MySQL架构和存储引擎
MySQL架构
MySQL8.0服务器是由连接池、服务管理⼯具和公共组件、NoSQL接⼝、SQL接⼝、解析器、优化
器、缓存、存储引擎、⽂件系统组成。MySQL还为各种编程语⾔提供了⼀套⽤于外部程序访问服务器的连接器,也就是API。整体架构图如下所⽰:
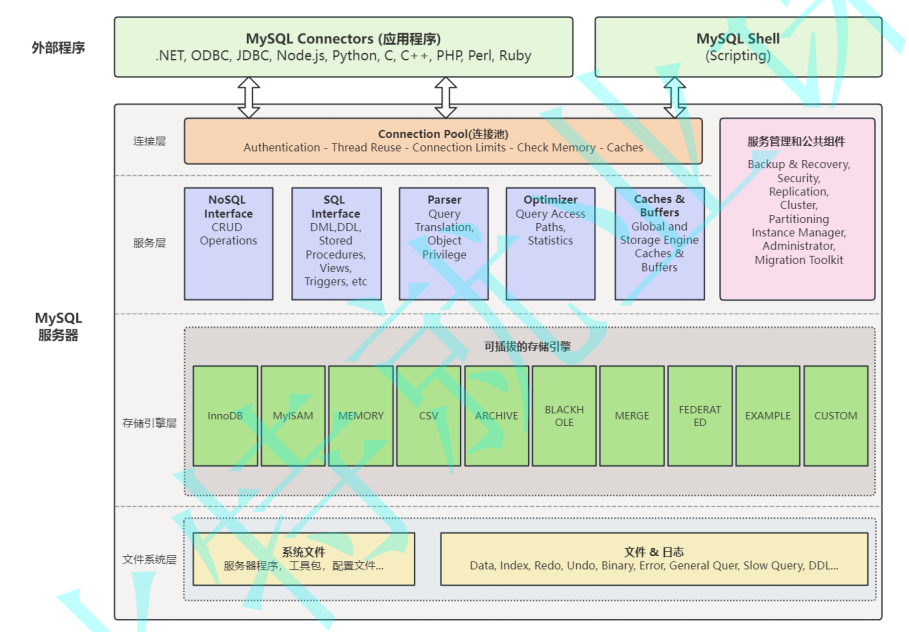
• MySQL Connectors:为使⽤MySQL服务的编程语⾔平台,提供了访问接⼝,可以根据⾃⼰实际使⽤的编程语⾔到官⽹下载地址下载。
• MySQL Shell:是⼀个⾼级客⼾端和代码编辑器,以组件的形式提供,需要单独安装。除了提供的类似于 mysql 客⼾端的功能,还可以使⽤ JavaScript 和 Python 调⽤MySQL 的API,⼀般为开发⼈员使⽤。
• 连接层:对客⼾端连接进⾏权限校验并保存客⼾端的连接信息,通过池化技术实现线程重⽤,以及根据具体的配置限制连接数量。
• 服务管理和公共组件:提供了数据备份与恢复,安全组件,主从复制和集群管理,表分区等实⽤功能。
• 服务层:提供了NoSQL API, SQL API, SQL语句解析,SQL语句优化,SQL语句缓存等组件,并将优化后的SQL语句发送⾄存储引擎执⾏相应的操作并返回结果。
• 存储引擎层:⼀系列可插拔的存储引擎,主要负责数据的写⼊和读取,与底层的数据和⽇志⽂件进行交互,可以根据具体的业务需求选择不同的存储引擎,后⾯我们具体介绍他们之间的区别。
• ⽂件系统层:包含了MySQL发⾏版的⽂件和程序,以及具体数据库⽂件和⽇志
连接层
⽹络端⼝和连接管理线程
⽹络端⼝
⼀台服务器能够侦听多个⽹络端⼝上的客⼾端连接,开放多个端⼝,只需在选项⽂件中指定多个端⼝即可,配置如下所⽰:
[mysqld] # mysqld节点
port=3306 # 端⼝1
port=3307 # 端⼝2连接管理线程
-
单进程多 Socket:一个线程可创建多个监听套接字(由操作系统支持),绑定不同的端口。
-
I/O 多路复用:通过
epoll(Linux)/kqueue(BSD)等系统调用,单线程可监控多个监听套接字。
客户端连接线程管理
服务器连接管理器线程在接收到客⼾端连接请求后建立通信套接字,把通信套接字给真正的执行线程,由该线程来处理连接的⾝份验证和其他具体请求。执⾏线程使⽤线程池技术进⾏缓存,当⼀个通信套接字需要分配执行线程时,先从线程池中查找是否有可⽤的线程,如果没有则新创建⼀个,当连接结束时,如果线程池没有满,则把当前线程放⼊线程池,主要的作⽤是提⾼线程的复⽤,减少创建线程造成的系统开销从⽽提⾼效率,如果线程池已经满了,那就直接释放线程
通过以下系统变量和状态变量控制和监视线程池和执行线程:
1、系统变量 thread_cache_size 决定了线程池的⼤⼩。默认情况下,服务器在启动时会⾃动
调整这个值,但也可以通过选项⽂件明确指定⼤⼩,值为 0 时线程池大小为0,即不使用线程池
2、有些复杂的SQL语句在执⾏过程中可能会有深层递归从⽽消耗更多的内存,通过设置
thread_stack=N 调整线程栈⼤⼩;
3、要查看线程池中的线程数以及超过线程池大小后新创建的线程数,通过状态变量 Threads_cached 和Threads_created 查看
[mysqld] # mysqld节点
thread_cache_size=16 #线程池⼤⼩
thread_stack=1048576 #堆栈内存⼤⼩
连接量管理
• 系统变量 max_connections 可以控制服务器允许同时连接的最⼤客⼾端数,当服务器达到
max_connections 指定的连接数时会拒绝所有新的连接请求,同时会增加状态变量
Connection_errors_max_connections 的值;
