【pytorch学习打卡挑战】day2 Pytorch张量运算API
前言
本专题致力于学习Pytorch及其相关项目。
参照B站教程
【2、PyTorch张量的运算API(上)】
【3、PyTorch张量的运算API(下)】
今日任务
第2个视频,主要围绕官方文档来介绍张量的运算API。
回顾时,建议直接看官方文档:
pytorch官方文档
内容总结
根据你提供的文章内容,我将其中提到的PyTorch函数进行了系统的归纳对比:
PyTorch张量运算函数对比表
| 函数名称 | 主要功能 | 核心参数 | 返回值类型 | 是否原地操作 | 主要应用场景 |
|---|---|---|---|---|---|
| torch.chunk | 按数量分割张量 | input, chunks, dim=0 | 元组(Tensors) | 否 | 数据并行处理、分步计算 |
| torch.gather | 按索引收集元素 | input, dim, index | 张量 | 否 | 高级索引、分类任务、数据重排 |
| torch.reshape | 改变张量形状 | input, shape | 张量 | 否 | 维度调整、模型输入适配、扁平化 |
| torch.scatter_ | 按索引分散值 | dim, index, src | 张量 | 是 | 稀疏数据填充、one-hot编码 |
| torch.scatter_add_ | 按索引累加值 | dim, index, src | 张量 | 是 | 数据聚合、稀疏矩阵构建 |
| torch.split | 按大小分割张量 | tensor, split_size_or_sections, dim=0 | 元组(Tensors) | 否 | 批量数据处理、多头注意力 |
| torch.squeeze | 移除维度为1的轴 | input, dim=None | 张量 | 否 | 模型输出处理、数据预处理 |
| torch.stack | 沿新维度堆叠张量 | tensors, dim=0 | 张量 | 否 | 批次数据构建、多通道合并 |
| torch.take | 按线性索引提取元素 | input, index | 张量 | 否 | 无明确维度的元素提取 |
| torch.tile | 重复张量内容 | input, dims | 张量 | 否 | 数据扩增、模式生成 |
| torch.transpose | 交换两个维度 | input, dim0, dim1 | 张量 | 否 | 矩阵转置、维度顺序调整 |
| torch.unbind | 沿维度完全拆分 | input, dim=0 | 元组(Tensors) | 否 | 序列数据处理、维度分量提取 |
| torch.unsqueeze | 增加维度为1的轴 | input, dim | 张量 | 否 | 广播对齐、神经网络输入 |
| torch.where | 条件选择元素 | condition, x, y | 张量 | 否 | 元素替换、分段函数、掩码操作 |
随机数生成函数对比
| 函数名称 | 分布类型 | 主要参数 | 应用场景 |
|---|---|---|---|
| torch.manual_seed | 随机种子控制 | seed | 实验可重复性 |
| torch.bernoulli | 伯努利分布 | input(概率) | 二分类模拟、dropout |
| torch.normal | 正态分布 | mean, std | 权重初始化、噪声添加 |
功能分类总结
1. 张量分割类
- chunk: 按数量均分
- split: 按大小分割
- unbind: 完全展开
2. 索引操作类
- gather: 按维度索引收集
- take: 线性索引提取
- scatter_: 按索引分散
- scatter_add_: 按索引累加
3. 形状变换类
- reshape: 改变形状
- squeeze/unsqueeze: 维度压缩/扩展
- transpose: 维度交换
- stack: 新建维度堆叠
- tile: 重复扩展
4. 条件操作类
- where: 条件选择
5. 随机生成类
- bernoulli: 二项分布
- normal: 正态分布
- manual_seed: 随机种子
关键区别说明
- chunk vs split: chunk按数量分割,split按大小分割
- gather vs take: gather保持维度结构,take使用扁平索引
- scatter_ vs scatter_add_: scatter_替换值,scatter_add_累加值
- stack vs cat: stack创建新维度,cat在现有维度拼接
- reshape vs view: reshape自动处理连续性,view要求连续
基础知识
环境
开始一个项目之前,第一步是配环境,可以去官网下载pytorch
这里主要目的是学习,所以我们直接去谷歌的colab写代码,可以直接使用pytorch。
colab使用教程可参考
torch.chunk 的功能
torch.chunk 是 PyTorch 中的一个张量分割函数,用于将输入张量沿指定维度分割成多个子张量。子张量的数量可以指定,分割方式为均分或尽可能均分(当无法整除时)。
语法
torch.chunk(input, chunks, dim=0)
- input: 输入张量。
- chunks: 需要分割的子张量数量。
- dim: 沿哪个维度进行分割,默认为 0。
参数说明
- input: 必须是 PyTorch 张量(Tensor)。
- chunks: 正整数,表示分割的子张量数量。如果输入张量在指定维度上的大小无法被
chunks整除,最后一个子张量会较小。 - dim: 分割的维度索引,支持负数(表示从后往前索引)。
返回值
返回一个包含 chunks 个子张量的元组。子张量是输入张量的视图(view),共享底层数据。
示例代码
示例 1:沿默认维度 (dim=0) 分割
import torchx = torch.arange(10) # 形状 [10]
