吃透大数据算法-用 “任务排队” 讲透 Kahn 算法的核心
618 大促的凌晨,订单中心的技术小哥小明盯着屏幕直冒冷汗 —— 还有 3 小时就要开卖,可新上线的 “订单处理流程” 突然报了个 “依赖异常” 警告。要是开卖后订单卡住,损失可就大了。

“别急,用‘任务排队法’查一查。” 组长老王递过来一杯咖啡,“这就是咱们平时说的 Kahn 算法,专门治这种‘谁先谁后’的依赖乱麻。”
一、大促订单的 “依赖迷宫”:Kahn 算法的场景还原
小明负责的 “订单处理流程”,其实是 6 个环环相扣的任务,每个任务都得等 “前置任务” 做完才能启动,就像做一道复杂的电商版 “番茄炒蛋”:
| 任务名称 | 作用 | 前置依赖(必须先做的事) |
|---|---|---|
| 库存锁定(A) | 锁定用户买的商品库存 | 无(直接就能干) |
| 优惠券核销(B) | 扣减用户的优惠券金额 | 无(直接就能干) |
| 订单生成(C) | 生成正式订单号 | A、B(得先锁库存、核优惠券) |
| 支付确认(D) | 确认用户付款到账 | C(得有订单号才能付款) |
| 物流调度(E) | 分配仓库和快递 | D(付了款才发物流) |
| 短信通知(F) | 给用户发 “下单成功” 短信 | C(有订单号才能发) |
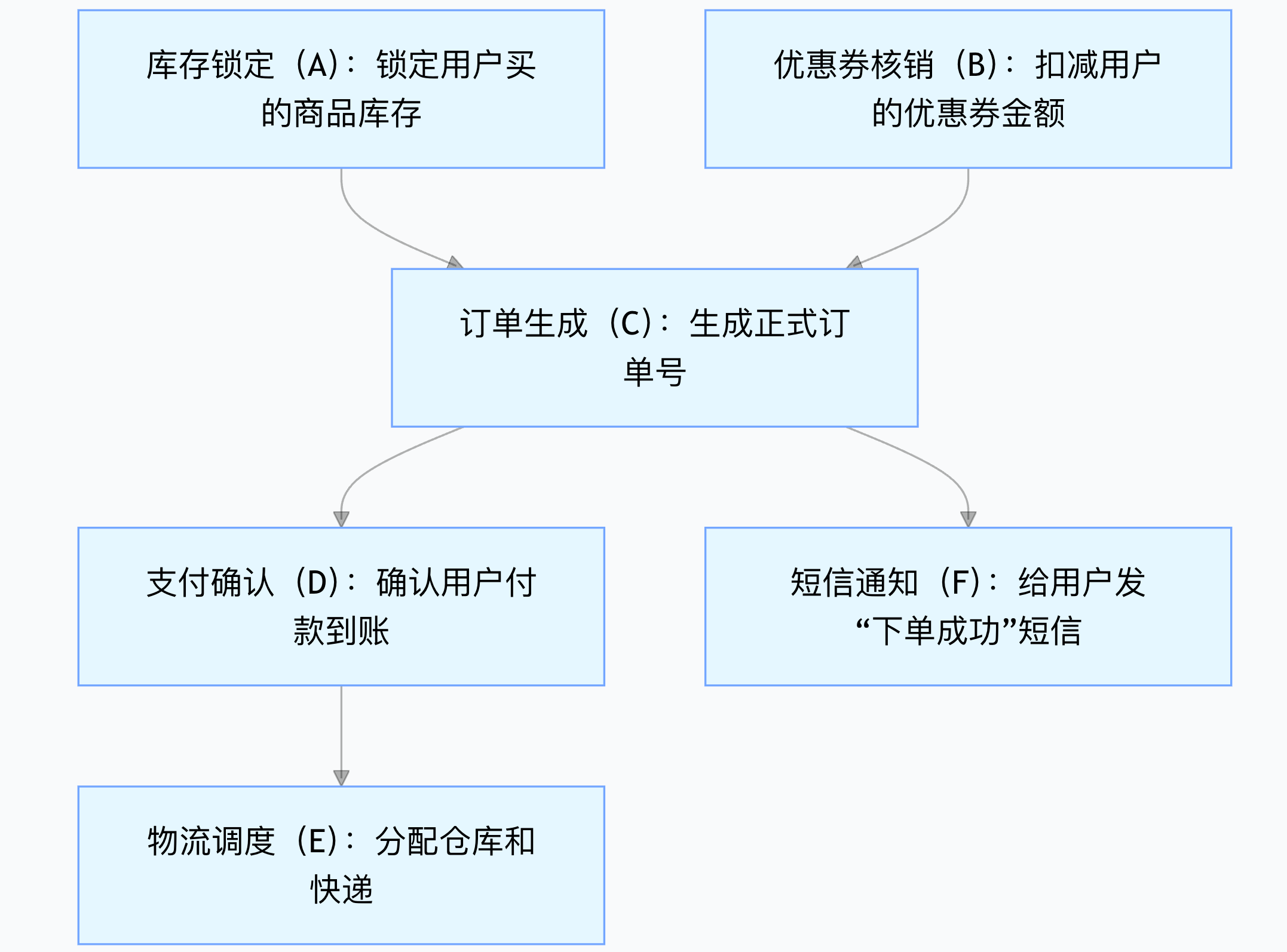
“你看,这些任务就像一串糖葫芦,有的得靠前面的‘签子’才能串起来。” 老王指着表格说,“Kahn 算法的第一步,就是给每个任务算‘门槛数’—— 专业叫‘入度’,也就是‘必须做完几个前置任务才能启动’。”
小明很快算出了每个任务的 “入度”:
- A(库存锁定):入度 0(没门槛)
- B(优惠券核销):入度 0(没门槛)
- C(订单生成):入度 2(要等 A 和 B)
- D(支付确认):入度 1(要等 C)
- E(物流调度):入度 1(要等 D)
- F(短信通知):入度 1(要等 C)
二、Kahn 算法的 “排队执行”:像大促分任务给工程师
“接下来就简单了,咱们当‘调度组长’,把任务分给工程师干活。” 老王打开了一个 “待执行任务队列”,“规则就两条:
- 先把‘没门槛’(入度 0)的任务放进队列,这些是‘马上能上手’的活;
- 工程师做完一个任务,就去‘帮它的后续任务减门槛’—— 比如做完 A,就把 C 的入度从 2 减到 1;
