yolov3代码详解
代码部分预览
打标签
在此之前先学习下如何对图片进行打标签,这里使用labelme(直接通过pip进行安装)来进行打标签。具体操作如下:
win+R 然后cmd打开终端输入labelme,然后找到图片文件夹进行框图

然后保存下来就会得到一个json文件。
这个是一个字典,其中重要部分是shapes部分,其中包括了我们的label和points。
其中最下面的一大串编码是我们的图片经过Base64 编码 的二进制数据。可以通过下面代码转化为数据,方便了我们的网络传输数据。
json数据转化
import json
import osimport json
import base64
from PIL import Image
from io import BytesIOname2id = { 'dog':0, 'cat':1}#有多少个类别,在字典中就写多少个对应的就可以def convert(img_size, box):dw = 1./ (img_size[0])dh = 1./(img_size[1])x = (box[0] + box[2])/2.0 - 1y = (box[1] + box[3])/2.0 - 1w = box[2]- box[0]h = box[3] - box[1]x = x*dww = w*dwy = y*dhh = h*dhreturn (x,y,w,h)def decode_json(json_floder_path,json_name ) :#转换好的标签路径,建议保存在data\custom\labels中txt_name = r'data\\custom2\\labels\\' + json_name[0:-5] + '.txt'txt_file = open(txt_name,'w')json_path = os.path.join(json_floder_path, json_name)data = json.load(open(json_path, 'r'))img_w = data[ 'imageWidth' ]img_h = data[ 'imageHeight' ]for i in data[ 'shapes']:label_name = i['label']if ( i['shape_type' ] == 'rectangle' ):x1 = int(i['points'][0][0])y1 = int(i['points'][0][1])x2 = int(i['points'][1][0])y2 = int(i['points'][1][1])bb = (x1,y1,x2,y2)bbox = convert((img_w,img_h),bb)txt_file.write(str(name2id[label_name]) + " " +" ".join([str(a) for a in bbox]) + '\n')# 2. 提取 imageData 并解码image_data_base64 = data["imageData"]image_bytes = base64.b64decode(image_data_base64) # 解码为二进制字节流# 3. 将字节流转换为图像并保存image = Image.open(BytesIO(image_bytes)) # 从字节流加载图像save_path = r'data\\custom2\\Images\\' + json_name[0:-5] + '.png'image.save(save_path)print(f"图像已还原并保存至:{save_path}")txt_file.close()前面我们获得已经标签好的数据很明显是不方便训练的,下面我们把json转化为可以训练的数据。
训练train
导入库
其中部分库是我们自己写的并不是第三方下载的库,例如utils
from models import *
from utils.logger import *
from utils.utils import *
from utils.datasets import *
from utils.parse_config import *
from test import evaluateimport warnings
warnings.filterwarnings("ignore")from terminaltables import AsciiTableimport os
import time
import datetime
import argparseimport torch
from torch.utils.data import DataLoader
from torch.autograd import Variable
配置参数