• mysqld实际上允许 max_connections+1 个客⼾端连接。额外的连接为拥有
CONNECTION_ADMIN 权限的帐⼾(管理员)使⽤,即使普通连接达到了 max_connections 的
数量,管理员也可以连接到服务器进⾏管理操作;
• 在部署为主从复制的环境中,从节点的连接数也会计⼊ max_connections 中,如果连接达到上
限主从复制将会失败;
服务层
数据库服务层是整个数据库服务器的核⼼,主要包括了服务管理和公共组件、NoSQL和SQL接⼝、解析器、查询优化器和缓存
服务管理和公共组件
MySQL提供了多种功能服务以满⾜不同使⽤场景下的需要,常⽤的服务如下:
• Backup & Recovery:备份与恢复,在 备份与恢复专题介绍;
• Security:安全,在安全性与权限管理专题介绍;
• Replication:主从复制,在主从复制专题介绍;
• Cluster:MySQL集群,在MySQL集群专题介绍;
• Partitioning:表分区,在分库分表与表分区专题介绍;
• Instance Manager:实例管理,在系统数据库专题介绍;
• Administrator:MySQL管理员,在安全性与权限管理介绍专题;
• Migration Toolkit:迁移⼯具包,在安全性与权限管理专题介绍
NoSQL接⼝与SQL接⼝
主要负责接收客⼾端发送的各种SQL语句和命令,并将SQL发送到其他部分,然后把接收到的结果返回给客⼾端。
Parser(解析器)
解析器的主要作⽤是将客⼾端发来的SQL语句,转换为⼀棵语法树,转换的过程包括词法分析和语法分析
词法分析:将 SQL 字符串拆解为有意义的 Token 序列
语法分析:验证 Token 序列是否符合 SQL 语法规则,构建 抽象语法树(AST)
# 例如有如下SQL语句, 对应的解析树⼤致如图所⽰
select sn, name from student where id = 1;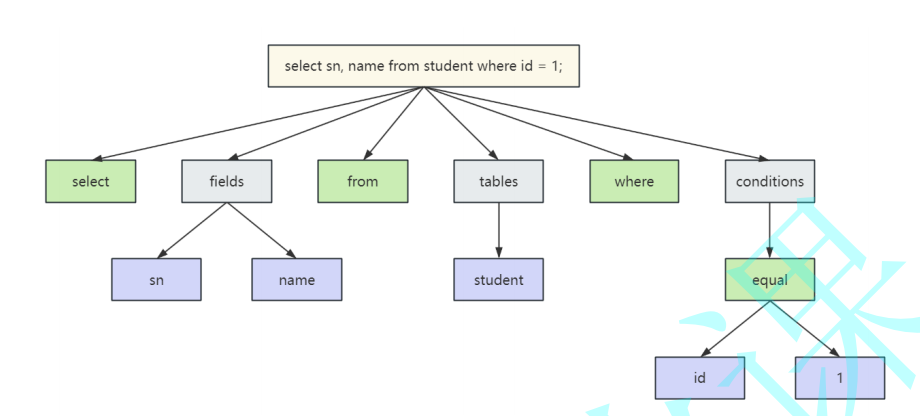
Optimizer(优化器)
通过解析的SQL语句将进⼊优化器处理阶段,优化器会将语法树转化为查询执行计划,⼀般情况下,⼀条查询可以有很多种执⾏⽅案,查询优化器会根据索引选择最佳的执⾏⽅案,最终把确定要执⾏的SQL交给执⾏器调⽤存储引擎API
Caches & Buffers(缓存)
MySQL的缓存主要的作⽤是为了提升查询的效率,当服务器接收到⼀个 select 查询语句时,会
先进⼊缓存查询当前SQL语句在缓存中是否存在,缓存以 key (SQL语句)和 value(查询结果) 的形式存储,key是具体的SQL语句,value是结果的集合,如果命中缓存,直接返回结果,⽆法命中缓存,则进⼊解析器进⾏正常查询流程。
这⾥需要说明的是,缓存数据在表被更新之后将会失效,尤其在写多读少的场景中,缓
存会频繁失效与新增,命中率⾮常低,因此MySQL5.6之后服务层缓存功能默认关闭,⽽且在
MySQL8.0中服务层缓存被官⽅删除,这⾥不做过多讨论。
SQL语句的执⾏流程
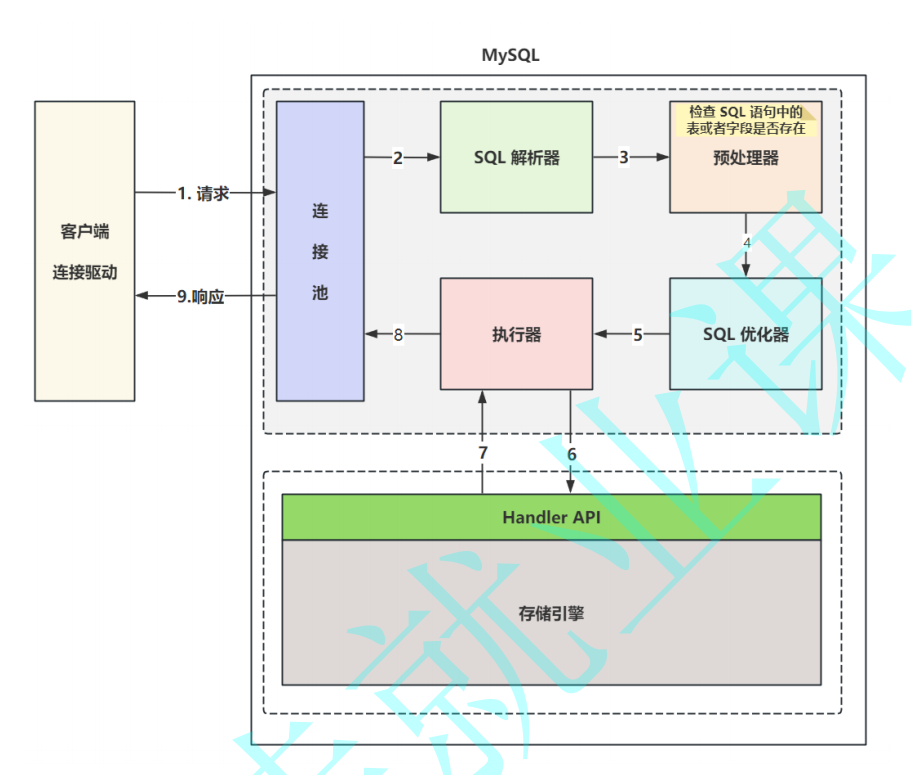
存储引擎
存储引擎是处理不同表类型SQL操作的MySQL组件。MySQL服务器采⽤可插拔的存储引擎架构,
在服务器运⾏时可以动态的加载和卸载。
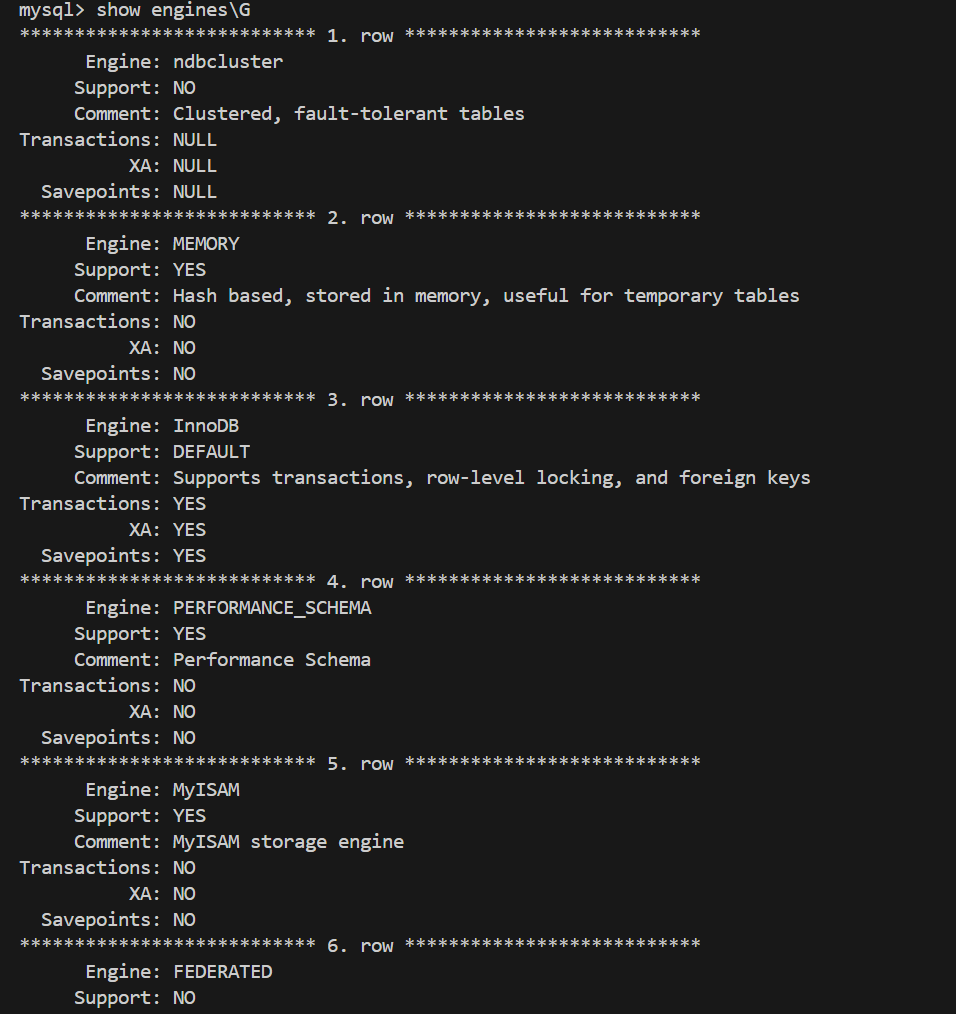
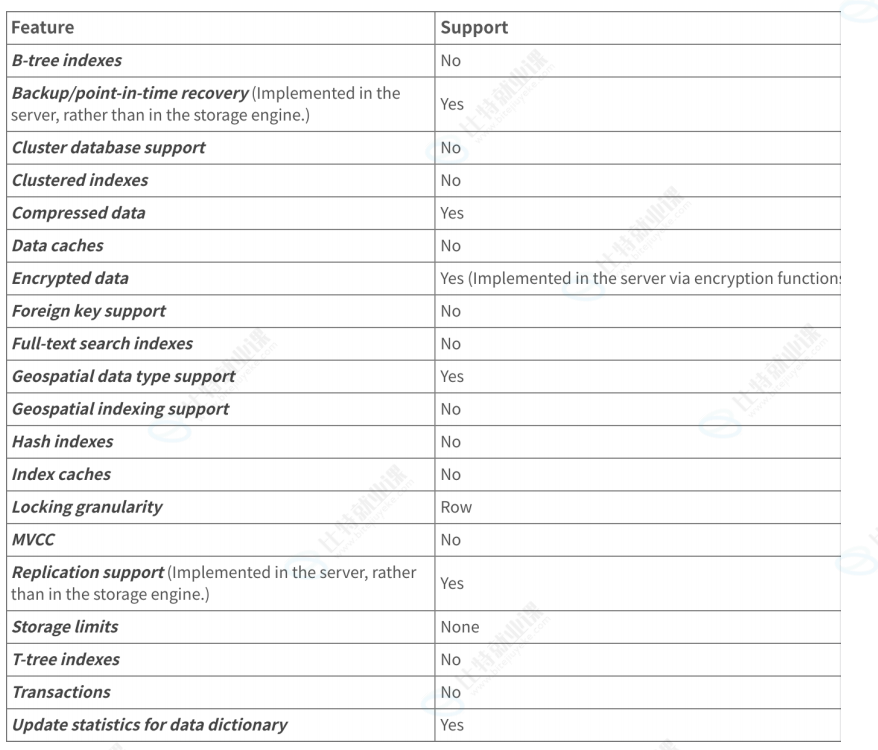
查看当前服务器⽀持哪些存储引擎可以使⽤ SHOW ENGINES 语句, Engine 表⽰:存储引擎的
名称, Support :表⽰当前服务器是否⽀持,值 YES 、 NO 和 DEFAULT 分别表⽰,⽀
