网站设计弹窗西安免费做网站公司
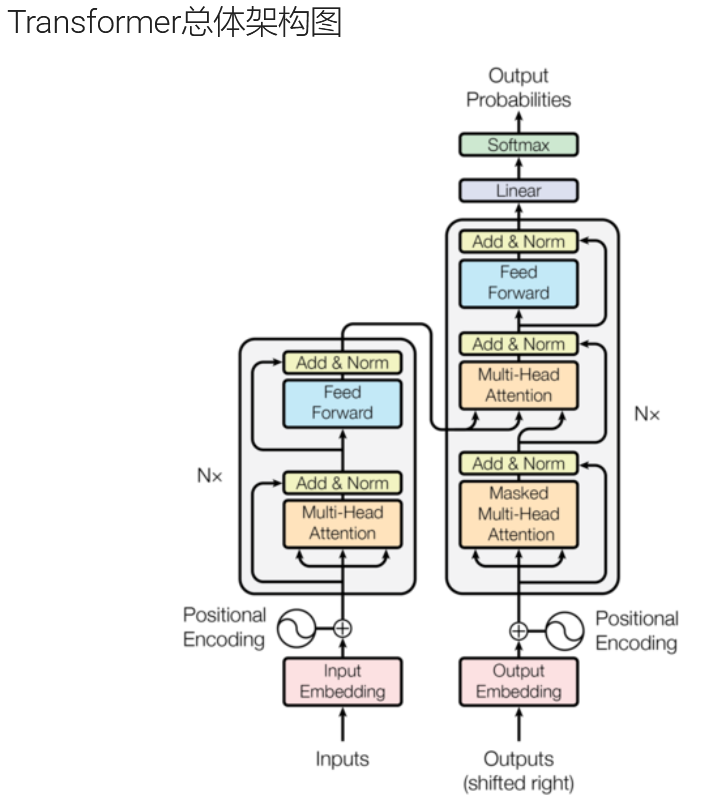
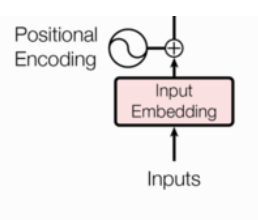
本篇文章主要介绍Transformer左侧输入部分三个关键细节:
- 为什么词嵌入要乘以
- 位置编码层把pe注册到模型的缓冲区,为什么使用register_buffer,而不是
nn.Parameter - 把 '词向量' 和 '位置编码' 进行相加时为什么要加[:,:x.size(1)]
看不懂我在说什么?没关系,下面我们先来看一下Transformer架构中的输入部分 --> 词嵌入层 和 位置编码的一个简单的代码演示。
代码演示:
"""
案例:演示Transformer架构中的 输入部分 -> 词嵌入层 和 位置编码.总结:Transformer的输入部分由2部分组成, 分别是:词嵌入层(Word Embedding)位置编码(Positional Encoding)
"""# 导包
import torch
import torch.nn as nn
import math# todo 1.定义类(模拟词嵌入层), 实现输入部分 -> 词嵌入层 的功能.
class Embedding(nn.Module):# 1. 初始化函数.def __init__(self, vocab_size, d_model):"""初始化参数用的:param vocab_size: 词汇表大小(去重后的单词个数):param d_model: 词嵌入的维度."""# 1.1 初始化父类信息super().__init__()# 1.2 定义变量, 接收: 词汇表大小(去重后的单词个数), 词嵌入的维度.self.vocab_size = vocab_sizeself.d_model = d_model# 1.3 定义词嵌入层, 将单词索引映射为词向量.# '欢迎来广州' -> {0: '欢迎', 1: '来', 2: '广州'} -> 把0(单词索引)转成 [值1, 值2, 值3...]词向量形式self.embed = nn.Embedding(vocab_size, d_model)# 2. 前向传播函数.def forward(self, x):# 将输入的单词索引映射为词向量, 并乘以 根号d_model 进行缩放.# 缩放的目的: 为了平衡梯度, 避免梯度爆炸或者梯度消失.return self.embed(x) * math.sqrt(self.d_model)# todo 2. 测试Embedding(词嵌入层)
def dm01_embedding():# 1. 定义变量, 记录: 词表大小, 词嵌入维度.vocab_size, d_model = 1000, 512# 2. 实例化自定义的词嵌入层.my_embed = Embedding(vocab_size, d_model)# 3. 创建张量, 包含2个句子, 每个句子4个单词.x = torch.tensor([# 单词# ['我', '爱', '吃', '猪脚饭'],# ['我', '爱', '吃', '螺蛳粉'],# 单词索引[100, 2, 421, 600],[500, 888, 3, 615]])# 4. 计算嵌入结果.result = my_embed(x)# 5. 打印结果print(f'result: {result}, {result.shape}')# todo 3.定义类(模拟位置编码层), 实现输入部分 -> 位置编码 的功能.
