视频模型的主流结构
相较于单张图像,视频比图片多了一个时间维度,针对多出的时间维度,目前模型的主流架构有以下三种:
- 双流
- 3D
- R(2+1)D
- Vedio Transformer
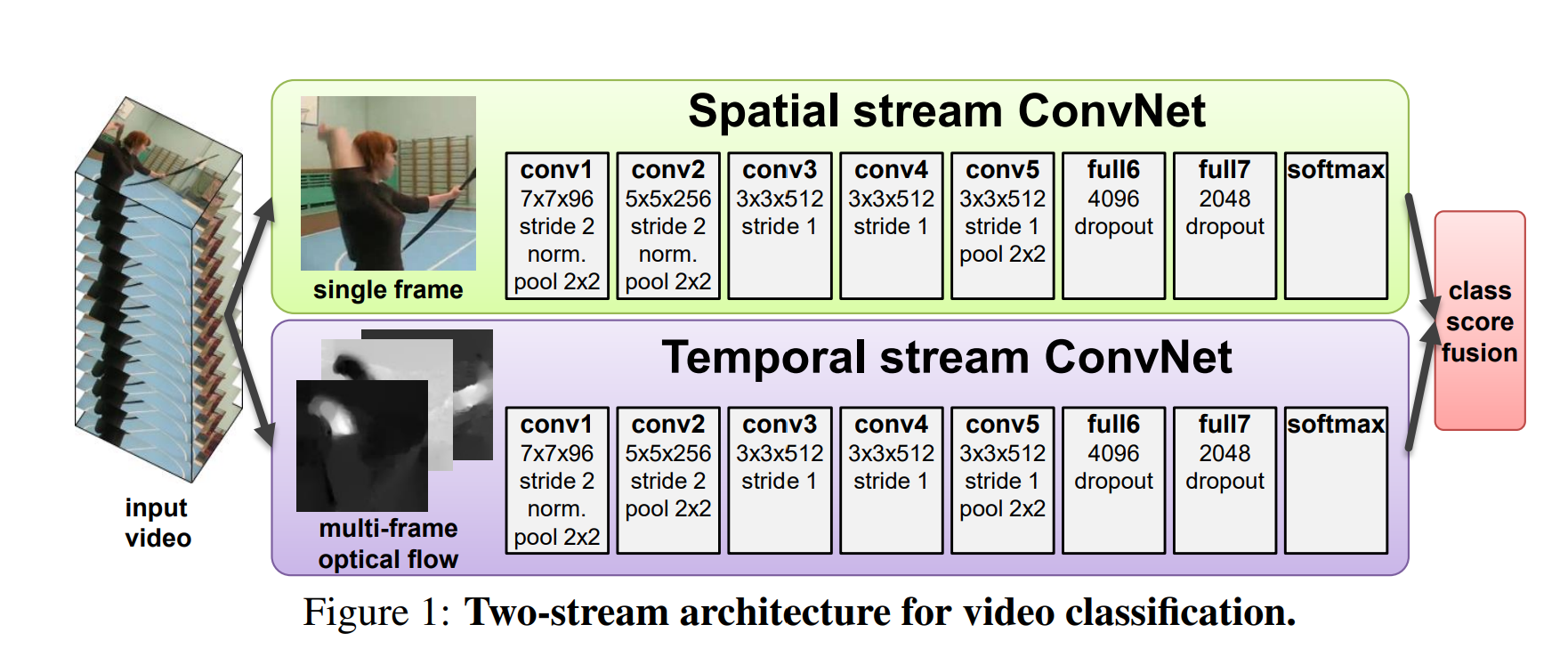
Two-Stream
双流网络是第一个能让深度学习网络的结果媲美手工设计特征的视频分类结构,从此之后,深度学习在视频领域开始占据主流。双流网络通过额外引入一个时间流网络,巧妙的利用光流来提供运动信息(时序信息 )。当使用一个网络无法很好的处理时序信息时,只需要在下面再加一个神经网络去专门处理时序信息 ,比如从原始的视频抽取光流图像,光流图像中包含运动和时序信息。两个网络都不用学习时序的信息,分别学习rgb到分类、光流到分类的映射,把问题简化了幅提高了模型的性能。
光流是描述连续图像帧中像素点运动模式的二维矢量场,广泛应用于计算机视觉、无人机导航和机器人定位等领域。光流说就是每个物体的运动轨迹,运动越明显的区域亮度越高。通过提取光流,可以去掉背景噪声、人物穿着性别等和运动无关的特征都忽略掉,所以最后提取的特征能很好的描述运动信息,也变相的相当于视频里的时序信息的特征表示。光流由一些位移矢量场组成的,其中第t帧的位移矢量用dt表示,是通过第t和第t+1帧图像得到的。dt可以拆分成水平部分dtx和竖直部分dty。将dt、dtx、dty可视化后结果如下:

a、b是前后两帧图片;c是光流dt的可视化显示;d、e分别是水平位移dtx和垂直位移dty。每两张图得到一个光流,如果视频一共抽取L帧,那么光流就是L-1帧。这些光流一起输入光流网络。将光流的密集表示(dense)转为稀疏表示(sparse)以减少光流存储空间,具体来说就是做类似RGB图像的压缩。将光流值全部rescaled到[0,255]的整数,存成JPEG图片
对于空间流和时间流测融合,也有很多的研究工作,1)根据融合的位置也分为Late Fusion、Early Fusion、Slow Fusion;2)尝试更深的网络也是一个研究方向;3)LSTM时序建模。
3D
C3D
3D CNN是直接学习视频里的时空信息,就不需要再额外用一个时间流网络去对时序信息单独建模了,也就不需要使用光流。但是3D网络参数量大,且需要合适的视频数据集去做预训练,之前受到数据的限制,所以之前的3D网络都不太深(比如C3D模型,其网络只有8层),效果也不如双流网络。
I3D
I3D即Inflated 3D ConvNet。Inflated是扩大膨胀的意思,这里是指把一个2D模型扩张到一个3D模型(比如直接将ResNet的卷积核从二维替换为三维,池化也使用3D池化等等)。这样做的优点是,不用再从头设计一个3D网络,直接使用成熟的2D网络进行扩充,而且还可以使用2D网络的预训练参数进行模型初始化,简化了训练过程,使用更少的训练时间达到了更好的训练效果,所以模型可以做的很深,也不需要太多的视频数据进行训练
Inflated
扩张方式非常的简单粗暴,其它网络结构都不变,就是把2D的卷积核加一维变为3D(K*K->K*K*K),2D池化改为3D池化。一直到最新的video swin transformer(2022年),将swin transformer从2D扩张到3D,也是使用这种方式。