持、不⽀持和当前默认存储引擎
InnoDB 存储引擎
InnoDB是⼀款兼顾⾼可靠性和⾼性能的通⽤存储引擎。在MySQL8.0中默认的存储引擎是 InnoDB ,使⽤ CREATE TABLE 语句创建表时,在没有修改默认存储引擎或明确指定其他存储引擎时,将创建⼀个 InnoDB 的表。
InnoDB存储引擎的特性
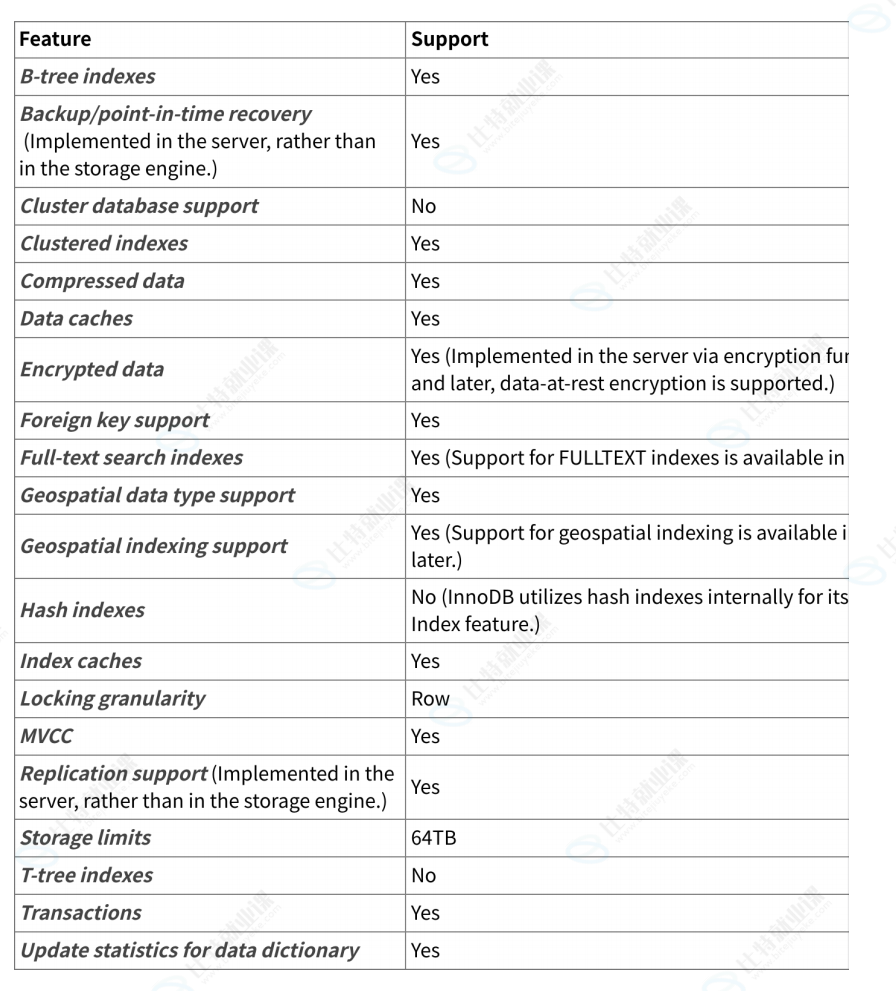
InnoDB 的主要优势
1、DML操作遵循ACID模型,事务具有提交、回滚和崩溃恢复功能,以保护⽤⼾数据。事务和锁专题中介绍
2、如果发⽣意外⽽崩溃,⽆论当时数据库发⽣了什么,都不需要在重启数据库后执⾏任何特殊操作。InnoDB 的崩溃恢复功能会⾃动完成崩溃之前提交的更改,并撤消崩溃前正在进⾏但未提交的更改,从⽽允许我们从中断的地⽅继续执⾏。备份与恢复专题介绍
3、⽀持⾏级锁,提⾼了多⽤⼾的读取并发性和性能。事务和锁专题中介绍
4、 InnoDB 存储引擎维护了⼀个⾃⼰的缓冲池,访问数据时在内存中缓存表和索引数据,对于经常使⽤的数据直接从内存中处理,⼤幅提升了效率。在专⽤数据库服务器上,通常会将⾼达 80% 的物理内存分配给缓冲池。
5、InnoDB表优化了基于主键的查询,每个InnoDB表都有⼀个称为聚簇索引的主键索引,实现通过最少的磁盘I/O完成对主键的查找。索引专题中介绍
6、为了保持数据完整性, InnoDB ⽀持 FOREIGN KEY (外键)约束。在进⾏插⼊、更新和删除数据时确保相关表之间的⼀致性
7、当从表中反复查询相同的⾏时,⾃适应哈希索引会⾃动接管这些查询,此时查询效率和哈希表相同。
验证InnoDB是否为默认存储引擎
1、查看表创建
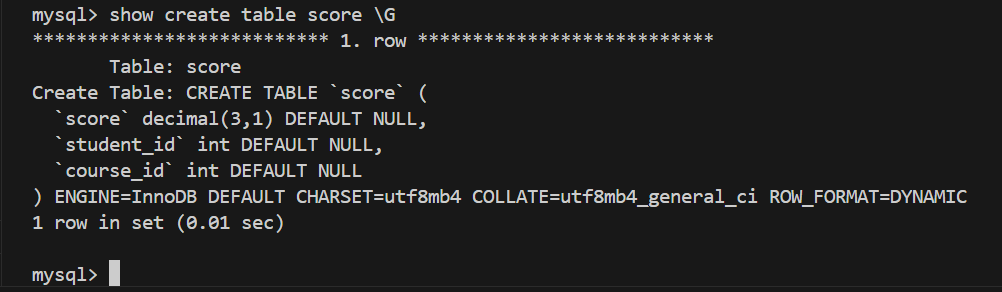
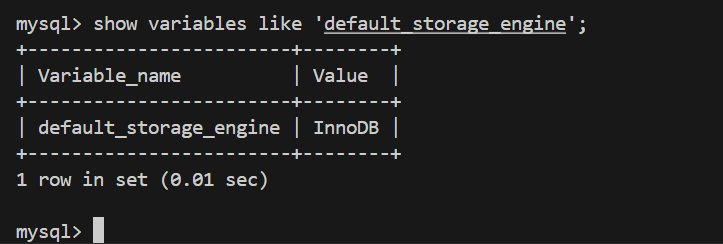
2、如果InnoDB不是默认的存储引擎,可以通过在服务器命令⾏指定选项 --default-storageengine=InnoDB 或者在选项⽂件的 [mysqld] 节点定义 default-storageengine=InnoDB 并重新启动服务器来设置 InnoDB 存储引擎
创建InnoDB表
# 选择⽬标数据库
use test_db# 创建⼀个使⽤InnoDB存储引擎的表
CREATE TABLE t_innodb (id int(11) PRIMARY KEY AUTO_INCREMENT,name varchar(20)
) ENGINE = InnoDB;
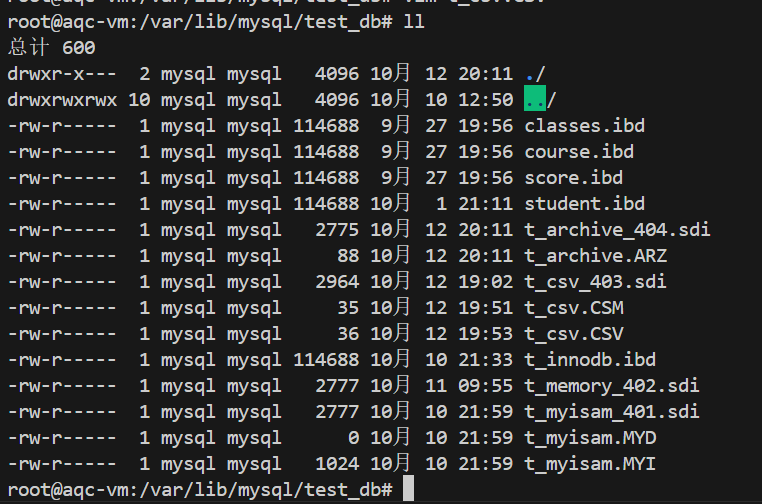
当创建⼀个存储引擎为 InnoDB 的表时,会在 data_dir/test_db ⽬录下⽣成⼀个⽤来存储结构、数据、索引的物理⽂件,命名格式为 表名.ibd ,以当前为例会在 /var/lib/mysql/test_db ⽬录下⽣
成⼀个 t_innodb.ibd 的表空间⽂件
在MySQL8.0中表结构也保存在 .ibd ⽂件中,可以使⽤ ibd2sdi ⼯具提取表定义的具
体信息,使⽤⽅法: ibd2sdi --dump-file=t_innodb.txt t_innodb.ibd ,⽣成的
t_innodb.txt ⽂件中有对应表的具体描述。在MySQL5.7中表结构是由.frm文件来存储的,.ibd文件存储数据和索引,在MySQL8.0中合并了这两个
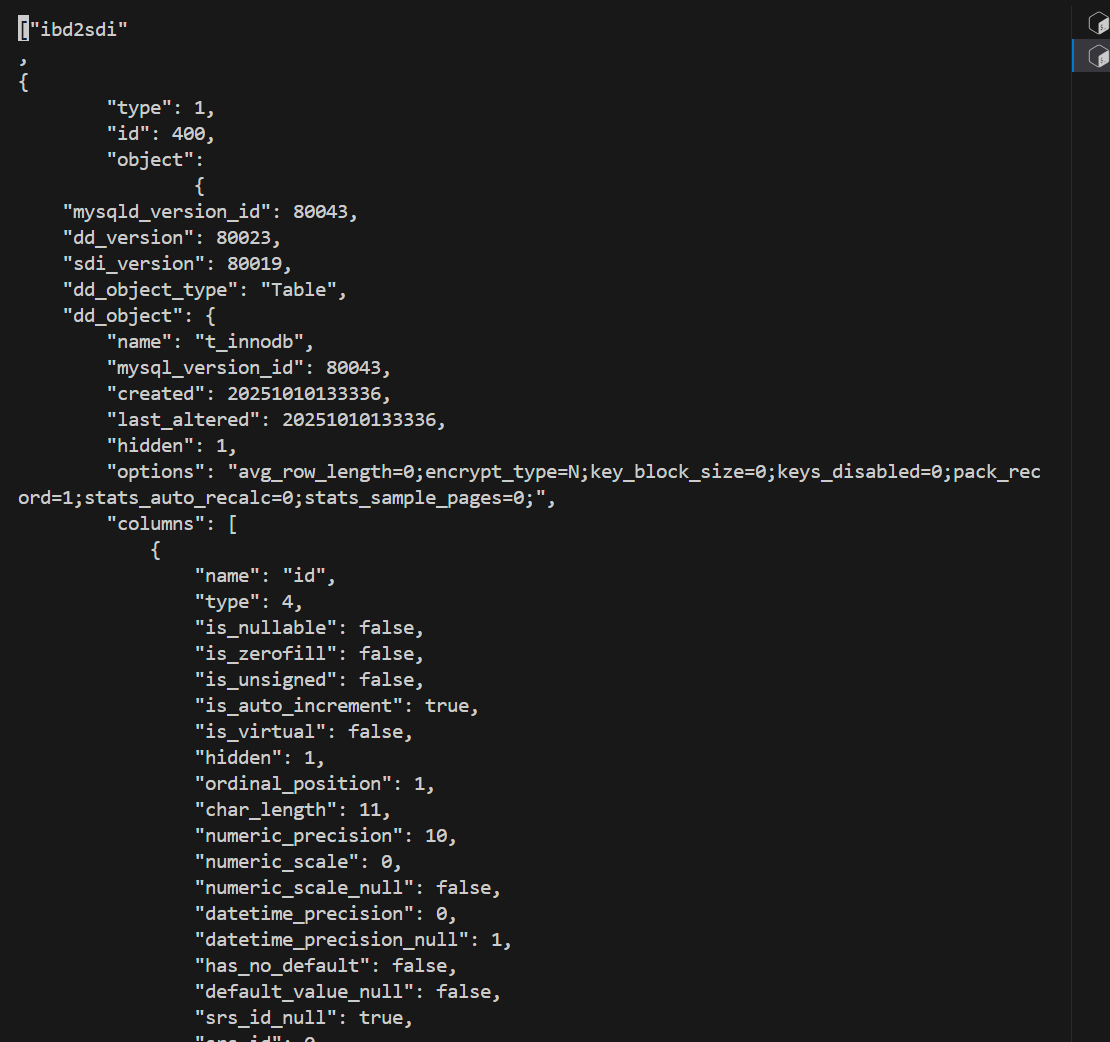
下面是t_innodb.txt的内容
MyISAM存储引擎
使⽤MyISAM存储引擎的表占⽤空间很⼩,但是由于使⽤表级锁,所以限制了并发读/写操作的性能,通常⽤于只读或主要是读的场景,因为读锁是共享锁,读是可以并发的。
