推荐系统学习笔记(十八)SECR-快手-用户留存建模
论文链接: https://arxiv.org/pdf/2504.05628
论文标题:Stratified Expert Cloning for Retention-Aware Recommendation at Scale
研究方向:多目标/留存优化
来源:快手
关键词:模仿学习、用户分层、留存优化
1.背景与挑战
为什么“留存”突然成了推荐系统的主角?
在流量红利见顶的今天,平台拉新成本逐年飙升,“让用户明天继续打开 App” 比“让用户多点一次”更值钱。传统 CTR、CVR 模型把每条样本当成独立事件,只顾眼前 GMV,却忽视推荐对用户长期活跃度的滞后影响;强化学习理论上可以最大化长期回报,但奖励稀疏、信用分配困难,再加上超大动作空间,真线上跑几周就翻船。
快手团队给出的解题思路很直接:“别硬憋奖励函数了,直接照抄高留存用户的行为!” 这就是他们发表在 CIKM’25 的《Stratified Expert Cloning for Retention-Aware Recommendation at Scale》的核心——用模仿学习复制“留存专家”的决策轨迹,再按用户层级动态匹配最合适的专家策略,兼顾个性化与多样性。
优化长期用户保留的挑战
在现实世界的推荐系统中优化长期用户保留提出了几个技术挑战:
-
1. 延迟影响和信用分配:推荐对用户保留的影响通常是延迟的,使得将保留结果归因于特定动作变得困难。例如,用户可能会收到新类别的推荐,这会激发他们的兴趣并导致短期参与度增加。然而,这种推荐对用户保持活跃平台的长期影响可能不会立即观察到。动作和奖励之间的时间差距使得信用分配问题复杂化。
-
2. 样本低效和探索:所有可能推荐的大动作空间,加上广泛探索的需求,可能导致样本低效和次优用户体验。探索不相关或质量差的推荐可能会让用户感到沮丧并阻碍保留。因此,平衡探索和利用在样本高效中至关重要。
-
3. 复杂用户偏好和行为:用户偏好和行为是动态的,并且随时间演变。用户的兴趣可能会从一个类别转移到另一个类别,或者他们对某些类型推荐的敏感性可能会根据他们当前的生活阶段或外部因素而变化。捕捉这些复杂动态并适应用户特定模式对于有效保留至关重要。
传统方法,如协同过滤和基于内容的方法,主要关注短期参与度指标,未能捕捉推荐对用户保留的长期影响。强化学习技术虽然前景广阔,但在应用于用户保留时面临信用分配、样本效率、奖励定义和探索方面的困难。
2.主要工作
1.提出留存感知的模仿学习范式:不同于传统强化学习依赖奖励设计,SEC 直接利用高留存用户的行为数据作为专家示范,通过行为克隆学习推荐策略,规避了奖励稀疏和探索风险。
2.多级专家分层建模:将高留存用户按活跃程度进一步细分为多个层级(如 K=3),每层单独训练一个专家策略,以捕捉不同留存水平下的行为差异,提升策略的细粒度与个性化能力。
3.自适应专家选择机制:在线推理时,根据用户当前状态与每层专家行为聚类中心的距离,动态选择最匹配的专家策略进行推荐,实现个性化路由,并支持用户留存水平提升后的策略“升层”。
4.动作熵正则化增强多样性:引入基于核范数(连续动作)或熵(离散动作)的正则项,防止策略输出过于集中,提升推荐多样性,缓解模仿学习中的策略崩塌问题。
3.具体方案
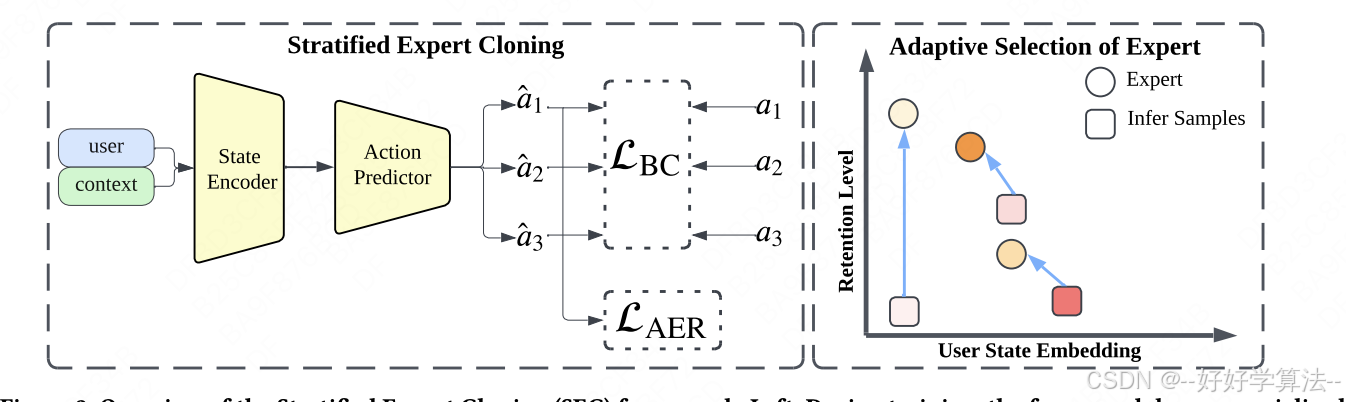
1)多级专家分层(Multi-level Expert Stratification)
过去做 Imitation Learning 常把用户二分成“专家/非专家”,但快手发现:
-
高留存群体内部行为差异依然巨大;
-
非专家在 embedding 空间里并非一团,而是散落在各级专家周围。
于是按月度活跃天数分位点把 Top 用户再切 3 层(K=3),每层单独学策略,既保留行为细节,也给“潜力股”用户预留上升通道。
训练loss:
具体实现细节:
划分对象:仅在“高留存用户”内部进行,非专家用户不参与分层。
划分指标:原文 4.2.1 给出“月度活跃天数”或“LTV”均可,实际按月度活跃天数分位点切为 3 段(K=3),对应 Level-1、Level-2、Level-3。
数据流程:先定义专家集合 UE ⊆ U,再在 UE 内按分位点得到 {UE^1, UE^2, UE^3};每层收集对应轨迹 Dk = {(s,a)} 用于后续行为克隆。
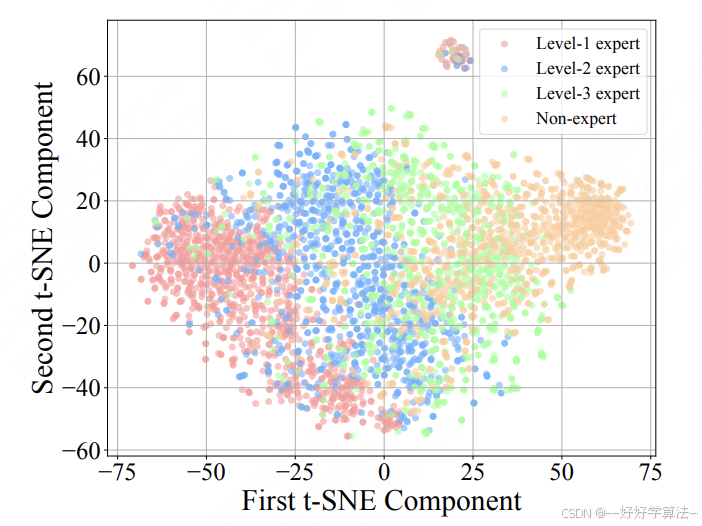
图 3 验证:对 UE^1、UE^2、UE^3 及非专家的用户状态 embedding 做 t-SNE,可见非专家点云散布在 Level-2/3 附近,而非 Level-1,作者据此强调“连续谱”而非二分类。
2)自适应专家选择(Adaptive Expert Selection)
线上新用户状态 s 来了,系统用共享编码器 f_φ 生成 embedding,跟每层专家样本的 K-means 中心算距离,最近且不低于该用户历史留存档位的层被选中。
-
距离全部超限 → 退到最低层,保证不降级体验;
-
随着用户活跃天数上涨,可自动“升舱”到更高层策略,实现动态成长。
具体实现细节:
-
路由输入:用户当前状态 s 经共享编码器 f_φ 得到 ht = f_φ(s)。
-
距离计算:对每层 k 预存 Ck个 K-means 中心,计算用户对于质心的距离
-

-
选择规则:原文式 (7) 取 k* = argmink{dk | dk ≤ δk},其中 δk 设为该层中心间平均距离的一半;若均超限,则退到 argmink dk。
-
历史档位约束:引入用户历史留存水平 rh(过去 30 天活跃天数对应的档位),最终分配层号取 min(k*, rh),防止把低活用户映射到过高策略。
3)动作熵正则(Action Entropy Regularization)
行为克隆天生爱“抄近道”,同样类型物品反复推,用户很快疲劳。
SEC 对连续动作矩阵直接最大化核范数(奇异值之和),强迫动作空间满秩;对离散动作则最大化类别熵。结果同一批状态会被迫采样出分散的推荐向量,线上 A/B 显示有效兴趣簇提升 1.3 %,恰恰弥补模仿学习多样性不足的通病。
任务loss:
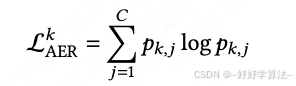
总体loss:
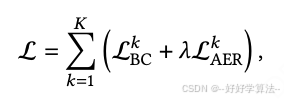
4.训练流程
