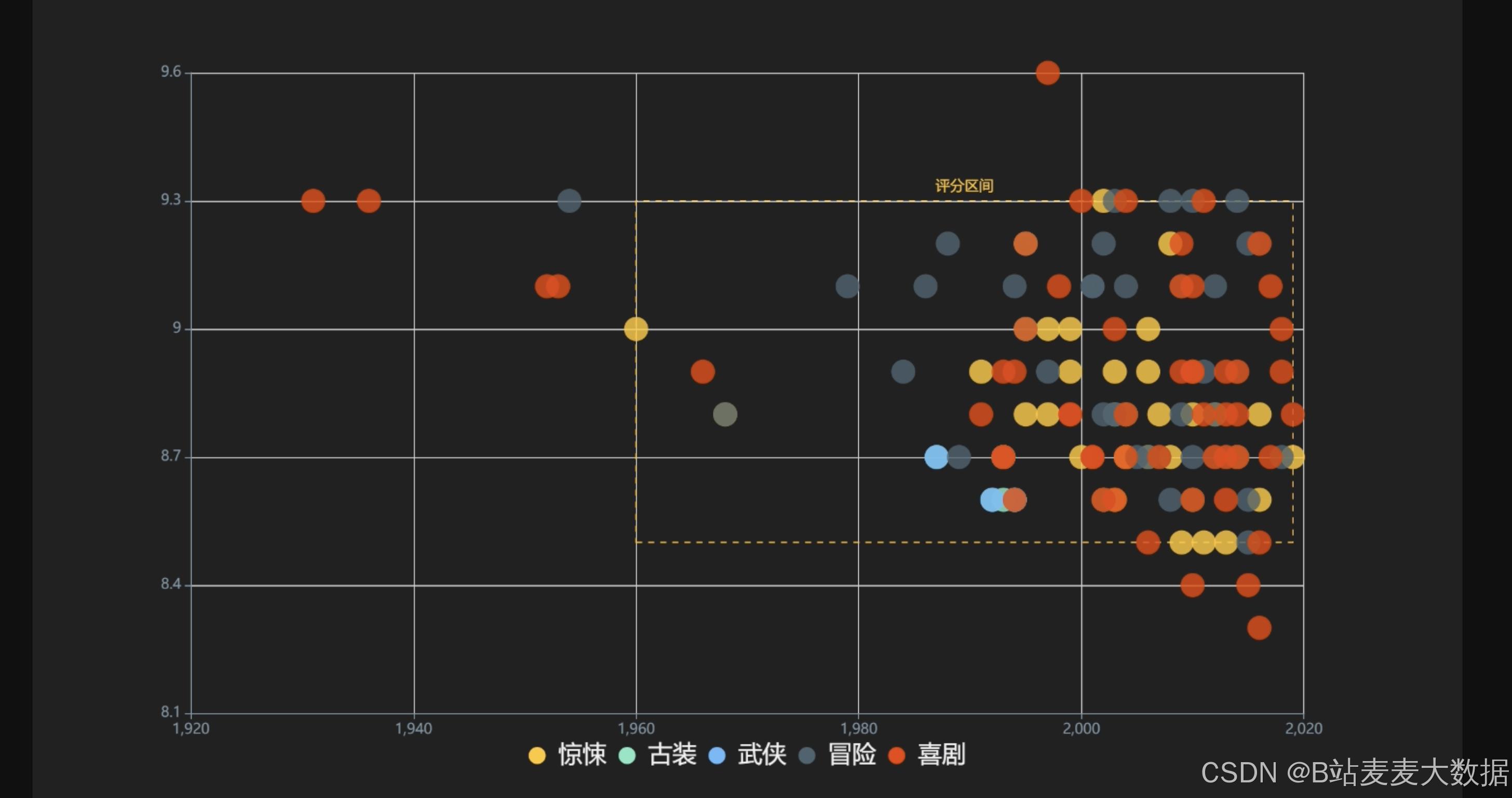
散点图分析
时间轴
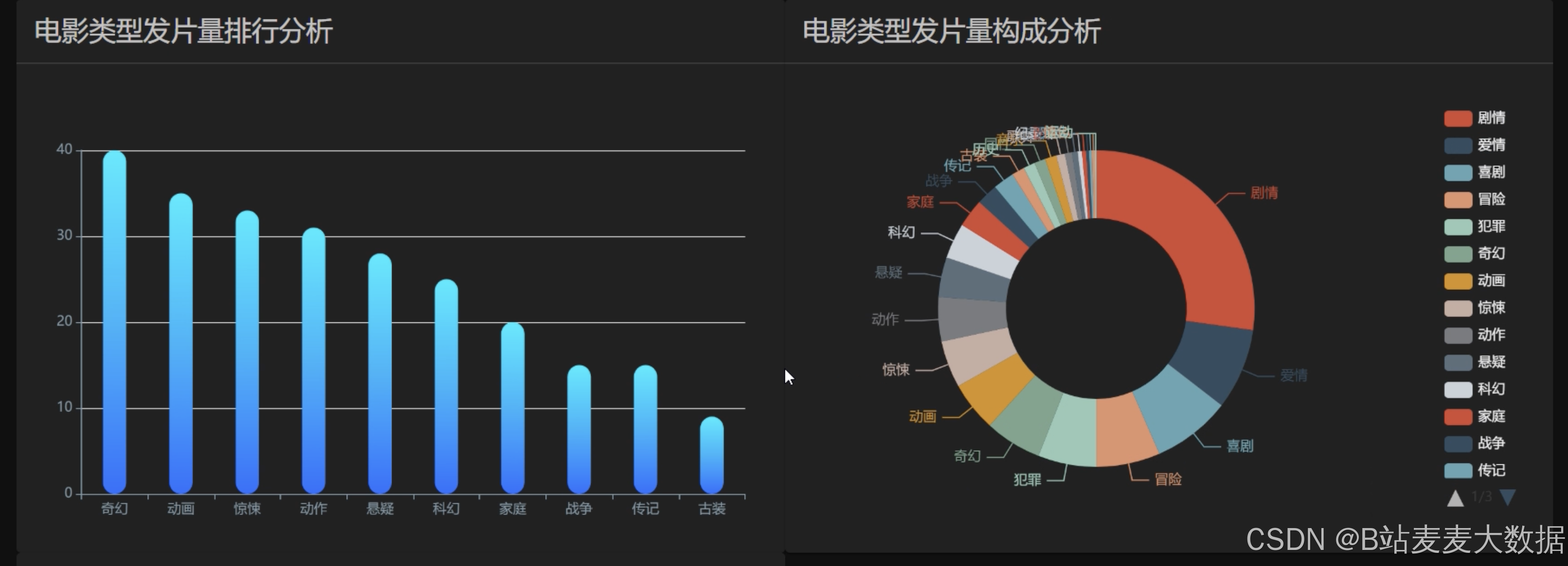
其他各种echarts的图形,比如柱状图、折线图等
4 开发环境和关键技术 🧬
- 服务端技术:Flask SQLAlchemy Blueprint 等
- 前端技术:Vue Echarts 等
- 爬虫技术: bs4 re 等
- 数据库:mysql
- 开发语言: Python 3.8 Vue 2.x
- 集成开发环境: WebStorm 2021.2.2 Windows 10
import pandas as pd
from surprise import Dataset, Reader, KNNBasic
from surprise.model_selection import train_test_split
from surprise import accuracy# 加载数据
def load_data(csv_path):data = pd.read_csv(csv_path)return data# 将数据转换为 Surprise 所需的格式
def to_surprise_data(data):reader = Reader(rating_scale=(0.5, 5.0)) # 豆瓣评分范围一般是 0.5 - 5.0return Dataset.load_from_df(data[['user_id', 'movie_id', 'rating']], reader)# 定义用户-物品协同过滤
def user_based_collaborative_filtering(data, user_id, movie_id, k_neighbors=20):# 转换数据格式surprise_data = to_surprise_data(data)# 分割训练集和测试集trainset, testset = train_test_split(surprise_data, test_size=0.25)# 使用 KNN(基于用户相似度)sim_options = {'name': 'cosine', # 相似度计算方式'user_based': True # True 表示用户-物品协同过滤}model = KNNBasic(k=20, sim_options=sim_options)model.fit(trainset)predictions = model.test(testset)# 