chunks = torch.chunk(x, 3) # 分割为 3 份
for c in chunks:print(c)
输出:
tensor([0, 1, 2, 3])
tensor([4, 5, 6, 7])
tensor([8, 9])
说明:10 无法被 3 整除,前两个子张量大小为 4,最后一个为 2。
示例 2:沿指定维度分割
y = torch.rand(4, 6) # 形状 [4, 6]
chunks = torch.chunk(y, 2, dim=1) # 沿第 1 维(列)分割
for c in chunks:print(c.shape)
输出:
torch.Size([4, 3])
torch.Size([4, 3])
说明:第 1 维大小为 6,被均分为 2 个子张量,每份大小为 3。

示例 3:无法整除的情况
z = torch.rand(5, 7) # 形状 [5, 7]
chunks = torch.chunk(z, 3, dim=1) # 沿第 1 维分割为 3 份
for c in chunks:print(c.shape)
输出:
torch.Size([5, 3])
torch.Size([5, 3])
torch.Size([5, 1])
说明:7 无法被 3 整除,前两个子张量大小为 3,最后一个为 1。

常见用途
- 数据并行处理时,将批量数据分割到不同设备。
- 将张量拆分为多个部分进行分步计算。
- 实现自定义的神经网络模块时分割输入特征。
注意事项
- 如果
chunks大于输入张量在指定维度上的大小,返回的子张量数量等于该维度大小,每个子张量大小为 1。 - 输入张量必须是连续的(contiguous),否则可能触发错误。可通过
input.contiguous()解决。
与类似函数的区别
torch.split: 可以指定每个子张量的大小(而非数量),灵活性更高。torch.unbind: 沿指定维度完全展开张量,返回大小为 1 的子张量序列。
torch.gather 的基本概念
torch.gather 是 PyTorch 中的一个函数,用于沿指定维度收集张量的值。它通过索引张量(index)从输入张量(input)中提取数据,生成一个新的张量。其核心功能是根据索引从输入张量中提取对应位置的值。
函数定义
torch.gather(input, dim, index, *, sparse_grad=False, out=None)
- input:输入张量,从中提取数据。
- dim:指定收集操作的维度。
- index:索引张量,形状需与
input在非dim维度上一致。 - sparse_grad:是否启用稀疏梯度(默认为
False)。 - out:输出张量(可选)。
工作原理
假设输入张量 input 的形状为 ( d 0 , d 1 , . . . , d n − 1 ) (d_0, d_1, ..., d_{n-1}) (d0,d1,...,dn−1),索引张量 index 的形状需满足:
- 除
dim维度外,其他维度大小与input相同。 index的值必须小于input在dim维度的大小。
输出张量的形状与 index 相同,其每个元素的计算公式为(对于3维张量来说):
output [ i ] [ j ] [ k ] = input [ index [ i ] [ j ] [ k ] ] [ j ] [ k ] ( if dim = 0 ) \text{output}[i][j][k] = \text{input}[\text{index}[i][j][k]][j][k] \quad (\text{if dim}=0) output[i][j][k]=input[index[i][j][k]][j][k](if dim=0)
out[i][j][k] = input[index[i][j][k]][j][k] # if dim == 0
out[i][j][k] = input[i][index[i][j][k]][k] # if dim == 1
out[i][j][k] = input[i][j][index[i][j][k]] # if dim == 2
使用示例
示例 1:沿行(dim=0)收集数据
import torch# 输入张量
input = torch.tensor([[1, 2, 3], [4, 5, 6]])# 索引张量
index = torch.tensor([[0, 1, 0], [1, 0, 1]])# 沿 dim=0 收集
output = torch.gather(input, dim=0, index=index)
print(output)
输出:
tensor([[1, 5, 3],[4, 2, 6]])
解释:
output[0][0] = input[ index[0][0] ][0] = input[0][0] = 1output[0][1] = input[ index[0][1] ][1] = input[1][1] = 5output[0][2] = input[ index[0][2] ][2] = input[0][2] = 3output[1][0] = input[ index[1][0] ][0] = input[1][0] = 4
也就是index成为对应位置要取的值的下标
示例 2:沿列(dim=1)收集数据
input = torch.tensor([[1, 2, 3], [4, 5, 6]])
index = torch.tensor([[1, 0], [2, 1]])# 沿 dim=1 收集
output = torch.gather(input, dim=1, index=index)
print(output)
输出:
tensor([[2, 1],[6, 5]])
解释:
output[0][0] = input[0][1] = 2output[0][1] = input[0][0] = 1output[1][0] = input[1][2] = 6
