LLMs-from-scratch :KV 缓存
原文链接:https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04/03_kv-cache
概述
简而言之,KV 缓存存储中间的键(K)和值(V)计算结果以便在推理过程中重复使用,这能在生成响应时带来显著的速度提升。缺点是会增加代码复杂性,增加内存使用量,并且不能在训练过程中使用。然而,在部署大语言模型时,推理速度的提升通常值得在代码复杂性和内存方面做出权衡。
工作原理
想象一下大语言模型正在生成一些文本。具体来说,假设大语言模型收到以下提示:“Time flies”。
下图显示了底层注意力分数计算的摘录,使用了第3章的修改图形,其中突出显示了键和值向量:
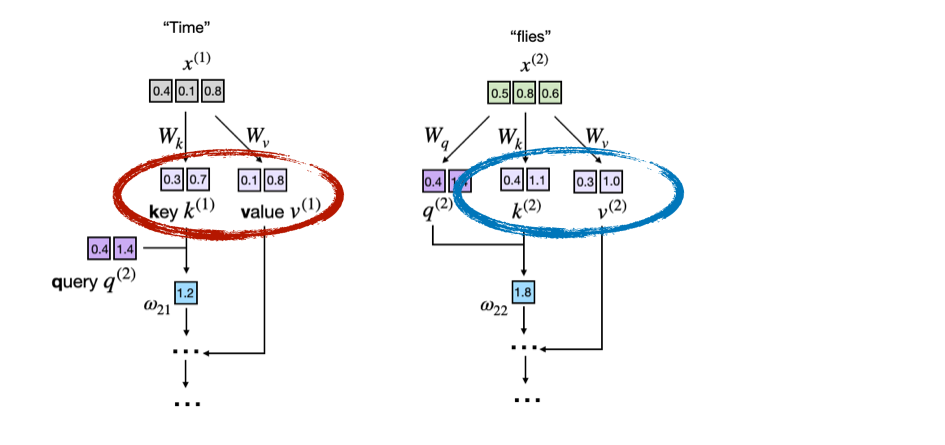
现在,正如我们在第2章和第4章中学到的,大语言模型一次生成一个词(或标记)。假设大语言模型生成了单词"fast",那么下一轮的提示就变成了"Time flies fast"。这在下图中进行了说明:
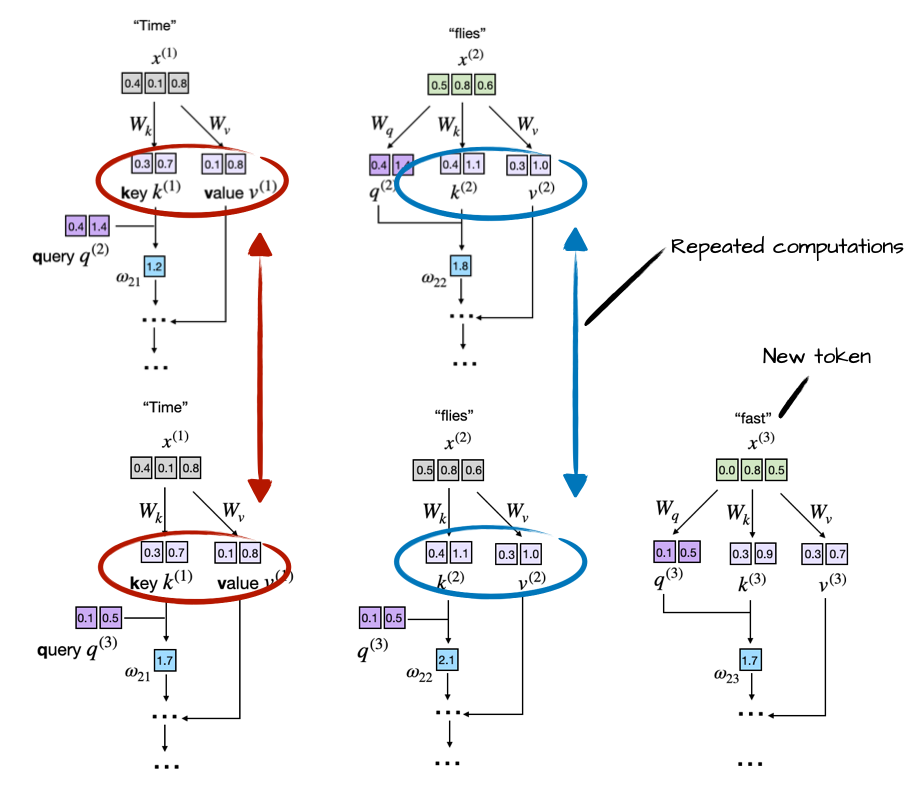
正如我们通过比较前面两个图所看到的,前两个标记的键和值向量完全相同,在每一轮的下一个标记文本生成中重新计算它们是浪费的。
因此,KV 缓存的想法是实现一个缓存机制,存储先前生成的键和值向量以供重复使用,这有助于我们避免不必要的重新计算。
KV 缓存实现
有许多方法可以实现 KV 缓存,主要思想是我们只为每个生成步骤中新生成的标记计算键和值张量。
我选择了一个强调代码可读性的简单方法。我认为最简单的方法就是浏览代码更改来了解它是如何实现的。
本文件夹中有两个文件:
gpt_ch04.py:从第3章和第4章中提取的自包含代码,用于实现大语言模型并运行简单的文本生成函数gpt_with_kv_cache.py:与上面相同,但进行了必要的更改以实现 KV 缓存。
你可以选择:
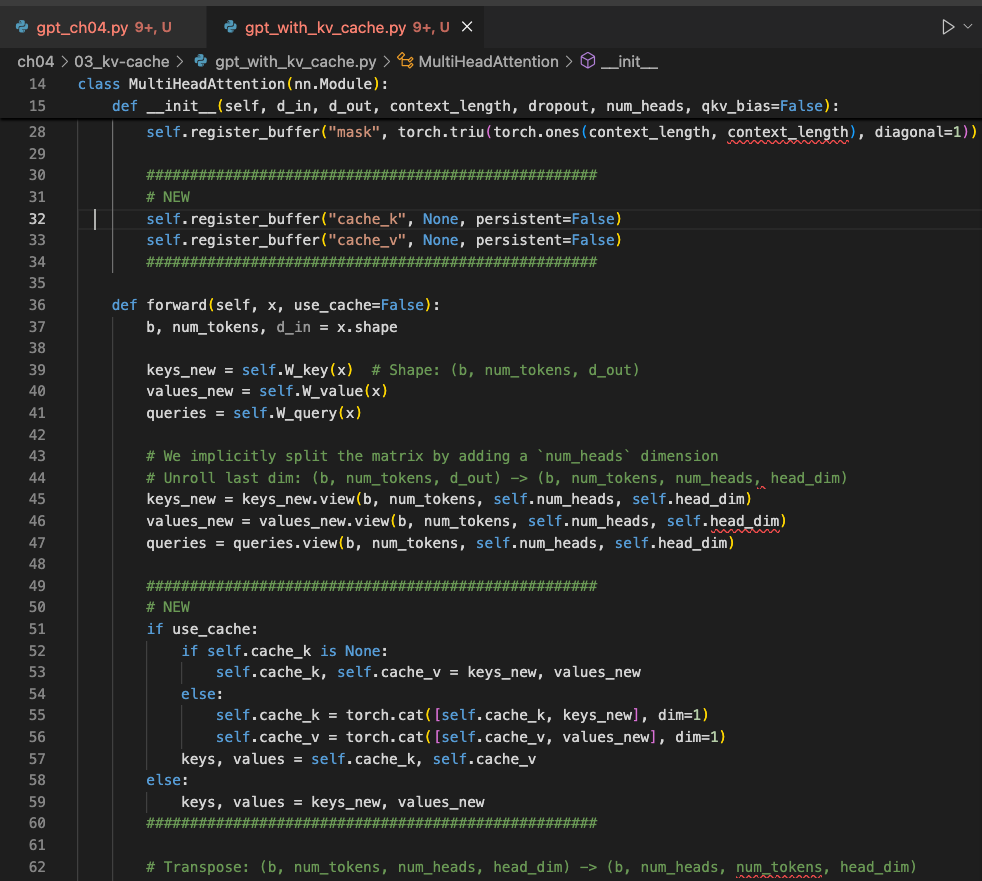
a. 打开 gpt_with_kv_cache.py 文件并查找标记新更改的 # NEW 部分:
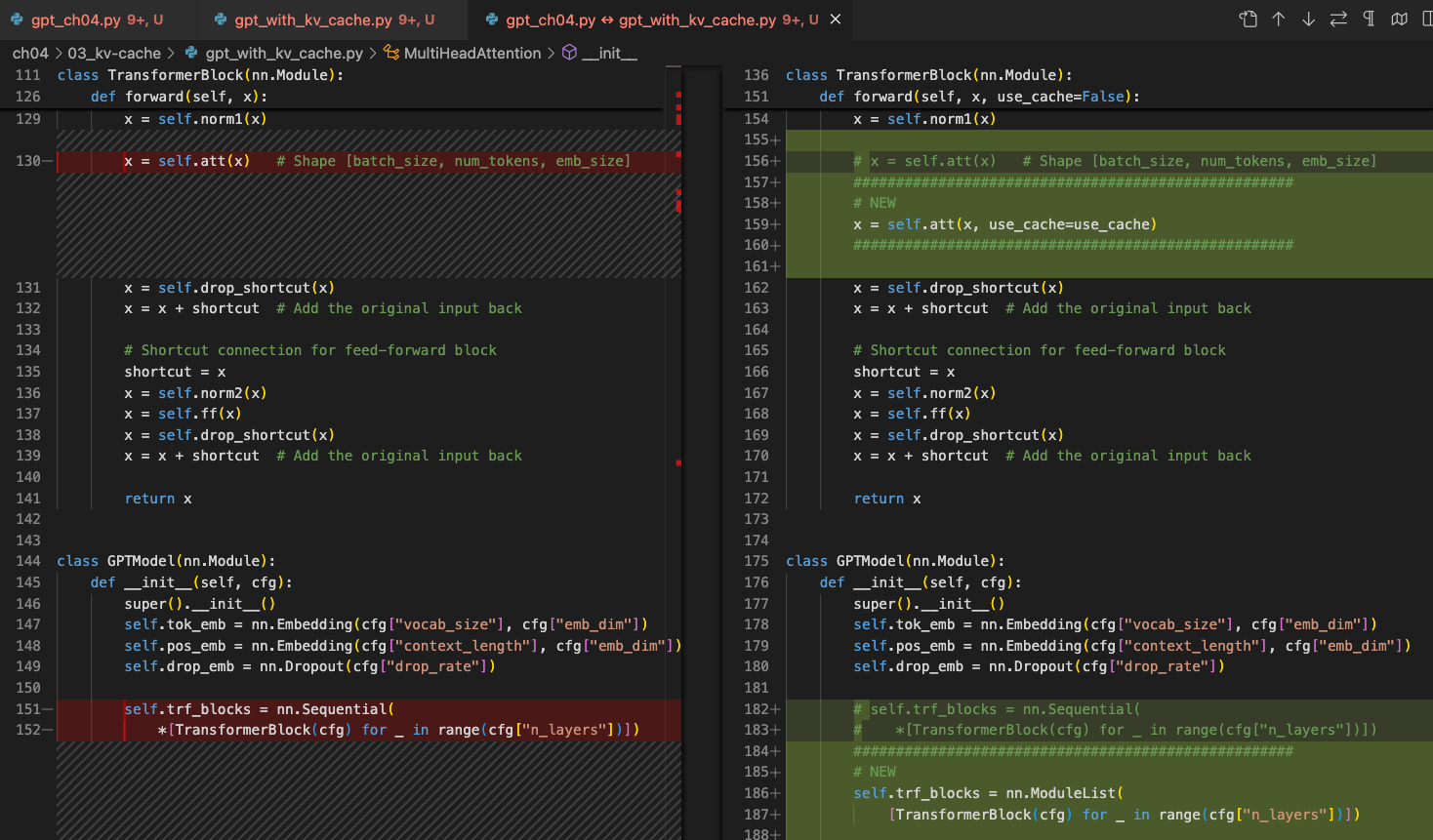
b. 通过你选择的文件差异工具查看两个代码文件以比较更改:
为了总结实现细节,这里是一个简短的演练。
1. 注册缓存缓冲区
在 MultiHeadAttention 构造函数内部,我们添加两个非持久缓冲区 cache_k 和 cache_v,它们将保存跨步骤连接的键和值:
self.register_buffer("cache_k", None, persistent=False)
self.register_buffer("cache_v", None, persistent=False)
2. 带有 use_cache 标志的前向传播
