深度学习进阶(二)——视觉与语言的融合:多模态模型的架构演化
一、前言:从“看懂图像”到“理解世界”
当人类阅读一幅漫画、听一段音乐、看一场电影时,我们的大脑在同时处理图像、语言、声音、情绪等多种模态。
而过去十年,深度学习的进步几乎都是“单模态”的:
-
CNN 处理图像,
-
RNN/Transformer 处理语言,
-
WaveNet 或 Tacotron 处理语音。
每一种模态都像一条孤立的河流,各自流淌,却未曾汇合。
但从 2020 年起,事情开始改变。
GPT 让机器会“写字”,ViT 让机器会“看图”,而 CLIP 让机器第一次能同时理解图像与文字的语义联系。
从那一刻开始,我们进入了多模态时代——
模型不再只是“识别”,而是“理解”。
二、什么是多模态:不仅是拼接输入
在机器学习中,“模态(Modality)”指信息的来源类型。
图像是一种模态,文本是一种模态,声音也是一种模态。
所谓多模态,就是同时处理不同类型的数据。
直觉上,我们可能以为多模态只是简单“拼接”输入,比如:
输入 = 图片 + 文字
输出 = 分类标签
但事实上,多模态学习的核心不是拼接,而是对齐(Alignment)。
模型必须学会:
-
哪一段文字对应哪一块图像区域;
-
哪个声音片段与哪个画面同步;
-
哪个动作描述与视频中的行为对应。
举个例子:
当我们说“一个红衣女子在弹吉他”,
模型不仅要知道“红衣女子”是图像中的哪部分,
还要理解“弹吉他”这一动作与时间轴的关系。
这就涉及到多模态的两个核心问题:
-
表示学习(Representation Learning):如何将不同模态的数据映射到同一语义空间。
-
跨模态对齐(Cross-modal Alignment):如何让这些表示之间建立可解释的联系。
三、早期探索:CNN + RNN 的松散结合
在 2014 年至 2017 年之间,多模态还处于“实验阶段”。
最典型的结构是 CNN + RNN:
-
CNN 负责提取图像特征;
-
RNN(通常是 LSTM)负责生成文本。
伪代码示意如下:
# 图像编码
img_feature = CNN(image)# 文本生成
hidden = init_state(img_feature)
for word in sequence:hidden = LSTM(hidden, word)output = softmax(hidden)
这种架构第一次实现了“看图说话”(Image Captioning)——
给定图片,输出一句描述,比如:
“一只狗在草地上奔跑。”
然而,它的局限也很明显:
-
模型难以真正理解“哪部分图对应哪句话”;
-
语言生成过于模板化,容易出现模式坍塌;
-
不同模态间的信息融合过浅。
所以人们开始思考:
是否可以让视觉与语言在更深层次上“共享语义空间”?
这就引出了下一个革命性思想:对比学习(Contrastive Learning)。
四、CLIP:让图像与文字共享语义空间
2021 年,OpenAI 发布了 CLIP(Contrastive Language–Image Pretraining)。
它没有采用复杂的交叉网络,而是用极其简单的方式,完成了惊人的跨模态学习效果。
CLIP 的核心目标是:
让匹配的图像和文本在向量空间中靠近,不匹配的远离。
训练时,模型有两部分:
-
图像编码器(通常是 ResNet 或 ViT);
-
文本编码器(Transformer)。
它的伪代码几乎可以一眼看懂:
for (image, text) in dataset:img_vec = ImageEncoder(image)txt_vec = TextEncoder(text)loss = contrastive_loss(img_vec, txt_vec)
对比损失(InfoNCE)定义为:
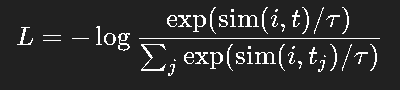
CLIP 的训练数据极其庞大(4 亿对图文),因此它学到的“语义对齐”非常强。
模型可以实现“零样本识别”:
输入一张猫的图片,不用重新训练,只要输入文字标签“a photo of a cat”,模型即可识别匹配。
这意味着——图像与语言第一次拥有了共同的“理解坐标系”。
五、BLIP、ALIGN 与跨模态预训练浪潮
CLIP 的成功,引发了跨模态预训练的爆炸式发展。
例如:
-
ALIGN(Google):使用更大规模的数据(10 亿对),采用噪声鲁棒训练;
-
BLIP(Salesforce):在 CLIP 的基础上加入生成式学习,让模型不仅能匹配,还能描述。
BLIP 的思路非常值得一提,它的训练目标包含三部分:
-
对比学习(像 CLIP 一样对齐图文);
-
语言建模(学习描述生成);
-
图文匹配(判断配对是否合理)。
伪代码示意:
image_feature = VisionEncoder(image)
text_feature = TextEncoder(text)# 三重任务
contrastive_loss = align(image_feature, text_feature)
caption_loss = generate_caption(image_feature)
matching_loss = discriminate(image_feature, text_feature)total_loss = α*contrastive + β*caption + γ*matching
这让 BLIP 既能“理解”也能“生成”,成为向多模态对话模型过渡的关键桥梁。
六、从理解到对话:LLaVA、BLIP-2 与 GPT-4V
2023 年开始,多模态模型进入了新阶段:
不再是“看图识别”或“图文匹配”,而是看图对话(Visual Dialogue)。
这一阶段的关键创新,是将**视觉编码器(如 ViT 或 CLIP)与大型语言模型(LLM)**连接起来。
最典型的代表是 LLaVA(Large Language and Vision Assistant)。
它使用一个视觉编码器提取图像特征,然后通过一个线性映射模块(Projection Layer),将视觉特征嵌入 LLM 的语义空间中。
伪代码:
img_feat = VisionEncoder(image)
img_embed = LinearProjection(img_feat)
response = LLM(prompt + img_embed)
这样,LLM 就能“读懂”图像信息,用自然语言回答问题。
BLIP-2 则进一步优化了这个过程,它通过一个“Q-Former”模块将视觉信息转化为查询向量,与语言模型交互。这种方式兼顾了语义表达力和计算效率。
最终的 GPT-4V、Gemini、Claude 3 等模型,都是这一思路的延伸。
它们不仅能识别图像内容,还能进行推理、生成、理解上下文,甚至处理复杂文档。
可以说,这就是多模态AI的完全体:让语言成为所有模态的统一接口。
七、多模态学习的核心挑战
多模态看似辉煌,但仍有很多工程和理论难题。
1. 表示对齐困难
不同模态的数据分布、噪声、尺度差异巨大,对齐需要复杂训练和大量数据。
2. 模态不平衡
语言数据极多,图像和视频成本高,导致模型在语义学习上偏向语言。
3. 计算成本高
训练一个多模态模型通常需要上千张 GPU,工程门槛极高。
4. 解释性差
模型内部的语义对齐过程不可见,我们无法确切知道它是如何建立图文联系的。
这些问题正促使研究者探索新的方向:
-
模态蒸馏(让强模态指导弱模态学习)
-
自监督预训练(减少标注成本)
-
模块化架构(分离视觉、语言、推理部分)
八、趋势展望:走向统一模型与语义世界
我们正逐渐接近一个“模态无关的通用模型”时代。
Transformer 已经成为统一结构,语言模型的“提示理解能力”成为核心驱动力。
未来的多模态模型可能具备以下特征:
-
统一输入接口:一切输入(文字、图片、声音)都以 token 形式表示;
-
动态模态融合:模型根据任务自动选择关注模态;
-
通用语义空间:所有信息都在统一向量空间中交互。
换句话说,
深度学习的最终目标,不是让机器“识别模态”,而是“理解意义”。
九、结语:当世界成为数据的语言
从 LeNet 到 Transformer,再到 GPT-4V,我们见证了深度学习从“感知”走向“理解”。
视觉不再只是像素矩阵,语言不再只是词的序列。
它们在模型中,融合成一种新的语义形式——一种机器能理解的世界语言。
而我们离真正的“通用人工智能”,
或许就隔着一个更强大的多模态 Transformer。