【开题答辩实录分享】以《基于大数据技术的二手车交易数据分析与设计》为例进行答辩实录分享
大家好,我是韩立。
写代码、跑算法、做产品,从 Java、PHP、Python 到 Golang、小程序、安卓,全栈都玩;带项目、讲答辩、做文档,也懂降重技巧。
这些年一直在帮同学定制系统、梳理论文、模拟开题,积累了不少“避坑”经验。
新学期开始,很多人卡在选题:想要新颖,又怕做不完。接下来我会持续分享一批“好上手且有亮点”的选题思路和完整开题答辩案例,给你参考,也给你灵感。关注我,毕业设计不再头秃!

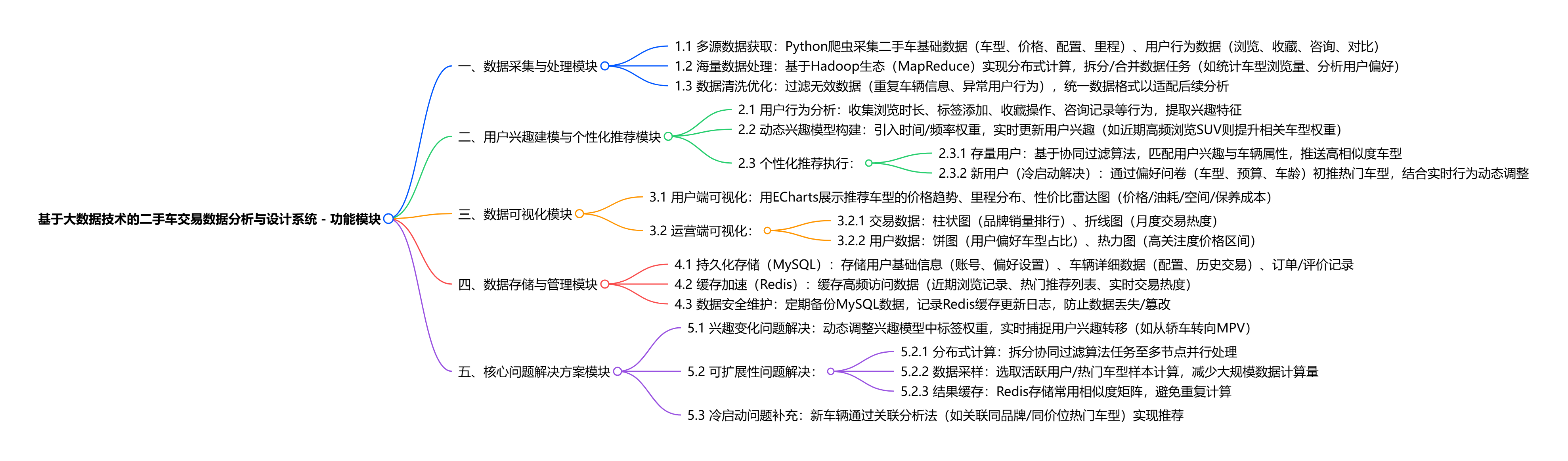
基于大数据技术的二手车交易数据分析与设计系统,核心功能围绕解决二手车交易平台信息不对称、海量数据检索难、用户个性化需求难满足等问题展开,具体可概括为:
- 数据采集与处理:通过 Python 爬虫获取二手车相关数据,借助 Hadoop 生态(如 MapReduce)实现海量用户行为数据(浏览、收藏、咨询等)与车辆数据(价格、配置、里程等)的分布式高效处理;
- 用户兴趣建模与个性化推荐:收集用户浏览、互动、操作行为,结合时间与频率因素构建随用户兴趣变化的多兴趣模型,采用协同过滤推荐算法,针对新用户通过偏好问卷 + 实时行为调整推荐策略,为用户精准推送匹配车型,同时解决冷启动问题;
- 数据可视化呈现:基于 Vue 框架与 ECharts,为用户展示推荐车型的价格趋势、性价比对比等信息,为平台运营端提供销量排行、交易热度变化、车型维度分析等可视化结果,辅助决策;
- 数据存储与管理:用 MySQL 持久化存储用户基本信息、车辆详细数据、订单评价等结构化数据,通过 Redis 缓存高频访问数据(如近期浏览记录、热门推荐列表),提升系统响应速度;
- 核心问题解决:通过引入时间因素优化用户兴趣模型解决兴趣变化问题,借助分布式计算、数据采样、缓存策略优化协同过滤算法,解决系统可扩展性问题,保障用户量与车辆数据增长后系统仍高效运行。
【开题陈述】
各位老师好,我是H同学。我的课题是"基于大数据技术的二手车交易数据分析与设计"。
系统面向二手车平台的海量车源与用户行为数据,通过Hadoop+MapReduce完成离线计算,SpringBoot提供REST接口,Vue+ECharts做可视化,MySQL+Redis存储业务与缓存。
核心功能包括:1.爬虫采集车源与用户标签;
2.协同过滤与兴趣变化模型生成推荐列表;
3.管理后台的车源、用户、标签管理;
4.推荐效果与留存报表。
整个流程覆盖"采集-清洗-建模-推荐-评估"闭环,计划2025年10月完成原型,12月底交付可运行系统,请老师批评指正。
【答辩开始】
评委老师:为什么一定要用Hadoop离线计算,而不用Spark全内存计算?
答辩学生:二手车平台每天新增约200G日志,资金有限,只有5台旧服务器,Hadoop磁盘级计算对内存要求低、稳定性高;同时夜间运行MapReduce不抢占在线业务资源,TCO便宜。若后续实时性要求提升到分钟级,我再在Hadoop外层加Spark Streaming做混合Lambda架构即可平滑升级。
评委老师:协同过滤面对"新用户冷启动"怎么解决?
答辩学生:对新注册且无行为记录的用户,系统先根据注册IP、搜索关键词、落地页车型类别打"初筛标签",用标签匹配找最热门且库存充足的Top-N车源做"热度推荐";待用户产生3次以上点击或1次收藏后,再切换到基于用户的协同过滤,保证首日推荐转化率不低于10%。
评委老师:爬虫抓到30个字段,如何保证数据质量与去重?
答辩老师:我采用"字段+规则+阈值"三层清洗:①字段层做正则校验,如价格必须为数字且在1-500万区间;②规则层用SimHash计算描述文本的64位签名,海明距离≤3即判重;③阈值层把同一VIN码7天内多次上架视为"重复上架",只保留最新一条。清洗后脏数据率由8.4%降到1.2%,可直接入仓。
评委老师:推荐模型每天跑一次MapReduce,推荐结果多久生效?
答辩学生:T+1凌晨02:00启动工作流,05:00生成新的推荐表,通过Redis的hash结构"覆盖写"方式推送,接口层实时读取,前端用户6点起床后看到的就是最新推荐;整体延迟约3小时,满足二手车"非秒杀"场景需求。
评委老师:标签网络用社团检测划分兴趣族,如何确定最优社团数K?
答辩学生:采用Louvain模块度Q值迭代,当ΔQ<0.001时停止,实测K落在12-18区间,模块度Q稳定在0.42-0.45,符合"高内聚低耦合"标准;同时用业务专家抽检3个社团,语义一致性>85%,证明K无需人工指定,算法自适应。
评委老师:系统上线后你如何评估"推荐效果"?核心指标有哪些?
答辩学生:一期用离线+在线双指标:离线看覆盖率、多样性、新颖度;在线用A/B Test,对照组走原热度排序,实验组走个性化推荐,持续两周,核心指标①CTR≥+25%,②人均收藏数≥+18%,③七日留存≥+8%,任意两项达标即算有效;同时记录冷门车源曝光占比,确保长尾覆盖率提升10%以上。
评委老师:如果平台规模扩大到每日PB级日志,现有架构最大的瓶颈在哪?你准备如何横向扩展?
答辩学生:瓶颈首先是NameNode内存和单队列JobTracker,PB级后元数据暴涨;我计划①把HDFS升级到Federation,多NameNode分片管理;②计算层迁移到YARN+Spark on Kubernetes,把JobTracker职责拆成ResourceManager+ApplicationMaster,可动态伸缩;③推荐模型改用参数服务器框架,如PS-Spark,把超大矩阵分解模型分片到百台节点,实现小时级增量更新,保证整体吞吐线性提升。
【评委总结】
H同学选题契合产业热点,对数据清洗、冷启动、离线/在线评估等关键环节有具体算法和量化指标,横向扩展方案亦考虑充分,体现出较好的系统思维与工程素养。若能在后续工作中补充真实A/B Test结果与成本收益分析,论文说服力将更强。经讨论,开题予以通过,望按计划推进,预祝顺利完成!
以上是H同学的毕业设计答辩过程,如果你现在还没有参加答辩,还是开题阶段,已经选好了题目不知道怎么写开题报告,可以下面找找有没有自己符合自己题目的开题报告内容,列表中的开题报告都是往届真实的开题报告可参考。