【完整源码+数据集+部署教程】 【运动的&足球】足球场景目标检测系统源码&数据集全套:改进yolo11-ASF-P2
背景意义
随着计算机视觉技术的快速发展,目标检测在各个领域的应用愈发广泛,尤其是在体育赛事分析中,目标检测技术的应用能够为赛事的战术分析、运动员表现评估以及观众体验提升提供重要支持。足球作为全球最受欢迎的运动之一,其比赛过程中的动态场景复杂多变,涉及多个目标的实时检测与识别,因此,开发高效、准确的目标检测系统显得尤为重要。
本研究基于改进的YOLOv11模型,旨在构建一个针对足球场景的目标检测系统。该系统将重点识别三类目标:球门、运动员和足球。数据集包含2500张图像,涵盖了丰富的比赛场景,确保了模型训练的多样性和有效性。通过对这些图像的深入分析,我们能够捕捉到足球比赛中目标的动态变化及其相互关系,从而提高目标检测的准确性和实时性。
改进YOLOv11模型的核心在于其高效的特征提取能力和快速的推理速度,适合处理复杂的足球场景。通过引入先进的深度学习技术,我们希望能够提升模型在不同光照、角度和遮挡条件下的鲁棒性。此外,目标检测系统的成功实施不仅能够为教练和分析师提供数据支持,帮助他们制定更有效的战术策略,还能为观众提供更为丰富的比赛解读和互动体验。
综上所述,本研究不仅具有重要的学术价值,还能为足球赛事的智能化分析提供实用的技术支持,推动体育科技的发展。
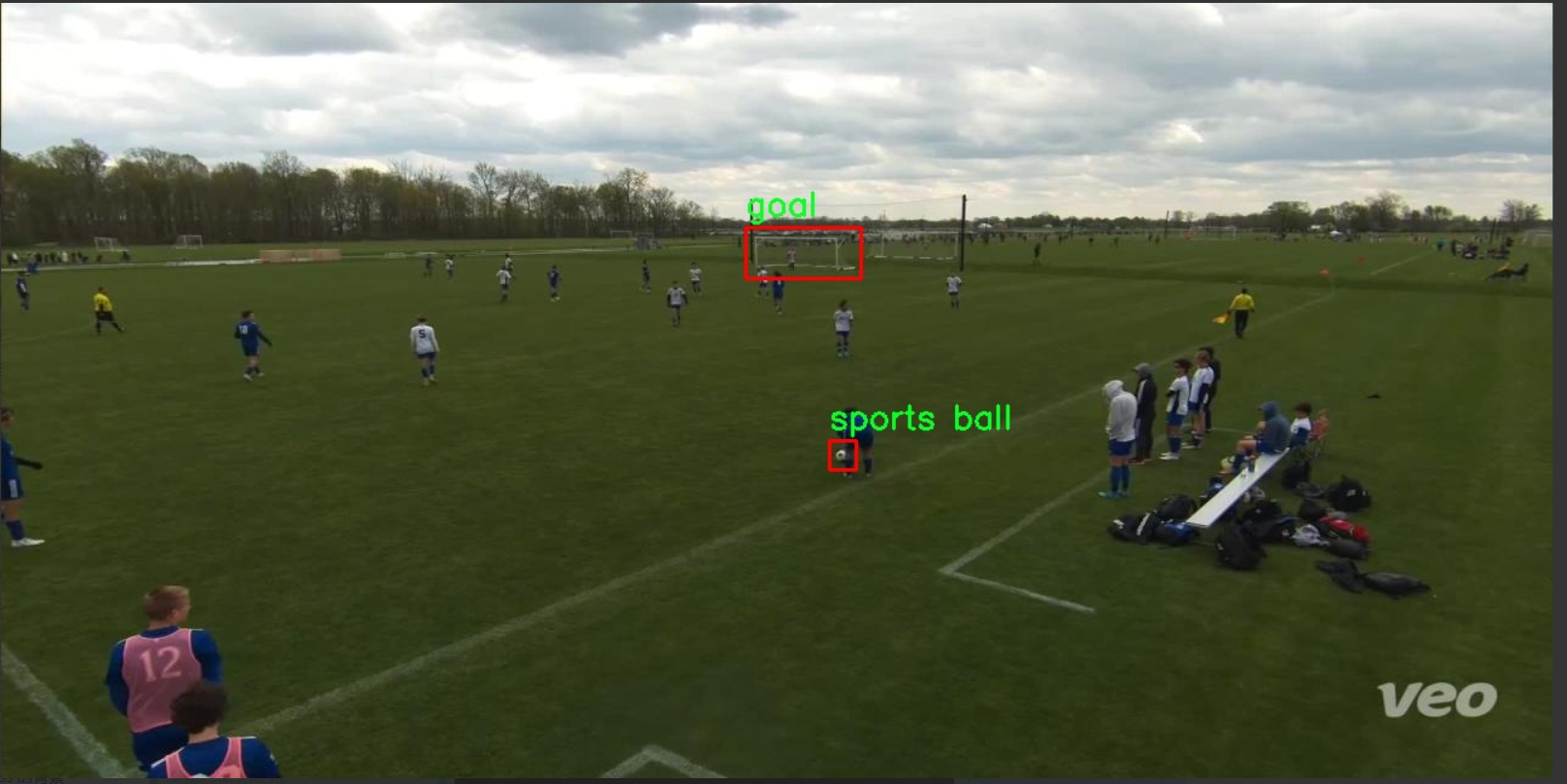
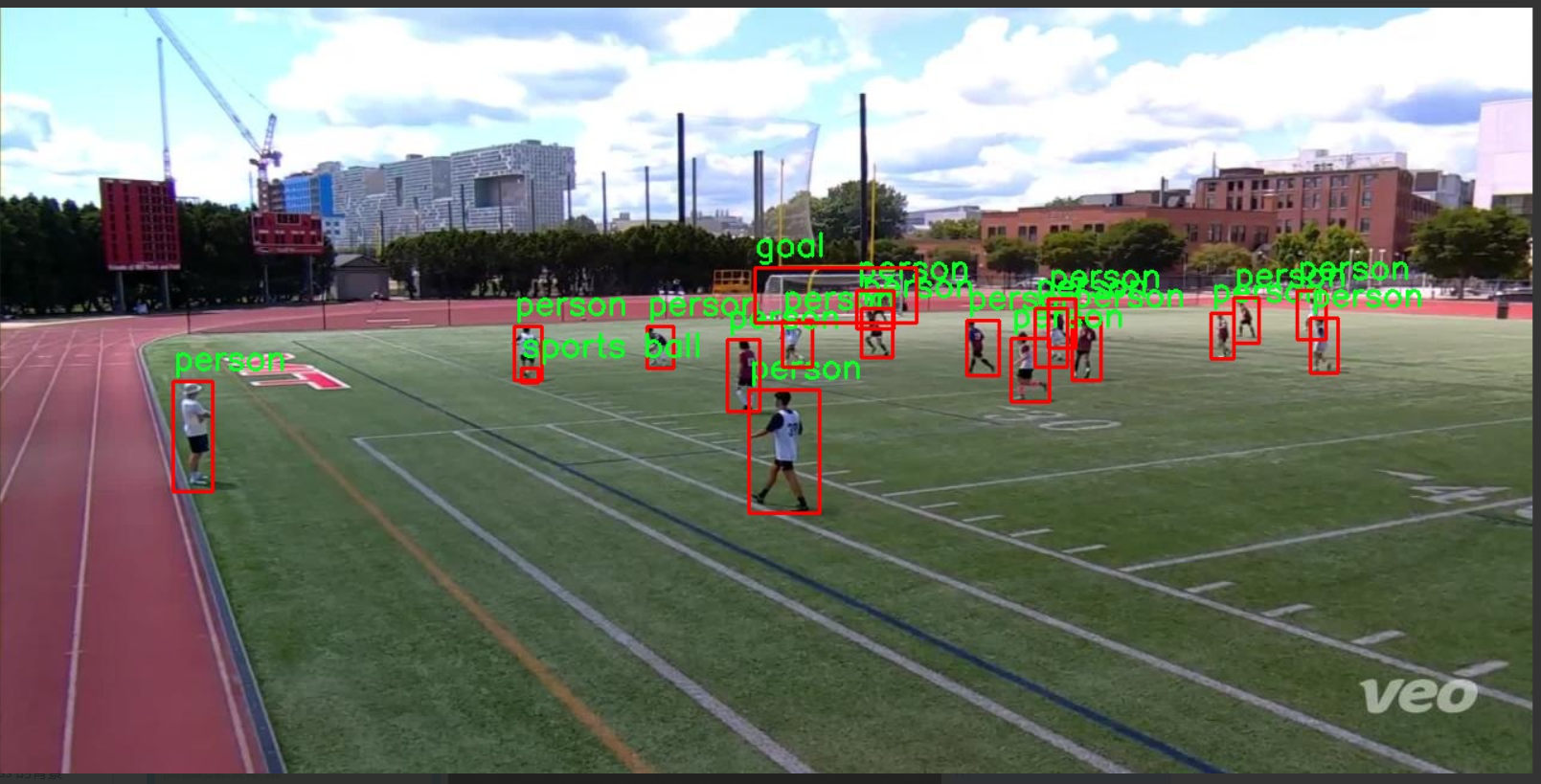
图片效果
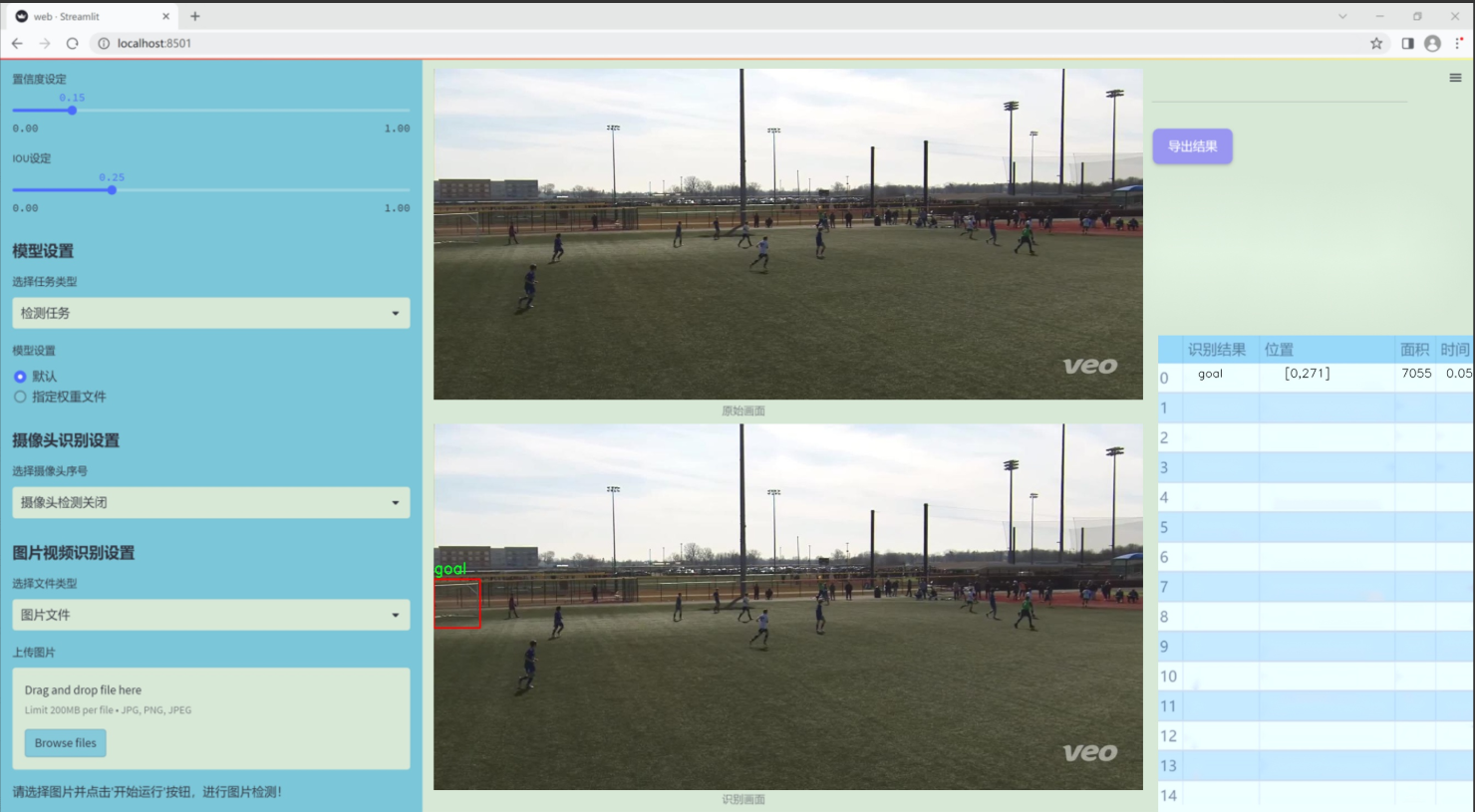
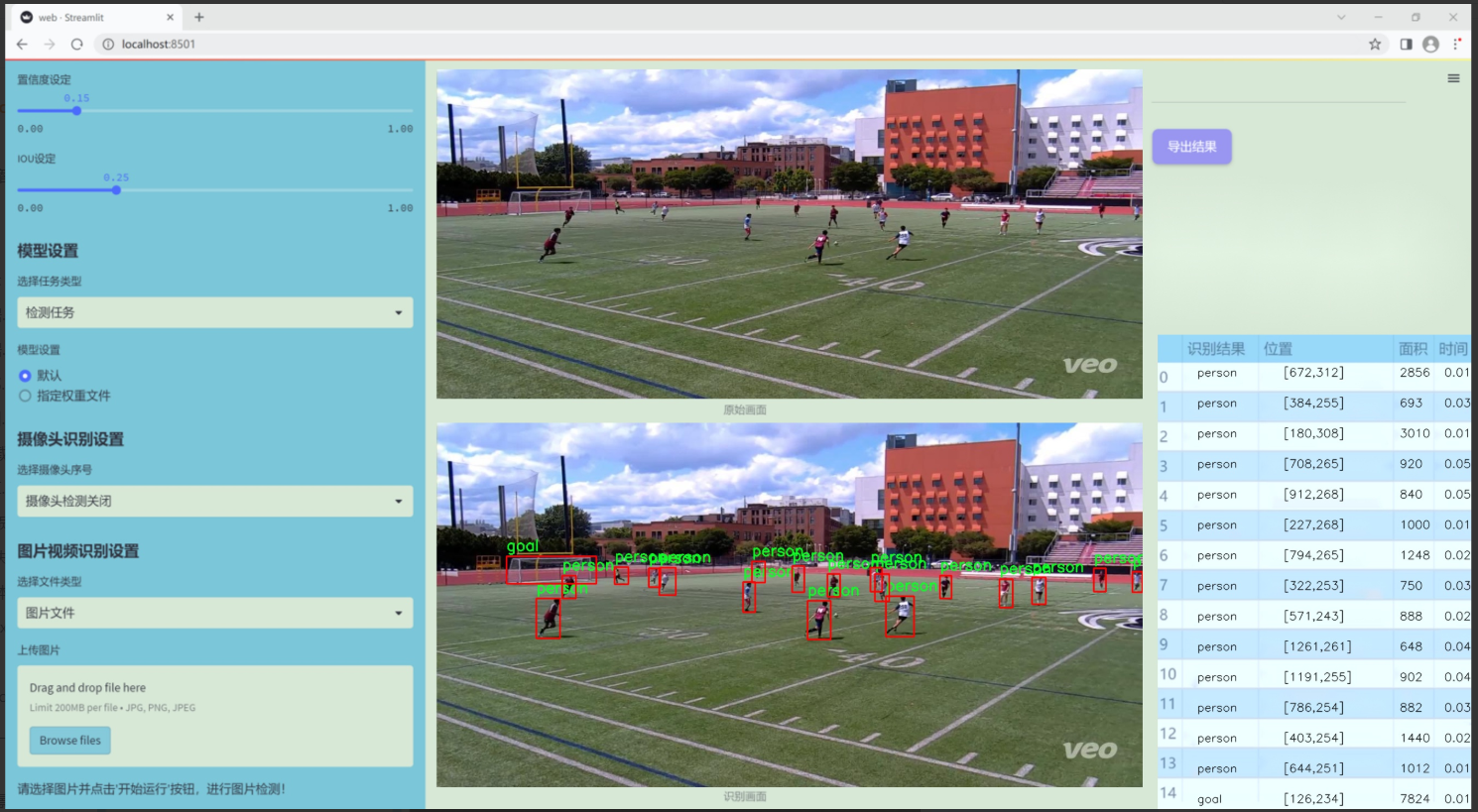
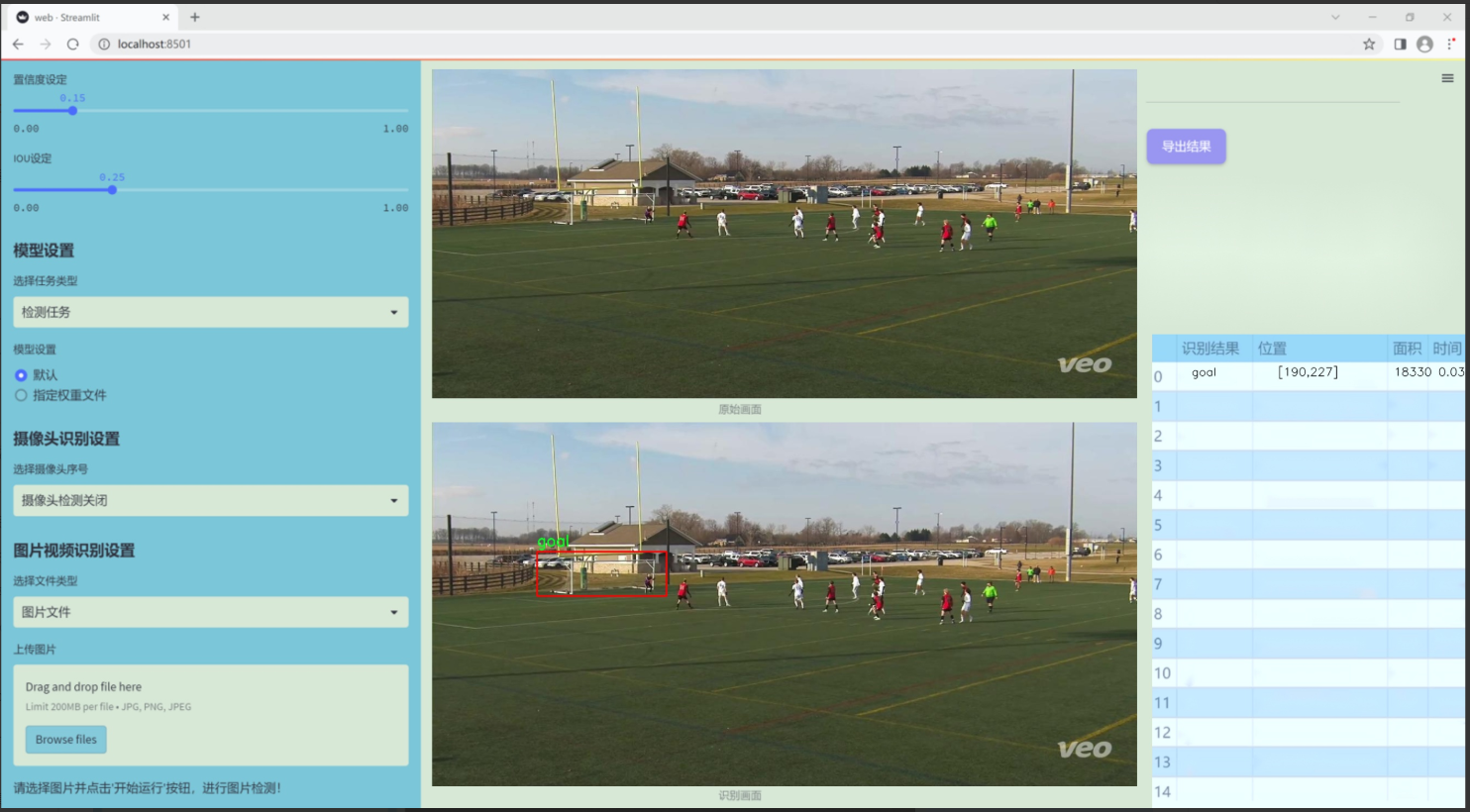
数据集信息
本项目采用的数据集名为“Soccer Detection”,旨在为改进YOLOv11的足球场景目标检测系统提供高质量的训练数据。该数据集专注于足球比赛中的关键目标物体,包含三类主要目标:球门(goal)、运动员(person)和运动球(sports ball)。通过精心标注的图像,数据集为目标检测算法提供了丰富的样本,确保模型能够在复杂的足球场景中准确识别和定位这些重要元素。
“Soccer Detection”数据集的构建考虑了足球比赛的多样性和复杂性,包含了不同时间、地点和天气条件下的比赛场景。这种多样性不仅增强了模型的泛化能力,还使其能够适应不同的视觉环境。数据集中每一类目标的样本数量经过精心设计,以确保模型在训练过程中能够充分学习到每个类别的特征和变化。例如,球门作为比赛的关键元素,其在场景中的位置和外观可能会因不同的角度和光照条件而有所变化;而运动员的姿态和动作也会因比赛的动态性而变化,运动球则在比赛中频繁移动,增加了检测的难度。