Bootstrapping
验证模型是否正确初始化:使用预训练模型初始化自己的模型时,如果同一张图片,分别输入原模型和初始化后的模型,最终输出的结果都一样,就说明原模型的参数初始化是对的(因为两个模型的结构和输入都是一样的)。I3D的作者受此启发,将一张图复制粘贴N次就得到了一个视频,这个视频每个时间步上都是同一张图片。将图片x和其复制N次得到的视频x′分别输入2D网络f和3D网络f′,将后者的网络除以N,如果和2D网络的输出一样,则说明3D网络初始化正常。
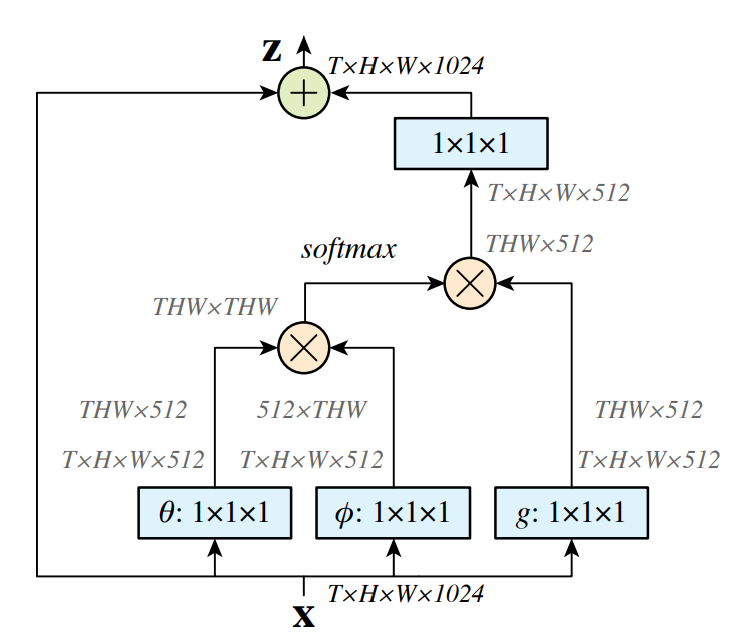
Non-local Block
受到Transformer的影响,Non-local Neural Networks的作者,就考虑将自注意力融入I3D当中。Non-local操作,即将所有位置的特征加权求和,作为某个位置的响应。这些“所有位置”可以是空间维度、时间维度或空间-时间维度,分别对应于图像、序列和视频。

图中xi(球),这个球与前面的所有位置都有关联,但图中只给出了关联性最高的位置。
Non-local Block如下所示:
![]()
这种残差结构,可以让我们在任意的模型中插入一个新的Non-local Block,而不改变其原有的结构。
R(2+1)D
将3D卷积核分解为2D空间卷积和1D时间卷积,通过增加非线性层提升模型表达能力,同时减少优化难度。
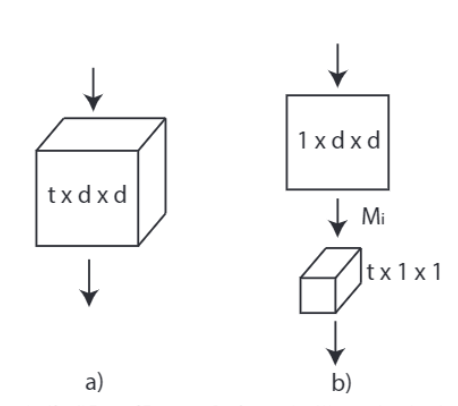
