分布式与长序列attention
flash attention
下文叙述的分布式场景长序列attention都是基于单卡的flash attention,flash attention之前介绍过,详见:
flash attention
flash attention 2
Blockwise Parallel Transformers(BPT)
这一篇和分布式没啥关系,不过和RingAttention是同一个作者,所以顺便看了一下。
长序列场景下,attention和ffn的激活值占用显存会变大,现有工作主要关注attention的显存,该论文解决的是ffn的激活值优化。
fa计算过程为
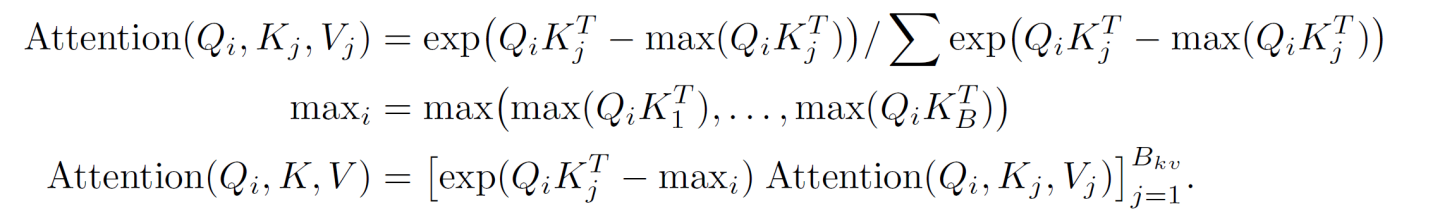
BPT的想法是fa中通过Qi计算得到的Oi可以直接和后续ffn进行融合,不用等fa完全计算完成,这样可以减少访存,并且减少激活值内存。伪代码如下

显存占用由8bsh降为2bsh,因此BPT认为可以将序列扩为原来的2-4倍。
RingAttention
RingAttention有点像多卡版本的flash attention,如下图b所示,卡间在Q维度并发,即外层循环。
