Vllm Semantic-router MoM 架构
Vllm Semantic-router MoM 架构
在开始之前,先看两个问题,作为文章引子。
第一个问题:什么是路由,大模型中路由的是什么?
路由在维基百科中的定义是:路由(routing)是任何网络中选取路径的程序,在此"程序"是指一组在电脑中执行的程序。一般由 Gateway 担任路由角色,将流量通过一些特征路由到指定的后端服务。
在大模型中,将自然语言任务交给更适合的“模型”来完成便是大模型路由。
第二个问题:大模型路由可以做什么?
设想以下内容:我的问题是帮我计算一个数学问题:2x^2−4x−6=0 的解是什么?众所周知,数学不能只看答案,理解怎么得出结果的过程才是最重要的。那我就需要大模型开启 CoT(Chain-Of-Thought)深度思考来说明是怎么得出解。现在我的问题换成了今天的天气怎么样?这对模型来说是简单问题,只需要一次工具调用即可得到答案。
对于问题一,如果使用的是 DeepSeek-R1 模型,自带 CoT 输出,效果是最好的。如果是不带 CoT 的输出,只给一个答案,不符合实际。如果是复杂的数学题,我们选择更厉害、更贵的 GPT5 模型,简单的问题选择 GPT3 模型,节约成本。
对于问题二,如果使用的是 DeepSeek-R1 模型,调用天气工具,还要输出 reasoning content,多此一举还浪费 Token。
现在我们将问题放大到用户自然语言的输入上,面对如何选择合适的模型,花费最少的 Token、最少的算力来解决用户的问题,便是模型路由要解决的问题。
现在,我们知道了模型路由是什么以及需要解决的问题之后。
在接着往下,讨论关于模型路由的解决方案。文章中将会介绍两类模型路由方案: MoE 和 Vllm SR 提出来的的 MoM 架构方案。
1. Mixture-of-Expert (MoE) 架构
混合专家(Mixture-of-Experts,简称 MoE)。
MOE 架构的基本思想是在传统 Transformer 模型中,将每个前馈网络(FFN)层替换为一个 MoE 层。一个 MOE 层通常由两个关键部分组成:
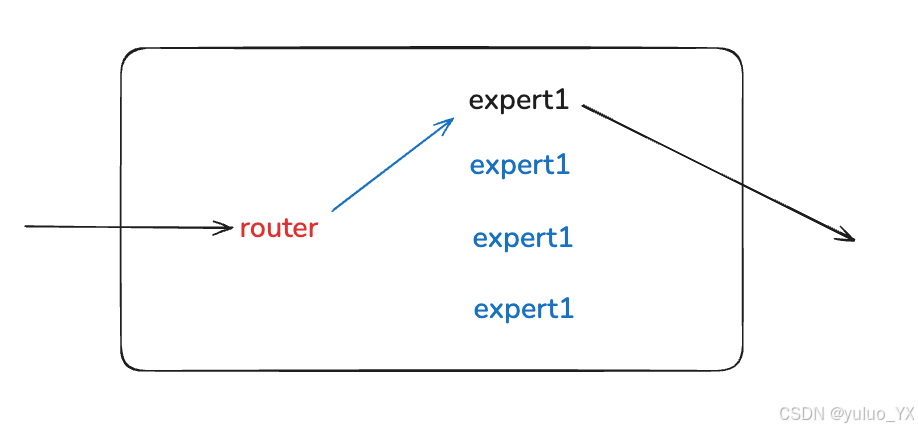
- 专家网络(Experts)
每个专家是一个独立的子网络(通常是 FFN),在实际计算中只有部分专家会被激活并参与处理。通过让多个专家分担不同数据子集计算的方式,模型在预训练时可以以较低的算力开销获得大参数量带来的涌现能力。 - 门控网络(Gating/Router)
负责根据输入的 Token 特征动态选择激活哪些专家。门控网络一般采用一个带 softmax 的简单前馈网络来计算每个专家的权重。经过训练后,门控网络会逐步学会将相似的输入路由到表现更好的专家。
在 DeepSeek‑V3 等 MOE 大模型中,通过将 FFN 层替换为 MOE 层,在拥有海量参数的同时,其实际计算量却与传统稠密模型相当,实现了高效预训练和快速推理。
1.1 工作原理
当一个 Token 的表示传入 MoE 层时,首先会经过 Gate 网络,该网络负责计算 token 与各个路由专家之间的匹配得分。具体流程是:
- 计算匹配得分
Gate 网络通过线性变换计算每个 token 与所有路由专家的兼容性得分。得分反映了 token 与各专家“契合”的程度。 - 选择 Top-K 专家
基于得分,Gate 网络为每个 token 选择 Top-K 个最合适的路由专家。在 DeepSeek‐V3 中,每个 token 通常选择 8 个路由专家(在一些实现中还可能对跨节点路由做限制,如最多路由到 4 个不同节点),从而只激活极少数专家进行计算,使用更少参数和算力解决问题。 - 专家处理与加权聚合