接下来,我们扩展 MultiHeadAttention 类的 forward 方法以接受 use_cache 参数。在将新的标记块投影到 keys_new、values_new 和 queries 之后,我们要么初始化 kv 缓存,要么追加到我们的缓存中:
def forward(self, x, use_cache=False):b, num_tokens, d_in = x.shapekeys_new = self.W_key(x) # Shape: (b, num_tokens, d_out)values_new = self.W_value(x)queries = self.W_query(x)#...if use_cache:if self.cache_k is None:self.cache_k, self.cache_v = keys_new, values_newelse:self.cache_k = torch.cat([self.cache_k, keys_new], dim=1)self.cache_v = torch.cat([self.cache_v, values_new], dim=1)keys, values = self.cache_k, self.cache_velse:keys, values = keys_new, values_new# ...num_tokens_Q = queries.shape[-2]num_tokens_K = keys.shape[-2]if use_cache:mask_bool = self.mask.bool()[self.ptr_current_pos:self.ptr_current_pos + num_tokens_Q, :num_tokens_K]self.ptr_current_pos += num_tokens_Qelse:mask_bool = self.mask.bool()[:num_tokens_Q, :num_tokens_K]
3. 清除缓存
在生成文本时,在独立序列之间(例如两次文本生成调用之间),我们必须重置两个缓冲区,因此我们还向 MultiHeadAttention 类添加了一个缓存重置方法:
def reset_cache(self):self.cache_k, self.cache_v = None, Noneself.ptr_current_pos = 0
4. 在完整模型中传播 use_cache
在对 MultiHeadAttention 类进行更改后,我们现在修改 GPTModel 类。首先,我们在构造函数中为标记索引添加位置跟踪:
self.current_pos = 0
然后,我们用显式循环替换单行块调用,通过每个变换器块传递 use_cache:
def forward(self, in_idx, use_cache=False):# ...if use_cache:pos_ids = torch.arange(self.current_pos, self.current_pos + seq_len, device=in_idx.device, dtype=torch.long)self.current_pos += seq_lenelse:pos_ids = torch.arange(0, seq_len, device=in_idx.device, dtype=torch.long)pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)x = tok_embeds + pos_embeds# ...for blk in self.trf_blocks:x = blk(x, use_cache=use_cache)
上述更改还需要对 TransformerBlock 类进行小的修改以接受 use_cache 参数:
def forward(self, x, use_cache=False):# ...self.att(x, use_cache=use_cache)
最后,我们向 GPTModel 添加模型级重置,以便一次清除所有块缓存:
def reset_kv_cache(self):for blk in self.trf_blocks:blk.att.reset_cache()self.current_pos = 0
5. 在生成中使用缓存
通过对 GPTModel、TransformerBlock 和 MultiHeadAttention 的更改,最后,这是我们如何在简单的文本生成函数中使用 KV 缓存:
def generate_text_simple_cached(model, idx, max_new_tokens, context_size=None, use_cache=True):model.eval()ctx_len = context_size or model.pos_emb.num_embeddingswith torch.no_grad():if use_cache:# 用完整提示初始化缓存model.reset_kv_cache()logits = model(idx[:, -ctx_len:], use_cache=True)for _ in range(max_new_tokens):# a) 选择具有最高对数概率的标记(贪婪采样)next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)# b) 将其追加到运行序列中idx = torch.cat([idx, next_idx], dim=1)# c) 只向模型提供新标记logits = model(next_idx, use_cache=True)else:for _ in range(max_new_tokens):logits = model(idx[:, -ctx_len:], use_cache=False)next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)idx = torch.cat([idx, next_idx], dim=1)return idx
