Video Understanding Baseline via papers
CV Backbone
Deformable Convolution
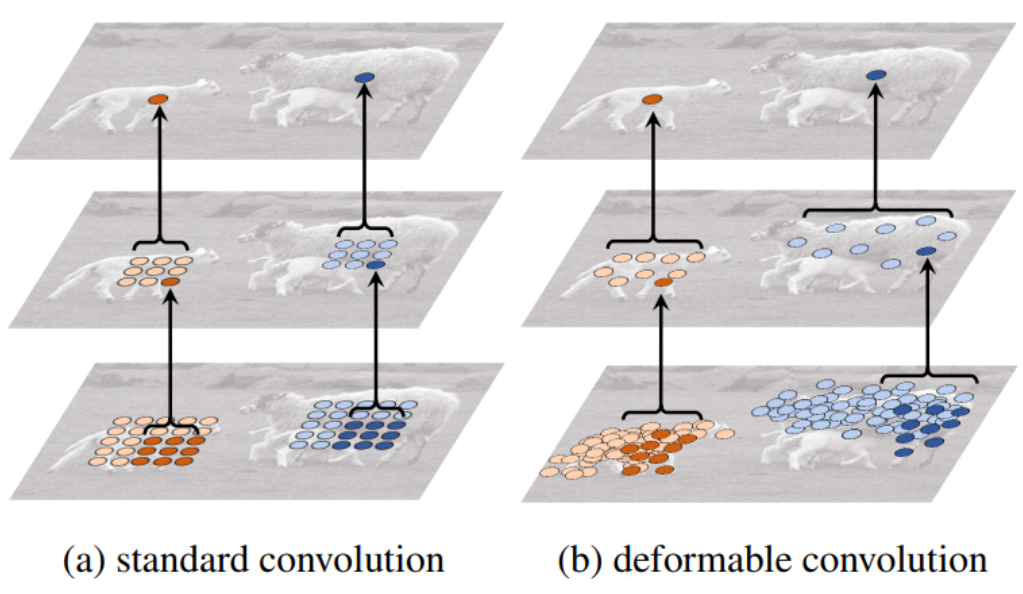
可变性卷积顶层特征图中最终的特征点学习了物体的整体特征,更能排除背景噪声的干扰
原理是基于一个网络学习offset(偏移),使得卷积核在input feature map的采样点发生偏移,集中于我们感兴趣的区域或者目标,偏移量是由输入特征图与另一个卷积(通道2N,表示卷积核分别学习x方向与y方向的偏移量)生成的,通常是小数,使用双线性插值来得到偏移后的像素值
一个batch内的每张特征图用到的偏移量是一样的
Deformable Attention
Deformable DETR
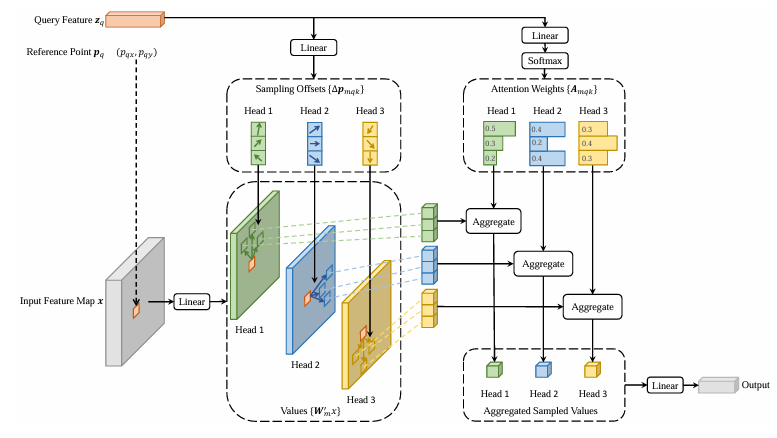
对object query在不同head的尺度下预测偏移量和注意力分数,融合
DAT
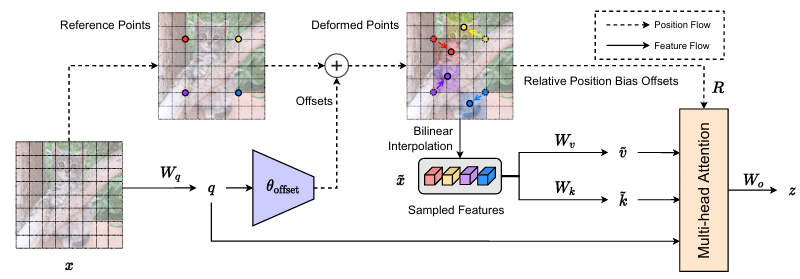
每个patch token同时是 query、key、value
Reference point是每个 query 的空间位置(例如它在 feature map 上的坐标)
将通道分成多个 head,每个 head 独立地预测采样点偏移和权重,双线性插值得到偏移后的特征值特征,把多个head的偏移特征合并
