语义循环的幽灵——循环解释悖论对NLP深层语义分析的影响与启示
摘要
本报告旨在深入探讨源于哲学、语言学和认知科学的“循环解释悖论”(Paradox of Circular Explanation)对人工智能(AI),特别是自然语言处理(NLP)领域中深层语义分析所带来的根本性挑战与深远启示。报告首先界定并剖析了循环解释悖论的核心特征,即在定义、解释或理解一个概念时陷入自我指涉或相互依赖的逻辑闭环,从而导致意义悬浮、真值不确定甚至逻辑矛盾。随后,报告详细论述了这一悖论在NLP领域的具体影响,指出当前主流的深度学习模型(如Transformer架构)在处理语义时,因其训练方式和内在机制,天然地容易陷入类似的“循环”困境,具体表现为:语义基础的“悬浮”问题、在面对逻辑矛盾和悖论性语句时的处理失效,以及模型解释性的“循环论证”困境。最后,本报告基于以上分析,为未来NLP研究提出三大启示与发展方向:一、通过融合多模态与物理世界知识,打破纯文本的语义循环;二、推动符号主义与连接主义的再融合,增强模型的逻辑推理与一致性检验能力;三、构建能够检测和应对逻辑悖论的新型评测基准与可解释性框架,以期推动AI迈向更鲁棒、更可信的深层语义理解。
引言
随着大型语言模型(LLM)的飞速发展,人工智能在自然语言处理领域取得了前所未有的成就。机器翻译、文本生成、情感分析等任务的性能已达到甚至超越人类水平 。然而,在通往真正“理解”语言的道路上,AI仍然面临着深层次的瓶颈,其中“深层语义分析”是核心挑战之一 。深层语义分析不仅要求模型识别词汇的表面含义,更需要其掌握句子结构、逻辑关系、语境依赖和隐含意义 。
正是在对“意义”本身的追问中,我们遇到了一个古老而深刻的哲学难题——循环解释的悖论。这一悖论在人类的语义和认知活动中普遍存在,它拷问着任何一个试图构建意义体系的尝试。本报告的核心论点是,这一看似抽象的哲学悖论,正在以一种具体而隐蔽的方式,制约着当前NLP技术的发展,并成为其迈向通用人工智能(AGI)的关键障碍。理解此悖论不仅有助于我们认清当前技术的局限,更能为未来的研究指明突破方向。
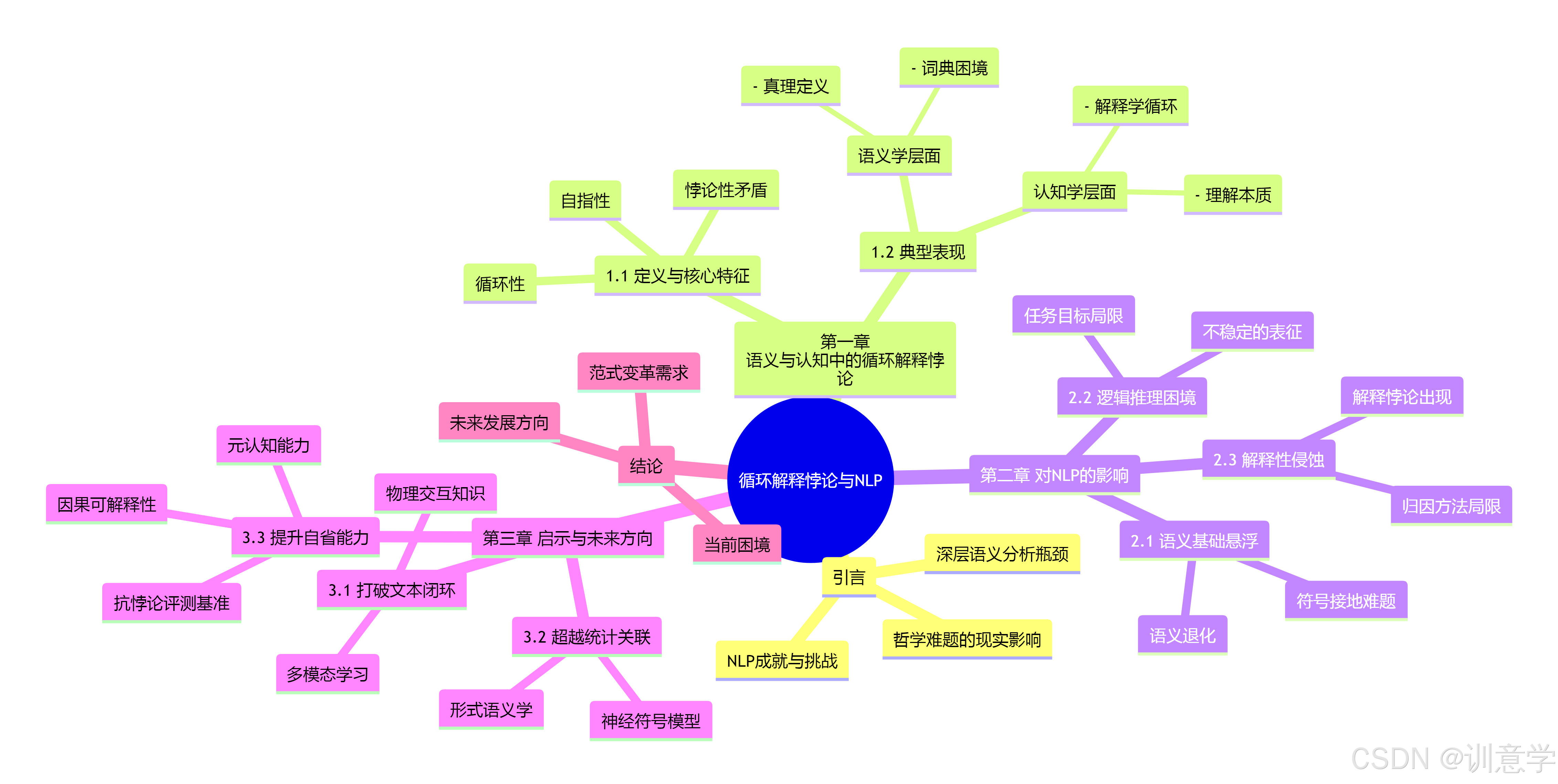
第一章: 语义与认知中的循环解释悖论之解析
在深入探讨其对NLP的影响之前,我们必须首先清晰地界定“循环解释悖论”的内涵、特征及其在人类语义与认知系统中的表现形式。
1.1 定义与核心特征
“循环解释悖论”并非一个单一、固定的术语,而是对一类现象的概括。综合搜索结果,我们可以将其定义为:在试图为某一概念、命题或符号提供最终解释或意义基础时,所陷入的一种自我指涉(self-reference)或相互依赖(interdependence)的闭环,该闭环不仅无法提供新的有效信息,反而可能导致逻辑矛盾、无限回归(infinite regress)或意义的彻底悬空 。其核心特征可分解为以下三点:
循环性(Circularity): 这是其最表层的结构特征。解释A需要B,而解释B又需要C,...,最终解释N又需要回到A 。这种结构可以是直接的(A解释A)或间接的(A->B->A)。例如,“循环定义”(Circular Definition)就是典型的表现,即用一个术语自身或其同义词来定义该术语 。“循环论证”(Circular Reasoning)也属于此类,其结论被用作其前提之一 。