class PositionalEncoding(nn.Module):# 1. 初始化函数.# 参1: 词向量的维度(512), 参2: 随机失活概率, 参3: 最大句子长度def __init__(self, d_model, dropout, max_len=60):# 1.1 初始化父类信息super().__init__()# 1.2 定义dropout层, 防止 过拟合.self.dropout = nn.Dropout(p=dropout)# 1.3 定义pe(Positional Encoding), 用于保存位置编码信息(结果)pe = torch.zeros(max_len, d_model) # [60, 512]# 1.4 定义1个位置列向量, 范围: 0 ~ max_len - 1position = torch.arange(0, max_len).unsqueeze(1) # 形状: [60, 1]# print(f'position: {position.shape}')# 1.5 定义1个变化矩阵, 本质是: 公式里的 1 / 10000^(2i / d_model)# 10000^(2i / d_model) = e ^ ((2i / d_model) * ln(10000)# 1 / 上述内容, 所以求倒数: e ^ ((2i / d_model) * -ln(10000) -> e ^ (2i * -ln(10000) / d_model)# torch.arange(0, d_model, 2) -> [0, 2, 4, 6, 8....510] 偶数维度# [0, 2, 4, 6, 8....510] + 1 -> [1, 3, 5, 7, 9....511] 奇数维度div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model)) # 形状: [1, 256]# print(f'div_term: {div_term.shape}')# 1.6. 计算三角函数里边的值.# position形状: [max_len, 1] -> [60, 1]# div_term形状: [1, 256]# position * div_term形状: [60, 256]position_value = position * div_term# 1.7 进行pe的赋值, 偶数位置使用 正弦函数(sin)pe[:, 0::2] = torch.sin(position_value)# 1.8 进行pe的赋值, 奇数位置使用 余弦函数(cos)pe[:, 1::2] = torch.cos(position_value)# 1.9 将pe进行升维, 形状: [1, 60, 512]pe = pe.unsqueeze(0)# 1.10 把pe注册到模型的缓冲区, 利用它, 不断的更新参数.self.register_buffer('pe', pe)# 2. 前向传播.def forward(self, x):# x: 词向量, 形状为: [batch_size, seq_len, d_model] -> [1, 60, 512]# 这个代码的核心是: 把 '词向量' 和 '位置编码' 进行相加(融合).x = x + self.pe[:, :x.size(1)] # [1, 60, 512] + [1, 60, 512] = [1, 60, 512]# 随机失活, 不改变形状.return self.dropout(x)# todo 4. 测试PositionalEncoding(位置编码层)
def dm02_position():# 1. 定义词汇表大小 和 词嵌入维度.vocab_size, d_model = 1000, 512# 2. 实例化Embedding层.my_embed = Embedding(vocab_size, d_model) # [1000, 512]# 3. 创建输入张量, 形状: [2, 4], 两个句子, 每个句子四个单词.x = torch.tensor([# 单词索引[100, 2, 421, 600],[500, 888, 3, 615]])# 4. 计算词嵌入结果.embed_x = my_embed(x)# 5. 实例化位置编码层.my_position = PositionalEncoding(d_model, 0.1)# 6. 计算位置编码结果.position_x = my_position(embed_x) # [2, 4, 512]# 7. 返回结果return position_x# 测试代码
if __name__ == '__main__':# 1. 测试词嵌入层dm01_embedding() # shape: [2, 4, 512]print('-' * 40)# 2. 测试位置编码层result = dm02_position()print(result, result.shape)一、为什么词嵌入要乘以 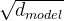