Depthwise Separable Convolution
先,一个卷积核负责一个通道,一个通道只被一个卷积核卷积
再,合并通道过卷积核,所有通道被多个卷积核卷积,一个卷积核负责全部通道
DaViT
交替堆叠Spatial Attention和Channel Attention
Spatial Attention → 用类似 Swin Transformer 的 window-based attention;
Channel Attention → 用 grouped attention 的方式在 通道维度 上计算。
MM Backbone
ALIGN
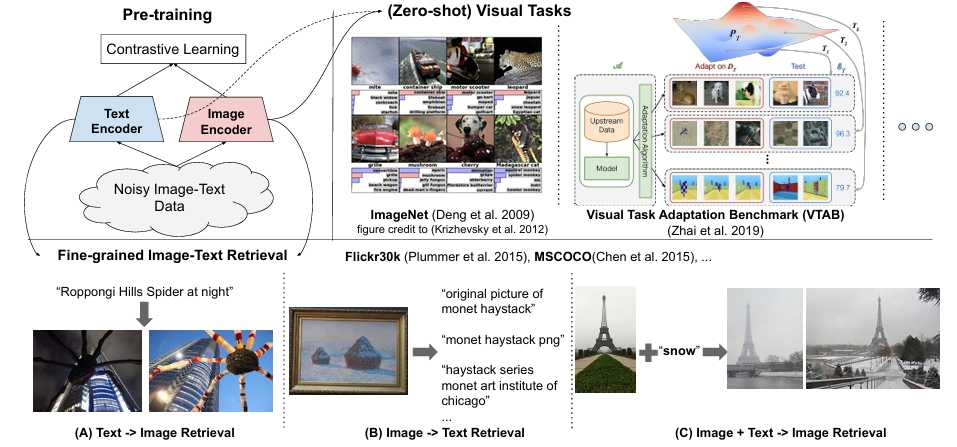
Image Encoder用EfficientNet,Text Encoder用BERT
18亿图文对,但是数据来自网络很杂,只在频域简单过滤了一下,其他和CLIP没区别
Florence-2
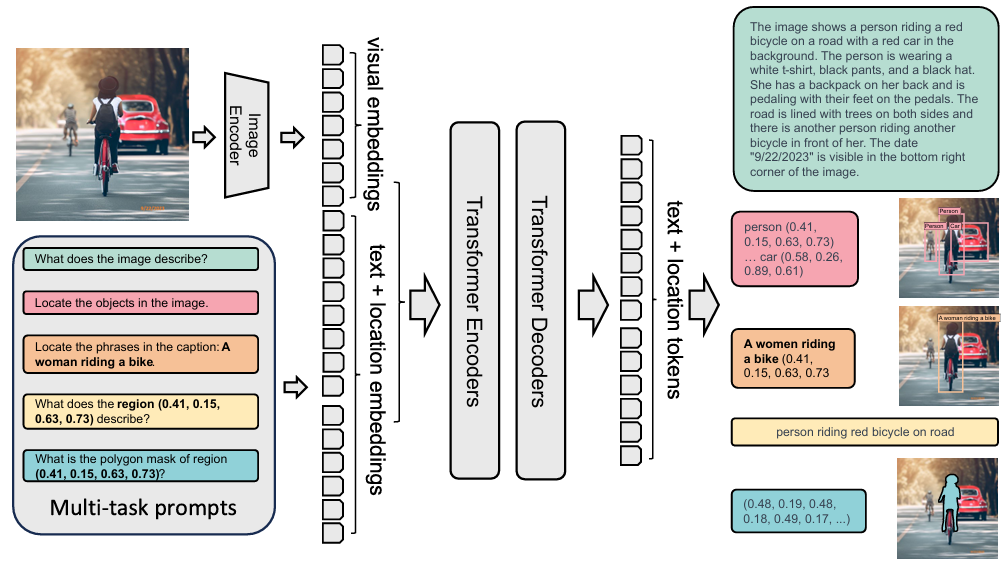
将每个任务都制定为一个翻译问题:给定一个输入图像和一个特定于任务的提示,我们生成相应的输出响应。根据任务的不同,提示和响应可以是文本或区域
当提示是区域时,将位置tokens添加到分词器的词汇表中,表示量化坐标
Image Encoder用DaViT
使用扩展的语言分词器和词嵌入层获得提示嵌入prompt,然后将视觉嵌入对齐后与提示嵌入拼起来得到多模态编码器模块输入。对所有任务使用标准语言建模和交叉熵损失