此外,数据集的标注过程采用了严格的标准,确保每个目标的边界框准确无误,极大地提高了训练数据的质量。这些高质量的标注数据为YOLOv11模型的训练提供了坚实的基础,使其能够在实际应用中实现高效的目标检测。通过使用“Soccer Detection”数据集,本项目希望能够显著提升YOLOv11在足球场景中的目标检测性能,为后续的研究和应用提供有力支持。



核心代码
以下是经过简化并添加详细中文注释的核心代码部分:
import math
import torch
import torch.nn as nn
def autopad(k, p=None, d=1):
“”“自动填充以保持输出形状不变。”“”
if d > 1:
# 计算实际的卷积核大小
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k]
if p is None:
# 自动计算填充大小
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
class Conv(nn.Module):
“”“标准卷积层,包含卷积、批归一化和激活函数。”“”
default_act = nn.SiLU() # 默认激活函数def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):"""初始化卷积层,参数包括输入通道数、输出通道数、卷积核大小、步幅、填充、分组数、膨胀率和激活函数。"""super().__init__()# 定义卷积层self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)# 定义批归一化层self.bn = nn.BatchNorm2d(c2)# 设置激活函数self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):"""前向传播:执行卷积、批归一化和激活函数。"""return self.act(self.bn(self.conv(x)))
class DWConv(Conv):
“”“深度可分离卷积,使用深度卷积。”“”
def __init__(self, c1, c2, k=1, s=1, d=1, act=True):"""初始化深度卷积层,参数包括输入通道数、输出通道数、卷积核大小、步幅、膨胀率和激活函数。"""super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), d=d, act=act)
