热门搜索怎么做企业网站优化需要多少钱
Kafka4.0 介绍
Kafka4.0 的重大变革 —— KRaft 模式。Kafka4.0 最具革命性的变化,默认运行在 KRaft(Kafka Raft)模式下,彻底摒弃了对 Apache ZooKeeper 的依赖。KRaft 模式的引入,可谓是 Kafka 架构演进的一次重大飞跃。它基于 Raft 一致性算法构建共识机制,将元数据管理功能巧妙地集成到 Kafka 自身的体系之中,从而实现了对 ZooKeeper 的无缝替换。
主要优势:
- 简化部署与运维流程:运维人员从此无需再为搭建和维护复杂的 ZooKeeper 集群耗费大量精力,大大降低了整体的运营开销。新的架构设计极大地简化了系统的复杂性,使得 Kafka 的安装、配置以及日常管理工作变得更加直观、高效,即使是新手也能轻松上手。
- 显著增强可扩展性:在 KRaft 模式下,Kafka 集群的扩展性得到了进一步的提升。新增 Broker 节点的操作变得更加简便快捷,能够更好地适应大规模数据处理场景下,对系统资源进行动态调整的需求。无论是应对业务高峰期的数据洪峰,还是随着业务增长逐步扩展集群规模,KRaft 模式都能游刃有余。
- 提升系统性能与稳定性:去除 ZooKeeper 这一外部依赖后,Kafka 在元数据操作的响应速度和一致性方面表现得更加出色。特别是在高并发写入和读取的场景中,系统的稳定性和可靠性得到了显著增强,有效减少了因外部组件故障而可能引发的单点问题,为企业级应用提供了更加坚实可靠的底层支撑。
观测云
观测云是一款专为 IT 工程师打造的全链路可观测产品,它集成了基础设施监控、应用程序性能监控和日志管理,为整个技术栈提供实时可观察性。这款产品能够帮助工程师全面了解端到端的用户体验追踪,了解应用内函数的每一次调用,以及全面监控云时代的基础设施。此外,观测云还具备快速发现系统安全风险的能力,为数字化时代提供安全保障。
部署 DataKit
DataKit 是一个开源的、跨平台的数据收集和监控工具,由观测云开发并维护。它旨在帮助用户收集、处理和分析各种数据源,如日志、指标和事件,以便进行有效的监控和故障排查。DataKit 支持多种数据输入和输出格式,可以轻松集成到现有的监控系统中。
登录观测云控制台,在「集成」 - 「DataKit」选择对应安装方式,当前采用 Linux 主机部署 DataKit。
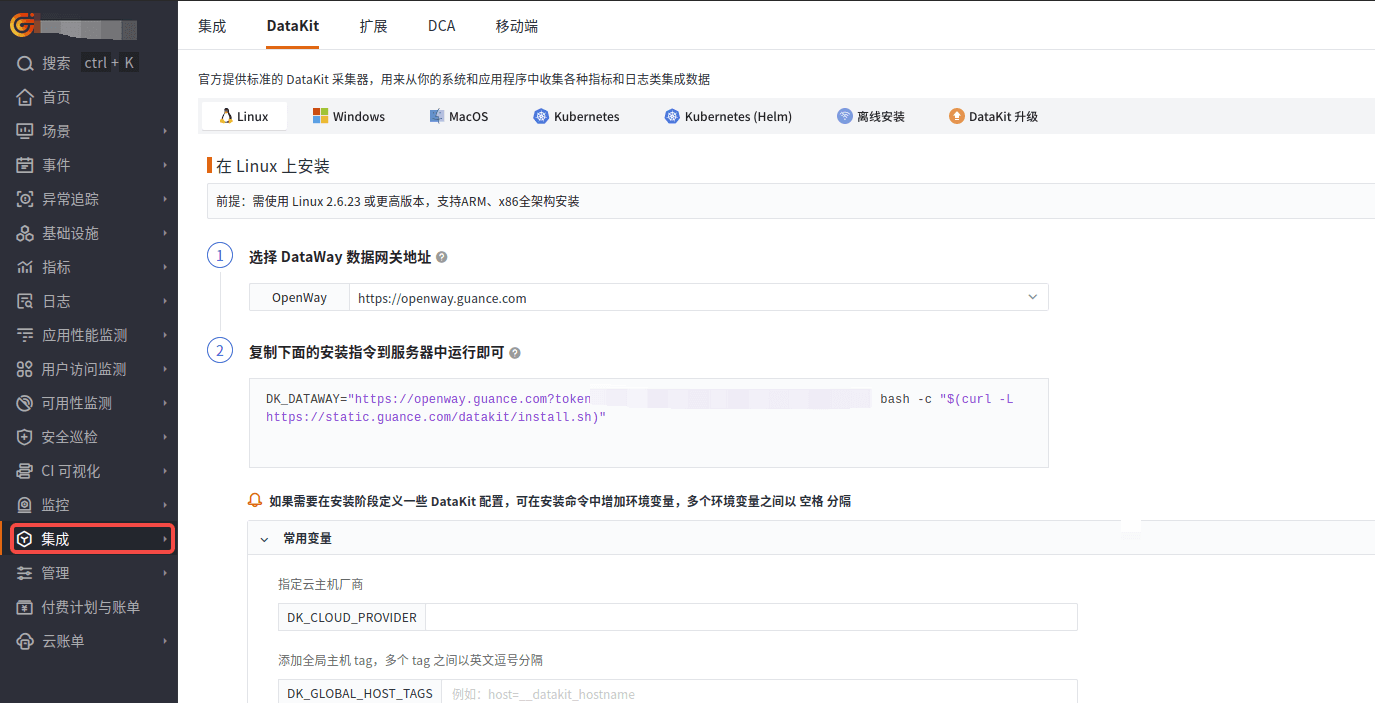
采集步骤
下载 JMX Exporter
下载地址:https://github.com/prometheus/jmx_exporter/releases/tag/1.3.0
配置 JMX 脚本和启动参数
注意:采集 Producer、Consumer、Streams、Connect 指标需要开各自独立进程,启动各自进程时注意替换对应的 yaml 文件和对应的启动脚本,如下可参考。
KRaft Metrics
- 创建 KRaft Metrics 配置文件
kafka.yml
# ------------------------------------------------------------
# Kafka 4 Prometheus JMX Exporter Configuration
# ------------------------------------------------------------
lowercaseOutputName: false
lowercaseOutputLabelNames: true
cacheRules: true
rules:# 1. Broker / Topic / Partition Metrics- pattern: kafka.server<type=BrokerTopicMetrics, name=(BytesInPerSec|BytesOutPerSec|MessagesInPerSec|TotalFetchRequestsPerSec|ProduceRequestsPerSec|FailedProduceRequestsPerSec|TotalProduceRequestsPerSec|ReassignmentBytesInPerSec|ReassignmentBytesOutPerSec|ProduceMessageConversionsPerSec|FetchMessageConversionsPerSec)(?:, topic=([-\.\w]*))?><>(Count|OneMinuteRate|FiveMinuteRate|FifteenMinuteRate|MeanRate)name: kafka_server_broker_topic_metrics_$1type: GAUGElabels:topic: "$2"# 2. Request / Network Metrics- pattern: kafka.network<type=RequestMetrics, name=(.+)><>(Count|OneMinuteRate|FiveMinuteRate|FifteenMinuteRate|MeanRate)name: kafka_network_request_metrics_$1type: GAUGE# 3. Socket Server Metrics- pattern: kafka.network<type=SocketServer, name=(.+)><>(Count|OneMinuteRate|FiveMinuteRate|FifteenMinuteRate|MeanRate|Value)name: kafka_network_socket_server_metrics_$1type: GAUGE# 4. Log / Segment / Cleaner Metrics- pattern: kafka.log<type=LogFlushStats, name=(.+)><>(Count|OneMinuteRate|FiveMinuteRate|FifteenMinuteRate|MeanRate)name: kafka_log_$1_$2type: GAUGE# 5. Controller (KRaft) Metrics- pattern: kafka.controller<type=KafkaController, name=(.+)><>(Count|Value)name: kafka_controller_$1type: GAUGE# 6. Group / Coordinator Metrics- pattern: kafka.coordinator.group<type=GroupMetadataManager, name=(.+)><>(Count|Value)name: kafka_coordinator_group_metadata_manager_$1type: GAUGE# 7. KRaft Specific Metrics- pattern: kafka.controller<type=KafkaController, name=(LeaderElectionSuccessRate|LeaderElectionLatencyMs)><>(Count|Value)name: kafka_controller_$1type: GAUGE# 8. New Generation Consumer Rebalance Protocol Metrics- pattern: kafka.coordinator.group<type=GroupMetadataManager, name=(RebalanceTimeMs|RebalanceFrequency)><>(Count|Value)name: kafka_coordinator_group_metadata_manager_$1type: GAUGE# 9. Queue Metrics- pattern: kafka.server<type=Queue, name=(QueueSize|QueueConsumerRate)><>(Count|Value)name: kafka_server_queue_$1type: GAUGE# 10. Client Metrics- pattern: kafka.network<type=RequestMetrics, name=(ClientConnections|ClientRequestRate|ClientResponseTime)><>(Count|OneMinuteRate|FiveMinuteRate|FifteenMinuteRate|MeanRate)name: kafka_network_request_metrics_$1type: GAUGE# 11. Log Flush Rate and Time- pattern: kafka.log<type=LogFlushStats, name=LogFlushRateAndTimeMs><>(Count|OneMinuteRate|FiveMinuteRate|FifteenMinuteRate|MeanRate)name: kafka_log_log_flush_rate_and_time_mstype: GAUGE
- 启动参数
export KAFKA_HEAP_OPTS="-Xms1g -Xmx1g"
export KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote.port=9999 \-Dcom.sun.management.jmxremote.rmi.port=9999 \-Dcom.sun.management.jmxremote.authenticate=false \-Dcom.sun.management.jmxremote.ssl=false \-Djava.rmi.server.hostname=127.0.0.1"
export Environment="KAFKA_OPTS=-javaagent:/opt/jmx_exporter/jmx_prometheus_javaagent.jar=7071:/opt/jmx_exporter/kafka.yml"/opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/kraft/server.properties
Producer Metrics
- 创建 Procucer Metrics 配置文件
producer.yml
---
lowercaseOutputName: true
rules:# 新增:producer-node-metrics- pattern: kafka\.producer<type=producer-node-metrics, client-id=([^,]+), node-id=([^>]+)><>([^:]+)name: kafka_producer_node_$3labels:client_id: "$1"node_id: "$2"type: GAUGE- pattern: 'kafka\.producer<type=producer-metrics, client-id=([^>]+)><>([^:,\s]+).*'name: 'kafka_producer_metrics_$2'labels:client_id: "$1"type: GAUGE# 抓取 Selector 全部指标(Kafka 4.0 新增)- pattern: 'kafka\.(?:(producer|consumer|connect))<type=(producer|consumer|connect)-metrics, client-id=([^>]+)><>(connection-.+|io-.+|network-.+|select-.+|send-.+|receive-.+|reauthentication-.+)'name: 'kafka_${1}_${4}'labels:client_id: '$3'type: GAUGE
- 启动参数
export Environment="KAFKA_OPTS=-javaagent:/opt/jmx_exporter/jmx_prometheus_javaagent.jar=7072:/opt/jmx_exporter/producer.yml"/opt/kafka/kafka/bin/kafka-console-producer.sh \--broker-list localhost:9092 \--topic xxxx \--producer-property bootstrap.servers=localhost:9092
Consumer Metrics
- 创建 Consumer Metrics 配置文件
consumer.yml
lowercaseOutputName: true
rules:# consumer-coordinator-metrics- pattern: 'kafka\.consumer<type=consumer-coordinator-metrics, client-id=([^>]+)><>([^:,\s]+).*'name: 'kafka_consumer_coordinator_metrics_$2'labels:client_id: "$1"type: GAUGE- pattern: 'kafka\.consumer<type=consumer-metrics, client-id=([^>]+)><>([^:,\s]+).*'name: 'kafka_consumer_metrics_$2'labels:client_id: "$1"
- 启动参数
export Environment="KAFKA_OPTS=-javaagent:/opt/jmx_exporter/jmx_prometheus_javaagent.jar=7073:/opt/jmx_exporter/consumer.yml"/opt/kafka/kafka/bin/kafka-console-consumer.sh \--broker-list localhost:9092 \--topic xxxx \--producer-property bootstrap.servers=localhost:9092
Streams Metrics
- 创建 Streams Metrics 配置文件
stream.yml
lowercaseOutputName: true
lowercaseOutputLabelNames: truerules:# Kafka Streams 应用指标 - 移除特殊字符- pattern: 'kafka.streams<type=stream-metrics, client-id=(.+)><>([a-zA-Z0-9\-]+)$'name: kafka_streams_$2labels:client_id: "$1"# 处理包含特殊字符的属性名- pattern: 'kafka.streams<type=stream-metrics, client-id=(.+)><>([a-zA-Z0-9\-]+):(.+)$'name: kafka_streams_$2_$3labels:client_id: "$1"# Processor Node 指标- pattern: 'kafka.streams<type=stream-processor-node-metrics, client-id=(.+), task-id=(.+), processor-node-id=(.+)><>(.+)'name: kafka_streams_processor_$4labels:client_id: "$1"task_id: "$2"processor_node_id: "$3"# Task 指标- pattern: 'kafka.streams<type=stream-task-metrics, client-id=(.+), task-id=(.+)><>(.+)'name: kafka_streams_task_$3labels:client_id: "$1"task_id: "$2"# 线程指标- pattern: 'kafka.streams<type=stream-thread-metrics, client-id=(.+), thread-id=(.+)><>(.+)'name: kafka_streams_thread_$3labels:client_id: "$1"thread_id: "$2"# JVM 指标- pattern: 'java.lang<type=Memory><>(.+)'name: jvm_memory_$1- pattern: 'java.lang<type=GarbageCollector, name=(.+)><>(\w+)'name: jvm_gc_$2labels:gc: "$1"# 线程池指标- pattern: 'java.lang<type=Threading><>(.+)'name: jvm_threads_$1# 默认规则- pattern: '(.*)'
- 启动参数
export KAFKA_HEAP_OPTS="-Xms512m -Xmx512m"
export KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote.port=9996 \-Dcom.sun.management.jmxremote.rmi.port=9996 \-Dcom.sun.management.jmxremote.authenticate=false \-Dcom.sun.management.jmxremote.ssl=false \-Djava.rmi.server.hostname=127.0.0.1"
export Environment="KAFKA_OPTS=-javaagent:/opt/jmx_exporter/jmx_prometheus_javaagent.jar=7075:/opt/jmx_exporter/stream.yml"java $KAFKA_HEAP_OPTS $KAFKA_JMX_OPTS $EXTRA_ARGS -cp "libs/*:my-streams.jar" WordCountDemo
Connect Metrics
- 创建 Connect Metrics 配置文件
connect.yml
lowercaseOutputName: true
lowercaseOutputLabelNames: true
rules:# 1) connect-worker-metrics(全局)- pattern: 'kafka\.connect<type=connect-worker-metrics><>([^:]+)'name: 'kafka_connect_worker_$1'type: GAUGE# 2) connect-worker-metrics,connector=xxx- pattern: 'kafka\.connect<type=connect-worker-metrics, connector=([^>]+)><>([^:]+)'name: 'kafka_connect_worker_$2'labels:connector: "$1"type: GAUGE# 3) connect-worker-rebalance-metrics- pattern: 'kafka\.connect<type=connect-worker-rebalance-metrics><>([^:]+)'name: 'kafka_connect_worker_rebalance_$1'type: GAUGE# 4) connector-task-metrics- pattern: 'kafka\.connect<type=connector-task-metrics, connector=([^>]+), task=([^>]+)><>([^:]+)'name: 'kafka_connect_task_$3'labels:connector: "$1"task_id: "$2"type: GAUGE# 5) sink-task-metrics- pattern: 'kafka\.connect<type=sink-task-metrics, connector=([^>]+), task=([^>]+)><>([^:]+)'name: 'kafka_connect_sink_task_$3'labels:connector: "$1"task_id: "$2"
- 启动参数
export KAFKA_HEAP_OPTS="-Xms512m -Xmx512m"
export KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote \-Dcom.sun.management.jmxremote.authenticate=false \-Dcom.sun.management.jmxremote.ssl=false \-Dcom.sun.management.jmxremote.port=9995 \-Dcom.sun.management.jmxremote.rmi.port=9995 \-Djava.rmi.server.hostname=127.0.0.1"
export Environment="KAFKA_OPTS=-javaagent:/opt/jmx_exporter/jmx_prometheus_javaagent.jar=7074:/opt/jmx_exporter/connect.yml"# 启动 Kafka Connect
/opt/kafka/kafka/bin/connect-distributed.sh /opt/kafka/kafka/config/connect-distributed.properties
启动成功后,可通过 curl http://IP:端口号/metrics 查看获取到的监控数据。
配置 DataKit
- 进入 datakit 安装目录下的
conf.d/prom目录,复制prom.conf.sample并命名为kafka.conf
cp prom.conf.sample kafka.conf
- 调整
kafka.conf
[[inputs.prom]]## Exporter URLs.urls = ["http://127.0.0.1:7071/metrics","http://127.0.0.1:7072/metrics","http://127.0.0.1:7073/metrics","http://127.0.0.1:7074/metrics","http://127.0.0.1:7075/metrics"]## Collector alias.source = "kafka"## Prioritier over 'measurement_name' configuration.[[inputs.prom.measurements]]prefix = "kafka_controller_"name = "kafka_controller"[[inputs.prom.measurements]]prefix = "kafka_network_"name = "kafka_network"[[inputs.prom.measurements]]prefix = "kafka_log_"name = "kafka_log"[[inputs.prom.measurements]]prefix = "kafka_server_"name = "kafka_server"[[inputs.prom.measurements]]prefix = "kafka_connect_"name = "kafka_connect"[[inputs.prom.measurements]]prefix = "kafka_stream_"name = "kafka_stream"
重启 DataKit
执行以下命令:
datakit service -R
指标集
以下是 kafka4.0 部分指标说明,更多指标可参考 Kafka 指标详情。
kafka_server指标集
| 指标名 | 描述 | 单位 |
|---|---|---|
Fetch_queue_size | 当前活跃的 Broker 数量 | Count |
Produce_queue_size | 当前活跃的 Broker 数量 | Count |
Request_queue_size | 当前活跃的 Broker 数量 | Count |
broker_topic_metrics_BytesInPerSec | 当前活跃的 Broker 数量 | Count |
broker_topic_metrics_BytesOutPerSec | 当前活跃的 Broker 数量 | Count |
broker_topic_metrics_FailedProduceRequestsPerSec | 当前活跃的 Broker 数量 | Count |
broker_topic_metrics_FetchMessageConversionsPerSec | 当前活跃的 Broker 数量 | Count |
broker_topic_metrics_MessagesInPerSec | 当前活跃的 Broker 数量 | Count |
broker_topic_metrics_ProduceMessageConversionsPerSec | 当前活跃的 Broker 数量 | Count |
broker_topic_metrics_TotalFetchRequestsPerSec | 当前活跃的 Broker 数量 | Count |
broker_topic_metrics_TotalProduceRequestsPerSec | 当前活跃的 Broker 数量 | Count |
socket_server_metrics_connection_count | 当前活跃的 Broker 数量 | Count |
socket_server_metrics_connection_close_total | 当前活跃的 Broker 数量 | Count |
socket_server_metrics_incoming_byte_rate | 当前活跃的 Broker 数量 | Count |
kafka_network 指标集
| 指标名 | 描述 | 单位 |
|---|---|---|
request_metrics_RequestBytes_request_AddOffsetsToTxn | AddOffsetsToTxn 请求大小 | bytes |
| request_metrics_RequestBytes_request_Fetch | Fetch 请求大小 | count |
| request_metrics_RequestBytes_request_FetchConsumer | FetchConsumer 请求大小 | bytes |
| request_metrics_RequestBytes_request_FetchFollower | FetchFollower 请求大小 | bytes |
| request_metrics_TotalTimeMs_request_CreateTopics | CreateTopics 请求总时间 | ms |
| request_metrics_TotalTimeMs_request_CreatePartitions | CreatePartitions 请求总时间 | ms |
| request_metrics_RequestQueueTimeMs_request_CreatePartitions | CreatePartitions 在请求对列等待时间 | ms |
| request_metrics_RequestQueueTimeMs_request_Produce | Produce 在请求对列的等待时间 | ms |
kafka_controller 指标集
| 指标名 | 描述 | 单位 |
|---|---|---|
ActiveBrokerCount | 当前活跃的 Broker 数量 | Count |
ActiveControllerCount | 活跃控制器数量 | Count |
GlobalPartitionCount | 分区数量 | Count |
GlobalTopicCount | 主题数量 | Count |
IgnoredStaticVoters | bytes | Kong的带宽使用量,单位为字节 |
OfflinePartitionsCount | 离线分区数量 | Count |
PreferredReplicaImbalanceCount | Preferred Leader 选举条件的分区数 | Count |
TimedOutBrokerHeartbeatCount | Broker 心跳超时的次数 | Count |
kafka_producer 指标集
| 指标名 | 描述 | 单位 |
|---|---|---|
producer_metrics_batch_split_rate | 批次分割率 | count/s |
producer_metrics_buffer_available_bytes | 未使用的缓冲区内存总量 | bytes |
producer_metrics_buffer_exhausted_rate | 缓冲区耗尽而丢弃的每秒平均记录发送数量 | count/s |
producer_metrics_buffer_total_bytes | 缓冲区总字节大小 | bytes |
producer_metrics_bufferpool_wait_ratio | 缓冲池等待比率 | % |
producer_metrics_bufferpool_wait_time_ns_total | 缓冲池等待时间 | ms |
producer_metrics_connection_close_rate | 关闭连接率 | count/s |
producer_metrics_connection_count | 关闭连接数量 | count |
kafka_consumer 指标集
| 指标名 | 描述 | 单位 |
|---|---|---|
consumer_coordinator_metrics_failed_rebalance_total | 再平衡失败数量 | count |
consumer_coordinator_metrics_heartbeat_rate | 每秒平均心跳次数 | count/s |
consumer_coordinator_metrics_heartbeat_response_time_max | 心跳响应最大时间 | count |
consumer_coordinator_metrics_join_rate | Group 每秒加入速率 | count/s |
consumer_coordinator_metrics_join_total | Group 加入总数 | count |
consumer_coordinator_metrics_last_rebalance_seconds_ago | 自上次重新平衡事件以来的秒数 | ms |
consumer_coordinator_metrics_rebalance_latency_total | 重新平衡延迟总计 | ms |
consumer_fetch_manager_metrics_bytes_consumed_rate | 每秒消耗的字节数 | bytes/s |
consumer_fetch_manager_metrics_fetch_latency_avg | Fetch 请求延迟 | ms |
consumer_metrics_connection_count | 连接数 | count |
consumer_metrics_incoming_byte_rate | 输入字节数率 | bytes/s |
kafka_connect 指标集
| 指标名 | 描述 | 单位 |
|---|---|---|
worker_connector_count | Connector 数量 | count |
worker_task_startup_attempts_total | 任务启动重试次数 | count |
worker_connector_startup_attempts_total | 连接器尝试启动次数 | count |
worker_task_startup_failure_total | 任务启动失败数量 | count |
worker_connector_startup_failure_percentage | 连接失败率 | % |
worker_rebalance_completed_rebalances_total | 再平衡完成总数 | count |
worker_task_startup_failure_percentage | 任务启动失败占比 | % |
worker_rebalance_time_since_last_rebalance_ms | 自上次重新平衡以来的时间 | ms |
| worker_task_startup_attempts_total | 任务尝试启动次数 | count |
kafka_stream 指标集
| 指标名 | 描述 | 单位 |
|---|---|---|
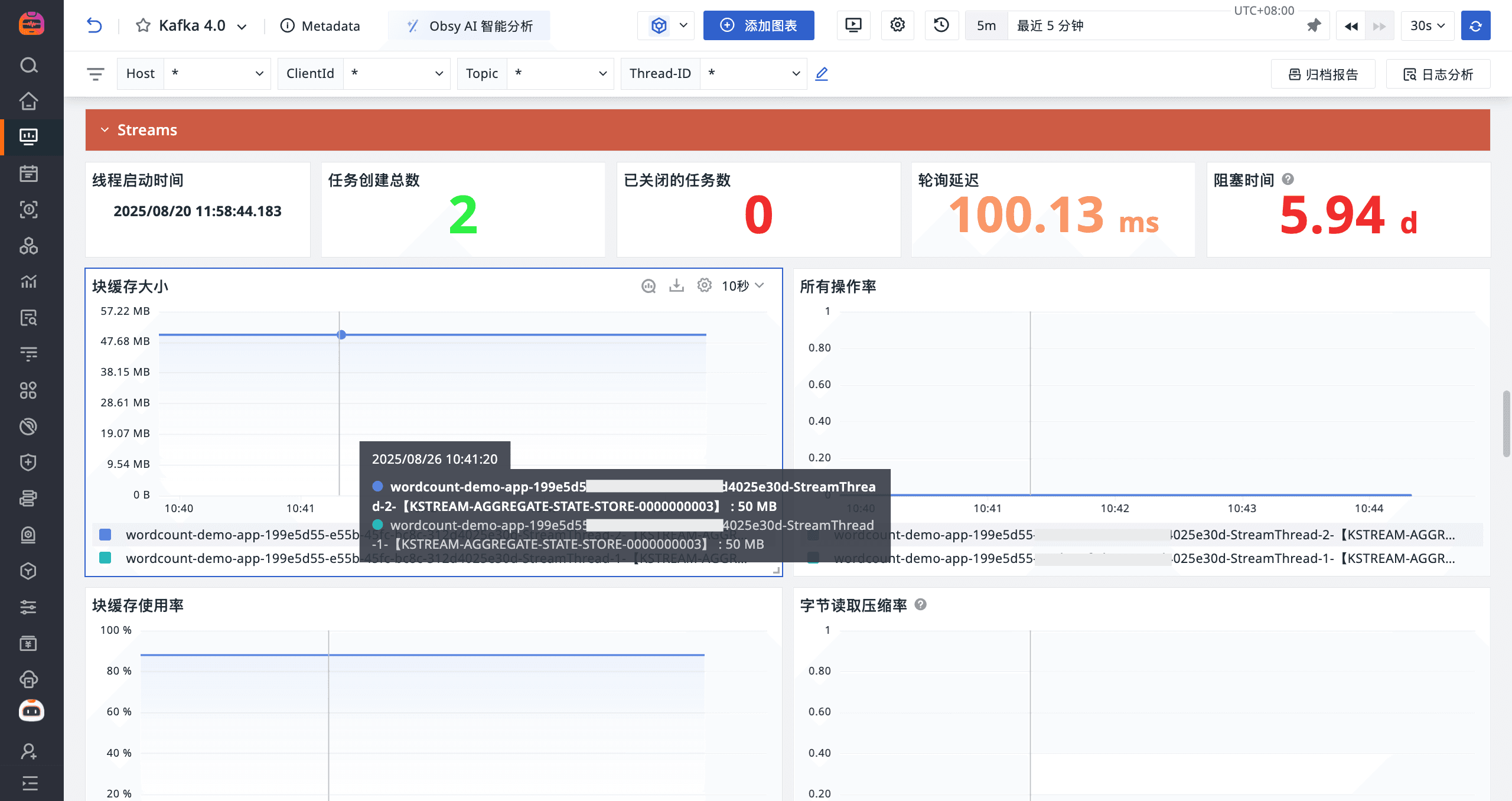
stream_thread_metrics_thread_start_time | 线程启动时间 | 时间戳 ms |
stream_thread_metrics_task_created_total | 任务创建总数 | count |
stream_state_metrics_block_cache_capacity | 块缓存大小 | bytes |
stream_state_metrics_all_rate | 所有操作率 | count/s |
stream_state_metrics_block_cache_usage | 块缓存使用率 | % |
stream_state_metrics_bytes_read_compaction_rate | 字节读取压缩率 | bytes/s |
stream_state_metrics_bytes_written_compaction_rate | 字节写入压缩率 | bytes/s |
stream_state_metrics_block_cache_index_hit_ratio | 块缓存索引命中率 | % |
stream_state_metrics_block_cache_data_hit_ratio | 块缓存数据命中率 | % |
场景视图
登录观测云控制台,点击「场景」 -「新建仪表板」,输入 “Kafka 4”, 选择 “Kafka 4”,点击 “确定” 即可添加视图。
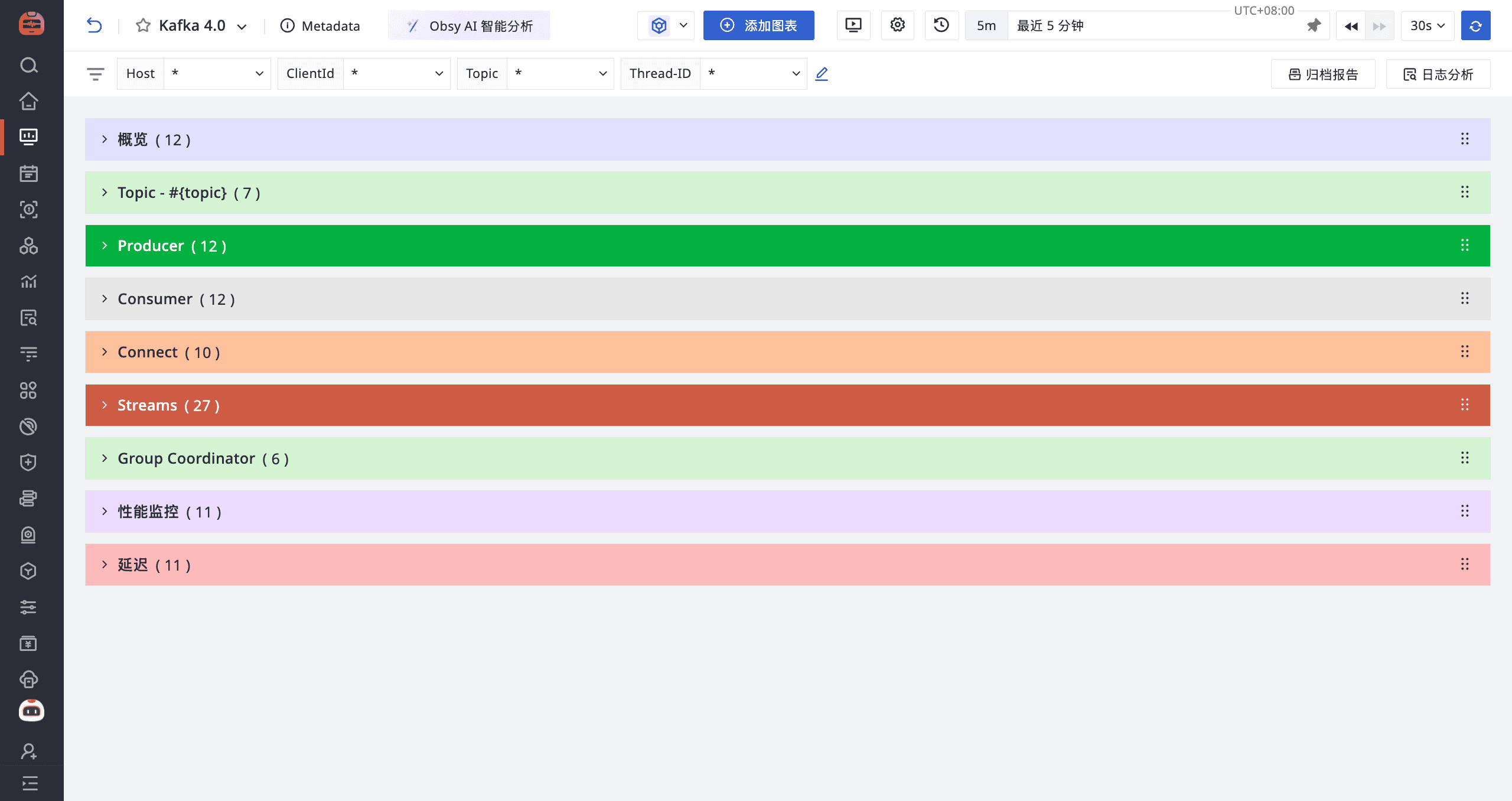
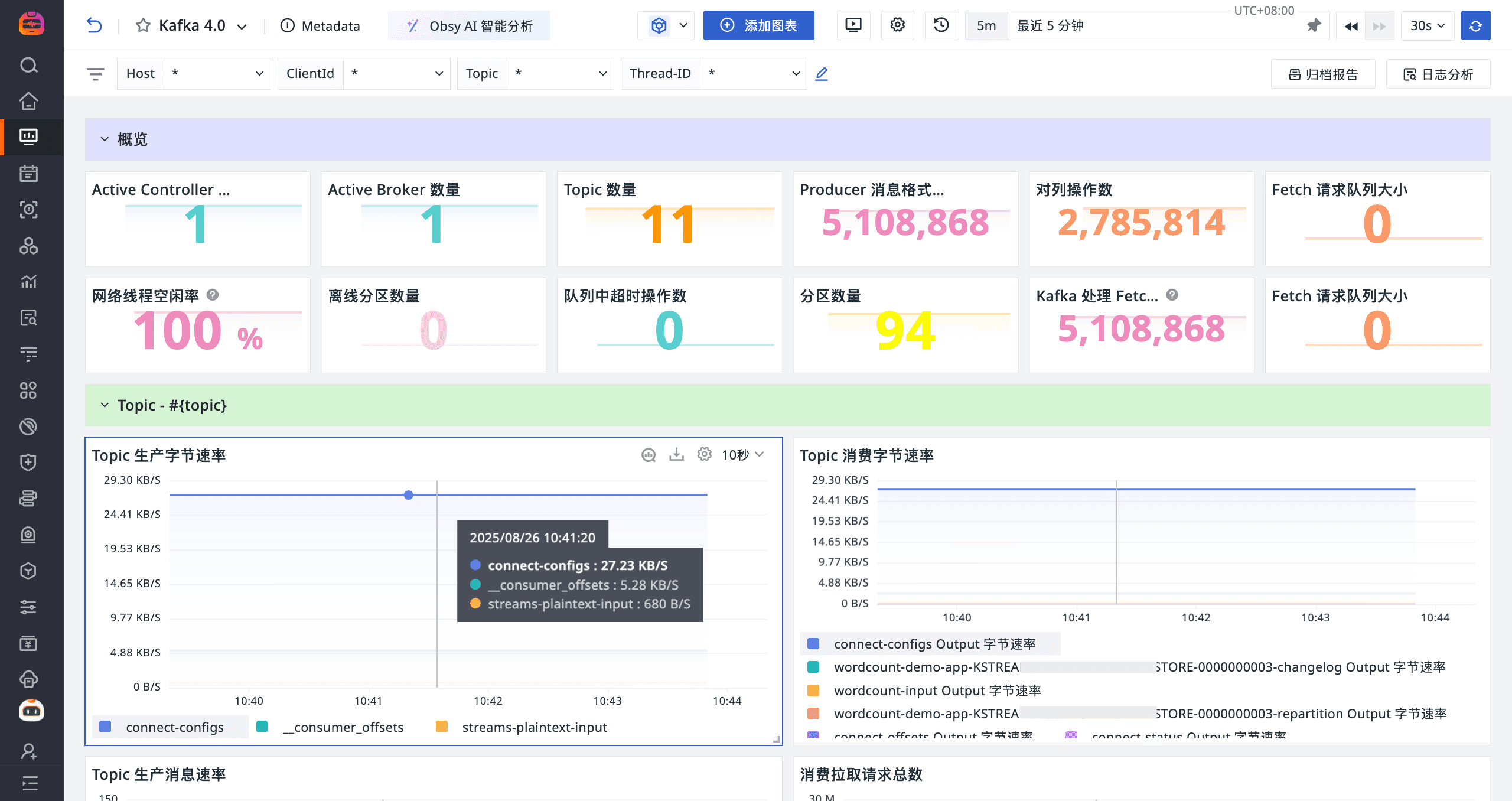
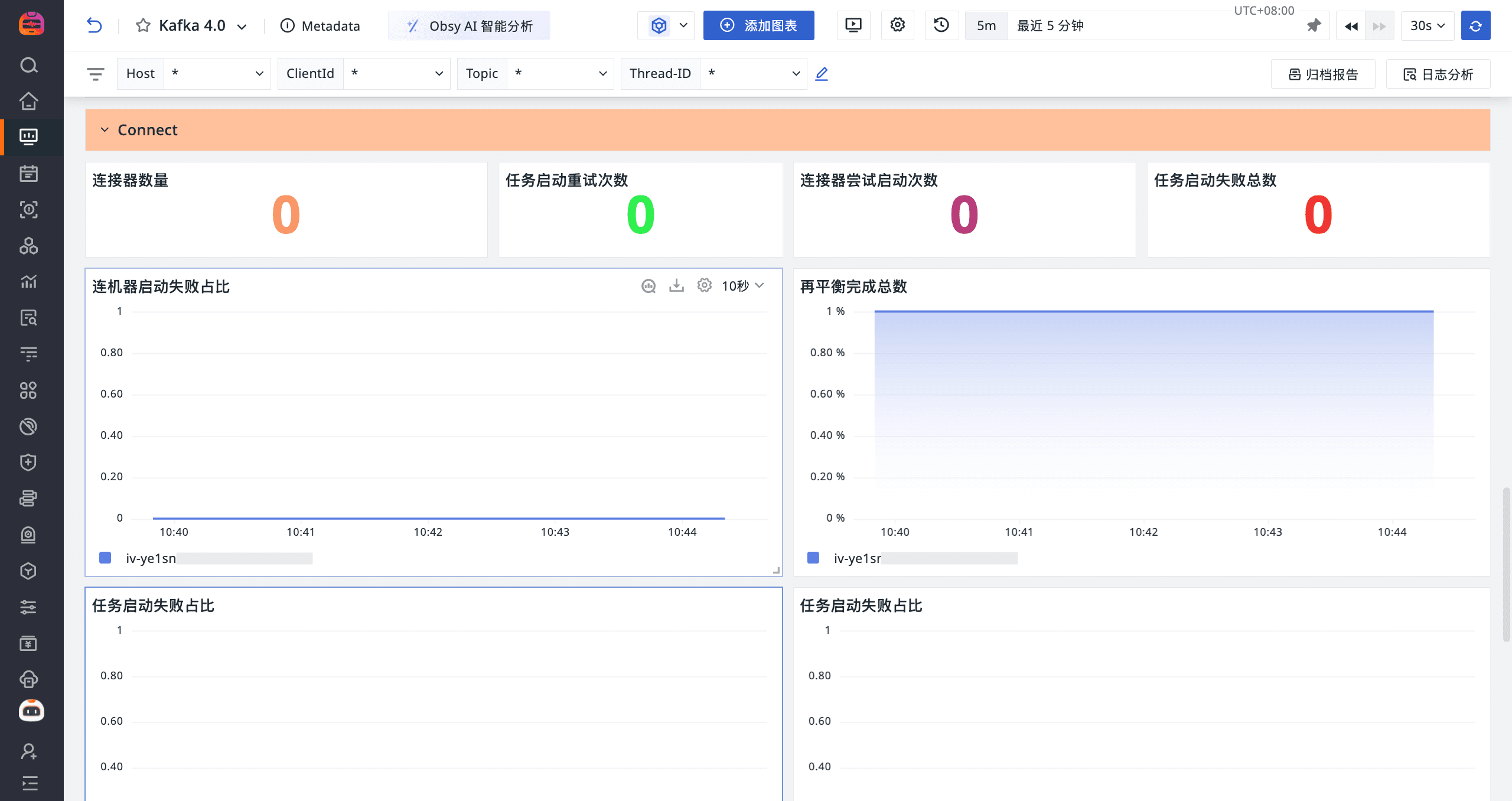
监控器(告警)
登录观测云控制台,点击「监控」 -「新建监控器」,输入 “kafka”, 选择对应的监控器,点击 “确定” 即可添加。
Kafka 连接过期被关闭客户端连接
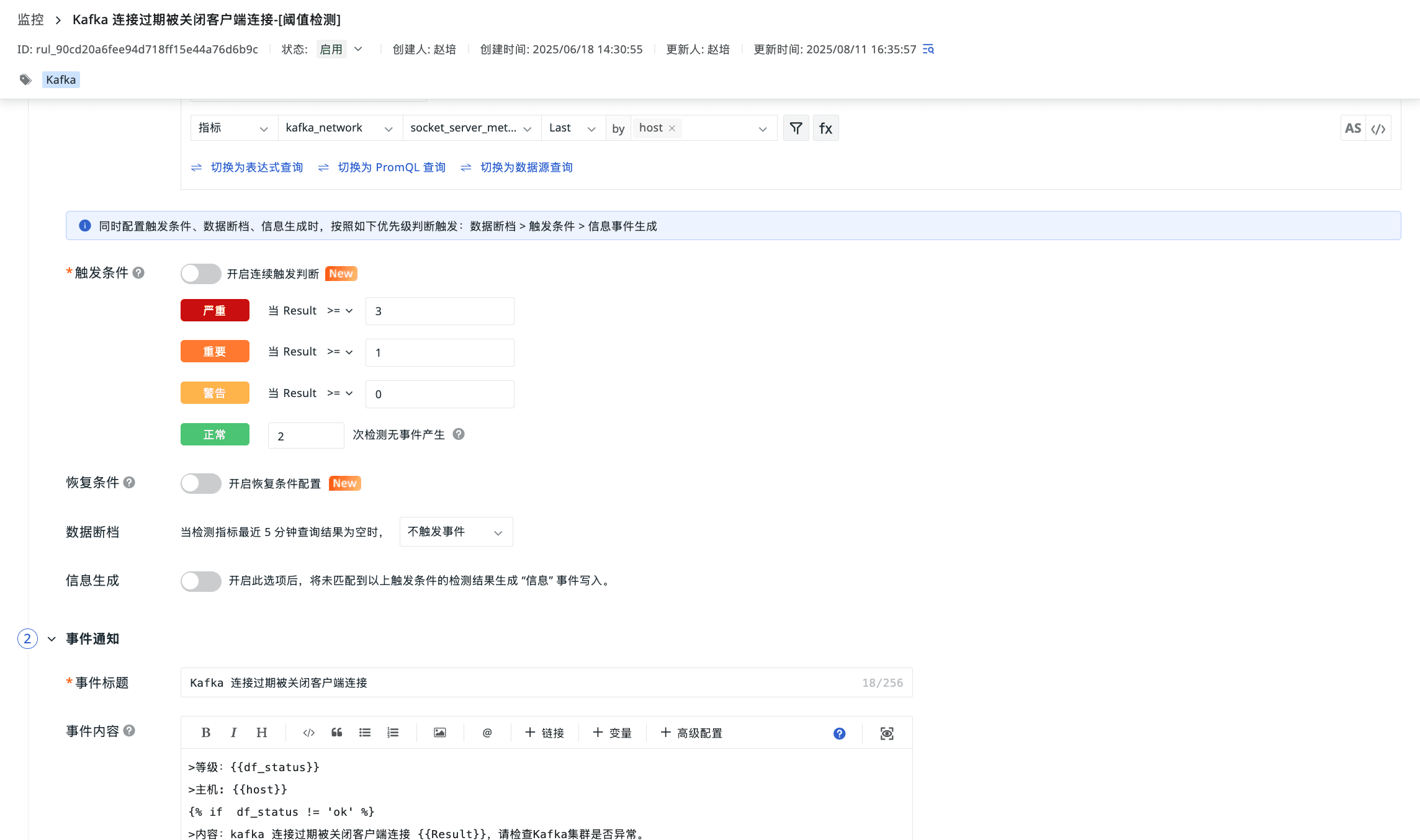
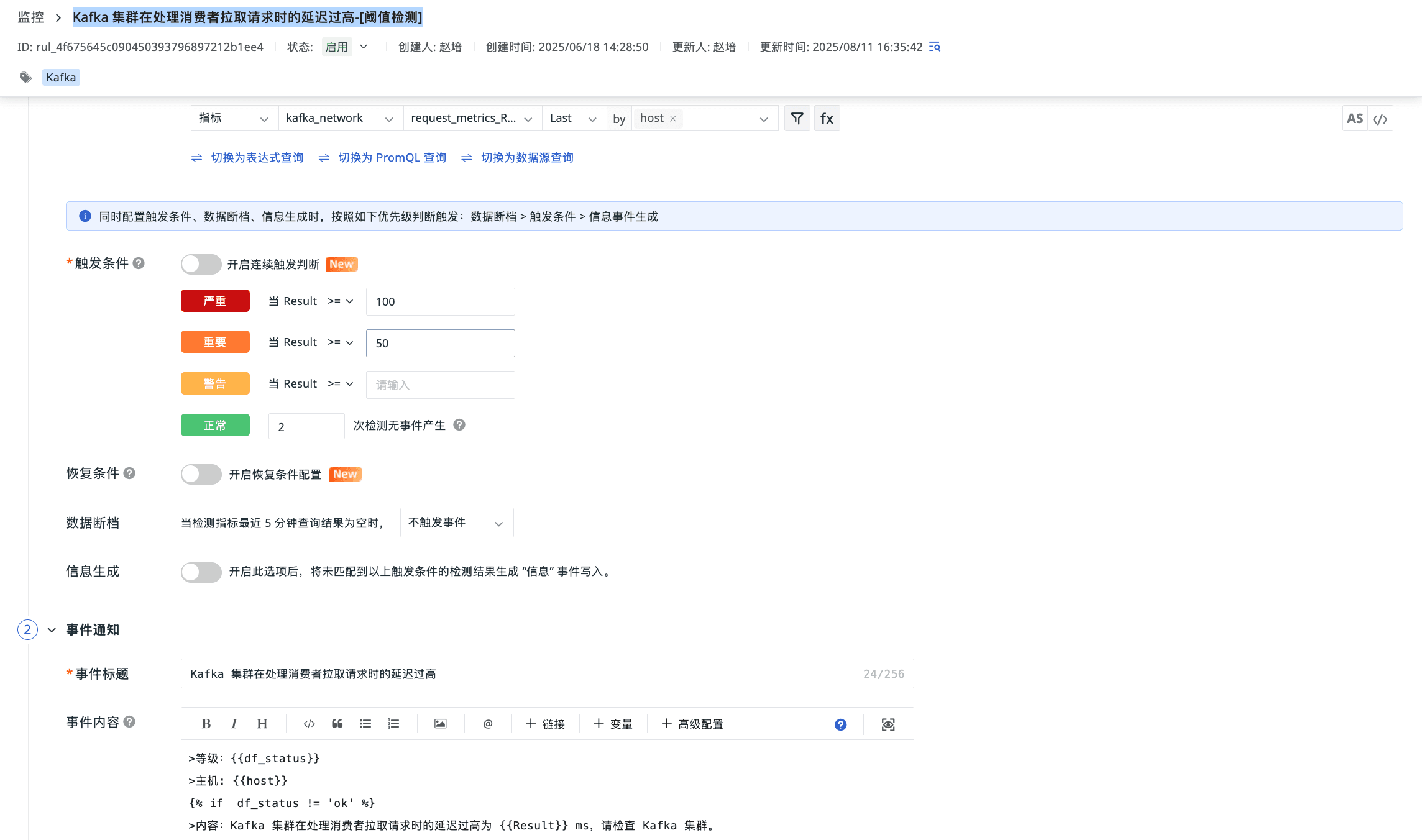
Kafka 集群在处理消费者拉取请求时的延迟过高
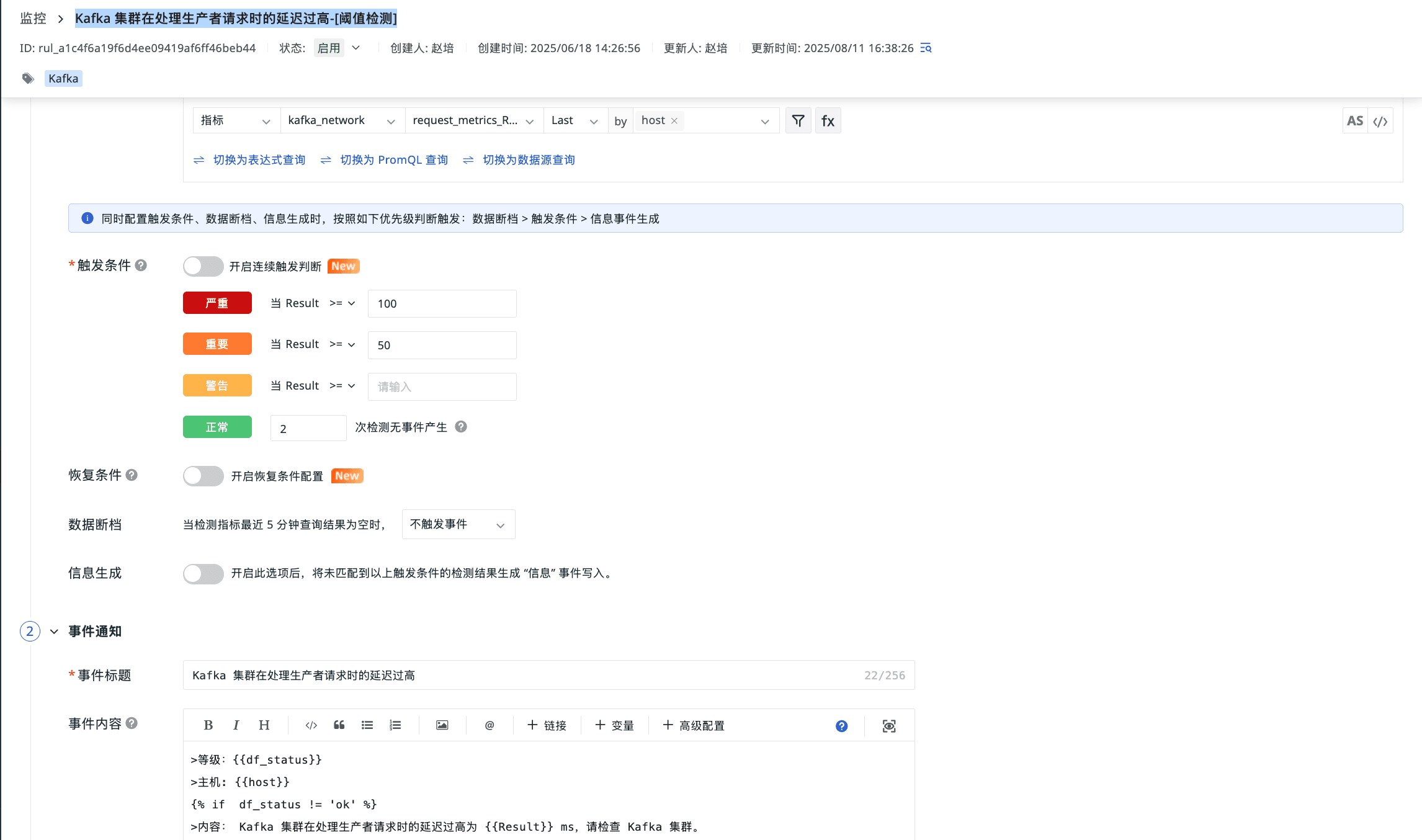
Kafka 集群在处理生产者请求时的延迟过高
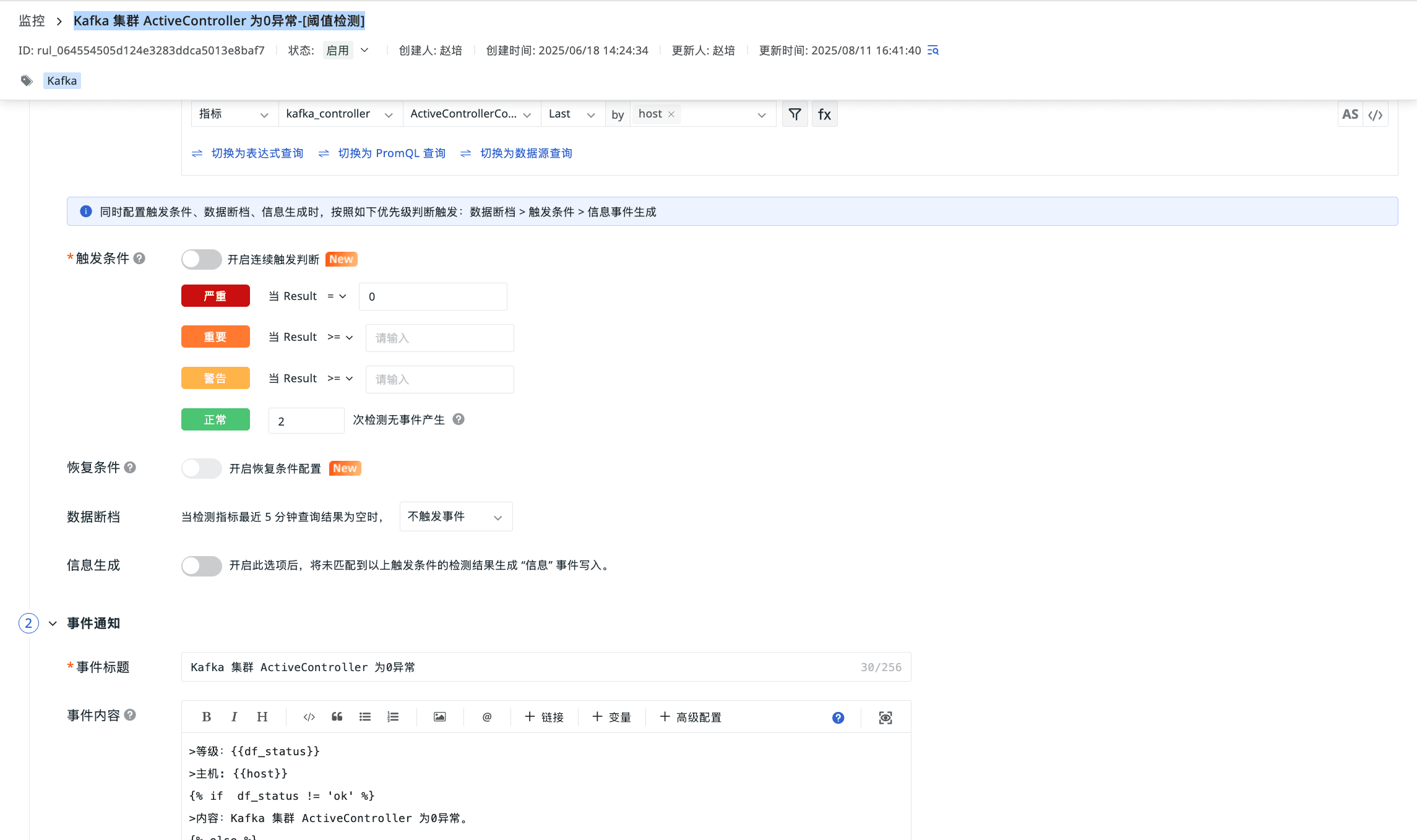
Kafka 集群 ActiveController 为0异常
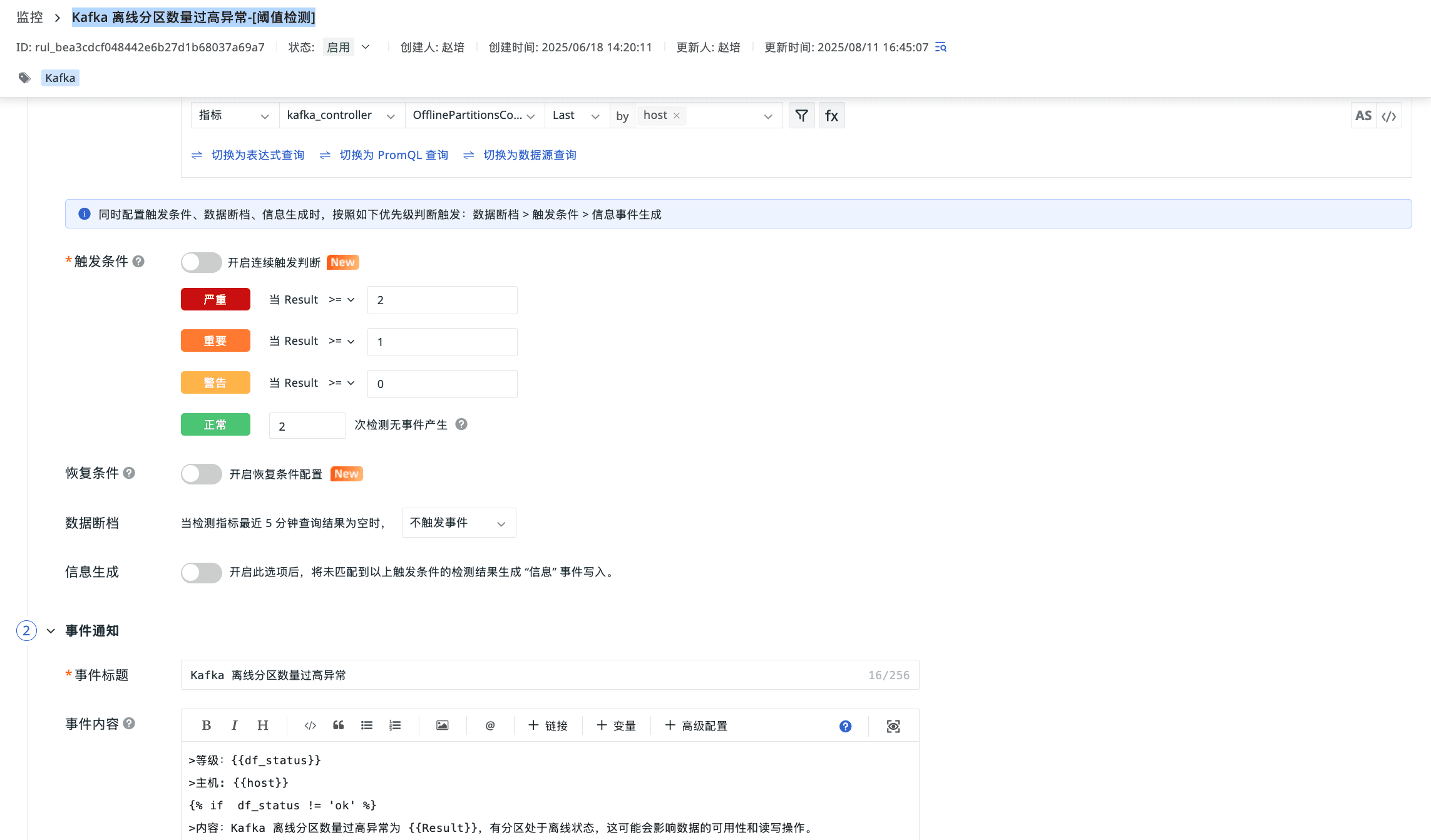
Kafka 离线分区数量过高异常
总结
通过监控 Kafka,我们可以实时掌握消息吞吐、消费者滞后、Broker 健康等关键指标,提前发现副本缺失、网络拥塞或消费延迟,保障系统稳定;也能结合历史基线做容量预测与异常检测,为扩缩容、参数调优提供量化依据,让数据持续高效、可观测、可演进。