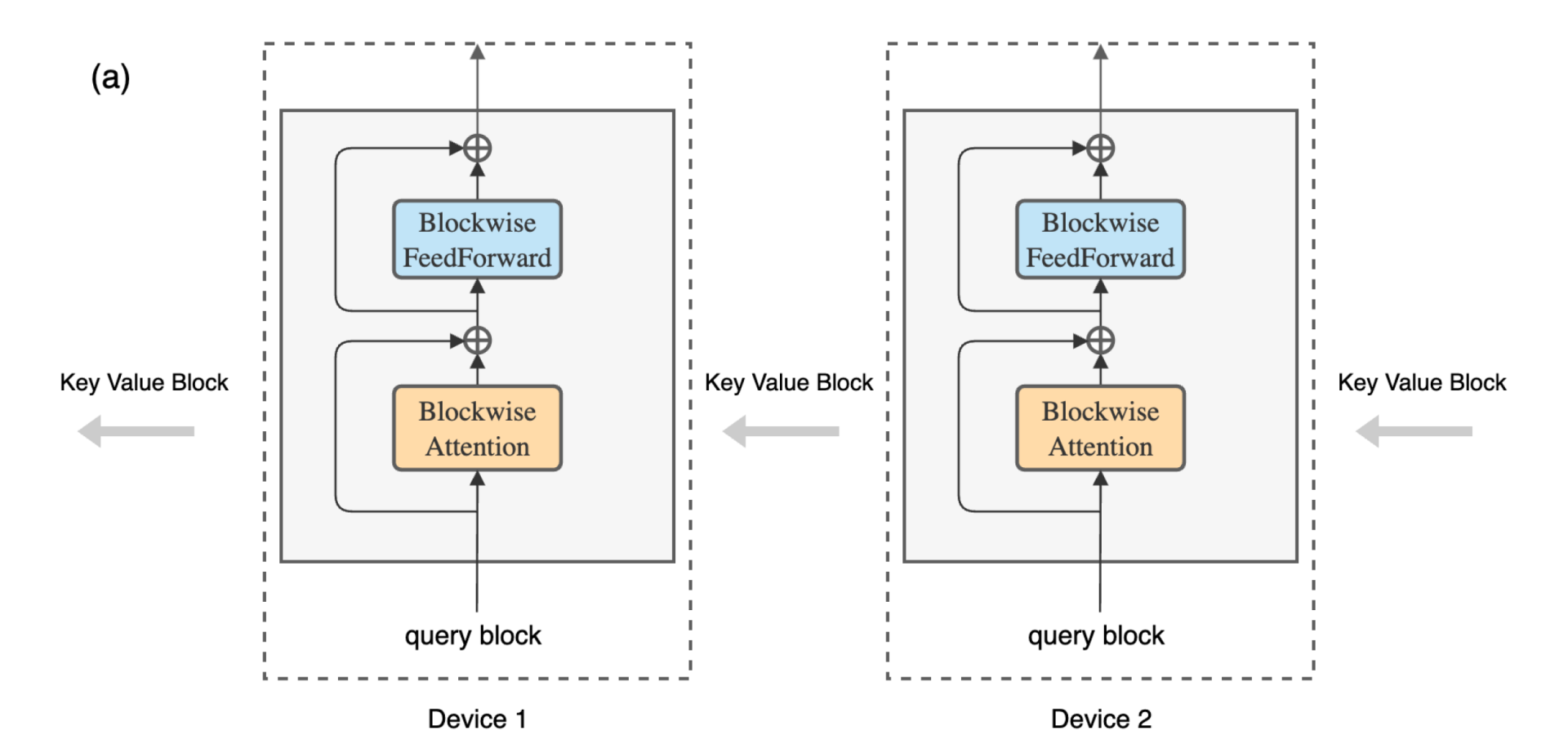
通过序列并行,每个卡保存原始Q的一个block Qi和对应的KVi,所有卡组成一个环,当rank[i]计算Qi的attention时,同时将自己的KV发送给rank[next],并从rank[prev]获取KV,理想场景下KV的通信和单卡计算attention可以overlap。伪代码如下

因为每次计算的都是一个block的attention,因此每次计算得到的O block也需要类似flash attention的方法进行scale以得到最后的结果。
假设序列长度为N,所有head的hidden总和为d,P个GPU,那么通信量为N * d * (P - 1) / P。
DeepSpeed Ulysses
还是假设P个GPU,seq长度为N,总的hidden维度为d。
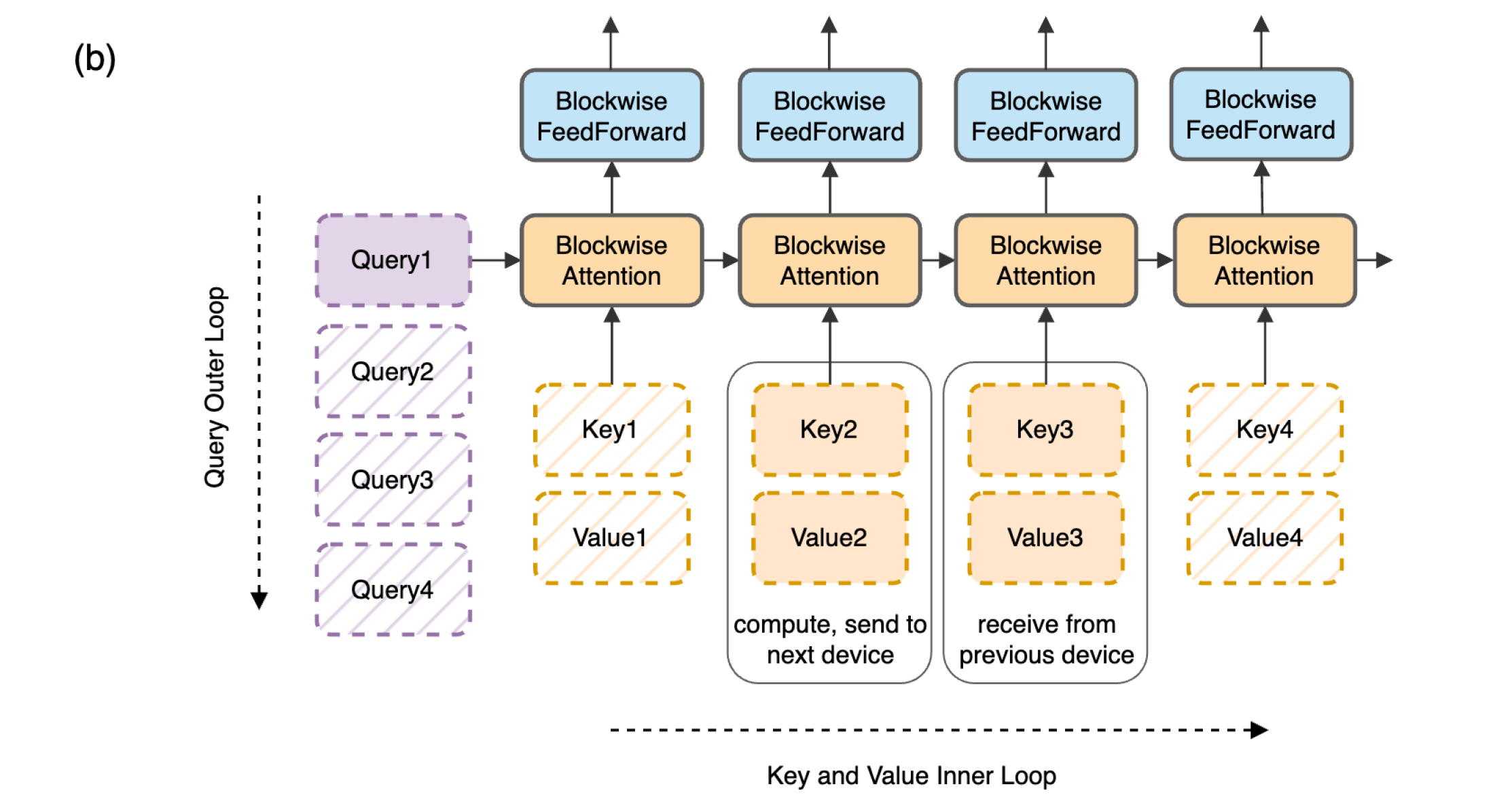
输入X的shape为[N, d],按照序列并行切分到所有的GPU,一个GPU对应的X维度为[N / P, d]。ulysses不对模型做切分,每张卡保存所有完整模型,即Wq,Wk,Wv,维度均为[d, d],因此每张卡可以独立计算得到QKV分块,shape均为[N / P, d]。然后开始对QKV分块分别执行all2all,此时每张卡维护的Q的shape为[N,d / P],相当于一张卡维护了整个序列对于部分head的结果,因此Ulysses的缺点很明显,扩展性限制于head数,另外all2all多机的话会引入非同号网卡的通信。
all2all之后每张卡独立计算自己维护的QKV分块的fa结果P,最后通过一次all2all恢复为shape [N / P, d]。
对于通信量,正向反向一共需要8次all2all,单词通信量为(N * d) / P,另外这些all2all可以进行overlap。
Unified Sequence Parallelism(USP)
SP-Ulysess在attention的head维度切,并行度不能超过attention head数,尤其在GQA或者MQA场景,例如llama3-8B使用GQA,head数为8,因此sp degree最多为8。如果使用MQA,head数为1,那么将无法使用ulysses。
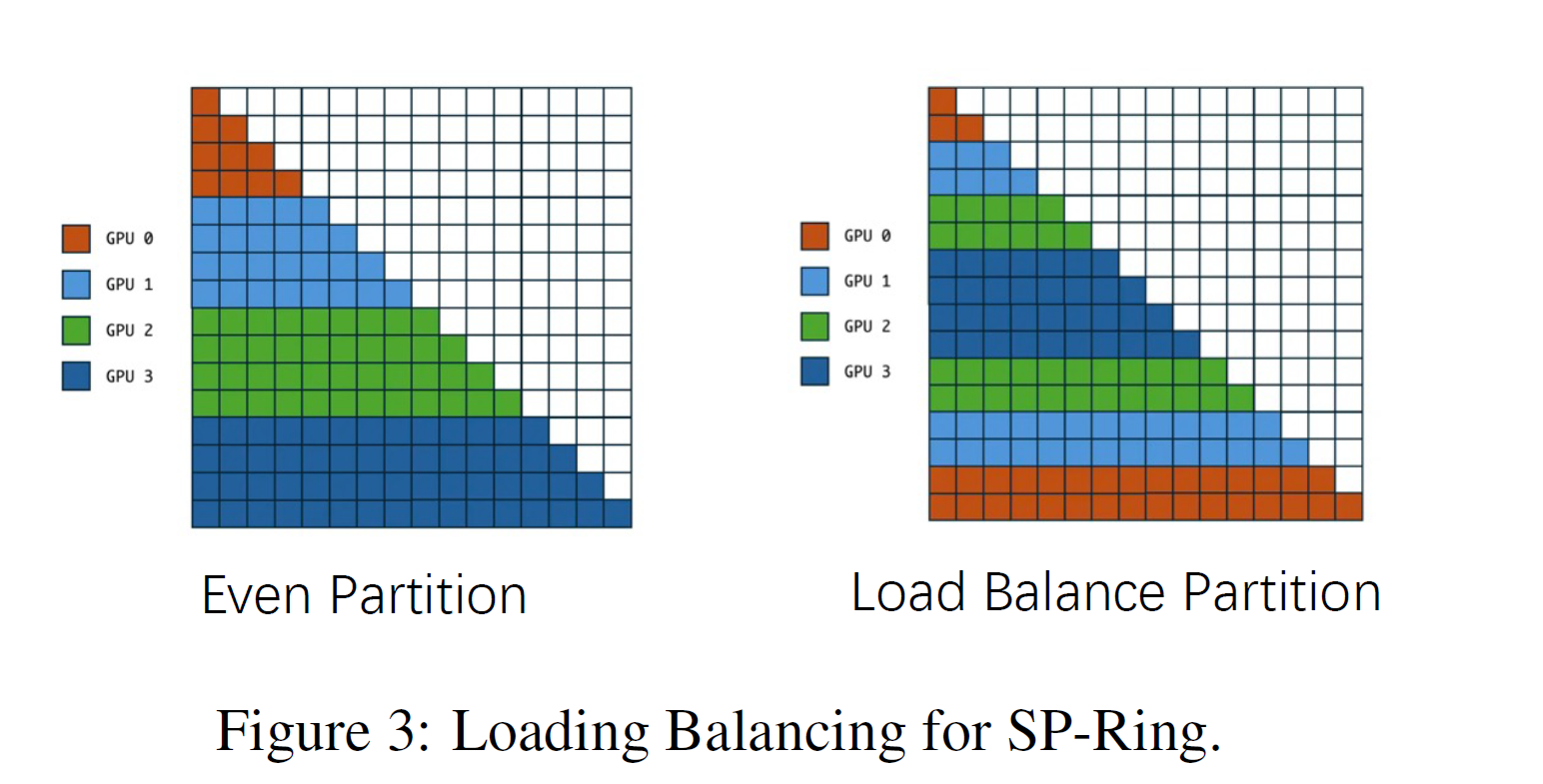
SP-Ring对Q进行切分,可能会导致切分过小导致计算效率低,即使通信和计算完美的overlap,可能整体耗时也是变长的,另外sp-ring还有负载均衡的问题。
因此作者提出usp,将ulysess和ring进行混合并行,是正交的两个维度。
整体算法流程如下


下图展示了算法过程,假设一共四张卡,4个Q block,两个head,图中一个正方形表示一个head的一个Q block,GPU0和GPU1组成SP-Ulysses,同理GPU2和GPU3。GPU0和GPU2组成SP-Ring,同理GPU1和GPU3。
初始状态为A,每个GPU拥有一个Q block的所有head。
如B所示,开始执行SP-Ulysses,通过对QKV block的all2all,每个GPU获取到SP-Ulysses组的所有token的一个head的数据。
如C所示,开始执行SP-Ring,通过环形通信,每个GPU计算得到两个Q block一个head的O block。
如D所示,最后执行对O block的all2all,每个GPU获取到一个block所有head的O。
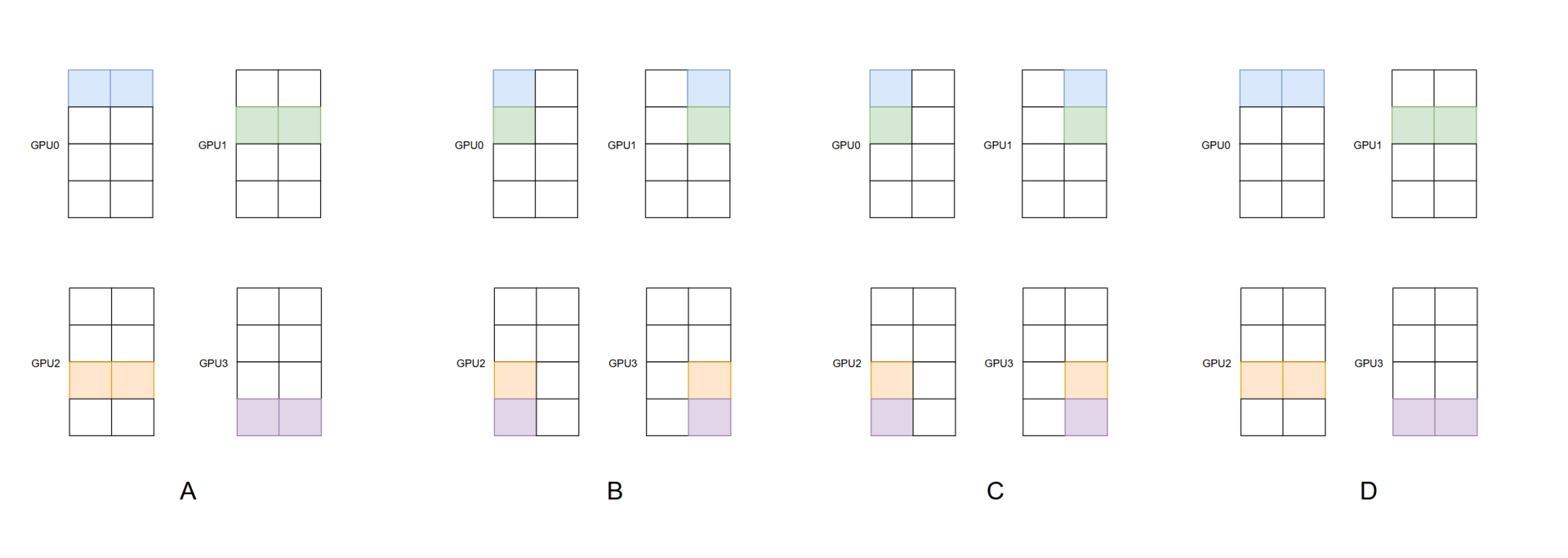
下图左侧的切分方式,比如GPU0,维护了Q[0 - 3],那么对于KV[4]之后的不会再进行运算,这会导致负载不均衡,因此USP重新分配了Q block的分配方式,缓解这一问题。
MagiAttention
视频场景下transformer有如下问题
- seq会达到4M级别,现有CP方案会有规模限制,或者通信开销大,导致扩展性问题
- 复杂的mask导致现有算子无法高效处理
因此sandai提出了如下方案:
- Flex-Flash-Attn(FFA)
- Comp Load-Balance
- Zero-Redundant Comm
- Multi-Stage Overlap
Flex-Flash-Attn(FFA)
对于复杂mask的场景,原生fa支持有限,sandai的做法是将mask切分为(Qrange, Krange, MaskType)组成的AttnSlice,如下图所示
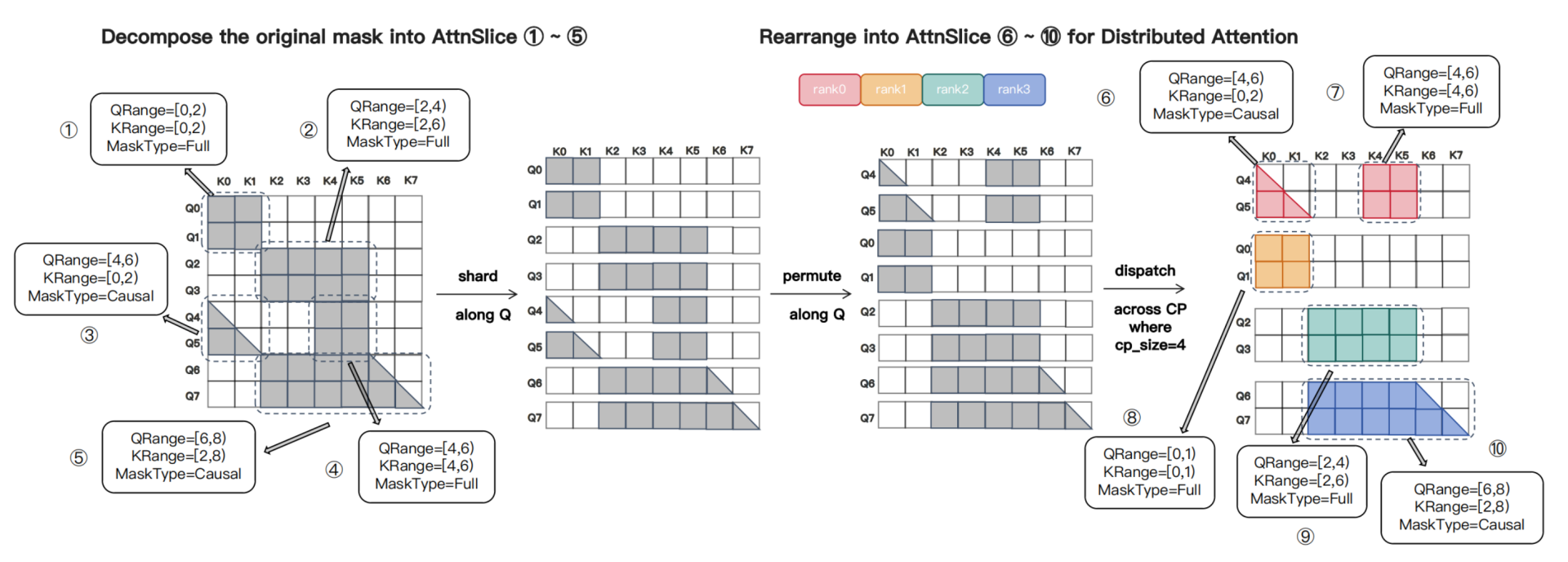
Comp Load-Balance
ringattention对于causal mask可以做到负载均衡,但是在复杂mask场景下,ringattention的切分策略会导致负载不均衡。
问题具体化为,n个Q chunk,分配给cp_size个桶,每个桶的chunk数相等(保证token粒度的平衡),最小化最大的桶的mask area。
这个问题为NP-hard,sandai提供了一个贪心解法,如下,将chunk按照area排序,然后分配给优先队列中的桶。

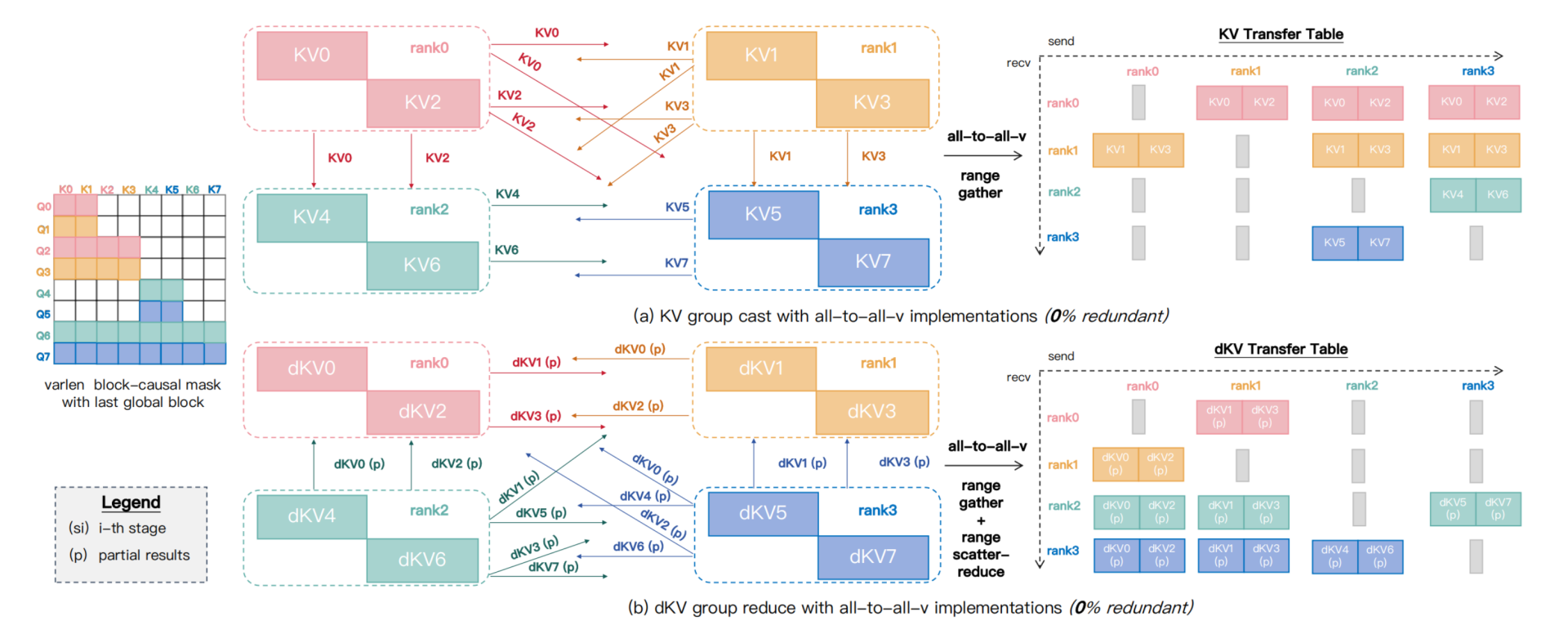
Zero-Redundant Comm
现有方案都是基于ring-attention,使用p2p原语进行通信,这会导致冗余通信,以causal mask为例会导致25%的冗余通信,如下图a所示,KV0被所有rank需要,因此他需要被广播到所有rank,反向时dKV0需要执行allreduce。但是对于KV7,是不需要任何通信的,但是在ring-attention中,还是被环形通信了一圈。进一步的,对于不规则的mask,会进一步加剧,如下图B,会导致33%的冗余通信。