被选中的专家各自对 token 进行独立处理(一般采用一个轻量级的前馈网络,类似于 Transformer 中的 FFN 模块),产生各自的输出。最终,这些专家的输出会根据 Gate 网络给出的权重进行加权聚合,再与共享专家的输出进行融合,形成当前 MoE 层的最终输出表示。
1.2 简单理解
在一个超大的模型里,放很多“专家”子网络,Token 输入进来之后,router 根据 embedding 计算分数,选 top-k 个专家,激活参数进行推理并得出结果。理论上,既能扩大容量,又能节省推理开销。
由此可以看到显而易见的缺点:根据 Token 打分,并没有真正理解上下文语义,也不真正关心整个任务目标。最终选择的专家可能对当前的用户问题没有任何用户,只是分数接近。
关于 LLM Token,参考 https://yuluo-yx.github.io/docs/LLMs-AI-llms-what-token。
2. Mixture of Models (MoM) 架构
混合模型 (Mixture-of-Models,简称 MoM)。
了解了什么是 MoE 架构,接下来再看看 MoM 架构。和 MoE 不同的是,MoM 更强调语义概念,通过理解语义,理清问题,之后再交由具体的 experts 处理。
不再根据输入的 Token 去计算得分决定由哪些专家解决问题,而是当一条完整请求进来时,先用一个轻量的语义编码器做语义判别,理解清楚请求语义,然后一次性决定这条请求该交给哪一个模型或模型组合来处理。这就是所谓的 MoM(Mixture of Models)。
3. Semantic Router
对于大模型来说,用户输入的 Prompt 可能会有多个答案输出,并不是像传统的路由服务,路由到一个确定的 backend。相同的模型面对相同的 Prompt 都会有不同的输出,所以是不可控的。
所以语义感知的路由:slee让 router 不只是要分配“哪个机器来算”,而是要理解“用户到底想干什么”,再决定“哪个模型最合适
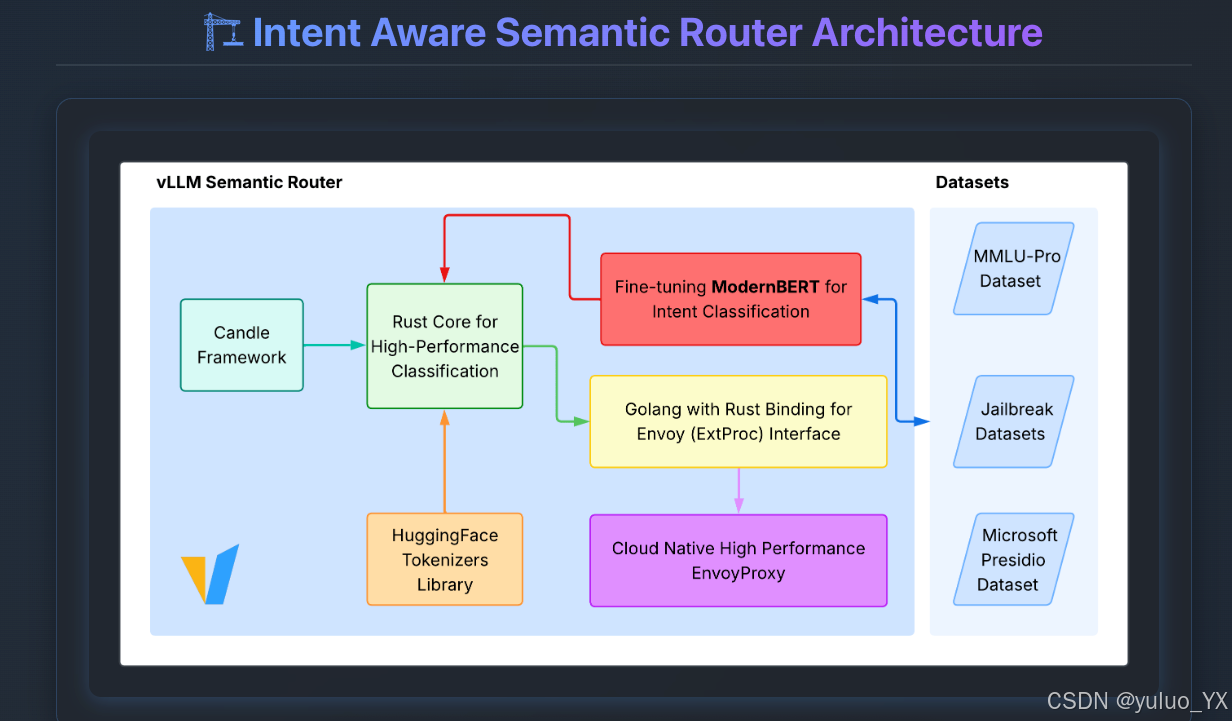
下图为 Vllm SR 的核心架构:
3. 参考链接
- Vllm SR:https://github.com/vllm-project/
- MOE (Mixture of Experts)架构:https://huggingface.co/blog/zh/moe
- MOM (Mixture of models)架构:https://x.com/shao__meng/status/1811187309116895402
- 语义路由:https://thenewstack.io/semantic-router-and-its-role-in-designing-agentic-workflows/
- https://github.com/katanemo/archgw/tree/main/demos/use_cases/claude_code_router
- https://arxiv.org/abs/2406.18665
- https://arxiv.org/abs/2506.16655
- https://mp.weixin.qq.com/s/S6un8mBPE53HlpYrgNs6Nw
- Transformer 模型: https://zhuanlan.zhihu.com/p/338817680