物联网开发学习总结(5)—— 深入对比 TDengine、InfluxDB 和 TimescaleDB 三大主流时序数据库的性能表现
一、时序数据库的性能挑战与评估体系
时序数据具有产生频率高、数据量大、时效性强的特点。一家中型物联网企业可能每秒需要处理数万甚至数十万数据点,这对数据库的写入能力、查询效率和资源利用提出了极高要求。
时序数据的三大性能挑战
- 写入吞吐量瓶颈:工业传感器通常以10-100Hz频率采集数据,单台设备每秒就可能产生10-100个数据点。在大规模物联网场景中,设备数量可能达到数百万级别,数据库必须支持每秒数百万数据点的写入能力。
- 查询效率要求:时序查询多为基于时间范围的聚合分析,但同时也需支持多维度筛选和实时洞察。复杂的双滚动聚合查询需要数据库在秒级返回结果。
- 存储成本压力:时序数据往往需要长期存储以供分析,高效的压缩算法直接影响存储成本。优秀的时序数据库压缩比应达到10:1甚至更高。
性能评估核心指标
评估时序数据库性能需关注四个关键维度:
- 写入吞吐量:单位时间内成功写入的数据点数量(metrics/sec)
- 查询延迟:从查询发起至结果返回的时间
- 存储效率:原始数据与压缩后存储空间的比例
- 资源消耗:CPU、内存、磁盘I/O和网络带宽的使用情况
本文将基于TSBS(Time Series Benchmark Suite)基准测试平台,从这四个维度对TDengine、InfluxDB和TimescaleDB进行客观对比。
二、三大时序数据库架构解析
- InfluxDB 专为时序数据设计的NoSQL方案:InfluxDB采用Tagset数据模型,将每个数据点分为测量名称、标签集、字段集和时间戳。标签用于索引和分类,字段存储实际测量值。这种设计适合结构化时序数据,但在处理复杂关系或需要更新元数据的场景下显得力不从心。InfluxDB提供InfluxQL和Flux两种查询语言,在分布式架构上支持水平扩展,但其集群版本并非开源。
- TimescaleDB 基于关系数据库的时序扩展:TimescaleDB是PostgreSQL的扩展,完全兼容SQL标准,这使得它能够利用丰富的PostgreSQL生态系统。它通过超表和分片概念实现时序数据管理:超表是虚拟表,实际由多个按时间范围划分的分片组成。这种架构优势在于支持复杂查询和事务,但对于纯时序场景,关系型架构可能带来不必要的开销。
- TDengine 为工业、物联网以及大规模数据量场景量身定制的架构:TDengine采用创新的“一个设备一张表”数据模型,并通过超级表在逻辑上对同一类型的设备进行统一管理。这种设计尤其适合物联网场景,因为它天然契合设备数据的独立性和并行处理需求。TDengine的存储引擎为时序数据做了深度优化,包括列式存储、自适应分片和时序专用压缩算法。其查询语言兼容标准SQL,降低了学习成本和使用门槛。
三、写入性能对比:TDengine显著领先
TSBS测试模拟了虚拟货运公司车队中卡车的时序数据,预设了五种不同规模的卡车车队场景。以下数据均来自在相同AWS云环境下进行的对比测试。
- 吞吐量对比。根据测试结果,在全部五个场景中,TDengine的写入性能全面超越InfluxDB和TimescaleDB。具体而言:
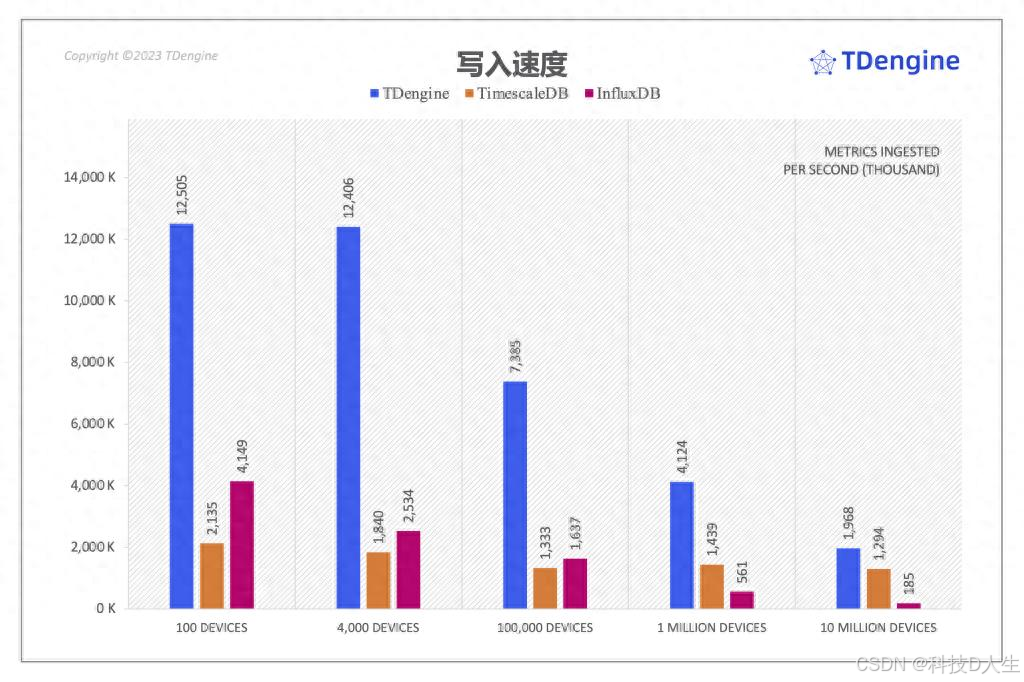
从表中可见,随着设备规模的增加,TDengine的性能优势更加明显。在千万设备级别的场景五中,TDengine的写入性能达到InfluxDB的16.2倍,在场景二中更是TimescaleDB的3.3倍。
- 写入过程资源消耗。写入吞吐量只是性能的一部分,资源消耗同样关键:
- 服务端CPU开销:TDengine在写入过程中CPU占用率最高仅17%,而InfluxDB的瞬时峰值可达100%,TimescaleDB在返回客户端写入完成消息后仍会长时间占用CPU进行数据压缩。