✅ 一句话回答
乘以
是为了平衡词嵌入(Embedding)和位置编码(Positional Encoding)的幅度,防止位置编码在相加时被“淹没”。
这不是“放大”,而是一种缩放(scaling)策略,确保不同来源的信号强度相当。
一、先看代码上下文
class Embedding(nn.Module):def __init__(self, vocab_size, d_model):super().__init__()self.embed = nn.Embedding(vocab_size, d_model)self.d_model = d_modeldef forward(self, x):return self.embed(x) * math.sqrt(self.d_model)self.embed(x):输出词向量,形状[batch, seq_len, d_model]- 每个词向量是随机初始化的,均值为 0,方差较小(通常 ~1/d_model)
- 然后乘以
二、为什么要这么做?核心原因
🎯 问题:词向量太“小”,位置编码太“大”
在 Transformer 中,下一步通常是:
x = embedding(x) + positional_encoding(x)- 词嵌入
embedding(x):来自nn.Embedding,初始权重很小(如 Xavier 初始化,方差 ~1/d_model) - 位置编码
positional_encoding:是固定的正弦函数,值在 [-1, 1] 之间
📌 如果不缩放:
- 词向量:平均幅度 ~1/
- (比如 d_model=512 → ~0.044)
- 位置编码:幅度 ~1
- 相加时,词向量几乎被“淹没”了!
❌ 位置编码 dominates 词嵌入 → 模型一开始只看到位置,看不到语义
✅ 解决方案:放大词嵌入
乘以 后:
- 词向量幅度:1d×d=1d
1×d
- =1
- 位置编码幅度:~1
✅ 两者幅度相当 → 融合更合理
三、数学解释(可选,深入理解)
假设词嵌入矩阵 W∈RV×dW∈RV×d 使用 Xavier 初始化:
- 每个元素 wij∼N(0,1d)wij∼N(0,d1)
- 所以一个词向量 eiei 的 L2 范数期望:E[∥ei∥2]=d⋅1d=1E[∥ei∥2]=d⋅d1=1
- 但单个维度的值很小:~1/d1/d
乘以 dd
后:
- 每个维度变为:eij⋅d∼N(0,1)eij⋅d
- ∼N(0,1)
- 整体幅度提升到与位置编码相当
四、“缩放”是什么意思?不是放大吗?
你问得好!这里“缩放”(scaling)是中性词,不是“缩小”!
在深度学习中,“scale” 可以是:
- 放大(scale up):乘以 >1 的数
- 缩小(scale down):乘以 <1 的数
这里的 * math.sqrt(d_model) 是 scale up(放大),目的是:
让词嵌入的初始幅度和位置编码匹配
所以叫“缩放”没问题,就像你调音量“scale the volume”。
五、后续操作:为什么位置编码不缩放?
因为位置编码是固定的、有明确范围的函数(sin/cos),它的输出天然在 [-1,1],不需要调整。
而词嵌入是可学习的、初始化较小的参数,需要主动放大。
六、这是必须的吗?不加会怎样?
实验表明:
- 不加
- ,模型也能训练,但收敛更慢,初期不稳定
- 加了之后,训练更稳定,性能更好
这也是为什么 Transformer 原论文和大多数实现都采用这个技巧
七、返回值是什么?
return self.embed(x) * math.sqrt(self.d_model)返回的是:
经过幅度缩放的词向量,形状为
[batch_size, seq_len, d_model]
例如:
- 输入:
x = [1, 2, 3](三个词 ID) - 输出:三个 512 维向量,每个都乘了 512≈22.6512
- ≈22.6
这些向量将用于:
- 加上位置编码
- 输入到多头注意力层
八、总结
| 问题 | 回答 |
|---|---|
| 为什么乘 | 让词嵌入的初始幅度和位置编码相当,避免被淹没 |
| 这是放大还是缩小? | 是放大(scale up),但统称“缩放” |
| 不加会怎样? | 模型可能收敛慢、初期不稳定 |
| 返回值是什么? | 缩放后的词向量,形状 [batch, seq_len, d_model] |
| 是必须的吗? | 不是绝对必须,但强烈推荐,是标准做法 |
是一种初始化平衡技巧:它放大词嵌入的幅度,使其与位置编码“势均力敌”,确保在相加融合时,语义信息和位置信息都能被模型有效利用。这不是多余的放大,而是为了让两者“公平对话”。
二、把pe注册到模型的缓冲区
register_buffer 是 PyTorch 中一个非常有用但初学者容易忽略的功能,它在构建深度学习模型(尤其是像 Transformer 这样的复杂架构)时扮演着关键角色。
我们来系统、深入、实战化地讲解:
register_buffer是什么?怎么用?为什么用?和nn.Parameter有什么区别?在 Transformer 中有哪些典型应用?