class DSConv(nn.Module):
“”“深度可分离卷积层,包含深度卷积和逐点卷积。”“”
def __init__(self, c1, c2, k=1, s=1, d=1, act=True):super().__init__()# 定义深度卷积self.dwconv = DWConv(c1, c1, 3)# 定义逐点卷积self.pwconv = Conv(c1, c2, 1)def forward(self, x):"""前向传播:先进行深度卷积,再进行逐点卷积。"""return self.pwconv(self.dwconv(x))
class ConvTranspose(nn.Module):
“”“转置卷积层。”“”
default_act = nn.SiLU() # 默认激活函数def __init__(self, c1, c2, k=2, s=2, p=0, bn=True, act=True):"""初始化转置卷积层,参数包括输入通道数、输出通道数、卷积核大小、步幅、填充、是否使用批归一化和激活函数。"""super().__init__()self.conv_transpose = nn.ConvTranspose2d(c1, c2, k, s, p, bias=not bn)self.bn = nn.BatchNorm2d(c2) if bn else nn.Identity()self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):"""前向传播:执行转置卷积、批归一化和激活函数。"""return self.act(self.bn(self.conv_transpose(x)))
class ChannelAttention(nn.Module):
“”“通道注意力模块。”“”
def __init__(self, channels: int):"""初始化通道注意力模块,参数为通道数。"""super().__init__()self.pool = nn.AdaptiveAvgPool2d(1) # 自适应平均池化self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True) # 1x1卷积self.act = nn.Sigmoid() # 激活函数def forward(self, x: torch.Tensor) -> torch.Tensor:"""前向传播:计算通道注意力并与输入相乘。"""return x * self.act(self.fc(self.pool(x)))
class SpatialAttention(nn.Module):
“”“空间注意力模块。”“”
