深度学习之yolov2
yolov2对比yolov1升级点
下面图片对比了yolov1与yolov2,可以观察到yolov2用了其他技术去提升map
表格说明:
这张对比表格清晰地展示了从YOLO到YOLOv2的渐进式改进过程。表格从左到右显示了不同技术特性的引入顺序及其对检测精度(mAP)的影响。
主要改进点解析:
批归一化:最先引入,提升训练稳定性
高分辨率分类器:改善特征提取能力
卷积结构优化:提升计算效率
锚框机制:改进边界框预测
新网络设计:Darknet-19骨干网络
多尺度训练:增强模型鲁棒性
批归一化(BatchNorm)

使用更大分辨率

yolov2的网络结构

锚框与定向预测
YOLOv2 借鉴了Faster R-CNN的锚框(Anchor Box)思想,但进行了重要优化:它并非手动设置固定宽高比,而是通过对训练数据集中的真实边界框进行 K-means 聚类,自动得到一组最具有代表性的先验框尺寸。这使得锚框的形状更贴合实际数据的分布。
从图1的对比数据可以看到,引入锚框机制后:
mAP(平均精度) 从 69.5 略微下降到 69.2。
Recall(召回率) 从 81% 显著提升至 88%。
这个结果意义重大:虽然整体精度略有波动,但模型能够检测到的目标数量大幅增加,这意味着模型“漏检”的情况大大减少,为后续的性能提升奠定了坚实基础。
2. 定向位置预测,解决训练发散难题
然而,简单地引入锚框带来了新的挑战。YOLOv1 直接预测边界框相对于网格的偏移量 t_x, t_y,公式为 x = x_cell + w_anchor * t_x。如图2所示,这种无约束的预测会导致一个问题:例如当 t_x = 1时,边界框中心会向右移动一个锚框的宽度,这可能在训练初期导致预测框“跑飞”,使得模型难以收敛。
YOLOv2 的解决方案非常巧妙——Directed Location Prediction。它改变了预测策略:
中心点预测:使用 Sigmoid 函数将
t_x, t_y的预测值约束在 (0, 1) 范围内。新的计算公式为b_x = σ(t_x) + c_x,其中c_x是网格左上角的坐标。这意味着边界框的中心点被限制在当前的网格单元内进行微调,而不会发生大幅度跳跃。宽高预测:使用指数函数预测宽高的缩放比例
b_w = p_w * e^(t_w),确保宽高始终为正值。
YOLOv2 借鉴了Faster R-CNN的锚框(Anchor Box)思想,但进行了重要优化:它并非手动设置固定宽高比,而是通过对训练数据集中的真实边界框进行 K-means 聚类,自动得到一组最具有代表性的先验框尺寸。这使得锚框的形状更贴合实际数据的分布。