自指性(Self-Reference): 许多语义悖论的核心在于自指或循环指称 。当一个陈述的内容指向陈述本身时,就构成了自指。这种结构是引发悖论的温床,因为它为逻辑矛盾的产生提供了闭环条件 。
悖论性矛盾(Paradoxical Contradiction): 并非所有的循环都是有害的。然而,当循环性或自指性导致了一个无法消解的逻辑矛盾时,悖论就产生了 。最经典的例子是“说谎者悖论”(Liar Paradox):“这句话是假的” 。如果我们假设它为真,则根据其内容,它必须为假;如果我们假设它为假,则它符合其内容描述,又变为真。这种真值的振荡使其无法被稳定地判定 ,其证明过程无法被“归一化”或“归约” 。
1.2 在语义与认知中的典型表现
循环解释悖论并非仅仅是逻辑学家的游戏,它深刻地根植于人类理解世界的方式之中。
语义学层面:词典的困境与真理的定义
在语义学中,最直观的例子莫过于词典。任何一本词典本质上都是一个庞大的循环定义系统 。我们用词语A来解释词语B,用词语C解释A,最终,整个词汇系统形成一个封闭的网络,没有任何一个词语的意义能够“逃逸”到语言之外,与客观实体建立绝对的、非中介的联系。这种意义的内在循环性,使得“意义是什么”这一根本问题悬而未决 。此外,对“真理”这一核心语义概念的定义也充满了悖论色彩。塔斯基(Tarski)试图通过区分对象语言和元语言来解决说谎者悖论,但其理论本身也被批评为存在循环定义的嫌疑 因为定义真理的过程最终可能还是要依赖于我们预先理解的“真”的概念 。认知学层面:解释学循环与理解的本质
在认知科学和哲学解释学中,“解释学循环”(Hermeneutical Circle)是一个核心概念 。它描述了人类理解过程中的一个基本循环:对一个文本(或任何认知对象)整体的理解依赖于对其各个部分的理解,而对各个部分的理解又反过来依赖于对整体的预先把握 。例如,要理解一个句子,你需要理解其中的单词;但要准确理解一个单词的含义,你又需要它所在的句子的上下文。这种部分与整体之间的循环依赖,虽然在认知上是有效的,甚至被认为是理解的必要过程,但从形式逻辑上看,它构成了一个无法提供最终基础的循环解释结构 。这揭示了人类认知并非一个线性的、从公理出发的演绎过程,而是一个动态的、循环往复的建构过程。
第二章: 循环解释悖论对NLP深层语义分析的影响
当前的深度学习模型,特别是基于Transformer架构的大型语言模型 其学习范式和内部机制在不经意间复现了“循环解释”的结构,从而给深层语义分析带来了三大潜在的、根本性的影响。
2.1 语义基础的“悬浮”问题:意义的闭环
当前NLP模型的核心思想之一是“分布式假设”,即词的意义由其上下文决定。诸如Word2Vec、GloVe和BERT等模型,都是通过分析海量文本中词语的共现模式来学习词向量(Word Embeddings) 。一个词的向量表示,本质上是其所有可能上下文向量的加权平均 。
这种方法的巨大成功掩盖了一个深刻的问题:它完美地复刻了词典的循环定义困境。模型在一个纯文本的封闭世界里学习“意义”,一个词的“意义”(其向量)是由其他词的“意义”来定义的。整个语义空间是自洽的、内部关联的,但却是“悬浮”的,缺乏与物理世界或人类经验的“锚点”(Grounding)。这直接导致了:
- 符号接地难题(Symbol Grounding Problem) :模型知道“苹果”经常和“吃”、“甜”、“红色”等词一起出现,但它不知道一个真实的苹果是什么样子、什么味道。它的理解是纯粹关系性的,而非指称性的。这种语义循环使得模型在需要常识推理和与物理世界交互的任务中表现脆弱。