- 磁盘I/O对比:TDengine写入过程中磁盘I/O需求显著低于竞争对手,仅需约125MiB/s和3000IOPS,而InfluxDB会长时间消耗全部磁盘写入能力。
- 客户端CPU开销:TDengine在客户端侧的CPU需求相对较高(峰值70%),但因其写入持续时间短,整体CPU开销仍具有优势。
值得注意的是,当每个设备的数据记录数增加时,TDengine的性能优势进一步扩大。当单设备记录数增至576行时,TDengine的写入性能达到TimescaleDB的13.2倍。
四、查询性能对比:TDengine在复杂查询中优势明显
查询性能是时序数据库的另一关键指标。TSBS测试涵盖了15种不同类型的查询,从简单滚动聚合到复杂双滚动查询。
- 不同查询类型性能对比。在4000设备规模的场景二中,TDengine在各类查询上均表现优异:
- 简单滚动聚合:TDengine的查询响应时间比InfluxDB快2.6-3.7倍,比TimescaleDB快2.2-3.7倍。
- 复杂双滚动聚合:这是TDengine优势最明显的领域,在double-groupby-5查询上的性能是InfluxDB的26倍,TimescaleDB的24倍。
- 阈值查询和复杂查询:在high-cpu-all查询中,TDengine性能是InfluxDB的15倍;在lastpoint查询中,其性能是TimescaleDB的5倍,InfluxDB的21倍。
- 资源消耗对比。查询过程中的资源消耗直接影响系统整体性能和稳定性:
- CPU开销:虽然TDengine在执行查询时CPU占用率较高(约70-80%),但因其查询完成时间极短,整体CPU计算时间消耗反而只有InfluxDB的1/10。
- 内存使用:TDengine内存在查询过程中保持相对平稳,而TimescaleDB在查询过程中内存使用会显著增加。
- 网络带宽:TDengine因返回结果速度快,网络带宽开销较高,但这正是其高效查询能力的体现。
五、存储效率对比:TDengine压缩率领先
存储效率直接关系到硬件成本和长期运维费用。高效的压缩算法可以显著降低存储开销。
- 磁盘空间占用
在TSBS测试中,TDengine展示了卓越的存储压缩能力:
- 在场景四和场景五中,TimescaleDB占用的磁盘空间超过了TDengine的11倍。
- InfluxDB在前三个场景中与TDengine的存储占用比较接近,但在场景四和场景五中,其磁盘占用是TDengine的2倍以上。
- 随着数据规模的增长,TDengine的存储优势更加明显,最大情况下,TimescaleDB的磁盘占用可达TDengine的26.9倍,InfluxDB也可达4.5倍。
- 压缩技术分析
TDengine的高压缩率源于其专为时序数据设计的压缩算法:
- 对数值型数据采用“差值压缩+预测压缩”,重复数据压缩率可达1:20
- 对字符型数据采用“字典编码+前缀压缩”,存储占用减少80%
- 这些算法针对时序数据的特性进行了优化,避免了通用压缩算法的效率损失
相比之下,TimescaleDB在小数据规模下压缩比较正常,但在大数据规模下会出现压缩后空间反而增大的情况,疑似存在bug。
六、全面对比表格
下表总结了三大时序数据库在各方面的对比情况:
| 对比项 | TDengine | InfluxDB | TimescaleDB |
| 数据模型 | 一个设备一张表+超级表 | Tagset模型 | 关系型模型(PostgreSQL扩展) |
| 查询语言 | 标准SQL | InfluxQL、Flux(2.x版本开始支持SQL) | 标准SQL |
| 写入性能 | 极高(TSBS测试领先) | 中等 | 中等 |