一、定义
model.register_buffer(name, tensor)作用:向模型注册一个 “持久化的张量”,它:
- 会随模型一起保存和加载(如
.state_dict())- 不会被当作可训练参数(不参与梯度更新)
- 可以在
forward中直接通过self.name访问
二、和 nn.Parameter 的对比(核心区别)
| 特性 | nn.Parameter | register_buffer |
|---|---|---|
| 是否可训练 | ✅ 是(参与梯度更新) | ❌ 否(不计算梯度) |
是否保存在 state_dict | ✅ 是 | ✅ 是 |
| 是否随模型移动(.cuda()) | ✅ 是 | ✅ 是 |
| 是否参与反向传播 | ✅ 是 | ❌ 否 |
| 典型用途 | 权重矩阵 WW、偏置 bb | 掩码、位置编码、动量统计量 |
📌 简单说:
nn.Parameter→ 模型要学习的参数register_buffer→ 模型需要携带的辅助数据
三、为什么要用 register_buffer?不用不行吗?
❌ 不用的坏处:
如果你直接写:
self.mask = torch.tril(torch.ones(10, 10)) # 错误做法!会有以下问题:
- 不会被
state_dict保存 → 模型保存后再加载,self.mask就没了 - 不会自动转移到 GPU → 调用
model.cuda()时,self.mask还在 CPU - 不便于管理 → 不是“官方推荐”的做法
✅ register_buffer 解决了这些问题。
四、基本用法(代码示例)
import torch
import torch.nn as nnclass MyModel(nn.Module):def __init__(self, seq_len=10):super(MyModel, self).__init__()# 1. 注册一个下三角掩码(用于解码器自注意力)mask = torch.tril(torch.ones(seq_len, seq_len))self.register_buffer('mask', mask) # 名字是 'mask'# 2. 注册一个位置编码(可学习 or 固定)pe = self._generate_sinusoidal_encoding(seq_len, 512)self.register_buffer('pe', pe)# 3. 一个真正的可训练参数self.weight = nn.Parameter(torch.randn(512, 512))def _generate_sinusoidal_encoding(self, seq_len, d_model):position = torch.arange(0, seq_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))pe = torch.zeros(seq_len, d_model)pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)return pedef forward(self, x):# 在 forward 中可以直接使用x = x + self.pe # 加位置编码# ... 其他操作return x五、在 Transformer 中的典型应用场景
场景 1️⃣:因果掩码(Causal Mask / Triangular Mask)
在解码器的自注意力中,要防止当前位置看到未来的信息。
# 注册一个上三角掩码(未来位置设为 -inf)
mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1).bool()
mask = mask.masked_fill(mask == 1, float('-inf'))
self.register_buffer('causal_mask', mask)使用时:
scores = scores + self.causal_mask # 加上掩码,未来位置变成 -inf
attn = F.softmax(scores, dim=-1)场景 2️⃣:固定位置编码(Positional Encoding)
如 Transformer 原论文中的正弦位置编码:
pe = self._get_sinusoidal_encoding(max_len, d_model)
self.register_buffer('pe', pe) # 固定不变,不训练在 forward 中:
x = x + self.pe[:, :x.size(1)] # 自动对齐维度场景 3️⃣:可学习位置编码(Learned Position Embedding)
虽然可学习,但通常也用 register_buffer 或 nn.Embedding:
# 可学习的位置嵌入
self.pos_embedding = nn.Embedding(max_len, d_model)
# 或者:
pe = nn.Parameter(torch.randn(1, max_len, d_model))
self.register_parameter('pos_embedding', pe) # 注意:这里是 Parameter⚠️ 注意:如果是可学习的位置编码,应该用
nn.Parameter,而不是register_buffer
场景 4️⃣:BatchNorm 的 running_mean / running_var
你可能不知道:BatchNorm 内部就是用 register_buffer 实现的!