MyISAM 存储引擎的特性
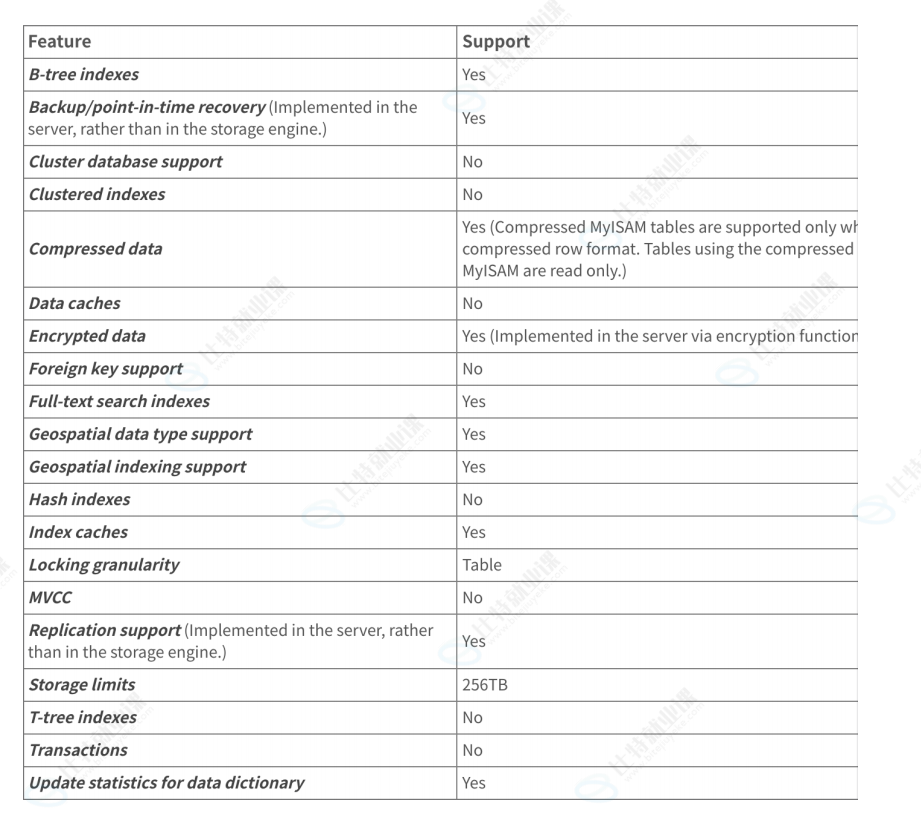
MyISAM 的主要优势
1、MyISAM表的最⼤⾏数为 (2^32)^2 及 (1.844E+19) ⾏,毕竟表限制是256TB
2、每个MyISAM表最多可以创建64个索引,每个索引最多可以包含16个列;
3、通过 CREATE table 创建表时,指定 DATA DIRECTORY=PATH 和 INDEX
DIRECTORY=PATH 将数据⽂件和索引⽂件放在不同设备的不同⽬录中,从⽽提⾼访问速度;
4、 BLOB 和 TEXT 数据类型的列也可以被索引;
5、在索引列中允许使⽤NULL值;
6、如果mysqld启动时设置了 myisam_recover_options 系统变量,那么MyISAM表在打开时进
⾏会⾃查,如果上⼀次表没有正确关闭将会修复;
7、表中 VARCHAR 和 CHAR 列的⻓度总和最多可达64KB。
8、UNIQUE 约束的⻓度不受限制
创建MyISAM 表
1、在MySQL 8.0中 InnoDB 是默认引擎,所以在创建表时需要指定 ENGINE=MyISAM
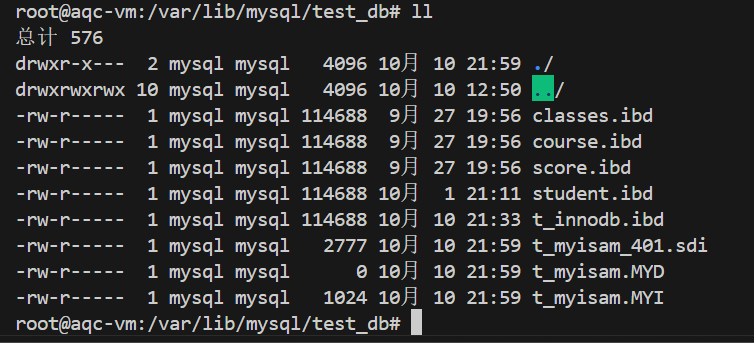
2、创建 MyISAM 表会根据表名⽣成三个不同后缀名⽂件,分别是以 .MYD ( MYData )为后缀的表数据⽂件,以 .MYI ( MYIndex ) 为后缀的表索引⽂件,以 .sdi 为后缀的表信息⽂件(JSON格式),注意在MySQL8.0以前,MyISAM表的表信息文件是.frm后缀。
MyISAM 表存储格式
1、MyISAM 表⽀持三种不同的存储格式,其中 FIXED 静态(固定)格式和 DYNAMIC 动态格式,根据使⽤的列类型⾃动选择,如果有可变⻓度的列 ( VARCHAR、VARBINARY 、
BLOB 或 TEXT ) 时,那就默认采用动态格式,如果没有那就采用静态格式,第三种是压缩格式,只能使⽤ myisampack 实⽤程序⽣成并且是只读格式
2、当表中没有 BLOB 或 TEXT 数据类型的列,可以使⽤ CREATE TABLE 或 ALTER TABLE 语句创建或修改表时,可以结合 ROW_FORMAT 表选项将表格式设置为 FIXED 或 DYNAMIC,也就是说哪怕表中有VARCHAR或VARBINARY,也可以通过设置选项来变成静态格式,那就是取 VARCHAR或VARBINARY最大值来分配空间,如果表包含 BLOB 或 TEXT 列,则不能使用 FIXED 格式。
3、使⽤ myisamchk 实⽤⼯具对已压缩的MyISAM表进⾏解压操作, myisamchk --unpack 。
静态格式(Fixed-Length)表
1、当表不包含可变⻓度的列 ( VARCHAR、VARBINARY 、BLOB 或 TEXT ) 时默认就是静态格式,每⾏都使⽤固定数量的字节存储。
2、 MyISAM 的三种存储格式中,静态格式是最简单和最安全的(最不容易损坏),同时也是最快的磁盘格式,因为每⾏的⻓度固定,根据索引中的⾏号乘以⾏⻓度就可以计算出该行所在表文件的位置,此外,每次读取固定数量的⾏也⾮常的⾼效。
3、静态格式表具有以下特点:
◦ CHAR 和 VARCHAR 类型的列⽤空格填充到指定的列宽; BINARY 和 VARBINARY 类型的列
⽤ 0x00 字节填充到列宽
◦ 每个为NULL的列,都⽤⼀个 1 BIT 的额外空间记录当前列是否为空;
◦ 速度⾮常快,且易于缓存;
◦ 崩溃后易于重建,因为⾏都位于固定位置;
◦ 通常需要⽐动态格式表更多的磁盘空间,因为每行都是固定大小,哪怕改行的有些列是空,也需要占用对应空间