- 语义退化(Semantic Degeneracy) :有研究指出,大型语言模型在生成长文本时,可能会陷入重复循环或语义漂移 。这可以被看作是其内部循环语义系统的一种不稳定表现。当缺乏外部世界的坚实约束时,模型在纯粹的符号操作中可能会迷失方向,陷入无意义的模式重复。
2.2 逻辑推理与真值判断的困境:悖论处理的失效
深层语义分析的一个核心目标是实现逻辑推理。然而,循环解释悖论直接挑战了模型处理逻辑一致性和真值判断的能力。当模型面对一个悖论性句子,如“此声明为假”或更复杂的Yablo悖论(一个无限序列的句子,每个都声称后续所有句子为假 ,会发生什么?
由于当前的深度学习模型是基于统计规律而非形式逻辑构建的,它们缺乏处理这类逻辑矛盾的原生机制。
- 不稳定的表征:当Transformer模型试图为“这句话是假的”生成一个语义表征时,其自注意力机制(Self-Attention)会捕捉到句子内部的自指关系 。然而,由于内容与其自身真值断言之间的根本矛盾,模型无法收敛到一个稳定的、一致的语义状态。这可能导致输出的概率分布变得平坦(高熵),或者在不同的、相互矛盾的解释之间振荡,表现为模型的“困惑”或“瘫痪”。
- 任务目标的局限:模型训练的目标(如预测下一个词或恢复被遮蔽的词)与逻辑真值的判断是完全不同的任务 。模型被优化用来生成“貌似合理”的文本,而非“逻辑上为真”的陈述。因此,当面对一个精心构造的、挑战逻辑底线的悖论时,模型很可能会生成一个回避问题、自相矛盾或毫无意义的回答,因为它没有被训练过去发现并解决这种深层次的逻辑冲突 。
2.3 解释性与可信度的侵蚀:解释的循环
近年来,AI的可解释性(Explainability)成为研究热点 。我们不仅想知道模型给出的答案,更想知道“为什么”它会这么做。然而,循环解释悖论在此处投下了浓重的阴影,导致模型的解释可能陷入“循环论证”的陷阱。
- 归因方法的局限:许多解释性方法,如LIME或SHAP,通过分析输入特征对输出的贡献来提供局部解释 。但如果模型的内部“推理”本身就是循环的,那么这种归因就失去了意义。例如,模型可能判定句子A很重要是因为句子B,而在另一个上下文中,它又会说B很重要是因为A。这种解释构成了一个无法提供真正洞见的闭环 。
- “解释悖论”的出现:有研究指出,在解释深度神经网络时存在一种“解释悖论” 。模型的复杂性越高,性能越强,但其可解释性就越差 。我们可以将循环解释视为这一悖论的根源之一。一个深度的、拥有数千亿参数的模型 ,其内部形成了极其复杂的特征和概念网络。当我们试图解释某个高层概念时,解释本身又是由其他同样复杂的、需要被解释的内部概念构成的,这极易形成解释的无限回归或恶性循环 最终使得任何解释都停留在模型内部的符号游戏里,无法连接到人类可以理解的、基础性的概念上。这严重侵蚀了我们对模型决策过程的信任。
第三章: 对当前NLP研究的启示与未来方向
正视循环解释悖论在NLP领域的“幽灵”,并非要我们悲观地放弃现有技术路径,而是要从中汲取深刻的启示,指引下一代AI技术的发展方向。
3.1 启示一:打破文本闭环——拥抱多模态与物理世界知识
要解决语义的“悬浮”问题,最直接的路径就是打破纯文本的循环。必须将语言符号与非语言信息进行“接地”(Grounding)。