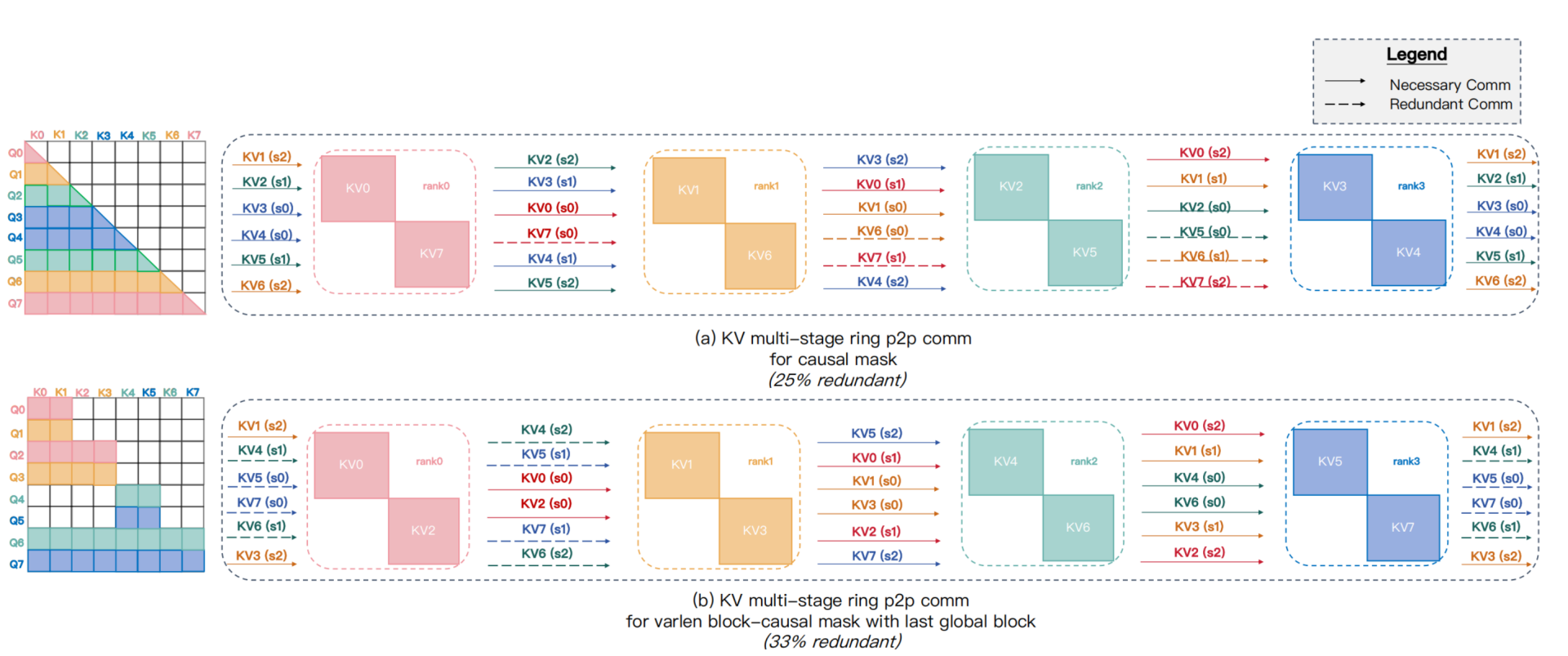
为了解决这个问题,sandai基于nccl的all2allv设计了Group-Cast和Group-Reduce语义,还是对于上图causal mask的场景,只有Q6和Q7才需要rank2的KV5,因此rank2的KV5只需要通过Group-Cast广播到rank0和rank1。
具体的,如下图所示,Group-Cast原语中会通过range gather构建一个KV transfer table,然后执行nccl all2all原语,反向同理,还是range gather构建KV transfer table,执行all2all之后通过range reduce对多个节点传输回来的数据进行求和(不过联想到DeepEP,这里的mask或者transfer table和EP的topk本质一样,因此也可以尝试使用DeepEP的方式进行优化,减少通信量,fuse reduce kernel)。
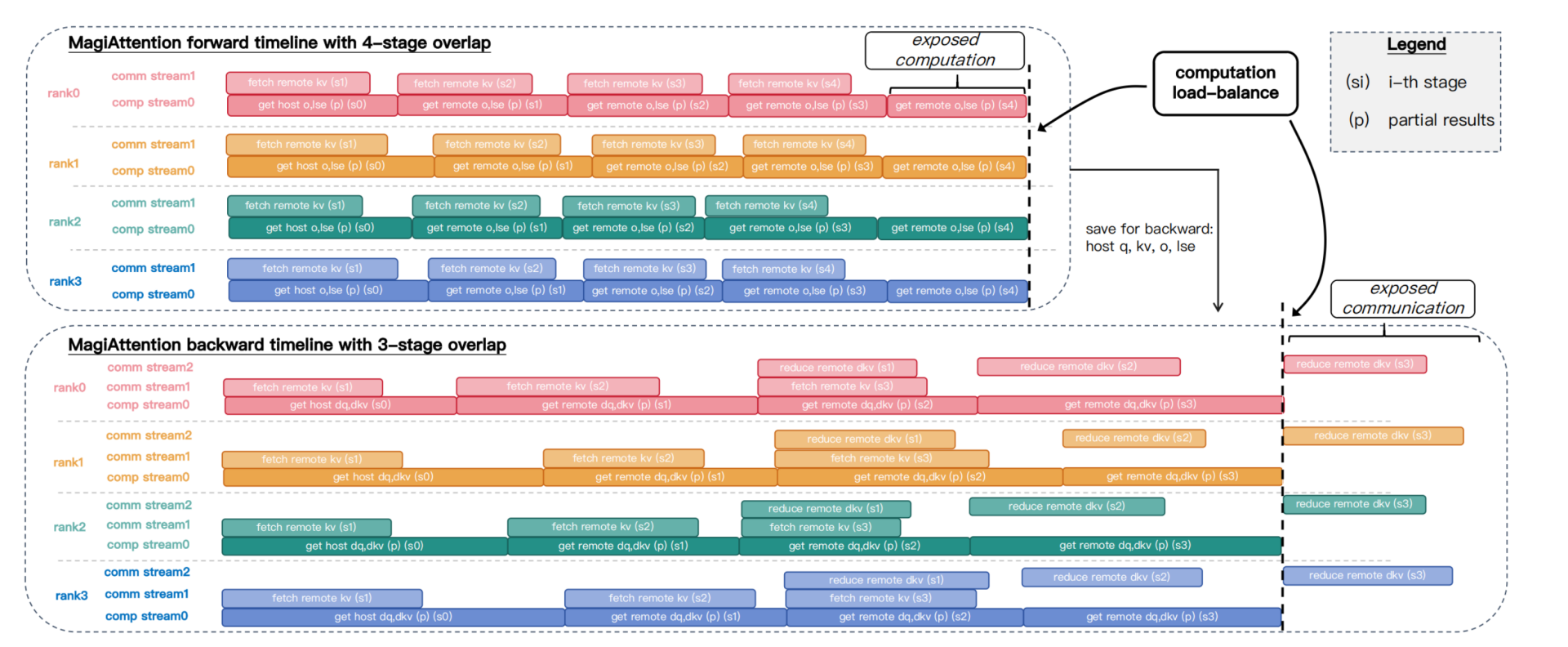
Multi-Stage Overlap
在零冗余的通信算子基础上,sandai设计了通信计算overlap的multi-stage方案,每个rank将remote KV/dKV分块为多个stage,如下图所示,前向为4-stage,反向为3-stage。
前向过程中首先launch一个Group-Cast kernel获取remote KV,然后launch FFA kernel计算attention。反向的时候需要三个stream,对next KV的预取的通信stream,计算dq,dkv的计算stream,还需要对上一个dkv进行reduce的stream。
对于stage的选择,sandai也设计了一个搜索算法,假设离线已经知道了通信和计算的耗时,然后对remote KV/dKV进行切分为候选的stage集合比如为数组pi[],pi[x]表示rank[i]的第x个候选stage,然后每个rank遍历各自的pi,通过离线的耗时计算每个候选stage的耗时,选择出最小的称为Si,然后选出全局最大的Si成为最后的stage。