MLLM Backbone
Florence-VL
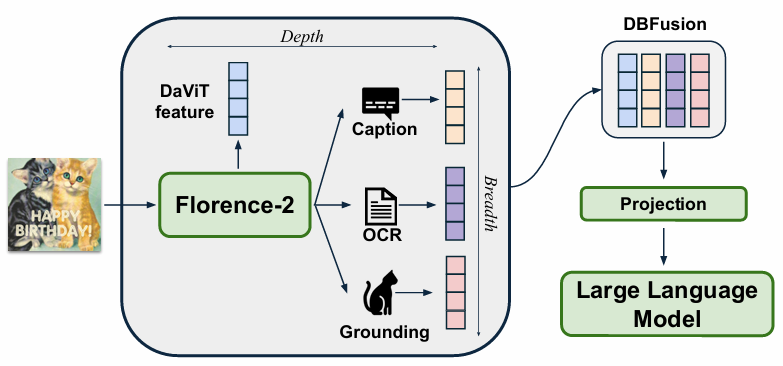
Florence-2比较好用,因为每个任务都制定为一个翻译问题,所以方便统一,从而在深度和广度两个方向融合对齐给大语言模型
Video Understanding Backbone
AdaFocus
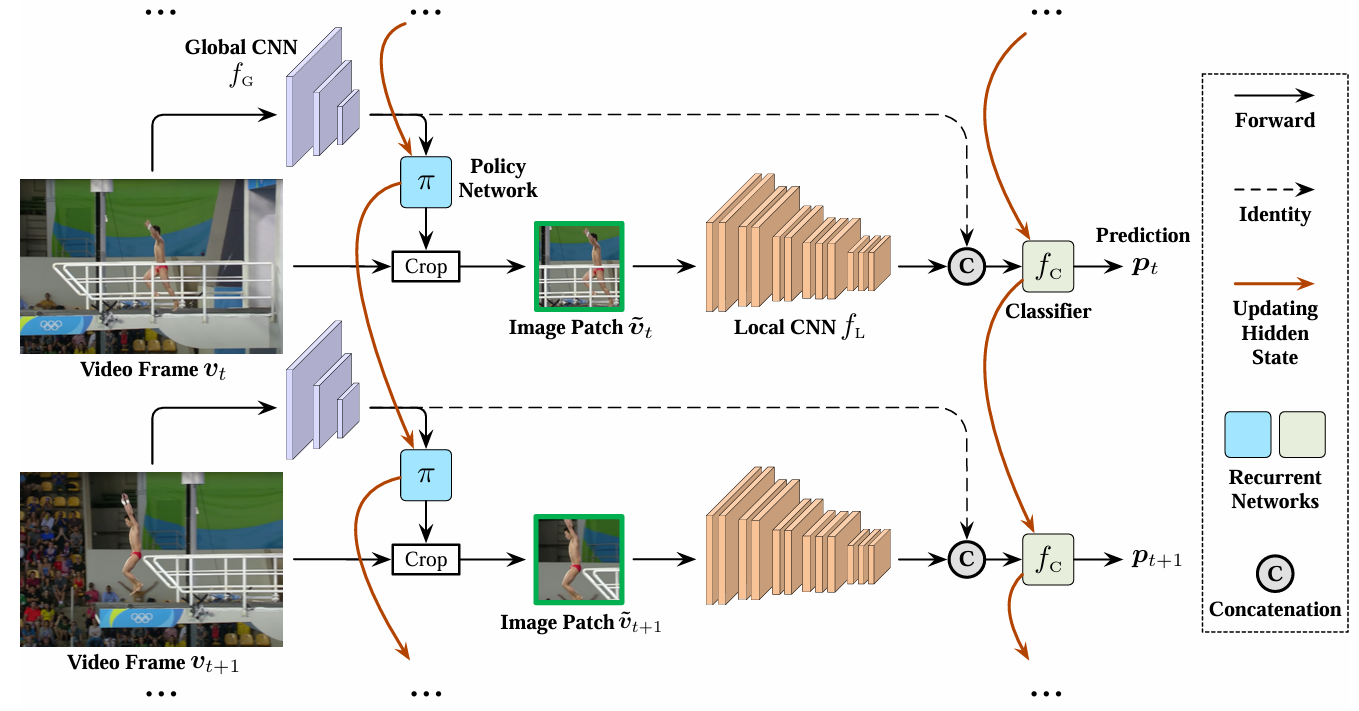
降低视频的空间冗余性(即寻找和重点处理视频帧中最关键的图像区域),同样是一种高效的方法
Global CNN轻量,Local CNN密集,Π是用策略梯度学的RNN(取得patch的crop操作不可求导),fC是RNN
AdaFocus的训练分为三个阶段:(1)移除Π,多次随机crop训练Local CNN和fC这俩分类网络。因为背景 patch 的梯度 ≈ 随机噪声,整体方向不稳定 → 会被平均掉;而含有目标的 patch 的梯度 → 有一致方向 → 会在统计上占主导(2)引入Π,冻结分类网络(3)冻结Π,微调分类网络
AdaFocus V2
将 AdaFocus 的训练流程简化为端到端
让策略网络输出 patch 的中心坐标,通过插值机制在原图 / 特征图上“采样”出 patch 内容,从而使得从分类损失反向传播时可以对策略网络也传梯度
提出了三种增强机制来稳定训练