注意,我们在 c) 中只通过 logits = model(next_idx, use_cache=True) 向模型提供新标记。没有缓存时,我们向模型提供整个输入 logits = model(idx[:, -ctx_len:], use_cache=False),因为它没有存储的键和值可以重复使用。
简单性能比较
在概念层面介绍了 KV 缓存之后,最大的问题是它在小例子的实际应用中表现如何。为了试用这个实现,我们可以将前面提到的两个代码文件作为 Python 脚本运行,这将运行小型 1.24 亿参数大语言模型来生成 200 个新标记(给定 4 个标记的提示"Hello, I am"开始):
pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/requirements.txtpython gpt_ch04.pypython gpt_with_kv_cache.py
在配备 M4 芯片的 Mac Mini(CPU)上,结果如下:
| 标记/秒 | |
|---|---|
gpt_ch04.py | 27 |
gpt_with_kv_cache.py | 144 |
因此,正如我们所看到的,我们已经在小型 1.24 亿参数模型和短 200 标记序列长度下获得了约 5 倍的速度提升。(注意,这个实现针对代码可读性进行了优化,而不是针对 CUDA 或 MPS 运行时速度进行了优化,后者需要预分配张量而不是重新实例化和连接它们。)
注意: 在两种情况下,模型都生成"胡言乱语",即看起来像这样的文本:
输出文本:Hello, I am Featureiman Byeswickattribute argue logger Normandy Compton analogous bore ITVEGIN ministriesysics Kle functional recountrictionchangingVirgin embarrassedgl …
这是因为我们还没有训练模型。下一章训练模型,你可以在训练好的模型上使用 KV 缓存(但是,KV 缓存只能在推理期间使用)来生成连贯的文本。在这里,我们使用未训练的模型来保持代码简单。
不过,更重要的是,gpt_ch04.py 和 gpt_with_kv_cache.py 实现产生完全相同的文本。这告诉我们 KV 缓存实现是正确的——很容易犯索引错误,这可能导致不同的结果。
KV 缓存的优缺点
随着序列长度的增加,KV 缓存的好处和缺点在以下方面变得更加明显:
-
[好处] 计算效率提高:没有缓存时,步骤 t 的注意力必须将新查询与 t 个先前的键进行比较,因此累积工作量呈二次方增长,O(n²)。有了缓存,每个键和值只计算一次然后重复使用,将总的每步复杂度降低到线性,O(n)。