论文公式把共享编码器 φ 与 3 个专家头 θ_k 写进同一 loss,看似端到端,但工业实现必须两阶段:
阶段 1:用全量样本(专家+非专家)训多任务底座——CTR、时长、完播等,先把通用 f_φ 训稳。
阶段 2:冻结底座前几层,低学习率微调,同时从零训练各专家头,仅专家样本参与行为克隆 + 熵正则。
最后再用专家 embedding 算一次 K-means,产出路由表。这样既避免非专家样本没有监督信号导致 embedding 乱飘,也让专家头快速收敛到各层专属策略。
为什么不能端到端进行训练:
-
根据文章中的说法,模型只有三个专家expert,如果用户是非专家用户(即距离三个聚类的质心都超界),那么就退回到最低档的专家;但是如此依赖,我们就只能用专家用户进行模型训练,无法使用非专家用户进行训练。那么对于编码器来讲,这部分样本量不足以支持其收敛,且对于主目标正样本丢失过多
-
那么我们可以很自然的想到,可以尝试把非专家用户也设置一个专家,这样就能利用到非专家用户的样本了,但是,这样做依然会存在问题:由于巨量的低活用户引入而导致了整体任务梯度方向被拉偏,换句话说对于专家任务,我们想学的样本在总样本里过于稀疏。可能会导致专家的训练效果不及预期。(⚠️文中并没有进行类似的尝试,纯理论推测)
5.实验结果
实验设置
我们在快手和快手极速版平台上部署了SEC,每个平台都有超过2亿日活跃用户。与离线实验中我们完全控制项目排名不同,在线环境中我们与现有排名系统集成。
由于视频ID数量庞大,我们基于多模态特征进行视频聚类以生成推荐动作。我们在两个排名阶段将聚类动作预测概率与其他细粒度排名分数结合,以对视频进行排名。我们使用MLP网络进行状态编码器和动作预测器,用户根据高活跃天数被分为3个专家层。在我们的A/B测试中,我们为基线和SEC优化版本分配了10%的流量,持续了两周多。
-
在线A/B测试显示,在快手和快手极速版两大平台(均拥有超2亿日活用户)上,SEC显著提升用户留存
-
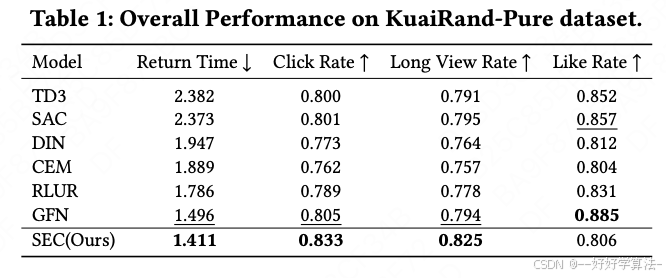
-
活跃天数分别累计提升0.098%和0.122%,相当于每日为每个平台带来超20万额外日活用户
-
用户兴趣扩展指标(有效兴趣簇)也提升1.31%和1.14%,证明方法能有效拓宽用户兴趣
-
有效兴趣簇 +1.3 %,证明多样性正则真正扩大了用户视野;
-
消融实验去掉多级或熵正则,留存增益立刻缩水,印证两组件缺一不可。
-
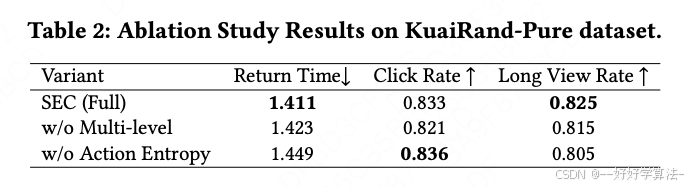
6.落地可行性与局限性
-
可行性:框架已成功部署于亿级用户规模的短视频平台,计算复杂度可控(使用共享状态编码器和分级策略),通过与现有排序系统集成实现平滑落地
-
局限性:尽管提出的SEC框架展示了强大的性能,但其适用性受到几个限制。首先,其效果根本上依赖于足够大和多样化的高保留“专家”用户集,这在新兴平台或细分领域中可能不可用。此外,自适应专家选择机制依赖于高质量的用户状态表示;对于新用户来说,这些可能稀疏或不可靠,在冷启动场景中构成重大挑战。最后,尽管在短视频平台上得到了验证,SEC的可推广性到其他领域(如电子商务或新闻推荐)仍需进一步研究,因为专家行为和保留指标的定义在不同领域间可能有显著差异。