动态格式表
1、当表中包含可变⻓度列( VARCHAR 、 VARBINARY 、 BLOB 或 TEXT ),则默认表格式为动态存储格式
2、动态格式表具有以下特点:
◦ 列类型是字符串,且⻓度⼤于等于4,⻓度都是动态的;
◦ 每⼀⾏都有⼀个标志来指⽰⾏有多⻓,当因更新操作⽽变得更⻓时,数据可能存储在不连续的
空间,可以使⽤ OPTIMIZE TABLE table_name 语句或 myisamchk -r 对表进⾏碎⽚整理;
◦ 每个允许为NULL的列,都⽤⼀个 1 BIT 的额外空间记录当前列是否为空

前三列不允许为空,mail列和remark列是可以为空的列,所以有对应bit位来表示是否为空,如果是1就表示为空,并且如果一列的值为空的话,那这一列就不分配空间了
◦ 通常磁盘空间占⽤⽐固定⻓度表要少很多,因为可变列按实际长度分配空间,空列直接不分配空间;
◦ 每⾏都单独压缩,每列都可能⽤单独的⽅式进⾏压缩。
3、常⽤的压缩⽅式:
◦ 如果数值列的值为0,⽆论原始数据类型是哪种都⽤⼀个 BIT 类型存储该值,注意和空列的位图分开,这个是在行数据中分配的1bit空间◦ 如果整数列中的值范围较⼩,则尽可能使⼩的类型存储该列,⽐如:列中的值范围在 -128到 127 之间,即使原始类型为 bigint (8bytes),也使⽤ TINYINT (1 byte) 类型存储
◦ 如果列中只有⼀⼩组可能出现的值,则数据类型转换为 ENUM ;
压缩格式表
1、压缩存储格式是使⽤myisampack⼯具⽣成的只读格式数据表,压缩表可以⽤ myisamchk解压
缩。
2、压缩格式表具有以下特点:
◦ 压缩表占⽤很少的磁盘空间;
◦ 静态格式表或动态格式表都可压缩
◦ 压缩表是只读的,因此不能在表中更新或添加数据;
MEMORY存储引擎
使⽤MEMORY存储引擎(以前称为HEAP)创建的表,内容存储在内存中。当服务器由于硬件问题、
断电或其他原因崩溃时数据会丢失,因为表文件并不会刷盘,因此这些表仅⽤作临时⼯作区或从其他表中提取数据的只读缓存。
使⽤场景
1、涉及瞬时、⾮关键数据的操作,例如会话管理或需要缓存的数据,当服务器停⽌或重新启动时,MEMORY 表中的数据会丢失;
2、⽤于快速访问和低延时,数据量可以完全放在物理内存中,不使⽤虚拟内存;
3、只读或以读为主的数据访问场景(有限的更新)
MEMORY存储引擎的特性
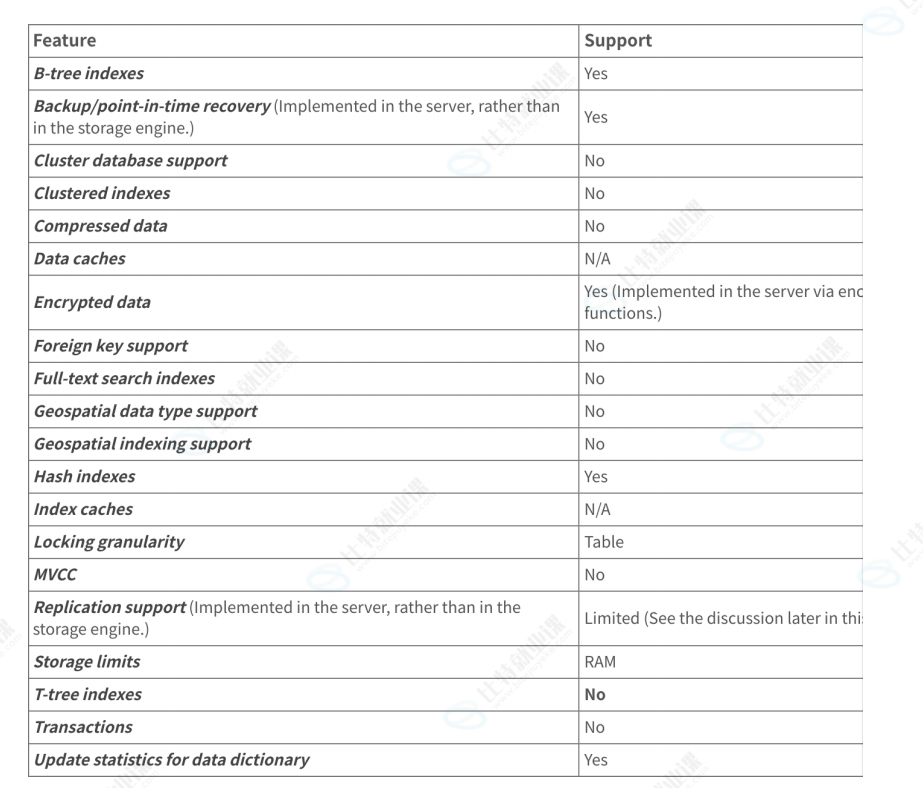
• MEMORY存储引擎统一采用静态格式,无论有没有可变长度的列,如果有可变⻓度类型,例如 VARCHAR 则使⽤固定⻓度存储,也就是取最大值分配空间
• 不能包含 BLOB 或 TEXT 列;
• ⽀持 AUTO_INCREMENT 列;
• ⾮ TEMPORARY MEMORY 表在所有客⼾端之间共享;
• ⽀持 HASH 索引(默认)和 BTREE 索引;
• 不⽀持表分区,因为表分区是在磁盘上进行的,而MEMORY存储引擎的表文件只在内存中
• 由于使⽤表级锁,在⾼负载的场景下可能会涉及严重的锁竞争,特别是在多个客⼾端并发执⾏更新操作的情况下,性能并不⼀定会⽐ InnoDB 更快。
创建MEMORY表
1、在MySQL 8.0中 InnoDB 是默认引擎,所以在创建表时需要指定 ENGINE=MEMORY

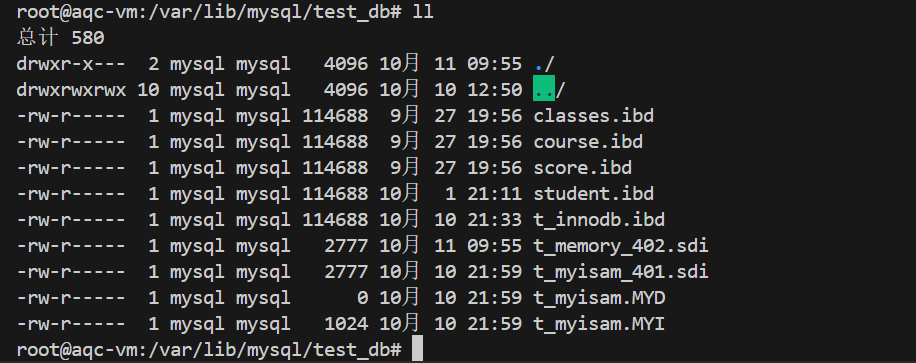
MEMORY表存储在内存上,所以数据库目录下只有表信息文件,没有数据和索引文件
内存管理
1、 删除单⾏数据,不会回收内存,只有删除整个表的数据时才会回收内存。要释放该表所使⽤的所有内存,可以执⾏ DELETE 或 TRUNCATE table 删除所有⾏,或者使⽤DROP table 删除表也行。