-
[缺点] 内存使用量线性增长:每个新标记都会追加到 KV 缓存中。对于长序列和更大的大语言模型,累积的 KV 缓存会变得更大,这可能消耗大量甚至令人望而却步的(GPU)内存。作为解决方法,我们可以截断 KV 缓存,但这会增加更多复杂性(但同样,在部署大语言模型时这可能是值得的。)
优化 KV 缓存实现
虽然我上面的 KV 缓存概念实现有助于清晰理解,主要面向代码可读性和教育目的,但在实际场景中部署它(特别是对于更大的模型和更长的序列长度)需要更仔细的优化。
扩展缓存时的常见陷阱
-
内存碎片和重复分配:如前所示,通过
torch.cat持续连接张量会导致性能瓶颈,因为频繁的内存分配和重新分配。 -
内存使用量的线性增长:没有适当的处理,KV 缓存大小对于非常长的序列变得不切实际。
技巧 1:预分配内存
与其重复连接张量,我们可以基于预期的最大序列长度预分配足够大的张量。这确保了一致的内存使用并减少开销。在伪代码中,这可能看起来如下:
# 键和值的预分配示例
max_seq_len = 1024 # 预期的最大序列长度
cache_k = torch.zeros((batch_size, num_heads, max_seq_len, head_dim), device=device)
cache_v = torch.zeros((batch_size, num_heads, max_seq_len, head_dim), device=device)
在推理期间,我们可以简单地写入这些预分配张量的切片。
技巧 2:通过滑动窗口截断缓存
为了避免耗尽我们的 GPU 内存,我们可以实现带有动态截断的滑动窗口方法。通过滑动窗口,我们只在缓存中维护最后 window_size 个标记:
# 滑动窗口缓存实现
window_size = 512
cache_k = cache_k[:, :, -window_size:, :]
cache_v = cache_v[:, :, -window_size:, :]
实际中的优化
你可以在 gpt_with_kv_cache_optimized.py 文件中找到这些优化。
在配备 M4 芯片的 Mac Mini(CPU)上,使用 200 标记生成和等于上下文长度的窗口大小(以保证相同结果),代码运行时间比较如下:
| 标记/秒 | |
|---|---|
gpt_ch04.py | 27 |
gpt_with_kv_cache.py | 144 |
gpt_with_kv_cache_optimized.py | 166 |
不幸的是,在 CUDA 设备上速度优势消失了,因为这是一个微小的模型,设备传输和通信超过了 KV 缓存对这个小模型的好处。
额外资源
- Qwen3 从零开始的 KV 缓存基准测试
- Llama 3 从零开始的 KV 缓存基准测试
- 从零开始理解和编码大语言模型中的 KV 缓存 – 这个 README 的更详细写作