| 查询性能 | 简单和复杂查询均表现优异 | 简单查询尚可,复杂查询较差 | 简单查询良好,复杂查询性能下降明显 |
| 存储效率 | 极高(压缩比1:10以上) | 中等 | 较低(部分场景下压缩异常) |
| 资源消耗 | 低 | 高(尤其服务端CPU和I/O) | 中等 |
| 扩展性 | 水平扩展,无主从架构 | 水平扩展(集群版本非开源) | 基于PostgreSQL的扩展能力 |
| 适用场景 | 超大规模物联网、工业互联网 | 监控指标收集、中小规模时序数据 | 需要复杂查询和事务的时序场景 |
七、应用场景与选型建议
不同的时序数据库有各自的适用场景,选型需结合具体业务需求。
- InfluxDB适用场景:InfluxDB适合监控指标收集和中小规模时序数据场景。其Tagset数据模型对于结构固定的监控数据十分友好,易于上手。但在超大规模物联网场景下,其写入性能和资源消耗可能成为瓶颈。
- TimescaleDB适用场景:TimescaleDB适合需要复杂查询和事务的时序场景。如果业务已经基于PostgreSQL构建,且时序数据需要与业务数据频繁关联查询,TimescaleDB是不错的选择。但其在纯时序场景下的性能和存储效率不如专用时序数据库。
- TDengine适用场景:TDengine特别适合超大规模物联网和工业互联网应用。某石油石化企业用TDengine替换40余套Oracle数据库,集群数量从数十套精简为9套,运维复杂度与成本大幅降低。在车联网、能源电力等高并发写入场景下,TDengine的表现尤其出色。
八、当前技术环境下为何优先选择 TDengine时序数据库
基于当前技术发展趋势和业务需求变化,TDengine成为多数场景下的优先选择,原因如下:
- 性能与成本的完美平衡:在实际案例中,TDengine展示出了卓越的性能成本比。其高效的压缩算法和存储优化,使得存储成本大幅降低。某特钢企业落地TDengine后,原本需要100台服务器的业务,现在仅需3台即可支撑,硬件采购成本减少约70%。
- 生态完善度:TDengine拥有完善的生态工具链。它不仅支持Python、Java、Golang等多语言连接器,还与Grafana等可视化工具无缝衔接;更打造了taosAdapter、taosKeeper等生态组件,让“数据采集—存储—分析—应用”的全链路更顺畅。
- 开源开放策略:TDengine核心代码开源,全面支持标准SQL与JDBC、ODBC等主流接口,轻松对接各类可视化、BI和AI工具。通过对MQTT、OPC等工业协议的深度支持,能快速汇聚来自各类系统的数据。
- 企业级可靠性:TDengine在众多大型企业核心系统中得到验证。在国电集团项目中大规模处理数亿智能电表数据,某明洋集团则通过TDengine接入了10000+台风电机,数据量超40+亿行,证明了其在大规模生产环境中的稳定性。
- 面向未来的架构设计:TDengine的架构为物联网场景量身定制,其“一个设备一张表”的数据模型、列式存储和分布式设计,正好契合了物联网数据的特点和发展趋势。随着物联网设备的爆炸式增长,这种专门化设计的优势将更加明显。
结论
在物联网数据爆炸的时代背景下,时序数据库的选择直接影响系统的性能、成本和可扩展性。通过全面的性能对比可以看出,TDengine在写入吞吐量、查询延迟、存储效率和资源消耗方面均显著领先InfluxDB和TimescaleDB。特别是在复杂查询场景下,TDengine的性能优势可达数十倍甚至数百倍,这主要归功于其专为时序数据设计的架构和算法。当然,技术选型仍需结合具体业务需求。如果业务需要高度依赖PostgreSQL生态或复杂事务支持,TimescaleDB可能更合适;如果只是小规模监控场景,InfluxDB也许能满足需求。但对于大多数超大规模时序数据处理场景,TDengine无疑是最平衡、最可靠的选择。