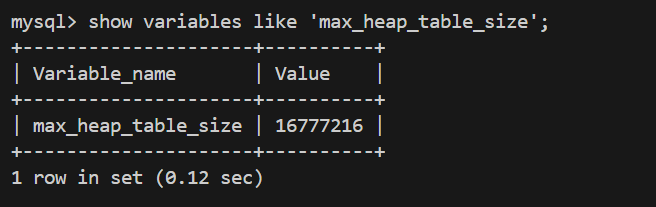
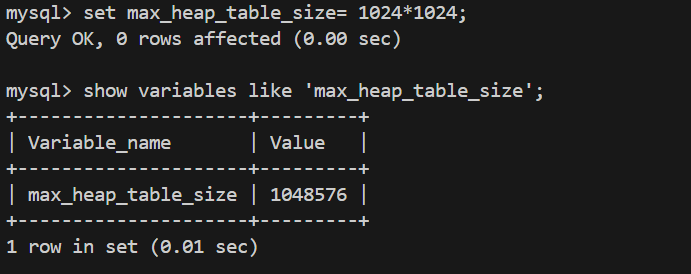
2、max_heap_table_size 系统变量设置了内存表的最⼤限制,默认为16MB,要控制单个表
的最大限制,在创建每个表之前设置该变量的 session 值。
CSV存储引擎
CSV是逗号分隔值(Comma-Separated Values)的缩写,以纯⽂本形式存储表格数据
创建CSV表
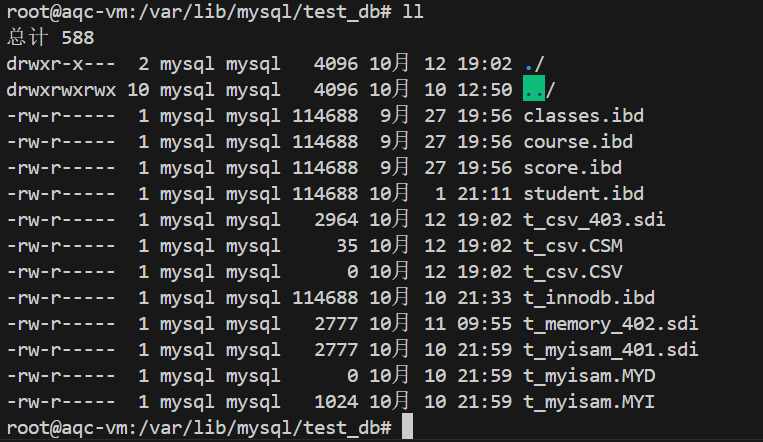
创建 CSV 表时,服务器会创建三个⽂件,其中以 .CSV 为扩展名的⽂件⽤于以逗号分隔值的格式
保存数据;扩展名为 .CSM 的⽂件,⽤于存储表的状态和表中的⾏数;以 .sdi 为后缀的表信息
描述⽂件(JSON格式)
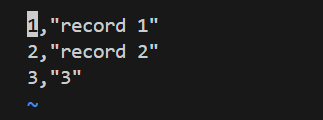
CSV表中的数据
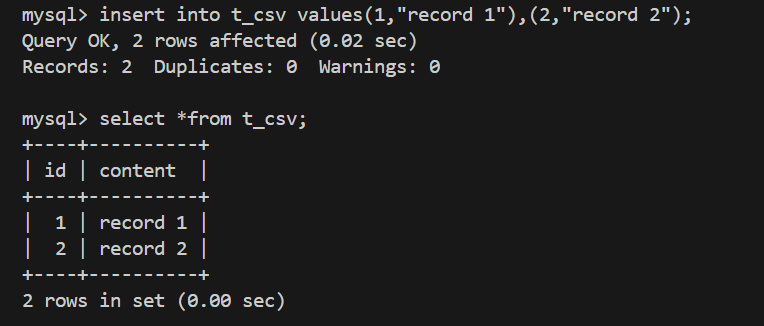
.CSV文件内容

CSV 表的修复和检查
1、CSV 存储引擎⽀持使⽤ CHECK TABLE 和 REPAIR TABLE 语句来检查或修复的 CSV表。
.CSV文件
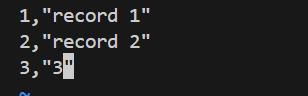
check表正确
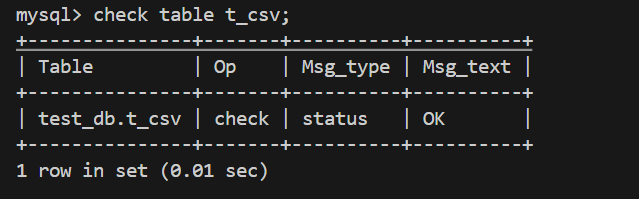
写一行错的数据
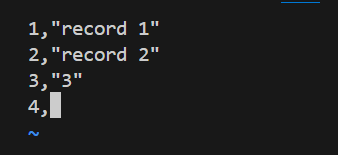
修复表
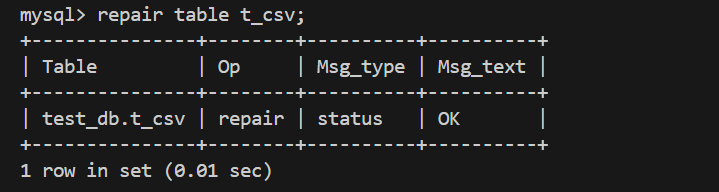
注意:
在修复表时,会将第一行出错的数据包括其后面的的数据全部删除
CSV表限制
1、CSV 存储引擎的表不⽀持索引;
2、CSV 存储引擎的表不⽀持分区;
3、使⽤ CSV 存储引擎创建的表中的所有列都必须为 NOT NULL
ARCHIVE存储引擎
使⽤ ARCHIVE 存储引擎创建的表,可存储⼤量不被索引的数据,占⽤空间很⼩,⼀般⽤于归档数据的存储
ARCHIVE存储引擎的特性
1、⽀持 INSERT , REPLACE 和 SELECT ,但不⽀持 DELETE 和 UPDATE ;
2、⽀持列的 AUTO_INCREMENT 属性,该列可以有唯⼀约束,且⼿动指定的值不能⼩于该列的最⼤值;
3、不⽀持索引,在任何列上尝试建⽴索引都会报错;
4、插⼊时,数据将被压缩, ARCHIVE 引擎使⽤ zlib ⽆损数据压缩; INSERT 语句只是将数据写
⼊压缩缓冲区并且根据需要刷新到磁盘,当执⾏ SELECT 时会强制刷新缓冲区;
5、检索时,按需要进⾏解压缩,不⽀持⾏缓存;
6、SELECT操作执⾏全表扫描,找出当前查询的⾏,并读取⾏数;
7、使⽤⾏级锁
8、不⽀持表分区
创建ARCHIVE表
创建 ARCHIVE 表会根据表名⽣成两个不同后缀名⽂件,分别是以 .ARZ 为后缀的数据⽂件,
以 .sdi 为后缀的表信息描述⽂件(JSON格式)
BLACKHOLE存储引擎
BLACKHOLE 存储引擎就像⼀个"⿊洞",接受数据,但不存储数据,检索时总是返回⼀个空结果
BLACKHOLE存储引擎的特性
• BLACKHOLE 表不会存储任何数据,但如果启⽤了基于语句的⼆进制⽇志记录,则会记录 SQL 语句并将其复制到副本服务器
• ⽀持索引;
• 不⽀持表分区;
BLACKHOLE存储引擎的⽤途
• 验证转储⽂件语法
• 通过⽐较启⽤和不启⽤⼆进制⽇志记录的性能,测量⼆进制⽇志记录的开销;
• 本质上是⼀个 "⽆操作"的存储引擎,可⽤于查找与存储引擎本⾝⽆关的性能瓶颈
创建BLACKHOLE表