- 重复前两步,直到所有任务都做完,或者队列空了还有任务没做(那就是有环了)。”
小明跟着老王模拟了一遍 “618 任务执行流程”:
第一步:初始化队列,放进 “无门槛任务”
队列里先住进 A 和 B(入度都是 0),就像大促前先把 “不用等别人” 的活分给工程师。
第二步:执行 A,帮后续任务减门槛
工程师小李做完 A(库存锁定),跑过来跟小明说:“A 搞定了!”小明马上找到 A 的后续任务 ——C(订单生成),把 C 的入度从 2 减到 1。现在 C 的入度是 1,还没到 0,不能进队列;A 已经做完,“退休” 了。
第三步:执行 B,帮后续任务减门槛
工程师小张做完 B(优惠券核销),也来报喜:“B 搞定!”小明又找到 B 的后续任务 —— 还是 C,把 C 的入度从 1 减到 0。“C 的门槛清完了!” 小明赶紧把 C 放进队列。
第四步:执行 C,帮后续任务减门槛
工程师小王做完 C(订单生成),后续任务有两个:D(支付确认)和 F(短信通知)。小明把 D 的入度从 1 减到 0,把 F 的入度从 1 减到 0—— 赶紧把 D 和 F 放进队列。
第五步:执行 D 和 F,继续减门槛
- 工程师小赵做完 D(支付确认),后续任务是 E(物流调度),把 E 的入度从 1 减到 0,E 进队列;
- 工程师小钱做完 F(短信通知),没后续任务,直接 “退休”。
第六步:执行 E,任务全完成
工程师小孙做完 E(物流调度),也没后续任务。这时候队列空了,所有 6 个任务都做完了 —— 没出现 “有任务剩下来” 的情况,说明 “订单流程” 里没有环,大促能正常跑!
三、如果出了 “死循环”:Kahn 算法的 “排雷” 能力
“要是有人不小心加错了依赖,比如让‘支付确认(D)’依赖‘物流调度(E)’,会怎么样?” 老王突然问。
小明赶紧改了依赖:E 依赖 D,D 又依赖 E—— 相当于 “要付款得先发物流,要发物流得先付款”,典型的死循环。
再跑一遍 Kahn 算法:
- 队列先放进 A 和 B,执行完后 C 的入度变 0,C 进队列;
- 执行 C,D 和 F 的入度变 0,D 和 F 进队列;
- 执行 F,退休;执行 D,E 的入度变 0,E 进队列;
- 执行 E,要减后续任务的入度 —— 可 E 的后续任务是 D(新改的依赖),D 已经 “退休” 了,入度没法减;
- 队列空了,但 D 和 E 的依赖还没清完 —— 这时候 Kahn 算法就会报警:“有任务没做完,存在环!”