self.register_buffer('running_mean', torch.zeros(num_features))
self.register_buffer('running_var', torch.ones(num_features))
self.register_buffer('num_batches_tracked', torch.tensor(0, dtype=torch.long))这些统计量:
- 不是可训练参数
- 但需要保存和更新
- 所以用
register_buffer
六、和 state_dict 的关系
model = MyModel()# 查看 state_dict
print(model.state_dict().keys())
# 输出:
# ['weight', 'mask', 'pe']
# 注意:'mask' 和 'pe' 也在里面!✅ 所以:
- 保存模型:
torch.save(model.state_dict(), 'model.pth') - 加载模型:
model.load_state_dict(torch.load('model.pth')) - 所有
register_buffer和nn.Parameter都会被正确加载
七、总结:什么时候用 register_buffer?
用 register_buffer 的情况 | 用 nn.Parameter 的情况 |
|---|---|
| 掩码(mask) | 权重矩阵 WQ,WK,WVWQ,WK,WV |
| 固定位置编码(sinusoidal) | 可学习位置编码 |
| 动量统计量(如 BN) | 偏置 bb |
| 预定义的查找表(不训练) | 词嵌入(可训练) |
| 任何需要“携带但不训练”的张量 | 任何需要梯度更新的参数 |
register_buffer是 PyTorch 中用于注册“持久化但不训练”的张量的机制,它确保这些辅助数据(如掩码、位置编码、统计量)能随模型一起保存、加载和设备转移,是构建复杂模型(尤其是 Transformer)的必备工具。
它不是“可训练参数”,但却是模型“运行所需”的一部分,就像火箭的燃料箱——不参与推进,但必不可少。
三、把 '词向量' 和 '位置编码' 进行相加细节
为什么要加 [:, :x.size(1)]?我们来彻底讲清楚。
一句话回答:
[:, :x.size(1)]是为了动态截取位置编码的前seq_len列,以适应当前输入序列的实际长度,避免维度不匹配。初始化的长度不一定等于输入序列的长度。
一、背景:为什么需要这个操作?
假设:
- 你预先注册了一个最大长度为 5000 的位置编码(如 Transformer 原论文)
- 但当前输入的句子长度是 60(
x.size(1) = 60) - 你不能把整个
[1, 5000, 512]的位置编码加到[1, 60, 512]的输入上
所以必须:
只取位置编码的前 60 个位置 →
[1, 60, 512]
这样才能进行 + 操作(广播加法)
二、拆解代码含义
self.pe # 形状: [1, max_len, d_model] = [1, 5000, 512]这是你通过 register_buffer 预先生成的完整位置编码表,比如:
| 位置 | 向量(512维) |
|---|---|
| 0 | pe[0] |
| 1 | pe[1] |
| ... | ... |
| 4999 | pe[4999] |
x.size(1) # 当前输入序列的实际长度,比如 60
self.pe[:, :x.size(1)] # 取前 60 个位置 → [1, 60, 512]然后:
x + self.pe[:, :x.size(1)] # [1, 60, 512] + [1, 60, 512] → 逐元素相加✅ 完美匹配!
总结
| 问题 | 回答 |
|---|---|
为什么加 [:, :x.size(1)]? | 因为 self.pe 是预生成的长序列编码,必须截取当前需要的部分 |
x.size(1) 是什么? | 是当前输入 x 的序列长度(即 seq_len) |
| 不加会怎样? | 维度不匹配,报错! |
| 这个操作安全吗? | 安全,但要确保 seq_len <= max_len |
self.pe[:, :x.size(1)]是一种动态适配机制:无论当前输入句子多长(只要不超过最大长度),都只取对应长度的位置编码进行融合,确保词向量与位置编码在序列维度上对齐。