def __init__(self, kernel_size=7):"""初始化空间注意力模块,参数为卷积核大小。"""super().__init__()assert kernel_size in {3, 7}, "卷积核大小必须为3或7"padding = 3 if kernel_size == 7 else 1self.cv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False) # 卷积层self.act = nn.Sigmoid() # 激活函数def forward(self, x):"""前向传播:计算空间注意力并与输入相乘。"""return x * self.act(self.cv1(torch.cat([torch.mean(x, 1, keepdim=True), torch.max(x, 1, keepdim=True)[0]], 1)))
class CBAM(nn.Module):
“”“卷积块注意力模块。”“”
def __init__(self, c1, kernel_size=7):"""初始化CBAM模块,参数为输入通道数和卷积核大小。"""super().__init__()self.channel_attention = ChannelAttention(c1) # 通道注意力self.spatial_attention = SpatialAttention(kernel_size) # 空间注意力def forward(self, x):"""前向传播:依次通过通道注意力和空间注意力模块。"""return self.spatial_attention(self.channel_attention(x))
代码说明:
autopad: 计算卷积时的自动填充,以保持输出的形状与输入相同。
Conv: 标准卷积层,包含卷积、批归一化和激活函数的组合。
DWConv: 深度卷积层,使用深度可分离卷积的方式。
DSConv: 深度可分离卷积,结合深度卷积和逐点卷积。
ConvTranspose: 转置卷积层,常用于上采样。
ChannelAttention: 实现通道注意力机制,通过自适应池化和1x1卷积来增强特征。
SpatialAttention: 实现空间注意力机制,通过对输入特征的平均和最大池化进行处理。
CBAM: 结合通道注意力和空间注意力的模块,增强特征表示能力。
这个程序文件 conv.py 定义了一系列用于卷积操作的模块,主要用于深度学习中的卷积神经网络(CNN)。文件中包含多个类和函数,提供了不同类型的卷积层和相关操作,适用于图像处理和计算机视觉任务。