“这就是 Kahn 算法的核心厉害之处。” 老王拍了拍小明的肩膀,“大促时咱们有上万个任务,靠人工查环根本不可能,Kahn 算法就像‘自动排雷兵’,用‘入度管理 + 队列执行’的逻辑,既能快速排好任务顺序(拓扑排序),又能一眼揪出死循环,保证订单不卡住。”
四、Kahn 算法在电商的 “真实用武之地”
其实不只是 618 订单,电商的很多业务都在靠 Kahn 算法 “捋顺依赖”:
- 淘宝的商品推荐:“给用户推商品” 得等 “用户画像生成”“商品标签匹配” 这两个前置任务,Kahn 算法帮推荐系统排执行顺序;
- 支付宝的账单结算:“生成月度账单” 得等 “每日交易记录汇总”“手续费计算” 完成,Kahn 算法避免结算卡住;
- 菜鸟的物流调度:“分配快递员” 得等 “仓库出库”“订单付款确认”,Kahn 算法保障物流不混乱。
“说到底,Kahn 算法的核心就是‘先做没门槛的事,做完帮别人减门槛’—— 这和咱们大促时‘先拆简单活,再啃复杂活’的工作逻辑一模一样。” 小明看着恢复正常的订单系统,终于松了口气。
凌晨 3 点,618 准时开卖,订单像流水一样顺畅处理,小明知道:这背后,是 Kahn 算法用最朴素的 “排队逻辑”,守护着每一笔交易的顺利完成。
五、Kahn 算法在大数据组件中的应用对照表
| 组件类型 | 具体组件 | 核心应用场景 | Kahn 算法核心作用 | 实际业务价值 |
|---|---|---|---|---|
| 任务调度工具 | Apache Airflow | 定义 DAG 任务流(如 “日志采集→数据清洗→特征计算→模型训练”“日活统计→报表生成”) | 1. 启动 DAG 前做环检测,拦截反向依赖(如 “模型训练→日志采集”);2. 执行时做拓扑排序,按依赖生成任务执行顺序,优先调度无依赖任务 | 避免调度卡死,确保任务按业务逻辑执行,减少人工干预 |
| 任务调度工具 | Azkaban | 批处理任务调度(如 “订单数据同步→用户数据同步→GMV 聚合计算→结果写入 MySQL 报表库”) | 1. 解析.job配置文件中的依赖关系;2. 生成任务执行队列,完成前置任务后自动触发后续任务 | 保障批处理任务时序正确,避免因依赖错乱导致的统计数据不准确 |
| 流处理框架 | Apache Flink | 实时流处理作业(如 “Kafka Source→数据过滤→订单金额聚合→MySQL Sink”“用户行为实时分析”) | 1. 生成 JobGraph 时做算子拓扑排序,确定 Source→中间算子→Sink 的执行顺序;2. 优化资源分配,相邻依赖算子优先部署到同一 TaskManager | 确保数据流向正确,降低跨节点数据传输成本,提升实时计算吞吐量 |
| 流处理框架 | Apache Spark | Spark SQL 多表查询 / 批处理作业(如 “用户表扫描→订单表扫描→Join 算子→GROUP BY 聚合”) | 1. Query Planner 阶段解析算子依赖图;2. 生成最优执行计划,避免 “先计算后扫表” 的错误顺序 | 减少无效计算步骤,提升批处理 / 查询效率,降低 CPU / 内存资源消耗 |
| 数据集成工具 | DataX | 跨数据源同步(如 “MySQL 用户表→Hive 用户表”“MySQL 订单表→HDFS”,需保证 “用户表先同步,订单表后同步”) | 1. 根据表依赖生成同步任务顺序;2. 若前置表同步失败,阻塞后续表同步 | 避免因外键缺失导致的数据同步错误,保障跨数据源数据一致性 |
| 数据集成工具 | Flink CDC | 实时数据捕获同步(如 “MySQL 分库分表→Hudi,商品表→库存表→订单表的实时同步”) | 1. 解析数据库表外键依赖,确定同步顺序;2. 检测 “表间循环依赖” 并提前报错 | 防止实时同步数据错乱,支持高并发场景下的分表数据整合 |
| 云原生调度 | Kubernetes CronJob | 云原生定时任务(如 “HDFS 数据压缩→归档日志清理→清理结果通知”“ES 索引优化→数据备份”) | 依赖 Argo Workflows 等工具,解析 Job 依赖并生成执行顺序,确保前置 Job 完成后再执行后续 Job | 避免 “清理未压缩数据”“备份未优化索引” 等错误,保障云原生任务稳定性 |
| 云原生调度 | Argo Workflows | 云原生工作流(如 “机器学习训练:数据下载→数据预处理→模型训练→模型部署”) | 1. 解析 Workflow YAML 中的 Step 依赖;2. 支持无依赖 Step 并行执行,提升资源利用率 | 最大化利用 GPU/CPU 资源,缩短复杂工作流(如模型训练)的执行周期 |
| 数据仓库工具 | Apache Hive | Hive 视图 / 分区查询(如 “GMV 视图依赖订单表 + 支付表”“按日期分区的用户行为表查询”) | 1. 解析视图 - 表 / 分区依赖关系;2. 确保基表 / 前置分区加载完成后,再计算视图 / 查询结果 | 避免因基表缺失 / 分区未加载导致的查询错误,保障数据仓库查询准确性 |
| 数据仓库工具 | ClickHouse | 物化视图刷新(如 “实时 GMV 物化视图依赖订单表实时写入”“用户留存物化视图依赖用户行为表”) | 1. 确定 “基表→物化视图” 的刷新顺序;2. 检测物化视图间的循环依赖,禁止无效视图创建 | 保障物化视图数据实时性,避免无效视图占用存储 / 计算资源 |
(欢迎关注。欢迎订阅 本专栏 )