应用场景
- 高级索引操作:从张量中提取非连续或条件化的数据。
- 分类任务:从预测结果中提取特定类别的概率。
- 数据重排:根据索引重新组织张量的数据。
注意事项
- 索引张量
index的值必须在input的dim维度范围内,否则会报错。 index的形状必须与input在非dim维度上匹配。- 反向传播时,
torch.gather支持梯度计算。
通过灵活使用 torch.gather,可以实现复杂的数据提取和重组操作。
torch.reshape 的功能
torch.reshape 是 PyTorch 中的一个张量操作函数,用于改变张量的形状(shape),但不改变其数据内容和顺序。该函数返回一个与原始张量共享数据存储的新张量,但形状不同。如果给定的形状与原始张量元素总数不匹配,会抛出错误。
基本语法
torch.reshape(input, shape) → Tensor
input:需要改变形状的张量。shape:目标形状,可以是一个元组或列表,指定新张量的维度大小。
关键特性
- 共享存储:返回的张量与输入张量共享底层数据存储,修改其中一个会影响另一个。
- 连续性要求:如果目标形状满足连续性(contiguous)条件,操作高效;否则可能触发隐式拷贝。
- 元素总数不变:输入张量的元素总数必须与目标形状的元素总数一致,否则会报错。
示例代码
import torch# 原始张量
x = torch.arange(6) # tensor([0, 1, 2, 3, 4, 5])# 改变形状为 2x3
y = torch.reshape(x, (2, 3))
print(y)
# 输出: tensor([[0, 1, 2],
# [3, 4, 5]])# 尝试不兼容的形状会报错
try:z = torch.reshape(x, (3, 3)) # 元素总数不匹配
except RuntimeError as e:print(e) # 输出错误信息
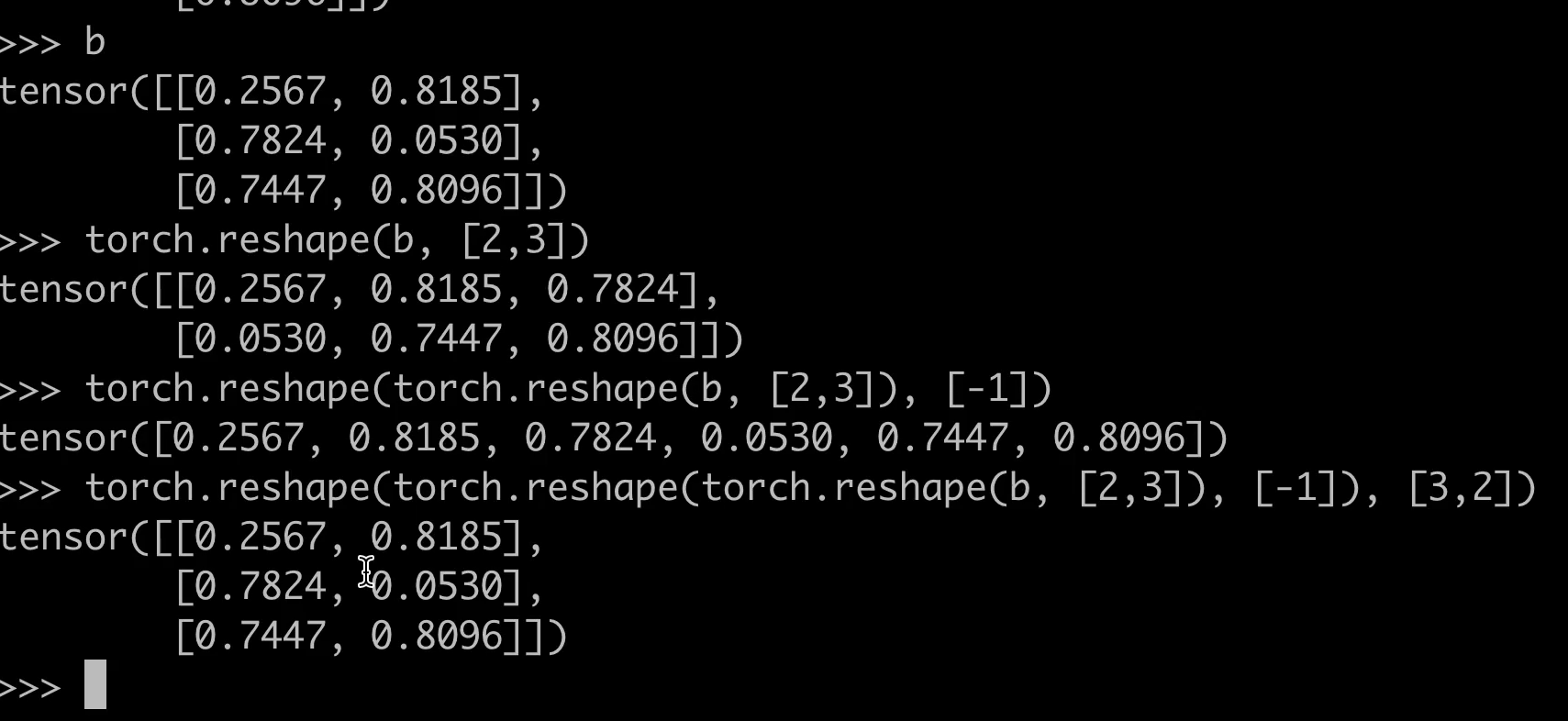
与 view() 的区别
view()要求张量是连续的(contiguous),否则需要先调用contiguous()。reshape()会自动处理连续性,若需要会触发拷贝,因此更通用但可能略慢。
常见用途
- 调整维度:将一维张量转换为多维张量,或反之。
- 适配模型输入:预处理数据以满足模型的输入形状要求。
- 扁平化操作:将多维张量展平为一维(如
reshape(-1))。
注意事项
- 避免在需要高效计算的场景中频繁使用,隐式拷贝可能影响性能。
- 确保目标形状的元素总数与原始张量一致。
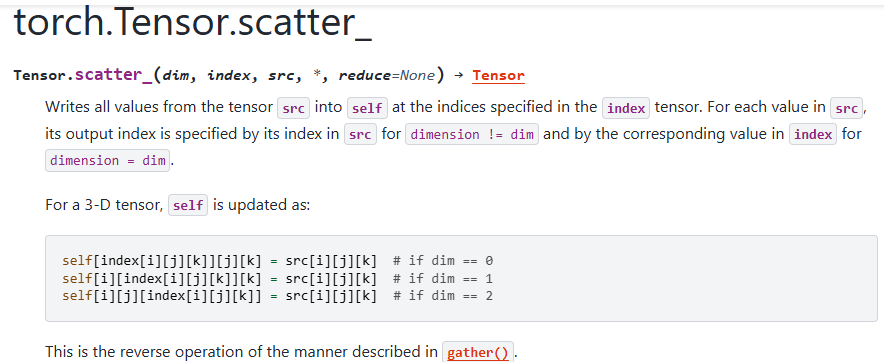
torch.scatter_ 的功能
torch.scatter_ 是 PyTorch 中的一个原地操作函数,用于按照指定的索引将张量的值分散(scatter)到目标张量中。该函数常用于将稀疏数据映射到密集张量中,或实现特定维度的赋值操作。其核心功能是根据 index 张量将 src 张量的值分配到目标张量的指定位置。
函数签名
torch.scatter_(dim, index, src) → Tensor
- dim:指定分散操作的维度(例如
dim=0表示按行分散,dim=1表示按列分散)。 - index:包含目标位置的索引张量,形状需与
src一致或可广播。 - src:包含待分散数据的源张量。
关键特性
- 原地操作:函数名末尾的下划线(
_)表示该操作会直接修改输入张量,而非返回新张量。 - 索引规则:
index张量的每个元素指定目标张量在dim维度的位置。- 若
index包含重复索引,结果可能取决于具体实现(通常后写入的值会覆盖先前的值)。
gather的逆运算:
示例代码
以下示例展示如何将数据分散到目标张量中:
import torch# 目标张量(将被修改)
target = torch.zeros(3, 5)
# 源数据
src = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 索引张量(指定列位置)
index = torch.tensor([[0, 1, 2], [0, 1, 2], [0, 1, 2]])# 按行分散(dim=1)
target.scatter_(1, index, src)
print(target)
输出:
tensor([[1, 2, 3, 0, 0],[4, 5, 6, 0, 0],[7, 8, 9, 0, 0]])
示例解析
该代码演示了PyTorch中scatter_方法的用法,将源张量src的数据按指定索引分散到目标张量target中。以下是关键点分析:
输入张量说明
- 目标张量
target:初始化为全零的3x5矩阵,作为数据写入的目标。 - 源张量
src:3x3矩阵,包含待分散的数据。 - 索引张量
index:3x3矩阵,指定src中每个元素应写入target的列位置。
操作逻辑
target.scatter_(dim=1, index=index, src=src)表示:
- 沿
dim=1(列方向)操作。 - 将
src[i][j]的值写入target[i][index[i][j]]的位置。 - 例如,
src[0][0]=1写入target[0][index[0][0]=0],即target[0][0]=1。
输出结果
- 前三列被
src的数据填充,后两列保持为0。 - 每行完成
src到target的按列映射:tensor([[1, 2, 3, 0, 0], # src的第一行[1,2,3]写入target前三列[4, 5, 6, 0, 0], # 第二行同理[7, 8, 9, 0, 0]])
常见应用场景
- 稀疏数据填充:将稀疏矩阵的非零值填充到密集矩阵中。
- 类别标签转换:如将分类标签转换为 one-hot 编码。
- 动态更新张量:在特定位置批量更新张量值。
注意事项
- 索引越界:
index的值必须在目标张量的dim维度范围内,否则会引发错误。 - 广播规则:
index和src的形状必须可广播到目标张量的形状。 - 性能影响:频繁使用原地操作可能影响计算图的构建,尤其在自动微分场景中需谨慎。
torch.scatter_add_ 概述
torch.scatter_add_ 是 PyTorch 中的一个张量操作方法,用于将指定来源张量的值按照索引规则累加到目标张量中。该操作是原地(in-place)操作,会直接修改目标张量。
功能说明
torch.scatter_add_ 的基本功能是将来源张量(src)的值按照索引(index)的规则累加到目标张量(self)中。具体行为如下:
- 目标张量的每个位置
self[i][j][...]会根据索引index[i][j][...]决定累加哪些src的值。 - 如果多个索引指向同一个目标位置,这些值会被累加。
语法
torch.scatter_add_(dim, index, src) → Tensor
dim:指定沿哪个维度进行散布操作。index:包含散布位置的索引张量,形状通常与src一致。src:来源张量,包含需要累加的值。
参数说明
dim(int):操作的维度,必须在[0, self.dim())范围内。index(LongTensor):索引张量,形状通常与src相同或可广播。src(Tensor):来源张量,包含需要累加的值。
示例代码
以下是一个简单的示例,展示如何使用 torch.scatter_add_:
import torch# 目标张量
self = torch.zeros(3, 5)# 来源张量
src = torch.tensor([[1, 2, 3, 4, 5], [6, 7, 8, 9, 10], [11, 12, 13, 14, 15]])# 索引张量
index = torch.tensor([[0, 1, 2, 0, 0], [2, 0, 0, 1, 2], [1, 2, 0, 1, 2]])# 沿 dim=1 进行 scatter_add
self.scatter_add_(1, index, src)print(self)
输出解释
假设输入如下:
self初始为零张量,形状为(3, 5)。src是一个形状为(3, 5)的张量。index是一个形状为(3, 5)的索引张量。
操作会按照 index 的指示将 src 的值累加到 self 中。例如:
- 对于
i=0和j=0,index[0][0] = 0,因此src[0][0] = 1被累加到self[0][0]。 - 如果多个
src值指向同一个self位置(如self[0][0]可能被多次累加),这些值会被求和。
注意事项
- 原地操作:
scatter_add_是原地操作,会直接修改目标张量。 - 索引范围:
index的值必须在目标张量的对应维度范围内,否则会抛出错误。 - 形状匹配:
index和src的形状必须可广播到目标张量的形状。
应用场景
torch.scatter_add_ 常用于需要高效聚合数据的场景,例如:
- 稀疏矩阵的构建或更新。
- 统计或直方图计算中按索引聚合数据。
- 图神经网络(GNN)中邻居信息的聚合。
与 torch.scatter_ 的区别
torch.scatter_ 的功能类似,但它是直接替换目标张量的值,而非累加。如果需要累加效果,应使用 scatter_add_。
torch.split 的基本功能
torch.split 是 PyTorch 中的一个张量分割函数,用于将输入张量沿指定维度拆分为多个子张量。支持通过固定大小或可变大小进行分割,适用于需要按块处理数据的场景。
参数说明
- tensor (Tensor): 待分割的输入张量。
- split_size_or_sections (int or list):
- 若为整数,表示每个子张量的固定大小(沿分割维度)。
- 若为列表,表示按列表中的值动态分割(如
[2, 1, 3]会生成大小为 2、1、3 的子张量)。
- dim (int, 可选): 分割的维度,默认为
0。
返回值
返回一个包含子张量的元组(Tuple[Tensor, ...])。
使用示例
按固定大小分割
import torch
x = torch.arange(10).reshape(2, 5) # 形状 (2, 5)
result = torch.split(x, 2, dim=1) # 沿第1维度每块大小为2
print(result)
# 输出: (tensor([[0, 1], [5, 6]]), tensor([[2, 3], [7, 8]]), tensor([[4], [9]]))
按动态大小分割
sections = [1, 4]
result = torch.split(x, sections, dim=1) # 第1维度分割为1和4
print(result)
# 输出: (tensor([[0], [5]]), tensor([[1, 2, 3, 4], [6, 7, 8, 9]]))
相当于就是规定分块的位置:

注意事项
- 若
split_size_or_sections不能整除分割维度的长度,最后一个子张量会小于指定大小。 - 动态分割时,列表值的总和必须等于分割维度的长度,否则会报错。
典型应用场景
- 批量数据处理时按块划分。
- 模型多分支输入的分割(如注意力机制中的多头分割)。
torch.squeeze 概述
torch.squeeze 是 PyTorch 中的一个张量操作函数,用于移除张量中所有维度为 1 的轴。若指定 dim 参数,则仅移除该特定维度(当且仅当该维度为 1 时)。
函数语法
torch.squeeze(input, dim=None) → Tensor
- input:输入张量。
- dim(可选):指定需移除的维度(索引从 0 开始)。若该维度不为 1,则张量保持不变。
核心功能
-
默认行为(不指定
dim):自动移除所有长度为 1 的维度。x = torch.zeros(1, 3, 1, 2) # 形状: [1, 3, 1, 2] y = torch.squeeze(x) # 形状: [3, 2] -
指定维度:仅当目标维度长度为 1 时生效。