if __name__ == "__main__":parser = argparse.ArgumentParser()parser.add_argument("--epochs", type=int, default=10, help="number of epochs") #训练次数parser.add_argument("--batch_size", type=int, default=1, help="size of each image batch") #batch的大小parser.add_argument("--gradient_accumulations", type=int, default=1, help="number of gradient accums before step")#在每一步(更新模型参数)之前累积梯度的次数”parser.add_argument("--model_def", type=str, default="config/yolov3.cfg", help="path to model definition file") #模型的配置文件parser.add_argument("--data_config", type=str, default="config/coco.data", help="path to data config file") #数据的配置文件parser.add_argument("--pretrained_weights", type=str, help="if specified starts from checkpoint model") #预训练文件parser.add_argument("--n_cpu", type=int, default=0, help="number of cpu threads to use during batch generation")#数据加载过程中应使用的CPU线程数。parser.add_argument("--img_size", type=int, default=416, help="size of each image dimension")parser.add_argument("--checkpoint_interval", type=int, default=1, help="interval between saving model weights")#隔多少个epoch保存一次模型权重parser.add_argument("--evaluation_interval", type=int, default=1, help="interval evaluations on validation set")#多少个epoch进行一次验证集的验证parser.add_argument("--compute_map", default=False, help="if True computes mAP every tenth batch")parser.add_argument("--multiscale_training", default=True, help="allow for multi-scale training")#允许多尺寸特征图融合的训练opt = parser.parse_args()print(opt)这个是方便我们在环境变量中传参数,方便在于我们改参数的时候不用一个一个的改了。
"""配置参数:
--model_def
config/yolov3-custom.cfg
--data_config
config/custom1.data
--pretrained_weights
weights/darknet53.conv.74
"""这里我们对模型参数,和数据配置,还有模型权重参数作出了修改,其他的全是默认参数。
模型参数
这个里面保存的就是我们的模型,只是之前我们写的模型是直接搭建的,然后现在我们的模型先写出来,然后后面再操纵进行搭建。
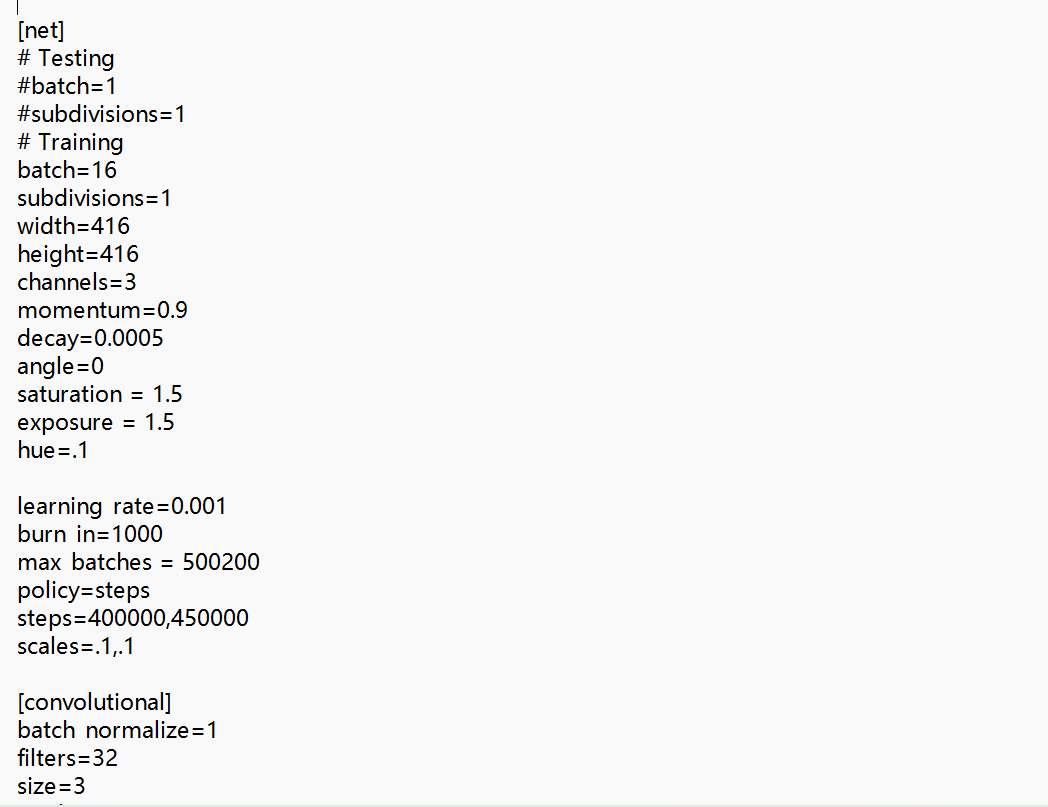
数据参数
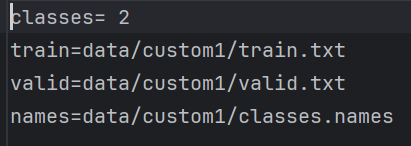
其中有数据的类别数,train和valid的地址,还有类名。
初始化参数
logger = Logger("logs")#日志文件device = torch.device("cuda" if torch.cuda.is_available() else "cpu")os.makedirs("output", exist_ok=True)os.makedirs("checkpoints", exist_ok=True)# Get data configurationdata_config = parse_data_config(opt.data_config)train_path = data_config["train"]valid_path = data_config["valid"]class_names = load_classes(data_config["names"])保存日志文件,可以不用管
选择设备 选择GPU或者CPU
创建两个文件夹 用于保存后面训练产生的结果
data_config = parse_data_config(opt.data_config)
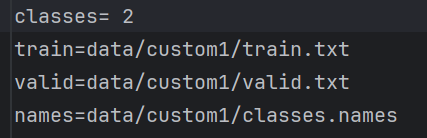
调用
def parse_data_config(path):"""Parses the data configuration file"""options = dict()options['gpus'] = '0,1,2,3'options['num_workers'] = '10'with open(path, 'r') as fp:lines = fp.readlines()for line in lines:line = line.strip()if line == '' or line.startswith('#'):continuekey, value = line.split('=')options[key.strip()] = value.strip()return options得到

这一步就是把我们的文本变成一个字典,用于后面直接使用。
train_path = data_config["train"]valid_path = data_config["valid"]像这样直接使用值。
class_names = load_classes(data_config["names"])
调用
def load_classes(path):"""Loads class labels at 'path'"""fp = open(path, "r")names = fp.read().split("\n")[:-1]return names直接调取'data/custom1/classes.names'中的值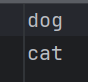
然后转化为列表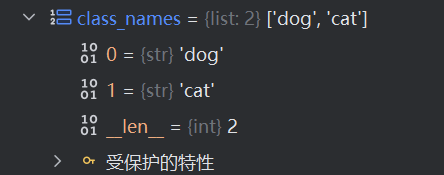
模型搭建
model = Darknet(opt.model_def).to(device)opt.model_def就是我们的模型文件
像这样的一个文件,然后我们进入到我们的建立模型的文件
class Darknet(nn.Module):"""YOLOv3 object detection model"""def __init__(self, config_path, img_size=416):super(Darknet, self).__init__()self.module_defs = parse_model_config(config_path)self.hyperparams, self.module_list = create_modules(self.module_defs) #创建出网络中需要的所有网络层,每一层需要哪些参数self.yolo_layers = [layer[0] for layer in self.module_list if hasattr(layer[0], "metrics")] #hasattr()是Python的一个内置函数,它用于检查对象是否具有给定(metrics)的属性。self.img_size = img_sizeself.seen = 0self.header_info = np.array([0, 0, 0, self.seen, 0], dtype=np.int32)我们继承了Darknet,然后对我们的模型参数进行读取。
self.module_defs = parse_model_config(config_path)调用了
def parse_model_config(path):"""Parses the yolo-v3 layer configuration file and returns module definitions"""file = open(path, 'r')lines = file.read().split('\n')lines = [x for x in lines if x and not x.startswith('#')] #x.startswith('#')用于检查字符串变量x是否以#前缀开始。如果x以该前缀开头,该方法将返回一个布尔值,通常是True,否则返回False。lines = [x.rstrip().lstrip() for x in lines] # get rid of fringe whitespacesmodule_defs = []for line in lines:if line.startswith('['): # This marks the start of a new blockmodule_defs.append({})module_defs[-1]['type'] = line[1:-1].rstrip()if module_defs[-1]['type'] == 'convolutional':module_defs[-1]['batch_normalize'] = 0else:key, value = line.split("=")value = value.strip()module_defs[-1][key.rstrip()] = value.strip()
这一步是把我们的文本数据转化为列表数据,然后其中的元素为字典型数据
最终转化为
这样的一个数据。
细节部分
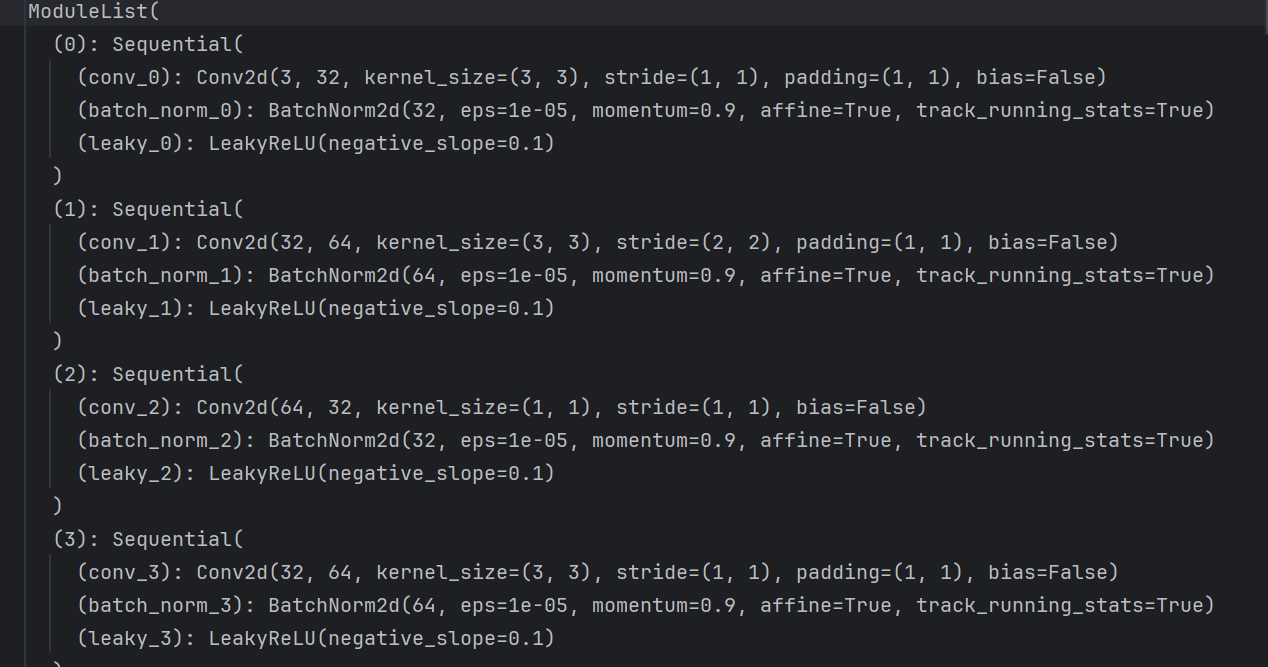
def create_modules(module_defs):"""Constructs module list of layer blocks from module configuration in module_defs"""hyperparams = module_defs.pop(0)output_filters = [int(hyperparams["channels"])] #输出特征图的个数,也是卷积核的个数module_list = nn.ModuleList()#nn.ModuleList()是PyTorch中的一个类,用于将一个或多个nn.Module的实例包装到一个可迭代对象中。这个类在定义神经网络模型时非常有用,因为它允许你将多个网络层(每个都是nn.Module的实例)组合在一起,并以列表的形式管理和使用。#具体来说,nn.ModuleList()的工作方式类似于Python的列表。你可以像向普通列表添加元素一样向ModuleList添加层,然后可以通过索引访问它们,就像访问普通的列表一样。然而,与普通列表不同的是,ModuleList中的元素是nn.Module的实例,即神经网络层。for module_i, module_def in enumerate(module_defs):modules = nn.Sequential()#nn.Sequential()主要用于实现线性堆叠,内部实现了前向传播函数;而nn.ModuleList()则用于存储多个网络层,以便在需要时进行调用,并不实现任何前向传播功能。if module_def["type"] == "convolutional":bn = int(module_def["batch_normalize"])filters = int(module_def["filters"]) #卷积核的个数kernel_size = int(module_def["size"])pad = (kernel_size - 1) // 2modules.add_module(f"conv_{module_i}",nn.Conv2d(in_channels=output_filters[-1],#输入特征图的数量,即输入的维度。out_channels=filters, #输出特征图的数量,即输出的维度。kernel_size=kernel_size, #卷积核的大小stride=int(module_def["stride"]), #卷积核滑动的步长大小padding=pad, #在输入数据边界上填充0的层数bias=not bn, #是否在卷积后添加偏置项。默认情况下,bias=True,即使用偏置项。),)if bn:# nn.BatchNorm2d的输入参数包括:# num_features:输入图像的通道数量。# eps:稳定系数,防止分母出现0。默认值为1e - 05。# momentum:一个用于运行过程中均值和方差的一个估计参数。默认值为0.1。可用于控制批量归一化中移动平均和指数加权的因子。这意味着,随着时间的推移,momentum将推动均值和方差向新的数据进行调整。较小的momentum会导致较慢的调整速度,而较大的momentum则会加快调整速度。# 这个参数的设置是有实际意义的。因为在深度神经网络训练过程中,数据分布会随时间变化。通过设置momentum参数,我们可以使批量归一化层的均值和方差能够跟随数据分布的变化而动态调整,从而更好地适应新的数据分布。# 例如,如果我们有一个网络,其中第一个层使用了批量归一化,而第二个层没有使用批量归一化。在这种情况下,如果我们提高了第一个层的momentum值,那么随着时间的推移,第一个层的均值和方差将逐渐调整以适应新的数据分布。这将使得第二个层能够更好地处理经过归一化的输入数据,从而提高整个网络的性能。# 总之,momentum参数在nn.BatchNorm2d中起到了推动批量归一化层的均值和方差向新数据进行调整的作用,有助于提高网络对数据分布变化的适应能力。modules.add_module(f"batch_norm_{module_i}", nn.BatchNorm2d(filters, momentum=0.9))if module_def["activation"] == "leaky":# nn.LeakyReLU是PyTorch中的一个非线性激活函数,它是一种带有泄漏的线性整流激活函数(LeakyReLU)。