创建 BLACKHOLE 表时,服务器会在全局数据字典中创建表定义并⽣成 .sdi 为后缀的表信息描
述⽂件;
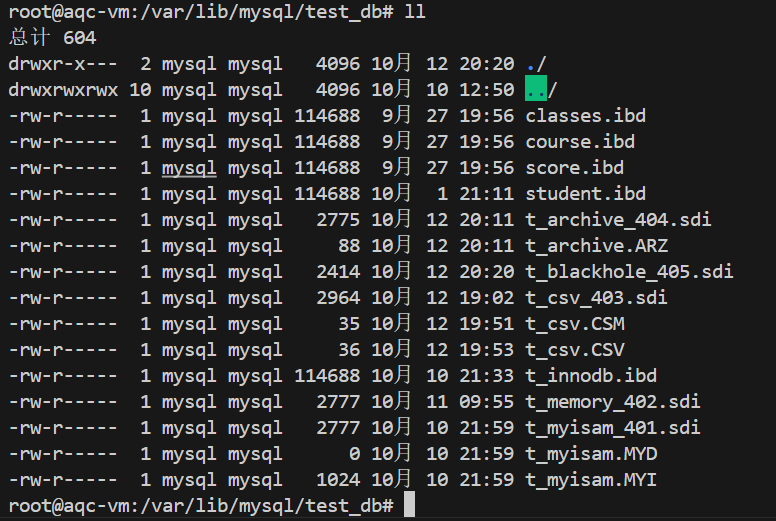
blackhole存储引擎由于并不存储数据,所以磁盘没有对应数据文件,只有表结构描述文件
创建MERGE表
MERGE存储引擎,也称为MRG_MyISAM引擎,允许在逻辑上将⼀系列结构相同的MyISAM表分组,并将它们最终作为⼀个对象引⽤。适⽤于VLDB(Very Large Data Bases)环境,如数据仓库。这⾥的结构相同表⽰所有表中的列都有相同的数据类型和索引信息。
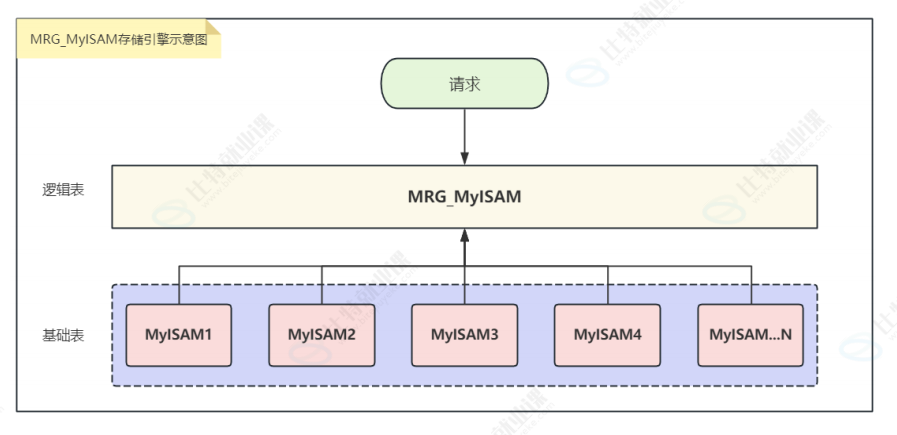
创建MERGE表
1、创建MERGE表必须指定 UNION=(list-of-tables) 选项,表⽰要使⽤哪些MyISAM表;还可
以通过指定 INSERT_METHOD 选项来控制如何对MERGE表进⾏插⼊操作, FIRST 或 LAST 值分别表⽰在第⼀个或最后⼀个基础表中进⾏插⼊,如果没有指定 INSERT_METHOD 选项,或者指定它的值为 NO ,那么在 MERGE 表中执⾏插⼊将会报错
# 创建基础表1
mysql> CREATE TABLE test_m1 (id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,content CHAR(20)) ENGINE=MyISAM;# 创建基础表2
mysql> CREATE TABLE test_m2 (id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,content CHAR(20)) ENGINE=MyISAM;# 向基础表中写⼊数据
mysql> INSERT INTO test_m1 (content) VALUES ('Testing1'),('table1'),
('test_m1');
mysql> INSERT INTO test_m2 (content) VALUES ('Testing2'),('table2'),
('test_m2');# 创建MERGE表
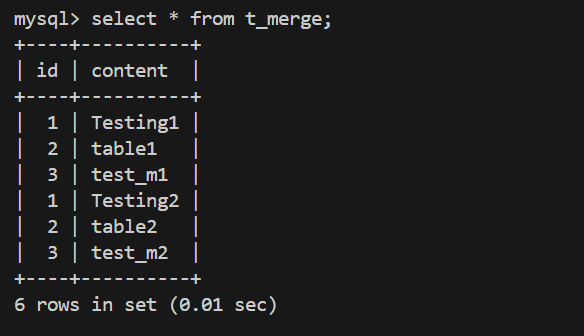
mysql> CREATE TABLE t_merge (id INT NOT NULL AUTO_INCREMENT,content CHAR(20), INDEX(id))ENGINE=MERGE UNION=(test_m1,test_m2) INSERT_METHOD=LAST;
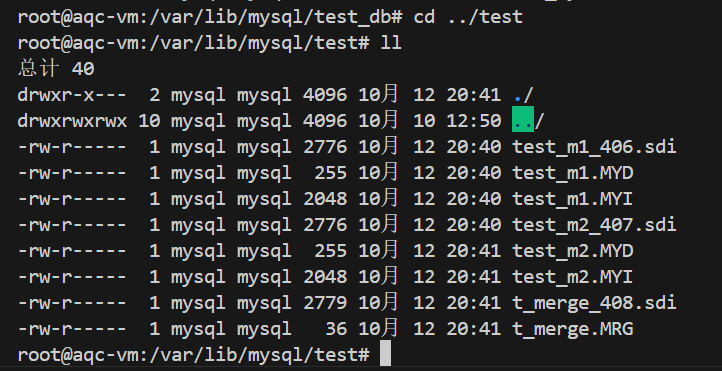
2、创建 MERGE 表时,会在磁盘上创建⼀个 .mrg ⽂件,其中包含了基础MyISAM表的名称。MERGE的表格式存储在MySQL数据字典中; .sdi 为后缀的表信息描述⽂件;

操作MERGE表
1、基础表中作为主键索引的列,并不作为整个MERGE表的主键。同样的,基础表中具有 UNIQUE 索引的列也做不了MERGE 表的UNIQUE索引
2、要将MERGE表重新作为不同的MyISAM基础表的集合,您可以使⽤以下⽅法之⼀:
◦ 删除MERGE表并重新创建;
◦ 使⽤ ALTER TABLE tbl_name UNION=(…) 修改基础表的集合;
ALTER TABLE…UNION=() 列表为空时,表⽰MERGE表为空集合
3、使⽤ DROP TABLE 只会删除MERGE表定义,基础MyISAM表不受影响。
FEDERATED 存储引擎
1、默认不⽀持,可以在启动时通过命令⾏选项 --federated 或选项⽂件的配置来启⽤