R(2+1)D 就是将一个t*d*d的卷积核,替换为一个1*d*d的卷积核和一个t*1*1的卷积核。也就是先只在空间维度(宽高尺度)上做卷积,时间维度卷积尺寸保持为1不变;然后再保持空间维度不变,只做时间维度的卷积。
3D和2+1D都是目前比较常用的结构, HunyuanVideo使用的就是3D,Movie Gen使用的则是2+1D。
Video Transformer
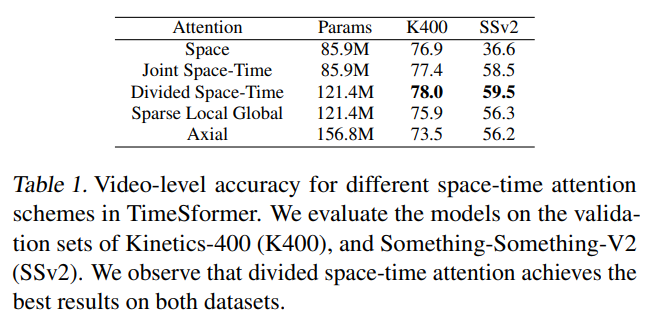
TimeSFormer
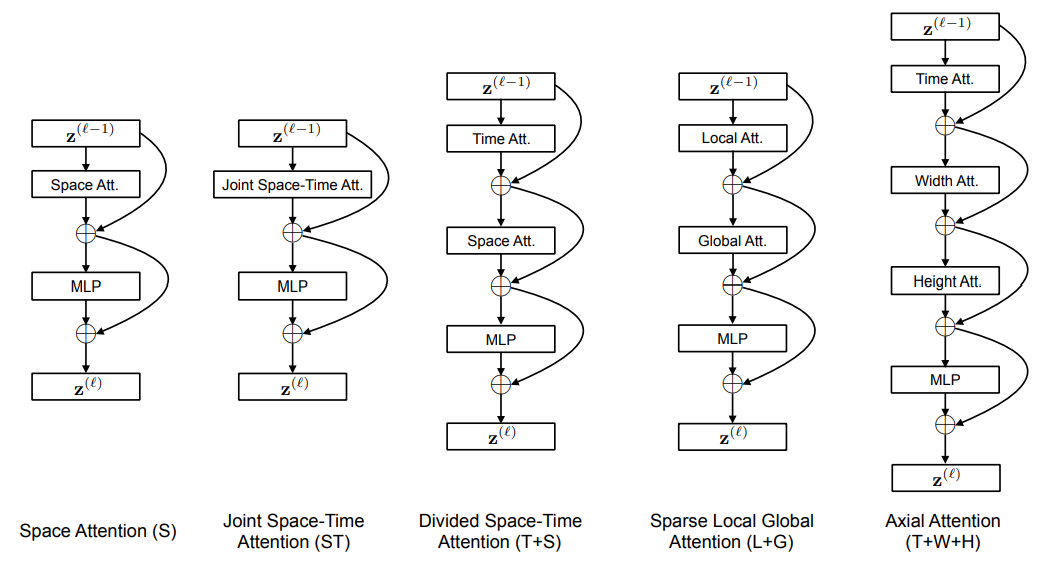
TimeSformer是Facebook AI于2021年提出的无卷积视频分类方法,该方法使用ViT网络结构作为backbone,提出时空自注意力机制,以此代替了传统的卷积网络。借鉴R(2+1)D 的方法,将自注意力操作其拆分为时间自注意力和空间自注意力。
Video Swin Transformer
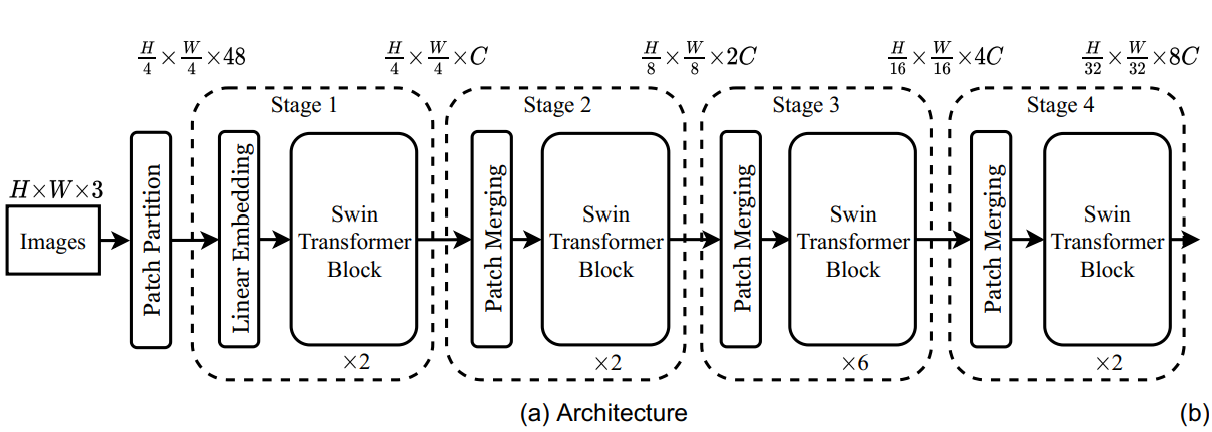
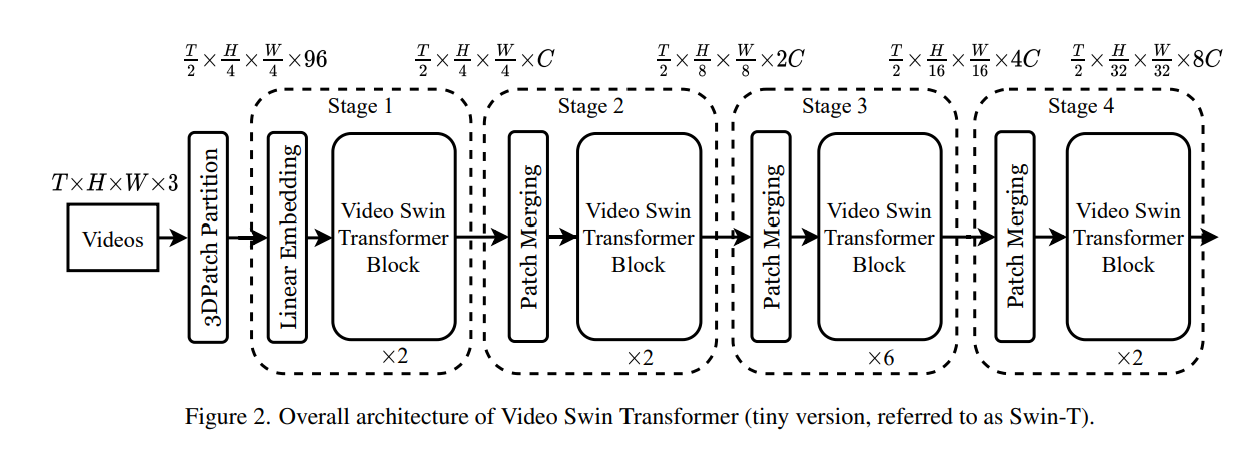
Video Swin Transformer属于是 Swin Transformer的一个变体,它是通过用基于 3D 移位窗口的多头自注意模块替换标准 Transformer 层中的多头自注意(MSA)模块构建的,并保持其他组件不变。因此可以使用在大规模图像数据集上预训练的Swin Transformer模型对其进行初始化。