x = torch.zeros(1, 3, 1, 2) y = torch.squeeze(x, dim=2) # 形状: [1, 3, 2] z = torch.squeeze(x, dim=0) # 形状: [3, 1, 2]
注意事项
- 若指定
dim但该维度长度不为 1,张量不会发生变化。 - 与
torch.unsqueeze(增加维度)互为逆操作。 - 非原地操作:返回新张量,原张量不变。
典型应用场景
- 处理模型输出:卷积层输出可能包含多余的批次维度(如
[1, C, H, W]),需压缩为[C, H, W]以便后续处理。 - 数据预处理:删除单通道图像的通道维度(如
[1, H, W]转为[H, W])。
示例代码
import torch# 移除所有长度为1的维度
a = torch.rand(1, 4, 1, 2)
b = torch.squeeze(a) # 形状: [4, 2] # 指定维度移除
c = torch.rand(3, 1, 5)
d = torch.squeeze(c, dim=1) # 形状: [3, 5] # 无效操作(dim不为1)
e = torch.rand(2, 3)
f = torch.squeeze(e, dim=0) # 形状仍为 [2, 3]
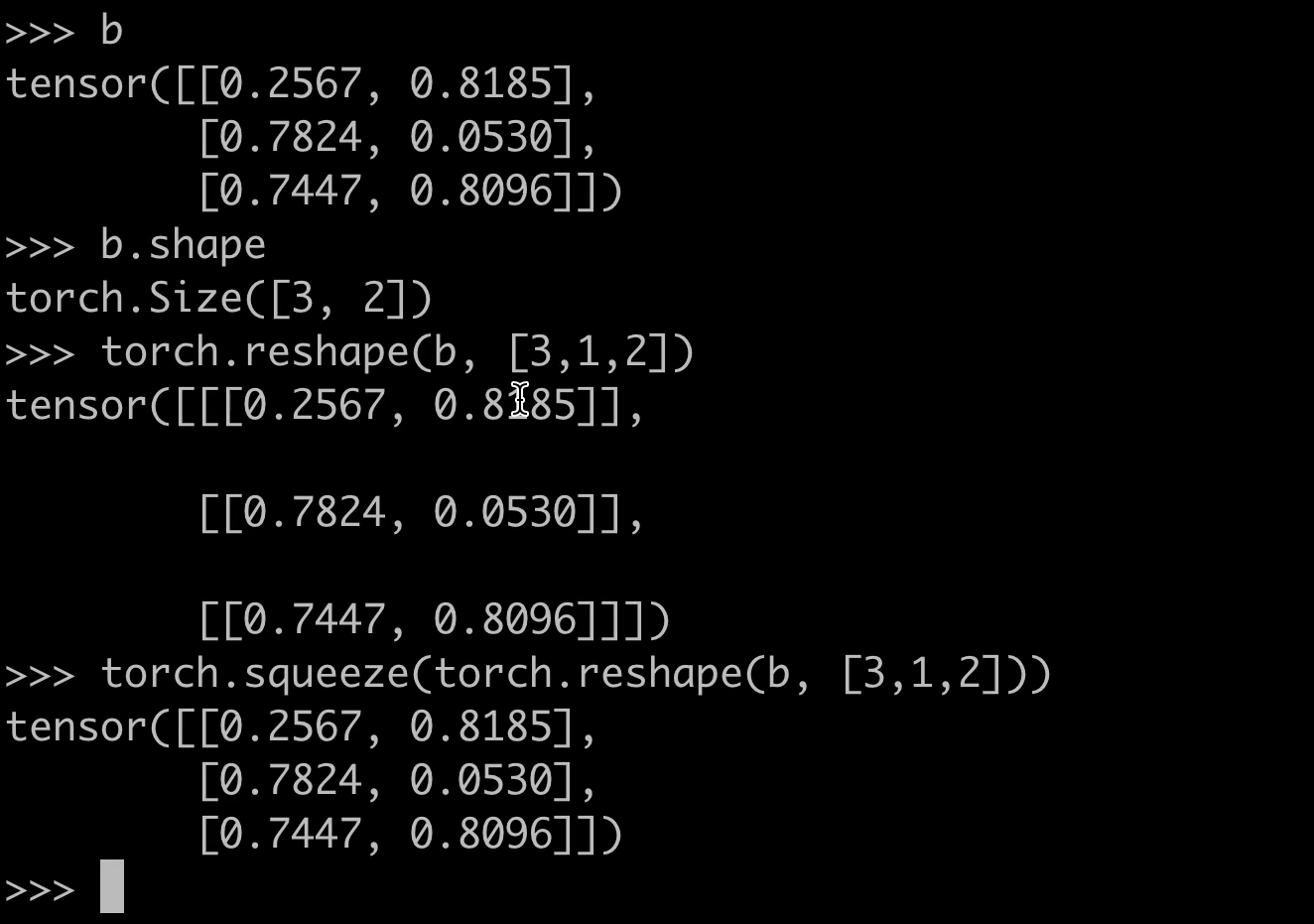
通过合理使用 torch.squeeze,可简化张量形状,避免不必要的维度干扰计算或可视化流程。
可以选择维度,一次只能选择一个:
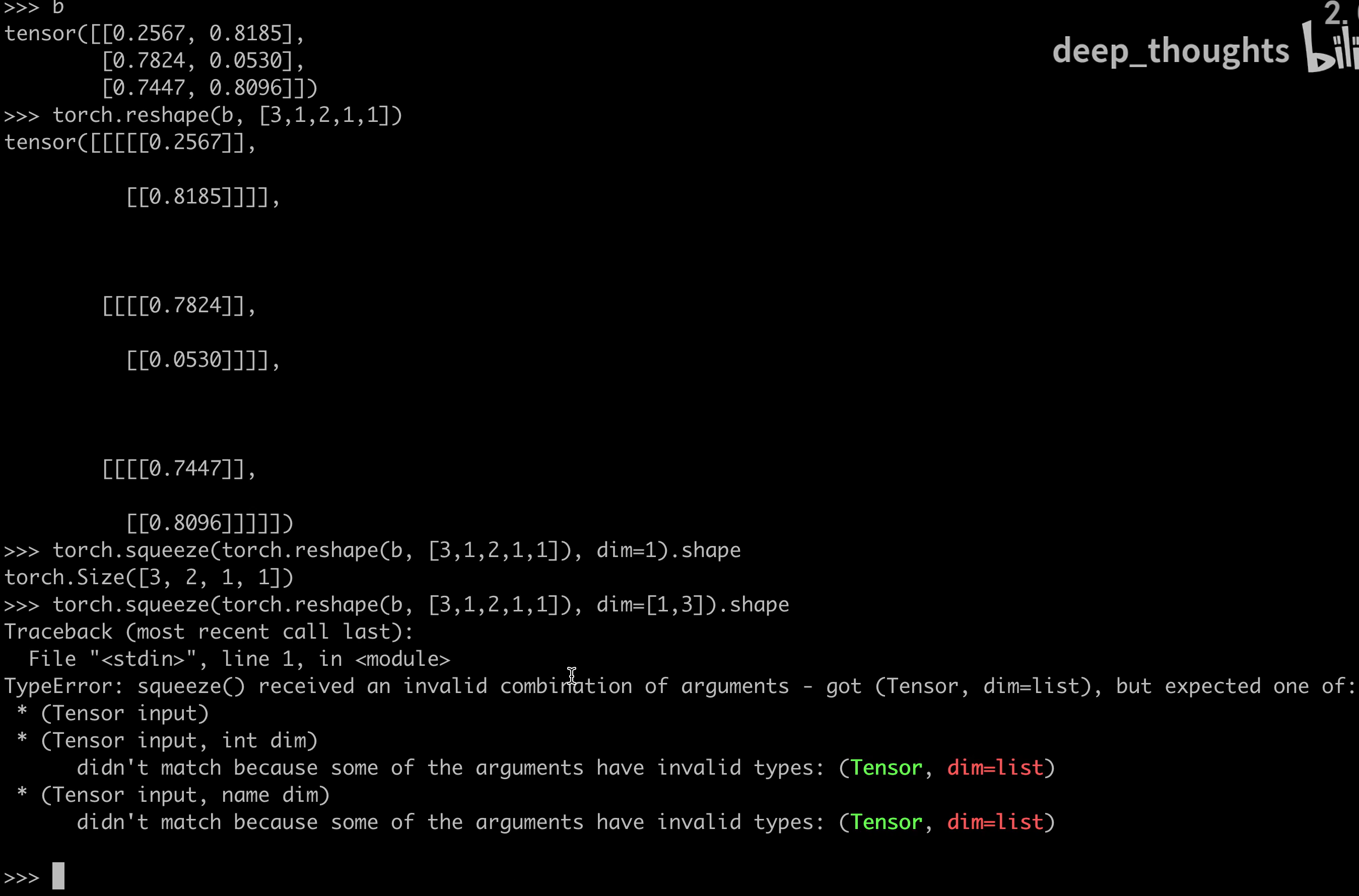
torch.stack 的基本概念
torch.stack 是 PyTorch 中用于将多个张量(tensors)沿新维度堆叠的函数。与 torch.cat 不同,torch.stack 会创建一个新的维度,而 torch.cat 仅在现有维度上拼接。
语法格式
torch.stack(tensors, dim=0, *, out=None)
- tensors:需要堆叠的张量序列(如列表或元组)。
- dim:指定新维度的位置,默认为
0。 - out(可选):输出张量。
关键特性
- 输入张量形状必须一致:所有输入张量的形状需完全相同。
- 输出维度增加:输出张量的维度比输入张量多一维。
- 堆叠方向:通过
dim参数控制堆叠方向,例如dim=0在行方向堆叠,dim=1在列方向堆叠。
示例代码
示例 1:沿新维度堆叠
import torchx = torch.tensor([1, 2, 3])
y = torch.tensor([4, 5, 6])# 默认沿 dim=0 堆叠
stacked = torch.stack([x, y])
print(stacked)
# 输出:
# tensor([[1, 2, 3],
# [4, 5, 6]])
输出张量的形状为 (2, 3),其中 2 是新创建的维度。
示例 2:指定堆叠维度
# 沿 dim=1 堆叠
stacked_dim1 = torch.stack([x, y], dim=1)
print(stacked_dim1)
# 输出:
# tensor([[1, 4],
# [2, 5],
# [3, 6]])
输出张量的形状为 (3, 2),新维度插入在 dim=1 的位置。
示例 3:堆叠三维张量
a = torch.randn(2, 3)
b = torch.randn(2, 3)# 沿 dim=2 堆叠(需确保 dim 不超过输入维度+1)
stacked_3d = torch.stack([a, b], dim=2)
print(stacked_3d.shape) # 输出:torch.Size([2, 3, 2])
与 torch.cat 的区别
torch.cat在现有维度上拼接,不创建新维度。torch.stack必须创建新维度,输入张量的形状需完全一致。
# torch.cat 示例
cat_result = torch.cat([x.unsqueeze(0), y.unsqueeze(0)], dim=0)
print(cat_result) # 输出与 torch.stack([x, y]) 相同,但逻辑不同
常见应用场景
- 批量数据处理:将多个样本堆叠为批次(batch)。
- 多通道数据合并:如将 RGB 图像的三个通道堆叠为三维张量。
- 时间序列处理:堆叠不同时间步的数据。
注意事项
- 若输入张量形状不一致,会触发
RuntimeError。 - 堆叠后的张量会占用更多内存,需注意显存限制。
torch.take 的功能
torch.take 用于从输入张量中按照给定的索引提取元素,返回一个新张量。索引可以是扁平化后的线性索引(即将输入张量视为一维数组),支持任意维度的输入张量。
参数说明
- input (Tensor): 输入张量,可以是任意维度。
- index (Tensor): 索引张量,每个元素代表输入张量扁平化后的位置(从0开始)。索引张量可以是任意形状。
返回值
返回一个与 index 同形状的张量,其值为 input 中对应索引位置的元素。
示例代码
import torch# 示例1:从二维张量中提取元素
x = torch.tensor([[1, 2], [3, 4]])
indices = torch.tensor([0, 3]) # 扁平化后索引0(1)和索引3(4)
result = torch.take(x, indices) # 输出 tensor([1, 4])# 示例2:从高维张量中提取
y = torch.randn(2, 3, 4)
indices = torch.tensor([0, 10, 5])
result = torch.take(y, indices) # 提取扁平化后的第0、10、5个元素
注意事项
- 索引值必须在
[0, input.numel() - 1]范围内,否则会报错。 - 输入张量不会因操作而改变,始终返回新张量。
- 若需按维度提取元素,可考虑使用
torch.gather或torch.index_select。