2、在不使⽤复制或集群技术的情况下, FEDERATED 存储引擎可以实现对远程MySQL数据库中数据的访问,以远端物理服务器为基础创建⼀个逻辑数据库,当查询 FEDERATED 表时,将会从远程数据库获取数据,⾮常适合分布式或数据集市环境。
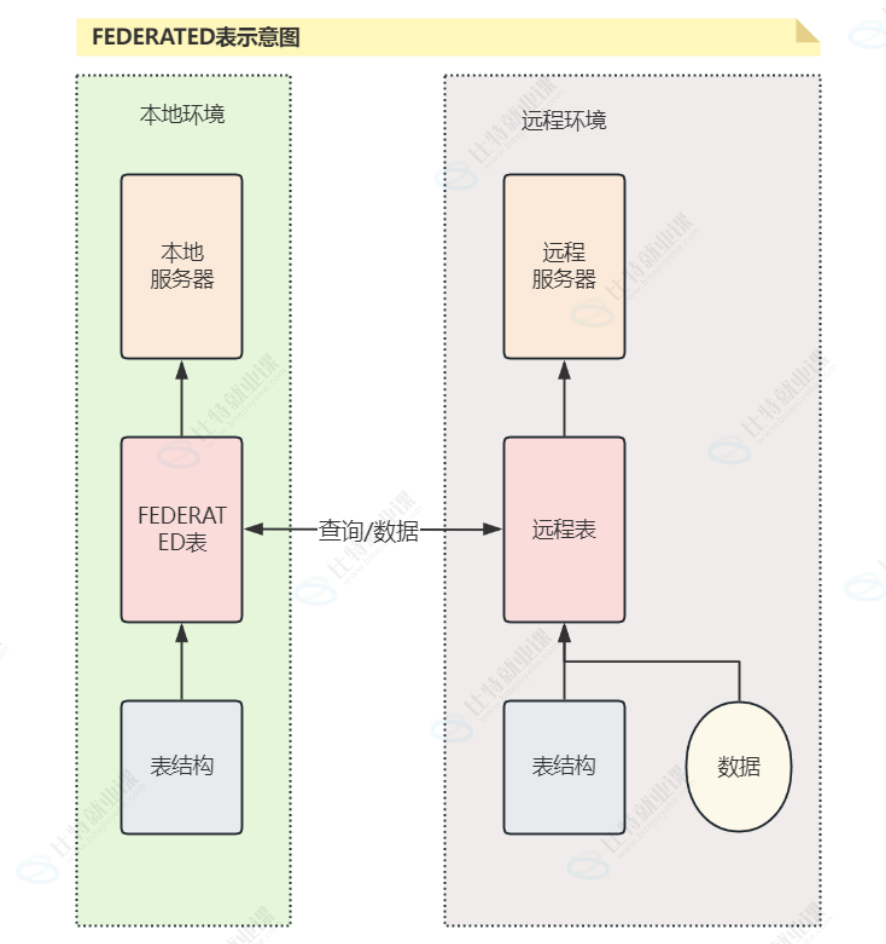
创建FEDERATED表
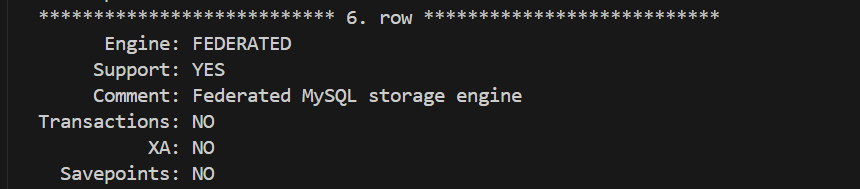
1、本地配置⽂件中的 [mysqld] 节点下加⼊ federated=1选项 来启⽤ FEDERATED 引擎,之后重启MySQL服务查看 FEDERATED 引擎是否启⽤
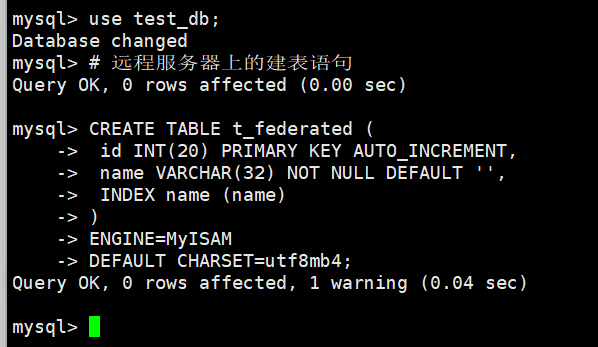
2、在ubuntu下打开FEDERATED 引擎,然后在centos下创建一个MyISAM表
centos上创建一个用户federator,并赋予所有权限给该MyISAM表


在ubuntu下创建一个federated表

# 本地服务器上的建表语句
CREATE TABLE t_federated (id INT(20) PRIMARY KEY AUTO_INCREMENT,name VARCHAR(32) NOT NULL DEFAULT '',INDEX name (name))
ENGINE=FEDERATED
DEFAULT CHARSET=utf8mb4
CONNECTION='mysql://federated:Fed123!!!@192.168.100.242:3306/test_db/t_federate
d'; # 指定远程服务器的连接--CONNECTION='mysql://fed_user@remote_host:3306/test_database/test_table';连接字符串的格式:
scheme://user_name[:password]@host_name[:port_num]/db_name/tbl_namescheme : 连接协议,⽬前只⽀持mysql;
user_name : ⽤于连接远程服务器的⽤⼾名,注意:这个⽤⼾在远程服务器已创建,并授予了相应
的操作权限;
password :⽤⼾的密码;
host_name :远程服务器的IP地址;
port_num :远程服务器MySQL服务的端⼝号;
db_name : 远程表所在的数据库名;
tbl_name :远程表名,本地表名与远程表名可以不同,但建议保持⼀致。
在centos下MyISAM表插入数据
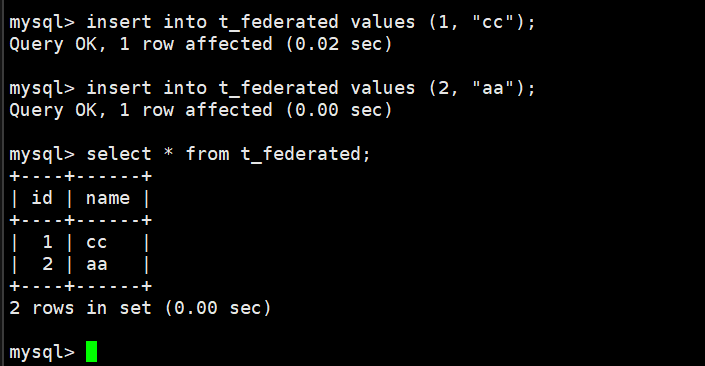
在ubuntu下federated表也可以看到
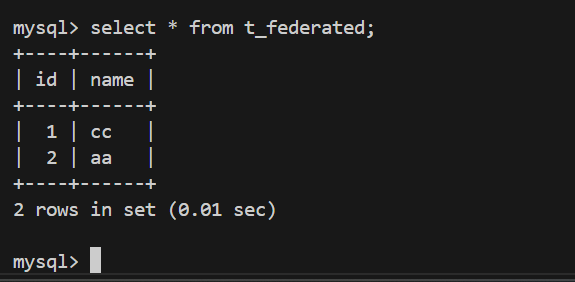
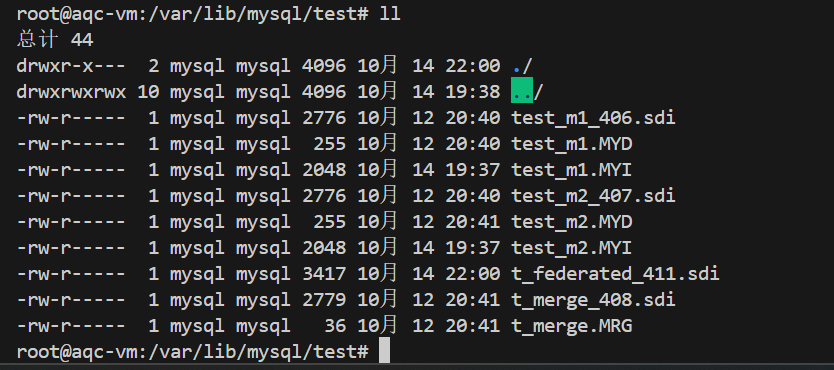
3、federated表不会有数据⽂件,表定义在数据字典中,⽣成 .sdi 为后缀的表信息描述⽂件(JSON格式)
FEDERATED表注意事项
1、远程服务器必须是MySQL服务器;
2、使⽤ CONNECTION 字符串时,密码中不能使⽤"@"字符;
3、DROP TABLE 只删除本地FEDERATED表,不删除远程表;
4、不⽀持事务
EXAMPLE 存储引擎
1、EXAMPLE 存储引擎什么也不做,它的存在⽬的是为开发⼈员说明如何开始编写⼀个新的存储引擎,是MySQL源代码中的⼀个⽰例。
2、不⽀持索引和表分区
3、当创建⼀个 EXAMPLE 表时,不会在磁盘上创建任何⽂件,表中不能存储任何数据,查询时始终返回⼀个空结果。
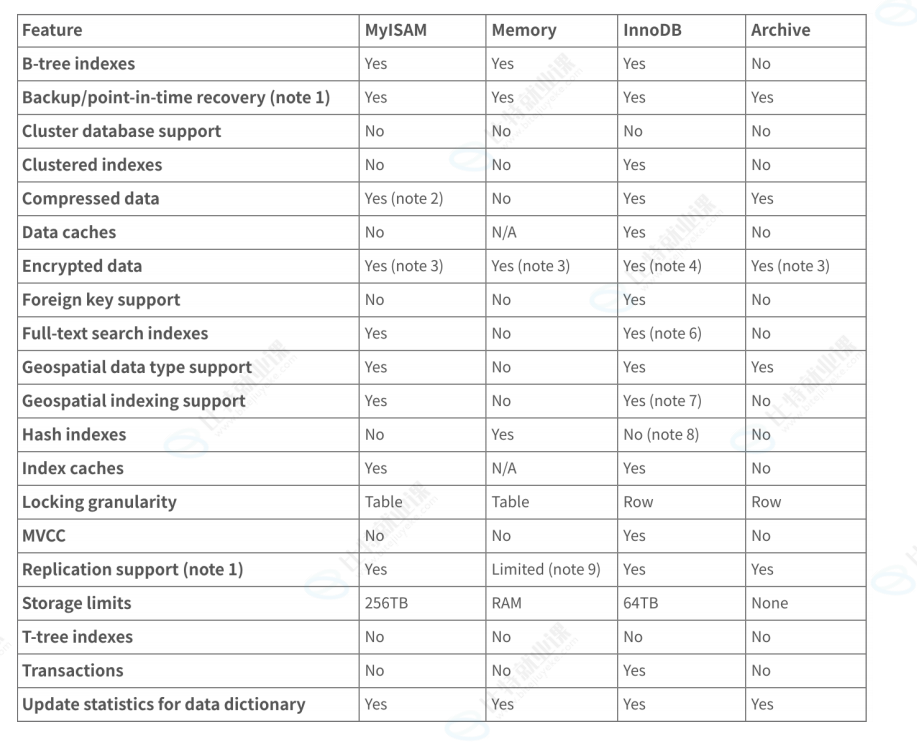
不同存储引擎的特性