与ReLU不同,Leaky# ReLU在输入为负数时不是完全的截断,而是有一个小的负斜率。这意味着,对于负输入,LeakyReLU将不会输出0,而是逐渐增加的输出值。# 这种设计有助于解决ReLU在负数区域的问题,特别是在深度神经网络中,ReLU的截断可能导致一些神经元无法激活,而LeakyReLU可以缓解这个问题。modules.add_module(f"leaky_{module_i}", nn.LeakyReLU(0.1))elif module_def["type"] == "maxpool": #darknet网络中没有池化层,因此本段代码不会执行kernel_size = int(module_def["size"])stride = int(module_def["stride"])if kernel_size == 2 and stride == 1:modules.add_module(f"_debug_padding_{module_i}", nn.ZeroPad2d((0, 1, 0, 1)))maxpool = nn.MaxPool2d(kernel_size=kernel_size, stride=stride, padding=int((kernel_size - 1) // 2))modules.add_module(f"maxpool_{module_i}", maxpool)elif module_def["type"] == "upsample": #上采样upsample = Upsample(scale_factor=int(module_def["stride"]), mode="nearest")#yolov3.cfg文件中保存的参数为stride=2modules.add_module(f"upsample_{module_i}", upsample)elif module_def["type"] == "route": #为concat的操作,是数据的拼接。layers = [int(x) for x in module_def["layers"].split(",")]filters = sum([output_filters[1:][i] for i in layers])modules.add_module(f"route_{module_i}", EmptyLayer())#初始化的空网络elif module_def["type"] == "shortcut": # #残差的链接,也就是进行数据的加法+运算filters = output_filters[1:][int(module_def["from"])]modules.add_module(f"shortcut_{module_i}", EmptyLayer())elif module_def["type"] == "yolo":anchor_idxs = [int(x) for x in module_def["mask"].split(",")]#预选框的id# Extract anchorsanchors = [int(x) for x in module_def["anchors"].split(",")]anchors = [(anchors[i], anchors[i + 1]) for i in range(0, len(anchors), 2)]anchors = [anchors[i] for i in anchor_idxs] #获取预选框的大小num_classes = int(module_def["classes"]) #输出的类别个数img_size = int(hyperparams["height"])# Define detection layeryolo_layer = YOLOLayer(anchors, num_classes, img_size)modules.add_module(f"yolo_{module_i}", yolo_layer)# Register module list and number of output filtersmodule_list.append(modules)output_filters.append(filters)return hyperparams, module_list前面我们对每一层都变成了一个字典,然后现在我们只要对列表中的字典进行读取,然后看其中的module_def["type"]是什么,然后进行搭建网络。
我们先创建一个列表,然后进行循环,循环的时候创建一个sequential,再往这个里面添加卷积层,池化层,和激活函数,或者yolo层,再或者残差层再把这个sequential添加到这个列表中去。
这样就成功搭建了一个网络