首先,文件引入了必要的库,包括 math、numpy 和 torch,并定义了一个名为 autopad 的函数,该函数用于自动计算卷积操作的填充,以确保输出形状与输入形状相同。该函数根据给定的卷积核大小、填充和扩张参数来计算所需的填充量。
接下来,定义了多个卷积相关的类。Conv 类是一个标准的卷积层,包含卷积操作、批归一化和激活函数。构造函数中接受多个参数,如输入通道数、输出通道数、卷积核大小、步幅、填充、分组和扩张等。forward 方法实现了前向传播,依次应用卷积、批归一化和激活函数。
Conv2 类是对 Conv 类的扩展,增加了一个 1x1 的卷积层,并在前向传播中将两个卷积的输出相加。它还提供了一个 fuse_convs 方法,用于融合卷积操作以提高计算效率。
LightConv 类实现了一种轻量级卷积,结合了标准卷积和深度卷积(DWConv)。DWConv 类则实现了深度卷积,主要用于减少模型参数和计算量。
DSConv 类实现了深度可分离卷积,它将深度卷积和逐点卷积结合在一起,以提高效率。
DWConvTranspose2d 和 ConvTranspose 类分别实现了深度转置卷积和标准转置卷积,用于上采样操作。
Focus 类用于将空间信息聚焦到通道维度,通过对输入张量进行特定的切片和拼接操作来实现。
GhostConv 类实现了 Ghost 卷积,通过主卷积和便宜的操作来高效地学习特征。
RepConv 类实现了一种重复卷积模块,支持训练和推理状态,并提供了融合卷积的功能,以提高推理速度。
ChannelAttention 和 SpatialAttention 类实现了通道注意力和空间注意力机制,分别用于对特征图的通道和空间信息进行加权,以增强重要特征。
CBAM 类结合了通道注意力和空间注意力,形成一个卷积块注意力模块,用于进一步增强特征表示。
最后,Concat 类用于在指定维度上连接多个张量,常用于特征融合。
整体来看,这个文件实现了多种卷积操作和注意力机制,提供了灵活的构建模块,适用于各种深度学习模型,尤其是在目标检测和图像分割等任务中。
10.4 convnextv2.py
以下是经过简化和注释的核心代码部分:
import torch
import torch.nn as nn
import torch.nn.functional as F
class LayerNorm(nn.Module):
“”" 自定义的层归一化,支持两种数据格式:channels_last(默认)和 channels_first。
channels_last 对应的输入形状为 (batch_size, height, width, channels),
而 channels_first 对应的输入形状为 (batch_size, channels, height, width)。
“”"
def init(self, normalized_shape, eps=1e-6, data_format=“channels_last”):
super().init()
# 权重和偏置参数
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps
self.data_format = data_format
if self.data_format not in [“channels_last”, “channels_first”]:
raise NotImplementedError
self.normalized_shape = (normalized_shape, )
def forward(self, x):# 根据数据格式进行归一化if self.data_format == "channels_last":return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)elif self.data_format == "channels_first":u = x.mean(1, keepdim=True) # 计算均值s = (x - u).pow(2).mean(1, keepdim=True) # 计算方差x = (x - u) / torch.sqrt(s + self.eps) # 标准化x = self.weight[:, None, None] * x + self.bias[:, None, None] # 应用权重和偏置return x
class Block(nn.Module):
“”" ConvNeXtV2的基本模块,包含深度可分离卷积和全连接层等。
Args:dim (int): 输入通道数。
"""
def __init__(self, dim):super().__init__()# 深度可分离卷积self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim)self.norm = LayerNorm(dim, eps=1e-6) # 归一化层self.pwconv1 = nn.Linear(dim, 4 * dim) # 1x1卷积self.act = nn.GELU() # 激活函数self.pwconv2 = nn.Linear(4 * dim, dim) # 1x1卷积def forward(self, x):input = xx = self.dwconv(x) # 深度卷积x = x.permute(0, 2, 3, 1) # 转换维度顺序x = self.norm(x) # 归一化x = self.pwconv1(x) # 1x1卷积x = self.act(x) # 激活x = self.pwconv2(x) # 1x1卷积x = x.permute(0, 3, 1, 2) # 恢复维度顺序return input + x # 残差连接
class ConvNeXtV2(nn.Module):
“”" ConvNeXt V2模型,包含多个特征分辨率阶段和残差块。
Args:in_chans (int): 输入图像的通道数。默认值为3。num_classes (int): 分类头的类别数。默认值为1000。depths (tuple(int)): 每个阶段的块数。默认值为[3, 3, 9, 3]。dims (int): 每个阶段的特征维度。默认值为[96, 192, 384, 768]。
"""
def __init__(self, in_chans=3, num_classes=1000, depths=[3, 3, 9, 3], dims=[96, 192, 384, 768]):super().__init__()self.downsample_layers = nn.ModuleList() # 下采样层# 初始卷积层stem = nn.Sequential(nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),LayerNorm(dims[0], eps=1e-6, data_format="channels_first"))self.downsample_layers.append(stem)# 添加下采样层for i in range(3):downsample_layer = nn.Sequential(LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),)self.downsample_layers.append(downsample_layer)self.stages = nn.ModuleList() # 特征分辨率阶段for i in range(4):stage = nn.Sequential(*[Block(dim=dims[i]) for _ in range(depths[i])])self.stages.append(stage)self.norm = nn.LayerNorm(dims[-1], eps=1e-6) # 最后的归一化层self.head = nn.Linear(dims[-1], num_classes) # 分类头def forward(self, x):for i in range(4):x = self.downsample_layers[i](x) # 下采样x = self.stages[i](x) # 通过阶段return x # 返回最后的特征图
