深度学习进阶(三)——生成模型的崛起:从自回归到扩散
一、前言:当模型开始“创造”
在深度学习的早期阶段,主流研究重心在“判别”任务——分类、检测、分割、识别。模型输入一个样本,输出它属于哪个类别,或者预测某个数值。
但当我们开始追问另一个问题时,一切变得不一样了:
“能不能让模型学会生成一个‘看起来像真的’样本?”
这个问题的意义非比寻常。
它不仅涉及算法性能,更触及智能的本质:理解、想象、再创造。
于是,生成模型(Generative Models)成为深度学习领域最令人着迷的方向之一。
从最早的自回归语言模型,到VAE 的连续潜空间学习,再到GAN 的对抗训练,最后到扩散模型(Diffusion Model) 席卷整个AI生成领域,这条路线几乎串起了整个深度学习的创造性发展史。
本文将沿着这条路径,系统梳理生成模型的思想演化,并尽可能以直觉、可理解的方式讲清楚它们的核心原理。
二、自回归模型:一步步“预测未来”
1. 基本思想
自回归(Autoregressive, AR)模型的思想非常朴素:
“我生成当前的数据点时,依赖于我之前生成的所有数据。”
在数学上,它对应一个概率分解:
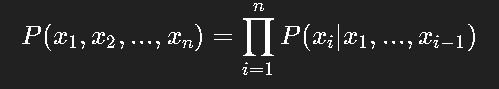
也就是说,模型通过学习条件概率 P(xi∣x<i)P(x_i | x_{<i})P(xi∣x<i),就能逐步生成整个样本。
这种方法最早用于语言建模:给定前面的词,预测下一个词。
伪代码如下:
x = []
for i in range(n):next = Model.predict(x)x.append(next)
return x
这种生成方式的直觉是“顺序地思考”。
每一步都依赖前文,所以它天然适合语言、语音、时间序列等任务。
2. RNN → Transformer:序列建模的演化
RNN(循环神经网络)最初承担了这种任务:输入一个词,输出下一个词的概率分布。
但随着序列变长,RNN 的梯度消失问题逐渐显露,于是 LSTM、GRU 等结构应运而生。
然而,它们仍然难以处理极长依赖。直到 Transformer 出现,
自注意力(Self-Attention)彻底改变了这一切——它让模型可以直接建模任意距离的依赖关系。
于是 GPT 这样的语言模型诞生了:
它依然是自回归的本质,只不过每一步的条件建模能力变得更强。
3. 自回归的优点与局限
✅ 优点:理论简单,生成连贯;训练稳定;概率定义明确。
❌ 缺点:生成速度慢(必须逐步生成);难以全局优化;对连续空间建模不自然。
这些问题促使研究者开始探索新的思路:
能否一次性“采样”出整张图像?能否直接从分布学习整体结构?
这时,VAE(变分自编码器)登场了。
三、VAE:让模型学会“想象”的空间
1. 动机:让网络学会分布,而不是点
在判别模型中,我们只关心“输入→标签”。
但在生成问题里,我们希望模型学会整个分布 P(X)P(X)P(X)。
于是有人提出:
如果我能把输入样本编码成某种“潜在表示”(latent variable)z,然后学会从 z 还原 x,就能从 z 的分布中采样,生成新的样本。
这就是变分自编码器(VAE)的思想。
它的结构分两部分:
编码器(Encoder):把输入 xxx 映射到潜在空间分布参数 (μ,σ)(\mu, \sigma)(μ,σ)。
解码器(Decoder):从采样的潜变量 z∼N(μ,σ)z \sim N(\mu, \sigma)z∼N(μ,σ) 还原出原始数据。
伪代码如下:
mu, sigma = Encoder(x)
z = mu + sigma * random_noise()
x_recon = Decoder(z)
loss = recon_loss(x, x_recon) + KL(mu, sigma)
2. 数学本质:最大化似然的近似
VAE 通过最大化一个“变分下界”(ELBO)来近似最大似然:
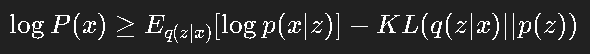
这两项分别代表:
重建误差(生成的样本像原样本);
KL 散度(编码分布接近先验)。
直觉上,模型既要学会“复现真实数据”,又不能让潜变量分布跑得太离谱。
3. 优点与缺陷
✅ 优点:结构简单;可微分采样;生成连续空间样本。
❌ 缺点:生成样本模糊;KL 项常导致“posterior collapse”(潜变量被忽略)。
虽然 VAE 带来了潜空间的概念,但生成质量还不够“锐利”。
研究者希望模型生成更逼真的样本——于是,对抗式思想登场。
四、GAN:让生成与判别彼此博弈
1. 基本思想
GAN(Generative Adversarial Network)由 Ian Goodfellow 在 2014 年提出。
它引入了一个革命性的设想:
“我不再直接告诉模型什么是好的样本,而是让它去骗一个判别器。”
整个系统包含两个网络:
生成器 G:从随机噪声 z 生成样本;
判别器 D:区分输入是真样本还是假样本。
它们在一个零和博弈中训练:
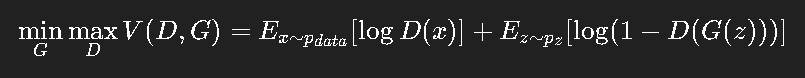
伪代码如下:
for each step:x_real = sample_real()z = random_noise()x_fake = G(z)loss_D = - (log D(x_real) + log(1 - D(x_fake)))loss_G = - log(D(x_fake))update(D)update(G)
判别器越强,生成器越难骗;
生成器越好,判别器越难区分。
这场博弈最终让 G 学会了“数据的真实分布”。
2. GAN 的成功与痛点
GAN 一度成为生成领域的明星。
DCGAN、StyleGAN、BigGAN 等不断刷新图像生成质量。
但 GAN 的问题也同样显著:
训练极不稳定;
模式崩溃(Mode Collapse);
缺乏显式概率解释;
对超参数敏感。
GAN 让我们第一次看到了生成的真实感,
但它的训练过程更像艺术而非工程。
研究者开始思考:
有没有一种方法,既能保证生成质量,又能稳定训练?
这时,扩散模型(Diffusion Model)登上舞台。
五、扩散模型:从噪声中重建世界
1. 基本思想
扩散模型的核心理念非常优雅:
“我可以先把数据逐步加噪声,直到完全变成随机分布;然后再学习一个过程,把噪声还原成数据。”
也就是说,我们让模型学会“逆向扩散”:从随机噪声一步步还原清晰样本。
正向过程:
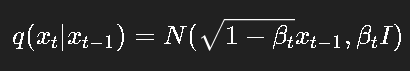
反向过程:
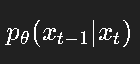
模型的目标是学习如何预测噪声,使得逐步还原的结果逼近真实分布。
伪代码:
x_T = random_noise()
for t in reversed(range(T)):noise_pred = model(x_t, t)x_t-1 = denoise(x_t, noise_pred, t)
return x_0
2. 理解扩散的直觉
可以把它想象成摄影的逆过程:
我们先往照片上加噪声,直到什么都看不清;
然后训练一个模型,让它一层层“去噪”,恢复出原图。
每一步只学一点点恢复,因此训练稳定、可控。
而当我们采样时,从纯噪声开始,模型能“从无到有”地创造图像。
3. 为什么扩散模型效果好?
每一步都是简单的高斯建模,梯度稳定;
训练目标直接对应噪声回归,优化清晰;
可以与条件信息(文本、姿态等)灵活结合;
容易并行训练(相比自回归模型更高效)。
于是我们看到了 Stable Diffusion、Imagen、DALL·E 2 等奇迹。
六、Diffusion 与 Transformer 的结合
现代生成模型中,扩散与 Transformer 正在融合:
Stable Diffusion 使用 U-Net 作为去噪网络;
DiT(Diffusion Transformer) 用纯 Transformer 构建扩散网络;
Consistency Model / Flow Matching 则进一步简化扩散过程,加速采样。
伪代码上看,它仍然是一个预测噪声的模型,但内部结构越来越强大:
noise_pred = Transformer(x_t + timestep_embedding)
x_t-1 = denoise_step(x_t, noise_pred)
七、从自回归到扩散:一条清晰的脉络
| 模型 | 核心思想 | 优点 | 局限 |
|---|---|---|---|
| 自回归 | 条件生成 | 简单、概率明确 | 速度慢 |
| VAE | 潜空间重建 | 可解释、连续 | 模糊 |
| GAN | 对抗训练 | 逼真 | 不稳定 |
| Diffusion | 去噪重建 | 稳定、高质量 | 采样慢 |
可以看到,每一代模型都在解决前一代的不足:
VAE 解决概率定义;
GAN 解决模糊;
Diffusion 解决稳定性。
这正是深度学习体系不断自我进化的体现。
八、未来展望:生成模型的方向
加速采样
扩散模型采样需数百步,研究者正在用 Flow Matching、ODE/SDE 简化采样。多模态统一
文本生成图像、图像生成音乐、声音生成动作——生成模型正在成为“跨模态桥梁”。控制与可解释性
如何让用户可控地生成指定风格、构图、语义,是下一个核心问题。能耗与部署
大模型的算力消耗高昂,模型压缩、蒸馏与 LoRA 将成为主流。
九、总结:生成模型的精神
从自回归的“一步步推理”,
到 VAE 的“潜空间想象”,
再到 GAN 的“博弈创造”,
最后到 Diffusion 的“从噪声中造世界”,
这条路线反映的不是算法的更替,而是智能的演化。
我们从最初“预测下一个词”,
走到了今天“生成整个人类想象力的边界”。
而生成模型真正的魅力,不仅在于它能画图、写诗、作曲,
而在于它让机器开始拥有——
理解分布、构建世界的能力。