与相似函数的区别
- torch.index_select: 按指定维度的索引提取子张量,索引需为1D张量。
- torch.gather: 按多维索引提取元素,支持更灵活的维度对齐。
- torch.take: 仅依赖扁平化后的线性索引,适用于无明确维度的场景。
torch.tile 的功能
torch.tile 是 PyTorch 中的一个张量操作函数,用于沿指定维度重复张量的内容。该函数通过复制输入张量的数据来扩展其形状,类似于 NumPy 的 tile 函数。其核心用途是快速生成重复模式的张量,无需手动拼接。
语法格式
函数调用形式为:
torch.tile(input, dims)
- input:需要重复的输入张量。
- dims:指定每个维度重复次数的元组或列表。长度必须与输入张量的维度数一致。
示例说明
假设有一个一维张量 [1, 2],若想将其重复两次生成 [1, 2, 1, 2],可执行以下操作:
import torch
x = torch.tensor([1, 2])
y = torch.tile(x, (2,)) # 输出 tensor([1, 2, 1, 2])
对于二维张量,如 [[1, 2], [3, 4]],若沿行重复 2 次、列重复 3 次:
x = torch.tensor([[1, 2], [3, 4]])
y = torch.tile(x, (2, 3))
# 输出:
# tensor([[1, 2, 1, 2, 1, 2],
# [3, 4, 3, 4, 3, 4],
# [1, 2, 1, 2, 1, 2],
# [3, 4, 3, 4, 3, 4]])
与 repeat 的区别
torch.repeat 功能类似,但两者在参数传递方式上存在差异:
tile直接接受目标维度的元组。repeat需要在每个维度上显式指定重复次数,如x.repeat(2, 3)与上述tile示例等效。
常见应用场景
- 数据扩增:快速复制张量以匹配网络输入的批量维度。
- 模式生成:创建周期性结构(如棋盘格、网格)。
- 广播兼容:调整张量形状以实现广播机制要求的维度对齐。
注意事项
- 内存占用:重复操作会显式增加内存使用,需注意大规模重复时的显存限制。
- 维度匹配:
dims的长度必须与输入张量的维度数一致,否则会抛出错误。
torch.transpose 概述
torch.transpose 是 PyTorch 中的一个函数,用于交换张量的两个维度。它适用于任意维度的张量,常用于矩阵转置或调整张量的维度顺序。
基本语法
torch.transpose(input, dim0, dim1) → Tensor
- input: 输入张量。
- dim0: 第一个要交换的维度。
- dim1: 第二个要交换的维度。
功能说明
torch.transpose 会返回一个新的张量,其中 dim0 和 dim1 两个维度的顺序被交换。原始张量不会被修改(除非使用原地操作)。
示例代码
矩阵转置(2D张量)
对于一个 2D 张量(矩阵),torch.transpose 可以实现矩阵的转置:
import torchx = torch.tensor([[1, 2, 3], [4, 5, 6]])
y = torch.transpose(x, 0, 1)
print(y)
输出:
tensor([[1, 4],[2, 5],[3, 6]])
高维张量交换维度
对于高维张量,可以交换任意两个维度:
x = torch.randn(2, 3, 4)
y = torch.transpose(x, 1, 2) # 交换第1和第2维度
print(y.shape) # 输出: torch.Size([2, 4, 3])
与 permute 的区别
torch.transpose 只能交换两个维度,而 torch.permute 可以重新排列所有维度的顺序:
x = torch.randn(2, 3, 4)
y = x.permute(2, 0, 1) # 将维度重新排列为 (4, 2, 3)
注意事项
- 非连续张量:
torch.transpose操作后的张量可能是非连续的,如果需要连续张量,可以调用.contiguous()。 - 性能影响:频繁的维度交换可能会影响计算效率,尤其是在 GPU 上。
替代方法
对于矩阵转置,可以直接使用 .T 属性:
x = torch.tensor([[1, 2, 3], [4, 5, 6]])
y = x.T
torch.unbind 函数概述
torch.unbind 是 PyTorch 中的一个张量操作函数,用于将输入张量沿指定维度拆分为多个子张量。该函数返回一个由子张量组成的元组,每个子张量是输入张量在指定维度上的切片。
语法
torch.unbind(input, dim=0) → tuple
- input:待拆分的输入张量。
- dim:指定拆分的维度(默认为 0)。
功能说明
- 将输入张量
input沿维度dim拆分为input.size(dim)个子张量。 - 每个子张量的维度比输入张量少一维(移除拆分后的
dim维度)。 - 若
input在dim维度上的大小为n,则返回一个包含n个子张量的元组。
示例代码
示例 1:沿默认维度(dim=0)拆分
import torchx = torch.tensor([[1, 2, 3], [4, 5, 6]])
unbind_tensors = torch.unbind(x) # 沿 dim=0 拆分
print(unbind_tensors)
# 输出:(tensor([1, 2, 3]), tensor([4, 5, 6]))
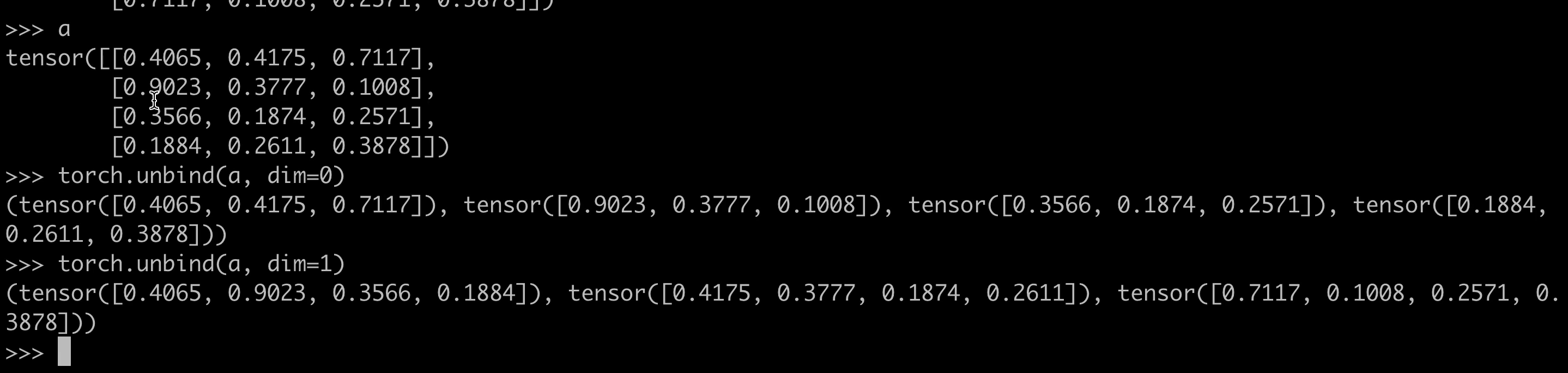
示例 2:沿指定维度(dim=1)拆分
y = torch.tensor([[1, 2], [3, 4], [5, 6]])
unbind_tensors = torch.unbind(y, dim=1) # 沿 dim=1 拆分
print(unbind_tensors)