代码注释说明:
LayerNorm类:实现了自定义的层归一化,支持不同的数据格式,确保在不同维度下的归一化处理。
Block类:构建了ConvNeXtV2的基本模块,包含深度可分离卷积、归一化、激活函数和残差连接。
ConvNeXtV2类:整体模型的构建,包含多个下采样层和特征提取阶段,每个阶段由多个Block组成,最终输出分类结果。
这个程序文件实现了一个名为 ConvNeXt V2 的深度学习模型,主要用于图像分类任务。代码中包含了多个类和函数,下面是对其主要部分的讲解。
首先,文件引入了必要的库,包括 PyTorch 和一些辅助函数。接着,定义了一个 LayerNorm 类,它实现了层归一化功能,支持两种数据格式:通道最后(channels_last)和通道第一(channels_first)。在 forward 方法中,根据输入数据的格式进行不同的归一化处理。
接下来,定义了一个 GRN 类,表示全局响应归一化层。该层通过计算输入的 L2 范数来进行归一化,并使用可学习的参数 gamma 和 beta 来调整输出。
然后,定义了 Block 类,这是 ConvNeXt V2 的基本构建块。每个块包含一个深度可分离卷积层、层归一化、点卷积、激活函数(GELU)、GRN 和另一个点卷积。该块还实现了随机深度(Drop Path)机制,以增强模型的泛化能力。
ConvNeXtV2 类是整个模型的主体。它的构造函数接受输入通道数、分类类别数、每个阶段的块数、特征维度、随机深度率等参数。模型的结构由多个下采样层和特征提取阶段组成。下采样层使用卷积和层归一化逐步减少特征图的空间维度,而特征提取阶段则由多个 Block 组成,负责提取更深层次的特征。
在 ConvNeXtV2 类中,还定义了 _init_weights 方法,用于初始化模型的权重,使用截断正态分布和常数初始化。
forward 方法实现了模型的前向传播,依次通过下采样层和特征提取阶段,并将每个阶段的输出存储在 res 列表中。
此外,文件中还定义了一个 update_weight 函数,用于更新模型的权重字典,确保模型和权重的形状匹配。
最后,提供了一系列函数(如 convnextv2_atto、convnextv2_femto 等),用于创建不同规模的 ConvNeXt V2 模型。这些函数允许用户指定预训练权重,并加载到相应的模型中。
总体而言,这个文件实现了一个灵活且可扩展的深度学习模型,适用于各种图像分类任务,并提供了多种不同规模的模型配置。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式