输出测试结果(RMSE)print("RMSE:", accuracy.rmse(predictions))# 预测特定用户对特定电影的评分prediction = model.predict(user_id, movie_id)print(f"预测用户 {user_id} 对电影 {movie_id} 的评分为: {prediction.est:.2f}")# 为用户推荐 Top-N 电影top_n = recommend_movies(model, data, user_id, n=10)print(f"为用户 {user_id} 推荐的 Top 10 电影为:")for i, (movie_id, rating) in enumerate(top_n[:10], 1):print(f"{i}. 电影ID: {movie_id}, 预测评分: {rating:.2f}")# 为用户推荐 Top-N 电影
def recommend_movies(model, data, user_id, n=10):# 获取所有电影IDall_movie_ids = data['movie_id'].unique()# 获取用户已经评分过的电影rated_movies = data[data['user_id'] == user_id]['movie_id'].unique()# 找出未评分的电影unrated_movies = [m for m in all_movie_ids if m not in rated_movies]# 预测评分predictions = [model.predict(user_id, movie_id) for movie_id in unrated_movies]# 根据预测评分排序predictions.sort(key=lambda x: x.est, reverse=True)# 返回 Top-N 的预测结果return [(pred.iid, pred.est) for pred in predictions[:n]]# 主函数
if __name__ == "__main__":# 请替换为你的豆瓣电影评分数据CSV路径data_path = "douban_ratings.csv"user_id = 1movie_id = 100ratings_data = load_data(data_path)user_based_collaborative_filtering(ratings_data, user_id, movie_id)