- 发展多模态学习:大力发展能够同时处理文本、图像、声音、视频等多模态信息的模型。让模型在学习“苹果”这个词时,不仅看到它在文本中的上下文,还能“看到”苹果的图片,“听到”咬苹果的声音。这种跨模态的关联学习,为语言符号提供了来自感官世界的意义锚点,从根本上打破了词语解释词语的闭环。
- 融合物理与交互知识:将NLP模型与机器人技术、强化学习相结合,让智能体在与物理世界交互的过程中学习语言。当模型执行“把红色的方块放到蓝色的圆圈上”这个指令并获得成功或失败的反馈时,它对“红色”、“方块”、“之上”等概念的理解就超越了纯粹的文本关联,获得了基于因果和物理规律的坚实基础。
3.2 启示二:超越统计关联——推动符号主义与连接主义的再融合
要解决模型在逻辑推理上的脆弱性,必须承认纯粹的、端到端的深度学习方法的局限性,并重新审视符号主义AI的价值。
- 神经符号(Neuro-Symbolic)模型:将深度学习强大的表示能力与符号逻辑严谨的推理能力相结合。例如,可以利用神经网络将自然语言句子解析为逻辑形式或知识图谱结构 然后在这些符号表示上进行精确的逻辑演算。这样的混合系统有潜力识别并处理悖论。当检测到一个类似“A and not-A”的逻辑矛盾时,符号推理引擎可以将其标记出来,而不是像纯神经网络那样陷入不稳定的状态。
- 引入形式语义学:在模型设计和训练中,更多地借鉴形式语义学和逻辑学的成果,例如,引入类型论、λ演算等工具来约束模型的语义表示空间,确保其生成的内容具有更好的组合性和逻辑一致性 。
3.3 启示三:提升模型自省能力——构建新的评测与可解释性框架
要解决解释性的循环困境和提升模型的可信度,我们需要开发能够“向内看”和“知之为知之”的新工具和新范式。
- 开发抗悖论评测基准:构建专门的评测数据集,其中包含大量的歧义句、花园路径句(garden-path sentences)逻辑谜题以及各种形式的语义悖论。用这些“照妖镜”来系统地评估模型在逻辑一致性、鲁棒性和处理不确定性方面的能力,推动研究朝着更可靠的方向发展。
- 发展因果可解释性:超越基于相关性的归因方法,探索基于因果推理的可解释性技术。例如,使用反事实解释(Counterfactual Explanations)通过提问“如果输入的某个部分不是这样,结果会如何?”来探究模型决策的关键因果驱动因素。这种方法比单纯的特征归因更能揭示模型的“思考”过程,也更容易发现其推理中的逻辑谬误或循环。
- 探索元认知(Metacognition)能力:研究如何让模型具备一定程度的“自我意识”,即能够评估自身预测的不确定性或识别出无法处理的输入(如悖论)。模型不应总是被迫给出一个答案,而应能学会说“我不知道”或“这个问题存在逻辑矛盾”。这将是通往更安全、更可信AI的关键一步。
结论
“循环解释的悖论”如同一面镜子,映照出当前人工智能在追求“智能”的道路上所面临的深层困境。它告诉我们,仅仅通过在海量数据中学习统计模式,AI或许能成为一个卓越的“模仿者”,但难以成为一个真正的“理解者”。当前的NLP模型,其成功在很大程度上建立在一个自我封闭的、循环的符号系统之上,这使其在语义接地、逻辑一致性和可信解释性方面存在着天然的、难以逾越的障碍。
未来的突破,将不再仅仅依赖于更大的模型和更多的数据,而更需要一场范式上的深刻变革。通过将语言与世界相连、将统计与逻辑相融、将能力与自省相结合,我们才有希望打破语义循环的魔咒,引导人工智能走出当前“高能低智”的困境,迈向真正意义上的深层语义理解。