# 输出:(tensor([1, 3, 5]), tensor([2, 4, 6]))
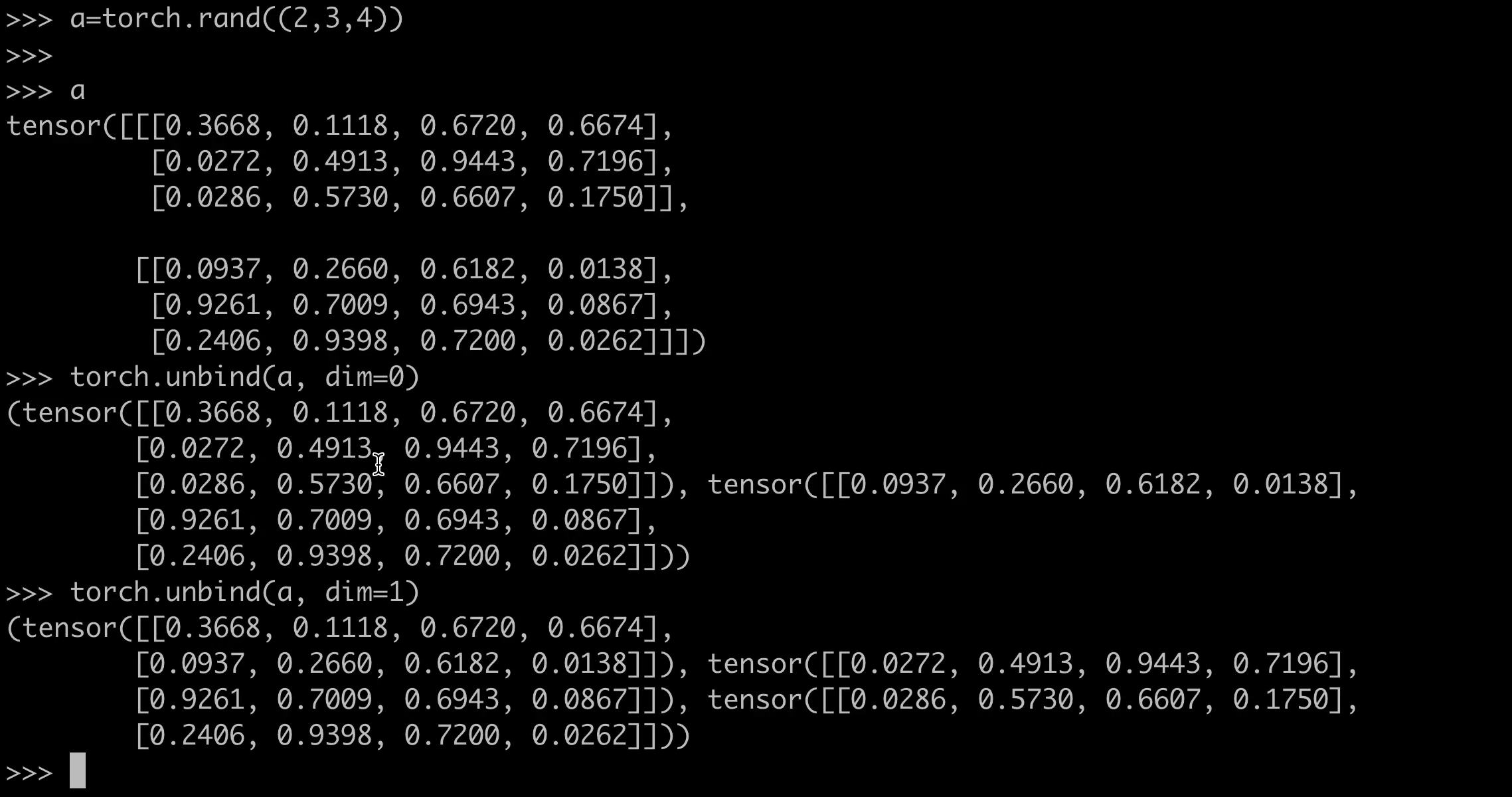
示例 3:三维张量拆分
z = torch.rand(2, 3, 4) # 形状为 (2, 3, 4)
unbind_tensors = torch.unbind(z, dim=1) # 沿 dim=1 拆分
print(len(unbind_tensors)) # 输出 3(因为 dim=1 的大小为 3)
print(unbind_tensors[0].shape) # 输出 torch.Size([2, 4])
注意事项
- 拆分后的子张量与输入张量共享存储空间(即视图操作),修改子张量会影响原始张量。
- 若需复制数据,需显式调用
.clone()。 - 类似功能的函数包括
torch.split()(按指定大小拆分)和torch.chunk()(按数量拆分)。
应用场景
- 处理序列数据时按时间步拆分(如 RNN 输入)。
- 提取张量的特定维度分量(如分离 RGB 图像的通道)。
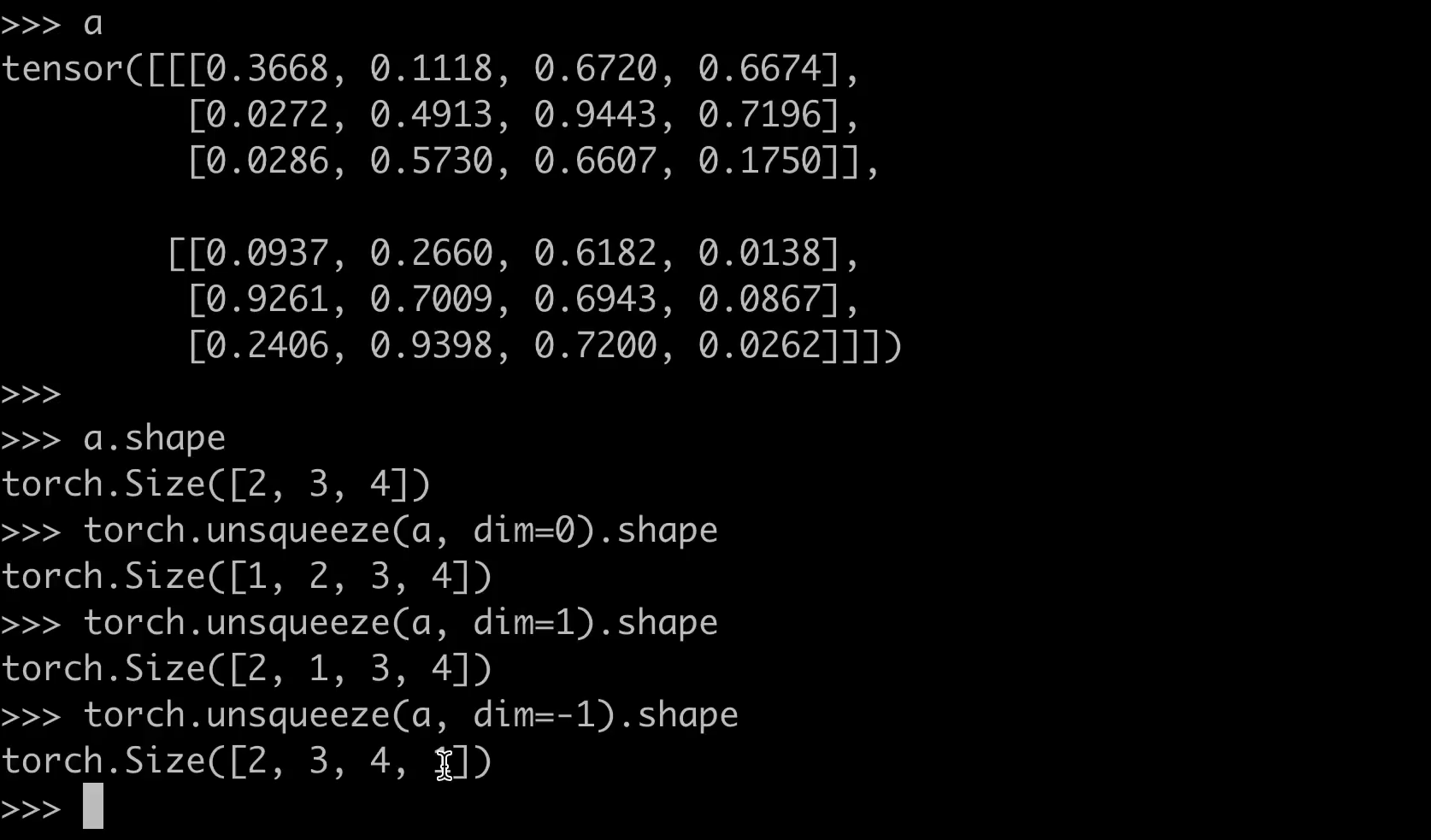
torch.unsqueeze函数的功能
torch.unsqueeze是PyTorch中的一个张量操作函数,用于在指定维度上增加一个大小为1的维度。这种操作通常用于调整张量的形状,使其满足某些运算的维度要求。
基本语法
torch.unsqueeze(input, dim)
- input: 输入张量。
- dim: 指定要插入新维度的位置(从0开始索引)。
使用示例
假设有一个形状为(3,)的一维张量:
import torchx = torch.tensor([1, 2, 3])
print(x.shape) # 输出: torch.Size([3])
在维度0上插入一个新维度:
y = torch.unsqueeze(x, dim=0)
print(y.shape) # 输出: torch.Size([1, 3])
在维度1上插入一个新维度:
z = torch.unsqueeze(x, dim=1)
print(z.shape) # 输出: torch.Size([3, 1])
等价操作
torch.unsqueeze也可以通过张量的unsqueeze方法实现:
y = x.unsqueeze(dim=0)
z = x.unsqueeze(dim=1)
实际应用场景
-
广播机制:当需要将一个张量的形状与其他张量对齐以进行广播时,
unsqueeze非常有用。 -
神经网络输入:通常需要将一维输入数据调整为二维(批量维度)或三维(时间序列)形式。
-
矩阵乘法:调整张量形状以满足矩阵乘法的维度要求。
注意事项
- 插入的维度大小始终为1。
dim参数的取值范围是[-input.dim()-1, input.dim()],负数表示从后向前索引。- 该操作不会改变张量的数据,仅调整形状。
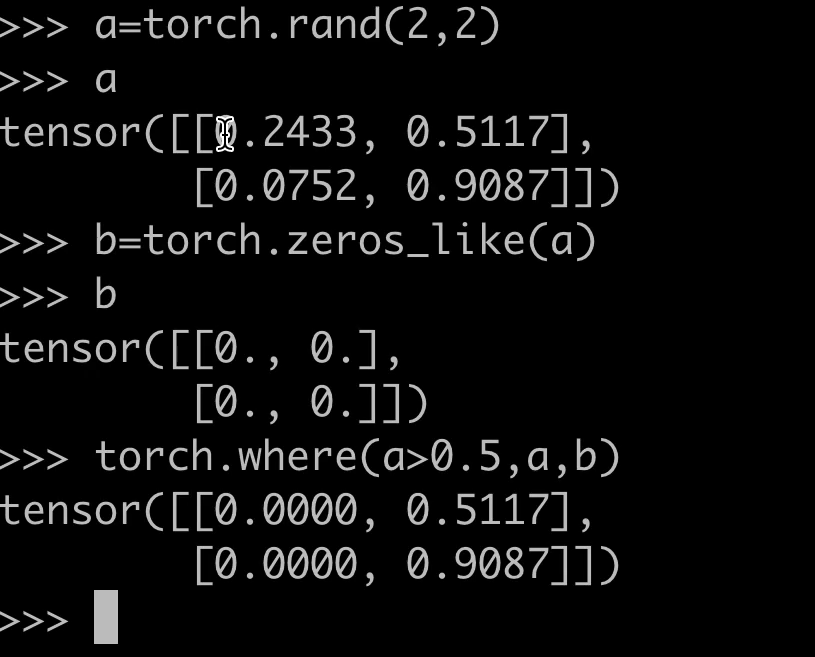
torch.where 的基本功能
torch.where 是 PyTorch 中的一个条件选择函数,根据条件从两个张量中选择元素。语法如下:
torch.where(condition, x, y)
condition:布尔型张量,决定选择x还是y的元素。x和y:形状相同的张量(或可广播为相同形状),提供待选择的元素。- 返回值:与
x和y形状相同的张量,元素根据condition从x或y中选取。
使用示例
示例 1:基础用法
import torchcondition = torch.tensor([[True, False], [False, True]])
x = torch.tensor([[1, 2], [3, 4]])
y = torch.tensor([[10, 20], [30, 40]])result = torch.where(condition, x, y)
# 输出:tensor([[ 1, 20], [30, 4]])
示例 2:广播机制
condition = torch.tensor([True, False, True])
x = torch.tensor(1) # 标量广播
y = torch.tensor([10, 20, 30])result = torch.where(condition, x, y)
# 输出:tensor([ 1, 20, 1])
应用场景
-
替换满足条件的元素
将张量中满足条件的值替换为指定值:tensor = torch.tensor([-1, 2, -3]) result = torch.where(tensor < 0, torch.zeros_like(tensor), tensor) # 输出:tensor([0, 2, 0]) -
实现分段函数
例如,ReLU 函数:def relu(x):return torch.where(x > 0, x, torch.zeros_like(x)) -
掩码操作
结合布尔条件进行数据过滤:data = torch.randn(3, 3) mask = data > 0.5 filtered = torch.where(mask, data, torch.zeros_like(data))
注意事项
x和y的形状必须可广播为相同形状。condition必须是布尔型张量。- 若仅传入
condition参数(无x和y),返回满足条件的元素索引(与numpy.where行为类似)。
torch.manual_seed 的作用
torch.manual_seed 是 PyTorch 中用于设置随机数生成器种子的函数。通过设置相同的种子,可以确保每次运行程序时生成的随机数序列相同,从而实现实验的可重复性。这在机器学习和深度学习的实验中尤为重要,因为许多操作(如权重初始化、数据打乱等)依赖于随机数生成器。
使用方法
调用 torch.manual_seed 时需要传入一个整数作为种子值。种子值可以是任意整数,但通常选择固定的值(如 42)以确保实验的可重复性。