从图1的对比数据可以看到,引入锚框机制后:
mAP(平均精度) 从 69.5 略微下降到 69.2。
Recall(召回率) 从 81% 显著提升至 88%。
这个结果意义重大:虽然整体精度略有波动,但模型能够检测到的目标数量大幅增加,这意味着模型“漏检”的情况大大减少,为后续的性能提升奠定了坚实基础。
2. 定向位置预测,解决训练发散难题
然而,简单地引入锚框带来了新的挑战。YOLOv1 直接预测边界框相对于网格的偏移量 t_x, t_y,公式为 x = x_cell + w_anchor * t_x。如图2所示,这种无约束的预测会导致一个问题:例如当 t_x = 1时,边界框中心会向右移动一个锚框的宽度,这可能在训练初期导致预测框“跑飞”,使得模型难以收敛。
YOLOv2 的解决方案非常巧妙——Directed Location Prediction。它改变了预测策略:
中心点预测:使用 Sigmoid 函数将
t_x, t_y的预测值约束在 (0, 1) 范围内。新的计算公式为b_x = σ(t_x) + c_x,其中c_x是网格左上角的坐标。这意味着边界框的中心点被限制在当前的网格单元内进行微调,而不会发生大幅度跳跃。宽高预测:使用指数函数预测宽高的缩放比例
b_w = p_w * e^(t_w),确保宽高始终为正值。
YOLOv2 借鉴了Faster R-CNN的锚框(Anchor Box)思想,但进行了重要优化:它并非手动设置固定宽高比,而是通过对训练数据集中的真实边界框进行 K-means 聚类,自动得到一组最具有代表性的先验框尺寸。这使得锚框的形状更贴合实际数据的分布。
从图1的对比数据可以看到,引入锚框机制后:
mAP(平均精度) 从 69.5 略微下降到 69.2。
Recall(召回率) 从 81% 显著提升至 88%。
这个结果意义重大:虽然整体精度略有波动,但模型能够检测到的目标数量大幅增加,这意味着模型“漏检”的情况大大减少,为后续的性能提升奠定了坚实基础。
2. 定向位置预测,解决训练发散难题
然而,简单地引入锚框带来了新的挑战。YOLOv1 直接预测边界框相对于网格的偏移量 t_x, t_y,公式为 x = x_cell + w_anchor * t_x。如图2所示,这种无约束的预测会导致一个问题:例如当 t_x = 1时,边界框中心会向右移动一个锚框的宽度,这可能在训练初期导致预测框“跑飞”,使得模型难以收敛。
YOLOv2 的解决方案非常巧妙——Directed Location Prediction。它改变了预测策略:
中心点预测:使用 Sigmoid 函数将
t_x, t_y的预测值约束在 (0, 1) 范围内。新的计算公式为b_x = σ(t_x) + c_x,其中c_x是网格左上角的坐标。这意味着边界框的中心点被限制在当前的网格单元内进行微调,而不会发生大幅度跳跃。宽高预测:使用指数函数预测宽高的缩放比例
b_w = p_w * e^(t_w),确保宽高始终为正值。

如图的示例所示,通过这种“微调”机制,网络能够稳定地学习如何将预设的锚框精细地调整到与真实目标框完美匹配。这极大地提升了训练的稳定性和收敛速度,是模型最终达到更高精度的关键。
感受野与特征融合
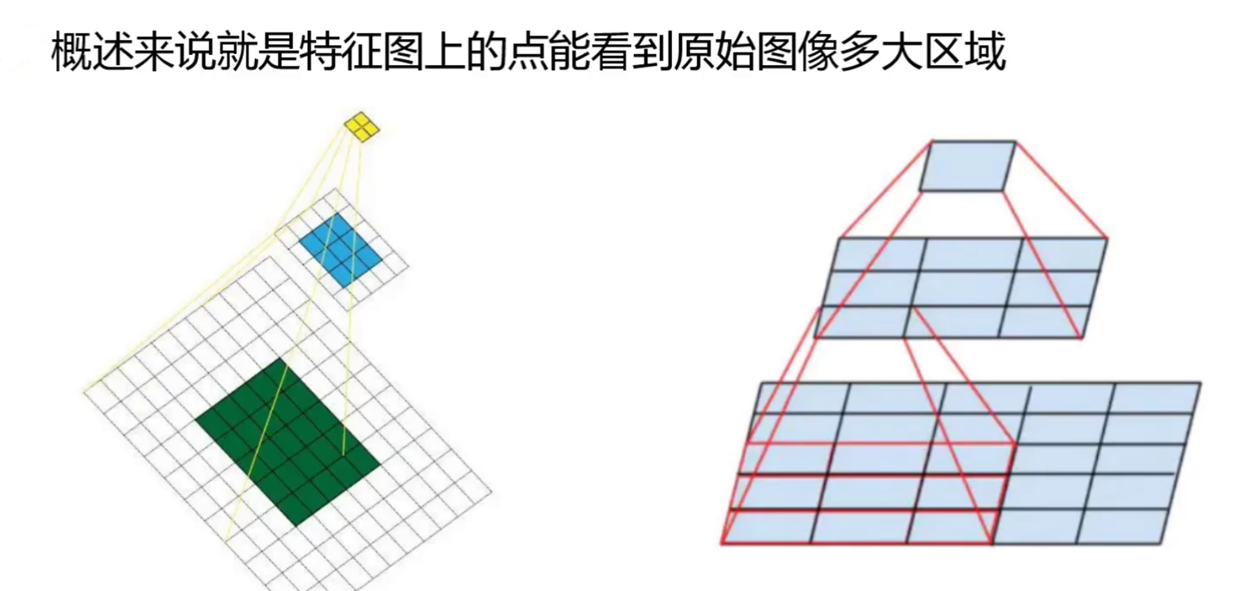
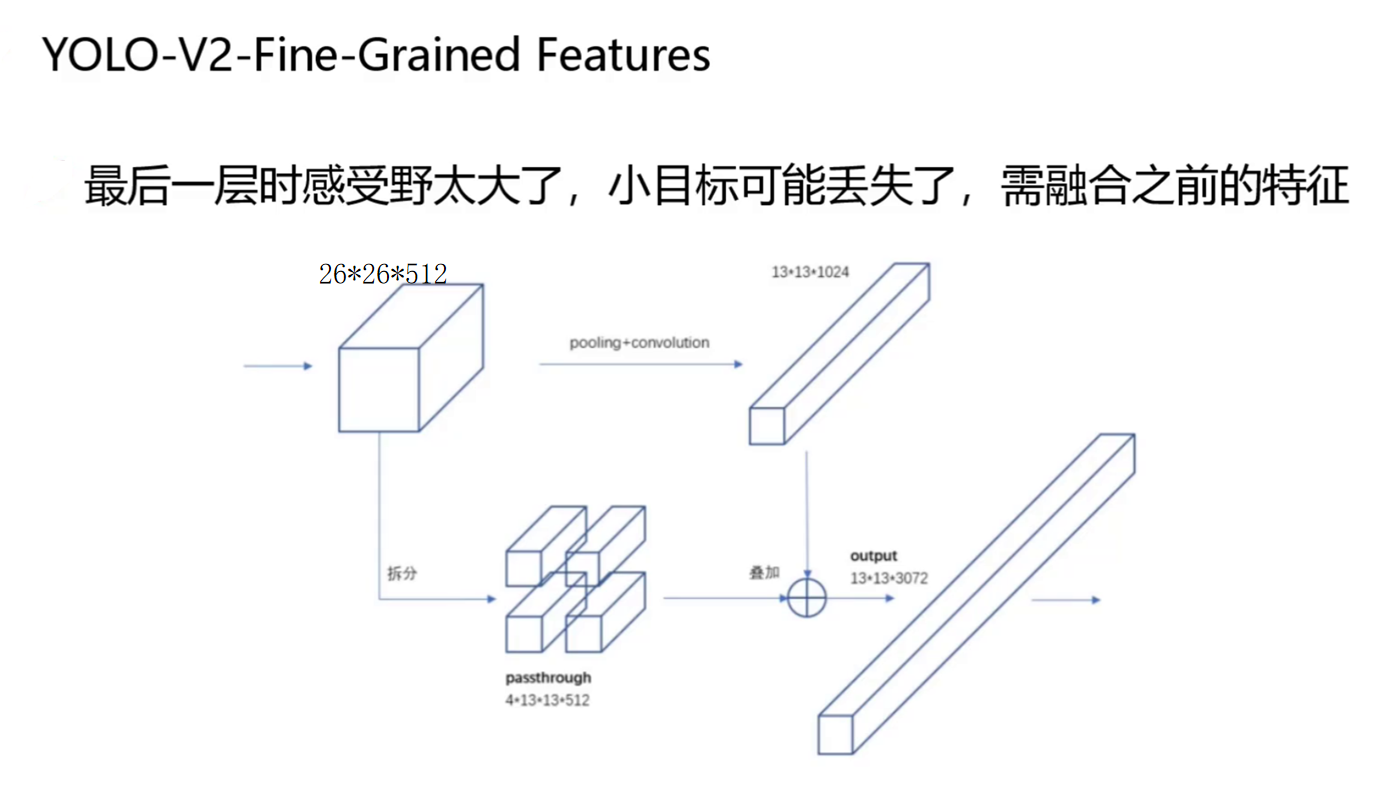
YOLOv2的缺点
尽管YOLOv2取得了巨大成功,但从技术发展的角度看,它仍然存在一些固有的缺点和局限性:
对密集小目标和重叠目标检测效果不佳:虽然引入了细粒度特征融合,但YOLOv2在每个网格位置仅预测有限数量的边界框。当场景中存在大量、密集且相互重叠的小目标时(如拥挤的人群),模型难以准确区分和定位每一个目标,容易产生漏检或误检。
边界框预测仍不够灵活:YOLOv2的定向位置预测将边界框中心限制在网格内部,这虽然稳定了训练,但在一定程度上限制了模型对极端形状或超出网格中心目标的定位灵活性。其边界框形状主要依赖于预定义的锚框,对于长宽比异常的目标适应性较差。
多尺度检测能力仍显粗糙:YOLOv2的多尺度训练策略是对输入图像的整体缩放,其检测头结构相对简单。相比后续采用特征金字塔网络(FPN)的模型(如YOLOv3),YOLOv2在不同尺度特征图的协同预测方面不够精细,对于尺度变化极大的目标群体,其性能仍有提升空间。
主干网络性能限制:Darknet-19虽然轻量高效,但其特征提取能力相较于更深的网络(如ResNet、Darknet-53)有所不足。这限制了模型在复杂场景下对更抽象、更判别性特征的捕捉能力。
单阶段检测器的共同局限:与两阶段检测器(如Faster R-CNN)相比,YOLOv2作为单阶段检测器,在精度上通常存在天花板。因为它直接对密集锚框进行分类和回归,缺少了两阶段方法中由区域提议网络(RPN)提供的预筛选和细化步骤,导致正负样本不平衡问题更突出,定位精度理论上限稍低。
正是为了克服这些缺点,才有了后续YOLOv3、v4等版本的持续演进,例如引入更强大的主干网络、特征金字塔结构以及更先进的损失函数等。