import torch# 设置随机种子为42
torch.manual_seed(42)
应用场景
- 权重初始化:神经网络的权重通常需要随机初始化,设置相同的种子可以确保每次训练的初始权重相同。
- 数据打乱:在数据加载过程中,设置种子可以确保每次数据打乱的顺序一致。
- 实验复现:在科学实验中,设置种子可以确保其他研究者能够复现实验结果。
注意事项
- 如果代码中使用了 CUDA(即 GPU 加速),还需要设置
torch.cuda.manual_seed或torch.cuda.manual_seed_all以确保 GPU 上的随机操作也是可重复的。 - 某些操作可能不受
torch.manual_seed影响,例如 Python 内置的random模块或 NumPy 的随机数生成器。如果使用了这些模块,需要分别设置它们的种子。
示例代码
以下是一个完整的示例,展示如何通过设置种子确保实验的可重复性:
import torch# 设置随机种子
torch.manual_seed(42)# 生成随机张量
random_tensor = torch.rand(3, 3)
print(random_tensor)
每次运行上述代码时,random_tensor 的值都会相同。
torch.bernoulli 功能概述
torch.bernoulli 是 PyTorch 中的一个函数,用于从伯努利分布中生成随机样本。伯努利分布是二项分布的特例,其输出为 0 或 1,概率由输入张量的对应值决定。
语法格式
torch.bernoulli(input, *, generator=None, out=None) → Tensor
- input:输入张量,每个元素表示伯努利分布的概率(取值范围 [0, 1])。
- generator:可选参数,用于控制随机数生成的随机种子。
- out:可选输出张量。
参数说明
-
input:
- 必须是浮点类型(如
float32或float64)的张量。 - 每个元素值应在 [0, 1] 区间内,表示生成 1 的概率。
- 必须是浮点类型(如
-
generator:
- 通过
torch.Generator()设置随机种子,确保实验结果可复现。
- 通过
-
out:
- 指定输出张量的形状和数据类型需与
input一致。
- 指定输出张量的形状和数据类型需与
使用示例
import torch# 示例1:基础用法
prob = torch.tensor([0.3, 0.7])
samples = torch.bernoulli(prob) # 可能输出 tensor([0., 1.])# 示例2:生成随机矩阵
prob_matrix = torch.rand(2, 3) # 生成 2x3 的概率矩阵
samples_matrix = torch.bernoulli(prob_matrix) # 输出同形状的 0/1 矩阵# 示例3:设置随机种子
gen = torch.Generator().manual_seed(42)
samples_seeded = torch.bernoulli(torch.tensor([0.5]), generator=gen)
注意事项
- 输入范围:若
input的值超出 [0, 1],可能引发未定义行为或错误。 - 随机性:每次调用结果不同,除非固定随机种子。
- 设备兼容性:输入张量可在 CPU 或 GPU 上运行,输出与输入设备一致。
数学原理
对于输入概率 ( p ),函数生成 1 的概率为 ( p ),生成 0 的概率为 ( 1-p )。公式表示为:
[ P ( x ) = { p if x = 1 , 1 − p if x = 0. ] [ P(x) = \begin{cases} p & \text{if } x=1, \ 1-p & \text{if } x=0. \end{cases} ] [P(x)={pif x=1, 1−pif x=0.]
应用场景
- 模拟二分类问题的随机标签。
- 实现 dropout 等随机掩码操作。
- 强化学习中的动作采样。
torch.normal 概述
torch.normal 是 PyTorch 中用于生成服从正态分布(高斯分布)随机张量的函数。支持多种参数形式,适用于生成不同均值和标准差的随机数。
基本语法
torch.normal(mean, std, *, generator=None, out=None)
- mean:均值,可以是标量或张量。
- std:标准差,可以是标量或张量。
- generator:随机数生成器(可选)。
- out:输出张量(可选)。
参数组合方式
1. 均值和标准差为标量
生成所有元素服从同一正态分布的张量:
# 生成形状为 (2, 3) 的张量,均值为 0,标准差为 1
x = torch.normal(mean=0.0, std=1.0, size=(2, 3))
2. 均值为张量,标准差为标量
为每个元素指定不同均值,但共享同一标准差:
mean = torch.arange(1.0, 3.0) # [1.0, 2.0]
x = torch.normal(mean=mean, std=0.5) # 输出形状与 mean 一致
3. 均值和标准差均为张量
均值和标准差需形状一致:
mean = torch.tensor([1.0, 2.0])
std = torch.tensor([0.1, 0.2])
x = torch.normal(mean=mean, std=std)
注意事项
- 若
mean或std为张量,输出形状与输入张量一致。 - 标准差
std必须为非负数。 - 通过
size参数可显式指定输出形状,但需与均值和标准差的形状兼容。
示例代码
生成一个 3x3 矩阵,均值为 0,标准差为 0.1:
x = torch.normal(0.0, 0.1, size=(3, 3))
生成与输入张量形状相同的随机数:
mean = torch.rand(2, 2)
std = torch.rand(2, 2)
x = torch.normal(mean, std)
其他提到的随机采样函数:
